【小白驯AI日志】机器学习篇02—KNN核心机制全透视:6种距离公式、K折验证详解,为手写算法铺路(中)
本文系统介绍了KNN算法中的核心距离度量方法(欧式、曼哈顿、切比雪夫、闵可夫斯基、余弦、杰卡德距离)及其代码实现,并详细解析了交叉验证技术(留出法和K折交叉验证)。通过对比不同距离公式的特点与适用场景,结合具体编程示例,帮助读者深入理解KNN算法的底层原理。文章还指出高维数据下的距离失效问题,并预告后续将探讨数据预处理、KNN实战应用及其局限性,为机器学习实践提供方法论指导。全文以技术拆解为主线,
目录
3.切比雪夫距离 (Chebyshev Distance):
4.闵可夫斯基距离(Minkowski Distance):
1.留出(保留)交叉验证 (HoldOut Cross-validation(Train-Test Split))
2.K-折交叉验证(K-fold Cross Validation,记为K-CV)
写在前面
“邻居”已经找到了,可到底多近才算亲?
上篇我们把 KNN 的投票规则拍成了“朋友圈合照”——谁离得近就拉谁入镜;今天直接升级成“精密测距仪”:
-
Manhattan 的街区拐角,Chebyshev的国际象棋,Jaccard的集合,一口气全装进
metric=; -
再把“拍脑袋选 K”扔进 10 折交叉验证的绞肉机,让数据自己喊疼;
-
最后徒手撸一遍纯数学逻辑 KNN,把 sklearn 的黑盒子拆成透明乐高。
接下来一小时,不讲故事,只拆零件——距离、调参、源码,三步走完,KNN 就从“玩具算法”变成“生产级武器”。
键盘敲起来,下一行代码,就让模型自己告诉你:谁才是真·邻居!
距离选择
上篇我们提到KNN中对于距离公式的选择至关重要,使用不同的距离公式会得到不同的分类效果,所以来介绍一下常用的距离计算方法
1.欧式距离(Euclidean Distance):
欧氏距离是最容易直观理解的两点之间的距离度量方法,也称为直线距离,简单来讲就是两点之间相连接的直线距离

图为欧式距离计算公式在二维、三维、n维上的计算公式
缺点:
1.欧氏距离虽然只管展示出两个点之间的相关性,然而我们在使用这一方法是需要先对数据进行标准化(为了避免不同特征的量纲、分布和重要性差异对距离计算产生不公平的影响)
2.随着数据维度的增加,欧式距离的用处也就越小
以下是对于欧式距离在代码中实际应用的例子
#编写eucalidean_distance (L2)
