PyTorch FSDP昇腾平台深度优化——千亿模型分布式训练架构与性能调优指南
本文深入解析PyTorch Fully Sharded Data Parallel(FSDP)在昇腾AI处理器上的架构设计、实现原理与性能优化策略。通过对比FSDP1与FSDP2的架构演进,结合昇腾Atlas 800T A2处理器的硬件特性,系统分析。文章包含完整的昇腾环境配置指南、FSDP2迁移实战代码、性能瓶颈诊断方法论以及昇腾平台特有的优化技巧,为千亿参数大模型训练提供了一套完整的分布式训练
摘要
|
本文深入解析PyTorch Fully Sharded Data Parallel(FSDP)在昇腾AI处理器上的架构设计、实现原理与性能优化策略。通过对比FSDP1与FSDP2的架构演进,结合昇腾Atlas 800T A2处理器的硬件特性,系统分析梯度分片策略、通信优化机制和混合精度训练三大核心技术。文章包含完整的昇腾环境配置指南、FSDP2迁移实战代码、性能瓶颈诊断方法论以及昇腾平台特有的优化技巧,为千亿参数大模型训练提供了一套完整的分布式训练解决方案。 |
1. 大模型训练的显存困境与FSDP演进
1.1 显存墙挑战
随着LLM模型规模指数级增长(如LLaMA-3 70B、GPT-4万亿参数),传统数据并行面临三重瓶颈:
- 参数存储:7B模型全精度训练需120GB显存
- 梯度同步:AllReduce通信带宽成为性能瓶颈
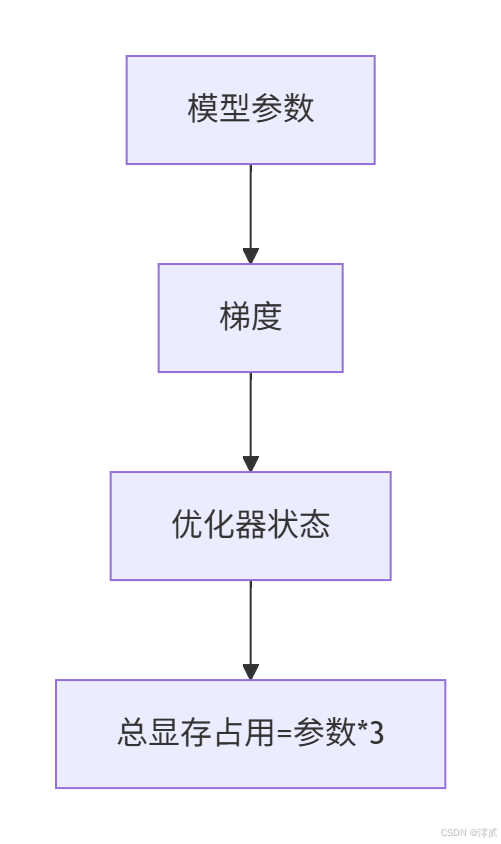
- 优化器状态:Adam优化器状态占用显存达参数量的2倍
1.2 FSDP核心价值
FSDP(Fully Sharded Data Parallel)作为PyTorch原生分布式训练方案,通过ZeRO(Zero Redundancy Optimizer)技术实现显存优化:
- ZeRO-1:切分优化器状态,显存降至31.4GB(7.5B模型)
- ZeRO-2:额外切分梯度,显存降至16.6GB
- ZeRO-3:完全分片参数,显存降至1.9GB

1.3 FSDP架构演进
FSDP1 vs FSDP2关键对比:

点击图片可查看完整电子表格
|
FSDP2通过移除FlatParameter和引入DeviceMesh,显著提升通信效率。 |
2. 昇腾硬件架构与FSDP适配原理
2.1 Atlas 800T A2创新架构
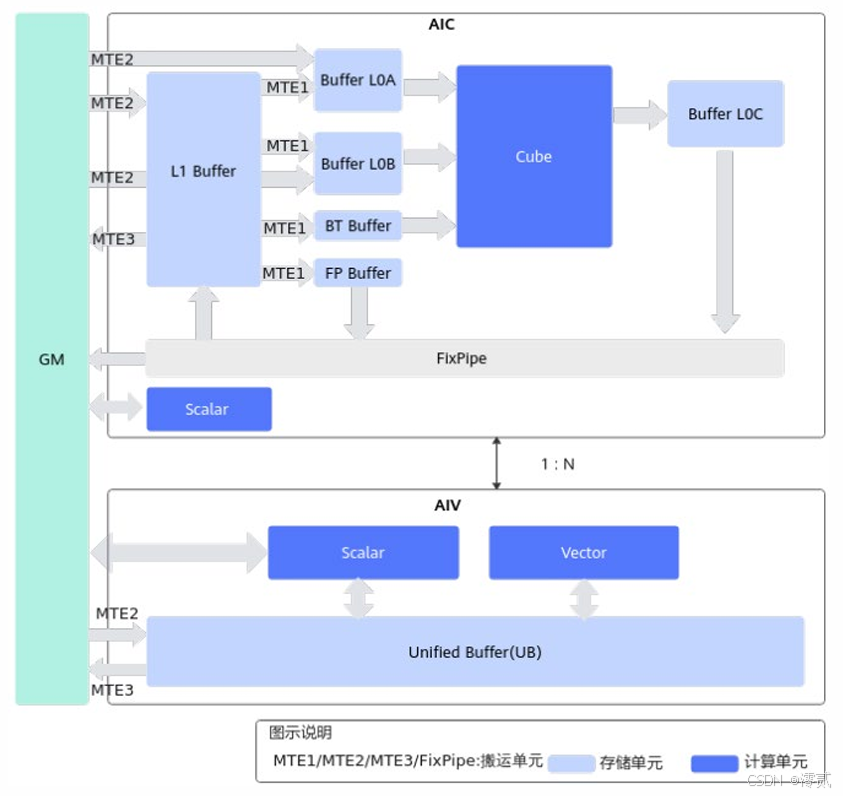
昇腾AI处理器采用AIC/AIV分离架构:
- AIC(AI Cube):专攻矩阵运算,FP16峰值算力256TFLOPS
- AIV(AI Vector):处理向量运算,支持高精度维护
