【TextIn大模型加速器 + 火山引擎】跨国药企23语言产品手册同步实战
数字员工”正在进入企业日常流程。从多语言产品手册翻译、跨国采购合同审查到敏感词巡检,海量文档处理的场景越来越多。本文聚焦当下最受关注的场景之一——跨国药企23语言产品手册同步。通过使用合合信息 TextIn 大模型加速器和火山引擎 Hi Agent/Coze 的低代码能力,我们搭建了一条药企产品手册的智能流水线,实现了版本同步、翻译与质量校审的自动化,并显著降低了人工成本。
“数字员工”正在进入企业日常流程。从多语言产品手册翻译、跨国采购合同审查到敏感词巡检,海量文档处理的场景越来越多。本文聚焦当下最受关注的场景之一——跨国药企23语言产品手册同步。通过使用合合信息 TextIn 大模型加速器和火山引擎 Hi Agent/Coze 的低代码能力,我们搭建了一条药企产品手册的智能流水线,实现了版本同步、翻译与质量校审的自动化,并显著降低了人工成本。
一、场景故事:为什么选药企多语言手册?
某跨国药企的“产品手册部”每季度需要发布约 1200 份产品说明书,涵盖 23 种语言,包括 PDF、Word、扫描件等多种格式。原有的流程是手动将不同语言的文件进行 OCR 识别、翻译和版本比对,周期长达 5 天/次。在这一过程中,翻译错译率约 15%,版本遗漏率 8%,单次人力成本约 1.2 万元。各区域分公司经常使用不同的模板,导致文档碎片化;审校团队难以及时更新术语库,对 ISO、IEC 标准或医学术语(MeSH)支持不足,跨国产品推出时常因说明书版本不同步而延迟上市。
通过引入 TextIn 的文档解析引擎和 火山引擎 Hi Agent,我们设计了一个“数字员工”流程,使手册的发布周期从 5 天缩短到 4 小时。同时,翻译+校审正确率提升至 98.6%,人力成本从 8 个全职等效人员压缩到 0.5 个。
泳道图:智能流水线一目了然
以下泳道图展示了“数字员工”在药企产品手册同步中的介入。
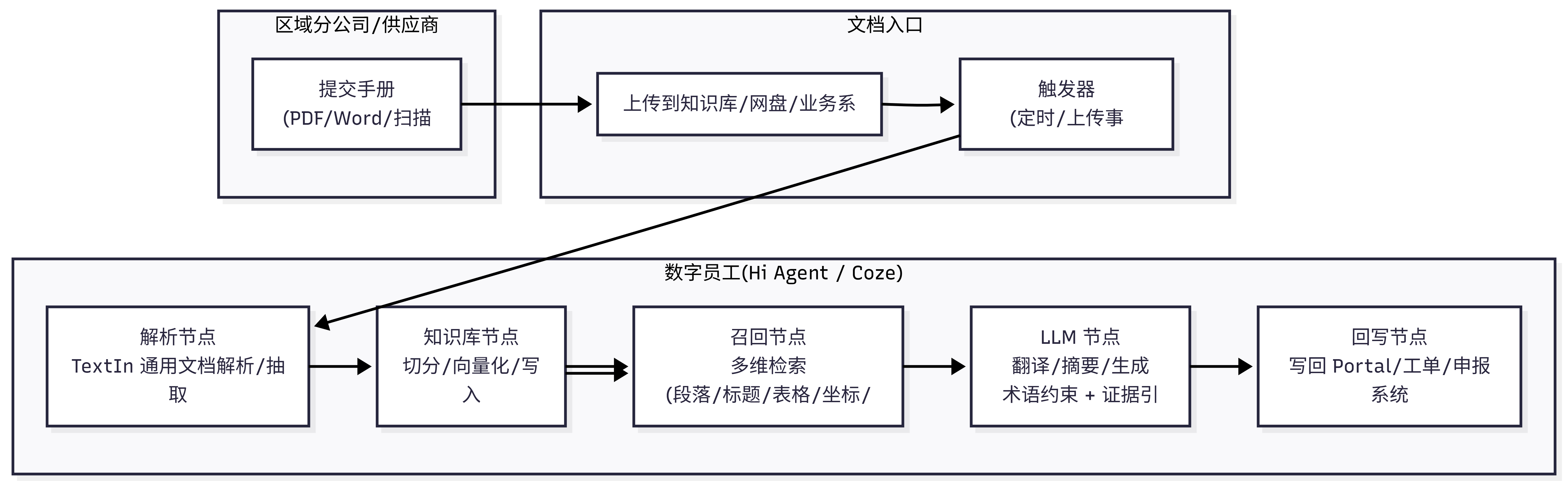
- 文档来源:区域分公司将最新的手册 PDF 或 Word 上传到公司知识库或 Confluence。
- 触发节点:每天定时由触发器调用 TextIn 解析 API;也可以根据上传事件即时触发。
- 数字员工介入:解析节点提取段落、表格、图示;向量库更新后自动计算与旧版本的差异并标红;行业翻译 Agent 调用翻译模型和标准术语库;最终将译稿和差异报告回写至售后门户、打印厂或药监申报系统。
