CANN 7升级到CANN 8常见问题与性能分析测评
随着昇腾AI计算平台的持续演进,CANN作为昇腾芯片的核心软件栈,它的版本迭代对模型训练性能提升非常大。本次测评主要是分析从CANN 7.0.1.3升级到CANN 8.0 RC2过程中常见的问题及性能差异,为大家提供实用的升级指导和性能优化建议。
引言
随着昇腾AI计算平台的持续演进,CANN作为昇腾芯片的核心软件栈,它的版本迭代对模型训练性能提升非常大。本次测评主要是分析从CANN 7.0.1.3升级到CANN 8.0 RC2过程中常见的问题及性能差异,为大家提供实用的升级指导和性能优化建议。
CANN 7与CANN 8环境对比
为确保分析的准确性,我保持除CANN版本外的其他环境因素一致,具体统计如下:
|
环境要素 |
CANN 7.0.1.3 |
CANN 8.0 RC2 |
|
Python |
3.10 |
3.10 |
|
HDK |
23.0.6 |
23.0.6 |
|
CANN |
CANN 7.0.1.3 |
CANN 8.0 RC2 |
|
Torch |
2.1.0 |
2.1.0 |
|
Torch_npu |
2.1.0 |
2.1.0post6 |
|
Apex |
apex-0.1+ascend-cp310-cp310-linux_aarch64.whl torchair-0.1-py3-none-any.whl |
apex-0.1+ascend-cp310-cp310-linux_aarch64.whl torchair-0.1-py3-none-any.whl |
Profiling数据采集与分析流程
1. 数据采集流程
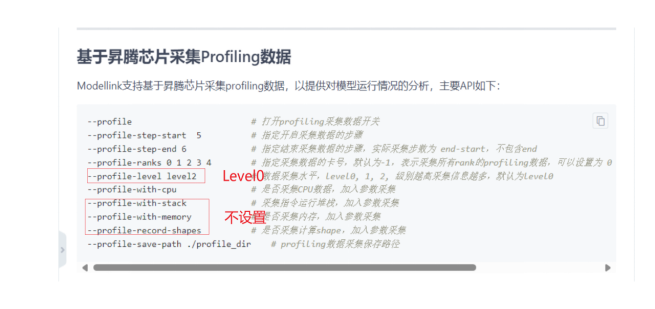
基于昇腾芯片采集Profiling数据
在ModelLink框架中,我通过以下API进行Profiling数据采集:

关键参数说明:
l --profile: 打开Profiling数据采集开关
l --profile-step-start: 指定开启采集数据的步骤
l --profile-step-end: 指定结束采集数据的步骤,实际采集步数为end-start,不包含end
l --profile-ranks: 指定采集数据的卡号,默认为-1,表示采集所有rank的Profiling数据
l --profile-level: 数据采集水平,level 0, 1, 2,级别越高采集信息越多,默认为level 0
l --profile-with-cpu: 是否采集CPU数据
l --profile-with-stack: 采集指令运行堆栈
l --profile-with-memory: 是否采集内存
l --profile-record-shapes: 是否采集计算shape
l --profile-save-path: Profiling数据集保存路径
