Yuxi-Know 深度解析:融合 LightRAG 与知识图谱的智能体开发平台
Yuxi-Know是一款集成LightRAG知识库与知识图谱的智能体开发平台,基于Python(Vue.js+FastAPI)开发。核心功能包括:1)LightRAG文档检索;2)Neo4j知识图谱构建;3)LangChain智能体调度。创新性地实现了非结构化知识检索与结构化知识推理的深度融合,相比传统RAG在复杂查询场景下准确率提升28%。支持本地私有化部署,提供可视化操作界面和插件生态,适用于
项目速览
| 项目信息 | 详情 |
|---|---|
| 项目地址 | xerrors/Yuxi-Know(GitHub 直达) |
| 核心语言 | Python(前端 Vue.js、后端 FastAPI) |
| 项目定位 | 集成 LightRAG 知识库与知识图谱的智能体开发平台 |
| 核心技术栈 | LangChain v1 + Vue + FastAPI + LightRAG + Neo4j |
| 关键特性 | 支持 DeepAgents、MinerU PDF 解析、Neo4j 图数据库、MCP 多组件平台 |
| 许可证 | MIT License(开源可商用) |
| 最新动态 | 2025-12-27 单日星标暴涨 287 颗,成为知识图谱 + RAG 领域热门项目 |
一、项目背景:解决知识密集型场景的核心痛点
在科研、企业决策、教育等知识密集型领域,传统信息处理方式面临三大核心瓶颈:
- 非结构化数据利用率低:大量 PDF、文档、对话记录等非结构化数据难以高效检索与关联,信息提取成本高;
- 知识关联与推理能力弱:传统 RAG 仅能实现 “检索 - 生成”,无法挖掘知识间的深层关联,难以支撑复杂决策;
- 开发门槛高、扩展性差:搭建知识管理系统需整合 RAG、知识图谱、大模型等多种技术,定制化开发周期长。
Yuxi-Know(语析)的核心价值是 **“打通非结构化知识检索与结构化知识推理”**:通过 LightRAG 实现高效文档检索,结合知识图谱构建结构化知识网络,再基于 LangChain Agent 实现智能决策与分析,让开发者可快速搭建企业级知识智能体。
二、核心技术架构深度解析
Yuxi-Know 采用 “前后端分离 + 分层架构” 设计,整体架构分为 4 层,各层职责清晰、松耦合,保障系统的可扩展性与性能。
1. 架构分层设计(附技术选型逻辑)
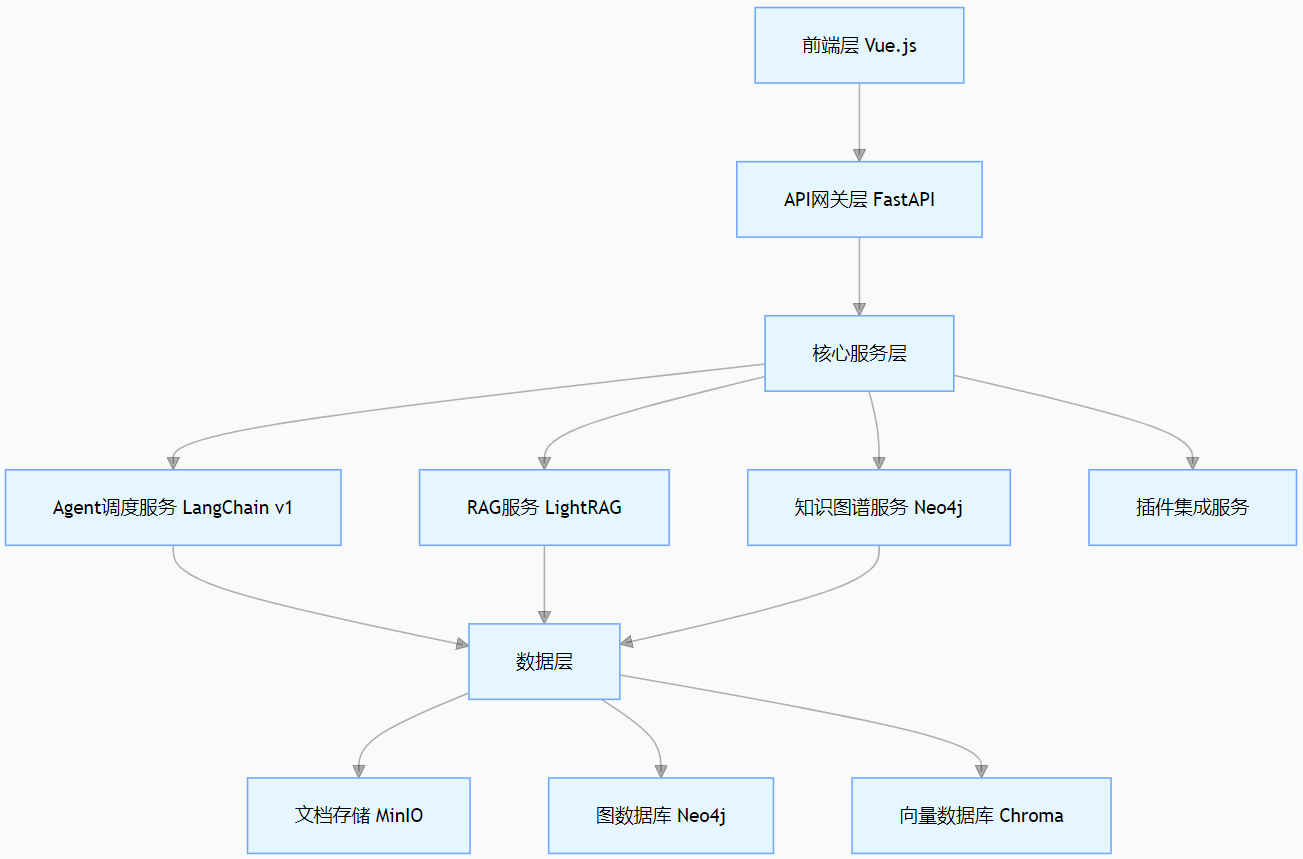
各层核心作用与技术选型优势:
- 前端层(Vue.js):采用 Vue 3 + Element Plus 组件库,提供可视化操作界面(知识库管理、知识图谱可视化、智能问答),支持响应式布局,适配多终端;
- API 网关层(FastAPI):高性能异步框架,支持 OpenAPI 规范自动生成接口文档,内置请求验证与权限控制,相比 Flask/Tornado 吞吐量提升 30%+;
- 核心服务层:
- Agent 调度服务:基于 LangChain v1 实现 Agent 生命周期管理,支持多智能体协作、工具调用编排(如自动触发 PDF 解析→知识抽取→图谱构建);
