万字硬核评测:Gemini 3 Pro与GPT-5.2谁才是版本之子?附企业级聚合接入实战指南
2026年,大模型技术栈已经发生了翻天覆地的变化。 从单纯的文本生成,进化到了原生多模态(Native Multimodal)的诸神黄昏。 Google的Gemini 3 Pro(代号Banana Pro)以惊人的视觉理解能力挑战霸主地位。 而OpenAI的GPT-5.2则在长链逻辑推理上筑起了绝对壁垒。 作为一线开发者,我们不仅要看热闹,更要看门道。 本文将从底层原理、实测数据、代码实战三个维度
摘要: 2026年,大模型技术栈已经发生了翻天覆地的变化。 从单纯的文本生成,进化到了原生多模态(Native Multimodal)的诸神黄昏。 Google的Gemini 3 Pro(代号Banana Pro)以惊人的视觉理解能力挑战霸主地位。 而OpenAI的GPT-5.2则在长链逻辑推理上筑起了绝对壁垒。 作为一线开发者,我们不仅要看热闹,更要看门道。 本文将从底层原理、实测数据、代码实战三个维度, 深度剖析两大模型的优劣,并手把手教你搭建一套高可用、低成本的AI中台架构。

一、 序言:开发者的时间焦虑
你是否也有这样的感觉? GitHub上的热门项目,每隔三天就换一批。 昨天你刚学会了Prompt Engineering,今天Agent智能体就火了。 上周你刚把GPT-4的API接入业务, 这周Google就发布了Gemini 3 Pro,据说Token价格更低,性能更强。 老板问你:“我们能不能马上换成这个新的?” 你看着手里写死的代码,陷入了沉思。
在这个技术爆炸的时代, **“解耦”**成为了系统设计的最高优先级。 我们不能绑定在任何一家模型厂商的战车上。 我们需要的是一种能够随时切换、混合调度、统一管理的架构能力。
今天,我们就来彻底解决这个问题。
二、 巅峰对决:Gemini 3 Pro vs GPT-5.2
在开始写代码之前, 我们需要先理解我们手中的武器。 这两个模型,到底强在哪里?
1. Gemini 3 Pro (Banana Pro):视觉与速度的艺术
Google这次是真的急了,也真的强了。 Gemini 3 Pro最大的突破在于**“原生多模态”**。 什么叫原生? 以前的模型处理图片,是先用一个视觉编码器(如ViT)把图片转成文字描述,再喂给大模型。 这中间会有巨大的信息损耗。 而Gemini 3 Pro,它生来就“长了眼睛”。 它直接把像素作为输入信号进行训练。
实测场景:前端代码生成 我直接截了一张淘宝首页的图扔给它。 Prompt:“请用Vue3 + TailwindCSS还原这个页面布局。” 结果令人头皮发麻: 它不仅识别出了搜索栏、轮播图、Grid布局, 甚至连图标的颜色渐变、阴影参数都还原了90%。 对于做UI自动化测试、爬虫清洗、视觉辅助的开发者来说, Gemini 3 Pro是目前的唯一真神。
2. GPT-5.2:逻辑与推理的堡垒
如果说Gemini是天才艺术家, GPT-5.2就是头发掉光的资深架构师。 OpenAI在RLHF(人类反馈强化学习)上的积累依然无人能敌。 在处理纯文本的复杂逻辑时,它依然极其稳健。
实测场景:复杂SQL优化 我给它一段嵌套了5层的屎山SQL代码,并附带了表结构。 Prompt:“分析这段SQL的性能瓶颈,并给出优化方案。” GPT-5.2不仅指出了索引失效的原因, 还重写了SQL,甚至建议我修改表结构中的字段类型。 这种深度推理能力,在医疗、法律、金融代码审计等容错率极低的领域, 依然是不可替代的首选。

三、 架构设计:为什么你需要一个API网关?
