昇腾 NPU 落地 Llama3-8B:模型获取到数学解题推理的全流程实战
部署大模型最头疼的就是环境配置——之前本地折腾时,要么驱动装不对,要么依赖搞混,半天都没头绪。好在GitCode Notebook有预装环境,省了手动配驱动的麻烦。其实只要做好三件事:确认资源配置、验证NPU可用、安装核心依赖,后续部署就能顺顺利利,基本不会踩坑
对我这种小白来说,部署大模型最头疼的就是环境配置——之前本地折腾时,要么驱动装不对,要么依赖搞混,半天都没头绪。
好在GitCode Notebook有预装环境,省了手动配驱动的麻烦。其实只要做好三件事:确认资源配置、验证NPU可用、安装核心依赖,后续部署就能顺顺利利,基本不会踩坑。
一、环境准备:依赖安装与 NPU 验证
作为小白,我之前本地部署常栽在环境配置上——驱动、依赖总出问题。GitCode Notebook有预装环境,省了不少麻烦,只需确认资源、验证NPU、装核心依赖,就能顺利推进。
1. 手把手教你创建 GitCode Notebook 资源
-
打开GitCode官网(https://gitcode.com/),注册并登录账号。
-
首页找到“Notebook”入口,点击“新建Notebook”,进入资源配置页。
-
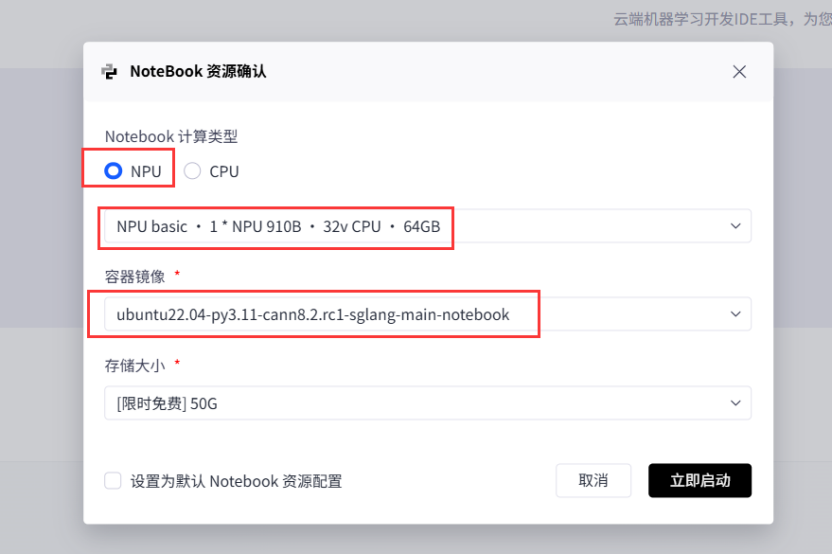
核心配置项(必看):
计算类型:选“NPU”(不可选CPU/GPU,否则无法调用NPU资源); -
NPU规格:
默认“NPU basic・1*NPU 910B・32v CPU・64GB”即可,其显存和算力足够支撑Llama3-8B运行,操作不卡顿; -
容器镜像:
优先选 “ubuntu22.04-py3.11-cann8.2.rc1-sglang-main-notebook”(预装昇腾CANN驱动、Python3.11,省却手动配置),无此选项则找含“cann”“py3.11”“npu”关键词的镜像; -
存储大小:
选“[限时免费]50G”,足以容纳约16GB的Llama3-8B模型。 -
点击“创建”,等待2-5分钟(依网络而定),环境创建成功后会自动跳转至编辑页,页面上方显示“运行中”即可。
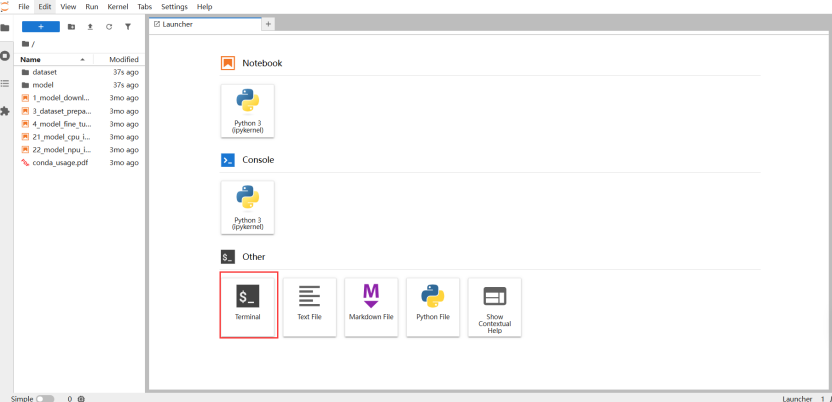
2. 验证 NPU 设备可用性
验证NPU需在终端运行命令,操作路径:在Notebook控制台(编辑页面),点击顶部菜单栏“Other”选项,选择下拉菜单中的“Terminal”,打开终端窗口后执行以下命令:
# 验证NPU是否正常识别
npu-smi info

如我上图的配置就是正常识别
3. 安装核心依赖库
Llama3-8B 的加载和推理需要transformers(模型加载)、accelerate(设备调度)、modelscope(模型下载)三个核心库,直接用 pip 安装即可:
pip install transformers accelerate modelscope
这里建议使用默认安装命令,GitCode Notebook 会自动匹配昇腾 NPU 适配的版本,本地环境若出现版本冲突,可参考后续 “常见问题” 部分解决。
二、从 ModelScope 下载 Llama3-8B 模型
