Waymo重磅开源!4000+长尾片段,颠覆ADE指标,重新定义端到端驾驶
在真实道路上,最危险的时刻往往不是“正常行驶”,而是那些罕见却致命的“意外”——一只闯入车道的狗、一辆突然变道的货车、或一名被遮挡的行人。它不只是一个新数据集,更像是让AI重新理解“安全”“选择”与“责任”的一次训练。图3|人类标注员如何选出“关键一帧”:在标注过程中,人工评审者会先完整观看视频,理解事件背景,再挑出第一次出现关键风险的画面,即所谓的“关键帧”。而像HMVLM这类语言模型,ADE略
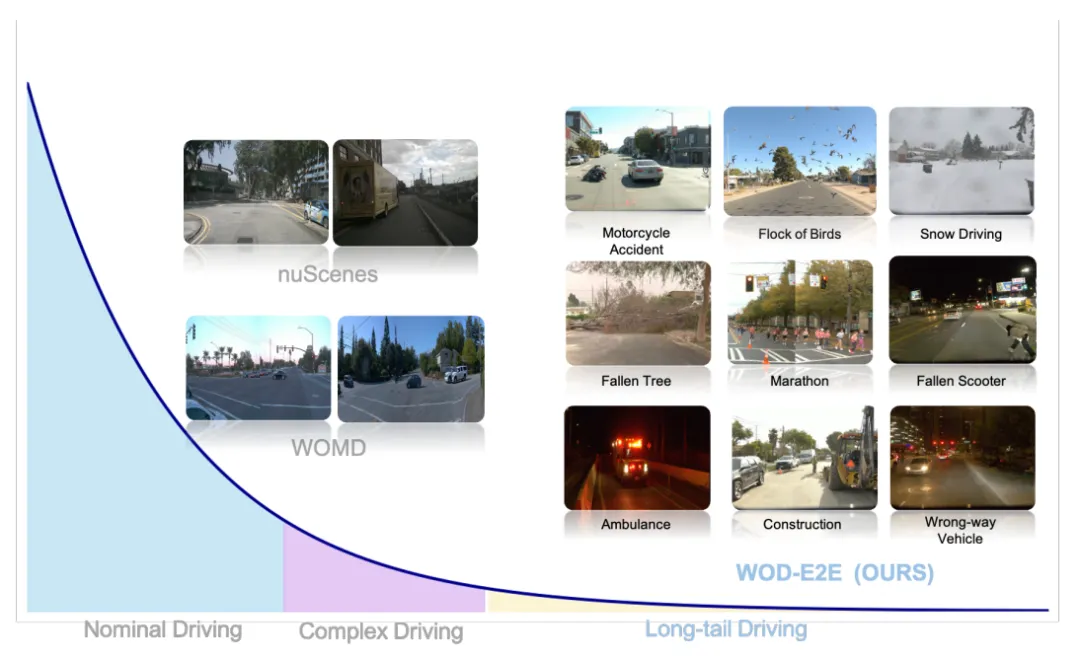
「一个专为长尾场景打造的新基准」
目录
在真实道路上,最危险的时刻往往不是“正常行驶”,而是那些罕见却致命的“意外”——一只闯入车道的狗、一辆突然变道的货车、或一名被遮挡的行人。这些极端事件构成了自动驾驶的“长尾难题”:它们极少发生,却决定了系统的生死。当前的端到端自动驾驶(E2E Driving)模型虽然能在常规路况中表现优异,但在这些长尾场景中往往失灵。因为现有数据集几乎都收录的是“平稳驾驶”,无法让模型学会真正的应变。
为此,Waymo团队推出了WOD-E2E(Waymo Open Dataset for End-to-End Driving)——一个专为长尾场景打造的新基准。
它汇集了超过4000段罕见驾驶片段(出现概率低于0.03%),并配合人类专家打分的新指标Rater Feedback Score(RFS),重新定义了“智能驾驶系统是否真的聪明”。这项工作让评测更接近真实世界的风险,也让AI学会思考“安全”意味着什么。
01 让长尾不再被忽略的E2E新基准
过去的E2E系统习惯以“平均距离误差(ADE)”来评价模型,即预测的轨迹离真实行驶路径有多远。但在现实中,驾驶是多模态的——面对一只突然飞出的鸟,既可以刹车,也可以绕行。ADE只看“偏差”,看不到“合理”。
Waymo团队意识到,真正的安全不只是“贴近数据”,而是“符合人类判断”。于是他们建立了WOD-E2E数据集:
- 从数百万英里的真实行驶日志中筛选出仅占0.03%的长尾片段,共计4,021段、12小时驾驶视频;
- 每段都包含8个环视相机画面、高精度路线指令与未来轨迹;
- 并由人类专家为三种可能的驾驶决策打分(0–10分),记录“最佳”“次优”“错误”的行为。
在此基础上,他们提出了RFS指标:模型预测的轨迹若落在人类高分轨迹的“信任区域”内,就能获得更高分数;若偏离则会指数衰减。与传统ADE不同,RFS让模型不仅要“走对路”,还要“像人一样思考风险”。

