RoboMemory:一种受大脑启发的多记忆智体框架,用于物理具身系统中的交互式环境学习
25年10月来自深圳未来智联网络研究院(FNii-Shenzhen)、香港中文大学SSE、香港中文大学(深圳)、香港大学、南洋理工、哈工大(深圳)、哈尔滨工程大学和 Infused Synapse AI 的论文“RoboMemory: A Brain-inspired Multi-memory Agentic Framework for Interactive Environmental Lear
25年10月来自深圳未来智联网络研究院(FNii-Shenzhen)、香港中文大学SSE、香港中文大学(深圳)、香港大学、南洋理工、哈工大(深圳)、哈尔滨工程大学和 Infused Synapse AI 的论文“RoboMemory: A Brain-inspired Multi-memory Agentic Framework for Interactive Environmental Learning in Physical Embodied Systems”。
具身智体在现实世界环境中面临着诸多挑战,包括部分可观测性、有限的空间推理能力以及高延迟的多记忆整合。RoboMemory,是一个受大脑启发的框架,它将空间记忆、时间记忆、情景记忆和语义记忆统一到一个并行化的架构下,以实现高效的长时程规划和交互式环境学习。动态空间知识图谱 (KG) 确保可扩展且一致的记忆更新,而带有评价模块的闭环规划器则支持在动态环境中进行自适应决策。在 EmbodiedBench 上的实验表明,基于 Qwen2.5-VL-72B-Ins 构建的 RoboMemory 的平均成功率比其基线提高 25%,并且比闭源最先进 (SOTA) 的 Gemini-1.5-Pro 高出 3%。现实世界的试验进一步证实其累积学习能力,其性能在重复任务中不断提升。
RoboMemory的设计灵感源于认知神经科学[27],包含四个核心组件(如图所示):(1)信息预处理器(受丘脑thalamus启发),用于多模态感觉整合。(2)综合具身记忆系统(受海马hippocampus启发),通过三层结构(长期记忆、短期记忆和感觉记忆)组织经验和空间知识。