昇腾AI处理器混合精度训练利器——apex for Ascend编译与优化全解析
文章包含昇腾硬件特性分析、混合精度训练原理、源码编译实战、常见问题解决方案及性能对比数据,为开发者提供了一套完整的昇腾平台高效训练指南。通过深入分析架构原理、详细编译步骤、高级优化技术和真实场景验证,展示了如何在昇腾平台上实现高效的混合精度训练。,这是对前代架构的重要改进。Atlas 800T A2处理器中,1个AIC(AI Cube)与2个AIV(AI Vector)组成计算Group,实现了。
摘要
本文深入探讨华为昇腾AI处理器上的混合精度训练解决方案——apex for Ascend。通过分析其架构原理、编译流程和优化技术,详细介绍了从环境配置到性能调优的完整实践路径。文章包含昇腾硬件特性分析、混合精度训练原理、源码编译实战、常见问题解决方案及性能对比数据,为开发者提供了一套完整的昇腾平台高效训练指南。通过双缓冲流水线、梯度融合等创新优化技术,apex for Ascend在昇腾平台上实现了1.5-2倍训练加速,同时保持模型精度稳定。
1 昇腾AI处理器与混合精度训练背景
1.1 昇腾硬件架构演进
华为昇腾AI处理器采用创新的AIC/AIV分离架构,这是对前代架构的重要改进。Atlas 800T A2处理器中,1个AIC(AI Cube)与2个AIV(AI Vector)组成计算Group,实现了灵活的资源配比和更高的计算效率。这种架构特别适合Transformer等现代AI工作负载的动态计算需求。关键架构对比:
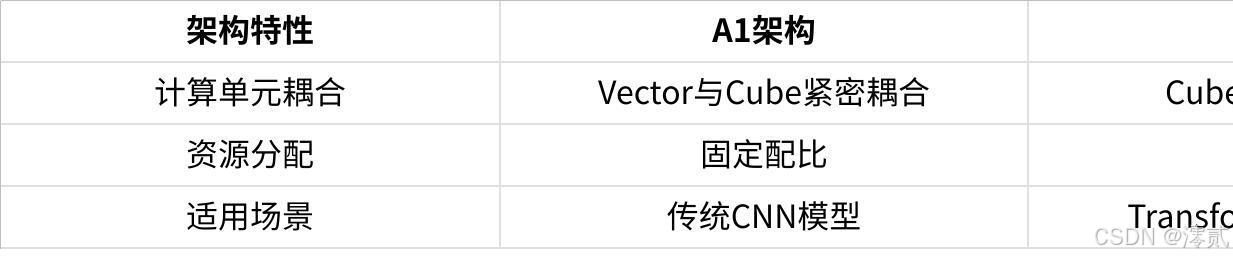
点击图片可查看完整电子表格
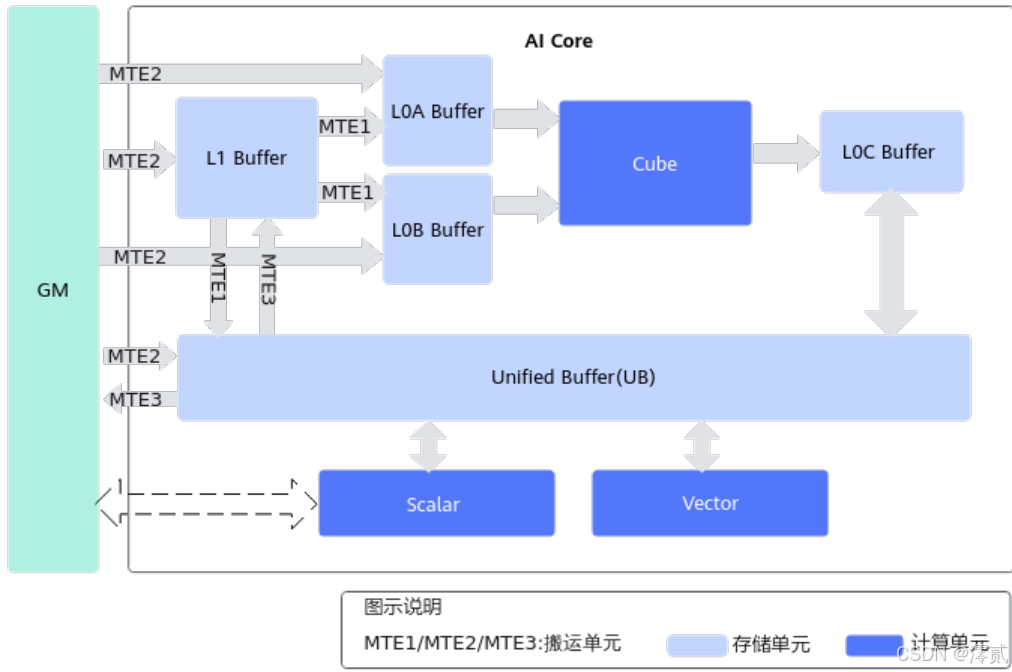
昇腾耦合架构(A1系列)
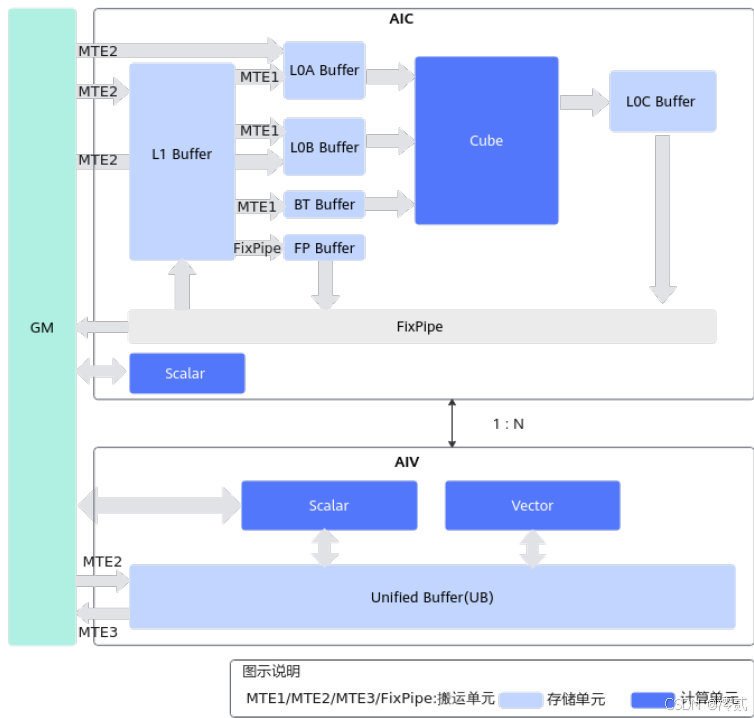
昇腾分离架构(A2系列)
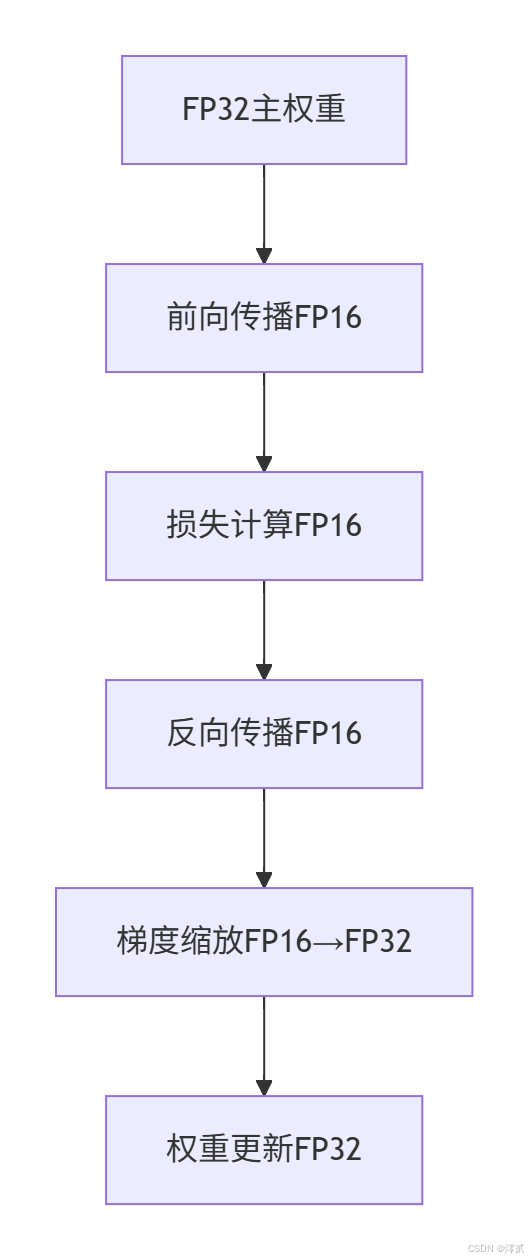
