【小白驯AI日志】机器学习篇02—scikit-learn初上手+KNN实战:用三行代码让机器认出邻居(上)
scikit - learn是一个开源的机器学习库,它是基于Python语言的。它建立在多种科学计算库之上。利用这些底层库,为机器学习提供了一整套简洁易用的工具k个最近的邻居,即每个样本都可以用它最接近的k个邻居来代表,KNN算法属于监督学习方式的分类算法,通过测量不同数据点之间的距离进行分类或回归分析原理-“近朱者赤”
写在前面:
上篇把机器学习的“家谱”聊了个遍,今天终于轮到上手真刀真枪——scikit-learn。别被它洋气的名字吓到,在我看来,它就像机器学习的“瑞士军刀”:不用自己造轮子,几行代码就能跑算法、看结果、画图一条龙。我们的第一个任务,是让电脑学会“认邻居”——K近邻(KNN)。听起来高大上?其实就是“谁离你近,你就跟谁一伙”。我会把每一步都拆成小白视角:从pip安装、数据载入,到调参、可视化,全程零废话。跟着敲完,你会收获人生第一张“算法决策边界”彩图,以及一份“我也行”的成就感。下一小时,一起把KNN驯成自家小宠物吧!
scikit-learn简介
scikit - learn是一个开源的机器学习库,它是基于Python语言的。它建立在多种科学计算库之上。利用这些底层库,为机器学习提供了一整套简洁易用的工具
scikit-learn特点
简洁高效:提供了简单高效的算法和工具,方便用户直接使用
模块化设计:采用模块化设计,使得用户可以根据需要自由组合不同的算法和工具,支持随时用随时导入
算法多样:提供了丰富多样的机器学习算法,包括分类、回归、聚类、降维等,满足用户不同需求
scikit-learn网站与中文文档
Scikit-learn官网:https://scikit-learn.org/stable/#
Scikit-learn中文文档:https://scikitlearn.com.cn/
scikit-learn安装与使用
01安装scikit-learn
可以使用pip或conda等包管理工具进行安装
eg:pip install -U scikit-learn
02基本使用方法
导入必要的模块和函数
新建一个.py文件
输入下面命令
from sklearn.linear_model import LinearRegression上面是对于scikit—learn的简要介绍,只需要我们做稍微了解,学会运用此类工具即可
接下来,进入到我们需要了解的第一个机器学习算法——KNN(K近邻)算法
KNN(K近邻算法)
我们开始从这样几个方面来认识KNN算法
1.算法理论
2.使用scikit—learn实现算法
3.数学方法实现算法
1.算法理论
KNN算法概念