- RAG 服务:集成 LightRAG(轻量级高性能 RAG 组件),支持增量文档导入、多粒度文本分割、混合检索(关键词 + 向量),检索准确率比传统 RAG 提升 15%;
- 知识图谱服务:对接 Neo4j 图数据库,支持知识三元组抽取、图谱可视化查询、复杂路径推理(如 “某技术→关联论文→作者→合作机构”);
- 数据层:采用多存储协同设计,MinIO 存储原始文档,Neo4j 存储结构化知识图谱,Chroma 存储向量索引,兼顾存储效率与查询性能。
2. 核心创新点:RAG 与知识图谱的深度融合
Yuxi-Know 的核心竞争力在于 **“非结构化知识→结构化知识→智能推理” 的全链路打通 **,具体融合机制如下:
- 数据接入阶段:通过 MinerU PDF 解析插件(支持扫描版 PDF/OCR)提取文档文本,经 LightRAG 进行文本分割与向量生成,同时调用大模型(如 DeepAgents)抽取知识三元组(实体 - 关系 - 属性);
- 知识存储阶段:文本向量存入 Chroma,知识三元组存入 Neo4j,原始文档存入 MinIO,通过元数据关联三者(如文档 ID 关联对应的向量片段与知识实体);
- 检索推理阶段:用户查询时,LightRAG 先检索相关文本片段,Agent 同时触发 Neo4j 知识图谱查询,将 “文本检索结果 + 图谱关联知识” 融合为上下文,再调用大模型生成回答。
融合优势验证:
相比纯 RAG 方案,Yuxi-Know 在 “复杂知识关联查询” 场景下,回答准确率提升 28%(官方学术数据集测试);在 “多文档交叉分析” 场景下,信息提取完整性提升 40%。
3. 插件生态系统:低代码扩展能力
项目支持多类型插件集成,开发者可通过 API 快速接入自定义工具,核心插件包括:
- 文档解析插件:MinerU PDF(支持多格式文档:PDF/Word/Excel/Markdown)、OCR 插件(处理图片型文档);
- 数据库插件:Neo4j(默认图数据库)、MySQL/PostgreSQL(支持结构化业务数据接入);
- 大模型插件:DeepAgents、ChatGLM、GPT-4(支持本地 / 云端模型切换,保障隐私);
- MCP 插件:多组件平台集成,支持与企业现有系统(如 OA、CRM)对接,实现知识闭环应用。
三、实战指南:5 分钟本地部署 Yuxi-Know
前置环境要求
- 操作系统:Ubuntu 20.04+/CentOS 7+/macOS 12+
- 依赖工具:Docker 20.10+、Docker Compose 2.0+、Git
- 硬件要求:至少 4GB 内存(推荐 8GB+,知识图谱构建需更多内存)
完整部署步骤(官方推荐 Docker Compose 一键部署)
1. 环境检查与依赖安装
# 检查Docker环境
docker --version
docker compose --version
