Transformer架构及其源码实现
Transformer架构中注意力机制已经应用到各种深度学习模型当前去提高细节关注AIGC、LLM大模型项目:https://chensongpoixs.github.io/LLMSAPP/
Transformer架构及其源码实现
Transformer架构及其源码实现
前言

Transformer架构中注意力机制已经应用到各种深度学习模型当前去提高细节关注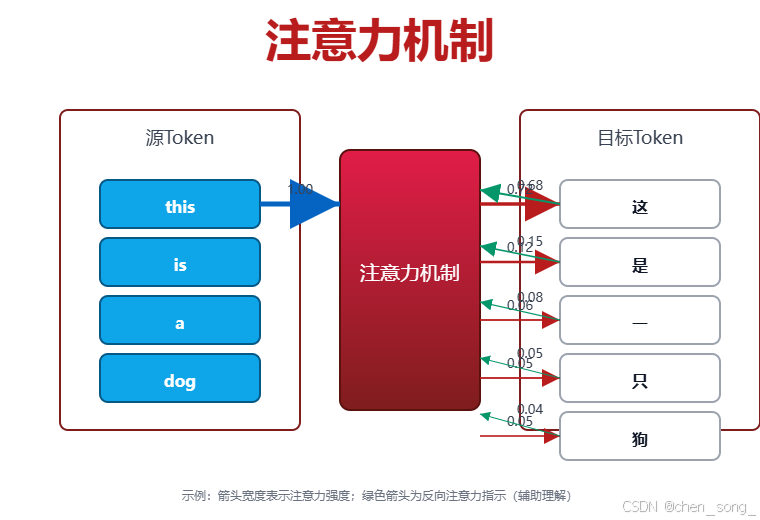
一、Transformer 整体架构图
输入序列 → 编码器 → 解码器 → 输出序列
1. 编码器(Encoder)流程图
┌─────────────────────────────────────────────────────────┐
│ 编码器 (Encoder) │
└─────────────────────────────────────────────────────────┘
↓
┌─────────────────────────────────────────────────────────┐
│ 输入序列 (Input Sequence) │
└─────────────────────────────────────────────────────────┘
↓
┌─────────────────────────────────────────────────────────┐
│ 嵌入层 + 位置编码 │
│ (Embedding + Positional Encoding) │
└─────────────────────────────────────────────────────────┘
↓
┌─────────────────────────────────────────────────────────┐
│ N × 编码器层 │
│ (N × Encoder Layer) │
├─────────────────────────────────────────────────────────┤
│ 层 1: │
│ ┌────────────────────┐ ┌────────────────────┐ │
│ │ 多头自注意力 │ → │ 前馈神经网络 │ │
│ │ (Multi-Head │ │ (Feed Forward) │ │
│ │ Self-Attention) │ └────────────────────┘ │
│ └────────────────────┘ ↑ │
│ ↑ │ 残差连接 │
│ │ 残差连接 │ + 层归一化 │
│ │ + 层归一化 │ │
└─────────────────────────────────────────────────────────┘
↓
┌─────────────────────────────────────────────────────────┐
│ 编码器输出 │
│ (Encoder Output) │
│ 包含输入序列的上下文表示 │
└─────────────────────────────────────────────────────────┘
编码器详细步骤:
- 输入处理:分词 → 词嵌入 → 位置编码
- 多头自注意力机制:
输入 → 线性变换 → 分成多个头 → 计算注意力 → 拼接 → 线性变换 - 前馈神经网络:两层线性变换 + ReLU激活
