【大模型】理论基础(5):常用的模型微调和优化手段,SFT、RLHF、DPO、LORA、RAG
本文系统介绍了大模型微调与部署的关键技术。主要内容包括:1. 模型微调方法:监督微调(SFT)、基于人类反馈的强化学习(RLHF)、直接偏好优化(DPO)等;2. 微调加速技术:LoRA通过低秩矩阵分解降低计算量;3. 检索增强生成(RAG)技术,结合外部知识库提升模型实时性;4. 模型部署流程,包括推理引擎选择及标准化调用接口。文章详细阐述了各种微调方法的数据准备、实现原理及适用场景,特别对RL

目录
1.模型的微调
什么是微调:
经过预训练阶段后,诞生base model,模型已经有了通用的基本能力。通过微调让模型拥有某一方面的垂直能力或者横向的扩展能力。
微调的前提是模型要有一定封装格式:
模型微调就是通过不停的去调整模型的核心参数,然后达到自己想要的微调效果。要能调整核心参数,首先就要把核心参数暴露出来,所以模型要有一定的封装格式。业内暂时是没有强制性的格式标准的,但标准这东西本身就是谁强大谁就能制定标准,目前最大的开源大模型集成平台是hugging face,可以将hugging face理解为AI 界的 GitHub。hugging face定义了一套模型的封装标准,可以把模型类比为一个"类",hugging face定义了:
-
模型的核心参数的变量名分别是什么?通过这些变量名就可以去调整核心参数
-
必须有一个启动方法
-
必须有一个初始化方法,初始化的时候可以给核心参数赋值
目前所有的模型的统一训练、部署平台基本上都是沿用hugging face这套模型封装标准,所以也可以把这套标准看做就是大模型的封装标准。
总结起来就是:任何模型想要被开源模型平台所托管,被加载,被部署,就必须满足hugging face的封装格式。
微调的手段:
-
SFT,监督微调。
-
RLHF,强化学习。
-
LORA算法
-
RAG,检索增强生成。
2.模型的部署
模型预训练+微调后,会打包成一个可执行文件,交给推理引擎来执行,常用的推理引擎有vllm、Ollama,推理引擎和web server有点相似:
-
它们都是运行环境/容器,负责管理、调度和执行打包好的内容。
-
Tomcat加载Jar包(Web应用),监听HTTP端口,管理线程池,处理并发请求,并将请求路由到正确的Servlet。
-
推理引擎加载模型文件,监听API端口(如HTTP),管理计算资源(GPU),处理并发的推理请求,并高效地执行模型计算。
-
模型的调用遵循OpenAI标准,这是行业标准。
以上说的这些都是传统的模型部署平台,其实现在的训练平台llama factory、model scope等都是集成了训练和部署的全套能力。
3.微调平台
微调的平台有两种:
-
hugging face提供的以transformer库为核心的一整依赖库,通过写代码的方式来微调
-
通过诸如国外的llama factory和或内的model scope之类的可视化的微调平台来微调
详细使用教程见笔记《hugging face》、《llama factory》、《model scope》
4.SFT(监督微调/指令微调)
SFT就是准备垂直领域的训练集,喂给模型即可,做两件事:
-
准备垂直领域的训练集
-
通过微调参数让模型去这个垂直领域的训练集中进行训练
区别在于,不同类型、不同任务的模型SFT的数据集格式不同,以下举例说明。
文本生成类模型下的对话模型:
// 单轮指令跟随
{
"instruction": "将以下英文翻译成中文。",
"input": "I believe artificial intelligence will change the world.",
"output": "我相信人工智能将改变世界。"
}
// 多轮对话
{
"conversations": [
{
"role": "user",
"content": "你好,请介绍下你自己。"
},
{
"role": "assistant",
"content": "你好!我是一个AI助手,由XXX公司开发。我乐于帮助你解答问题、提供信息。"
},
{
"role": "user",
"content": "你能做什么?"
},
{
"role": "assistant",
"content": "我可以进行对话、回答知识性问题、翻译语言、撰写文案、总结内容等等。请随时向我提问!"
