从零构建大模型(五)——从头实现GPT进行文本生成
本文实现了 GPT 的核心架构和生成流程,但模型还未训练。下一篇文章将讲解:如何准备文本训练数据(语料预处理、批量构建);GPT 的训练目标(自回归语言建模损失);用小数据集训练极简 GPT,让模型能生成有意义的文本。
建议该系列文章从前往后阅读~
引言
前序文章梳理了 Transformer 的整体架构,并编码实现了多头注意力机制。本文将基于 PyTorch 实现极简版 GPT 模型,包含:掩码自注意力层、前馈网络、残差连接 + LayerNorm,以及完整的自回归生成逻辑,让我们开始吧!
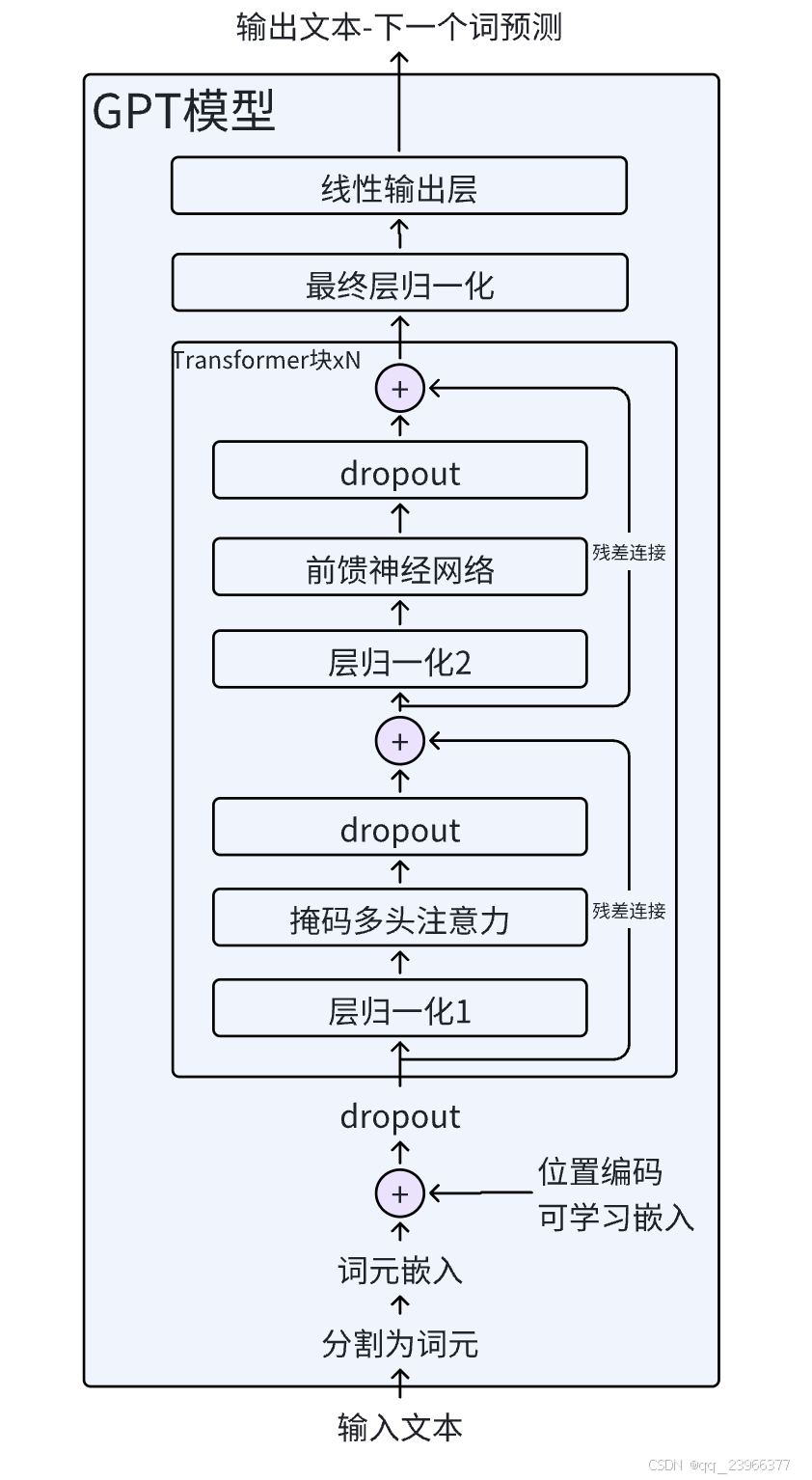
首先引入并详细展开上篇文章GPT模型结构图并提出几个问题:
-
残差+层归一化具体是什么,有什么作用,又是如何实现的
-
前馈神经网络如何实现
-
组装TransFormer块
-
组装GPT模型
-
使用组装的GPT模型生成预测文本
核心模块拆解与实现
残差连接 + 层归一化:训练稳定的双保险
残差连接:解决梯度消失
背景知识:神经网络训练,是通过计算损失对参数的梯度,不断微调参数,让模型预测越来越准的过程。而梯度,就是这个过程中的“导航信号”,因此在训练过程中梯度对训练结果影响非常大。
残差连接是一种跳跃连接(skip connection),将某一层的输入直接加到其输出上。其目的是:
-
解决深层网络中的梯度消失问题:通过直接将输入 x 加到输出上,确保了信息可以直接从一层传递到下一层,有助于缓解深度网络中的梯度消失问题。
-
加速训练过程:因为网络更容易学习恒等映射,即当 f(x)=0 时,输出等于输入,这使得优化更加容易。
-
增强表达能力:允许网络学习输入数据的残差部分,而非强制学习完整的表示,这可以提高模型的表现力。
接下来比较有残差连接和无残差连接网络来明确其作用:
import torch
from torch import nn
# 定义一个深度神经网络示例,支持可选的残差连接
class ExampleDeepNeuralNetwork(nn.Module):
def __init__(self, layer_sizes, use_shortcut):
"""
Args:
layer_sizes: 形如 [in_dim, h1, h2, ..., out_dim] 的列表,指定每层输入输出维度
use_shortcut: 是否启用残差连接
"""
super().__init__()
self.use_shortcut = use_shortcut
# 构建5个顺序层,每层包含一个线性变换 + GELU 激活
self.layers = nn.ModuleList([
nn.Sequential(nn.Linear(layer_sizes[0], layer_sizes[1]), GELU()),
nn.Sequential(nn.Linear(layer_sizes[1], layer_sizes[2]), GELU()),