在这个分层系统中,空间记忆、时间记忆、情景记忆和语义记忆四个记忆模块在统一的并行更新范式下运行,以实现连贯的知识整合,同时最大限度地减少延迟。(3)闭环规划模块(受前额叶皮层prefrontal cortex启发),用于高级动作排序。这三个模块共同构成一个具有全面感觉和记忆能力的高级规划器。 (4)底层执行器(受小脑cerebellum启发),由基于VLA的操作模型和基于SLAM的导航模型组成。底层执行器通过底层控制信号直接控制机器人,使其在真实环境中导航和运行。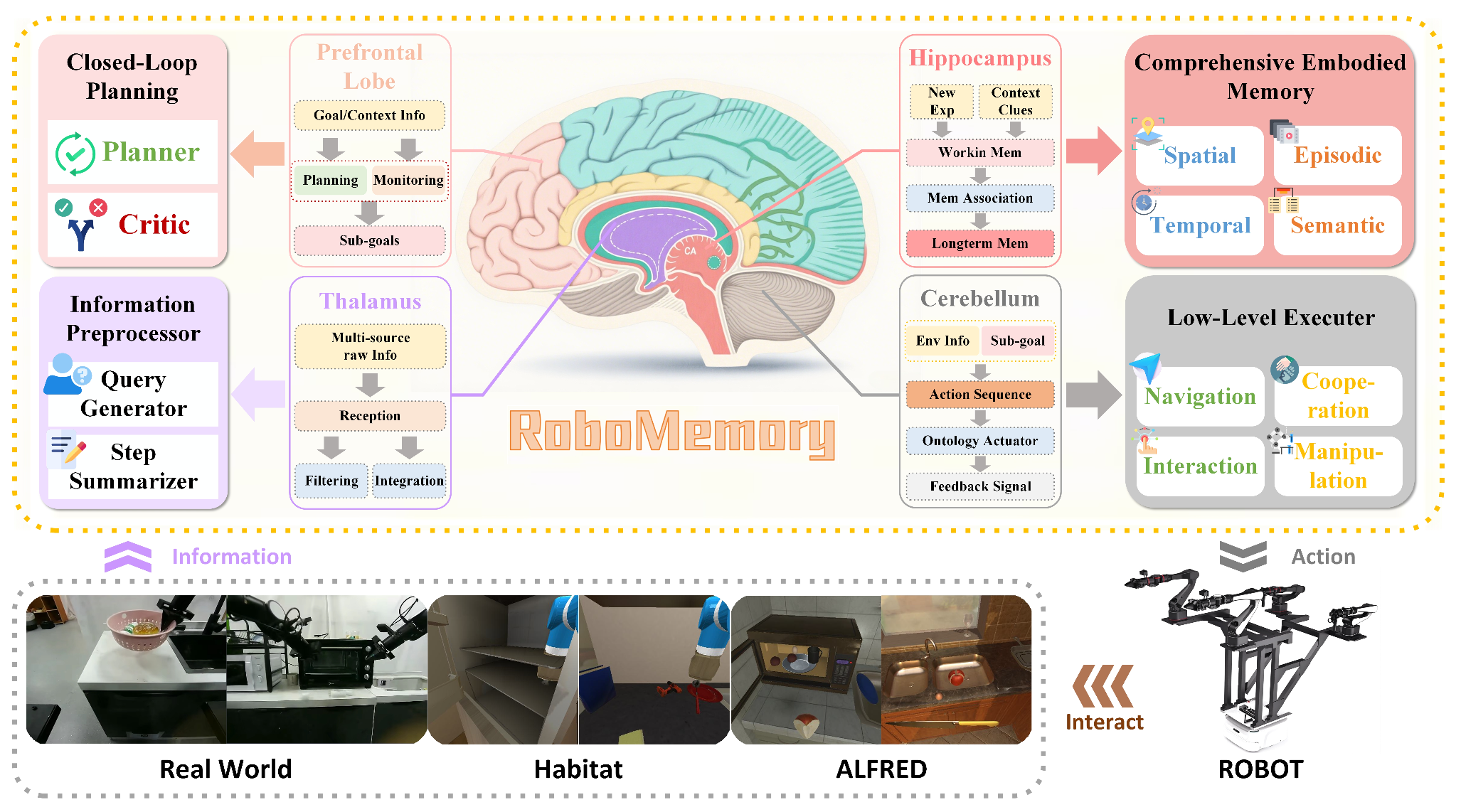
RoboMemory 是一种分层具身智体系统,它赋予机器人三种核心记忆能力:历史交互日志、动态更新的空间布局和累积的任务知识。如图所示,RoboMemory 在每次迭代中都遵循“感知-记忆-检索-规划-执行”的流程,确保智体能够在动态环境中持续校准其记忆和行为。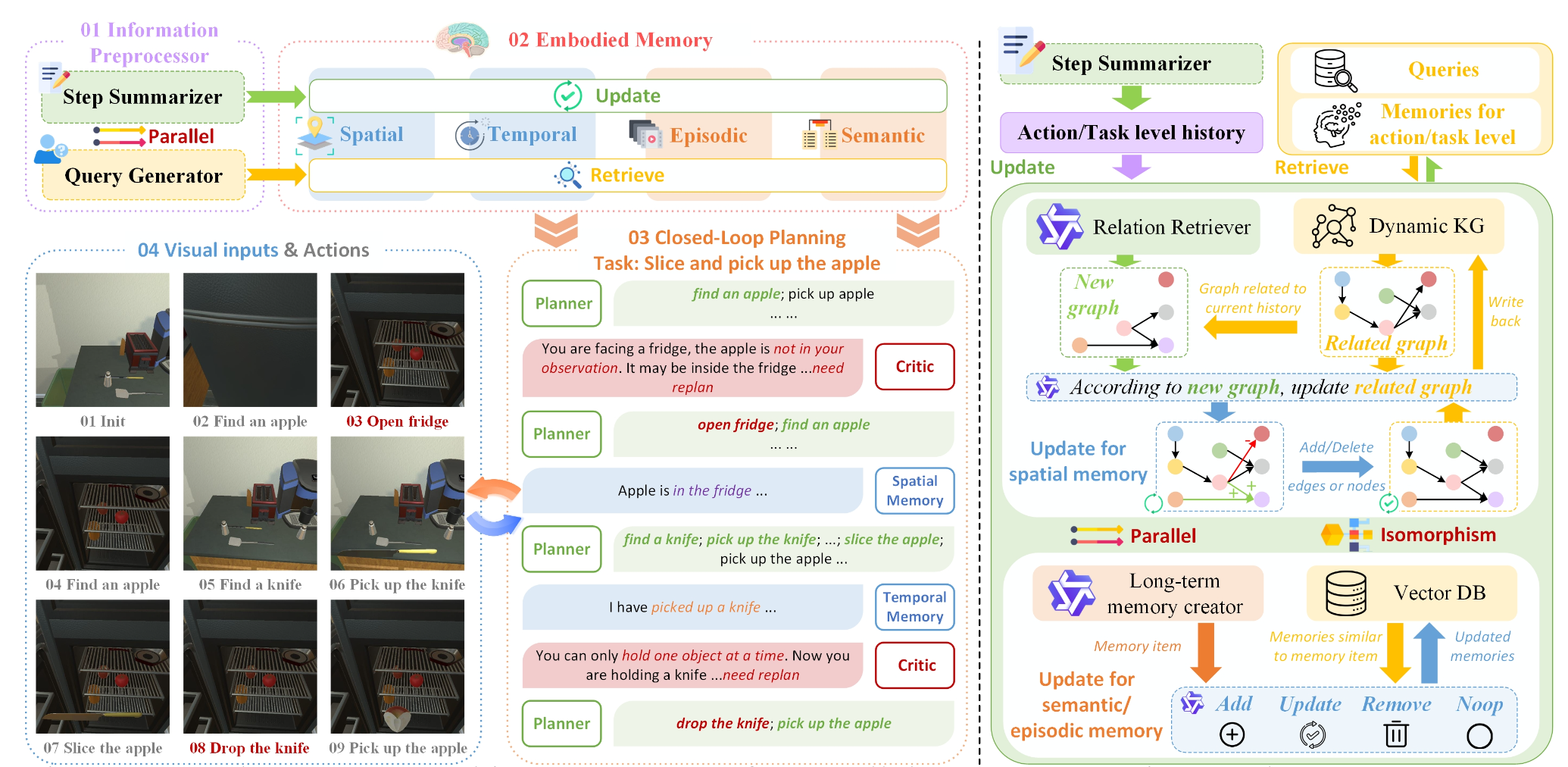
首先,信息预处理器将多模态传感器输入转换为当前场景的文本摘要,作为综合具身记忆的主要输入。接下来,综合具身记忆更新其内部表征,包括动作历史、物体位置和经验知识。信息更新后,记忆系统检索上下文相关的条目,以指导闭环规划模块。然后,闭环规划模块利用这些上下文记忆生成高级的、基于文本的动作指令。最后,这些指令被分发给底层执行器,由底层执行器直接控制机器人并完成指令。
信息预处理器
在每个时间步 i,RoboMemory 接收一个视觉观测值 O_i:在仿真环境中为 RGB 帧,在物理机器人中为短视频片段,代表智体的观测结果。
由于原始视觉数据不适合直接用于记忆构建和检索,RoboMemory 首先使用信息预处理器将多模态观测值转换为文本表示,从而为后续的记忆和规划模块提供语义接口。信息预处理器并行执行两个视觉语言模型 (VLM):(1) 步骤摘要器 S:将 O_i 转换为对刚刚执行的动作的简洁文本描述 s_i。字符串 s_i 存储在系统的工作内存中。(2) 查询生成器 Q:从相同的观测值 O_i 中导出查询 q_i,用于探测长期记忆中相关的事件。
S 和 Q 共同提供一个快速的、基于文本的界面,用于在原始感官数据之间进行交互,并在 RoboMemory 的综合具身记忆系统的每次迭代中提供基本信息。
综合具身记忆系统