#导入数学公式的包
import math
#数组
import numpy as np
#建立两个数据点
x_point=[7.3,4.5]
y_point=[6,4.2]
#第一种方法
def eucalidean_distance(x_point,y_point):
#zip压缩 打包
sum=0
for a,b in zip(x_point,y_point):
sum=sum+(a-b)**2
return np.sqrt(sum)
ed = eucalidean_distance(x_point, y_point)
print(f"ed:{ed}")
#第二种方法
def eucalidean_distance_1(x_point,y_point):
x_1=np.array(x_point)
y_1=np.array(y_point)
return np.sqrt(np.sum((x_1-y_1)**2))
#第2种方法
ed1=eucalidean_distance_1(x_point,y_point)
print(f"ed1 :{ed1}")
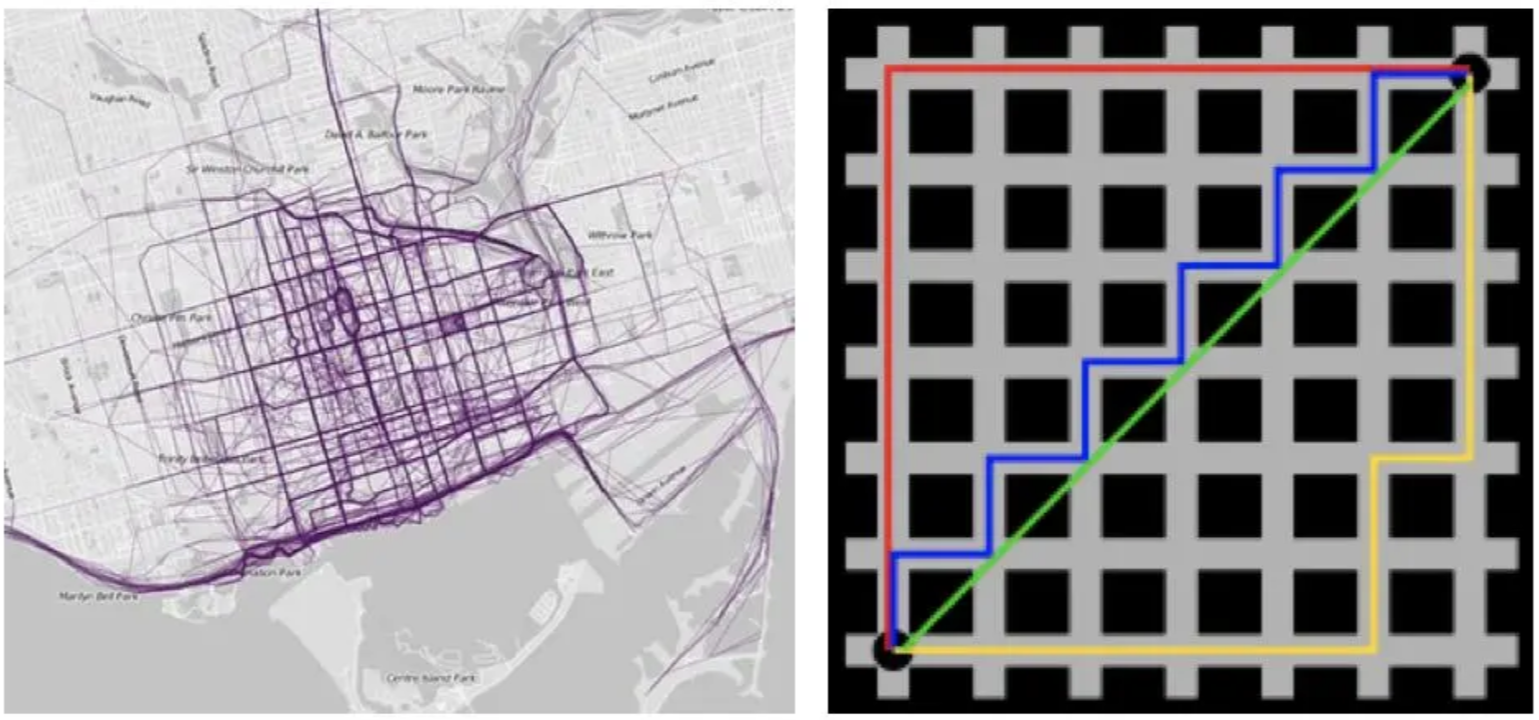
2.曼哈顿距离(Manhattan Distance):
曼哈顿距离是计算两点之间水平线段和垂直线段的距离之和,也称为城市街区距离或L1距离
在曼哈顿街区要从一个十字路口开车到另一个十字路口,驾驶距离显然不是两点间的直线距离。这个实际驾驶距离就是“曼哈顿距离”。曼哈顿距离也称为“城市街区距离”(City Block distance)。
二维并推广到n维的距离公式:
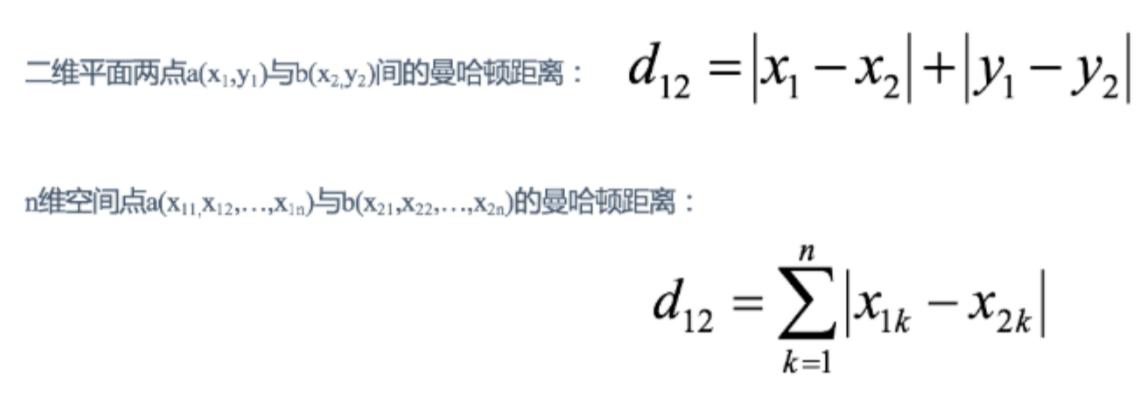 缺点:由于它不是可能的最短路径,它比欧几里得距离更有可能给出一个更高的距离值,随着数据维度的增加,曼合顿距离的用处也就越小。
缺点:由于它不是可能的最短路径,它比欧几里得距离更有可能给出一个更高的距离值,随着数据维度的增加,曼合顿距离的用处也就越小。
以下是对于曼哈顿距离在代码中实际应用的例子
#曼合顿距离也叫城市街区距离
import math
import numpy as np
#计算曼合顿距离
#第一步 先建立两个点
xa=[1,2,3,5,6]
xb=[4,6,7,8,9]
#第一种方法
def manhattan_distance(x,y):