nn.Sequential(nn.Linear(layer_sizes[2], layer_sizes[3]), GELU()),
nn.Sequential(nn.Linear(layer_sizes[3], layer_sizes[4]), GELU()),
nn.Sequential(nn.Linear(layer_sizes[4], layer_sizes[5]), GELU()),
])
def forward(self, x):
# 逐层前向传播
for layer in self.layers:
layer_output = layer(x) # 当前层的输出
# 如果启用了残差连接,并且输入 x 与当前层输出形状一致,则执行残差连接
# 仅做演示,仅在输入输出形状相同时启用残差连接。
# 实际模型(如 ResNet、Transformer)会通过架构设计(如 1x1 卷积、线性投影)确保残差路径维度匹配。
if self.use_shortcut and x.shape == layer_output.shape:
x = x + layer_output # 残差连接:x = x + F(x)
else:
x = layer_output # 否则直接使用当前层输出作为下一层输入
return x
# 定义一个函数,用于打印模型各层权重的平均梯度绝对值(用于观察梯度流动情况)
def print_gradients(model, x):
# 前向传播得到输出
output = model(x)
# 设定目标输出为 0(用于计算损失)
target = torch.tensor([[0.]])
# 使用均方误差(MSE)作为损失函数
loss_fn = nn.MSELoss()
loss = loss_fn(output, target)
# 清空之前的梯度(虽然此处是首次反向传播,但良好习惯)
model.zero_grad()
# 反向传播:自动计算所有可学习参数的梯度
loss.backward()
# 遍历模型的所有命名参数(包括 weight 和 bias)
for name, param in model.named_parameters():
# 只关注权重(weight)参数,忽略偏置(bias)
if 'weight' in name:
# 计算该层权重梯度的平均绝对值,用于衡量梯度大小
grad_mean_abs = param.grad.abs().mean().item()
print(f'name: {name} has gradient mean of {grad_mean_abs}')
# 设置网络结构:输入3维,中间4层均为3维,输出1维
layer_sizes = [3, 3, 3, 3, 3, 1]
# 创建一个单样本输入张量:shape = [1, 3]
sample_input = torch.tensor([[1., 0., -1.]])