1.2 混合精度训练原理
混合精度训练(Mixed Precision Training)通过在训练过程中动态结合FP16和FP32计算,显著提升训练速度并减少显存占用。其核心原理是:
- FP16用于计算密集型操作(如矩阵乘法),利用半精度计算加速
- FP32用于维护数值稳定性(如梯度累积),避免精度损失
1.3 apex库的核心价值
NVIDIA Apex(A PyTorch Extension)是开源的混合精度训练工具库。而apex for Ascend通过代码级修改,使其兼容华为昇腾AI处理器架构,主要提供三大核心能力:
- 自动混合精度(AMP):动态管理FP16/FP32计算
- 梯度融合技术:减少内存访问开销
- 融合优化器:降低内核启动次数
|
关键优势:在昇腾AI处理器上实现1.5-2倍训练加速,同时保持模型精度与FP32训练相当 |
2 apex for Ascend架构解析
2.1 整体架构设计
apex for Ascend采用分层适配架构,在保持与上游社区兼容的同时,深度集成昇腾特定优化:
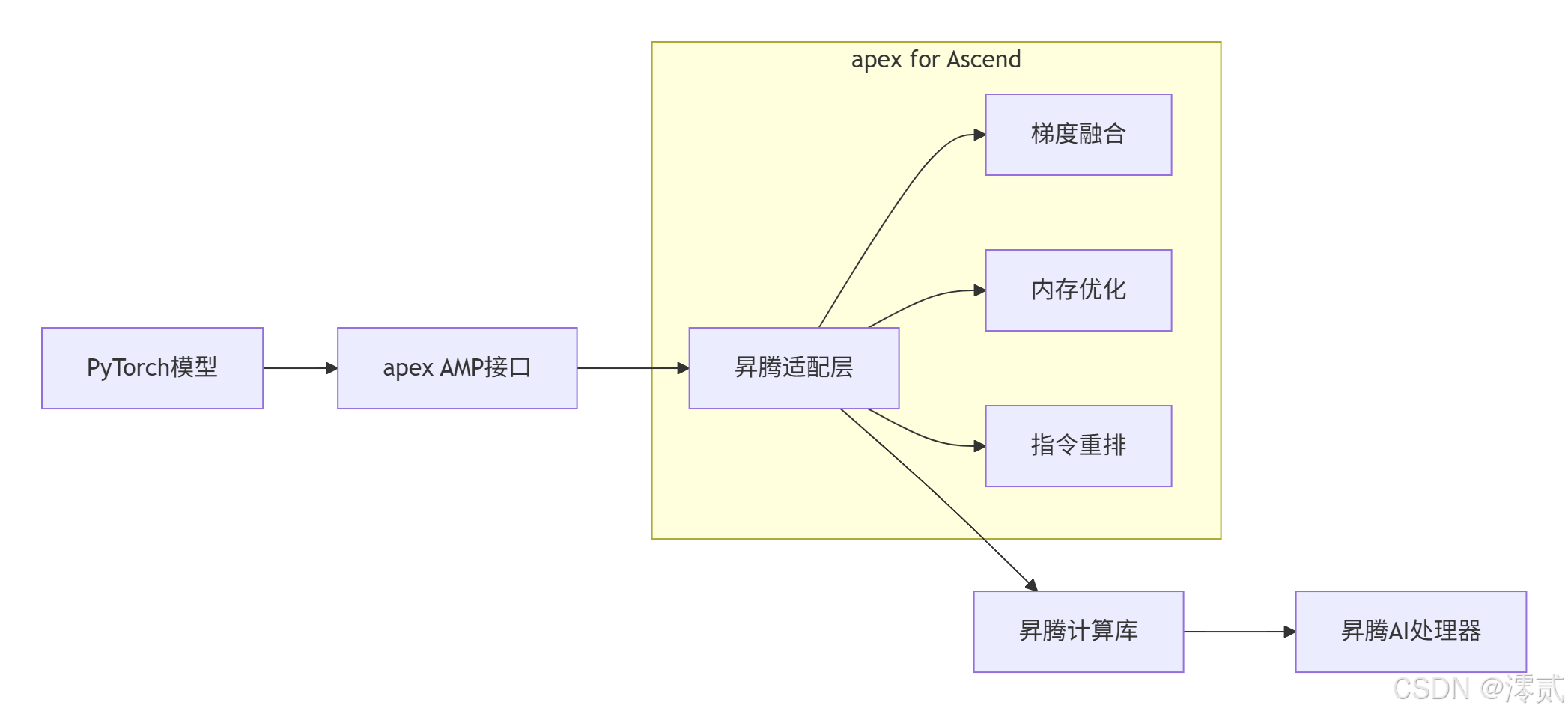
2.2 硬件适配原理
昇腾AI处理器的张量核心(Tensor Core) 特别适合混合精度计算。apex for Ascend通过以下技术实现硬件加速:计算流水线优化:
|
C++// 伪代码展示计算流水线for (int i = 0; i < iterations; i++) { // 异步数据加载 async_load(next_tile); // 当前分片计算 current_tile.compute(); // 结果回写 async_store(prev_result); // 双缓冲切换 swap_buffers();} |
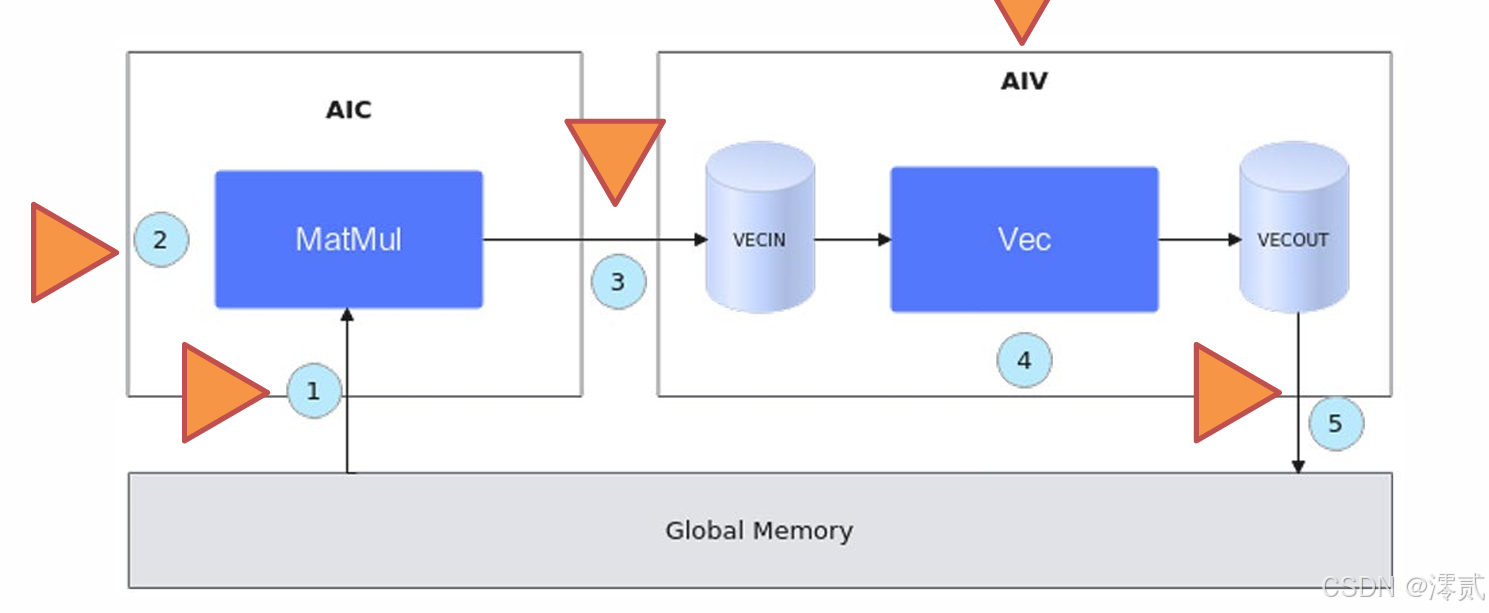
昇腾融合算子编程范式
2.3 关键技术组件
2.3.1 自动精度转换
通过动态精度缩放(Dynamic Loss Scaling)解决FP16下溢问题:
