拒绝盲目变异!百度自研LoongFlow:让AI进化迈向“导演式”定向变异,已斩获14枚Kaggle金牌!
导语: 在 AI 圈,让大模型“自己进化自己”早已不是新鲜事。但尴尬的现状是:大多数进化代理(Agent)像是一群“盲人摸象”——它们通过随机的代码变异来撞大运,不仅烧掉了天文数字般的 Token,还极易陷入死胡同。
最近,百度新开源了一个名为 LoongFlow 的新框架。它给狂奔的进化算法装上了“大脑”,引入了电影导演般的 PES(计划-执行-总结) 范式。结果相当惊人:在同等任务下,进化效率提升了 60% 以上,更在 Kaggle 竞赛中自动化拿下了 14 枚金牌。
一、 定位:一个会思考、会学习的专家级Agent开发框架
1.什么是会思考、会学习?
-
会思考:让agent框架具备结构化深度思考能力,不只靠模型乱猜。从而让agent具备稳定解决复杂问题能力。
-
会学习:让agent框架具备自我学习进化能力,不只靠模型训练。从而让agent具备从迭代中学习进化,让结果越跑越好能力。
-
专家级:致力于长程复杂研究性任务,对齐人类领域专家级效果。
2.为什么要会思考、会学习?
这就像一个普通人和一位科学家,大家的智力大多也差不多,但科学家却可以做出远超普通人的更深层次研究。这个差距,就在于结构化思考能力,科学家进化科学训练具备长期的架构话思考能力,能够将独立的知识组装起来,并能够从失败中学习。大模型具备非常丰富的知识储备,也具备短程的推理能力,但离应对长程复杂推理任务,还有明显差距,这才是agent框架该解决的关键问题。
3.怎么实现会思考、会学习?
LoongFlow通过自研PES思考范式,结合轻量级的学习进化能力,让Agent框架会思考、会学习,从而能够实现专家级效果。
4.目前没有其他能达到相同目的的框架嘛?
目前开源的Agent框架大致可以分为以下几类:
|
框架类型 |
框架举例 |
主要作用 |
局限 |
|
基础开发框架 |
langchain、langgraph、dify、n8n、adk、eino、agentscope等 |
预置了丰富的Agent开发基础组件 |
无法预知开发出的Agent,效果的好坏全凭开发者 |
|
场景Agent框架 |
deepResearch、deer-flow、JoyAgent、OpenManus、deepCode等 |
以解决某个场景问题为主研发的Agent框架,在垂类场景达到一定效果 |
仅擅长解决某个垂类问题,不够通用 |
|
进化Agent框架 |
openevolve、ShinkaEvolve、R&DAgent、AgentEvolver等 |
引入知识积累和经验迭代机制,通过强化学习、经验积累等方式,让Agent具有自进化能力 |
在高难度复杂的现实任务中,普遍出现缺乏战略规划盲目尝试、过早陷入局部最优多样性崩溃、依赖提示词缺乏反思等问题 |
