高效生成新纪元:Stable Diffusion 3.5 FP8创新应用场景与AI镜像开发未来展望
摘要: Stable Diffusion 3.5 FP8通过FP8量化技术实现算力降低50%、推理速度提升3倍,突破高算力依赖瓶颈,推动AI生成技术向边缘端和产业应用落地。其创新应用场景涵盖移动端实时创作、工业设计协同、医疗影像辅助及元宇宙动态内容生成,凸显轻量化与实时性优势。AI镜像开发未来将聚焦端云协同、多模态融合、动态量化等技术方向,同时需解决伦理与安全问题,包括版权归属、深度伪造风险及模型
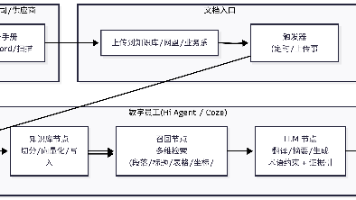
Stable Diffusion 3.5 FP8作为新一代低精度量化版本的文生图模型,凭借FP8(8位浮点)量化技术实现了算力消耗降低50%以上、推理速度提升3倍的核心优势,同时最大限度保留了模型的生成精度与细节表现力。这一技术突破打破了高精度生成模型“高算力依赖”的瓶颈,为AI生成技术从云端走向边缘端、从实验室走向规模化产业应用奠定了基础。与此同时,围绕生成式AI模型的镜像开发(包括模型轻量化封装、跨平台部署、功能定制化迭代)正成为技术落地的核心环节。本文将聚焦Stable Diffusion 3.5 FP8的创新应用场景设计,深度剖析AI镜像开发的未来发展方向,并对技术落地过程中的伦理与安全问题展开系统性探讨。
一、 基于Stable Diffusion 3.5 FP8的创新应用场景设计
Stable Diffusion 3.5 FP8的核心竞争力在于**“低算力高效果”的平衡能力**,其应用场景设计需紧扣“轻量化部署”“大规模并行处理”“实时交互生成”三大核心需求,覆盖消费级终端、工业生产、医疗健康、文化创意等多个领域。
(一) 边缘端智能创作:消费级设备的个性化内容生成
传统Stable Diffusion模型因算力需求较高,难以在手机、平板、便携式创作设备等边缘终端上实现本地推理。而Stable Diffusion 3.5 FP8的量化优化,使其能够在骁龙8 Gen3、天玑9300等旗舰移动芯片上流畅运行,催生三类创新应用:
- 移动端实时插画/漫画创作:设计师可通过手机APP输入文字描述(如“赛博朋克风格的猫咪宇航员,背景是火星基地”),模型在1-2秒内生成高清草稿,支持实时调整细节(如更换配色、修改服饰),无需依赖云端服务器,有效保护创作隐私。
- 车载场景的个性化内容生成:智能座舱可基于用户偏好,实时生成车载壁纸、仪表盘主题皮肤,甚至根据行车路线的风景(如海边、山区)生成对应的动态背景,提升驾乘体验。
- 嵌入式设备的创意辅助工具:在手绘板、智能笔等设备中集成模型,用户手绘草图后,模型可基于FP8的快速推理能力,自动填充细节、优化构图,实现“草图秒变成品”的创作效率提升。
(二) 工业设计协同:产品研发的快速原型生成与迭代
工业设计领域对模型的细节精度、风格一致性、迭代速度要求极高,Stable Diffusion 3.5 FP8的低算力特性使其能够融入工业研发流水线:
- 产品外观快速建模:工程师输入产品参数(如“一款轻量化的无人机机身,材质为碳纤维,设计风格极简”),模型可批量生成数十种外观方案,支持导出3D建模软件兼容的格式(如OBJ、STL),大幅缩短概念设计阶段的时间成本。
- 产线缺陷可视化标注:结合工业相机采集的产品缺陷图像,模型可快速生成缺陷区域的可视化标注图,辅助质检人员定位问题;同时,基于FP8的高效推理,可实现产线实时质检,提升检测效率。
- 跨团队协同设计库构建:企业可基于Stable Diffusion 3.5 FP8构建私有化模型镜像,集成企业专属的设计风格(如品牌LOGO、产品特征元素),不同部门的设计师可通过内网快速调用模型,确保设计风格的统一性。
(三) 医疗影像辅助:低成本的医学可视化与教育素材生成
医疗领域对AI模型的安全性、可解释性、低算力部署需求迫切,Stable Diffusion 3.5 FP8可在不依赖高性能服务器的前提下,实现两类创新应用:
- 医学影像三维可视化:结合CT、MRI等二维医学影像数据,模型可快速生成人体器官的三维可视化模型,帮助医生更直观地诊断病情;同时,该模型可部署在医院的门诊电脑上,无需专用算力集群,降低医院的设备投入成本。
- 医学教育素材定制化生成:医学院教师可输入文字描述(如“心肌梗死的病理变化过程,分阶段展示”),模型生成高精度的医学插图或动画分镜,用于课堂教学;相比传统手绘或3D建模,效率提升数十倍。
(四) 元宇宙实时内容生成:虚实融合场景的动态资产供给
元宇宙、AR/VR场景需要海量的虚拟资产(如场景、道具、角色),且对内容生成的实时性要求极高,Stable Diffusion 3.5 FP8的优势在此场景中尤为突出:
- AR实景交互的动态内容生成:用户通过AR眼镜扫描现实场景(如公园、商场),模型可实时生成与实景融合的虚拟元素(如在公园中生成卡通动物、在商场中生成促销虚拟海报),延迟控制在500ms以内,提升交互体验。