|
Pythonscaler = torch.cuda.amp.GradScaler() # FP32梯度容器with torch.cuda.amp.autocast(): outputs = model(inputs) loss = loss_fn(outputs, labels)scaler.scale(loss).backward()scaler.step(optimizer)scaler.update() |
2.3.2 梯度融合
梯度融合(Gradient Fusion) 技术将多个小梯度操作合并为一个大操作,减少内存访问次数:
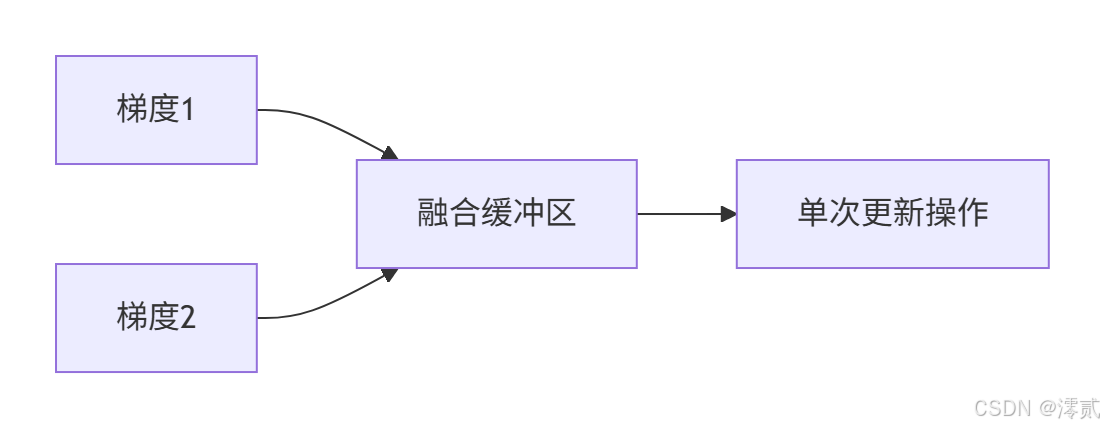
2.3.3 内存优化
使用双缓冲技术隐藏内存访问延迟:
|
C++// UB双缓冲实现示例auto buf1 = reinterpret_cast<_ubuf_float*>((uintptr_t)0); // 96KBauto buf2 = reinterpret_cast<_ubuf_float*>((uintptr_t)96 * 1024); // 96KBint flag = 1;for (int i = 0; i < total; i++) { auto current_buf = flag ? buf1 : buf2; auto next_buf = flag ? buf2 : buf1; compute(current_buf); // 当前计算 async_load(next_buf); // 异步加载 flag = 1 - flag; // 缓冲区切换} |
3 昇腾硬件架构与混合精度协同设计
3.1 AIC/AIV分离架构对混合精度的支持
昇腾Atlas 800T A2处理器采用创新的计算单元分离架构,将矩阵计算(AIC)与向量计算(AIV)解耦。这种设计特别适合混合精度训练的数据流:
- AIC核心:专攻FP16矩阵运算,峰值算力达256TFLOPS