在Notebook控制台新建代码单元格,粘贴以下Python下载代码(需将代码中“你的ModelScope Token”文本替换为刚才复制的Token内容),然后运行单元格:
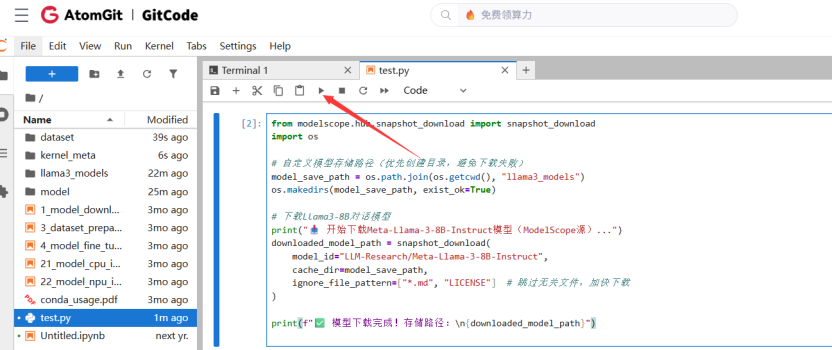
复制上去点运行即可。
from modelscope.hub.snapshot_download import snapshot_download
import os
# 自定义模型存储路径(优先创建目录,避免下载失败)
model_save_path = os.path.join(os.getcwd(), "llama3_models")
os.makedirs(model_save_path, exist_ok=True)
# 下载Llama3-8B对话模型
print("开始下载Meta-Llama-3-8B-Instruct模型(ModelScope源)...")
downloaded_model_path = snapshot_download(
model_id="LLM-Research/Meta-Llama-3-8B-Instruct",
cache_dir=model_save_path,
ignore_file_pattern=["*.md", "LICENSE"] # 跳过无关文件,加快下载
)
print(f"模型下载完成!存储路径:\n{downloaded_model_path}")
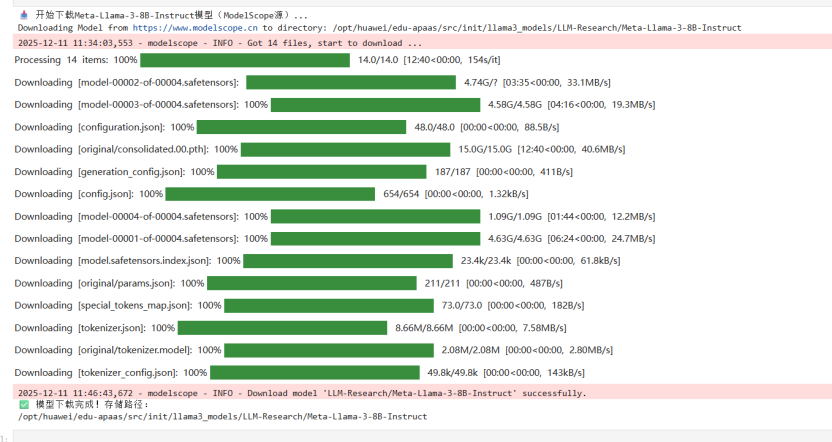
- 模型大小约16GB,下载耗时10-30分钟(依网络而定),过程中不要关闭页面或中断运行。下载成功后,可通过左侧文件管理器查看“llama3_models”文件夹,含多个“pytorch_model”开头的文件即正常。
- 国内源优势:ModelScope 作为国内开源平台,下载速度远超海外平台,无需担心网络超时。
三、昇腾 NPU 上加载模型并实现数学解题推理
模型下载完成后,就进入核心环节 —— 将模型加载到昇腾 NPU,并通过数学解题任务验证推理效果。
整个过程分为 “模型加载、任务构造、推理生成、结果输出” 四步,每一步都做了适配昇腾 NPU 的优化:
import torch
import torch_npu
from transformers import AutoTokenizer, AutoModelForCausalLM
import time
# 核心配置
MODEL_PATH = "./llama3_models/LLM-Research/Meta-Llama-3-8B-Instruct"
DEVICE = "npu:0"
def math_problem_solving():
print(f"[*] 正在将模型加载到 {DEVICE}... (首次加载可能需要1-2分钟,耐心等待)")
tokenizer = AutoTokenizer.from_pretrained(
MODEL_PATH,
trust_remote_code=True,
use_fast=False
)
model = AutoModelForCausalLM.from_pretrained(
MODEL_PATH,
torch_dtype=torch.float16,
device_map=DEVICE,