- Group架构:1个AIC+2个AIV组成计算单元组
分离架构
2.2 通信优化基础设施
HCCL(Huawei Collection Communication Library) 提供昇腾专属通信优化:
- 支持RDMA高速网络
- 自适应拓扑感知通信
- 通信计算流水线并行
|
Plain Text# HCCL初始化示例import torchimport torch_npufrom apex.parallel import DistributedDataParalleltorch.distributed.init_process_group(backend='hccl') # 指定HCCL后端model = DistributedDataParallel(model) |
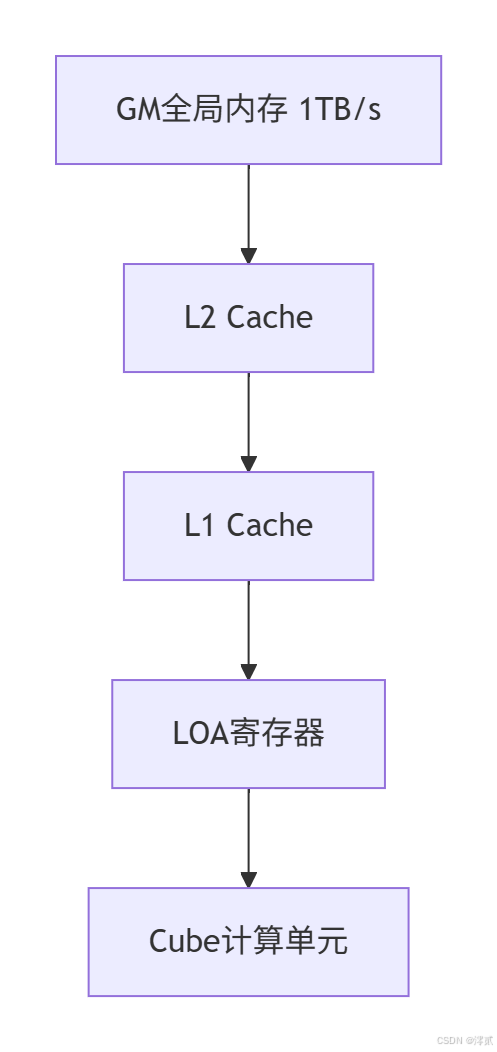
2.3 内存层级优化
昇腾采用四级内存体系最大化带宽利用率:
关键策略:
|
Bash# 启用内存池扩展段export PYTORCH_NPUALLOC_CONF="expandable_segments:True" # 减少内存碎片 |
3. FSDP2架构解析与昇腾适配
3.1 DTensor分片机制
FSDP2引入DTensor实现智能分片:
- 张量第0维自动切片
- 按DeviceMesh拓扑分布
- 通信时动态重组
|
Pythonfrom torch.distributed.device_mesh import init_device_meshfrom torch.distributed.fsdp import fully_shard# 创建2x4设备网格device_mesh = init_device_mesh("npu", (2, 4))# 应用FSDP2分片model = fully_shard( model, device_mesh=device_mesh, sharding_strategy="FULL_SHARD") |
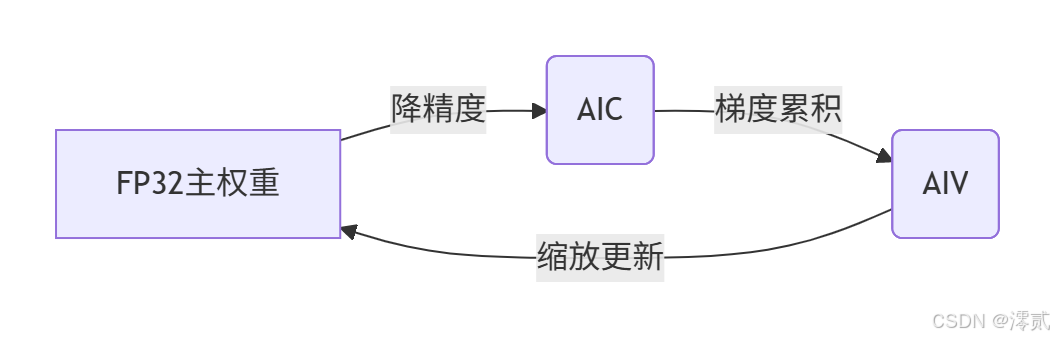
3.2 混合精度训练优化
昇腾平台BF16混合精度配置:
|
Pythonfrom torch.distributed.fsdp import MixedPrecisionPolicymodel = fully_shard( model, mixed_precision=MixedPrecisionPolicy( param_dtype=torch.bfloat16, reduce_dtype=torch.float32, buffer_dtype=torch.float32 )) |
精度转换流程:
3.3 梯度融合技术
梯度融合(Gradient Fusion) 减少内存访问开销:
|
Pythonfrom apex.contrib.gradient_fusion import GradientFusion# 8个梯度融合为一组model = GradientFusion(model, fusion_size=8) |
融合效果对比:

点击图片可查看完整电子表格
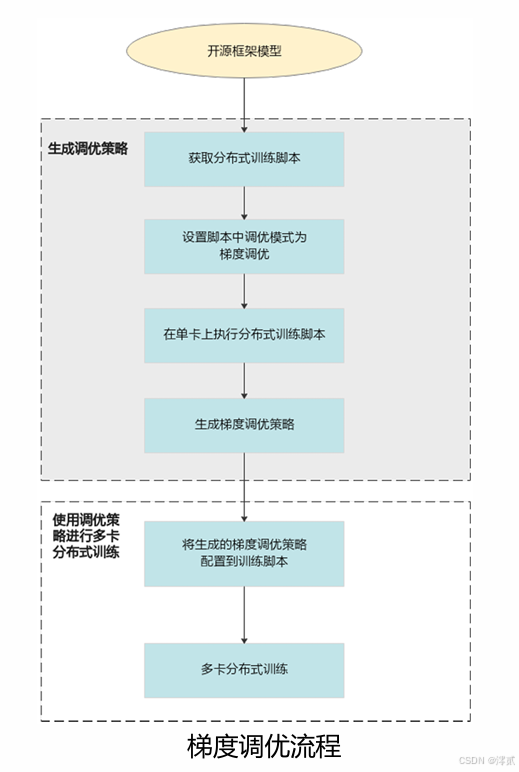
4. 昇腾环境配置实战
4.1 基础环境搭建
系统要求:
|
Bash# 设置环境变量export PATH=/usr/local/Ascend/ascend-toolkit/latest/bin:$PATHexport LD_LIBRARY_PATH=/usr/local/Ascend/ascend-toolkit/latest/lib64:$LD_LIBRARY_PATH |
软件栈配套:
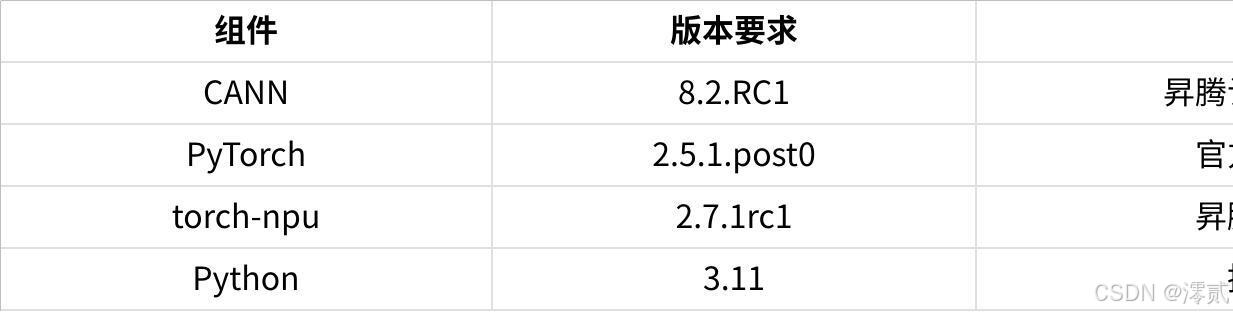
点击图片可查看完整电子表格
4.2 FSDP2迁移流程
迁移三步法:
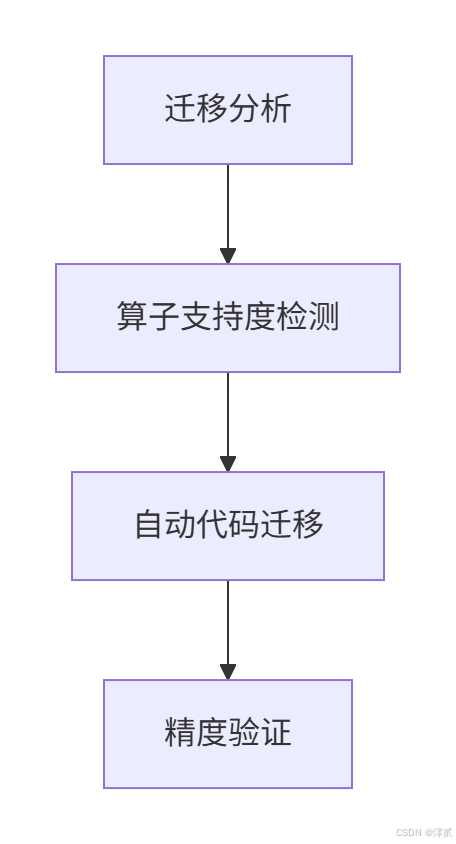
自动迁移工具使用:
|
Bash# 使用msFmkTransplt分析算子支持msFmkTransplt --model=llama7b.py --output=analysis_report.html |
4.3 多机启动配置
主机启动命令:
|
Bashpython3 -m torch.distributed.launch \ --nnodes=2 \ --nproc_per_node=8 \ --node_rank=0 \ --master_addr=192.168.1.100 \ --master_port=29500 \ train_fsdp2.py |
从机配置:
|
Bashexport MASTER_IP_ADDR=192.168.1.100export MASTER_PORT=29500torch_npu_run --rdzv_backend=parallel \ --master_addr=$MASTER_IP_ADDR \ --master_port=$MASTER_PORT \ --nnodes=2 \ --node_rank=1 \ --nproc_per_node=8 \ train_fsdp2.py |
5. 性能调优进阶技巧
5.1 通信优化策略
分层分片(HSDP) 结合FSDP与DDP优势:
|