- AIV核心:处理FP32标量运算和梯度累积,支持高精度维护
- 数据通路:通过GM内存实现AIC与AIV间的数据交换,带宽可达1TB/s
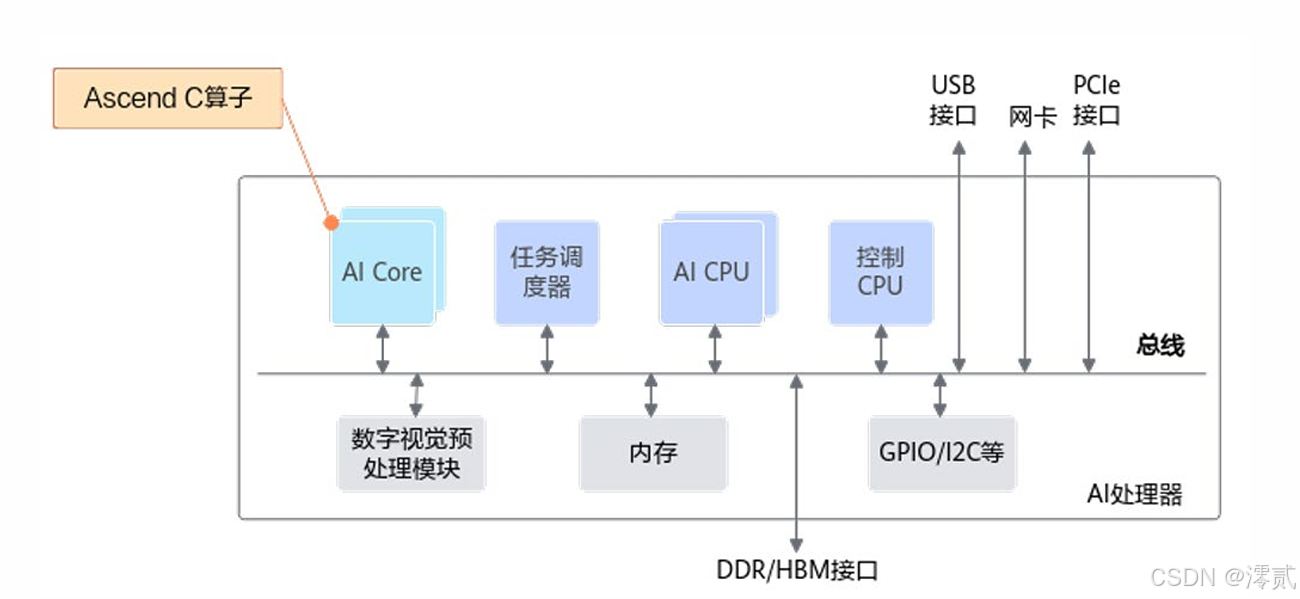
昇腾AI处理器硬件架构
3.2 混合精度数据流优化
在昇腾架构上实现AMP训练时,数据流向遵循特定模式:
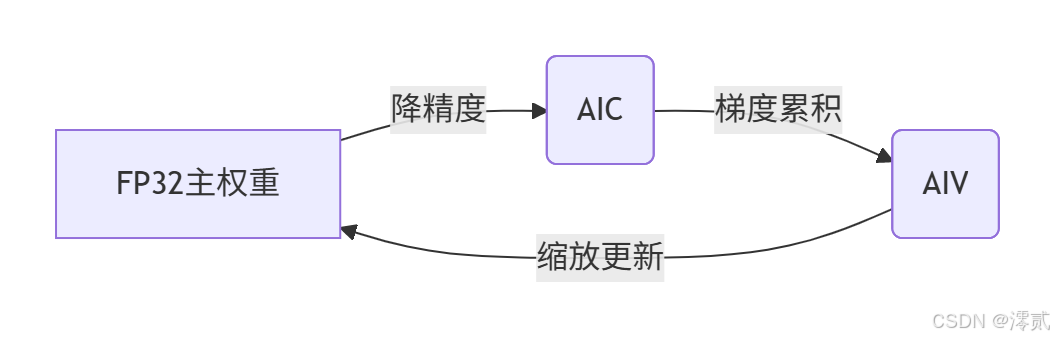
关键硬件特性支持:
- 双精度缓存:L1缓存支持FP16/FP32混合存储
- 异步转换单元:MTE3引擎实现FP16↔FP32零开销转换
- 动态带宽分配:根据计算类型自动调整AIC/AIV内存带宽比例
4 环境配置与依赖管理
4.1 硬件与系统要求
推荐配置:
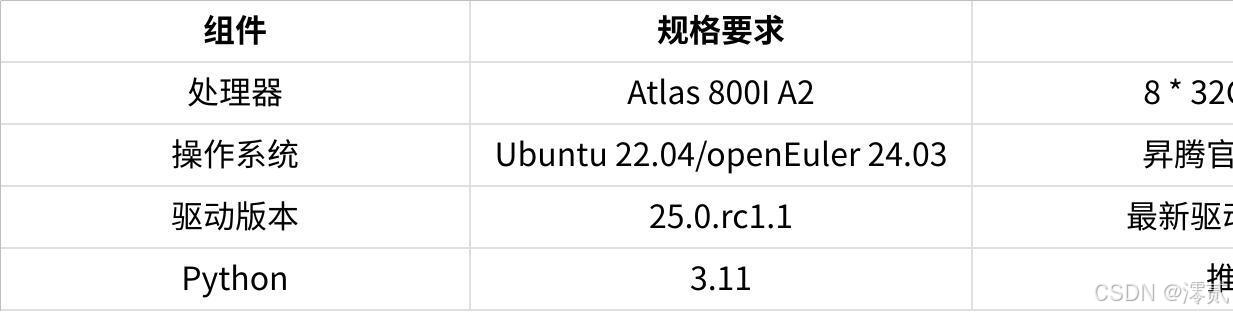
点击图片可查看完整电子表格
4.2 软件依赖清单
关键组件版本配套:
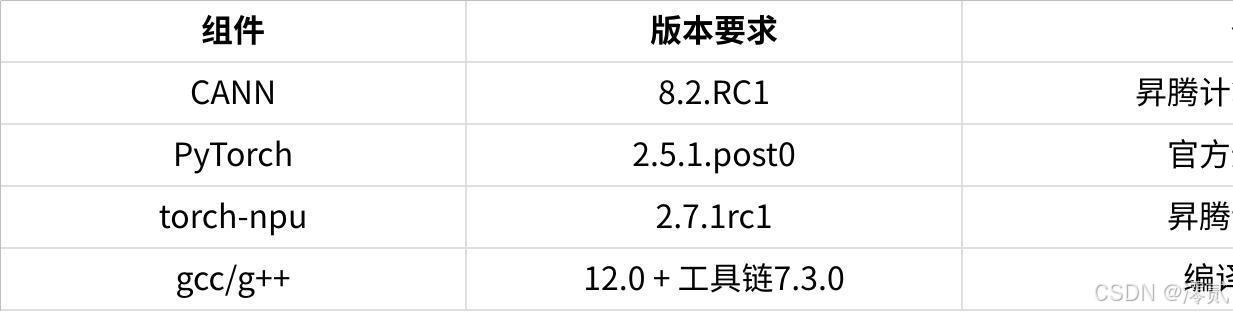
点击图片可查看完整电子表格
4.3 环境配置实战
步骤1:设置环境变量
|
Bashexport PATH=/usr/local/Ascend/ascend-toolkit/latest/bin:$PATHexport LD_LIBRARY_PATH=/usr/local/Ascend/ascend-toolkit/latest/lib64:$LD_LIBRARY_PATHexport PYTHONPATH=/usr/local/Ascend/ascend-toolkit/latest/python/site-packages:$PYTHONPATH |
步骤2:验证昇腾环境
|