K最近邻(K-Nearest Neighbor,KNN)分类算法属于数据挖局分类技术中最简单的方法之一,是著名的模式识别统计学方法,在机器学习分类算法中占有相当大的地位。它是一个理论上比较成熟的方法。既是最简单的机器学习算法之一,也是基于实例的学习方法中最基本的,又是最好的文本分类算法之一,藉由这样的特点,我们将其放在最开始讲解,希望可以让读者快速地了解机器学习算法的精髓与内核
KNN算法介绍
定义:KNN(K-Nearest Neighbor) k个最近的邻居,即每个样本都可以用它最接近的k个邻居来代表,KNN算法属于监督学习方式的分类算法,通过测量不同数据点之间的距离进行分类或回归分析
原理-“近朱者赤”是一种基于实例的学习(instance-based learning),属于懒惰学习(Lazy learning),即KNN没有显示的学习过程,也就是说没有训练阶段(仅仅是把样本保存起来,训练时间开销为零)它是通过测量不同数据点的之间的距离进行分类或者回归。
特点: KNN算法简单易懂,易于实现;无需训练阶段,直接进行分类或者回归;适用于多分类问题;对数据集的大小和维度不敏感
算法三要素
1.K值选择
2.距离选择
3.分类规则选择
1.K值选择
算法中的K在KNN中,称为超参数(Hyper parameter)(超参数就是需要你手动设定的参数),需要人为选择不同的K值
因此,K值选择就会相应的存在一些优点和问题
K值太小:针对于数据信息比较复杂的数据集,K值取得小=影响目标点的样本少=可能提供更加详细的决策边界,但是目标点容易受到局部特殊结构的影响,模型收到噪声(可以理解为数据集当中的少数异常数据)和异常值的影响更大
选择较小的K值,就相当于用较小的领域中的训练实例进行预测,“学习”近似误差会减小,只有与输入实例较近或相似的训练实例才会对预测结果起作用,与此同时带来的问题是“学习”的估计误差会增大,换句话说,K值的减小就意味着整体模型变得复杂,容易发生过拟合(相当于过度学习导致模型“僵化”,这里稍作了解后面会有详细说明)
K值过大:考虑到更多的全局信息,对于数据相对没有什么明显趋势的数据集,较大的K值可以提供更稳定的决策边界;然而在更为复杂的数据集中,较大的K值可能会导致模型过于简单,无法准确捕获数据的局部特征
选择较大的K值,就相当于用较大领域中的训练实例进行预测,其优点是可以减少学习的估计误差,但缺点是学习的近似误差会增大。这时候,与输入实例较远(不相似的)训练实例也会对预测器作用,使预测发生错误,且K值的增大就意味着整体的模型变得简单
当我们取到极端情况K=N时(N为训练样本个数),此时无论输入是什么,都只是在简单的预测他属于在实例当中最多的
2.距离选择
K近邻法(K-Nearest Neighbor,KNN):计算新的点(测试点)到每一个已知点(标签点)的距离,并比对距离,使用不同的距离公式会得到不同的分类效果。后面会介绍一下常用的距离计算方法。