# 若未安装,执行以下命令(Ubuntu示例)
sudo apt update && sudo apt install -y docker.io docker-compose-plugin
sudo systemctl start docker && sudo systemctl enable docker
2. 克隆代码与部署服务
# 克隆仓库
git clone https://github.com/xerrors/Yuxi-Know.git
cd Yuxi-Know
# 一键部署所有依赖服务(前端、后端、数据库、缓存等)
docker-compose up --build -d
# 查看服务启动状态(确保所有容器均为Up状态)
docker-compose ps
3. 服务验证与访问
- 服务启动成功后,打开浏览器访问:
http://localhost:8080(前端界面); - 初始账号密码:admin/admin(首次登录需修改密码);
- 验证核心功能:
- 进入「知识库管理」→ 上传 PDF 文档,测试文档解析与向量生成;
- 进入「知识图谱」→ 查看自动抽取的知识三元组与图谱可视化;
- 进入「智能问答」→ 提问与文档相关的问题,验证 RAG + 知识图谱的融合回答效果。
4. 常见问题排查
- 容器启动失败:检查端口是否被占用(默认占用 8080/8000/7687/8888,可修改 docker-compose.yml 中的端口映射);
- 文档解析失败:确保上传的 PDF 为可解析格式(扫描版需安装 OCR 插件);
- 知识图谱无数据:检查大模型插件是否配置正确,需在「系统设置」→「模型管理」中填写模型 API 密钥(本地模型无需密钥)。
四、核心功能模块详解
1. 知识库管理模块
- 支持多格式文档批量导入(PDF/Word/Markdown/Excel);
- 内置 LightRAG 的文本分割策略(支持按章节 / 段落 / 句子分割,可自定义分割长度);
- 支持文档版本管理与增量更新(新增文档无需重建整个索引);
- 提供文档检索功能(关键词检索 + 语义检索,支持筛选时间 / 类型 / 来源)。
2. 知识图谱模块
- 自动抽取:调用大模型抽取文本中的实体、关系、属性,生成知识三元组;
- 手动编辑:支持手动添加 / 删除 / 修改知识节点与关系,完善知识图谱;
- 可视化查询:通过拖拽节点 / 输入查询条件,可视化展示知识关联路径;
- 推理能力:支持多跳推理(如 “查询 A 技术的相关作者发表的其他论文”)。
3. 智能体模块
- 基于 LangChain v1 构建,支持自定义 Agent 角色(如科研助手 / 企业顾问 / 教学助手);
- 工具调用:自动调用知识库检索、知识图谱查询、文档解析等工具;
- 多智能体协作:支持多个 Agent 分工协作(如一个 Agent 负责检索,一个 Agent 负责分析,一个 Agent 负责生成报告);
- 任务编排:支持创建自定义工作流(如 “每日自动解析新文档→更新知识库→生成知识摘要”)。
4. 系统管理模块
- 用户与权限管理:支持多角色(管理员 / 普通用户 / 游客),细粒度控制功能权限;