sum=0
for a,b in zip(x,y):#zip()含义是把x和y相同的维度数据进行打包(1,4),(2,6)
sum=sum+abs(a-b)
return sum
md=manhattan_distance(xa,xb)
print(f"md:{md}")
#第2种方法
def manhattan_distance1(xa,xb):
x_1=np.array(xa)
y_1=np.array(xb)
return np.sum(np.abs(x_1-y_1))
md1=manhattan_distance1(xa,xb)
print(f"md1:{md1}")
3.切比雪夫距离 (Chebyshev Distance):
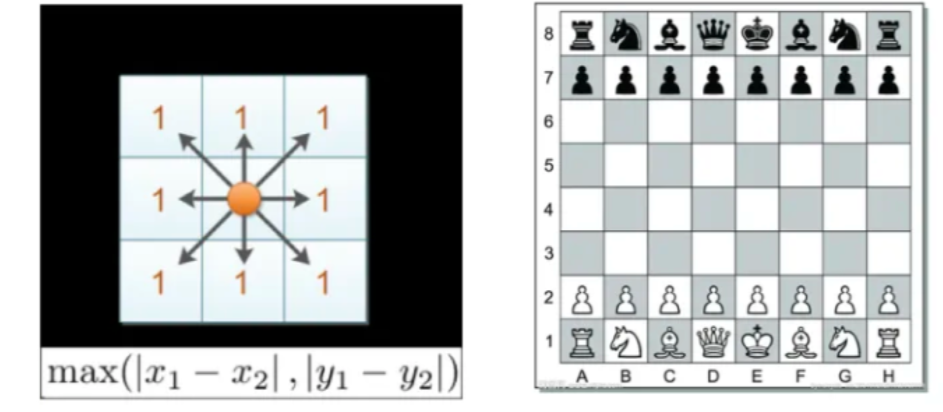
切比雪夫距离是计算两点在各个坐标上的差的绝对值的最大值。
国际象棋中,国王可以直行、横行、斜行,所以国王走一步可以移动到相邻8个方格中的任意一个。国王从格子(x1,y1)走到格子(x2,y2)最少需要多少步?这个距离就叫切比雪夫距离。
下图为简单图示
二维并推广到n维的距离公式
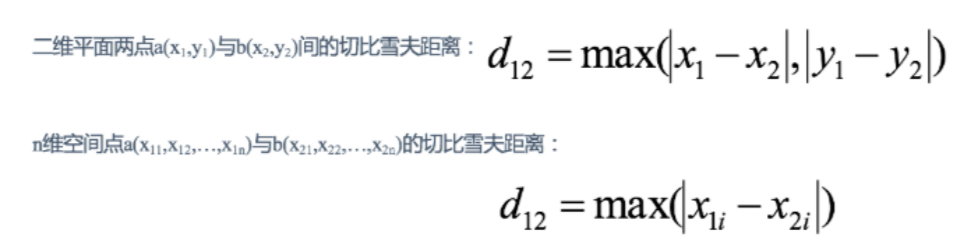
缺点:切比雪夫距离通常用于非常特定的用例,这使得它很难像欧氏距离那样作通用的距离度量
以下是对于切比雪夫距离在代码中实际应用的例子
#切比雪夫距离
import math
import numpy as np
#计算切比雪夫距离
x=[1,2]
y=[4,6]
#第一种方式计算切比雪夫距离
def chebyshev_distance(x,y):
max_list=[]
for a,b in zip(x,y):
max_list.append(abs(a-b))
return max(max_list)
cd=chebyshev_distance(x,y)
print(f"cd:{cd}")
#第2种方法
def chebyshev_distance1(x,y):
x_1=np.array(x)
y_1=np.array(y)
return np.max(np.abs(x_1-y_1))
cd1=chebyshev_distance1(x,y)
print(f"cd1 :{cd1}")4.闵可夫斯基距离(Minkowski Distance):