}
]
}
文本生成类模型下的文本分类模型:
数据集是csv格式
text,label "这部电影的视觉效果太震撼了,剧情也很棒!",positive "非常无聊的电影,看得我快睡着了。",negative "产品一般,没什么惊喜,但也不算差。",neutral
或者JSONL
{"text": "这款手机电池续航能力很强,很满意。", "label": "positive"}
{"text": "系统卡顿严重,体验非常差。", "label": "negative"}
多模态模型下的视觉问答模型:
{
"id": "vqa_001",
"image": "images/coco_00001.jpg",
"conversations": [
{
"from": "human",
"value": "图片里有什么动物?"
},
{
"from": "gpt",
"value": "图片里有一只棕色的猫和一只白色的狗。"
}
]
}
5.RLHF(基于人类反馈的强化学习)
5.1.概述
备注:RLHF(尤其是结合PPO)的实现非常复杂,需要进行大量的源码级改造和系统级工程优化,这使得许多开源训练框架对其支持有限或不完善,而更倾向于支持像DPO这样更简单、更稳定的算法。所以要是不具备大模型底层的研发能力,不建议做RLHF
RLHF,是一种让机器的回答更偏向于人类的偏好的一种微调技术。
比如:
问:法国的首都是哪里? 大模型可以回答:发过的首都是巴黎 也可以回答:巴黎
这种回答上的偏好就是可以通过RLHF去调整的。RLHF的过程如下:
-
准备好Base Model或者SFT Model,这个要被RLHF训练的Model统称为Policy Model(策略模型)
-
准备偏好数据集
-
对准备的Model,单一问题反复提问,就能单一问题得到多个答案
-
人工在单一问题的多个答案中进行比较,标注出偏好答案
-
-
通过偏好数据集训练奖励模型Reward Model
-
通过强化学习,用Reward Model作为裁判微调准备好的那个Base Model或者SFT Model
-
整个过程:Policy Model生成回答 -> 奖励模型(RM)为这个回答打分 -> 根据这个分数来更新Policy Model的参数
-
这里要注意要更新Policy Model,就要去调模型的参数,所以Policy Model要支持RLHF就必须按照一些规矩暴露一些“口子”出去,进行“外科手术式”的改造,在源码层面开出多个关键的“口子”或“接口”,让训练算法(PPO)能够深入到模型内部去获取信息、施加影响。
-
5.2.准备偏好数据集
拿单一问题去多次询问大模型,然后组成偏好对,比如问四次,会有四种回答{A, B, C, D},对于回答{A, B, C, D},如果通过多次两两比较,得出的排序是 B > A > C > D,那么你可以生成多个偏好对:(B, A), (B, C), (B, D), (A, C), (A, D), (C, D)
每一组可以组成:
{"prompt": "...", "chosen": "...", "rejected": "..."}
例如:
{"prompt": "中国的首都在哪里?", "chosen": "中国的首都在北京", "rejected": "北京"}
5.3.训练奖励模型
模型其实就是一个被修改了的LLM模型,它的输出从推理的文字,变成了一个具体的数据用来判定这个回答的偏好,由于这个模型能力不需要很强,所以一般选一个很小参数的小模型来作为奖励模型的基座来进行修改即可。
市面上目前有一部分开源的奖励模型,如果开源的奖励模型不够用的话,就只能去自研这个监督模型了,也就是说需要一些模型的开发能力去自研。
5.4.PPO
用偏好数据集训练好奖励模型了,那么接下来我该如何用这个奖励模型去强化学习目标模型喃?要用到PPO(近端策略优化)。