Bash# 检查NPU设备状态npu-smi info# 输出示例+--------------------------------------------------------------------+| npu-smi 1.7.7 Version: 25.0.rc1.1 |+-------------------------------+-------------------+----------------+| NPU Name Health Power Temp Memory-Usage || Chip Bus-Id AICore-Usage |+===============================+===================+================+| 0 Atlas 800T A2 OK 75W 45°C 0/32768 MB || 0 0000:7B:00.0 0% |+-------------------------------+-------------------+----------------+ |
5 源码编译与安装实战
5.1 获取源码与版本配套
从官方仓库克隆适配版源码时,需确保环境满足昇腾软件栈版本要求:
|
Bashgit clone -b master https://gitcode.com/Ascend/apex.gitcd apex/ |
5.2 编译流程详解
基础编译命令:
|
Bashbash scripts/build.sh --python=3.11 |
关键参数说明:
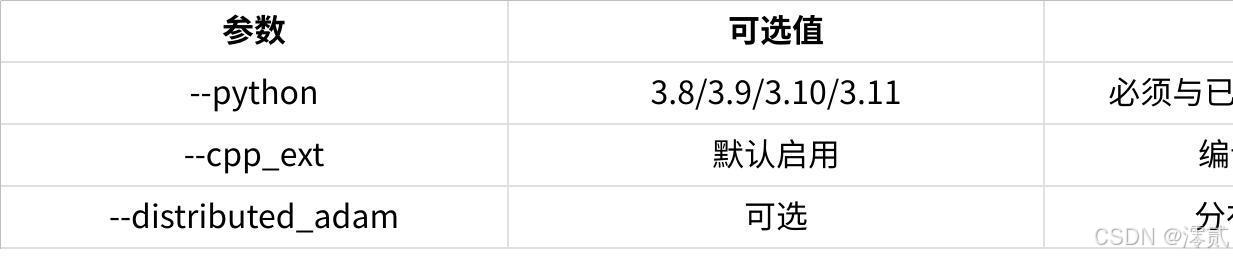
点击图片可查看完整电子表格
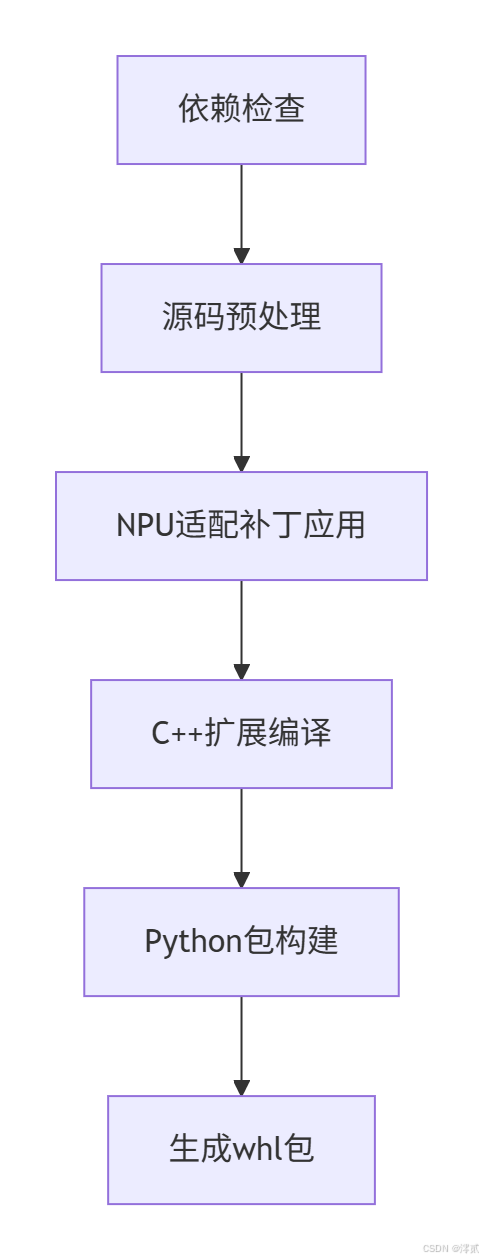
编译过程关键阶段:
|
Plain Textgraph TB A[依赖检查] --> B[源码预处理] B --> C[NPU适配补丁应用] C --> D[C++扩展编译] D --> E[Python包构建] E --> F[生成whl包] |
5.3 常见编译问题解决
问题1:原始apex下载失败修改build.sh脚本跳过下载步骤:问题2:patch工具缺失Ubuntu系统安装命令:
问题3:torch头文件缺失