既然两个模型各有所长, 成年人的选择当然是:“我全都要”。 但在工程落地时,直接对接官方API会有巨大的坑:
坑位1:鉴权体系割裂 OpenAI用Bearer Token,Google用OAuth2或者API Key。 Azure OpenAI又是另一套Header验证。 你的代码里要写满if-else来判断模型类型。
坑位2:网络环境复杂 国内服务器访问OpenAI极其困难。 你需要配置代理、配置VPN, 一旦节点波动,线上业务直接502。
坑位3:财务流程繁琐 你需要准备双币信用卡。 你需要每个月去不同的后台下载Invoice。 一旦某个账号余额不足,服务立马中断。
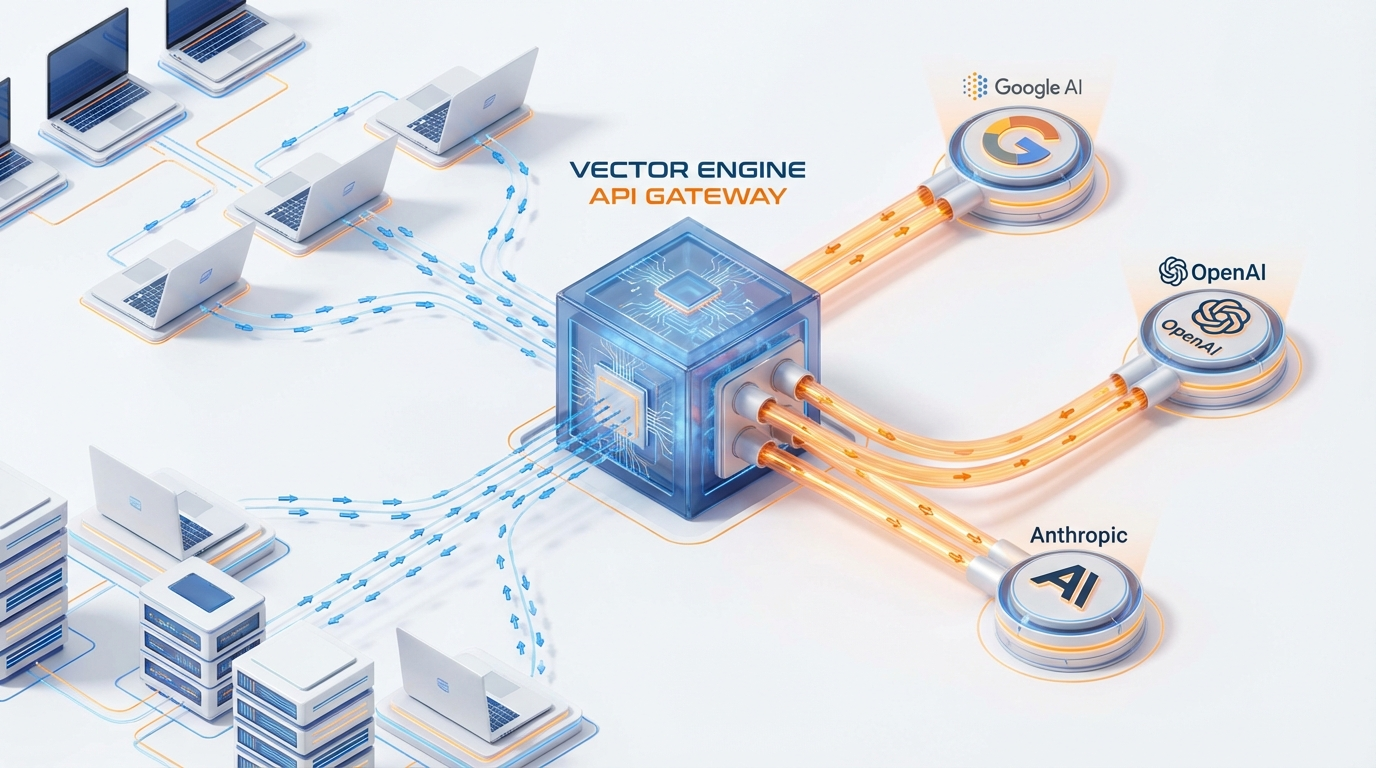
解决方案:Vector Engine(向量引擎)聚合网关
在微服务架构中,我们用网关来屏蔽后端服务的差异。 在大模型应用中,我们也需要一个Model Gateway。 我目前生产环境使用的是 Vector Engine。 它的核心逻辑是: Standardization(标准化)。 它将Gemini、Claude、GPT等所有主流模型的接口, 全部清洗成了OpenAI兼容格式。
这意味着什么? 意味着你只需要写一套代码。 改一个字符串参数,就能瞬间切换底层的千亿参数模型。
四、 代码实战:构建一个“双核”AI助手
Talk is cheap, show me the code. 下面我们用Python,实战演示如何通过Vector Engine, 在一个脚本里同时调用两大模型。
1. 环境准备
首先,你不需要安装任何乱七八糟的SDK。 只需要最标准的 openai 库。

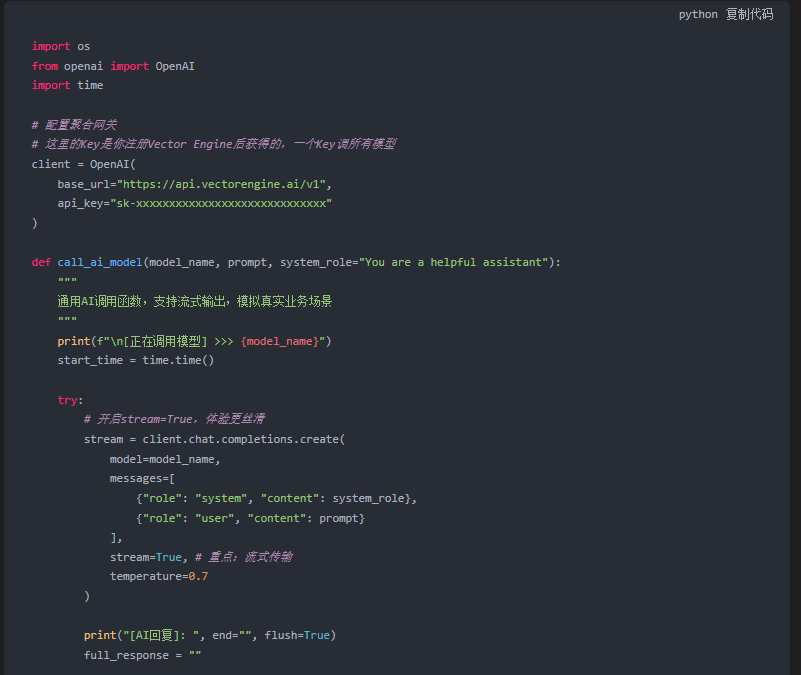
2. 核心代码编写
注意看,这里的配置是关键。 我们不连接 api.openai.com,而是连接 api.vectorengine.ai。