确认数据是否可用
打开采集到的某张卡数据(*ascend_pt结尾的文件夹),可用的数据应该具备以下文件:
./profiler_info_x.json,
/ASCEND PROFILER_OUTPUT/step_trace_time.csv,
./ASCEND_PROFILER_OUTPUT/trace_view.json,
./ASCEND_PROFILER_OUTPUT/kernel_details.csv,
./ASCEND_PROFILER_OUTPUT/communication.json,
./ASCEND_PROFILER_OUTPUT/communication_matrix.json或者具备:
analysis.db
ascend_pytorch_profiler_{rank_id}.db2. 数据解析流程
1. 确认数据是否可用
2. 将所有卡的数据拷贝并汇集到一个目录下,运行命令:

3. 生成cluster_analysis_output文件夹,包含以下交付件:
l summary.csv
l timeline.csv
l communication.csv
l kernel_details.csv
l step_trace_time.csv
3. 数据分析流程
MindStudio Insight是可视化工具,可以将解析后的日志信息可视化,方便用户比较差异。
定位异常算子流程
1. 在概览(Summary)界面,输入模型脚本对应的并行策略值,pp,tp设置和推理的值设置一致
2. 在"计算/通信概览"区域,分别选择"迭代ID"和"通信域",查看柱状图,观察总计算时间和未被覆盖的通信时间时长
3. 单击慢卡"通信算子详情"列的"查看更多",可查看每个通信算子耗时
4. 单击算子"总时间(ms)"后的排序按钮,进行降序排序,可以看到耗时最长的算子
5. 分别在"HCCL"和"通信时长"区域图表中,可看到该算子的耗时不对等
6. 通过上述途径定位异常算子
分析异常算子流程
1. 将定位到的最快卡和最慢卡的原始数据汇总至同一目录,并导入MindStudio Insight工具
2. 打开通信(Communication)界面,选择"通信耗时分析",在"算子名称"选项中输入定位到的慢卡算子名称,选择该算子
3. 在"HCCL"区域,分别找到该算子耗时最短和耗时最长的卡,在对应柱状图上右键单击"跳转至时间线页面"
4. 跳转至时间线(Timeline)界面对应卡的算子上
5. 单击"泳道置顶"按钮,分别将所属卡的泳道置顶,对该算子进行比较分析
6. 对所属卡其它进程的算子信息进行比较分析,定位慢卡原因
常见问题与解决方案
问题1:提示HCCL集合操作超时
现象:CANN 7训练5节点正常,但CANN 8训练5节点异常,提示HCCL集合操作超时
原因:
1. 使用CANN 8版本为CANN 8 RC3版本,存在偶发bug