提出一种高级记忆系统,旨在增强具身智体的长时程规划能力,并使其能够在动态、部分可观测的环境中进行交互式学习。该系统基于 RAG 和 KG 技术 [18],包含时空记忆和长期记忆。时空记忆持续编码物体关系、环境布局以及详细的任务执行轨迹。这些记录提供给长期记忆,长期记忆会处理每个任务中收集的时空信息,捕捉哪些策略成功或失败以及相关的环境信息(如上图所示)。
综合具身记忆模块从信息预处理器接收汇总的感知信息,以实时更新两个记忆组件。关键在于,所有更新和检索操作均并行执行,即使在多个记忆模块同时运行时也能确保高效运行。
提出一种基于检索的增量式知识图谱更新算法,该算法维护一个局部可修改、全局一致且动态自适应的空间记忆。如上右图所示,更新过程分为四个步骤:(1)检索新观测值周围最相关的子知识图谱。(2)通过基于 VLM 的关系检索器,从当前观测值注入新的关系。 (3) 使用基于 VLM 的解析器检测并解决新提取的关系与现有关系之间的冲突(例如,“杯子在桌子上”与“杯子在抽屉里”),并决定是添加、删除还是修改边。(4) 合并并剪枝孤立顶点。此外,基于检索的增量更新算法具有可证明的效率保证:对于具有 n 个顶点且最大度为 D 的知识图谱,每次更新处理的顶点数以 O(DK) 为界,其中 K 是检索跳数距离。
交互式环境学习系统
尽管情景记忆可以记录“发生了什么”,但它无法直接回答“为什么成功/失败”或“下次应该怎么做”。借鉴认知心理学对人类长期记忆的分类,将系统分为情景记忆和语义记忆:前者记录智体与环境的交互历史,后者提取经验洞察以支持长期任务推理。这种更新过程类似于人类在睡眠期间对日常经验的巩固[25]。
情景记忆:它捕捉任务层面的交互,并考虑同一环境中连续任务之间的时间依赖性。智体必须记住之前的行为才能完成未来的任务。此外,任务层面的交互可以作为参考,帮助智体改进未来的计划。
语义记忆:它积累逐步的动作使用经验(基于已执行的动作和结果),以指导动作安排。任务完成后,它会总结时间记忆,提炼已完成任务中的成功经验,并从失败任务中识别失败原因/改进策略,从而实现跨任务和动作层面的动作级和任务级学习。
