法准速查智能RAG系统
本项目基于RAG技术开发了一个法律文书智能解读系统,旨在解决法律文书专业术语难懂、咨询成本高的问题。系统采用三级缓存架构(Redis、MySQL、RAG引擎)实现高效检索,通过BM25算法和混合检索策略提升匹配精度。核心技术包括: 使用BGE-M3模型进行文本向量化,支持稠密和稀疏向量检索 采用LangChain框架整合文档处理流程 部署BERT微调模型进行意图识别 实现四种检索策略(直接检索、H
第一章:项目背景
法律行业常面临法律文书术语专业,解读困难的问题,线上搜索信息杂乱,专业咨询成本耗时较长成本较高.本项目基于RAG技术,利用LangChain结合MySQL整合权威知识库,通过milvus向量库快速检索匹配信息,为患者提供精准的,易懂的个性化报告解读.优点在于秒级效应,解释权威通俗易懂,并且利用Redis缓存高频问答,极大提升用户的体验和效率.
1.1痛点:
法律文书复杂,咨询成本高
咨询者容易忘记一些信息,经常反复咨询
纯向量RAG成本高,响应慢,高频问题重复检索浪费算力
1.2解决:
《大众常用法律文书一本通》与典型的病例问答切片入库Milvus,LangChain检索+BM25精排,上传pdf/拍照相关文书,OCR后自动匹配检索结果,生成'问题分类以及如何解决'报告;MYSQL,Redis存高频问答对,支持离线.
1.3项目成果
减小企业客户端,累计解读超过2000份报告
客户复问率降低38%,律师人均解释时间节省40min
缓存命中率76%,节省向量检索费用65%
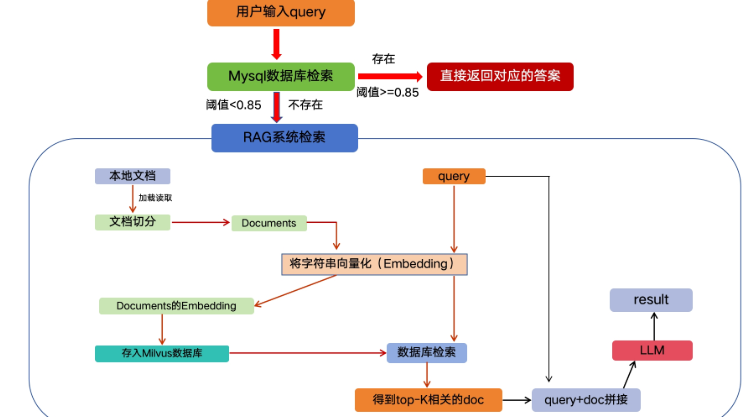
1.4项目本地化部署过程
- 用户输入Query
- Redis检索,MYSQL检索
- RAG系统检索
项目架构图示:
1.5技术栈
Python,LangChain,Mysql,Redis,Milvus,tf-idf/bm25,RAG,PaddleOCR,LoRA,BERT
1.6开发成本
约300万元
第二章:FQA系统概述
2.1数据分析:
数据来源:数据提供方:***公司
数据内容:mysql里面存储了476条高频问答对,有三个字段:分类名称,问题,答案.
使用BM25算法计算相似度,通过softmax归一化把得分转换为概率值,根据阈值判断答案可靠性(大于阈值且有明确答案为可靠答案).如果没有答案到RAG系统里面检索
2.2三级缓存响应层
2.2.1L1 Cache
Redis-只存储大于阈值且有明确回答的热点问题缓存,(目标:0延迟)
2.2.2L2 Cache
Mysql-保存高频问答对(目标:50ms内响应)
使用余弦相似度计算用户问题向量与表中question_vector的相似度,若相似度大于0.85,判断为语义等价问题,直接返回预制答案,并且把这个答案异步写会Redis.命中率大约37%,是降低RAG成本的核心.
2.2.3 L3 Cache
RAG引擎-冷启动处理(目标1.5s内响应)
当前两级缓存都没有命中,启动完整的RAG流程,确保所有问题都能得到解答.
2.3版本信息:
mysql:5.7
redis:2.4
第三章:实现MYSQLQA模块
2.1功能
mysql里面存储的是高频问答对,是本地化持久存储.redis存储的是top-k个超高频问答对,在内存中存储.
2.2数值转换方法
mysql数据库数据存到redis里面有两种方法:
- 键值对打包:把数据的question打包为key,把数据的answer和标签打包在一起为字符串打包成value
- hash编码:生成hash值,和question一起作为容器编号,容器里里面存储的是answer和标签.
2.2.1提取数据
使用键值对的方式提取回答的时候需要把字符串拆包,然后提取answer,使用hash方式,不需要拆包,只要找到hash值对应的容器,直接把值返回给用户就可以了,速度比键值对方式快一些.
2.3BM25算法
使用前先分词,是tf-idf改进,增加了词频和文本长度惩罚机制
BM25L:解决了基础版对超长文本惩罚过度的问题
为什么选择bm25算法计算query和数据库question相似度?
bm25算法是经典的相似度计算方法.尤其适用于短query和长文本直接相似度匹配.不需要向量计算,通过词频计算query和数据库数据相似度,支持批量检索,可以实现毫秒级检索.bm5模型不需要复杂的预训练模型或者硬件支持,可以实现快速落地.确定是给予字面匹配,不理解语义.我们的mysql数据库核心是实现数据与用户query快速匹配,符合我们的项目需求.当时也考虑了tf-idf算法,但是这个算法在长文本方面匹配精度低,因为考虑到数据中有长文本,所以就舍弃了tf-idf算法
2.4Redis数据库
高性能键值对的数据库,有16个数据库,默认第0个
存储原始问答对和分词后的问答对
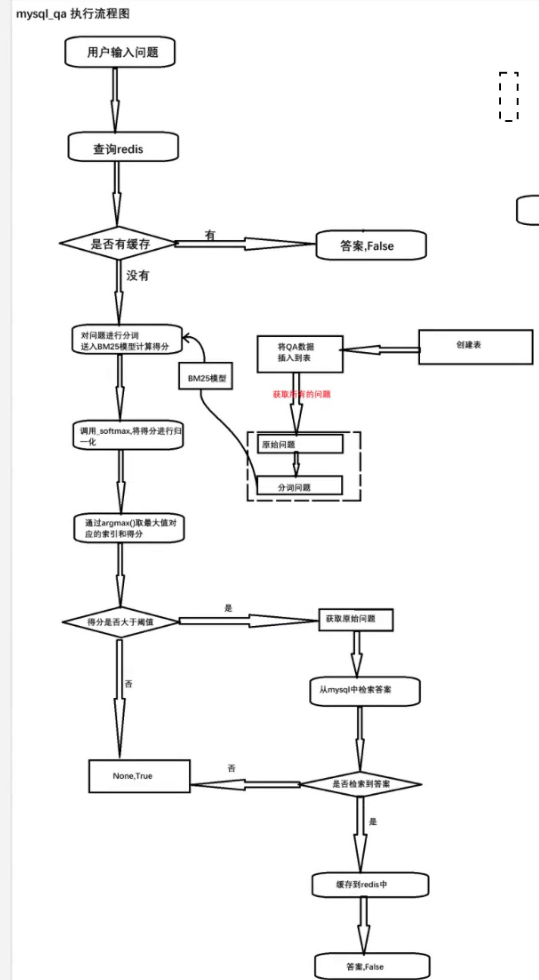
2.5执行流程
用户输入Query->在redis中检索->分词计算匹配度,使用softmax归一化,再用argmax取最大值索引->在mysql数据库中检索->返回数据并缓存到redis里面
若果相似度低于阈值或者在mysql里面没有检索到那么走rag
注意:redis里面没有相似度计算.只是查.
优化操作:提前对mysql数据分词
查询mysql前先要进行相似度计算.,最后在匹配query后把结果存到redis里面,
2.6混合检索
对多个条件相似度计算后,把相似度合并和重新排序(加权排序(WeightRanker)和重排序(RRFRanker))
2.7.阈值设置
阈值太高,都去走rag检索,耗时太长,成本太高;
阈值太低,准确率不够
2.8mysql,redis数据库代码实现
2.8.1数据格式
数据来源是csv格式,数目是468条,三个字段.