# 固定随机种子以确保结果可复现
torch.manual_seed(123)
# 实例化一个 **没有** 残差连接的模型
model_without_shortcut = ExampleDeepNeuralNetwork(layer_sizes=layer_sizes, use_shortcut=False)
# 打印无残差连接模型的各层梯度
print("打印无残差连接模型的各层梯度:")
print_gradients(model_without_shortcut, sample_input)
print('\n') # 空行分隔
# 实例化一个 **有** 残差连接的模型(use_shortcut=True)
model_with_shortcut = ExampleDeepNeuralNetwork(layer_sizes=layer_sizes, use_shortcut=True)
# 打印有残差连接模型的各层梯度
print("打印有残差连接模型的各层梯度:")
print_gradients(model_with_shortcut, sample_input)输出结果如下:
打印无残差连接模型的各层梯度:
name: layers.0.0.weight has gradient mean of 0.00020173587836325169
name: layers.1.0.weight has gradient mean of 0.0001201116101583466
name: layers.2.0.weight has gradient mean of 0.0007152041653171182
name: layers.3.0.weight has gradient mean of 0.001398873864673078
name: layers.4.0.weight has gradient mean of 0.005049646366387606
打印有残差连接模型的各层梯度:
name: layers.0.0.weight has gradient mean of 0.22169792652130127
name: layers.1.0.weight has gradient mean of 0.20694106817245483
name: layers.2.0.weight has gradient mean of 0.32896995544433594
name: layers.3.0.weight has gradient mean of 0.2665732502937317
name: layers.4.0.weight has gradient mean of 1.3258541822433472这段代码演示了残差连接如何缓解梯度消失问题。
1. 没有残差连接时:靠近输入的层接收到的梯度信号明显更弱
-
最后一层(
layers.4)梯度最大(靠近损失函数,反向传播起点) -
越靠近输入(
layers.0),梯度越小(可能只有最后一层的千分之一甚至更小) -
这就是典型的 梯度消失现象
原因:每经过一个 Linear + GELU,梯度都要乘以权重矩阵和激活函数导数。多层叠加后,梯度被不断“压缩”。
2. 有残差连接时:所有中间层梯度接近一致
-
从
layers.0到layers.3,梯度大小几乎相同 -
说明早期层也能接收到有效的梯度信号
-
模型更容易训练,收敛更快
原因:残差连接提供了一条恒等路径,让梯度可以直接“跳过”非线性变换,直接回传到浅层。
层归一化;稳定激活值分布
背景:在神经网络训练过程中,网络某一层的输入分布会随着前层参数更新而发生变化,导致后层需要不断适应新的分布,减慢训练速度,甚至引发梯度爆炸 / 消失。同时,在 Transformer 中,自注意力机制的计算会涉及矩阵乘法和Softmax 操作,很容易出现激活值异常,一旦出现异常,它会在层与层之间叠加传播,使得异常放大。
层归一化是一种对神经网络中间激活值进行归一化的技术。其主要思想是调整神经网络层的输出,使其均值为0,方差为1,相当于在每层出口安装一个“稳压器”,无论内部计算多么疯狂,输出都被拉回标准范围,阻断了异常值的跨层传播。有助于加速权重有效收敛并确保训练过程的一致性和可靠性。
其具体实现是:
import torch
from torch import nn
class LayerNorm(nn.Module):
"""
自定义实现层归一化(Layer Normalization)。
对输入张量的最后一个维度(通常是嵌入维度 emb_dim)进行归一化,
并引入可学习的缩放(scale)和偏移(shift)参数以保留模型表达能力。
"""
def __init__(self, emb_dim):
super().__init__()
self.eps = 1e-5 # 一个极小的常数,加到方差上防止除零错误,保证数值稳定性
# 可学习的缩放参数形状为 [emb_dim],初始化为1
# 允许模型在归一化后对每个特征维度进行自适应缩放
self.scale = nn.Parameter(torch.ones(emb_dim))
# 可学习的偏移参数形状为 [emb_dim],初始化为0
# 允许模型在归一化后对每个特征维度进行自适应平移
self.shift = nn.Parameter(torch.zeros(emb_dim))