在实现过程中,情景记忆和语义记忆共享同一个 RAG 框架,该框架由提取器、更新器和 RAG 存储组成(每个条目都是一个记忆实体)。任务完成后,提取器将任务的时空记忆总结成一个新的记忆实体。然后,RAG 从 RAG 中检索类似的现有实体(旧信息)。接着,更新器根据新信息删除、添加或更新旧的记忆实体。之后,将更新后的记忆实体写回 RAG。由于只更新与新信息相似的记忆实体,因此通过将更新限制在与新实体相关的旧记忆实体上,而不是更新 RAG 中存储的所有记忆实体,从而确保了效率。
动态环境下的闭环规划模块
闭环规划模块整合时空记忆提供的当前任务信息、长期记忆中记录的语义和情景信息以及当前观察结果,以执行动作规划。每个动作都经过规划,并传递给底层执行器执行。
为了在具身环境中实现闭环控制,闭环规划模块采用规划器-评价器机制[23],该机制由规划器模块和评价器模块组成。对于每个规划步骤,规划器都会生成一个包含多个步骤的长期规划。然而,由于具身环境的动态性,长期规划中的动作序列在执行过程中可能会过时。因此,在执行每个步骤之前,用评价器模型来评估该步骤中提出的动作在最新环境下是否仍然合适。如果不再合适,规划器将基于最新信息重新规划。上图展示了这一过程。
然而,实验表明,原始的规划器-评价器机制可能存在无限循环的问题。在原始机制中,规划器输出的动作序列的第一步在执行前会先由评价器进行评估,这可能导致无限循环:如果评价器总是要求重规划,则永远不会执行任何动作。为了解决这个问题,修改规划器-评论器机制,使得评论器不再评估第一步。这确保即使评论器持续要求重规划,RoboMemory 仍然能够执行动作。
底层执行器
RoboMemory 框架是一个两层分级智体框架。这种设计使 RoboMemory 能够在现实世界中完成长期任务。上层仅负责高层规划,而底层执行器则在真实环境中执行上层规划的动作。
采用经过 LoRA 微调的 VLA 模型 π0 [19, 5] 来生成操作动作,并采用基于 SLAM 的导航模型进行运动。底层执行器随后将 RoboMemory 规划的高层动作转化为现实世界中具体的机械臂和底盘运动。
为了便于比较,考虑两种类型的基线模型。首先,选择先进的闭源和开源VLM作为单个智体,并将其性能与 RoboMemory 进行比较。对于闭源 VLM,选择 GPT-4o 和 GPT-4o-mini [28, 21]、Claude3.5-Sonnet [2]、Gemini-1.5-Pro 和 Gemini-2.0-flash [36, 13]。