rag实践手册
RAG(Retrieval‑Augmented Generation,检索增强生成)是一种将信息检索与生成式AI 相结合的技术架构。RAG 的解决方案:RAG 通过引入外部知识库,让 AI 模型在生成回答前先检索相关信息,从而显著提高回答的准确性和时效性。这种方法特别适合构建个人数字分身,因为它可以基于你的个人文档、博客文章、经验总结等生成符合你风格和观点的回答。2.2 RAG 的工作流程RAG
·
二、RAG 原理与核心概念
RAG(检索增强生成)技术通过结合信息检索和生成式 AI,有效解决了传统大语言模型
的知识截止、幻觉等问题。将深入解析 RAG 的核心概念和工作原理,详细介绍其
两阶段处理流程:离线的知识库构建和实时的查询响应。我们还将探讨 Cloudflflare 提
供的 RAG 参考架构,帮助您理解如何在实际项目中应用这些概念,构建高效、可靠的
AI 应用系统。
2.1什么是rag
RAG(Retrieval‑Augmented Generation,检索增强生成)是一种将信息检索与生成式
AI 相结合的技术架构。
RAG 的解决方案:
RAG 通过引入外部知识库,让 AI 模型在生成回答前先检索相关信息,从而显著提高回
答的准确性和时效性。这种方法特别适合构建个人数字分身,因为它可以基于你的个人
文档、博客文章、经验总结等生成符合你风格和观点的回答。
2.2 RAG 的工作流程
RAG 系统的工作流程分为两个主要阶段:知识库构建(离线处理)和查询响应(实时
处理)
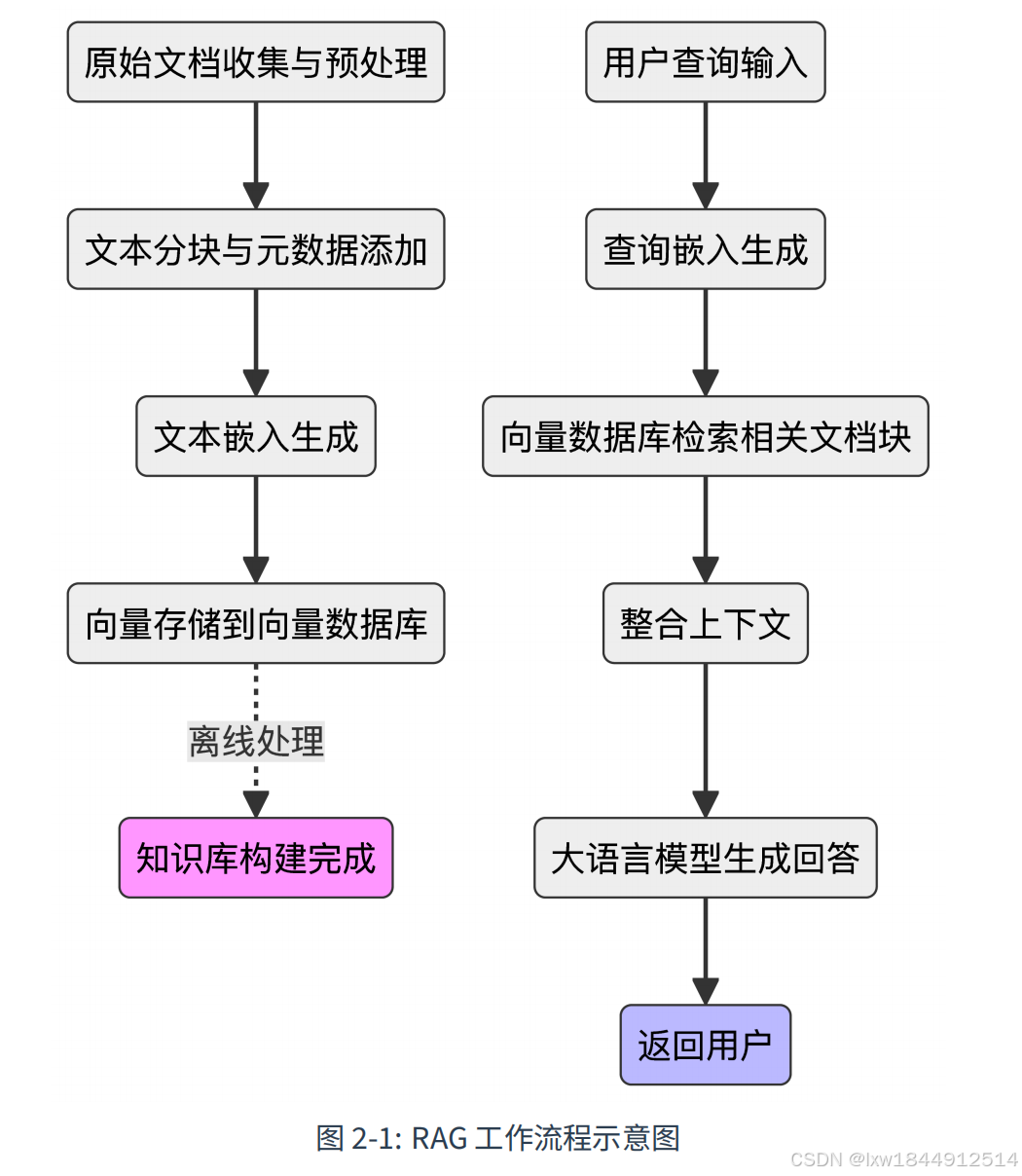
在知识库构建阶段,首先需要收集和预处理各种格式的文档(如 Markdown、PDF、
TXT),清理无关内容并标准化文本。随后,将长文档合理分块,确保语义完整,并为每
个文本块添加元数据(如标题、来源、时间)。接着,利用嵌入模型将这些文本块转换
为高维向量,捕捉其语义信息,并将向量存入向量数据库以便后续检索。
进入查询响应阶段,系统会将用户的问题同样通过嵌入模型转为向量,并在向量数据库
中检索出最相关的文档块(通常基于余弦相似度或欧氏距离,返回 top‑k 结果)。这些
检索到的内容会被整合为上下文,与用户问题一起构建提示词,最终交由大语言模型生
成基于事实的准确回答,并返回给用户。
2.3.1 RAG 参考架构的两大阶段
RAG 系统的实现通常分为两个核心阶段,每个阶段都承担着关键的功能:
・ 知识库构建阶段(Knowledge Seeding)