2.8.2mysql数据库连接
- 连接数据库
- 创建表
- 插入数据
- 查询所有问题
- 查询答案
- 关闭连接
import pymysql
from base.config import Config
from base.logger import logger
import pandas as pd
class MysqlClient(object):
def __init__(self):
self.logger = logger
conf = Config()
try:
self.connection = pymysql.connect(
host = conf.MYSQL_HOST,
user=conf.MYSQL_USER,
password=conf.MYSQL_PASSWORD,
database=conf.MYSQL_DATABASE
)
self.cursor = self.connection.cursor()
self.logger.info('mysql连接成功')
except Exception as e:
self.logger.error(f'数据库连接失败!失败原因{e}')
raise
def create_table(self):
create_table_sql = """
create table if not exists jpkb(
id int auto_increment primary key ,
subject_name varchar(20),
question varchar(1000),
answer varchar(1000)
)"""
try:
self.cursor.execute(create_table_sql)
self.connection.commit()
self.logger.info('创建表成功')
except Exception as e:
self.logger.error(f'创建表失败,失败原因{e}')
raise
def insert_data(self,csv_path):
try:
data=pd.read_csv(csv_path)
print(data)
for _,row in data.iterrows():
insert_query='insert into jpkb values (null,%s,%s,%s)'
self.cursor.execute(insert_query,(row['学科名称'],row['问题'],row['答案']))
self.connection.commit()
self.logger.info('数据插入成功')
except Exception as e:
self.logger.error(f'数据插入失败{e}')
self.connection.rollback()
raise
# 获取数据:有格式要求:元祖嵌套元组((问题一),(问题二))
def fetch_question(self):
try:
self.cursor.execute('select question from jpkb')
# fetchall()返回格式是元祖嵌套元组
results = self.cursor.fetchall()
self.logger.info('获取所有问题成功')
return results
except Exception as e:
self.logger.error(f'获取所有问题失败{e}')
return []
def fetch_answer(self,question):
try:
self.cursor.execute('select answer from jpkb where question=%s',(question))
result = self.cursor.fetchone()
print(result)
# fetchone()查询答案返回格式是元组嵌套
return result[0] if result else None
except Exception as e:
self.logger.error(f'获取答案失败{e}')
return None
def close(self):
try:
self.connection.close()
self.logger.info('mysql连接已关闭')
except Exception as e:
self.logger.error(f'关闭数据库连接失败{e}')
if __name__ == '__main__':
mysql_client=MysqlClient()
mysql_client.create_table()
# mysql_client.insert_data(csv_path='../data/JP学科知识问答.csv')
# question=mysql_client.fetch_question()
# print(question[:3])
# mysql_client.fetch_answer("lxml的tree报错")
mysql_client.close()
2.8.3redis数据库连接
import redis
import json
import os,sys
from base.config import Config
from base.logger import logger
class RedisClient:
def __init__(self):
self.logger = logger
try:
conf = Config()
self.client = redis.StrictRedis(
host=conf.REDIS_HOST,
port=conf.REDIS_PORT,
password=conf.REDIS_PASSWORD,
db=conf.REDIS_DB,
decode_responses=True # 直接返回字符串
)
self.logger.info('Redis连接成功')
except Exception as e:
self.logger.error(f'Redis连接失败{e}')
raise
def set_data(self,key,value):
try:
self.client.set(key,json.dumps(value,ensure_ascii=False))
self.logger.info('数据存储到redis中成功')
except Exception as e:
self.logger.errot(f'数据存储到redis中失败{e}')
def get_data(self,key):
try:
data = self.client.get(key)
self.logger.info('获取数据成功')
return json.loads(data) if data else None
except Exception as e:
self.logger.error(f'获取数据失败{e}')
return None
def get_answer(self,query):
try:
self.logger.info('在redis中查询答案中')
answer = self.client.get(f'answer:{query}')
if answer:
self.logger.info(f'从redis中获取答案:{query}')
return answer
return None
except Exception as e:
self.logger.error(f'redis查询失败{e}')
return None
if __name__ == '__main__':
redis_client = RedisClient()
redis_client.set_data('answer:pycharm导入模块的快捷键是什么','alt+enter')
print(redis_client.get_data('answer:pycharm导入模块的快捷键是什么'))
print(redis_client.get_answer(query="pycharm导入模块的快捷键是什么"))2.9mysqlqa执行流程
2.10数据预处理
import jieba
from base.logger import logger
def preprocess_text(text):
logger.info('开始与处理文本')
try:
return jieba.lcut(text.lower())
except Exception as e:
logger.error(f'文本预处理失败{e}')
return []
if __name__ == '__main__':
print(preprocess_text('黑马程序员'))2.11BM25search 模块
实现通过BM25计算匹配度,比较阈值以后决定是存入redis里面还是到rag检索
# 导包
from rank_bm25 import BM25Okapi # 用于实现BM250算法(基于概率文本搜索排序算法)
import numpy as np
import sys, os
from base.logger import logger
# todo1 路径配置
current_dir = os.path.dirname(os.path.abspath(__file__))
module_dir = os.path.dirname(current_dir)
# 把模块路径添加到系统路径
sys.path.insert(0, module_dir)
project_root = os.path.dirname(module_dir)
sys.path.insert(0, project_root)
from utils.preprocess import preprocess_text
from db.mysql_client import MysqlClient
from cache.redis_client import RedisClient
class BM25Search:
# todo 1. 初始化BM25Search方法
def __init__(self, redis_client, mysql_client):
# 1.初始化日志实例
self.logger = logger
self.redis_client = redis_client
self.mysql_client = mysql_client
# .初始化BM25大模型
self.bm25 = None
# 初始化分词后的问题列表
self.questions = None
# 初始化原生问题列表(用于匹配答案是的原始文本对照)
self.original_questions = None
# 调用数据加载方法
self._load_data()
# todo 2. 数据加载方法,优先从redis缓存加载
def _load_data(self):
# 1.定义redis缓存键(用于区分 原始问题 和 分词后的问题 的缓存)
original_key = "qa_original_questions" # 原始问题缓存键
tokenized_key = "qa_tokenized_questions" # 分词后问题缓存键
# 2.从redis获取原始问题(缓存读取速度快,减少mysql数据库访问)
self.original_questions = self.redis_client.get_data(original_key)
print(f"original_questions:{self.original_questions}")
# 3.从redis获取分词后的问题
tokenized_questions = self.redis_client.get_data(tokenized_key)
print(f"tokenized_questions:{tokenized_questions}")
# 4. 如果redis缓存中无数据(或者数据不完整),则从mysql加载并更新缓存
if not self.original_questions or not tokenized_questions:
# 4.1 从mysql数据库中获取原始问题列表
self.original_questions = self.mysql_client.fetch_questions()
# 4.2 若mysql中也无问题数据,记录警告日志并返回 (先记录一下日志!!!)
if not self.original_questions:
self.logger.warning("未从mysql加载到任务问题的数据") # 先记录到日志里面
return
# 4.3 走这里,即mysql存在 .所以对原始问题进行分词处理.
tokenized_questions = [preprocess_text(question[0]) for question in self.original_questions]
# print(f'tokenized_questions: {tokenized_questions}')
# 4.4 将原始问题列表 -> 字符串列表, 并缓存到Redis中.
self.redis_client.set_data(original_key, [(question[0]) for question in self.original_questions])
# 4.5 将分词后的问题列表缓存到Redis -> 供下次直接使用, 避免重复计算.
self.redis_client.set_data(tokenized_key, tokenized_questions)
# 5.保存分词后的问题列表(用于初始化bm25模型) ,后期bm25计算的时候使用分词的
self.questions = tokenized_questions
# 6.初始化bm25模型(使用分词后的问题列表作为语料库)
self.bm25 = BM25Okapi(self.questions)
# 7.记录info日志,确认模型初始化完成
self.logger.info("BM25模型初始化完成!")
#todo 3 softmax分数归一化方法:
def _softmax(self,scores):
"""
对输入的分数进行softmax归一化,输出总和为1的概率分布
"""
exp_scores=np.exp(scores-np.max(scores))
#2.返回归一化结果
return exp_scores/exp_scores.sum()
# todo 4 核心搜索方法:处理查询,计算相似度,返回匹配答案或者提示无结果
# 0.85值 是当前项目设置的 .
def search(self, query, threshold=0.85):
"""
根据输入查询检索最相似的问题并返回对应的答案
# 用户输入 问题 计算 问题与问题相似度 ->找答案
:param query: 用户查询文本
:param threshold: 相似度阈值(超过此值认为匹配成功)
:return: 若匹配成功 (答案,False) 若未匹配或者异常(None,True)
"""
# 1.检查查询有效性(为空 或者非字符串类型则视为无效)
#isinstance 判断query对象是否是某个字符串类型
if not query or not isinstance(query,str):
self.logger.error("无效查询:查询为空或者非字符串类型")
return None,True
# 2.先检查redis缓存(若查询结果已缓存,直接返回,提升效率)
cachad_answer=self.redis_client.get_answer(query)
if cachad_answer:
return cachad_answer,False
try:
# 3.对查询文本进行预处理(分词,与问题库预处理逻辑一致)
query_tokens=preprocess_text(query)
# 4.计算查询与所有问题的bm25相似度分数
scores=self.bm25.get_scores(query_tokens)
# print(f"scores:{scores}")
# 5. 对分数softmax归一化(转为概率分布,便于与阈值比较)
softmax_score=self._softmax(scores)
# print("*"*48)
# print(f"softmax_score:{softmax_score}")
# 6.找最高的相似度对应的索引和分数
best_idx=softmax_score.argmax() #最高分索引
best_score=softmax_score[best_idx]
# 7.若最高分超过阈值,视为匹配成功
if best_score>=threshold:
# 7-1: 获取最高匹配度的原始问题(用于从数据库查询答案)
original_question=self.original_questions[best_idx]
# 7-2:从mysql数据库中查询对应的答案
answer=self.mysql_client.fetch_answer(original_question)
if answer:
# 7-3:将查询-答案缓存到redis(供下次使用)
self.redis_client.set_data(f"answer:{query}",answer)
# 7-4:记录日志
self.logger.info(f"搜索成功,softmax相似度:{best_score:.3f}")
return answer,False #第二个参数false表示非新查询(已缓存)
# 8.若未超过阈值,记录info日志并返回无结果
self.logger.info(f"未找到可靠答案,最高的softmax相似度:{best_score:.3f}(低于阈值{threshold})")
return None,True
# 9.异常处理
except Exception as e:
self.logger.error(f"搜索查询失败:{e}")
return None,True
if __name__ == '__main__':
redis_client = RedisClient()
mysql_client = MysqlClient()
# 实例化BM25Search(自动加载数据并初始化模型)
bm25_search = BM25Search(redis_client, mysql_client)
bm25_search._load_data()
# result=bm25_search.search("吃了吗?")
# print(result)
小问题补充:
Bm250:使用分以后的问题初始化Bm25模型
第三章:RAG模块实现
RAG技术通过检索外部知识库增强大语言模型的回答能力,特别适用于需要专业知识的场景
3.1.milvus向量数据库操作(存储索引向量)
3.1.1索引类型
- FLAT
- IVF-FLAT
- IVF-SQ8
- IVF-PQ
- HNSW
3.1.2相似度计算方法
- 欧几里得距离
- 内积
- 余弦相似度:计算两个向量夹角的余弦值
3.2LangChain组件
- models:通用models,chat models,嵌入大模型
- memory:短期记忆,长期记忆
- index:document加载切分,向量化.milvus向量存储,检索器加载
- chain:lcel,通用chain
- prompt:通用prompt,chat prompt(对一系列组件调用)
- Agent:决定LLM执行流程
3.3RAG系统的工作流程
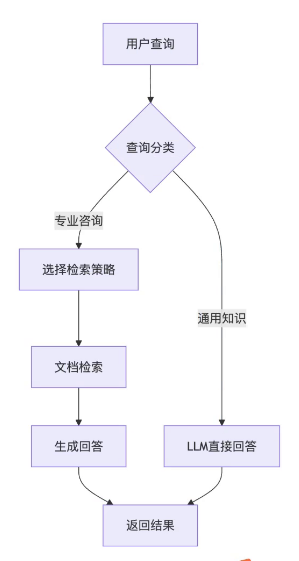
可能在RAG的检索中也查询不到答案,这一般是问题太新导致的,这时候引导去找客服处理
3.4检索策略
- 直接检索:通过关键字检索
- Hyde检索:问题很抽象,像是开放题,没有具体答案.先假设一个回答,根据这个回答拓展回答
- 子查询检索:查询问题里面有多个子问题子维度,分别检索各个子问题做出回答
- 回溯检索:复查问题简化后检索,先在问题表层回答,后面深挖回答
3.5文档处理
3.5.1文件类型
论文:pdf
使用说明书:word
研报:ppt
图片
3.5.2不同类型数据的加载方式
- markdown和txt读取方式都是langchain内置模块
- txt文档读取的时候要指定编码格式,在后续读取的时候要分情况讨论,因为其他格式的文件读取不需要指定编码格式
- markdown的切分方式是langchain内置的切分模块(根据markdon本身的格式切分)
- 其他类型的文档加载器和文档切分器都是由第三方社区导入
- 文档加载:百度飞桨paddleOCR(图片识别内嵌文字)识别不同类型的数据转为document对象
- 为什么选择百度飞桨ocr作为文档识别的模型? 我们以数据是中文文本以及数据来源复杂(ppt,pdf,word,markdown等)为参考调研市场上的模型,选择百度飞桨作为文档识别模型.首先是因为他是中文识别主导的模型,可以实现包含大量的pdf,图片文档的场景,然后他是开源免费的,可是实现本地部署.其次我们研究了百度飞桨的评估报告,在识别精度可以达到99.7%,f1值可以达到99.2,相当高的指标以及工具的一体化使我们选择他作为我们数据识别的原因.