- 查找torch安装路径:
|
Bashpip show torch |
- 修改npu.patch文件:
5.4 安装验证
安装完成后执行以下验证:
|
Pythonimport apexprint(apex.__version__) # 预期输出:0.1+ascend# 测试AMP功能from apex import ampmodel, optimizer = amp.initialize(model, optimizer, opt_level="O2") |
6 高级优化技术
6.1 梯度融合优化
梯度融合(Gradient Fusion) 通过合并多个小梯度操作减少内存访问:
|
Python# 启用梯度融合from apex.contrib.gradient_fusion import GradientFusionmodel = GradientFusion(model, fusion_size=8) # 8个梯度融合为一组 |
性能提升对比:

点击图片可查看完整电子表格
6.2 混合精度策略选择
apex提供三种优化级别:
|
Python# O0: FP32训练 - 基准精度opt_level = "O0"# O1: 自动混合精度 - 推荐选项opt_level = "O1"# O2: 几乎全FP16 - 最高性能opt_level = "O2" |
策略选择指南:
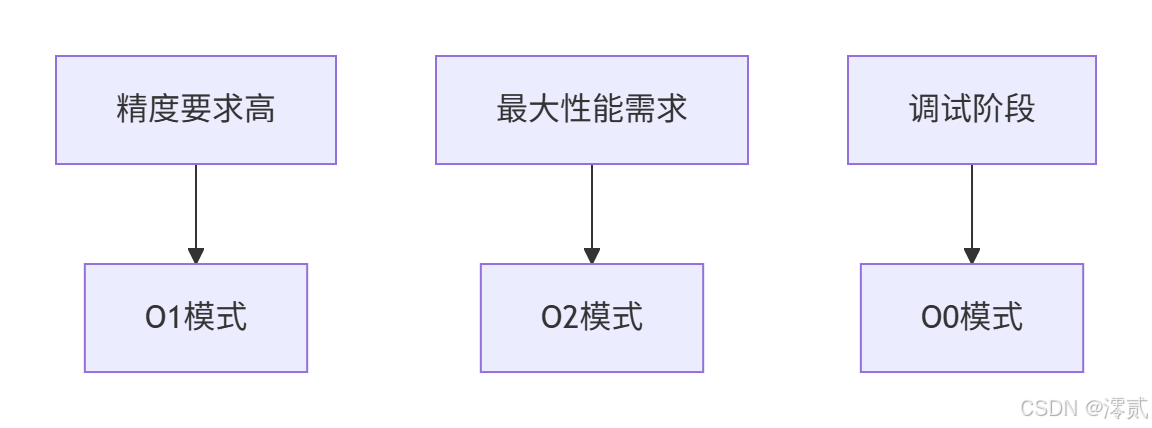
6.3 内存优化技术
6.3.1 显存分页管理
|
Pythonfrom apex.optimizers import FusedAdamoptimizer = FusedAdam(model.parameters(), lr=0.001, max_grad_norm=1.0, capturable=True) |
6.3.2 零冗余优化器
|