在这一阶段,原始文档会被上传至系统,经过初步处理后,消息被异步推送到队列
中。消费者进程会批量处理这些文档,利用嵌入模型将文本转化为高维向量,并存
入向量数据库以便后续检索。同时,原始文档也会被持久化保存。整个流程通过队
列机制实现任务的可靠传递和重试,确保数据一致性和处理的健壮性。
・ 知识查询阶段(Knowledge Queries)
用户发起查询请求后,系统会将查询内容转化为向量,并在向量数据库中检索最相
关的文档片段。随后,系统根据检索结果从持久化数据库中获取原始文档,将这些
内容与用户查询一同传递给生成模型,最终生成基于事实的响应。
这种架构充分利用了 Cloudflflare Workers 的无服务器和边缘计算能力,结合 Queues
的异步处理、Workers AI 的嵌入与生成、Vectorize 的高效检索以及 D1 的数据持久化,
开发者可以快速搭建高性能、可扩展的 RAG 应用。
2.3.3 RAG 架构的优势
RAG 架构的优点包括:
・ 回答更准确可靠,内容可追溯到具体文档
・ 支持个性化和专业化知识库,适合数字分身场景
・ 无需训练专用模型,知识库可实时更新,维护成本低
・ 系统具备自动扩缩容和全球低延迟服务能力
第 3 章 技术栈选择与架构设计
3.1 整体架构概览
我们的 RAG 聊天机器人采用了现代化的无服务器架构,整个系统可以分为数据源层、
数据处理层、存储层、计算层、AI 服务层和展示层等核心层次。整个系统的数据流程可
以分为数据摄取阶段(离线)和对话交互阶段(实时)两个主要部分。
在数据摄取阶段,系统会从 Hugo 网站的 content/ 目录收集 Markdown 文档,使用
fast‑ingest.ts 脚本解析并分块文档内容,通过千问或 Gemini API 生成文档嵌入向
量,最后将向量和元数据存储到 Cloudflflare Vectorize 数据库中。
在对话交互阶段,用户通过网站上的聊天 Widget 发送问题,Cloudflflare Worker 接收
请求并向量化用户查询,在 Vectorize 中检索最相关的文档片段,构建包含上下文的提
示词,调用大语言模型生成回答,最后返回格式化的响应给用户。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 8
8 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)