- 文档切分:nlp_bert_document_egmrntation_chinesee_base(基于bert_base_chinese)是AliTextSplitter提供的基于大模型的文本切分
- 为什么选择nlp_bert_document_segmrntation_chinesee_base模型作为文档切分模型?
- 我们的数据既有多段落也有多段落,经过调研市场模型,我们看了这个模型可以处理单段落和多段落文本的切分,一句子整体为判断是否作为段落的开头.并且我们看过了该模型的的评估报告,在准确率方面达到78.4%,精确率方面有70%,f1值有73.7,满足我们数据切分要求
- 相较于基于规则切分,基于模型的语义切分更好的根据语义的关联性切分,而不仅仅是标点符号.
- 缺点是因为大模型的参与.开发成本更高一些
3.5.2文档切分方式
- 基于规则的递归切分:使用标点符号切分文档,
- 基于模型的语义切分:基于语义切分文档
我们在这里用的是基于递归规则的方式切分文档.切分的要求是,先把文档切成父块,再把父块切为子块.后面再把子块变为嵌入向量存到向量数据库里面
为什么要把文档切成父块子块?
把文档切分小块加强检索精度
3.6切分代码
import sys,os
from langchain_community.document_loaders import TextLoader
from langchain_community.document_loaders.markdown import UnstructuredMarkdownLoader
from langchain.text_splitter import MarkdownTextSplitter
from datetime import datetime
current_dir=os.path.dirname(os.path.abspath(__file__))
module_dir= os.path.dirname(current_dir)
sys.path.insert(0,module_dir)
project_root=os.path.dirname(module_dir)
sys.path.insert(0,project_root)
# 自定义的文档加载器和文档分割器 ,直接复制过来用即可. 无需手动编写.如果后续开发用到类似操作.直接使用代码即可
from edu_text_spliter import AliTextSplitter, ChineseRecursiveTextSplitter
from edu_document_loaders import OCRPDFLoader, OCRDOCLoader, OCRPPTLoader, OCRIMGLoader
from base.config import Config
from base.logger import logger
conf = Config()
document_loaders = {
".txt": TextLoader, # txt文本文件 ,用langchain的textloader加载
".pdf": OCRPDFLoader, # pdf 用OCRPDFLoader(pdf文档加载,支持扫描件/图片的pdf的文字识别)加载
".docx": OCRDOCLoader, # word文档
".ppt": OCRPPTLoader, # ppt文档
".pptx": OCRPPTLoader, # pptx文档
".jpg": OCRIMGLoader, # 图片文件 jpg
".png": OCRIMGLoader, # 图片文本 png
".md": UnstructuredMarkdownLoader # md文件
}
def load_document_from_directory(directory_path):
documents=[]
# 获取加载器名称 格式是[""."",""......]
supported_extensions = document_loaders.keys()
# 提取文件名
source=os.path.basename(directory_path).replace('_data','')
for root,_,files in os.walk(directory_path):
# root:文件目录
# _:文件子目录
# files:文件内部文件
for file in files:
file_path=os.path.join(root,file)
file_extension=os.path.splitext(file)[1].lower()
if file_extension in supported_extensions:
try:
loader_class=document_loaders[file_extension]
if file_extension == '.txt':
loader=loader_class(file_path,encodings='utf-8')
else:
loader=loader_class(file_path)
loaded_docs = loader.load()
for doc in loaded_docs:
doc.metadata['source']=source
doc.metadata['file_path']=file_path
doc.metadata['timestamp']=datetime.now().isoformat()
documents.extend(loaded_docs)
logger.info(f'文件:{file_path}加载成功')
except Exception as e:
logger.error(f'文本{file_path}加载失败,原因{e}')
else:
logger.warning(f'不支持文件类型{file_path}')
return documents
def process_documents(directory_path,parent_chunk_size = conf.PARENT_CHUNK_SIZE,
child_chunk_size = conf.CHILD_CHUNK_SIZE,
chunk_overlap=conf.CHUNK_OVERLAP):
documents=load_document_from_directory(directory_path)
logger.info(f'加载文档的数量{len(documents)}')
parent_splitter=ChineseRecursiveTextSplitter(chunk_size = parent_chunk_size,chunk_overlap=chunk_overlap)
child_splitter=ChineseRecursiveTextSplitter(chunk_size=child_chunk_size,chunk_overlap=chunk_overlap)
markdown_parent_splitter=MarkdownTextSplitter(chunk_size=parent_chunk_size,chunk_overlap=chunk_overlap)
markdown_child_splitter=MarkdownTextSplitter(chunk_size=child_chunk_size, chunk_overlap=chunk_overlap)
child_chunks = []
for i ,doc in enumerate(documents):
file_extension = os.path.splitext(doc.metadata.get('file_path',''))[1].lower()
is_markdown = (file_extension=='.md')
parent_splitter_to_use=markdown_parent_splitter if is_markdown else parent_splitter
logger.info(f'处理文档_父:{parent_splitter_to_use}')
#4.2.2 选择子块切分
child_splitter_to_use=markdown_child_splitter if is_markdown else child_splitter
logger.info(f"处理文档_子:{child_splitter_to_use}")
parten_docs=parent_splitter_to_use.split_documents([doc])
for j,parent_doc in enumerate(parten_docs):
parent_id = f'doc_{i}_parent_{j}'
parent_doc.metadata['parent_id']= parent_id
parent_doc.metadata['parent_content']=parent_doc.page_content
sub_chunks = child_splitter_to_use.split_documents([parent_doc])
for k,sub_chunk in enumerate(sub_chunks):
sub_chunk.metadata['parent_id']=parent_id
sub_chunk.metadata['parent_content']=parent_doc.page_content
sub_chunk.metadata['id'] = f'{parent_id}_child_{k}'
child_chunks.append(sub_chunk)
logger.info(f'子块数量{len(child_chunks)}')
return child_chunks
if __name__ == '__main__':
document=load_document_from_directory('../data/ai_data')
# print(document)
chunks=process_documents('../data/ai_data')
print(chunks)
3.6.1返回内容
最终返回子文档列表,每个子文档里面的格式和内容如下包含:
父文档的信息,子文档和父文档的关联以及子文档的内容

3.7向量库实现
3.7.1向量分类
- 稀疏向量:one-hot,n-gram,tf-idf
- 稠密向量:word2vec,fasttex
3.7.1.2文本转向量
- BGE-M3嵌入模型:可以把文本转换为稀疏向量和稠密向量
- 为什么选择这个模型?
m3顾名思义三个特点:多语言性,多粒度性,多功能性.
这个模型是2024年我国发布的轻量高效的通用语意向量模型,完全开源.支持超过100多种语言,在多语言检索和跨语言检索方面表现很好.同时支持稠密检索和稀疏检索以及混合检索.支持长文本检索,支持处理短文本到长文本的不同长度的场景.我们考虑了我们数据内部的长文本以及对检索效率的要求,所以选择这个模型
- 向量表中的字段由字块中的字段决定,其中稠密向量要指定维度数(默认:1024).文本长度指定为65535,构建nlist=128个簇
- 下面是构建集合的信息:
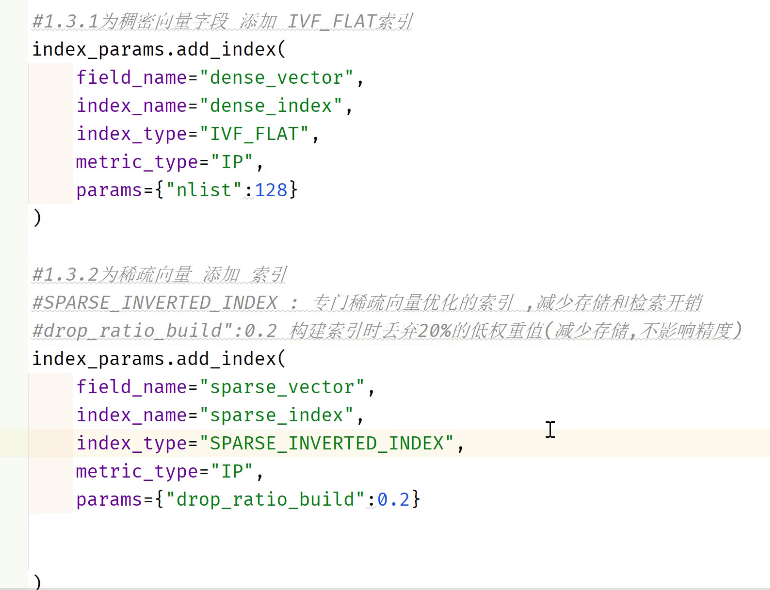
- 集合加载之前只能执行插入操作
3.8稠密向量和稀疏向量的格式
3.9混合检索,重排序
混合检索,用户输入query,把query转换为向量,在子块中匹配相似度前三的子块,返回对应的父块,然后返回对应的前两个父块.
混合检索返回的结果是双层列表,可以返回多个请求的回答,这里[0]表示返回第一个query的回答
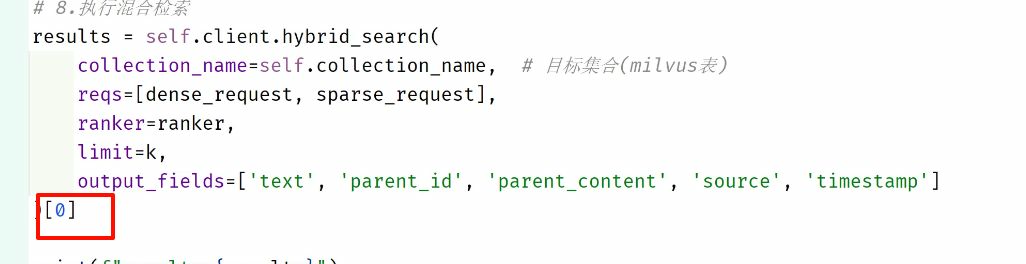
混合检索第一个query返回的内容:

我们这个项目用的是加权排序,稠密向量权重设为1.0,稀疏向量权重设置为0.7.