两个n维变量a(x11,x12,…,x1n)与b(x21,x22,…,x2n)间的闵可夫斯基距离的数学公式为:
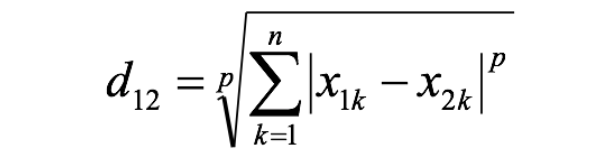
其中:
1.p≥1 是一个实数参数;
2.当 p<1 时,不满足三角不等式,通常不被视为“合法”距离。
闵可夫斯基距离是度量空间中两点之间距离的一种通用公式,它通过一个参数 p 统一了多种常见的距离度量方式,包括上述的三个距离都可以被看做是闵可夫斯基距离公式当中p取不同值时的特殊情况:
当p=1时,就是曼哈顿距离;
当p=2时,就是欧氏距离;
当p→∞时,就是切比雪夫距离。
总的来说,闵可夫斯基距离是一个“距离家族”的统一框架
缺点:
1.对量纲敏感,如果特征单位不同(如身高用 cm,体重用 kg),数值大的特征会主导距离计算(度量标准混乱)
2.高维下失效(维度灾难)在高维空间中,所有点之间的距离趋于相近,导致距离度量失去区分能力(无法分析复杂空间)
以下是对于闵可夫斯基距离在代码中实际应用的例子
import math
import numpy as np
#计算闵可夫斯基距离
#先新建两个数据点
x=[1,2]
y=[4,6]
# 计算闵可夫斯基距离
#p需要初始化为
p=10
def MinkowskiDistance(x, y, p):
x = np.array(x)
y = np.array(y)
if p==1 or p==2:
#计算每维的p次幂的和,然后取1/p次幂
test_num=np.power(np.sum(np.power(np.abs(x-y),p)),1/p)
return test_num
else:
return np.max(np.abs(x-y))
md = MinkowskiDistance(x, y, p)
print(f"md:{md}")5.余弦距离(Cosine Distance)
余弦距离是衡量两个非零向量方向差异的常用度量,它不关注向量的大小(模长),只关注它们之间的夹角,那么这里牵扯到余弦相似度的概念
余弦相似度是两个向量之间的夹角余弦值,表示两个向量的方向差异,而不是长度差异
假设在二维空间中存在两个向量A(x1,y1)B(x2,y2),AB间的夹角余弦公式为:
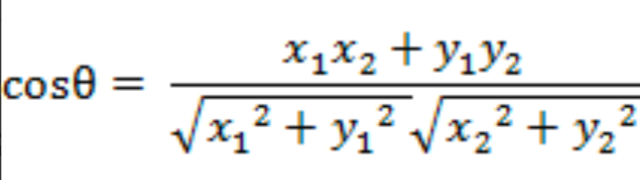
那么我们推广到n维空间中去,假设我们有两个n维样本点a(x11,x12........,x1n)和b(x21,x22..........,x2n),他们间的夹角余弦为:
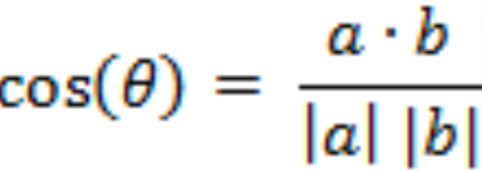
即
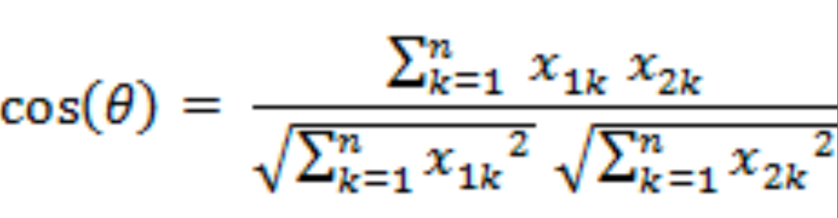
他们的夹角余弦值越大,说明两个向量相似度越高
缺点:
余弦相似度无法捕捉向量的幅度信息,只考虑方向
以下是对于余弦距离在代码中实际应用的例子
import math
import numpy as np
#计算余弦距离
#建立两个数据点
x=[1,1]
y=[2,-2]
#计算余弦距离
def consine_similarity(x,y):
#单独求分子分母
#分子初始化为零
numerator = 0
#分母初始化为零
denominator=0
denominator_x = 0
denominator_y = 0
for a,b in zip(x,y):
#求分子
numerator =numerator +a*b
#分母
denominator_x =denominator_x +a**2
denominator_y=denominator_y+b**2
denominator=math.sqrt(denominator_x)*math.sqrt(denominator_y)
if denominator>0:
return numerator / denominator
return 0
cs=consine_similarity(x,y)
print(f"cs:{cs}")
6.杰卡德距离(Jaccard Distance)
杰卡德距离是用于衡量两个集合差异程度的度量方法,它基于杰卡德相似系数(Jaccard Similarity Coefficient),通过“1 - 相似度”得到距离
杰卡德相似系数:两个集合A和B的交集元素在A,B的并集中所占的比例,称为两个集合的杰卡德相似系数,用符号J(A,B)表示,他的数学表示是:
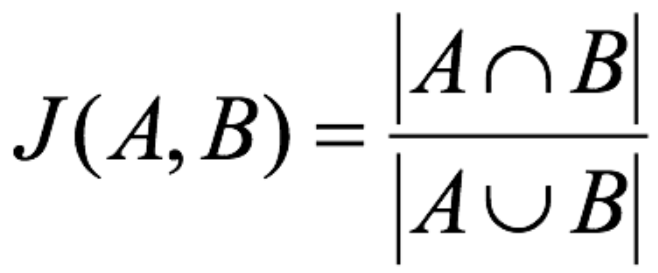
了解到相似度后,我们就可以知道杰卡德距离的数学表示,它使用两个集合中不同元素占所有元素的比例来衡量两个集合的区分度:
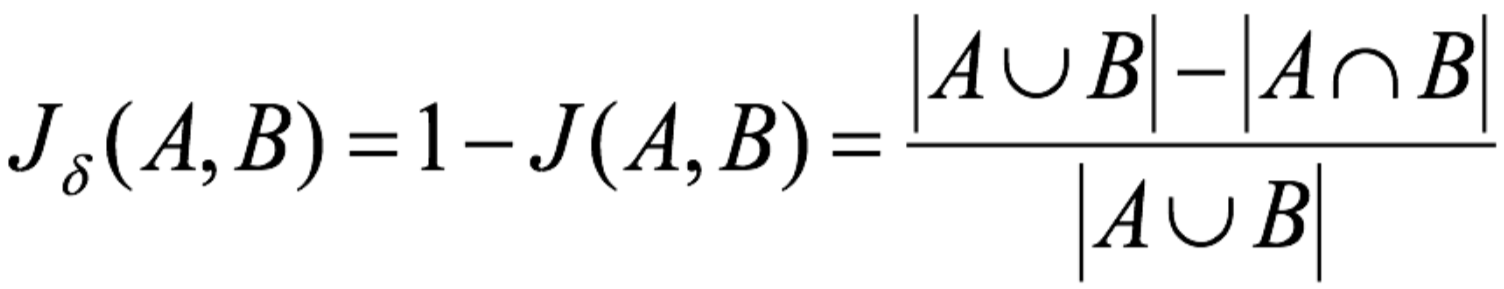
以下是对于杰卡德距离在代码中实际应用的例子
import math
import numpy as np