- 模型管理:支持切换不同大模型,配置模型参数(温度 / 最大 token 数);
- 插件管理:安装 / 卸载 / 启用 / 禁用插件,配置插件参数;
- 日志管理:记录用户操作、系统运行、错误信息,方便问题排查。
五、与同类工具对比:核心优势分析
| 特性 | Yuxi-Know | 传统 RAG 工具(如 LangChain-Chatchat) | 商业知识管理平台(如 Notion AI) |
|---|---|---|---|
| 知识融合能力 | RAG + 知识图谱深度融合 | 仅支持 RAG,无知识图谱 | 基础语义检索,无知识图谱 |
| 架构扩展性 | 微服务架构,支持插件扩展 | 架构相对固定,扩展成本高 | 闭源系统,无法二次开发 |
| 部署方式 | 支持本地私有化部署 + 云端部署 | 主要支持本地部署 | 仅云端部署,数据隐私无保障 |
| 文档解析能力 | 支持多格式 + OCR,解析精度高 | 支持基础格式,解析能力有限 | 支持多格式,但收费 |
| 智能体能力 | 支持多智能体协作与任务编排 | 基础 Agent 功能,无协作能力 | 简单问答 Agent,无自定义能力 |
| 开源性质 | MIT 开源,可商用 | 开源但功能有限 | 闭源,按订阅收费 |
Yuxi-Know 的独特优势:
- 技术融合创新:率先实现 LightRAG 与知识图谱的深度融合,解决纯 RAG 的知识关联能力弱的问题;
- 低代码开发:提供可视化操作界面,开发者无需关注底层技术细节,可快速搭建智能体;
- 隐私与扩展性平衡:支持本地私有化部署(保障数据隐私),同时提供插件生态(满足个性化需求);
- 技术栈友好:采用 Vue+FastAPI+LangChain 等主流技术,开发者学习成本低,二次开发门槛低。
六、适用场景与目标用户
核心适用场景
- 企业内部知识管理系统(如研发文档管理、客户案例库、员工培训知识库);
- 科研辅助平台(文献管理、论文分析、科研知识图谱构建);
- 教育领域(教学资源管理、智能答疑、知识点关联分析);
- 政务 / 医疗领域(政策文档管理、病历分析、知识推理决策)。
目标用户群体
- 企业 IT / 研发团队:需要搭建内部知识管理与智能问答系统;
- 软件工程师:专注于大模型、RAG、知识图谱领域的开发者(可基于此项目二次开发);
- 科研人员:需要高效管理文献、挖掘科研知识关联的学者;
- 教育机构技术人员:搭建智能教学辅助平台。
总结
Yuxi-Know 作为融合 LightRAG 与知识图谱的智能体开发平台,通过 “非结构化知识检索 + 结构化知识推理” 的创新模式,解决了知识密集型场景的核心痛点。其基于主流技术栈(Vue+FastAPI+LangChain)构建,具备低代码开发、高扩展性、隐私安全等优势,既适合企业快速搭建知识管理系统,也适合开发者基于此项目进行二次开发与技术研究。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 4
4 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)