可以看到,目前的Agent框架,要不聚焦在基础开发脚手架,要不聚焦在某个领域做效果。要研发一个能够解决特定领域问题的Agent(比如能够做GPU低效问题定位的Agent),依然要进行从头全新设计,要达到人类专家级效果难度依然非常高,需要非常丰富的Agent设计和调优经验。而LoongFlow提出会思考、会学习的Agent开发框架,提出面向复杂问题的通用思考范式,超越了早期静态提示词依赖人类手工设计指令,作为新一代自我进化Agent,利用大语言模型(LLM)作为变异算子,迭代优化自身的代码和参数,让Agent可以像人类专家一样思考解决复杂问题,把面向复杂问题Agent工作模型标准化,让开发者只需要轻量级实现对应扩展,只需把领域经验注入给Agent,就可以取得领域专家级的Agent效果。
除此之外,基于LoongFlow框架,开发团队还开发了通用算法发现和机器学习两个开箱即用的Agent,并在高难度benchmark上跑出了比肩人类顶尖领域专家效果,验证了LoongFlow框架的适用性和领先效果,可以帮助用户更好的理解并使用LoongFlow框架。
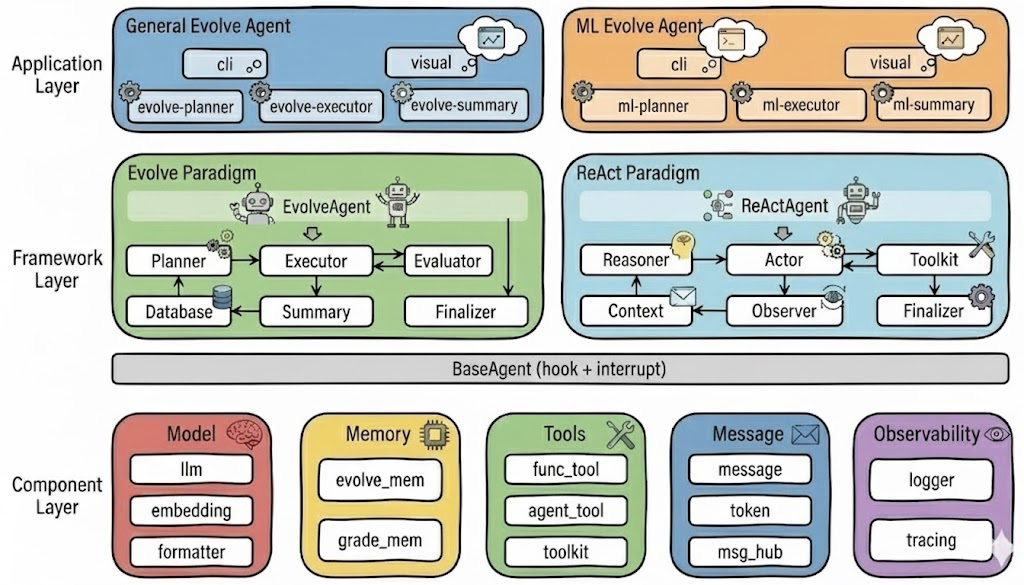
框架详细内容和代码,请参阅LoongFlow github仓库(https://github.com/baidu-baige/LoongFlow)获取。
二、 LoongFlow 的核心武器:PES 范式
LoongFlow 最具突破性的创新在于将随机的变异过程转化为了一个结构化的认知循环,即 “计划-执行-总结”(Plan-Execute-Summarize, PES)范式 。复杂问题之所以"复杂",是因为其信息量超过了单一处理单元(无论是人脑还是大模型)的瞬时处理能力。人类解决复杂问题,已经进化出了一套从“直觉驱动”转向“数据与逻辑协同”的系统化模式。LoongFlow的思考模式,正是参考这套通用思考模式,模拟人类专家设计、实验、总结,多次迭代的探索性研究思考模式,抽象出了PES思考范式。下图可作一个漫画式解析。
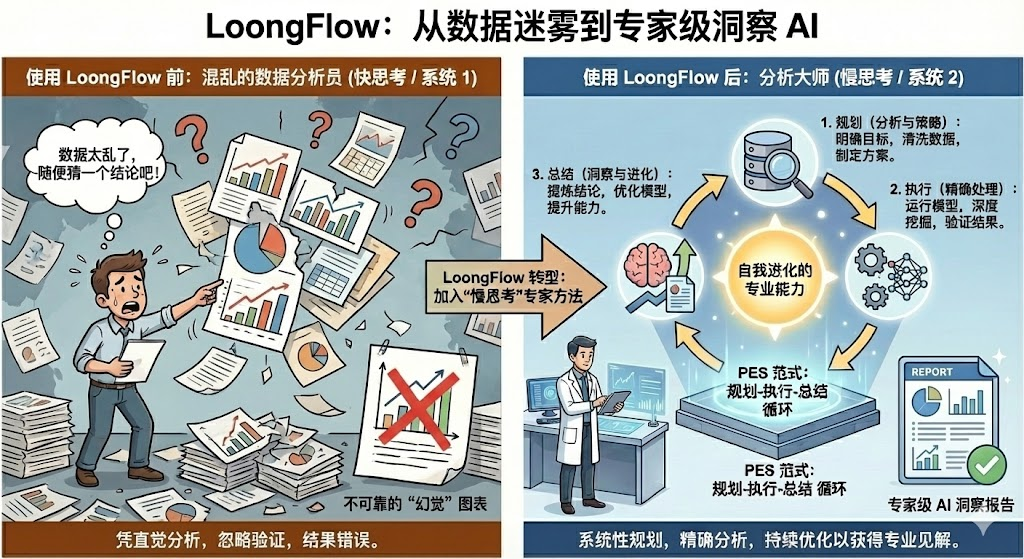
1. 计划者(Planner):不仅仅是搜索,更是“策略剪枝”
在无限的解空间中,随机漫步是极其低效的。LoongFlow 的 Planner 扮演了战略架构师的角色 。
-
血缘上下文检索: 不同于传统的模糊语义检索(RAG),Planner 利用进化过程中的显式谱系链接,调取祖先节点的“原始意图”和“回顾性反馈” 。
-
意图追踪与纠偏: 通过阅读过去的计划,它知道之前的尝试方向;通过阅读过去的总结,它识别出需要避开的坑 。这使得每一次变异都是基于逻辑的“精细微调”,而非“胡乱跳跃” 。
2. 执行者(Executor):从意图到代码的稳健转化
执行者负责将高层的战略蓝图转化为可运行的代码 。
-
多态执行策略: 支持可插拔的工作流,既可以作为逻辑密集的单次编程器,也可以作为多阶段的工作流引擎,适配不同领域 。
-
局部验证(Fast-Fail): 在提交给全局评估器之前,Executor 会先进行自检(如语法纠错、导入检查),通过“快慢结合”减少无效资源的浪费 。
3. 总结者(Summary):构建长效“进化记忆”