def forward(self, x):
"""
前向传播:对输入 x 的最后一个维度进行层归一化。
输入:
x: 张量,形状通常为 [batch_size, seq_len, emb_dim]
输出:
归一化并经过仿射变换后的张量,形状与输入相同
"""
# 计算输入 x 在最后一个维度(emb_dim)上的均值
# keepdim=True 保持维度不变,结果形状为 [..., 1],便于广播
mean = x.mean(-1, keepdim=True)
# 计算输入 x 在最后一个维度上的方差
# unbiased=False 表示使用有偏估计(除以 n 而非 n-1),这是深度学习中的标准做法
var = x.var(-1, keepdim=True, unbiased=False)
# 执行标准化:(x - mean) / sqrt(var + eps)
# 结果 norm_x 的每个位置(token)在其 emb_dim 维度上均值≈0,方差≈1
norm_x = (x - mean) / torch.sqrt(var + self.eps)
return self.scale * norm_x + self.shift残差连接+层归一化协同作用
残差连接主要解决梯度反向传播的问题(让梯度能流到浅层);
LayerNorm 解决的是前向传播中激活值的数值稳定性问题。
两者互补:
-
没有 LayerNorm → 前向激活爆炸 → 即使梯度能传回来,参数更新也基于错误的信号
-
没有残差 → 梯度消失 → 浅层学不到东西
所以 Transformer 同时使用 残差连接 + LayerNorm,形成“前向稳 + 反向通”的双重保障。
前馈神经网络:局部特征精炼
前馈神经网络(FFN)是 Transformer 中负责对每个 token 独立进行非线性特征变换的子模块,通过“升维→激活→降维”的结构,为模型提供强大的局部表达能力,与自注意力机制形成“全局交互 + 局部精炼”的互补架构。本质上是一个包含激活函数的小型神经网络。
接下来用代码实现一个具有GELU激活函数的前馈神经网络。
class GELU(nn.Module):
def __init__(self):
super().__init__()
def forward(self, x):
return 0.5*x*(1+torch.tanh(torch.sqrt(torch.tensor(2.0/torch.pi))*(x+0.044715*torch.pow(x,3))))
#前馈神经网络,两个线性层和一个激活函数组成
#在提升模型学习和泛化能力方面很关键。该模块输入输出维度保持一致,可以简化狂减,后需叠加多个层无需调整维度,增强模型扩展能力
class FeedForward(nn.Module):
def __init__(self, cfg):
super().__init__()
self.layers = nn.Sequential(
nn.Linear(cfg["emb_dim"], 4* cfg["emb_dim"]), #将嵌入维度扩展到更高维度,允许模型探索更丰富的表示空间
GELU(),
nn.Dropout(cfg["drop_ff"]),
nn.Linear(4* cfg["emb_dim"], cfg["emb_dim"]),
)
def forward(self, x):
return self.layers(x)上述前馈神经网络主要步骤是:
-
先将输入从 emb_dim 维扩展到更高维(如 4×emb_dim),其目的是
-
增加模型容量:更多参数 → 更强拟合能力
-
缓解信息瓶颈:如果直接
d → d,非线性变换可能退化为近似线性 -
实践验证有效:在多种任务上,4 倍扩维效果显著优于 1 倍或 2 倍
-
-
经过非线性激活函数(通常是 GELU)
-
再投影回原始维度 emb_dim
前馈神经网络的作用如下:
| 作用 | 详细解释 |
| 引入非线性 | 自注意力是线性加权求和,本身无法拟合复杂函数。FFN 通过 GELU 引入强非线性,使模型具备通用逼近能力。 |
| 逐位置特征变换 | 注意力是在 token 之间建模关系,而 FFN 是对每个 token 独立地进行特征空间变换。相当于:“基于上下文理解后,重新编码每个词的表示”。 |
| 增强表达能力 | 将 emb_dim 维向量映射到更高维空间(如 3072 维),在高维空间中更容易分离特征,再压缩回原空间,实现“特征提纯”。 |
自注意力和FNN的联系:自注意力 = “看全局上下文”;FFN = “基于上下文,重新思考每个词的含义”
组装TransFormer块:GPT的核心单元
之前文章和上述篇幅介绍了注意力机制、残差连接+层归一化、前馈神经网络;接下来将她们进行连接,从而实现上图所示的Transformer块。
import torch
from torch import nn
class TransformerBlock(nn.Module):
def __init__(self, cfg):
super().__init__()
# 多头自注意力机制(掩码注意力已在 MutiHeadAttention 内部实现)
#详见从零构建大模型记录(三)——从零实现 Transformer 核心模块(下)
self.att = MultiHeadAttention(