图1|WOD-E2E的全貌:城市、场景与行为分布:这张图从三个维度刻画了WOD-E2E的结构。左上为数据采集的城市分布,覆盖多样道路环境;左下展示了11类长尾场景(如行人、异物、施工、特种车辆等)在不同道路类型下的比例;右侧则描绘了驾驶行为统计——直行、变道、转弯与上匝道等,其中约三成数据来自高风险的交叉口操作
02 技术亮点
长尾聚焦:从6百万英里中挖出0.03%的关键瞬间
团队开发了一个结合规则与大模型(Gemini 2.5 Pro)的智能数据挖掘系统,自动识别罕见场景,包括:
- 建筑施工、行人冲出、异物坠落、特种车避让等11类高风险事件;
- 再经人工复筛与质量控制,确保仅保留最具挑战性的时刻。
这种“精炼采样”让WOD-E2E成为首个系统性覆盖长尾分布的公开E2E数据集。
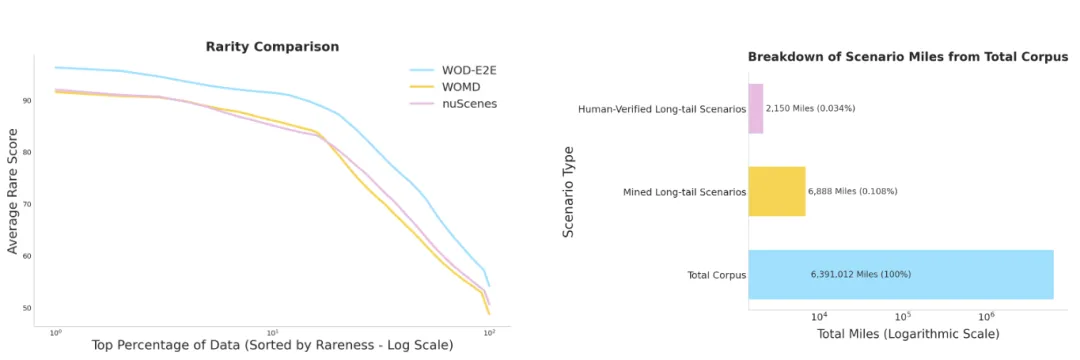
图2|数据稀有度对比:左图展示了多个主流自动驾驶数据集的“稀有度曲线”。可以看到,WOD-E2E在各百分位上的罕见事件占比都显著更高,说明它更集中地覆盖了那些真正棘手的场景。右图则显示了一个惊人的比例:在Waymo超过640万英里的行驶记录中,真正属于“长尾事件”的数据只占0.03%
人类评分:让AI理解什么是“合理驾驶”
在每个关键片段中,标注员需挑选出三个候选轨迹——一个最佳、一个中等、一个错误——并从安全、合法、反应及时、刹车合理、行驶效率五个维度打分。这种“多样评分”捕捉了驾驶的多模态性:不仅告诉AI哪条路正确,还告诉它为什么其他路不行,从而为学习提供更丰富的“行为边界”。
 图3|人类标注员如何选出“关键一帧”:在标注过程中,人工评审者会先完整观看视频,理解事件背景,再挑出第一次出现关键风险的画面,即所谓的“关键帧”。这一帧往往是车辆开始采取行动(如减速、避让)的瞬间,也被记录为模型学习的决策起点
图3|人类标注员如何选出“关键一帧”:在标注过程中,人工评审者会先完整观看视频,理解事件背景,再挑出第一次出现关键风险的画面,即所谓的“关键帧”。这一帧往往是车辆开始采取行动(如减速、避让)的瞬间,也被记录为模型学习的决策起点
新指标RFS:从数据拟合走向人类共识
RFS(Rater Feedback Score)通过对比模型预测与人类标注轨迹的空间重叠程度,计算出一个“人类一致性分数”。
- 若预测落在人类信任区间内,得满分;
- 偏离越多,分数按距离指数衰减;
- 完全偏离则直接“归零”。
这一机制让模型评测更符合真实安全标准,解决了ADE无法区分“多种正确解”的局限