整个PPO在微调过程中所处的位置:
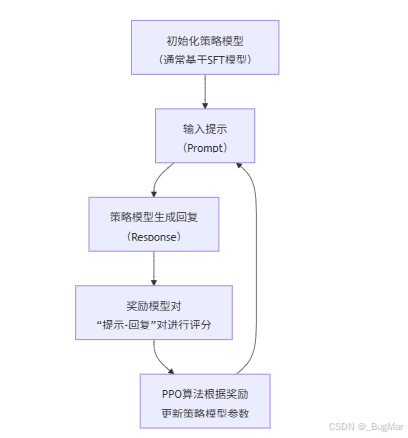
整个PPO可以理解为打游戏:
-
environment,整个游戏的引擎,负责生成内容,产生奖励,根据输入来做出对应响应,决定游戏什么时候结束等,这就是个黑盒子,不用了解实现细节,只负责和它交互就好。
-
agent,也就是被训练的模型,争取从environment获取最多的奖励。
-
state,游戏当前的状态,agent根据游戏当前的状态来做出决策。
-
action,agent做出的动作。
-
reward,监督模型,当agent做出动作的时候,给出对应的奖励或者惩罚。
整场游戏还有对应的一些术语:
-
action space:agent可以做的动作范围,比如{left,up,right}
-
policy,输入state的时候,action的概率分布,一般用π来表示,比如
-
π(left|St)=0.1,向左的概率为0.1
-
π(up|St)=0.2,向上的概率为0.2
-
π(right|St)=0.7,向右的概率为0.7
-
-
trajectory,轨迹,表示一连串状态和动作的序列,{s0,a0,s1,a1,......}
-
游戏一开始state=1
-
执行动作a0
-
state变成s1
-
执行动作a1
-
......
-
-
return,回报,从当前时间点到游戏结束的reward的累积和
期望
在无数次重复试验中,结果的平均值,它不是一个“预期”会发生的值,而是一个理论上的长期平均值。
用一个最简单的例子来理解。掷一个标准的六面骰子
-
问题: 如果我们掷无数次这个骰子,得到的点数平均值会是多少?
-
计算: (点数为1的概率 × 1 + 点数为2的概率 × 2 + ... + 点数为6的概率 × 6) 由于每个点数出现的概率是 1/6,上面的公式可以转化为: (1/6 × 1) + (1/6 × 2) + (1/6 × 3) + (1/6 × 4) + (1/6 × 5) + (1/6 × 6) = (1 + 2 + 3 + 4 + 5 + 6) / 6 = 21 / 6 = 3.5
所以,掷一个公平骰子的期望值就是 3.5。
请注意: 你永远不可能掷出3.5点。3.5这个数字的含义是:如果你掷骰子10万次、100万次,把所有点数加起来求平均,这个平均值会非常非常接近3.5。试验次数越多,就越接近。
PPO的目标:
训练一个神经网络,在所有状态下,给出相应的action,得到return的期望最大。
要达到上面的效果,换言之,就是让模型给出我们最偏好的,概率最大的回答就是,毕竟在训练奖励模型的时候就给每个回答算出了概率的。
但是要支持PPO的话,就要深入模型内部,模型开出对应的口子来才行。
6.DPO(直接偏好优化)
6.1.概述
DPO(Direct Preference Optimization,直接偏好优化),仅适用于生成模型,DPO不需要一个奖励模型,所以使用成本要比RLHF低很多。LLaMa-Factory所要求的的模型封装格式支持了DPO,所以LLaMa-Factory支持进行DPO。
整个DPO的过程总结如下:
-
准备好两个一摸一样的模型,一个作为策略模型,一个作为参考模型。
-
准备好chosen和rejected的回答
-
用策略模型、参考模型、chosen、rejected,一同去计算DPO的损失函数
-
DPO的损失函数的结果是模型对“优选回答优于拒绝回答”的信心概率,DPO算法会通过反向传播和梯度下降来调整策略模型的参数,使这个信心概率尽可能接近1。
DPO的损失函数:
DPO的损失函数是DPO的核心,DPO 损失函数会计算出一个介于 (0,1) 区间的值,这个值是模型对自己“认为优选回答(chosen)优于拒绝回答(rejected)”这个判断的“信心概率”。这个值是整个 DPO 训练过程的核心优化目标,朝着能让损失函数的值为1的方向去调参。
DPO的损失函数如下:
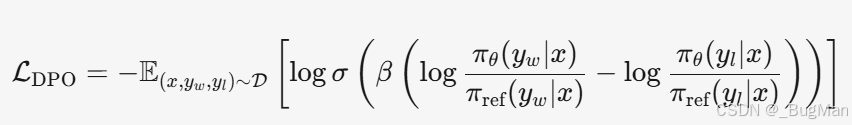
其中:
-
x 是提示(prompt)。
-
y**w 是优选回答(chosen)。
-
y**l 是拒绝回答(rejected)。
-
π**θ 是待优化的策略模型(参数为 θ)。
-
πref 是参考模型(参数固定)。
-
β 是一个超参数,控制模型偏离参考模型的强度。
-
σ 是 sigmoid 函数。
整个损失的核心部分为:

其余的项是保险:
| 损失函数组成部分 | 核心作用 | 直观理解 |
|---|---|---|
| **`β * [log (πθ(y_w | x) / π_ref(y_w | x)) - log (πθ(y_l |
σ (Sigmoid函数) |
1. 概率转换:将无限的差值映射到(0,1)区间,解释为“y_w优于y_l”的概率。 | 将无限的得分压缩到一个固定的概率范围内,符合Bradley-Terry偏好模型。 |
| 2. 稳定梯度:在差值极大或极小时,梯度会变小,防止过度优化和训练不稳定。 | 像一个“自动刹车”,防止模型为了拉大差距而走极端(忘记基础知识或过度优化)。 | |
-log(σ(...)) |
概率损失:将我们的目标(希望概率接近1)转化为一个最小化问题。 | 如果模型认为“好回答更好”的概率低(接近0),损失就会变得非常大,强力纠正模型。 |
β (温度参数) |
控制强度:调节模型对偏好数据的敏感度以及允许其偏离参考模型的程度。 | β越大,模型被鼓励更强烈地表达偏好(但可能偏离参考模型)。β越小,优化越保守。 |
6.2.数据集
DPO的数据集就比较统一了,不会根据模型类型、任务,分成不同格式,都是一个统一的格式:
{
"prompt": "向我解释一下什么是量子纠缠,就像我是10岁小孩一样。",
"chosen": "想象你有两颗神奇的‘纠缠’糖果。无论你把它们分开多远,哪怕一颗在地球,一颗在火星,只要你吃了其中一颗(比如是草莓味的),另一颗会瞬间变成柠檬味!科学家们发现,一些非常非常小的粒子,比如光子,就像这对糖果一样,会神秘地连接在一起。这就是量子纠缠,一个非常奇怪但真实的科学现象!",
"rejected": "量子纠缠是量子力学的一个特性,描述了两个或多个粒子在相互作用后,其量子状态纠缠在一起,以至于无法单独描述其中一个粒子的状态,而只能描述整体系统的状态。这种关联超越了空间距离,违反了贝尔不等式,为量子信息科学奠定了基础。"
}
6.3.如何调整策略模型的参数
计算出模型对“优选回答优于拒绝回答”的信心概率(即Sigmoid函数的输出值)之后,DPO算法会通过反向传播和梯度下降来调整策略模型的参数,使这个信心概率尽可能接近1。
| 核心机制 | 在DPO中的作用 | 直观理解 |
|---|---|---|
| 损失函数 | 将“信心概率”转化为可优化的量。信心越低,损失越大。公式为 L = -log(信心概率)。 |
提供了一个明确的优化目标:最小化损失。 |
| 梯度计算 | 通过反向传播计算损失函数对策略模型每一个参数的梯度。梯度指明了参数调整的方向(使损失减少)和幅度。 | 像一张地图,告诉模型参数应该往哪个方向移动多少距离,才能更准确地区分好坏回答。 |
| 参数更新 | 使用优化器(如AdamW)根据计算出的梯度更新策略模型的参数。公式大致为:新参数 = 旧参数 - 学习率 × 梯度。 |
模型根据“地图”的指引,实际迈出一步,更新自己的“内部知识”。 |