为什么使用权重重排序?
因为稠密向量重语义匹配,稀疏向量重关键字匹配.我们这个需要精确的结果,所以选择加权排序
3.10代码实现
# 导入 BGE-M3 嵌入函数,用于生成文档和查询的向量表示
import torch.cuda
from milvus_model.hybrid import BGEM3EmbeddingFunction
# 导入 Milvus 相关类,用于操作向量数据库
from pymilvus import MilvusClient, DataType, AnnSearchRequest, WeightedRanker
# 导入 Document 类,用于创建文档对象
from langchain.docstore.document import Document
# 导入 CrossEncoder,用于重排序和 NLI 判断
from sentence_transformers import CrossEncoder
# 导入 hashlib 模块,用于生成唯一 ID 的哈希值
import hashlib
from base.config import Config
from base.logger import logger
from document_processor import process_documents
import sys, os
# todo 1 路径配置
current_dir = os.path.dirname(os.path.abspath(__file__))
# .获取core文件所在绝对路径
rag_qa_path = os.path.dirname(current_dir)
# 把模块路径添加到系统路径
sys.path.insert(0, rag_qa_path)
project_root = os.path.dirname(rag_qa_path)
sys.path.insert(0, project_root)
# todo 2. 初始化全局配置
conf = Config()
# todo 3 定义VectorStore类 :封装向量库的核心功能(集合管理,文档入库,混合检索,结果处理)
class VectorStore:
# 3.1 初始化类方法:配置向量库,加载模型,初始化客户端
def __init__(self, collection_name=conf.MILVUS_COLLECTION_NAME,
host=conf.MILVUS_HOST,
port=conf.MILVUS_PORT,
database=conf.MILVUS_DATABASE_NAME
):
# 1.1 配置milvus核心配置
# 设置milvus集合名称
self.collection_name = collection_name
# 设置milvus主机地址
self.host = host
# 设置milvus端口号
self.port = port
# 设置milvus数据库名字
self.database = database
# 1.2 设置日志记录器
self.logger = logger
# 3.选择模型运行设备 : 优先选择gpu(cuda)加速, 没有gpu则使用cpu
self.device = "cuda" if torch.cuda.is_available() else "cpu"
self.logger.info(f"使用设备:{self.device}")
# 4.初始化bge-reranker 模型 用于重排序检索结果
# 4.1拼接重排序模型本地路径 rag_qa\models\bge-reranker-large
reranker_path = os.path.join(rag_qa_path, "models", "bge-reranker-large")
# 4.2加载模型
self.reranker = CrossEncoder(reranker_path, device=self.device)
# 5.初始化 BGE-M3嵌入函数 使用cpu 将不启用 FP16
# 5.1拼接模型路径(bge-m3)
beg_path = os.path.join(rag_qa_path, "models", "bge-m3")
# 5.2 加载模型
# 参1: 模型本地路径 参2:gpu是启动半精度计算(减少内存占用,提升速度) cpu时禁用 参3:模型运行设备
self.embedding_function = BGEM3EmbeddingFunction(model_name_or_path=beg_path, use_fp16=(self.device == "cuda"),
device=self.device)
# 6.初始化客户端
self.client = MilvusClient(uri=f"http://{self.host}:{self.port}", db_name=self.database)
# 7.获取稠密向量的维度
self.dense_dim = self.embedding_function.dim["dense"] # 1024
# 8.调用方法或者加载milvus集合(类似于:建表,加载数据)
self._create_or_load_collection()
# 3.2 创建或者加载milvus集合
# 作用:定义向量库结构和索引,
def _create_or_load_collection(self):
# 1.判断集合是否存在(避免重复创建)
if not self.client.has_collection(self.collection_name):
# 1.1 定义集合schema(数据结构)
# 参1: 禁止自动生成id
# 参2:允许动态添加未在schame定义字段(灵活拓展)
schema = self.client.create_schema(auto_id=False, _enable_dynamic_field=True)
# 1.2逐个添加字段(字段名,类型,是否为主键,长度)
# id :主键字段
schema.add_field(field_name="id", datatype=DataType.VARCHAR, is_primary=True, max_length=100)
# text 文档内容字段
schema.add_field(field_name="text", datatype=DataType.VARCHAR, max_length=65535)
# dense_vector 稠密向量字段
schema.add_field(field_name="dense_vector", datatype=DataType.FLOAT_VECTOR, dim=self.dense_dim)
# sparse_vector 稀疏向量字段
schema.add_field(field_name="sparse_vector", datatype=DataType.SPARSE_FLOAT_VECTOR)
# parent_id 父文档id
schema.add_field(field_name="parent_id", datatype=DataType.VARCHAR, max_length=100)
# parent_content 父文档内容
schema.add_field(field_name="parent_content", datatype=DataType.VARCHAR, max_length=65535)
# source 学科类别
schema.add_field(field_name="source", datatype=DataType.VARCHAR, max_length=50)
# timestamp 时间戳
schema.add_field(field_name="timestamp", datatype=DataType.VARCHAR, max_length=50)
# 1.3定义索引参数 :为向量字段构建索引,提升检索速度(非向量字段无需索引)
index_params = self.client.prepare_index_params()
# 1.3.1为稠密向量字段 添加 IVF_FLAT索引
index_params.add_index(
field_name="dense_vector",
index_name="dense_index",
index_type="IVF_FLAT",
metric_type="IP",
params={"nlist": 128}
)
# 1.3.2为稀疏向量 添加 索引
# SPARSE_INVERTED_INDEX : 专门稀疏向量优化的索引 ,减少存储和检索开销
# drop_ratio_build":0.2 构建索引时丢弃20%的低权重值(减少存储,不影响精度)
index_params.add_index(
field_name="sparse_vector",
index_name="sparse_index",
index_type="SPARSE_INVERTED_INDEX",
metric_type="IP",
params={"drop_ratio_build": 0.2}
)
# 1.4 创建集合 : 定义结构和索引
self.client.create_collection(
collection_name=self.collection_name,
schema=schema,
index_params=index_params
)
logger.info(f"已创建集合:{self.collection_name}")
else:
logger.info(f"已加载集合:{self.collection_name}")
# 3.将集合加载到内存中. 加载后才能执行查询
self.client.load_collection(self.collection_name)
# 3.3 将文档(子块)转换为向量并存储到milvus中
def add_documents(self, documents):
# 1.提取所有文档的内容列表, 即 从每个文档中提取page_content属性
texts = [doc.page_content for doc in documents] # 文本
# 2.使用BGE-M3模型将文档内容转为向量
# 输入:texts
# 输出: 字典 包含: dense(稠密向量列表) ,sparse(稀疏向量列表) ,ids(文档id列表)
embeddings = self.embedding_function(texts)
# print(f"embeddings:{embeddings}")
# 3.初始化空列表 ,存储插入milvus的数据(每个元素为一条字典)
data = []
# 4.遍历每个文档,组装插入数据 (i:文档索引 doc )
for i, doc in enumerate(documents):
# 4.1生成文本的唯一id ,对文本内容进行MD5哈希 ,避免重复插入
text_hash = hashlib.md5(doc.page_content.encode("utf-8")).hexdigest()
print(f"text_hash:{text_hash}")
# 4.2处理稀疏向量
sparse_vector = {}
# 4.2.1 获取第i个文本的系数向量行(getrow(i))
# embeddings['sparse'].getrow(i) # 旧版写法 会提示大量警告信息
row = embeddings['sparse'][[i]] # 新版写法
# 4.2.2 获取稀疏向量非零值索引
indices = row.indices # 非零值的索引列表 [10,25,50]
values = row.data # 非零值的权重列表 [0.1,0.2,0.3]
# 4.2.3 组装稀疏向量字段 将索引与权重配对 即: {索引:权重}
for idx, value in zip(indices, values):
sparse_vector[idx] = value # {索引:权重} {10:0.1 , 25:0.2...}
# 4.3 组装单条插入数据(字段要与schema一致)
data.append(
{
"id": text_hash,
"text": doc.page_content,
"dense_vector": embeddings["dense"][i],
"sparse_vector": sparse_vector,
"parent_id": doc.metadata["parent_id"],
"parent_content": doc.metadata['parent_content'],
"source": doc.metadata.get("source", "unknown"),
"timestamp": doc.metadata.get("timestamp", "unknown")
}
)
# 5. 插入数据到milvus数据库中
if data:
self.client.upsert(self.collection_name, data)
logger.info(f"已插入{len(data)}条数据到集合{self.collection_name}")
# 3.4 混合(稠密+稀疏)检索+结果重排序+返回精准父文档
def hybrid_search_with_rerank(self, query, k=conf.RETRIEVAL_K, source_filter=None):
"""
该函数用于执行混合检索(稠密+稀疏向量)结果重排序+返回精准父文档
:param query: 用户查询文本 例如: AI学科课程内容是什么?
:param k: 混合检索反馈top-K 子块数量 默认从conf读取
:param source_filter: 学科过滤条件 例如: "AI" ->仅检索该学科的文档
:return: 重排序后的top-K父文档列表
"""
# 1.生成查询文本嵌入向量 beg-m3 根据用户的提问获取稠密向量和稀疏向量
query_embedding = self.embedding_function([query])
# 2.获取稠密向量
dense_query_vector = query_embedding['dense'][0]
# 3.处理稀疏向量 {key:value}
sparse_query_vector = {}
# 3.1获取查询稀疏向量行
row = query_embedding['sparse'][[0]]
# 3.2获取非零值索引和权重
indices = row.indices # 索引列表
values = row.data # 权重列表
# 3.3组装稀疏向量字段 : 将索引与权重匹配 即:{索引:权重}
for idx, value in zip(indices, values):
sparse_query_vector[idx] = value
# 4.构建检索过滤表达式 按学科过滤
filter_expr = f"source == '{source_filter}'" if source_filter else ""
# 5.构建稠密向量检索请求: 定义稠密向量检索参数
dense_request = AnnSearchRequest(
data=[dense_query_vector], # 查询向量(列表)
anns_field="dense_vector",
param={"metric_type": "IP", "params": {"nprobe": 10}},
limit=k, # 检索top-k子块数量
expr=filter_expr, # 应用过滤表达式(按学科进行过滤) 要么空 要么学科名 "" 或者 source =='ai'
)
# 6.构建稀疏向量检索请求:定义稀疏向量检索参数
sparse_request = AnnSearchRequest(
data=[sparse_query_vector], # 查询向量(列表)
anns_field="sparse_vector",
param={"metric_type": "IP", "params": {}},
limit=k, # 检索top-k子块数量
expr=filter_expr, # 应用过滤表达式(按学科进行过滤) 要么空 要么学科名 "" 或者 source =='ai'
)
# 7.创建加权排序器
# 参1:周密向量权重(1.0) 参2:稀疏向量权重(0.7)
ranker = WeightedRanker(1.0, 0.7) # 稠密向量侧重:语义相似度 稀疏向量侧重于:关键词匹配
# 8.执行混合检索
results = self.client.hybrid_search(
collection_name=self.collection_name, # 目标集合(milvus表)
reqs=[dense_request, sparse_request],
ranker=ranker,
limit=k,
output_fields=['text', 'parent_id', 'parent_content', 'source', 'timestamp']
)[0]
# print(f"results:{results}")
# print(f"results:{type(results)}")
# print(f"results:{len(results)}")
# 9. 将检索结果转换为document对象列表 目的:统一格式 ,方便后续的管理
sub_chunks = [self._doc_from_hit(hit['entity']) for hit in results]
# 10. 从子块中提取去重的父文档 : 避免同一个父块的多个子块重复返回
parent_docs = self._get_unique_parent_docs(sub_chunks)