- 残差连接 + 层归一化:每个子层后都有
- 重复N次(原始论文中N=6)
2. 解码器(Decoder)流程图
┌─────────────────────────────────────────────────────────┐
│ 解码器 (Decoder) │
└─────────────────────────────────────────────────────────┘
↓
┌─────────────────────────────────────────────────────────┐
│ 目标序列 (Target Sequence) │
│ (右移一位,用于训练) │
└─────────────────────────────────────────────────────────┘
↓
┌─────────────────────────────────────────────────────────┐
│ 嵌入层 + 位置编码 │
│ (Embedding + Positional Encoding) │
└─────────────────────────────────────────────────────────┘
↓
┌─────────────────────────────────────────────────────────┐
│ N × 解码器层 │
│ (N × Decoder Layer) │
├─────────────────────────────────────────────────────────┤
│ 层 1: │
│ ┌────────────────────┐ ┌────────────────────┐ │
│ │ 掩码多头自注意力 │ → │ 编码器-解码器 │ → │
│ │ (Masked Multi-Head │ │ 注意力 │ │
│ │ Self-Attention) │ │ (Encoder-Decoder │ │
│ └────────────────────┘ │ Attention) │ │
│ ↑ └────────────────────┘ │
│ │ 残差连接 ↑ │
│ │ + 层归一化 │ 残差连接 │
│ │ │ + 层归一化 │
├─────────────────────────────────────────────────────────┤
│ ↓ │
│ ┌────────────────────┐ │
│ │ 前馈神经网络 │ │
│ │ (Feed Forward) │ │
│ └────────────────────┘ │
│ ↑ │
│ │ 残差连接 │
│ │ + 层归一化 │
└─────────────────────────────────────────────────────────┘
↓
┌─────────────────────────────────────────────────────────┐
│ 线性层 + Softmax │
│ (Linear + Softmax) │
└─────────────────────────────────────────────────────────┘
↓
┌─────────────────────────────────────────────────────────┐
│ 输出概率分布 │
│ (Output Probability) │