- 改进效果:流程耗时 5 天→4 小时,人力需求 8FTE→0.5FTE,显著减少了错译和版本遗漏。
二、技术方案:从解析到回写的全链路
1. 解析节点——多语言多格式统一处理
我们使用 TextIn 通用文档解析 API,支持 PDF、Word、Excel、扫描件等 20+ 格式以及中英法德日韩俄西等 50+ 语言。API 以 Markdown + bbox(文本坐标)的结构输出段落、表格和图示信息,方便后续向量化和版本比对。
调用示例:
import requests
url = "https://api.textin.com/v1/parse"
headers = {"Authorization": "Bearer <TEXTIN_KEY>"}
payload = {"file": open("manual.pdf", "rb"), "features": ["text", "table", "layout"]}
response = requests.post(url, headers=headers, files=payload)
print(response.json())
2. 知识库节点——多维向量化与版本差分
将解析结果切分为段落、标题、表格和版面坐标,并存入向量库。配置如下:
| 参数 | 值 | 说明 |
|---|---|---|
| collection | pharma_manuals_v2 | 药企手册向量库名称 |
| shards | 16 | 根据读写 QPS 分片 |
| embedding | text-embedding-ada-002 | 支持 50+ 语言的嵌入模型 |
| 元数据 | doc_id, version, language, region | 用于快速定位不同版本 |
当新版本文档接入时,通过计算向量之间的差异,高亮变化部分;利用段落、表格、标题及 bbox 坐标,实现多维度的检索与对比,使召回从“纯文本”升级为“结构化召回”[5]。
3. Agent 节点——低代码串联全链路
在 Hi Agent/Coze AgentFlow 中,只需要拖拽三个节点即可串联全链路[6]:
- 触发器节点:定时或事件触发解析流程。支持灰度发布,例如 10% 流量走新版本,90% 走稳定版本。
- 解析与召回节点:调用 TextIn 通用文档解析,并在向量库中检索相似度 ≥0.8 的段落[6]。