# print(f"parent_docs:{parent_docs}") # [document对象 ,document对象 ,document对象 ....]
# 11. 重排序逻辑:父文档<2 时 跳过重排序(无需优化) 直接返回
if len(parent_docs) < 2:
return parent_docs[:conf.CANDIDATE_M]
# 12. 父文档数量>=2 执行重排序
if parent_docs:
# 12.1 构建查询-文档 配对列表
pairs = [[query, doc.page_content] for doc in parent_docs]
# 12.2计算相关系得分 得分越高,相关性越强
scores = self.reranker.predict(pairs)
# 12.3 按得分进行降序排序
ranked_parent_docs = [doc for _, doc in sorted(zip(scores, parent_docs), reverse=True)]
else:
# 若父文档为空(无检索结果),返回空列表
ranked_parent_docs = []
# 13. 返回重排序后的M个文档
return ranked_parent_docs[:conf.CANDIDATE_M]
# 3.5 从子块列表中提取去重的父块
def _get_unique_parent_docs(self, sub_chunks):
# 初始化集合 用于存储已处理的父块内容(去重)
parent_contents = set()
# 初始化列表 用于存储唯一父文档
unique_docs = []
# 遍历所有子块
for chunk in sub_chunks:
# 获取子块的父块内容
parent_content = chunk.metadata.get("parent_content", chunk.page_content)
if parent_content and parent_content not in parent_contents:
# 创建新的document对象 ,包含父块内容和元数据
unique_docs.append(Document(page_content=parent_content, metadata=chunk.metadata))
# 将父块内容添加到去重集合
parent_contents.add(parent_content)
return unique_docs
# 3.6 将milvus检索结果转换为langchain的document对象
def _doc_from_hit(self, hit):
return Document(
page_content=hit.get("text"),
metadata={
"parent_id": hit.get("parent_id"),
"parent_content": hit.get("parent_content"),
"source": hit.get("source"),
"timestamp": hit.get("timestamp")
}
)
if __name__ == '__main__':
vector_store = VectorStore()
# documents = process_documents("../data/ai_data")
# vector_store.add_documents(documents)
query = "AI学科的课程内容是什么?"
result = vector_store.hybrid_search_with_rerank(query, source_filter="ai")
print(f"result:{result}")
print(f"result:{len(result)}")
第四章书写提示词与模型微调
4.1提示词优化策略
- 详细描述项目需求
- 让模型充当某个角色
- 使用分隔符表明输入的不同部分
- 对任务制定步骤,尽量避免一步完成
- 提供例子
4.2提示词代码实现
这个提示词是通过llm根据不同的检索方法改变用户的query
- hyde检索:假设一个回答,根据这个回答在milvus里混合检索
- 子查询检索:把query分成多个子问题列表,根据子问题取milvus多次混合检索,然后去重(遍历文档内容去重)(字典的键有唯一性).
- 回溯检索:简化问题,使用简化的问题取milvus里面混合检索
- 直接检索:只用用原query在milvus里面混合检索
"""
当前脚本功能 :
统一管理rag(检索增强生成) 流程中所需要各种提示词模板.
作用:通过langchain的promptTemplate类 ,将不同的场景的提示词模板(回答生成,查询分解)
"""
# 导包
from langchain.prompts import PromptTemplate
# todo 1 定义提示词类: 集中存放rag相关提示词模板,方便统一管理
class RAGPrompts:
# todo 1.1 基础rag回答 :根据上下文生成答案,无上下文则用自身支持,无法回答时,返回客服信息
@staticmethod
def rag_prompt():
"""
创建基础rag回答模版
核心逻辑: 优先基于传入的context生成答案,无上下文则用自身支持,无法回答时,返回客服信息
:param self:
:return: 提示词模板对象
"""
return PromptTemplate(
template="""
你是一个智能助手,帮助用户回答问题.
1.如果提供了上下文,请基于上下文回答;
2.如果没有上下文,请直接根据你的知识进行回答;
3.如果答案来源于检索文档,请在根据生成的内容进行说明.
上下文:{context},
问题:{question},
如果无法回答,请提示"信息不足,无法回答",请与人工客服联系,电话:{phone}
""",
# 定义模板所需要输入变量
input_variables=["context", "question", "phone"]
)
# todo 1.2 hyDe检索
@staticmethod
def heyd_prompt():
return PromptTemplate(
template="""
假设你是用户,想了解以下问题,请生成一个简短的假设答案:
问题:{query}
假设答案:
"""
,
input_variables=["query"],
)
# 定义子查询生成的 Prompt 模板
@staticmethod
def subquery_prompt():
# 创建并返回 PromptTemplate 对象
return PromptTemplate(
template="""
将以下复杂查询分解为多个简单子查询,每行一个子查询:
查询: {query}
子查询:
""",
# 定义输入变量
input_variables=["query"],
)
# 定义回溯问题生成的 Prompt 模板
@staticmethod
def backtracking_prompt():
# 创建并返回 PromptTemplate 对象
return PromptTemplate(
template="""
将以下复杂查询简化为一个更简单的问题:
查询: {query}
简化问题:
""",
# 定义输入变量
input_variables=["query"],
)
# todo 6 测试方法
if __name__ == '__main__':
heyd_prompt = RAGPrompts.heyd_prompt()
result2 = heyd_prompt.format(
query="怎么学习"
)
print(f"result2:{result2}")
4.3模型微调(意图识别)
4.3.1模型微调数据
- 基于bert_base_chinese,我们利用5000条混合数据集(80%训练集,20%验证集)进行训练,训练三轮,500条训练十分钟左右
- 数据的格式:内容,标签(通用知识,专业知识),标签用数字替代
4.3.2模型微调
- bert_base_chinese介绍
有12个隐层,输出768维张量,12个注意力头,1亿左右的参数,在简体和繁体中文文本上训练得到的
使用bert_base_chinese模型,微调二分类任务.使用训练数据训练模型精确率达到80%
- 微调策略
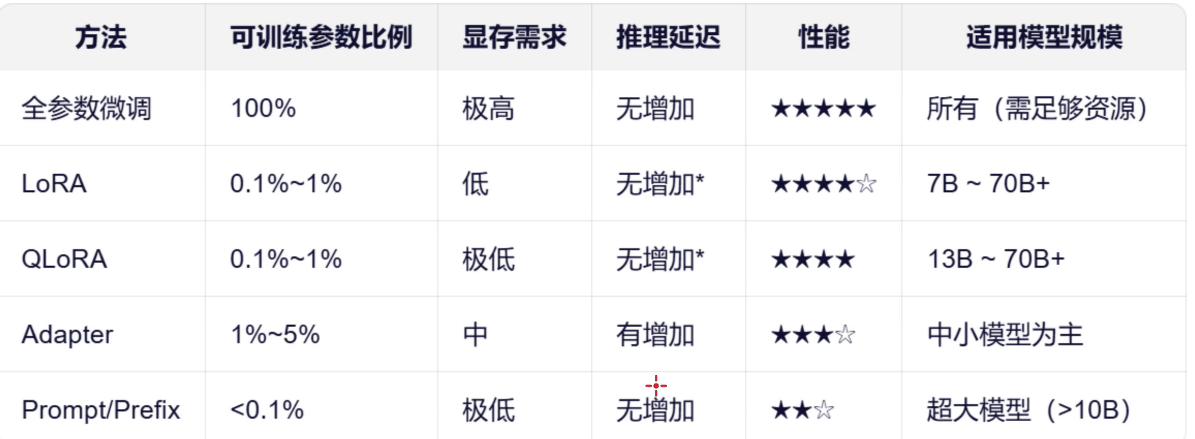
- 微调调哪些参数?
轮次:3 批次大小:8 权重衰减系数0.01 每轮训练结束后验证一次 加载训练效果最好的模型 指定验证集损失最小作为评估标准
4.3.3模型训练
我们用的是huggingface的transformers库中的trainer和trainargument训练模型.简化了训练流程,无需手写循环,梯度更新,分布式训练等底层逻辑.