- 元宇宙场景的按需生成:元宇宙平台无需预先存储海量虚拟资产,可基于用户的行为(如进入某一区域、触发某一任务),通过FP8模型实时生成对应的场景与道具,降低平台的存储与运维成本。
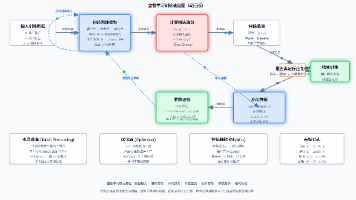
二、 AI镜像开发的未来发展方向思考与展望
AI镜像开发是连接模型算法与产业应用的核心桥梁,其本质是**“模型的封装、优化、定制化与跨平台部署”**。随着Stable Diffusion 3.5 FP8等低精度模型的普及,AI镜像开发将呈现五大核心发展趋势。
(一) 轻量化与端云协同:构建“边缘推理+云端精修”的分层架构
未来的AI镜像开发将打破“云端集中式推理”的单一模式,转向**“端云协同的分层架构”**:
- 边缘端镜像:极致轻量化:针对手机、嵌入式设备等边缘终端,开发基于FP8/INT4量化的超轻量镜像,实现本地快速推理,满足实时性与隐私保护需求;镜像体积控制在1GB以内,支持离线运行。
- 云端镜像:高精度精修:云端部署高精度模型镜像(如Stable Diffusion 3.5 FP16版本),负责对边缘端生成的内容进行细节优化、风格校准;边缘端与云端通过“轻量化特征传输”替代“全图传输”,降低带宽消耗。
- 动态切换机制:镜像内置智能调度模块,可根据网络状况、设备性能自动切换推理模式——网络良好时,自动同步云端精修结果;网络不佳时,完全依赖本地镜像运行,确保用户体验的连续性。
(二) 多模态融合:从“单一文生图”到“多模态交互”的镜像升级
当前的Stable Diffusion镜像以文生图功能为主,未来的镜像开发将向**“多模态融合”**方向演进:
- 多输入模态整合:开发支持“文字+图像+语音”多输入的镜像,例如用户上传手绘草图并搭配语音描述(“将这个草图改成古风风格,人物表情更柔和”),模型可精准理解用户需求,生成符合预期的内容。
- 多输出模态扩展:镜像不仅能生成图像,还可直接导出视频分镜、3D模型、动画脚本等多格式内容;例如,基于生成的静态图像,自动生成角色的动作序列,为动画制作提供素材。
- 跨模态知识迁移:在镜像中集成多模态预训练模型(如CLIP、BLIP),实现不同模态之间的知识共享,提升模型对复杂需求的理解能力。
(三) 动态自适应量化:精度与效率的智能平衡
固定精度量化(如FP8、INT4)难以兼顾所有场景的需求,未来的AI镜像开发将引入动态自适应量化技术:
- 任务感知的精度调整:镜像内置智能感知模块,可根据任务类型自动调整量化精度——例如,生成草稿时使用INT4量化,追求极致速度;生成高精度成品时,自动切换到FP8/FP16量化,保证细节质量。
- 硬件感知的优化策略:镜像可自动识别运行设备的硬件配置(如CPU型号、GPU算力),针对性优化推理引擎——例如,在AMD GPU上启用ROCm优化,在NVIDIA GPU上启用TensorRT加速,最大化硬件利用率。
- 增量式量化更新:支持“模型量化补丁”的在线推送,无需重新下载完整镜像,即可实现量化精度的升级,降低用户的更新成本。
(四) 开源生态与模块化镜像:降低产业应用的技术门槛
AI镜像开发的规模化落地,离不开开源生态的构建与模块化设计:
- 开源镜像仓库的搭建:建立统一的开源镜像仓库,提供标准化的Stable Diffusion 3.5 FP8镜像模板,支持用户基于模板快速定制行业专属镜像(如医疗版、工业版、教育版)。
- 模块化组件的即插即用:将镜像拆分为“推理引擎、风格插件、输出模块”等独立组件,用户可根据需求自由组合——例如,添加“古风风格插件”“3D模型输出模块”,无需修改模型核心代码。
- 低代码开发平台的集成:将AI镜像与低代码平台融合,非技术人员可通过拖拽式操作完成镜像的定制与部署,大幅降低产业应用的技术门槛。
(五) 安全可信的镜像签名体系:保障模型供应链安全
随着AI镜像的规模化应用,模型供应链安全将成为核心关注点,未来的镜像开发将建立完善的签名认证体系:
- 镜像数字签名:所有公开分发的镜像需经过官方签名认证,确保镜像未被篡改;用户可通过验证签名,判断镜像的合法性与完整性。
- 溯源与审计机制:镜像内置溯源模块,记录模型的训练数据来源、量化优化过程、部署历史;支持第三方机构对镜像进行安全审计,排查潜在的安全隐患。
- 沙箱化运行环境:镜像默认运行在沙箱环境中,限制其对设备系统资源的访问权限,防止恶意镜像窃取用户数据或破坏设备系统。
三、 对AI镜像开发伦理、安全等问题的探讨
Stable Diffusion 3.5 FP8的普及与AI镜像的规模化应用,在推动产业创新的同时,也带来了伦理失范、安全风险等一系列挑战,需要技术、法律、行业多方协同应对。
(一) 伦理问题:平衡创新与责任的边界
-
生成内容的版权归属问题
- 核心矛盾:用户基于AI镜像生成的内容,其版权归属于用户、镜像开发者还是模型训练数据的创作者?例如,模型训练过程中使用了大量艺术家的作品,生成的内容与原作品风格相似时,是否构成侵权?