d_in=cfg["emb_dim"], # 输入维度(通常 = d_model)
d_out=cfg["emb_dim"], # 输出维度(与输入一致,便于残差连接)
context_length=cfg["context_length"], # 上下文长度(用于生成 causal mask)
num_heads=cfg["n_heads"], # 注意力头数
dropout=cfg["drop_att"], # 注意力权重的 dropout 比例
qkv_bias=cfg["qkv_bias"], # Q/K/V 投影是否使用偏置
)
# 前馈神经网络(Feed-Forward Network)
self.ff = FeedForward(cfg)
# 两个独立的 LayerNorm 层,分别用于注意力子层和前馈子层
self.norm1 = LayerNorm(cfg["emb_dim"]) # 用于注意力前的归一化
self.norm2 = LayerNorm(cfg["emb_dim"]) # 用于前馈网络前的归一化
# Dropout 层,用于残差连接后的输出(增强泛化能力)
self.dropout_att = nn.Dropout(cfg["drop_att"])
def forward(self, x):
"""
前向传播:依次执行带残差连接的自注意力和前馈网络。
输入:
x: [batch_size, seq_len, emb_dim]
输出:
同形状的张量,经过一个完整 Transformer 块处理
"""
# ========== 自注意力子层(带残差连接)==========
shortcut = x # 保存原始输入,用于后续残差连接
# 先对输入进行 LayerNorm
x = self.norm1(x)
# 计算多头自注意力(内部已包含掩码,适用于 GPT 自回归)
x = self.att(x)
# 对注意力输出应用 Dropout
x = self.dropout_att(x)
# 残差连接:将原始输入加回到子层输出上
x = x + shortcut
# ========== 前馈网络子层(带残差连接)==========
shortcut = x # 更新 shortcut 为当前状态(即注意力子层的输出)
# Pre-LN: 对当前输入进行 LayerNorm
x = self.norm2(x)
# 前馈网络变换(非线性特征提取)
x = self.ff(x)
# 对 FFN 输出应用 Dropout
x = self.drop_shortcut(x)
# 残差连接:将输入(即注意力子层结果)加回到 FFN 输出上
x = x + shortcut
return x组装完整GPT模型
接下来,将之前所介绍的模块进行组装,实现一个简易的GPT模型,代码如下:
import torch
from torch import nn
class GPTModel(nn.Module):
"""
极简版 GPT 语言模型(仅解码器结构)。
输入 token 索引,输出每个位置下一个词的 logits(未归一化的预测分数)。
"""
def __init__(self, cfg):
super().__init__()
# 1. Token 嵌入层:将离散的 token ID 映射为连续的向量表示
# 形状: [vocab_size, emb_dim]
self.tok_emb = nn.Embedding(cfg["vocab_size"], cfg["emb_dim"])
# 2. 位置嵌入层:为序列中每个位置分配一个可学习的位置向量
# 注意:GPT 使用绝对位置编码,且最大长度由 context_length 限定
# 形状: [context_length, emb_dim]
self.pos_emb = nn.Embedding(cfg["context_length"], cfg["emb_dim"])
# 3. 嵌入层后的 Dropout:防止过拟合,增强泛化能力
self.drop_emb = nn.Dropout(cfg["drop_emb"])
# 4. 堆叠多个 Transformer 解码器块(无交叉注意力)
# 每个块包含:掩码自注意力 + 前馈网络 + 残差连接 + LayerNorm
self.trf_blocks = nn.Sequential(
*[TransformerBlock(cfg) for _ in range(cfg["n_layers"])]
)
# 5. 最终 LayerNorm:对最后一层 Transformer 输出进行归一化
# (部分实现会省略此层,但保留可提升训练稳定性)
self.final_norm = LayerNorm(cfg["emb_dim"])
# 6. 输出投影层:将隐藏状态映射回词汇表空间
# 注意:bias=False 是常见做法(与嵌入层权重绑定时更一致)
# 形状: [emb_dim, vocab_size]
self.out_head = nn.Linear(cfg["emb_dim"], cfg["vocab_size"], bias=False)
def forward(self, in_idx):
"""
前向传播:从 token 索引生成 logits。
参数:
in_idx: 表示输入的 token ID 序列(如 [23, 56, 102, ...])