Pythonfrom apex.optimizers import FusedAdamfrom apex.parallel import DistributedDataParallelmodel = DistributedDataParallel(model)optimizer = FusedAdam(model.parameters()) |
6.4 通信优化
HCCL(Huawei Collection Communication Library) 优化:
|
Pythonimport torchimport torch_npufrom apex.parallel import DistributedDataParalleltorch.distributed.init_process_group(backend='hccl')model = DistributedDataParallel(model) |
7 性能分析与调优
7.1 性能评估指标
关键性能指标:
- 计算利用率:Cube利用率 >85%
- 内存带宽:>90%峰值带宽
- 流水线平衡:计算与内存搬运比例1:1
- 加速比:相对FP32训练的加速倍数
7.2 性能分析工具
使用msprof进行性能分析:
|
Bashmsprof op --application="python train.py" \ --aic-metrics=L2Cache,Memory \ --output=./prof |
7.3 典型性能数据
训练速度对比(基于昇腾Atlas 800T A2):

点击图片可查看完整电子表格
7.4 瓶颈诊断流程
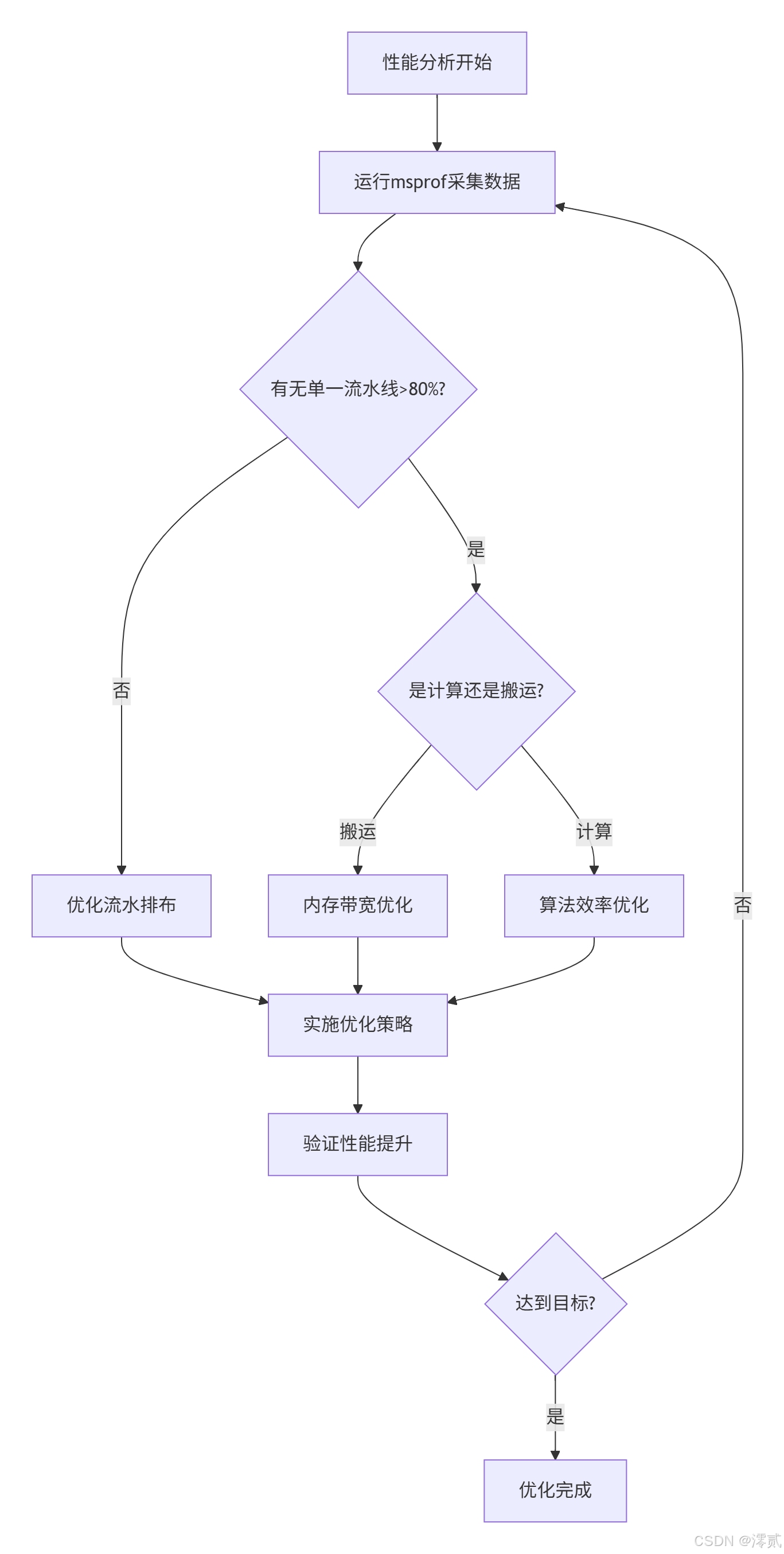
8 真实场景应用案例
8.1 DeepSeek-R1-671B模型训练
环境配置:
|
Bash# 双机环境变量配置export HCCL_IF_IP=141.61.41.164export TP_SOCKET_IFNAME="ens3f0"export OMP_NUM_THREADS=32 |
训练脚本:
|