- trainargument配置模型训练需要的超参数和参数
- trainer:训练接口,包装了训练,预测,评估流程
4.3.4意图识别模型微调代码实现
# 导入标准库
import json
import os
# 导入 PyTorch
import torch
# 导入日志
from base.logger import logger
# 导入numpy
import numpy as np
# 导入 Transformers 库
from transformers import BertTokenizer, BertForSequenceClassification
from transformers import Trainer, TrainingArguments
# 导入train_test_split
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report, confusion_matrix
import os, sys
# todo 1 路径配置
current_dir = os.path.dirname(os.path.abspath(__file__))
# .获取core文件所在绝对路径
rag_qa_path = os.path.dirname(current_dir)
# 把模块路径添加到系统路径
sys.path.insert(0, rag_qa_path)
project_root = os.path.dirname(rag_qa_path)
sys.path.insert(0, project_root)
# todo 1 定义QueryClassifier类 封装bert查询分类的完整流程(模型加载,数据处理,模型训练,评估,预测)
class QueryClassifier:
# 1.1 初始化方法:配置模型路径,记载分词器 , 选择设备 ,定义标签映射
def __init__(self, model_path="../models/bert_query_classifier"):
# 1.存储模型路径
self.model_path = model_path
# 2.加载bert分词器, 我爱编程,将文本转成模型可识别的tokenid
# 2.1 拼接预训练模型本地路径
bert_path = os.path.join(rag_qa_path, 'models', 'bert-base-chinese')
# 2.2 加载分词器
self.tokenizer = BertTokenizer.from_pretrained(bert_path)
# 3.初始化模型变量
self.model = None
# 4.选择模型运行设备,优先使用GPU 如果没有GPU 使用cpu
self.device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 5.定义标签映射 将文本标签转为数字,便于模型训练
self.label_map = {"通用知识": 0, "专业咨询": 1}
# 6.日志记录模型运行信息
logger.info(f"模型运行设备:{self.device}")
# 7.加载模型:初始化时,自动调用load_model(),确保模型可用
self.load_model()
# 1.2 加载模型方法,从指定路径加载已训练好的模型,若不存在,则初始化新模型
def load_model(self):
# 1 判断模型路径是否存在(即:是否有已经训练好的模型)
if os.path.exists(self.model_path): # ..models/bert_query_classifier
# 1.加载已训练好的模型
self.model = BertForSequenceClassification.from_pretrained(self.model_path)
# 2.将模型移动到指定设备
self.model.to(self.device)
# 3.日志记录模型加载成功
logger.info(f"模型加载成功:{self.model_path}")
# 2.若模型不存在,初始化新模型
else:
# 2.1基于bert_base_chinese 创建分类器
self.model = BertForSequenceClassification.from_pretrained("../models/bert-base-chinese",
num_labels=len(self.label_map))
# 2.2.将模型移动到指定设备
self.model.to(self.device)
# 3.日志记录模型加载成功
logger.info(f'模型加载成功:{"初始化新bert模型!!!"}')
# 1.3 保存模型
def save_model(self):
# 保存模型和分词器到指定目录 ,便于后续加载使用
self.model.save_pretrained(self.model_path)
self.tokenizer.save_pretrained(self.model_path)
logger.info(f"模型保存成功:{self.model_path}")
# 1.4 数据预处理
def preprocess_data(self, texts, labels):
"""
对文本进行分词,截断,填充
对标签转换为数字
:param texts:
:param labels:
:return:
"""
# 1.文本编码
encodings = self.tokenizer(texts, truncation=True, padding="max_length", max_length=128,
return_tensors="pt") # pytorch张量
# 2.标签转换
labels = [self.label_map[label] for label in labels]
# .3返回结果
return encodings, labels
# 1.5 创建(符合模型要求的)数据集
def create_dataset(self, encodings, labels):
# 1.定义内部类dataset类
class DataSet(torch.utils.data.Dataset):
def __init__(self, encodings, labels):
super().__init__()
# 文本编码 问题
self.encodings = encodings
# 标签 标签
self.labels = labels
# 返回数据集长度
def __len__(self):
return len(self.labels)
# 获取数据集某个样本
def __getitem__(self, idx):
# 提取第idx条编码数据
item = {key: val[idx] for key, val in self.encodings.items()}
# 添加标签(标签转为张量)
item['labels'] = torch.tensor(self.labels[idx])
return item
return DataSet(encodings, labels)
# 1.6 模型训练方法 : 加载数据集 数据预处理 配置训练参数并且训练模型
# 预训练模型 bert-base-chinese 给数据model_generic_5000.json 微调: bert_query_classifier
def train_model(self, data_file="../classify_data/model_generic_5000.json"):
# 1.检查数据集文件是否存在
if not os.path.exists(data_file):
logger.error(f"数据集文件{data_file}不存在")
raise FileNotFoundError(f"数据集文件{data_file}不存在!")
# 2.加载数据集 从json文件读取 文本 和 标签
with open(data_file, "r", encoding="utf-8") as f:
# 按行解释json数据 ,每行一个样本
data = [json.loads(value) for value in f.readlines()]
# 3.提取文本和标签
texts = [item['query'] for item in data]
labels = [item['label'] for item in data]
# 4.划分训练集和测试集 8:2
train_texts, val_texts, train_lables, val_labels = train_test_split(texts, labels, test_size=0.2,
random_state=18)
# 5.数据预处理
train_encodings, train_labels = self.preprocess_data(train_texts, train_lables) # 训练集
val_encodings, val_labels = self.preprocess_data(val_texts, val_labels)
# 6.创建数据集对象
train_dataset = self.create_dataset(train_encodings, train_labels)
val_dataset = self.create_dataset(val_encodings, val_labels)
# 7.配置训练参数 :定义模型训练超参
training_args = TrainingArguments(
output_dir="./bert_results", # 模型预测结果与检查点的保存目录
num_train_epochs=3, # 训练轮数
per_device_train_batch_size=8, # 训练(每个设备的)批次大小
per_device_eval_batch_size=8, # 验证(每个设备)批次大小
warmup_steps=20, # 学习率预热部署(逐步提升学习率,避免初期震荡)
weight_decay=0.01, # 权重衰减系数,防止过拟合
logging_dir="./bert_logs", # 日志保存路径
logging_steps=10, # 每个多少步保存一次日志
eval_strategy="epoch", # 每轮训练结束后进行验证
save_strategy="epoch", # 每轮训练结束后,保存模型的检查点
load_best_model_at_end=True, # 训练结果后加载验证集表现最好的模型
save_total_limit=1, # 只保存一个检查点,即:最优模型的 ->节省存储空间
metric_for_best_model="eval_loss", # 以验证集的损失作为最优模型的评判标准
fp16=False, # 禁用混合精度
)
# 8.初始化trainer :封装模型 ,训练参数
trainer = Trainer(
model=self.model, # 要被训练(微调)模型
args=training_args, # 训练参数
train_dataset=train_dataset, # 训练数据集
eval_dataset=val_dataset, # 验证数据集
compute_metrics=self.compute_metrics # 自定义评估指标
)
# # 9.开始模型训练并且记录日志 注意评估的时候需要注释掉
logger.info("开始训练(bert)模型")
trainer.train()
# 10.保存训练好的模型
self.save_model()
# 11.用测试集评估模型性能->帮助我们判断模型好不好用
self.evaluate_model(val_texts, val_labels)
# 1.7 评估指标:准确率
def compute_metrics(self, eval_pred):
"""
计算评估指标
:param eval_pred:
:return:
"""
logist, lalels = eval_pred
predictions = np.argmax(logist, axis=-1)
accuracy = (predictions == lalels).mean()
return {"accuracy": accuracy}
# 1.8 评估模型:用验证集评估模型性能
def evaluate_model(self, texts, labels):
"""
评估模型再指定文本和标签 输出分类报告(准确率,召回率等指标)和混淆矩阵
:param texts:待评估的文本列表(需要预测的输入文本)
:param labels:文本对应的真实标签(已经转为数字形式) 0 :通用知识, 1:专业咨询
:return: 无,评估结果通过日志输出
"""
# 1.文本编码,对输入的文本进行分词,截断,填充
encodings = self.tokenizer(texts, truncation=True, padding="max_length", max_length=128, return_tensors="pt")
# 2.创建验证集数据
dataset = self.create_dataset(encodings, labels)
# 3.初始化模型 :仅传入模型(评估阶段无需训练参数)
trainer = Trainer(model=self.model)
# 4.执行预测,让模型对整个数据集对象预测,得到所有样本预测结果
predictions = trainer.predict(dataset)
# 5.提取预测标签,模型输出是每个类别的可能性分数 [0.8,0.2] -> 0 通用知识 [0.3,0.7] 1专业咨询
pred_labels = np.argmax(predictions.predictions, axis=-1)
# 6.定义真实标签:直接使用输入的labels作为"标准答案" 和模型预测的结果对比
true_labels = labels
# 7.输出分类报告
logger.info("分类报告:")
logger.info(classification_report(
true_labels, # 标准答案
pred_labels, # 模型预测的标签
target_names=["通用知识", "专业咨询"] # 把数字转换为中文名称, 方便阅读
))
# 8.输出混淆矩阵
logger.info("混淆矩阵:")
logger.info(confusion_matrix(true_labels, pred_labels))
# 1.9 预测类别的方法 ->用户输入查询的文本,用训练好的模型判断它属于"通用知识"还是"专业咨询"
def predict_category(self, query):
"""
用训练好的模型对单个用户查询进行分类,判断它属于"通用知识"还是"专业咨询"
:param query: 用户输入的查询文本 例如: 什么是AI? 我的保险是如何理赔的?
:return: 意图识别的分类结果, 要么是"通用知识" 要么是"专业咨询"
"""
# 1.检查模型是否加载
if self.model is None:
# 1.1模型未加载 记录错误
logger.error("模型未训练或者未加载")
# 1.2 默认返回通用知识 (llm)
return "通用知识"
# 2.对查询进行编码 ,把用户输入的文本转换为模型能看懂格式
encoding = self.tokenizer(query, truncation=True, padding="max_length", max_length=128, return_tensors="pt")
# 3. 将编码移动到指定设备
encoding = {k: v.to(self.device) for k, v in encoding.items()}
# 4.开始预测(不需要计算梯度,进行预测)
with torch.no_grad():
# 获取模型输出
outputs = self.model(**encoding) # [0.8,0.2]
# 获取预测结果
prediction = torch.argmax(outputs.logits, dim=1).item()
# 5.根据预测结果返回类别
return "专业咨询" if prediction == 1 else "通用知识"
if __name__ == '__main__':
query_classifier = QueryClassifier()
# 2.训练模型
data_file = "../classify_data/model_generic_5000.json"
query_classifier.train_model(data_file)
# 3. 预测类别
# result=query_classifier.predict_category("数据库三大范式是什么")
result = query_classifier.predict_category("什么是“DevOps”文化?")
# AI学科的最新课程安排是什么时候?
print(result)
4.4策略选择
4.4.1原理
和大语言模型使用提示词交互,大语言模型返回检索策略字符串
4.4.2策略选择代码实现
这里的提示词是为了帮助llm选择不同的检索策略
# 导入 LangChain 提示模板
from langchain.prompts import PromptTemplate
# 导入日志和配置
from base.config import Config
from base.logger import logger
# 导入 OpenAI
from openai import OpenAI # 调用大语言模型的API(对接DashScope )
# todo 1 定义StrategySelector 类: 根据用户查询选择最合适的检索增强策略.
class StrategySelector:
# 3.1 初始化方法 : 创建大模型客户端(open ai) 加载策略选择的提示词模板
def __init__(self):
# 1.创建大模型客户端 key url
self.client = OpenAI(api_key=Config().LLM_DASHSCOPE_API_KEY, base_url=Config().LLM_DASHSCOPE_BASE_URL)
# 2.获取策略选择的提示词模板(定义好的问题格式,用于引导大模型选择策略)
self.strategy_prompt_template = self._get_strategy_prompt()
# 3.2 获取策略选择提示词模板方法:定义引导大模型选择策略的固定文本格式(模板)
def _get_strategy_prompt(self):
# 定义私有方法,获取策略选择 Prompt 模板
return PromptTemplate(
template="""
你是一个智能助手,负责分析用户查询 {query},并从以下四种检索增强策略中选择一个最适合的策略,直接返回策略名称,不需要解释过程。
以下是几种检索增强策略及其适用场景:
1. **直接检索:**
* 描述:对用户查询直接进行检索,不进行任何增强处理。
* 适用场景:适用于查询意图明确,需要从知识库中检索**特定信息**的问题,例如:
* 示例:
* 查询:AI 学科学费是多少?