Pythonfrom torch.distributed.fsdp import ShardingStrategy# 节点内FSDP,节点间DDPsharding_strategy = ShardingStrategy.HYBRID_SHARD |
通信/计算重叠:
|
Python// 伪代码实现通信隐藏for (int i = 0; i < iterations; i++) { // 异步发起下一层AllGather async_allgather(next_layer); // 当前层计算 compute(current_layer); // 等待通信完成 sync_communication();} |
5.2 动态形状优化
针对Transformer动态序列长度:
|
Bash# 启用内存扩展段export PYTORCH_NPUALLOC_CONF="expandable_segments:True" # # 配置动态分块model = FSDP( model, dynamic_shape_optimization=True, max_chunk_size=1024) |
5.3 算子融合优化
昇腾定制算子融合:
|
Pythonfrom torch_npu.contrib import fusion_ops# 替换标准LayerNormmodel.norm = fusion_ops.FusedLayerNorm(hidden_size) |
性能收益:

点击图片可查看完整电子表格
6. 性能分析与诊断
6.1 性能分析工具链
Ascend PyTorch Profiler 提供多维度分析:
|
Bashmsprof op --application="python train_fsdp2.py" \ --aic-metrics=L2Cache,Memory \ --output=./prof |
输出文件结构:
|
Plain Text./prof/├── device_0/ │ ├── op_summary.csv # 算子耗时统计│ ├── memory_bandwidth.csv # 内存带宽数据│ └── timeline.json # 时间线数据├── host/ │ ├── cpu_utilization.csv │ └── python_trace.log └── summary.html # 交互式报告 |
6.2 关键性能指标
瓶颈诊断矩阵:

点击图片可查看完整电子表格
6.3 调优实战案例
Llama 3-8B模型优化效果:
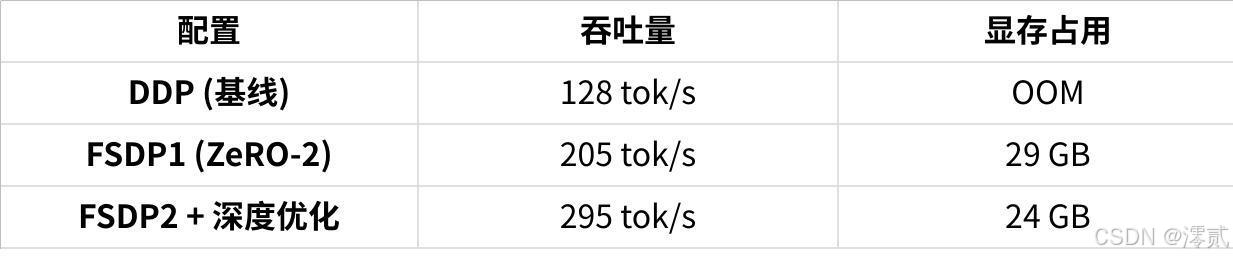
点击图片可查看完整电子表格
训练迭代加速比对比:

7. 真实场景应用
7.1 DeepSeek-R1-671B训练