Bashpython -m torch.distributed.launch --nproc_per_node=8 \ train.py \ --model DeepSeek-R1-671B \ --amp-opt-level O2 \ --gradient-fusion-size 16 \ --use-apex |
8.2 Qwen2.5-7B部署
推理优化配置:
|
YAMLvllm: tensor_parallel_size: 8 quantization: w8a8 amp_level: O2 max_batch_size: 32 |
8.3 性能对比
昇腾 vs A100训练速度:

点击图片可查看完整电子表格
9 未来发展与挑战
9.1 技术演进方向
- 自适应精度策略:根据模型结构动态调整FP16/FP32比例
- 稀疏训练支持:结合昇腾稀疏计算单元
- 跨架构兼容:统一接口支持多种AI处理器
9.2 社区生态建设
参与贡献途径:
9.3 开放性问题讨论
- 如何平衡混合精度训练中的速度与精度?
- 动态形状模型如何实现最佳优化?
- 分布式训练中如何优化跨节点通信?
总结
本文系统介绍了apex for Ascend在昇腾AI处理器上的编译、优化和应用全流程。通过深入分析架构原理、详细编译步骤、高级优化技术和真实场景验证,展示了如何在昇腾平台上实现高效的混合精度训练。关键要点包括:
- 架构适配:充分利用昇腾AIC/AIV分离架构特性
- 编译优化:合理配置Python环境和编译参数
- 性能调优:梯度融合+内存优化+通信加速的组合策略
- 实用技巧:动态损失缩放+激活检查点+数据流水线优化
随着昇腾生态的不断发展,apex for Ascend将持续优化,为AI训练提供更高效、更易用的解决方案。
参考资源

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 8
8 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)