* 策略:直接检索
* 查询:JAVA的课程大纲是什么?
* 策略:直接检索
2. **假设问题检索(HyDE):**
* 描述:使用 LLM 生成一个假设的答案,然后基于假设答案进行检索。
* 适用场景:适用于查询较为抽象,直接检索效果不佳的问题,例如:
* 示例:
* 查询:人工智能在教育领域的应用有哪些?
* 策略:假设问题检索
3. **子查询检索:**
* 描述:将复杂的用户查询拆分为多个简单的子查询,分别检索并合并结果。
* 适用场景:适用于查询涉及多个实体或方面,需要分别检索不同信息的问题,例如:
* 示例:
* 查询:比较 Milvus 和 Zilliz Cloud 的优缺点。
* 策略:子查询检索
4. **回溯问题检索:**
* 描述:将复杂的用户查询转化为更基础、更易于检索的问题,然后进行检索。
* 适用场景:适用于查询较为复杂,需要简化后才能有效检索的问题,例如:
* 示例:
* 查询:我有一个包含 100 亿条记录的数据集,想把它存储到 Milvus 中进行查询。可以吗?
* 策略:回溯问题检索
根据用户查询 {query},直接返回最适合的策略名称,例如 "直接检索"。不要输出任何分析过程或其他内容。
"""
,
input_variables=["query"],
)
# 3.3调用大模型API的方法:向dashscope发送请求.获取大模型选择策略的[名称](直接索引....)
def call_dashscope(self, prompt):
"""
调用DashScope大模型API ,获取模型对输入提示的响应
:param prompt: 发送给大模型的提示词模板,包含用户请求和任务要求
:return:大模型返回的文本结构 即:检索策略名称
"""
try:
# 1.发送聊天请求: 调用大模型 传入模型名称,对话内容和温度参数
completion = self.client.chat.completions.create(
model=Config().LLM_MODEL, # 模型名称
messages=[
{"role": "system", "content": "你是一个有用的助手"},
{"role": "user", "content": prompt} # 用户提示:包含具体的任务(即:选择检索策略)
],
temperature=0.1
)
# 2.提取并返回模型的回答:
return completion.choices[0].message.content if completion.choices else "直接检索"
except Exception as e:
# 3.异常处理 :若api调用失败(欠费了,网络原因,密钥错误....) 记录错误日志并返回默认策略
logger.error(f"DashScope API调用失败:{e}")
return "直接检索" # "保底"策略
# 3.4 选择检索策略的核心方法: 整合模板和大模型调用 ,返回最终策略
def select_strategy(self, query):
"""
根据用户查询,选择最合适的检索增强策略.
:param query: 用户输入的查询文本 例如"什么是AI?"
:return: 字符串 .选中的检索策略名称 : 例如 直接检索 ,子查询检索,hyde检索,回溯检索...
"""
# 1.格式化提示词模板
prompt = self.strategy_prompt_template.format(query=query)
# print(f"整合后的效果:{prompt}")
# 2.调用llm获取检索策略:将格式化的提示发个大模型.获取返回策略
strategy = self.call_dashscope(prompt).strip()
logger.info(f"为查询:{query} 选择的检索策略是:{strategy}")
return strategy
if __name__ == '__main__':
ss = StrategySelector()
# ss.select_strategy(query="什么是AI?")
ss.select_strategy(query="Mysql数据库能不能支持100w样本插入?")
第五章实现RAG系统
5.1无法回答生成
通用大模型和rag系统都会存在检索不到答案的情况.
在rag系统中,可能query查询的问题类别不属于rag系统中的类别或者用户问的问题太新,这时候llm无法检索到文档组成上下文,可能导致llm无法生成答案
通用llm也会存在类似问题,解决方法是返回客服联系方式,咨询客服获取解答
5.2milvus检索
确定了检索方案后,使用检索方案处理原始query.然后使用混合检索去milvus里面检索得到上下文,然后结合query传给llm生成答案.
5.3代码实现
# todo 1导包
import os, sys
import time
from rag_qa.core.prompts import RAGPrompts # 导入rag相关提示词模板
from rag_qa.core.query_classifier import QueryClassifier # 导入查询分类器
from rag_qa.core.strategy_selector import StrategySelector # 导入策略选择器
from rag_qa.core.vector_store import VectorStore # 导入向量数据库(用于存储和检索向量文档)
from base.config import Config # 加载配置文件
from base.logger import logger # 加载日志
# todo 1 路径配置
current_dir = os.path.dirname(os.path.abspath(__file__))
# .获取core文件所在绝对路径
rag_qa_path = os.path.dirname(current_dir)
# 把模块路径添加到系统路径
sys.path.insert(0, rag_qa_path)
project_root = os.path.dirname(rag_qa_path)
sys.path.insert(0, project_root)
conf = Config()
# todo 2. 定义RAGSystem类:封装RAG系统所需的核心组件(向量库,大模型,分类器....)
class RAGSystem:
# 2.1初始化方法:创建rag系统所需核心组件
def __init__(self, vector_store, llm):
"""
初始化rag系统
:param vector_store: 向量数据库对象(用于存储和检索文档向量,提供相似性搜索功能)
:param llm:大语言模型调用函数(接收提示词模板,返回模型生成答案)
"""
# 1.设置向量数据库对象:用于后续检索相关文档
self.vector_store = vector_store
# 2.设置大语言模型调用函数 :用于生成答案,检索策略选择
self.llm = llm
# 3.获取rag提示词模板:定义生成答案是固定的格式
self.rag_prompt = RAGPrompts.rag_prompt()
# 4. 获取查询分类器(意图识别模型)
# 4.1获取分类器路径
classifier_path = os.path.join(rag_qa_path, "models", 'bert_query_classifier')
# 4.2创建分类器对象
self.query_classifier = QueryClassifier(model_path=classifier_path)
# 5.初始化策略选择器:用于根据用户查询选择最适合的检索策略
self.strategy_selector = StrategySelector()
# 2.2 定义方法,使用假设文档进行检索(HyDE)(生成假设答案,用假设答案检索相关的文档)
def _retrieve_with_hyde(self, query, source_filter):
"""
使用hyde策略检索文档(生成假设答案,用假设答案检索相关的文档)->解决抽象问题检索,匹配度低的问题
:param query: 用户的原始查询文本,通常是抽象查询 - > "人工智能在教育领域应用方向有哪些?"
:param source_filter: 检索来源过滤条件 例如: ai -> 表示只检查和ai学科相关的文档
:return: list [document] 每个docment对象包含:page_content(文档内容),是后续生成答案来源.
"""
# 1.获取假设答案生成提示词模板:
logger.info(f"适用hyde策略进行检索,查询信息为:{query}")
hyde_prompt_template = RAGPrompts.hyde_prompt()
try:
# 2.使用大模型模型生成假设答案 : 用户模版格式化原始查询,输入LLM生成假设答案
hyde_answer = self.llm(hyde_prompt_template.format(query=query)).strip()
logger.info(f"生成的假设答案为:{hyde_answer}")
# 3.用假设的答案调用向量数据库检索 调用混合检索 ,获取相关的文档
docs = self.vector_store.hybrid_search_with_rerank(
query=hyde_answer,
k=conf.RETRIEVAL_K,
source_filter=source_filter
)
# 4.返回文档
return docs
# 5.异常处理
except Exception as e:
logger.error(f"HyDE策略执行失败:{e}")
return []
# 2.3 定义方法,使用子查询进行检索(将复杂查询拆分为多个子查询,分别检索后合并去重)
def _retrieve_with_subqueries(self, query, source_filter):
"""
针对涉及多个实体/多方面的复杂查询,拆分为多个简单子查询->分别检索合并去重
:param query:用户的原始查询文本,通常是逻辑复杂或者包含场景的问题->例如: 我有一个包含100亿数据集,我想把他存储到milvus中进行查询 ? 可以吗?
:param source_filter:检索来源过滤条件 例如: ai -> 表示只检查和ai学科相关的文档
:return:list [document] 每个docment对象包含:page_content(文档内容),是后续生成答案来源.
"""
# 1.获取子查询生成提示词模板:拆分复杂查询为多个子查询
logger.info(f"使用子查询策略进行检索,查询信息为:{query}")
subquery_prompt_template = RAGPrompts.subquery_prompt()
try:
# 2.调用大语言模型生成子查询: 用户模型格式化原数查询,传入llm生成子查询
subqueries_text = self.llm(subquery_prompt_template.format(query=query)).strip()
# 3.拆分子查询:根据换行符进行拆分,获取子查询列表
subqueries = [q.strip() for q in subqueries_text.split('\n') if q.strip()]
# 4.检查子查询有效性: 若未生成有效子查询,记录警告返回空列表
if not subqueries:
logger.warning("子查询生成无效,请检查模型生成结果.")
return []
# 5.遍历子查询,分别检索并收集结果
all_docs = [] # 存储所有子查询结果
for sub_q in subqueries:
# 5.1 用子查询去向量数据库进行检索,调用混合检索,获取相关文档
docs = self.vector_store.hybrid_search_with_rerank(
query=sub_q, # 子查询
k=conf.RETRIEVAL_K//2, # #检索数量
source_filter=source_filter
)
# 5.2 添加子查询检索结果总列表中
all_docs.extend(docs)
logger.info(f"子查询:{sub_q},检索结果:{len(docs)} 个文档")
# 6.对所有的检索结果去重:基于文档内容进行去重
unique_docs_dict = {doc.page_content: doc for doc in all_docs} # 用文档内容做键,字典的键具有唯一性
unique_docs = list(unique_docs_dict.values())
logger.info(f"所有的子查询共检索到{len(all_docs)}个文档,去重后剩下{len(unique_docs)}个文档")
# 7.返回去重后的文档列表
return unique_docs
except Exception as e:
# 8:异常处理
logger.error(f"子查询策略执行失败:{e}")
return []
# 2.4定义方法,使用回溯问题进行检索
def _retrieve_with_backtracking(self, query, source_filter):
"""
针对复杂查询,先生成简化"回溯问题",在用回溯的问题检索问题(解决复杂查询直接检索,效果差的问题)
:param query:用户的原始查询文本,通常是复杂的问题
:param source_filter:检索来源过滤条件 例如: ai -> 表示只检查和ai学科相关的文档
:return:list [document] 每个docment对象包含:page_content(文档内容),是后续生成答案来源.