#jaccrd相似系数
#先建立两个集合
x_set={1,2,3}
y_set={2,3,4}
# step2 jaccrd相似系数计算
def jaccrd_similarity_coefficient(x_set,y_set):
#分子
intersection = len(set(x_set)&set(y_set))
union = len(set(x_set)|set(y_set))
if (union > 0):
return intersection / union
return 0
jsc=jaccrd_similarity_coefficient(x_set,y_set)
print(f"jsc距离 :{1-jsc}")交叉验证方法(Cross Validation )
除了学习与设计模型的具体运行原理与代码以外,处理输入的数据集也是建立模型与验证模型不可或缺的一环,针对于这个问题,我们一般使用交叉验证
交叉验证是在机器学习建立模型和验证模型参数时常用的办法,一般被用于评估一个机器学习模型的表现。更多的情况下,我们也用交叉验证来进行模型选择
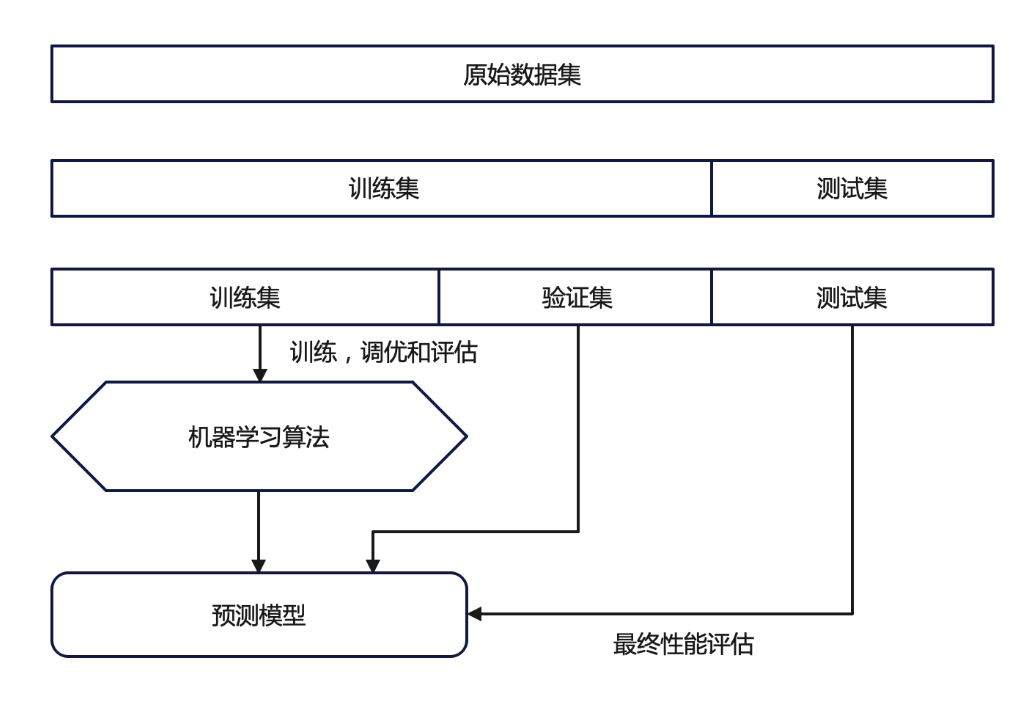
交叉验证的基本图解
尽管交叉验证的整体思想统一——即通过多次划分训练集与验证集来更稳健地评估模型性能,但其具体实现方式却有多种变体,适用于不同的数据规模、任务类型和计算资源条件。下面,我们将重点介绍两种最常用且具有代表性的交叉验证方法
1.留出(保留)交叉验证 (HoldOut Cross-validation(Train-Test Split))
采取直接划定的方式,将整个数据集随机地划分为训练集和验证集。根据经验法则,整个数据集的近70%被用作训练集,其余30%被用作验证集。也就是我们最常使用的,直接划分数据集的方法
2.K-折交叉验证(K-fold Cross Validation,记为K-CV)
模型最终的准确度通过取k个模型验证数据的平均准确度来计算
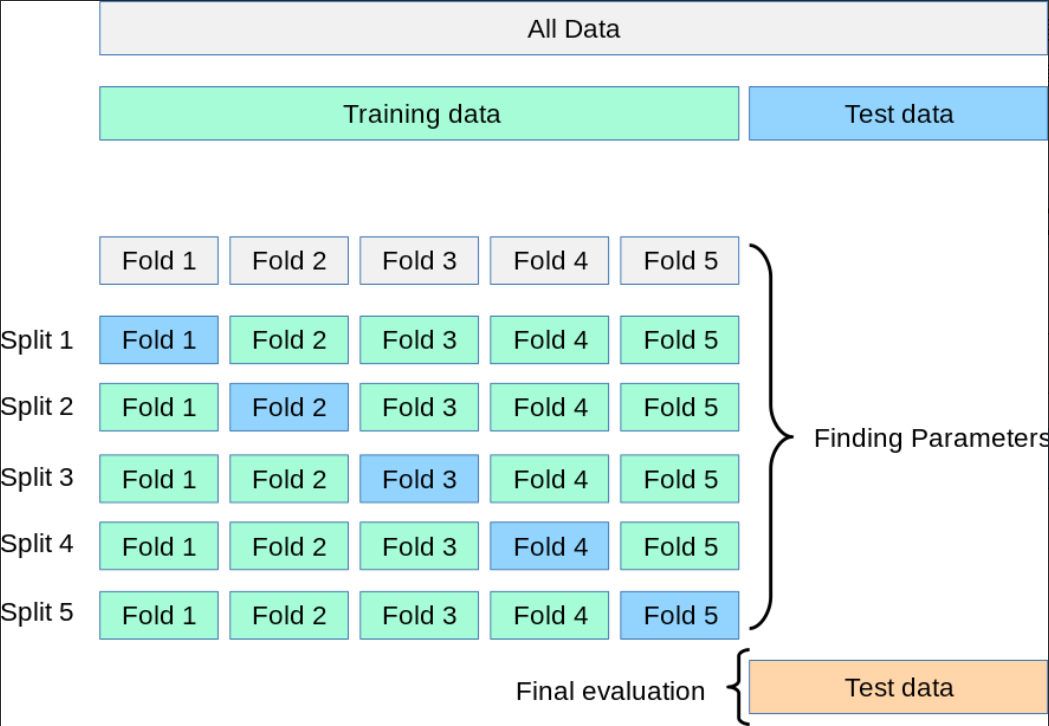
K-折交叉验证的图示
如图所示,
1.我们先将整个数据集氛围两个部分,分别是训练集(Training Data,用于训练模型和调参)与测试集(Test Data,最后用于最终评估模型性能,在整个过程中不参与训练或调参)
2.随后将Training data 被划分为 k 份(这里是 5 份)将训练数据平均分成 5 个“Fold”(折)
