[CVPR 2017]Improving Pairwise Ranking for Multi-label Image Classification
计算机-人工智能-神经网络预测多标签图像分类决策阈值和决策个数

目录
2.4.2. Comparison to Related Loss Functions
1. 心得
(1)啊...很硬货...虽然方法很简单但是一堆证明
2. 论文逐段精读
2.1. Abstract
①以前多标签的损失都是不平滑的也很难优化
②作者设计了成对损失,很平滑
2.2. Introduction
①现有的方法可能把多标签转化为多个二标签分类
②多标签精准匹配:
其中是第
个样本的预测标签,
是第
个样本的真实标签,
是indicator function(正确返回1不正确返回0),但这个指标太硬了,多标签错一个都0分
③稍微软一点的汉明距离:
用真实和预测算并集得到合集减去正确预测的真实和预测的交集得到哪些错了(这句话我一口气写了好长),最小化预测错误的个数
④排序指标:
对于一个样本,正类置信度应该高于负类
⑤排序分类示意:
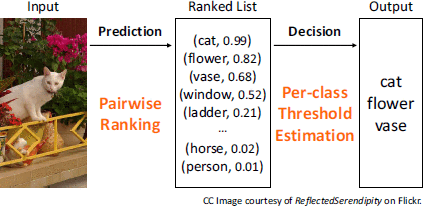
这样分类忽视了图片内容
⑥作者设计了一个平滑近似的log-sum-up的损失
2.3. Related Work
①介绍了一些方法
2.4. Approach
①设数据集为,其中
是第
个图像,
是其对应的标签
②标签集:,每个图片有不一样的标签个数
③作者将求解流程分为两步,第一步是将样本特征维度映射到标签维度得到logits
,第二步是决策
2.4.1. Label Prediction
①含有参数的标签预测模型
需要优化:
其中是损失,
是正则化项
②对于样本的logits,正例的元素的值理应比负例元素的值大:
其中下标代表第那么多个元素
③设计排名hinge损失函数:
其中是控制边缘的超参数,一般设置为1
④log-sum-exp pairwise (LSEP)平滑近似损失:
这个公式会渐进地逼近上一个hinge损失函数,且作者觉得这个函数不是线性突变的,是平滑的容易优化
⑤两两配对需要的时间复杂度,对于过多标签来说计算量很大。作者想把自己的损失变成线性的,使用word2vec的负采样技术(负例太多了所以只采样部分来算损失),采样
个记作
。新损失为:
⑥新损失的梯度:
其中
asymptotically adv.渐近地
2.4.2. Comparison to Related Loss Functions