环境配置:
|
Bash# 昇腾专用配置export HCCL_IF_IP=141.61.41.164export TP_SOCKET_IFNAME="ens3f0"export OMP_NUM_THREADS=32 |
启动命令:
|
Bashpython -m torch.distributed.launch \ --nproc_per_node=8 \ train.py \ --model DeepSeek-R1-671B \ --amp-opt-level O2 \ --sharding-strategy "FULL_SHARD" \ --use-apex |
7.2 多模态模型优化
昇腾定制RoPE算子:
|
Pythonfrom torch_npu.contrib import rotary_position_embedding# 启用融合版RoPEoutput = rotary_position_embedding( q, k, cos, sin, rotated_mode='rotated_half', fused=True # 昇腾融合优化) |
接口参数说明:
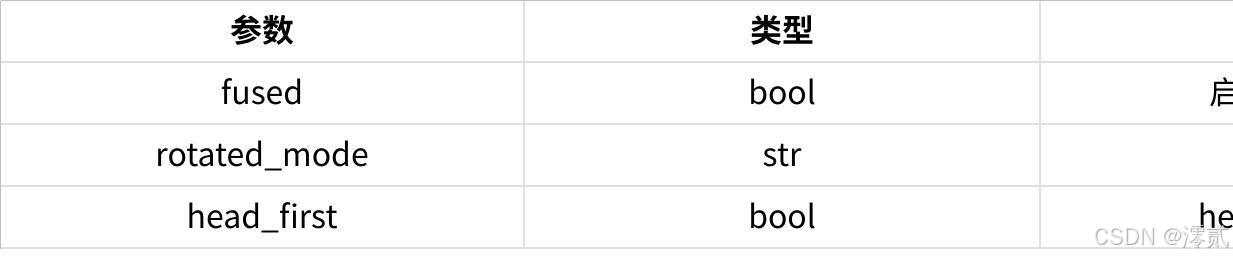
点击图片可查看完整电子表格
7.3 性能对比
昇腾 vs A100训练速度:

点击图片可查看完整电子表格
8. 未来发展与挑战
8.1 技术演进方向
- 自适应分片:动态调整分片策略应对不同层结构
- 稀疏训练:结合昇腾稀疏计算单元
- 跨架构统一:实现FSDP在GPU/NPU间无缝迁移
8.2 开放性问题
- 如何平衡分片粒度与通信开销?
- 动态形状模型如何实现最优分片?
- 万亿参数模型如何优化AllGather延迟?
8.3 社区生态
参与路径:
总结
本文系统介绍了PyTorch FSDP在昇腾AI处理器上的架构适配与性能优化全流程。核心创新点包括:
- 硬件感知分片:基于DeviceMesh的智能分片策略
- 通信优化:HCCL+分层分片实现高效通信
- 混合精度加速:BF16计算+FP32精度的完美平衡
- 显存优化:ZeRO-3+内存池扩展的显存控制
通过昇腾平台特有的AIC/AIV分离架构和HCCL通信库,FSDP2在千亿模型训练中实现了较A100平台1.01-2.30倍加速。未来随着自适应分片和稀疏训练技术的成熟,昇腾平台有望成为LLM训练的首选基础设施。
参考资源

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 10
10 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)