3.根据这五个折进行五次迭代(Split 1 ~ Split 5),每次选择其中四个是训练集,一个fold是验证集,在每一次迭代中使用训练集训练模型,使用验证集评估模型性能
4.综合所有因素找到最佳参数(Finding Parameters)
5.使用 之前保留的 Test data(测试集) 对最终模型进行最后一次、无偏评估
现在我们了解了K-折交叉验证的基本流程,再给出一个Kfold交叉验证代码实现
# Kfold交叉验证
from sklearn.model_selection import KFold
from sklearn.datasets import load_iris
#获得数据
iris = load_iris()
# iris数据集,X是特征,Y是标签
X=iris.data
Y=iris.target
#申请一个对象
kf = KFold(n_splits=5)
#kf.split(X)切分数据集切分成5份 #enumerate枚举和直接变量变量就多了一个索引值
for i,(train_index,test_index) in enumerate(kf.split(X)):
print(f"Fold{i+1}")
print(f" Train: index={train_index}")
print(f" Test: index={test_index}")结语
到这里,我们已经把 KNN 的“骨架”彻底拆开:
从欧式距离到余弦相似度,搞清了“谁才算真邻居”;
用K 折交叉验证代替盲目划分,让评估结果不再靠运气;
甚至亲手实现了各种距离函数和验证流程——
KNN 不再是黑箱里的玩具,而是一把可调、可控、可解释的基础建模利器。
但光有算法还不够。
真实世界的数据充满噪声、量纲混乱、特征冗余……
如何预处理?何时该用 KNN?它又为何在高维空间“失灵”?
下一期,我们将:
- 用 Python 从零手写 KNN 分类器
- 实战特征标准化与维度影响
- 深度剖析 KNN 的三大优势与致命短板
键盘已热,数据待洗——
真正的“驯AI”之旅,现在才刚开始。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 30
30 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)