└─────────────────────────────────────────────────────────┘
解码器详细步骤:
- 输入处理:目标序列嵌入 + 位置编码
- 掩码多头自注意力:
- 防止位置i关注位置j(j>i)
- 确保自回归性质
- 编码器-解码器注意力:
- Query来自解码器
- Key和Value来自编码器输出
- 连接两个序列的信息
- 前馈神经网络:与编码器相同
- 线性层 + Softmax:生成下一个词的概率分布
3. 编码器-解码器连接
┌─────────────┐ 编码器输出 ┌─────────────┐
│ 编码器 │─────────────────→│ 解码器 │
│ │ 作为K和V │ │
└─────────────┘ └─────────────┘
↓
┌─────────────┐
│ 输出序列 │
└─────────────┘
4. 核心组件详解
多头注意力机制流程:
输入 → 线性投影 → 分割成h个头 → 每个头:
Q, K, V = 线性变换
注意力分数 = softmax(Q·Kᵀ/√dₖ) · V
→ 拼接所有头 → 线性投影 → 输出
训练 vs 推理流程对比:
训练(Teacher Forcing):
输入序列 → 编码器 → 解码器(并行处理整个目标序列)
↓
计算损失 ← 与真实标签比较
推理(自回归):
输入序列 → 编码器 → 解码器(逐个生成token)
↓
生成token₁ → 加入输入 → 生成token₂ → ...
关键特点总结
- 编码器:双向上下文,可以看到整个输入序列
- 解码器:
- 自回归生成
- 掩码确保只能看到之前的位置
- 编码器-解码器注意力连接两个序列
- 位置编码:加入序列顺序信息
- 残差连接:缓解梯度消失
- 层归一化:稳定训练
这个架构使得Transformer能够处理序列到序列的任务,如机器翻译、文本摘要等,同时具有高度并行化的优势。

- 位置信息:用位置编码赋予词向量序列信息
- 三种注意力机制:编码器多头注意力、交叉注意力、解码器多头自注意力(含因果掩码)
- 残差网络
- 层归一化
- 前馈神经网络
残差连接+层归一化+前馈网络(FFN):形成标准层块,稳定深层训练
二、Transformer的输入
- Embedding(向量编码)
- Positional Encoding(位置编码)
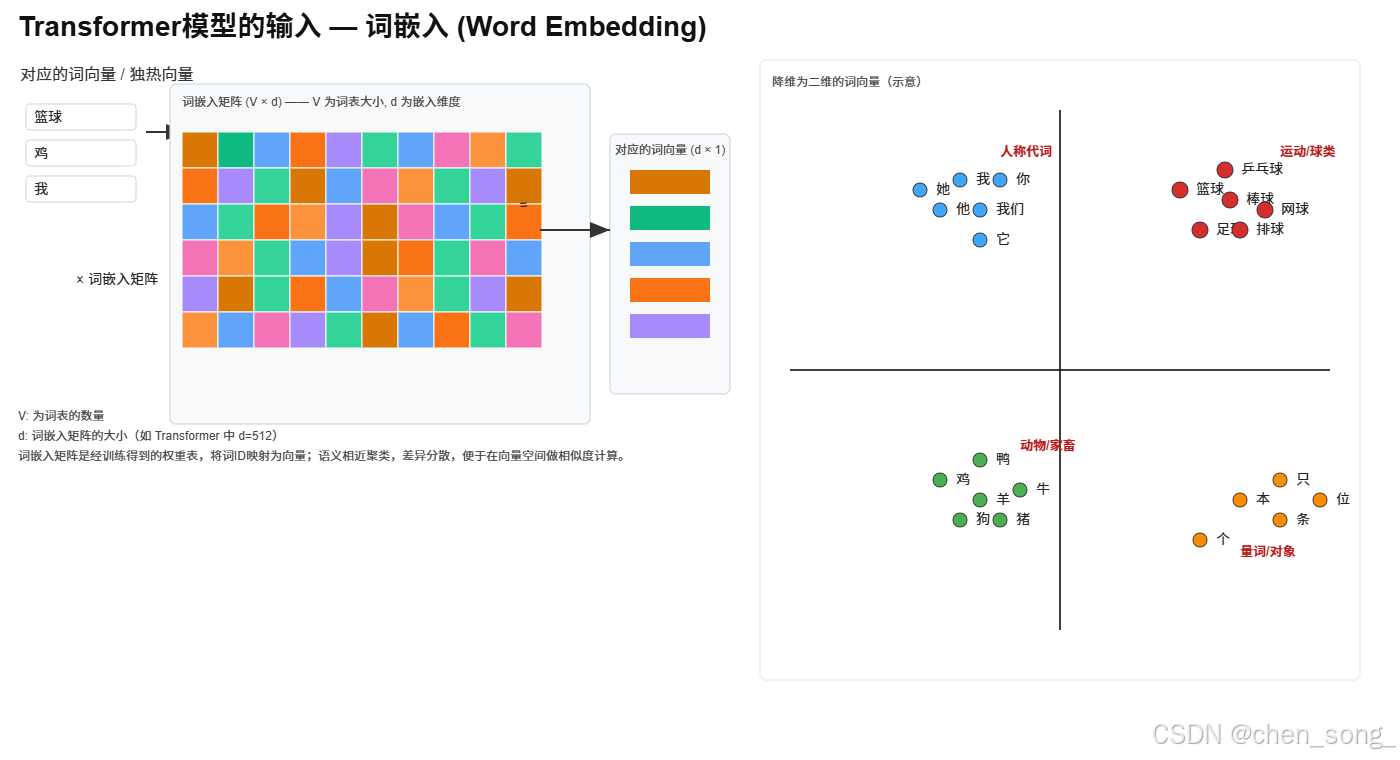
位置编码格式
P E ( p o s , 2 i ) = s i n ( p o s 10000 2 i d ) {PE_{(pos, 2i)} = sin(\frac{pos}{10000^{\frac{2i}{d}}}) } PE(pos,2i)=sin(10000d2ipos)
P E ( p o s , 2 i + 1 ) {PE_{(pos, 2i+1)}} PE(pos,2i+1) = c o s ( p o s 10000 2 i d ) {cos(\frac{pos}{10000^{\frac{2i}{d}}})} cos(10000d2ipos)
- pos: 表示该词在句子中位置(从0开始)
- i: 表示当前维度的位置
- d: 表示词向量维度
也就是是,对于输入的每个token(列如第5个词),我们遍历维度, 对每一个维度使用公式计算出其数值, 为其生成一个长度为d_model的向量, 交替使用sin和cos来填充奇偶维度
为什么要用正函数?