"""
# 1.获取回溯问题的生成提示词模板: 用户模板格式化原数查询,传入llm生成简化问题
logger.info(f"使用回溯问题策略进行检索,查询信息为:{query}")
backtracking_prompt_template = RAGPrompts.backtracking_prompt()
try:
# 2.调用大语言模型生成回溯问题
simplified_query = self.llm(backtracking_prompt_template.format(query=query)).strip()
logger.info(f"生成简化问题为:{simplified_query}")
# 3.用回溯问题调用向量数据库检索.调用混合检索,获取相关文档
return self.vector_store.hybrid_search_with_rerank(
query=simplified_query,
k=conf.RETRIEVAL_K,
source_filter=source_filter
)
except Exception as e:
logger.error(f"回溯问题执行策略失败:{e}")
return []
# 2.5 核心方法: 根据检索策略文档 ,并合并/筛选最终上下文文档
def retrieve_and_merge(self, query, source_filter=None, strategy=None):
"""
定义方法,检索并合并相关文档,即:统一入口 .根据指定策略(自动选择策略)调用对应的检索方法.筛选最终用于生成答案上下文文档
:param query: 用户的原始查询文本
:param source_filter:检索筛选过滤条件
:param strategy: 策略选择器
:return: list[document] ,筛选后的最终上下文文档列表
"""
# 1.未指定策略,自动选择策略:调用策略选择器
if not strategy:
strategy=self.strategy_selector.select_strategy(query) # 获取策略选择结果
# 2.根据策略调用对应检索方法 ,获取候选文档列表
ranked_chunks = [] # 初始化候选文档列表
# 判断策略 ,调用对应检索方法
if strategy == "回溯问题检索":
ranked_chunks = self._retrieve_with_backtracking(query, source_filter)
elif strategy == "子查询检索":
ranked_chunks = self._retrieve_with_subqueries(query, source_filter)
elif strategy == "假设问题检索":
ranked_chunks = self._retrieve_with_hyde(query, source_filter)
else: # 默认直接检索
logger.info(f"使用直接检索策略(查询{query})")
ranked_chunks = self.vector_store.hybrid_search_with_rerank(
query=query,
k=conf.RETRIEVAL_K,
source_filter=source_filter
)
# 3.筛选最终生成上下文文档 ,截取M个文档作为最终上下文文(控制上下文的长度,避免LLM输入超过限制)
logger.info(f"策略:{strategy},检索到{len(ranked_chunks)}个候选文档")
# 只获取前M个文档
final_context_docs = ranked_chunks[:conf.CANDIDATE_M]
# 4.打印日志返回结果
logger.info(f"最终上下文文档:{len(final_context_docs)}个!")
return final_context_docs
# 2.6 核心方法:处理用户查询 ,生成最终的答案(整合分类,检索,生成全部流)
def generate_answer(self, query, source_filter=None):
"""
Rag系统对外核心接口,接收用户查询,自动完成"查询分类->策略选择->文档检索->答案生成'全流程'"
:param query: 用户的原始的查询文本 例如:"地球为什么是圆的?"
:param source_filter: 检索来源过滤条件,仅对"专业咨询"生效,例如:ai(只检索ai学科文档)
:return:最终生成答案
"""
# 1.记录查询开始时间:用于计算整个程序耗时
start_time = time.time()
logger.info(f"开始处理查询:{query},学科过滤:{source_filter}")
# 2.调用查询分类器,判断查询类型(通用知识,专业咨询)
query_category = self.query_classifier.predict_category(query)
logger.info(f"查询分类结果:{query_category}")
# 3.判断 若为"通用知识":直接调用LLM生成答案即可(无需检索文档,既可以处理常识问题)
if query_category == '通用知识':
logger.info("查询为<<通用知识>>,直接调用LLM生成答案")
# 3.1 构建LLM提示:通用知识无需上下文,仅传入问题和客服电话
prompt_input = self.rag_prompt.format(
context="", # 通用知识无需上下文,仅传入问题
question=query, # 问题(用户需要查询问题)
phone=conf.CUSTOMER_SERVICE_PHONE # 配置中的客服电话,用于错误提示
)
try:
# 3.2 调用LLM生成答案
answer = self.llm(prompt_input)
# 3.3 异常处理 : LLM调用失败.返回包含客服电话的错误提示
except Exception as e:
logger.error(f"直接调用LLM失败:{e}")
answer = f"抱歉,处理您的通用问题时错误,请联系人工客服:{conf.CUSTOMER_SERVICE_PHONE}"
# 3.4记录通用知识查询耗时处理结果
processing_time = time.time() - start_time
logger.info(f"处理通用知识查询结果,耗时:{processing_time:.2f}秒,查询内容:{query}")
# 3.5 返回查询结果
return answer
# 4.判断若为"专业咨询" ,执行完整rag_qa流程(策略选择->文档检索->结合上下文生成答案)
logger.info("查询为<<专业咨询>>,执行完整RAG流程")
# 4.1 选择检索策略:调用策略选择器找最合适的检索策略
strategy = self.strategy_selector.select_strategy(query)
# 4.2 检索相关的文档 调用:retrieve_and_merge ,获取最终上下文文档
context_docs = self.retrieve_and_merge(query, source_filter=source_filter, strategy=strategy)
# 4.3 构建上下文文本 :将文档列表中page_content属性拼接为字符串
if context_docs:
context = "\n\n".join([doc.page_content for doc in context_docs])
logger.info(f"最终上下文文档:{len(context_docs)}个,总长度:{len(context)}字")
else:
# 若未检索到文档,上下文为空字符串
context = ''
logger.info(f"未检索到文档,上下文为空字符串")
# 4.4构建LLM:使用拼接后的上下文
prompt_input = self.rag_prompt.format(
context=context, # 上下文,
question=query,
phone=conf.CUSTOMER_SERVICE_PHONE
)
# 4.5 调用LLM生成答案(基于上下文内容)
try:
answer = self.llm(prompt_input)
# 4.6 异常处理
except Exception as e:
logger.error(f"调用llm失败:{e}")
answer = f"抱歉,处理您的专业咨询时出错,请联系人工客服:{conf.CUSTOMER_SERVICE_PHONE}"
# 4.7记录专业咨询查询的处理结果耗时
processing_time = time.time() - start_time
logger.info(f"查询处理完成,耗时:{processing_time:.2f}秒,查询内容为:{query}")
# 5.返回结果
return answer
if __name__ == '__main__':
vector_store=VectorStore()
llm=StrategySelector().call_dashscope
rag_system=RAGSystem(vector_store,llm)
# answer=rag_system.generate_answer(query="地球为什么是圆的?",source_filter="ai")
answer = rag_system.generate_answer(query="饿了吃什么?", source_filter="ai")
print(answer)
第六章rag系统评估
6.1RAgAS评估框架
基于检索部分和生成部分自动评估RAG的效果
6.2评估流程
ragas评估需要四部分:
question:用户输入的问题
answer:模型预测的结果
context:问题关联的上下文
ground_truths:人工标注的真实答案
这里我们准备了30对问答对作为rag系统的评估数据
6.3评估指标
6.3.1检索资料的指标
- 上下文精准度:有用信息占所有信息的比率
- 上下文召回率:有用信息占所有有用信息的比率
6.3.2生成答案的指标
- 忠实度:生成的答案是否符合事实(分数比较低,答案是幻觉答案的可能性较高)
计算公式:能推断出来的数量/总推断数量
- 答案相关性:衍生问题和用户的query的相似度
计算公式:llm根据用户原始问题生成几个衍生问题,然后使用余弦相似度计算每个衍生问题和原始问题的相似度得分,最后计算平均分作为相似度结果.
6.4代码实现
"""
需求: 使用ragas框架对rag系统性能进行量化评估
思路:
1:准备数据
1.1 :加载json文件(包含问题,上下文,答案,真实答案)
1.2 :转换格式转为dataset
2:环境配置
2.1 初始化大模型用于指标推理
2.2 配置嵌入模型计算语义相似度
3:指标选择:
忠实度
答案相关性
上下文相关性
上下文召回率
4:执行评估
5:结果处理
1:保存为csv文件
"""
import pandas as pd # 用于保存csv
from datasets import Dataset
import json
from base.config import Config
# 导入langchain一些包
from langchain_community.chat_models import ChatOpenAI
from langchain_community.embeddings import DashScopeEmbeddings
from langchain_ollama import ChatOllama, OllamaEmbeddings
# 导入ragas评估指标
from ragas.metrics import (
Faithfulness, # 忠实度
AnswerRelevancy, # 答案相关性
context_precision, # 上下文相关性
ContextRecall # 上下文召回率
)
from ragas import evaluate
# 1: 准备数据
# 1.1: 加载json文件(包含问题, 上下文, 答案, 真实答案)
with open("./rag_evaluate_data.json", "r", encoding="utf-8") as f:
# 将json文件内容加载到data变量中 ,data包含多条目录的列表
data = json.load(f)
print(f"加载数据条数:{len(data)}")
# 1.2: 转换格式转为dataset
# 创建字典,eval_data ,将json文件转换为ragas要求字段格式
eval_data = {
# 提取每个数据question字段,组成问题列表
"question": [item['question'] for item in data],
# 提取每个数据answer字段,组成答案列表
"answer": [item['answer'] for item in data],
# 提取每个数据context字段,组成上下文列表
"retrieved_contexts": [item['context'] for item in data],
# 提取每个数据ground_trunth字段,组成真实答案列表
"ground_truth": [item['ground_truth'] for item in data]
}
dataset = Dataset.from_dict(eval_data)
config = Config()
# 2: 环境配置
# 2.1 初始化大模型用于指标推理 (通义千问)
llm = ChatOpenAI(
model_name="qwen-plus",
openai_api_base="https://dashscope.aliyuncs.com/compatible-mode/v1",
openai_api_key=config.LLM_DASHSCOPE_API_KEY,
temperature=0.01
)
# 2.2配置嵌入模型计算语义相似度
embeddings = DashScopeEmbeddings(model="text-embedding-v2", dashscope_api_key=config.LLM_DASHSCOPE_API_KEY)
# 3: 指标选择:
# 忠实度
# 答案相关性
# 上下文相关性
# 上下文召回率
# 4: 执行评估
result = evaluate(
dataset=dataset,
metrics=[
Faithfulness(), # 忠实度
AnswerRelevancy(), # 答案相关性
context_precision, # 上下文相关性
ContextRecall() # 上下文召回率
],
# 指定大模型
llm=llm,
# 指定配置好的嵌入模型
embeddings=embeddings
)
# 5: 结果处理
print(f"ragas评估结果:{result}")
result_df = pd.DataFrame([result])
# 1: 保存为csv文件
result_df.to_csv("ragas_evaluation_result.csv", index=False)

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 79
79 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)