返回:
logits: 每个位置对应词汇表中每个词的未归一化得分
"""
batch_size, seq_len = in_idx.shape
# 获取 token 嵌入: [batch_size, seq_len, emb_dim]
tok_embeds = self.tok_emb(in_idx)
# 获取位置嵌入: [seq_len, emb_dim]
# 使用 torch.arange 生成位置索引 [0, 1, 2, ..., seq_len-1]
pos_embeds = self.pos_emb(torch.arange(seq_len, device=in_idx.device))
# 将 token 嵌入与位置嵌入相加(广播机制自动扩展 batch 维度)
x = tok_embeds + pos_embeds # [batch_size, seq_len, emb_dim]
# 对嵌入和应用 Dropout
x = self.drop_emb(x)
# 依次通过所有 Transformer 块
x = self.trf_blocks(x) # [batch_size, seq_len, emb_dim]
# 最终 LayerNorm(Pre-LN 结构下,最后一层后通常再加一次归一化)
x = self.final_norm(x)
# 投影到词汇表维度,得到 logits
logits = self.out_head(x) # [batch_size, seq_len, vocab_size]
return logits如上所述:这个 GPTModel 已具备完整自回归语言模型的核心结构。配合之前实现的 TransformerBlock、LayerNorm 和 MutiHeadAttention,即可训练一个小型 GPT!
将模型按照GPT-2模型初始化:参数配置如下
GPT_CONFIG_124M = {
'vocab_size': 50257, #词汇表大小,被BPE分词器使用的词汇表
'context_length': 1024, #上下文长度,模型通过位置嵌入能够处理的最大输入词元数量
'emb_dim': 768, #嵌入维度大小,可以将每个词元转化为768维度的向量
'n_heads': 12, #注意力头数
'n_layers': 12, #层数,transformer块数量
'drop_rate': 0.1, #dropout率 ,表示有10%的隐藏单元被随机丢弃,防止过拟合
'drop_emb': 0.1, #dropout率 ,表示有10%的隐藏单元被随机丢弃,防止过拟合
'drop_att': 0.1, #dropout率 ,表示有10%的隐藏单元被随机丢弃,防止过拟合
'drop_ff': 0.1, #dropout率 ,表示有10%的隐藏单元被随机丢弃,防止过拟合
'qkv_bias': False, #查询-键-值偏置
}使用未训练的GPT模型进行文本生成
此刻,我们已经组装好一个未经训练的GPT模型,怎么用该模型生成下个预测词呢,测试输出概率分布后,怎么通过概率分布转换为文本的。
从输入文本到输出文本,整体流程如下:
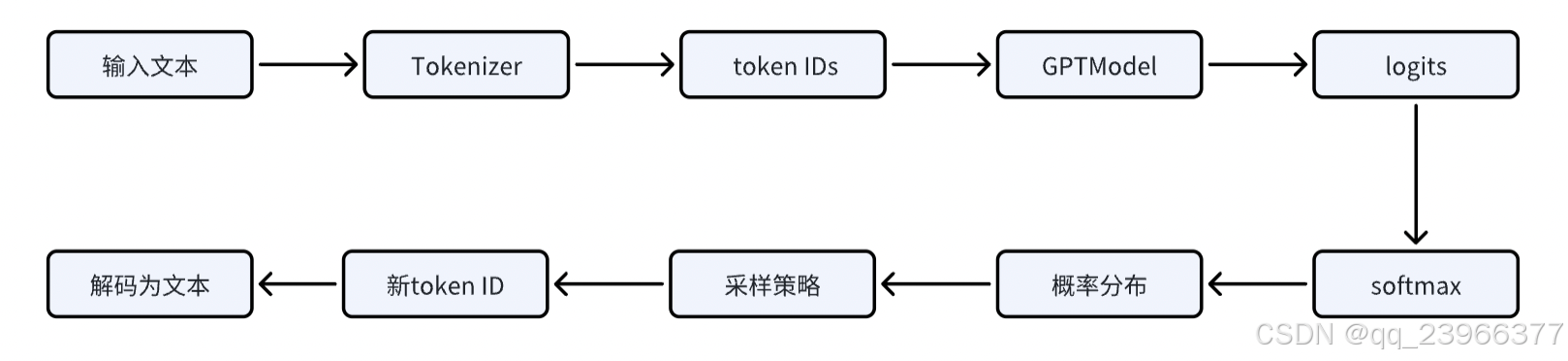
前面系列文章中已经实现了分词以及GPTModel的搭建,接下来我们还需要编写用于生成文本的函数:
def generate_text_simple(model, idx, max_new_tokens, context_size):
"""
使用 GPT 模型进行简单文本生成(贪婪解码)。
参数说明:
model (nn.Module): 已初始化的 GPT 模型(可以是随机权重或训练后的)
idx (LongTensor): 当前输入的 token 索引序列,形状为 [batch_size, n_tokens]
max_new_tokens (int): 要生成的新 token 数量
context_size (int): 模型支持的最大上下文长度(即最大输入序列长度)
返回:
LongTensor: 扩展后的 token 索引序列,形状为 [batch_size, n_tokens + max_new_tokens]
"""
# 循环生成指定数量的新 token
for _ in range(max_new_tokens):
# 1. 截断输入序列,确保不超过模型支持的最大上下文长度
# 例如:context_size=5,当前 idx 长度为 10 → 只取最后 5 个 token 作为输入
idx_cond = idx[:, -context_size:]