| 参考模型 | 提供一个基准。计算梯度时,策略模型相对于参考模型对优选回答的偏好提升会被鼓励,而对拒绝回答的偏好提升会被抑制。 | 像一个“锚点”或“守恒定律”,防止模型为了讨好偏好而变得面目全非,保持生成能力。 |
| 温度参数 β | 控制学习强度。β值越大,模型对偏好数据的响应越激进(梯度信号越强);β值越小,优化越保守。 | 像调整学习的“步伐大小”,步伐太大容易摔倒(偏离太远),步伐太小则学习缓慢。 |
7.LORA(加速微调)
Lora(Low-Rank Adaptation of Large Language Models, 大语言模型的低秩适应),不是拿来调优大模型的,而是用来加速调优过程的。传统的全参微调,会把整个权重矩阵重新算一遍,这个过程非常耗时、耗力(计算资源)。
LLaMA-Factory 支持 LoRA(Low-Rank Adaptation),并且对LoRA及其相关技术的支持是其核心特色和主要优势之一。它旨在帮助用户在有限的算力资源下,高效地微调大型语言模型。
Lora就是用一个小矩阵去撬动一个大矩阵:
-
权重矩阵:神经网络层(比如注意力机制中的Q, K, V矩阵)本质上都是巨大的矩阵(例如 1024x1024)。
-
微调的本质:微调就是给这个原始权重矩阵
W一个增量更新ΔW,变成W' = W + ΔW。 -
LoRA的洞察:
ΔW这个巨大的更新矩阵,其内部包含的信息其实很“稀疏”,可以用两个又小又瘦的矩阵A和B的乘积来近似表示,即ΔW = A * B。-
假设原始矩阵
W的维度是d x d。 -
LoRA 引入两个矩阵:
-
A:维度是d x r(一个降维矩阵) -
B:维度是r x d(一个升维矩阵)
-
-
这里的
r(秩) 是一个远小于d的数(比如 4, 8, 16)。
-
这样调一个大矩阵,就变成了调整一个小矩阵,要快很多。
8.RAG(检索增强生成)
RAG(Retrieval-Augmented Generation,检索增强生成),用来增强实时性。大模型所知道的知识库毕竟是预先训练,是固化的,如果要大模型的知识库是可以实时更新的,就要用到RAG。
RAG 的整个过程可以清晰地分为三个核心步骤:
第一步:检索
-
数据准备:首先,将一个外部的知识库(如公司内部文档、产品手册、法律法规、最新新闻等)进行预处理。
-
分割与向量化:将这些文档分割成小的文本块,并使用 嵌入模型 将每个文本块转换为数学上的 向量。这些向量被存入一个专门的数据库,称为 向量数据库。
-
问题检索:当用户提出一个问题时,同样将这个问题转换为向量。然后,在向量数据库中搜索与这个问题向量 最相似 的文本块(通常使用余弦相似度等算法)。这些被找到的文本块就是与问题最相关的“参考资料”。
第二步:增强
将 用户的原始问题 和 第一步检索到的相关文本片段 组合在一起,构建成一个新的、增强版的提示。
示例:
-
原始问题:“我们公司今年的年假政策有什么变化?”
-
检索到的资料:“【2024年人事政策更新】自2024年1月1日起,员工年假天数将根据司龄自动增加一天,详情请见内网。”
-
增强后的提示:
请根据以下背景信息回答问题: <背景信息开始> 【2024年人事政策更新】自2024年1月1日起,员工年假天数将根据司龄自动增加一天,详情请见内网。 <背景信息结束> 问题:我们公司今年的年假政策有什么变化?
第三步:生成
将这个增强后的提示发送给大语言模型(如 GPT-4、LLaMA 等)。模型基于提供的背景信息来生成答案,而不是仅仅依赖其内部知识。
生成的答案可能是: “根据公司2024年的人事政策更新,今年的年假政策主要变化是:从2024年1月1日起,员工的年假天数将根据司龄自动增加一天。”

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 16
16 0
0- 0



 已为社区贡献26条内容
已为社区贡献26条内容

所有评论(0)