图4|RFS:让AI学会靠近人类判断:Rater Feedback Score的机制如图所示:蓝线为模型预测的轨迹,灰线为人类专家评出的三种驾驶方案。系统会根据预测轨迹是否落入高分轨迹的“信任区间”来打分——越贴近人类偏好,得分越高;偏离越远,分数则逐步衰减
03 实验与表现
Waymo团队以简化版的 NaiveEMMA 模型作为基线,在WOD-E2E上验证RFS指标。
结果表明:
- 经过WOD-E2E数据微调后,模型的RFS从7.14提升至7.22;
- 加入多相机输入和测试时多样采样后,最高可达7.39,说明RFS能有效区分模型在复杂场景下的鲁棒性。
在公开排行榜中,三类模型形成了鲜明对比:
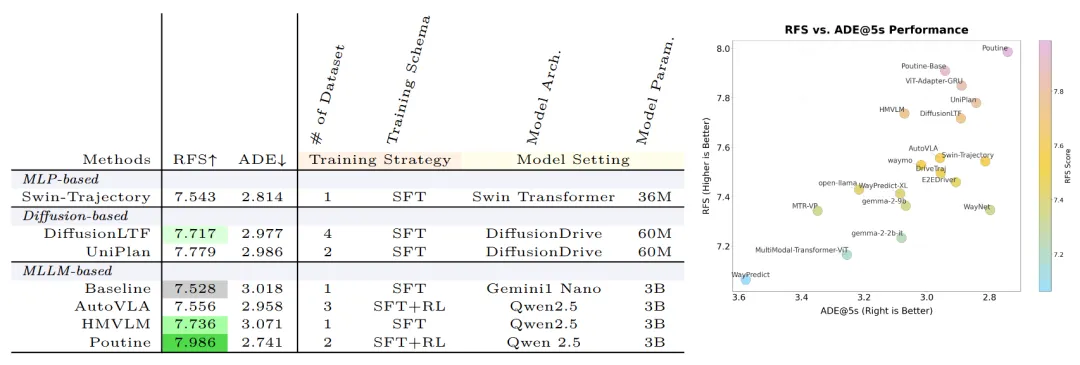
图5|三类模型的榜单表现:左表汇总了三种代表性方法——MLP类、扩散类与多模态大语言模型类(MLLM)——在WOD-E2E榜单上的成绩。右图展示了RFS与传统ADE指标的关系:两者相关性很弱,说明“距离正确”并不等于“行为安全”
- MLLM类(如Poutine、HMVLM、AutoVLA):利用多模态语言模型和链式推理(Chain-of-Thought)进行规划,其中Poutine以RFS 7.986位居榜首;
- Diffusion类(如DiffusionLTF、UniPlan):生成多样轨迹,RFS约7.7;
- 传统MLP类(如Swin-Trajectory):轻量但能力有限。
一个有趣的发现是:ADE并不等于安全。有些模型在ADE指标上表现优异,却在RFS上得分低;而像HMVLM这类语言模型,ADE略差却能获得更高的RFS——说明“偏离原轨迹”并非“错误”,只要行为安全且合理,人类依然会认可。

图6|RFS三种评分情形:贴合、偏离、失误。上:模型预测完全落在人类信任区内,获得满分。中:轨迹略微偏离理想路线,得分呈指数衰减。下:预测行为与人类方案完全不同(例如误转弯或加速过度),直接被判为最低分。这样的评分机制让AI的输出不再只追求“拟合”,而是真正贴近人类驾驶逻辑
04 总结与延伸
WOD-E2E让自动驾驶的“考题”终于变得像现实:充满突发、模糊、甚至无解的瞬间。通过引入人类偏好与长尾事件,这一基准重新定义了“什么才算安全驾驶”。它不只是一个新数据集,更像是让AI重新理解“安全”“选择”与“责任”的一次训练。当未来的智能体学会在复杂世界中做出人类式判断,也许那才是具身智能真正的起点。
论文标题:WOD-E2E: Waymo Open Dataset for End-to-End Driving in Challenging Long-tail Scenarios
论文作者:Runsheng Xu, Hubert Lin, Wonseok Jeon, Hao Feng, Yuliang Zou, Liting Sun, John Gorman, Kate Tolstaya, Sarah Tang, Brandyn White, Ben Sapp, Mingxing Tan, Jyh-Jing Hwang, Drago Anguelov
论文链接:https://arxiv.org/pdf/2510.26125

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 3
3 0
0- 0



 已为社区贡献67条内容
已为社区贡献67条内容

所有评论(0)