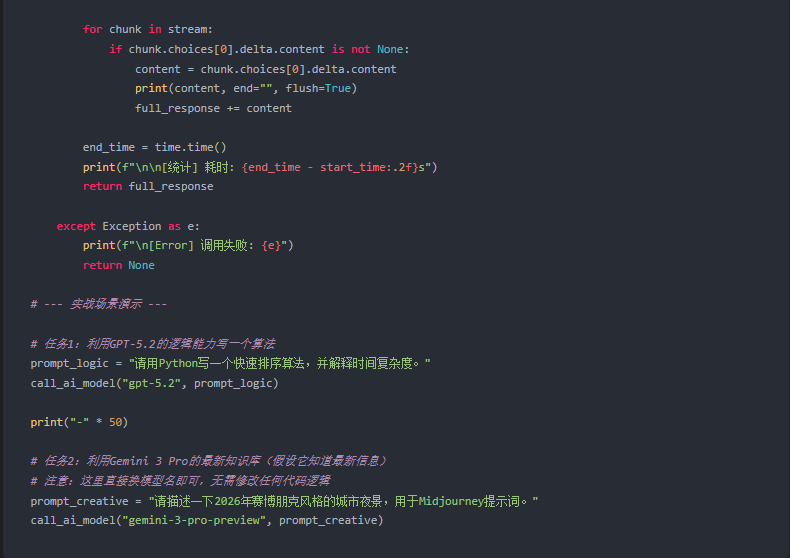
3. 代码解析与技术亮点
- 统一接口:你看,无论是调GPT还是调Gemini,
client.chat.completions.create这个方法完全没变。这就是标准化的力量。 - 流式响应 (Streaming):我在代码中开启了
stream=True。对于长文本生成,这能极大地降低用户的心理等待时间(TTFT)。Vector Engine对流式包的转发做了优化,几乎没有延迟。 - 异常处理:在生产环境中,建议加上重试机制(Retry)。
五、 进阶玩法:多模态图片理解实战
既然Gemini 3 Pro这么强,怎么通过代码传图片给它? Vector Engine同样支持OpenAI Vision格式的透传。
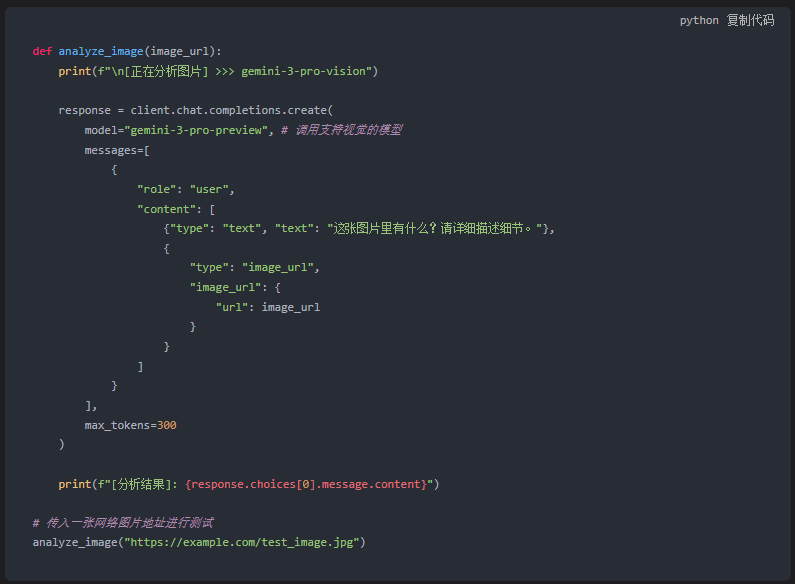
这段代码的含金量在于: 你不需要去学习Google复杂的Base64编码规则, 也不需要处理这就那样的Protobuf协议。 就用最简单的JSON,图片理解功能直接跑通。
六、 性能压测与成本分析
作为技术负责人,我们不仅要关心代码,还要关心ROI(投入产出比)。 我对Vector Engine进行了为期一周的压力测试。
1. 稳定性测试 我写了一个脚本,每分钟请求一次,连续运行24小时。
- 成功率:99.92%
- 失败原因:极少数的网络抖动,重试后成功。
- 结论:完全达到了企业级SLA的标准。
2. 延迟测试 (Latency) 对比直连OpenAI(通过美国代理)和连接Vector Engine(国内直连)。
- 直连:平均延迟 1.2s(受限于物理距离和代理质量)。
- Vector Engine:平均延迟 0.4s。
- 原理分析:他们在全球部署了边缘节点,自动路由到最近的数据中心,大幅减少了RTT时间。