①WARP损失:
其中是正类标签
的预测排名,
是单调函数。虽然这个有权重系数,但整体来说还是不平滑的
②Back-propagation for multi-label learning(BP-MLL)
它可以渐进等于去掉e低的损失:
monotonically adv.单调地;单调地,无变化地
2.4.3. Label Decision
①作者设计一个MLP去预测标签数和最佳阈值
②使用Softmax损失(还有这种玩意儿??):
其中代表向量
的第
个元素
③把阈值预测假设为一个维回归,去预测
个类别每个的阈值:
其中是MLP得到的决策向量
④缓解一下排序损失的交叉熵损失:
其中是
2.4.4. Implementation Details
①主干:VGG 16
②数据集:ImageNet ILSVRC
③最大标签预测数量被设置为4因为NUS-WIDE和MS-COCO中88.6%和83.7%的标签数量小于或等于4
④Epoch:50
⑤参数优化:动量为0.9,学习率为0.001的SGD
2.5. Theoretical Analysis
①贝叶斯预测规则,表示对于任意图像,预测它的标签应该也遵从
在标签集
中的分布:
其中表示标签集中第
个标签
②对于最优解,加上一个常数不会改变排序和概率比:
③最小化期望风险:
④LSEP损失等价于:
定义的话,可以改写期望风险:
⑤改写后期望风险的导数:
其中
⑥将导数置为0(最优解),全局最小值为:
logarithmic adj.对数(性,式)的
2.6. Experiments
①数据集:VOC2007,NUS-WIDE,MS-COCO
2.6.1. Methodology
①图片数量:VOC2007,NUS-WIDE,MS-COCO分别有10K图片(20个物体),260K图片(81个物体),120K图片(80个物体)
2.6.2. Baselines
①在标签预测方面,把LSEP和softmax, the standard pairwise ranking, WARP, 和BP-MLL对比
②在标签决策方面,与top k作对比
2.6.3. Results and Discussion
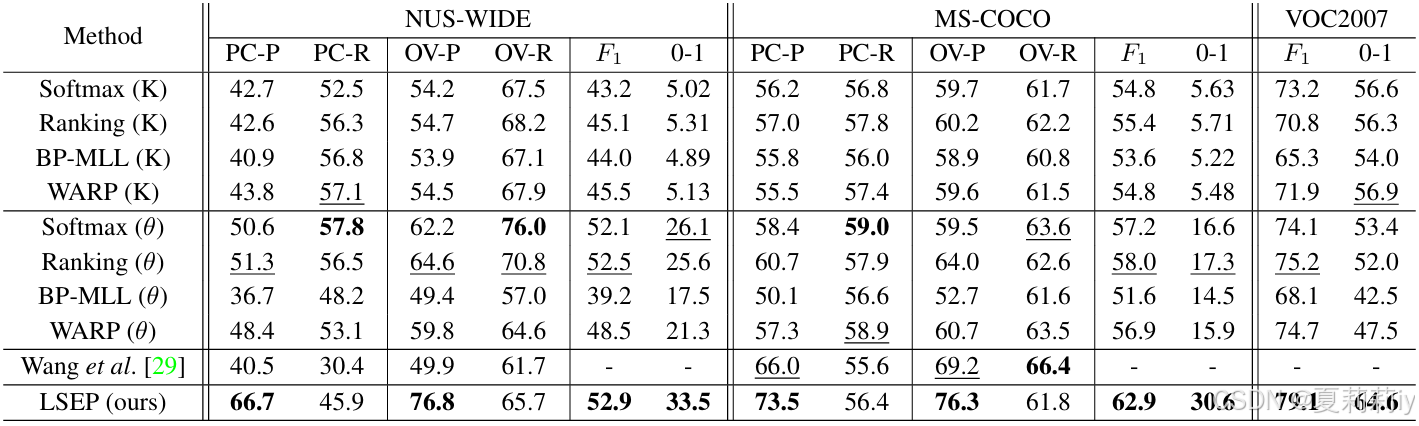
①对比实验:
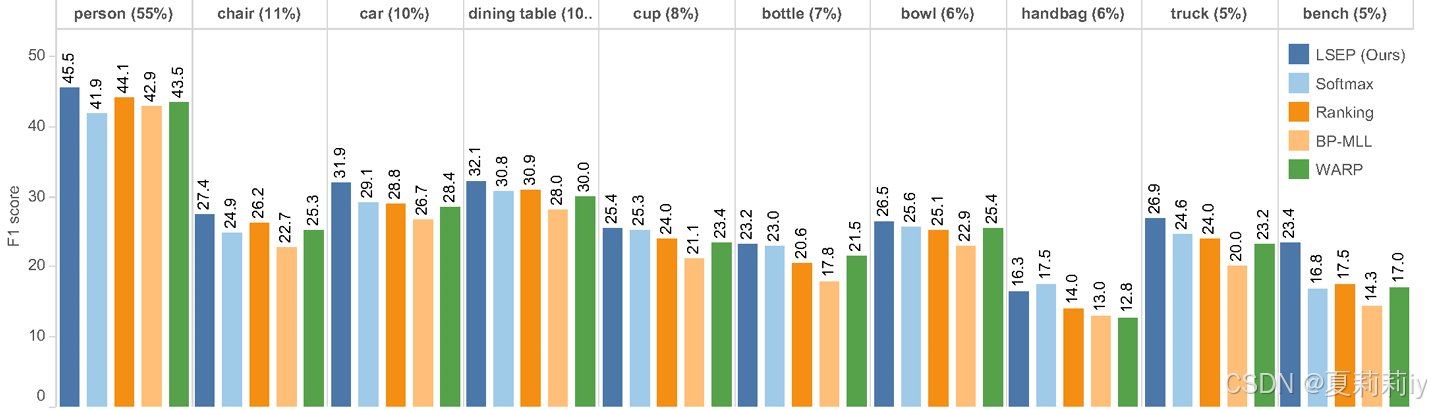
②每个类在不同标签预测下的F1分数:
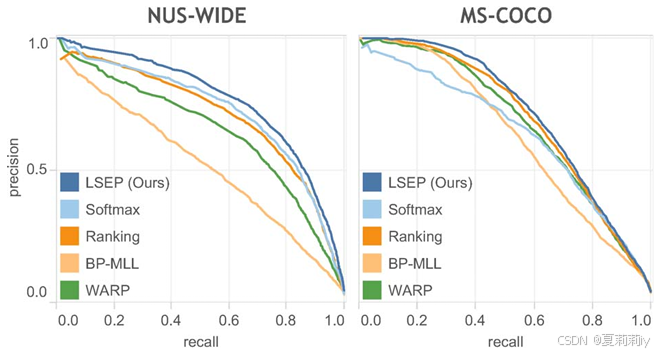
③
④和不同标签决策方法的对比:

⑤对于不同图片的预测阈值:

⑥不同方法下的预测情况,蓝色为TP,红色为FP,灰色是FN
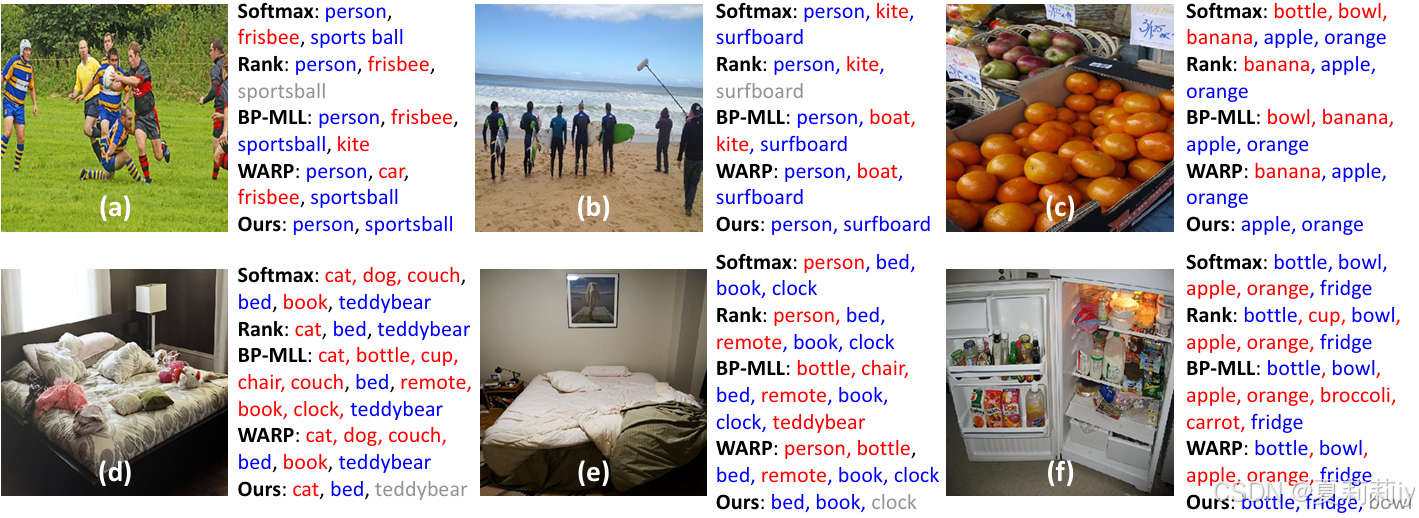
2.7. Conclusion
~

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 16
16 0
0- 0



 已为社区贡献33条内容
已为社区贡献33条内容

所有评论(0)