这是打破“循环错误”的关键。总结者在评估结束后进行溯因反思 。
-
它对比 Planner 的意图与实际运行结果,推断出因果关系,并生成结构化的洞察(Insight)存入“进化记忆数据库” 。这种元学习能力让系统随着代际更迭变得越来越“聪明” 。
这样,通过单次迭代中使用PES思考模式动态演化,在多轮迭代循环中,持续积累知识和产生优化,直到复杂问题得到彻底解决。
三、 LoongFlow多结构融合进化记忆组件:解决多样性与收敛的矛盾
除了认知层面的革新,LoongFlow 在架构底层设计了一套混合进化记忆系统,确保搜索的广度与深度 。
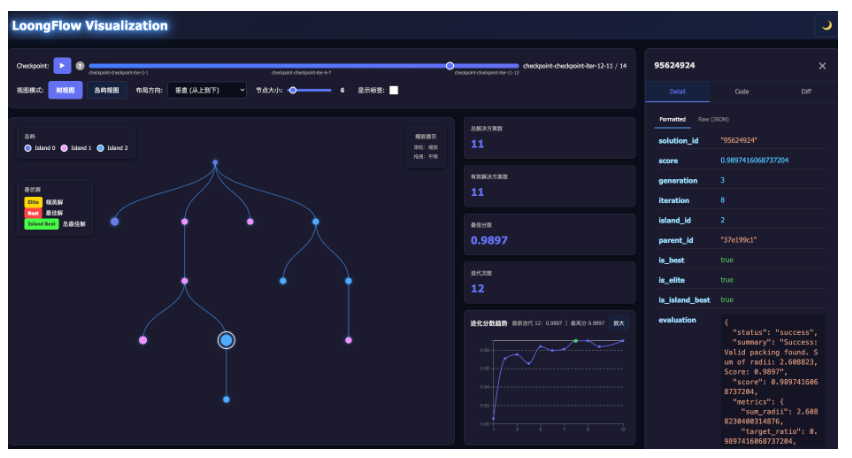
1. 多岛屿并行拓扑
为了防止单一成功策略形成的“物种垄断”,LoongFlow 采用了多岛屿模型(Multi-Island Model) 。不同的算法“物种”在相互隔离的岛屿上独立演化,只有当多样性差异超过阈值时才进行精英迁移,从而维持全局的多样性 。可视化岛屿图如下图。
2. MAP-Elites 特征网格
在每个岛屿内部,系统并不只保留“最高分” 。它通过行为描述符(如代码复杂度、内存占用)将解映射到特征网格中,保留每个生态位(Niche)中的最优个体,为 Planner 提供多样化的“基因库” 。
3. 自适应波兹曼选择
LoongFlow 放弃了僵化的贪婪选择,引入了自适应波兹曼选择(Adaptive Boltzmann Selection) 。
-
动态温度调节: 当种群多样性高时,降低“温度”鼓励开发(Exploitation);当种群趋同、活力下降时,升高“温度”强制探索(Exploration) 。这种自我调节机制实现了“寻找新思路”与“打磨旧方案”的完美平衡 。
四、 结语
为了验证 LoongFlow 的威力,研究团队在 AlphaEvolve 基准测试和 Kaggle 竞赛(MLE-Bench)中都进行了严苛的测试 。具体测试结果可以详见https://arxiv.org/pdf/2512.24077。
LoongFlow 的出现,标志着 AI 智能体从“盲目尝试”向“深度思考”的进化 。通过独特的 PES(计划-执行-总结)认知范式与混合进化记忆系统,它不仅打破了传统进化算法在复杂代码空间中的搜索瓶颈,更在 AlphaEvolve 基准测试中实现了高达 60% 的效率提升 。从发现复杂的数学算法到自动优化机器学习流水线,LoongFlow 证明了:当 LLM 具备了反思与长期记忆的能力,自主科学发现的“奇点”或许就在眼前 。
目前 LoongFlow 已在 GitHub 开源。你认为这种“认知进化”范式未来最可能在哪个科研领域取得突破?欢迎在评论区分享你的观点! 🔗 项目地址:https://github.com/baidu-baige/LoongFlow

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 2
2 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)