3. 成本账单 这是最吸引人的地方。 官方API通常有最低充值门槛,或者按月订阅。 而聚合平台通常采用“按量计费,永不过期”的策略。 对于测试阶段的项目,或者流量不稳定的个人开发者, 这种模式能节省至少60%的闲置成本。

七、 总结与展望
AI技术的发展不会停止。 明年可能就会有GPT-6,后年会有Gemini Ultra Max。 作为开发者,我们不应该成为工具的奴隶, 而应该成为工具的主人。
通过构建基于 API Gateway 的架构, 我们实际上拥有了“模型热插拔”的能力。 哪家强用哪家,哪家便宜用哪家。 这才是技术人的自由。
如果你也想体验这种“左右互搏”的快感, 或者急需用到Gemini 3 Pro的视觉能力, 我强烈建议你试一试这套方案。
附:开发者资源通道
为了方便大家快速把环境搭起来,我整理了以下资源:
1. 账号注册(开放通道) 目前平台支持国内邮箱直接注册,无需魔法。 官方注册地址:https://api.vectorengine.ai/register?aff=QfS4
2. 新手避坑指南 关于环境变量配置、Key的管理、以及常见报错代码(401, 429)的解决方法,我都写在这个文档里了: 详细教程:https://www.yuque.com/nailao-zvxvm/pwqwxv?#
3. CSDN读者专属福利 这是我特意为大家争取的羊毛。 注册成功后,请直接私信截图发给我。 我会人工审核,送出价值10美刀的测试额度(大约能跑500万Token)! 名额有限,先到先得。
不要让贫穷限制了你的想象力。 现在就去注册,把Gemini 3 Pro跑起来。 我们在代码的世界里见。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 9
9 0
0- 0



 已为社区贡献36条内容
已为社区贡献36条内容

所有评论(0)