# 2. 关闭梯度计算(推理阶段不需要反向传播)
with torch.no_grad():
logits = model(idx_cond) # 前向传播,得到每个位置的预测 logits
# 3. 只取最后一个位置的 logits(用于预测下一个 token)
# 输入 [x1, x2, ..., xt] → 模型输出 t 个位置的 logits
# 我们只关心第 t 个位置对 x_{t+1} 的预测
logits = logits[:, -1, :] # 形状从 [batch, seq_len, vocab_size] 变为 [batch, vocab_size]
# 4. 将 logits 转换为概率分布(使用 softmax)
probas = torch.softmax(logits, dim=-1) # 形状: [batch, vocab_size],每行和为 1
# 5. 贪婪解码(Greedy Decoding):选择概率最大的 token
# torch.argmax 返回索引,keepdim=True 保持维度为 [batch, 1]
idx_next = torch.argmax(probas, dim=-1, keepdim=True) # 形状: [batch, 1]
# 6. 将新生成的 token 索引拼接到原序列末尾
# idx 原形状: [batch, n_tokens]
# idx_next 形状: [batch, 1]
# 拼接后: [batch, n_tokens + 1]
idx = torch.cat((idx, idx_next), dim=1)
# 返回完整的 token 索引序列(包含原始输入和新生成的部分)
return idx上述函数使用 GPT 模型进行简单文本生成(贪婪解码),返回为idx即tokenId,之后还需要经过decode解码为文本。接下来使用一个真实的语句对整个未训练的模型进行下个词生成预测:
# pip install tiktoken
import tiktoken
tokenizer = tiktoken.get_encoding('gpt2')
model = GPTModel(GPT_CONFIG_124M)
start_context = "Hello, I am"
encoded = tokenizer.encode(start_context)
print("encoded", encoded)
encoded_tensor = torch.tensor(encoded).unsqueeze(0)
print("encoded_tensor.shape", encoded_tensor.shape)
model.eval()
out = generate_text_simple(
model = model,
idx = encoded_tensor,
max_new_tokens = 6,
context_size = GPT_CONFIG_124M["context_length"]
)
print("out", out)
print("out length", len(out[0]))
decoded_context = tokenizer.decode(out.squeeze(0).tolist())
print("decoded_context", decoded_context)输出如下:
decoded_context Hello, I am FOX persecuted Bolt implysylv workflow可以看到模型输出了无意义的内容,这是因为我们还没有对其进行训练,随机初始化的 GPT 模型不具备语言知识,其输出完全随机,仅用于验证生成流程是否通畅。真实能力需通过大规模预训练获得。后续文章中将对我们编写的简易GPT进行简单训练,从而了解大模型的训练步骤。
总结
本文实现了 GPT 的核心架构和生成流程,但模型还未训练。下一篇文章将讲解:
-
如何准备文本训练数据(语料预处理、批量构建);
-
GPT 的训练目标(自回归语言建模损失);
-
用小数据集训练极简 GPT,让模型能生成有意义的文本。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 2
2 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)