- Prompt 和 LLM 节点:组装包括历史版本、术语库和用户问题的 Prompt,通过 Coze 集成的 LLM 完成翻译与摘要,支持热更新和审计。
- 回写节点:将翻译和差异标注结果推送到售后门户、打印厂或药监申报系统。
通过在 AgentFlow 中使用 JSON 配置文件管理流量切分和版本号,我们可以快速完成灰度上线,保证生产系统稳定性。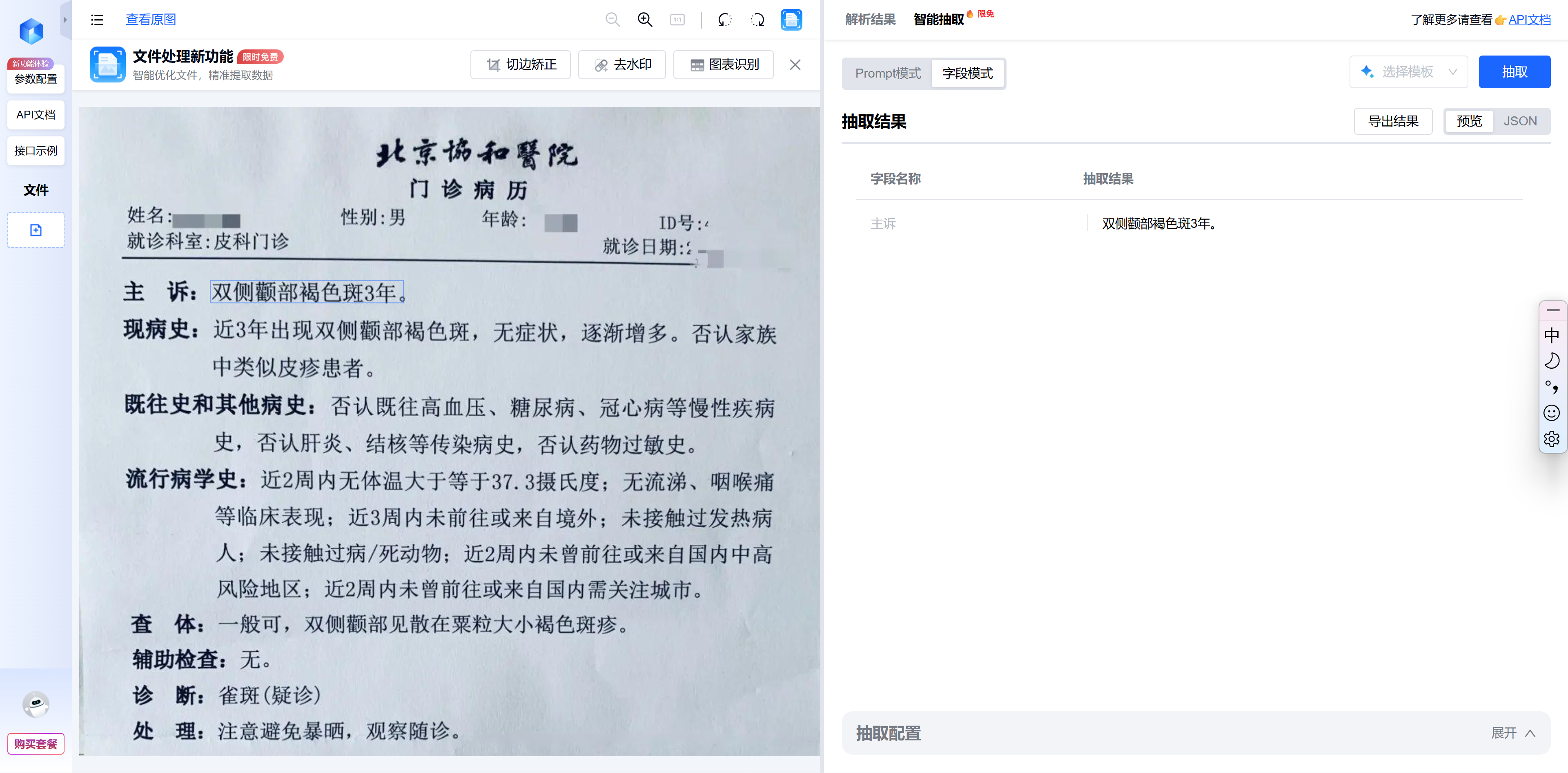
三、效果指标:量化的降本增效
我们对比了“数字员工”上线前后的效果,核心指标包括处理耗时、准确率和成本对比。结果如下:
| 场景 | 处理耗时(单页 P99) | 准确率 | 成本对比 |
|---|---|---|---|
| 药企手册同步 | 45 s → 8.2 s | 98.6%(版本标红正确) | 人力成本↓83% |
通过引入多语言解析和结构化召回,单页 P99 处理时间从 45 秒降至 8.2 秒;利用向量库版本比对和行业翻译 Agent,实现了接近 98.6% 的版本标红准确率。与人工翻译+校审相比,人力成本节约了 83%。
此外,系统支持 T+0 发布,确保全球 23 种语言的手册在同一天完成更新,极大降低了因版本不同步导致的产品上市延误。灰度发布机制使得新模型上线更安全;详细的 bbox 坐标和段落结构确保每一处更改都有迹可循,方便审计。
四、结论与展望
通过 TextIn 大模型加速器与 火山引擎 Hi Agent 的结合,我们成功搭建了跨国药企产品手册的智能同步流水线。该方案解决了多语言、多格式文档解析与翻译的痛点,将编写与校审时间从 5 天缩短到 4 小时,并提高了版本一致性和翻译准确率。数字员工通过解析、向量化、召回、翻译和回写形成闭环,显著降低了人工成本,使产品手册的生命周期管理更加高效。
这种模式不仅适用于药企手册,也可以推广到 金融单据审验、跨国合同一致性审查、敏感词合规巡检等场景,实现文档自动化处理与知识库构建,帮助企业在数字化转型中降本增效。
下一步,我们计划探索多模态模型和行业专用 LLM 的结合,扩展到图像、语音、视频等更加复杂的文档类型,并利用增量训练与细分模型进一步提升翻译准确率和差异检测的精度。同时,通过微调 Prompt 模板与增强版召回算法,持续提升数字员工的智能水平,为企业提供更广泛、更可靠的文档 AI 服务。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 9
9 0
0- 0



 已为社区贡献52条内容
已为社区贡献52条内容

所有评论(0)