3.分类规则选择
分类问题:对新的实例,根据与之相邻的K个训练实例的类别,通过多数表决法或者加权多数表决法等方式进行预测
回归问题:对新的实例,根据与之相邻的K个训练实例的标签,通过均值计算进行预测
KNN算法步骤
输入:训练数据集T={(x1,y1),(x2,y2)...(xn,yn)},x1为实例的特征向量,yi={c1,c2,c3...ck}为实例类别
输出:测试实例x所属的类别y
步骤:
(1)选择参数K
(2)计算未知实例与所有已知实例的距离(可选择多种计算距离的方式)
(3) 选择最近K个已知实例
(4) 根据少数服从多数的投票法则(Majority-voting),让未知实例归类为K个最近邻样本中最多数的类别。
KNN算法思想
K近邻算法,假定给定一个训练数据集,其中实例标签已定,当输入新的实例时,可以根据其最近的K个训练实例的标签,预测新实例对应的标注信息(标签属于哪一类)
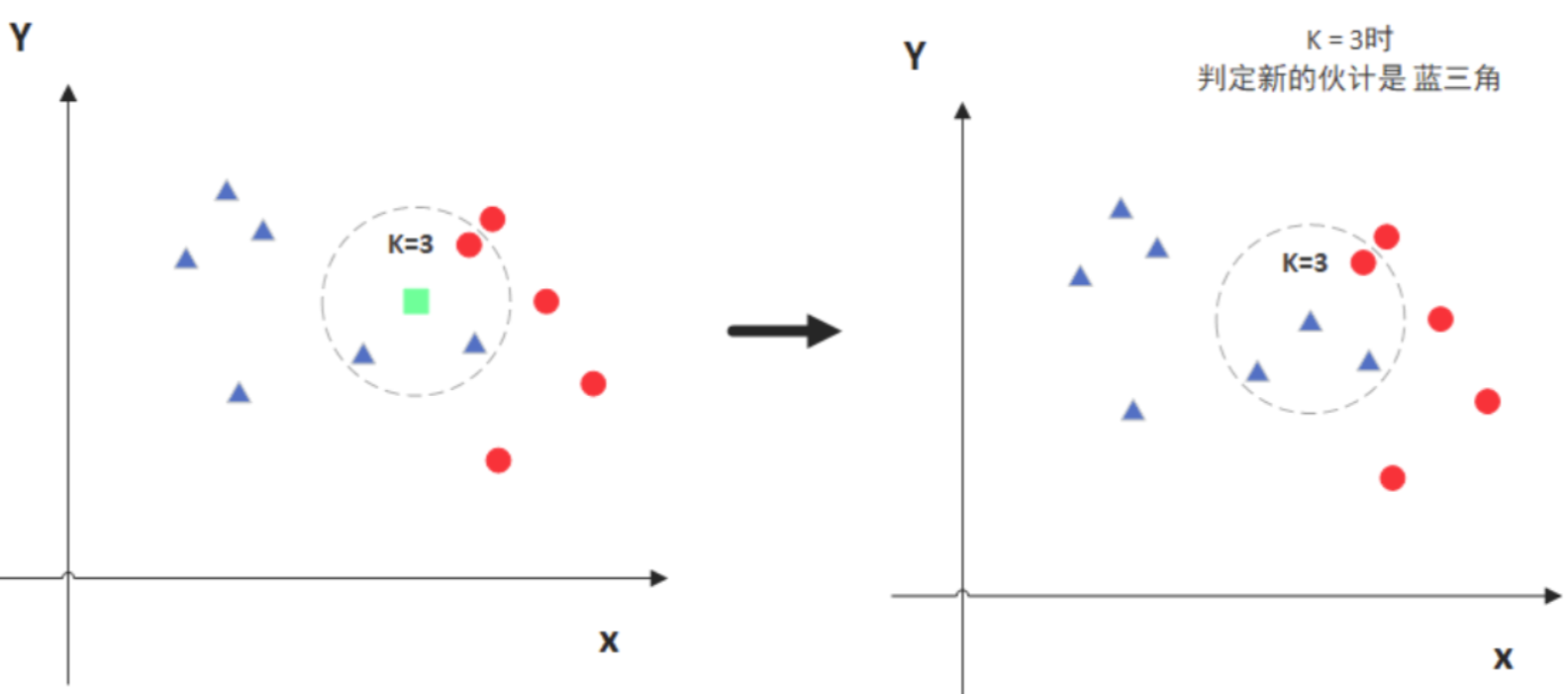
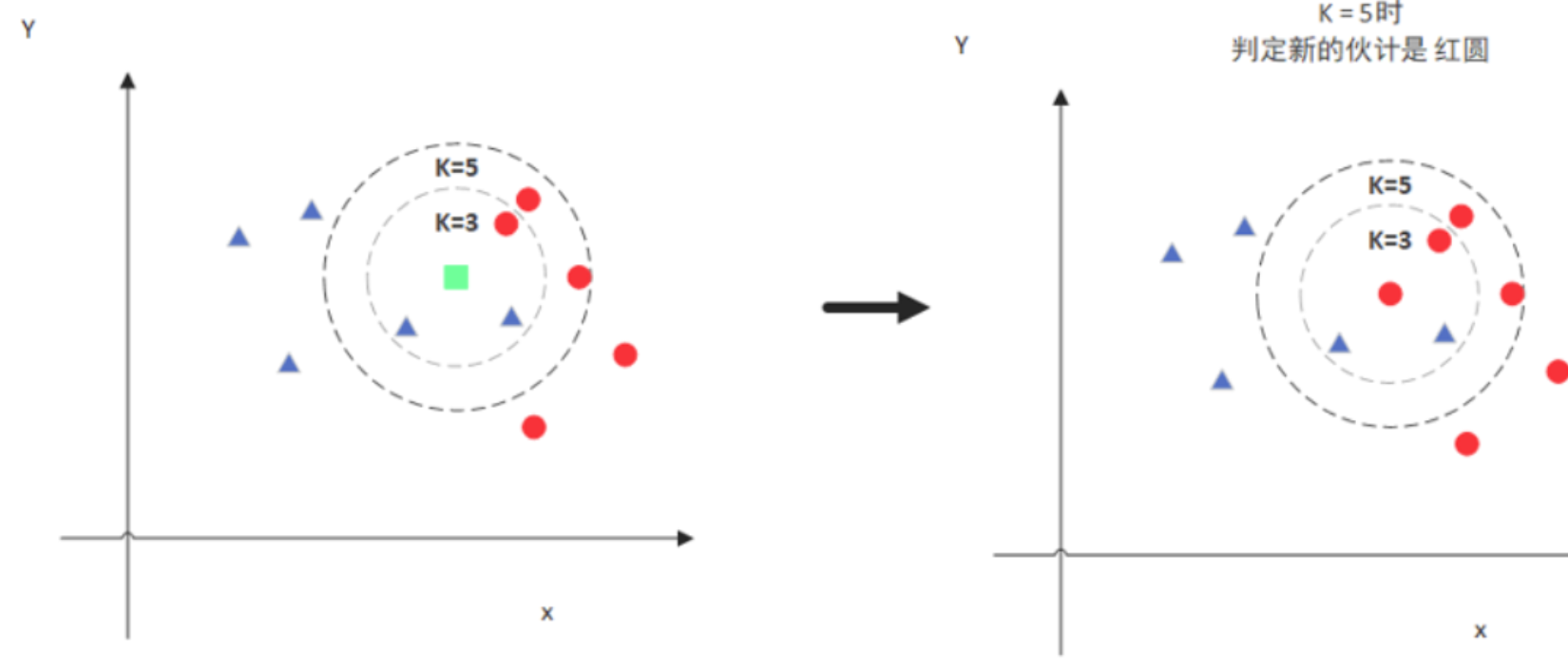
图例
图中绿色的点就是我们要预测的那个点,假设K=3。那么KNN算法就会找到与它距离最近的三个点(这里用圆圈把它圈起来了),看看哪种类别多一些,比如这个例子中是蓝色三角形多一些,新来的绿色点就归类到蓝三角了
注意:决策边界
定义:
决策边界是分类算法中用于区分不同类别的虚拟边界,通俗讲就是在什么范围内归为当前类
边界效果:
决策边界是否合理,直接影响到分类效果的好坏
KNN与决策边界:
KNN算法通过计算待分类样本与已知样本之间的距离,找到最近的K个样本,并根据这些样本的类型信息进行投票,以确定待分类样本的类别
结语
把 KNN 的“家谱”翻到这里,我们已经完成了三件事:
-
把 scikit-learn 这把“瑞士军刀”握在手里——会装、会导、知道去哪查文档;
-
把 KNN 的理论家底拆成三颗扣子:K 值、距离、投票规则,随用随扣;
-
在纸上跑完了算法全流程,连决策边界长啥样都提前剧透给你。
下一步,就该让代码替我们“画图”而不是“话图”——下篇直接上手:
-
了解如何具体计算数据点间的距离;
-
学习交叉验证,评估一个机器学习模型的表现;
-
使用Scikit-learn以及数学方法实现KNN算法”。
休息五分钟,活动手腕,下篇见——一起把 KNN 从理论宠物养成代码萌宠!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 27
27 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)