- 多尺度建模能力
通过
公式 10000 2 i d {10000^{\frac{2i}{d}}} 10000d2i
这样的频率控制, sin/cos的周期从大到小, **可以编码不同粒度的顺序信息**。 低纬捕捉长距离位置变化, 高维度捕捉局部变化- 平滑变化
随着位置pos变化, 编码向量是连续的, 符合自然语言中位置是连续变量的特点
- 支持序列泛化
因为是数字函数, 位置可以扩展到比训练时更长的序列, 而不会像可学习位置编码那样固定在训练长度上
- 简单高效
不需要额外学习参数, 占用显存小, 适合参数紧凑的场景
三、监督学习

训练过程中不停看每次训练完后损失然后反向传播更新神经网络的参数
四、Transformer代码实现

import torch
import torch.nn as nn
import math
from MySelfAttention import MultiHeadAttention
class MyGPTModel(nn.Module):
def __init__(self, cfg):
super().__init__()
self.token_embedding = nn.Embedding(cfg["vocab_size"], cfg["embedding_dim"])
self.position_embedding = nn.Embedding(cfg["max_seq_length"], cfg["embedding_dim"])
self.transformer_blocks = nn.Sequential(
*[MyTransformerBlock(cfg) for _ in range(cfg["n_layers"])]
)
#self.layer_norm = MyLayerNorm()
self.layer_norm = nn.LayerNorm(cfg["embedding_dim"])
self.out_head = nn.Linear(cfg["embedding_dim"], cfg["vocab_size"], bias=False)
self.drop = nn.Dropout(cfg["drop_rate"])
def forward(self, x):
#x它是一个矩阵,每一行是段训练数据(也就是一句话)
#x不是文字,而是文字所对应的token ID 串
#所以,x中包括了多行训练数据,称为一个批量
#它的列表示,每一段训练数据的长度
batch_size, seq_len = x.shape
#1. batch_size; 2. seq_len; 3. embedding_dim
token_embeds = self.token_embedding(x) #token_embeds 是一个三维的矩阵
#position_embedding结果是一个二维矩阵
#每一行表示arange生成的字符
#而每一行的列数是由embedding_dim决定的,GPT-2中是768
postion_embeds = self.position_embedding(torch.arange(seq_len, device=x.device))
#广播机制(batch_size, seq_len, embedding_dim), (batch_size, seq_len, embedding_dim)
x = token_embeds + postion_embeds
#防止过拟合
x = self.drop(x)
#(batch_size, seq_len, embedding_dim)
x = self.transformer_blocks(x)
x = self.layer_norm(x)
logits = self.out_head(x)
return logits
class NewGELU(nn.Module):
def forward(self, x):
return 0.5 * x * (1.0 + torch.tanh(math.sqrt(2.0 / math.pi) * (x + 0.044715 * torch.pow(x, 3.0))))
class FeedForwardNetwork(nn.Module):
def __init__(self, cfg):
super().__init__()
self.layers = nn.Sequential(
nn.Linear(cfg["embedding_dim"], 4*cfg["embedding_dim"]),
NewGELU(),
#nn.GELU(),
nn.Linear(4*cfg["embedding_dim"], cfg["embedding_dim"])
)
def forward(self, x):
return self.layers(x)
class MyTransformerBlock(nn.Module):
def __init__(self, cfg):
super().__init__()
# MY_GPT_CONFIG = {
# "vocab_size": 50257, #词汇表大小
# "max_seq_length": 1024, #每一句训练数据的最大长度
# "embedding_dim": 768, #嵌入向量的维度
# "n_heads": 12, #注意力头个数
# "n_layers": 12, #Transformer 层数
# "drop_rate": 0.1, #Dropout rate
# "qkv_bias": False #bias
# }
self.mha = MultiHeadAttention(
d_in=cfg["embedding_dim"],
d_out=cfg["embedding_dim"],
num_heads=cfg["n_heads"],
drop_rate=cfg["drop_rate"],
mask_matrix_len=cfg["max_seq_length"],
qkv_bias=cfg["qkv_bias"])
self.ffn = FeedForwardNetwork(cfg)
self.norm_1 = nn.LayerNorm(cfg["embedding_dim"])
self.norm_2 = nn.LayerNorm(cfg["embedding_dim"])
self.dropout = nn.Dropout(cfg["drop_rate"])
def forward(self, x):
old_x = x
x = self.norm_1(x)
x = self.mha(x)
x = self.dropout(x)
#残差
x = x + old_x
old_x = x #为后面的残差做准备
x = self.norm_2(x)
x = self.ffn(x)
x = self.dropout(x)
x = x + old_x
return x
总结

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 11
11 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)