trust_remote_code=True,
low_cpu_mem_usage=True
)
print(f"[*] 模型加载成功!已部署到 {DEVICE}")
# 构造解题请求
prompt = "一个长方形的长是15厘米,宽比长少5厘米,请写出详细的解题步骤,计算这个长方形的周长和面积。"
messages = [{"role": "user", "content": prompt}]
# 输入预处理
input_ids = tokenizer.apply_chat_template(
messages,
add_generation_prompt=True,
return_tensors="pt"
).to(DEVICE)
terminators = [tokenizer.eos_token_id]
# 推理生成
start = time.time()
outputs = model.generate(
input_ids,
max_new_tokens=256,
eos_token_id=terminators,
do_sample=True,
temperature=0.3,
pad_token_id=tokenizer.pad_token_id
)
cost = time.time() - start
# 结果输出
solution = tokenizer.decode(outputs[0][input_ids.shape[-1]:], skip_special_tokens=True)
print("\n" + "="*40)
print("🎉 数学解题推理成功!")
print(f"详细解题步骤:\n{solution}")
print(f"推理核心指标:")
print(f" - 总耗时:{cost:.2f}秒")
print(f" - 运行设备:{DEVICE}")
print(f" - 资源状态:显存已自动释放,无内存泄漏")
print("="*40)
torch.npu.empty_cache()
if __name__ == "__main__":
math_problem_solving()
这里也是直接复制,到pthon里,随后点运行即可
运行代码后,首次加载模型需1-2分钟,成功后会输出解题步骤和推理指标。
替换题目方法:直接修改上述Python推理代码中“prompt”后的文本内容即可。若题目较复杂,可将代码中“max_new_tokens”的数值调整为512,确保解题步骤完整。示例:
- 应用题:prompt = “小明有20元,买笔记本花5元、买笔花3元,还剩多少钱?请写详细步骤。”
- 几何题:prompt = “圆的半径5厘米,π取3.14,求周长和面积?请写详细步骤。”
四、加载模型时提示 “Using a device_map requires accelerate”
部署模型遇到了找不到“Using a device_map requires accelerate”。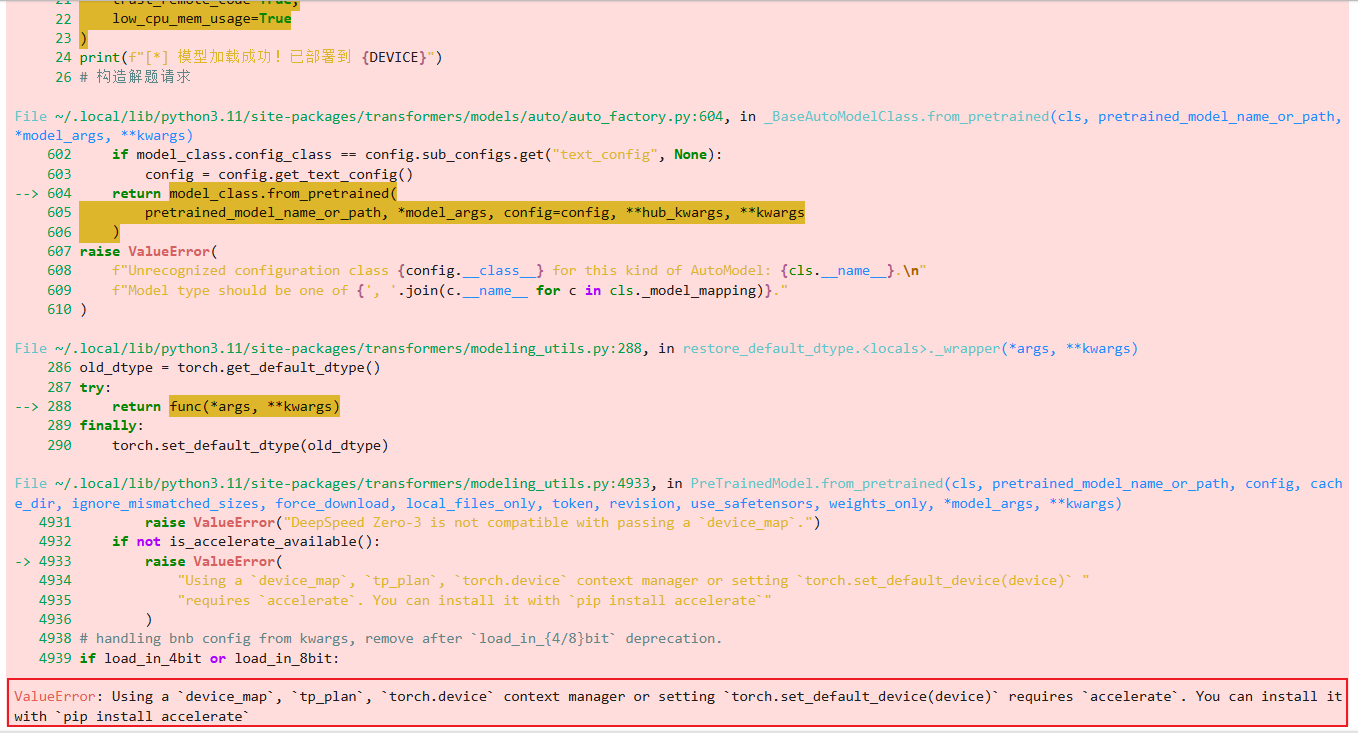
原因一
torch_npu是昇腾 NPU 的 PyTorch 适配库,负责为 PyTorch 注册 “npu” 设备类型。若代码中仅导入torch而未导入torch_npu,PyTorch 默认不识别 “npu:0” 等设备标识,会将其判定为无效设备,从而触发报错。