- 应对策略:一是建立训练数据溯源机制,镜像需公开训练数据的来源清单,明确标注受版权保护的内容;二是推动AI生成内容版权登记制度,明确用户在使用镜像生成内容时的权利与义务;三是开发风格相似度检测插件,帮助用户规避侵权风险。
-
深度伪造与内容滥用风险
- 核心矛盾:低精度AI镜像的轻量化部署,降低了深度伪造技术的使用门槛,可能被用于生成虚假图像、伪造身份信息等违法活动。
- 应对策略:一是在镜像中集成数字水印技术,所有生成内容均嵌入不可见的水印,可通过专用工具验证内容的真实性;二是建立内容生成审核机制,对涉及政治人物、公众人物、敏感场景的生成请求进行严格审核;三是推动法律法规的完善,明确深度伪造行为的法律责任。
-
算法偏见与内容公平性问题
- 核心矛盾:模型训练数据中存在的偏见(如性别、种族、地域偏见),会通过AI镜像传递到生成内容中,例如生成的“工程师”多为男性、“护士”多为女性。
- 应对策略:一是开展算法偏见审计,在镜像发布前,通过多样化的测试数据集排查模型的偏见问题;二是开发偏见修正插件,用户可通过调整参数,消除生成内容中的偏见;三是推动训练数据的多元化建设,减少数据本身的偏见。
(二) 安全问题:筑牢技术落地的安全防线
-
模型镜像的供应链安全风险
- 核心风险:恶意攻击者可能篡改开源镜像,植入木马、病毒等恶意程序;或通过伪造镜像签名,诱导用户下载使用恶意镜像,窃取用户数据或控制设备。
- 应对策略:一是建立镜像签名认证中心,强制要求所有公开镜像进行签名认证;二是开发镜像安全扫描工具,对下载的镜像进行病毒查杀、代码审计;三是推动开源镜像仓库的规范化管理,建立镜像上传审核机制。
-
隐私数据泄露风险
- 核心风险:用户在使用AI镜像生成内容时,可能上传个人照片、敏感文字描述等隐私数据;若镜像未采取足够的隐私保护措施,这些数据可能被泄露或滥用。
- 应对策略:一是推行本地推理优先原则,鼓励镜像开发者优化本地推理能力,减少用户数据上传至云端的需求;二是采用联邦学习技术,在不收集用户原始数据的前提下,实现模型的优化升级;三是明确数据收集与使用规范,镜像需公开数据收集范围,获得用户明确授权后方可收集数据。
-
对抗样本攻击风险
- 核心风险:攻击者可通过构造恶意输入(如在文字描述中添加特殊字符),诱导模型生成有害内容;或通过对抗样本攻击,使模型输出错误结果(如将“禁止通行”的标志生成为“允许通行”)。
- 应对策略:一是在镜像中集成对抗样本检测模块,识别并拦截恶意输入;二是开展鲁棒性测试,在镜像发布前,通过大量对抗样本测试模型的稳定性;三是开发动态防御机制,模型可根据攻击类型自动调整推理策略,提升抗攻击能力。
结语
Stable Diffusion 3.5 FP8的出现,标志着AI生成技术正式迈入“高效能、低门槛”的规模化应用阶段。而AI镜像开发作为技术落地的核心环节,其未来发展必须紧扣“轻量化、多模态、安全化”的趋势,同时兼顾伦理与安全的双重要求。技术的创新永无止境,但技术的发展必须以造福人类为终极目标。只有通过技术、法律、行业的多方协同,才能推动AI生成技术在健康、可持续的轨道上前行,真正释放其赋能产业、服务社会的巨大潜力。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 16
16 0
0- 0



 已为社区贡献241条内容
已为社区贡献241条内容

所有评论(0)