对于开源 VLM,选择 Llama-3.2-90B-Vision-Ins [26]、InternVL-2.5-78B/28B [10]、InternVL-3-72B [48] 和 Qwen2.5-VL-72B-Ins [3]。其次,选择三种智体框架:(1)Reflexion [32],它引入一个简单的长期记忆和一个自我反思模块。 Reflexion 利用自我反思模块将经验总结为长期记忆,从而增强模型的能力。(2) Voyager [38] 使用技能库作为其程序记忆,是具身智体规划中广泛使用的基线模型。(3) Cradle [35] 提出一种具有情景记忆和程序记忆的通用智体框架,并在各种多模型智体任务中取得良好的性能。
在实验中,每个智体框架都使用 Qwen2.5-VL-72b-Ins [37] 进行测试。Qwen2.5-VL-72b-Ins 是一个高性能的开源替代方案。值得注意的是,Qwen2.5-VL-72b-Ins 在多个基准测试任务中展现出与先进的闭源VLM 相当的性能 [39]。用 Qwen3-Embedding 模型 [45] 为 RoboMemory 中的 RAG 创建嵌入向量。对于低级执行器,由于 EB-ALFRED 提供高级操作 API,用 EmbodiedBench 提供的低级执行器,而不是基于 VLA 的方法。
为了评估 RoboMemory 在真实世界中的交互式环境学习能力,设计一个受 EB-ALFRED 和 EB-Habitat 启发的厨房环境。该场景包含 5 个可导航点、8 个交互式物体和 10 多个非交互式(但可能分散注意力)物体。环境如图所示。在真实世界中,用在动作执行过程中捕获的交互式环境视频录像(而不是动作完成后拍摄的静态快照)作为 RoboMemory 的输入。这提供更具时间连贯性的感知。创建三个任务类别(每个类别 5 个任务)。这些任务与 EB-ALFRED 的基础子集相匹配(平均预言机步数:10-20 步),但由于搜索和错误恢复,实际执行的步数通常会超过 20 步。


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 7
7 0
0- 0



 已为社区贡献180条内容
已为社区贡献180条内容

所有评论(0)