2. 超时响应时间为默认值180太小
解决方案:
1. 降低到CANN 8 RC2版本后,相同模型可以跑通
2. 推荐节点数为2的幂次方
3. 提高响应时间:

问题2:通过环境变量设置获得profile日志,无法获得完整的日志信息
原因:环境变量不适合大模型采集,不能控制step
解决方案:建议使用MindSpore Profiler的方式
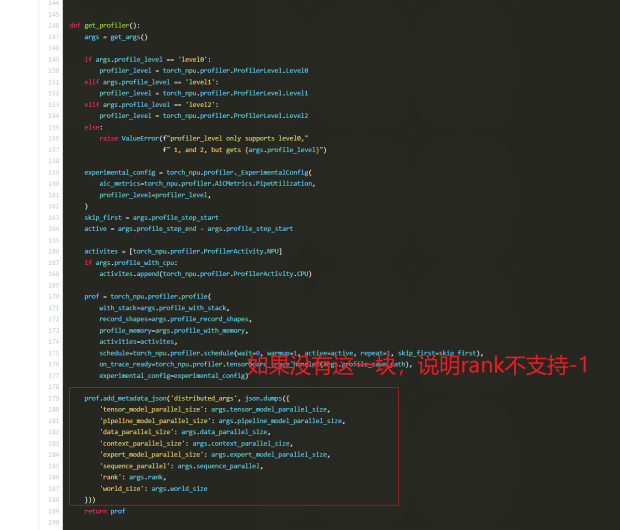
问题3:MindSpore Profiler方式采集时profile-ranks设置为-1会报错
原因:torch_npu新版的代码存在更新
解决方案:手动设置,假如2节点16卡,则设置为0-15。如果版本更老,可以根据教程手动采集。
问题4:发现随着节点数增加和layer模型层数增加,CANN 8的性能对比CANN 7下降
原因:CANN 8更新后,将CANN 7内很多融合算子拆开计算算子和通信算子,导致CANN 8的通信算子大大增加。当节点增大、通信更多的情况下,通信性能下降导致计算算子的优化部分被掩盖,总性能反而下降。
解决方案:开启MC2融合算子和其他优化算子,可以将CANN 8性能提升上去。
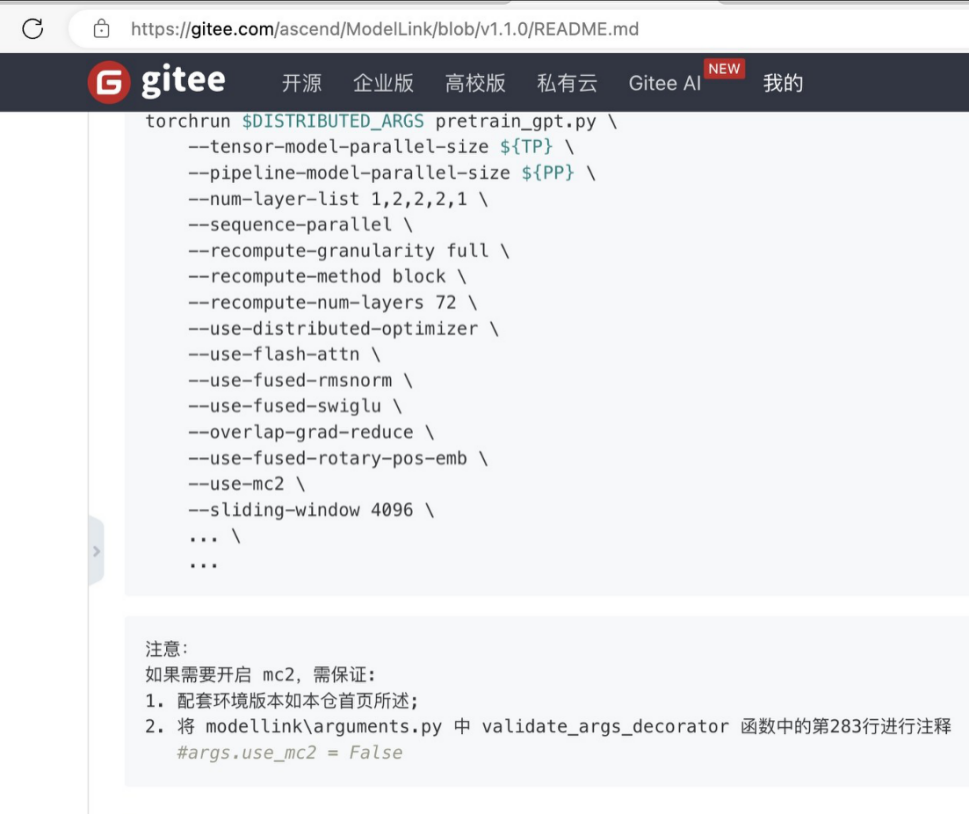 具体操作:
具体操作:
1. 需保证配套环境版本符合要求
2. 将modellink\arguments.py中validate_args_decorator函数中的第283行进行注释:

MC2优势:MC2支持指令微调,在微调效果保持一致的前提下,MindSpeed-LLM可以表现出优异性能,特别是在大规模分布式训练场景下。
性能对比分析
通过对比CANN 7和CANN 8在相同环境下的训练性能,我们发现:
1. 基础性能差异:在不开启MC2融合模式的情况下,CANN 8的通信算子数量显著增加,导致在大规模分布式训练中(如5节点以上)性能比CANN 7下降约10-15%。
2. MC2融合优化效果:开启MC2融合模式后,CANN 8的性能可以达到与CANN 7相当的水平,甚至在某些场景下略优于CANN 7。MC2通过融合多个通信操作,减少了通信次数,提升了整体性能。
3. 通信优化效果:CANN 8通过优化通信算法,减少了通信延迟,特别是在大规模集群(如16卡以上)下,通信优化效果更加明显。
总结
CANN 8在升级后带来了更丰富的功能和更好的硬件支持,但在大规模分布式训练场景下,由于通信算子数量增加,基础性能可能不如CANN 7。不过,通过开启MC2融合模式等优化措施,CANN 8的性能可以得到显著提升,达到甚至超过CANN 7的水平。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 3
3 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)