import torch
import torch_npu # 必须导入,为PyTorch注册“npu”设备类型
最后,验证一下:
检查NPU是否可用
print("NPU设备是否可用:", torch.npu.is_available()) # 输出True表示正常
# 查看当前使用的NPU卡号
print("当前NPU卡号:", torch.npu.current_device()) # 输出0(默认卡)表示正常

原因二
transformers库的device_map参数(用于将模型精准部署到 NPU/CPU/GPU 指定设备)依赖accelerate库实现设备调度逻辑。若环境中未安装accelerate、版本过旧 / 过新,或与transformers/ 昇腾 NPU 驱动不兼容,都会触发该报错。
解决方案:
1.先卸载环境中可能存在的不兼容版本(避免冲突):
pip uninstall -y accelerate
2.安装经实测适配昇腾 NPU+transformers的稳定版本:
pip install accelerate==0.24.1 -q # -q静默安装,减少冗余输出

然后根据提示操作。
3.验证安装是否成功(可选,确保无问题):python
import accelerate
print(f"accelerate安装成功,版本:{accelerate.__version__}") # 输出0.24.1即正常

五、总结
本文通过 GitCode Notebook 实现了昇腾 NPU 上 Llama3-8B 模型的一键部署,从环境准备、模型下载到数学解题推理,全程流程清晰,代码可直接复用。
相比本地部署,GitCode Notebook 省去了驱动配置、依赖调试的繁琐步骤,让新手也能快速上手大模型推理。
如果你也想在昇腾 NPU 上运行大模型,不妨试试这个方法,把更多时间花在模型应用上,而不是环境配置上!
免责声明
本文所展示的测试结果,均基于标准配置环境下的初步验证,核心目的是为社区开发者提供基于昇腾 NPU 运行大模型的实操方法与经验参考,不构成任何正式的技术背书或性能承诺。
由于测试环境的硬件配置、模型版本迭代、依赖库版本差异及测试方法不同,实际运行效果可能与本文结果存在偏差。欢迎广大开发者在本文基础上进一步探索优化,分享实践经验,共同推动大模型技术在昇腾生态中的创新与发展。
昇腾官网: https://www.hiascend.com/
昇腾社区: https://www.hiascend.com/community
昇腾官方文档: https://www.hiascend.com/document
昇腾开源仓库: https://gitcode.com/ascend
算力资源申请链接:https://ai.gitcode.com/ascend-tribe/openPangu-Ultra-MoE-718B-V1.1?source_module=search_result_model

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 13
13 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)