[ICLR 2025]Rethinking Classifier Re-Training in Long-Tailed Recognition: A Simple Logits Retargeting
计算机-人工智能-标签平滑长尾图像分类

目录
2.4. Rethinking Classifier Re-Training
2.4.1. Revisiting Classifier Re-Training methods
2.5.1. Deep Dive into Logits Magnitude
2.6.1. Datasets and Implementation Details
1. 心得
(1)如果没有数学基础要看很久,比较硬货
2. 论文逐段精读
2.1. Abstract
①先前的长尾工作将训练和分类分开
2.2. Introduction
①对于长尾问题,通常使用解耦方法。即先学习表征,再重学习分类
②VanillaCross-Entropy(CE)和作者提出的logits retargeting approach (LORT)在CIFAR 100-LT对于不同基数类别的正负例logits分布:
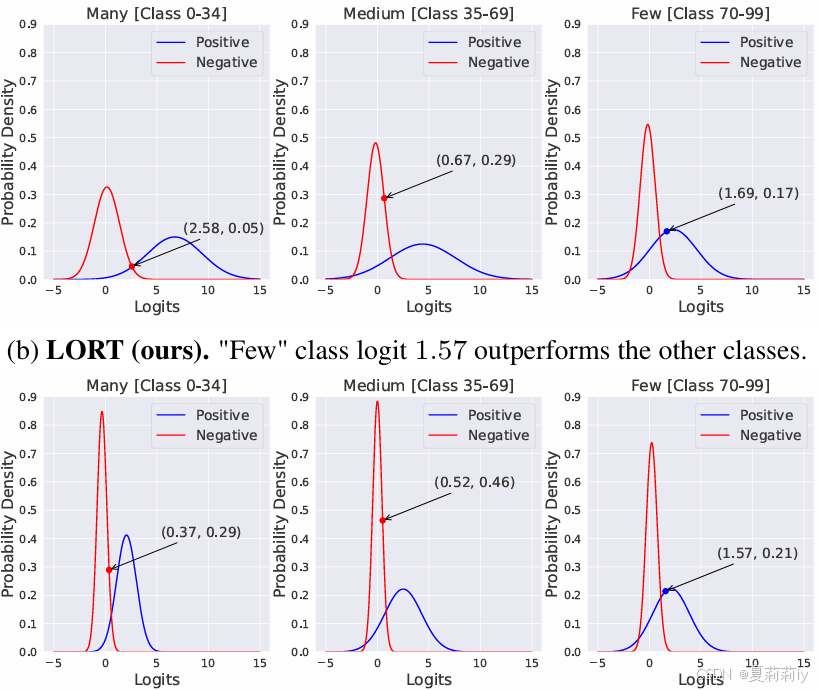
discernibility n.辨别能力;分辨率;鉴别力
2.3. Related Work
①现有的长尾解决办法:重采样、损失加权、表征学习、分类器设计、解耦训练、数据增强
②举例一些解耦办法
2.4. Rethinking Classifier Re-Training
2.4.1. Revisiting Classifier Re-Training methods
①使用LTWB作为主干,在训练分类器的时候冻结主干
②对于个类别,第
个类别有
个样本
③图像加工后的特征表示为
④分类器权重:
⑤联合公式:
其中是分类器计算出的logits,
表示当前标签的重分配权重因子
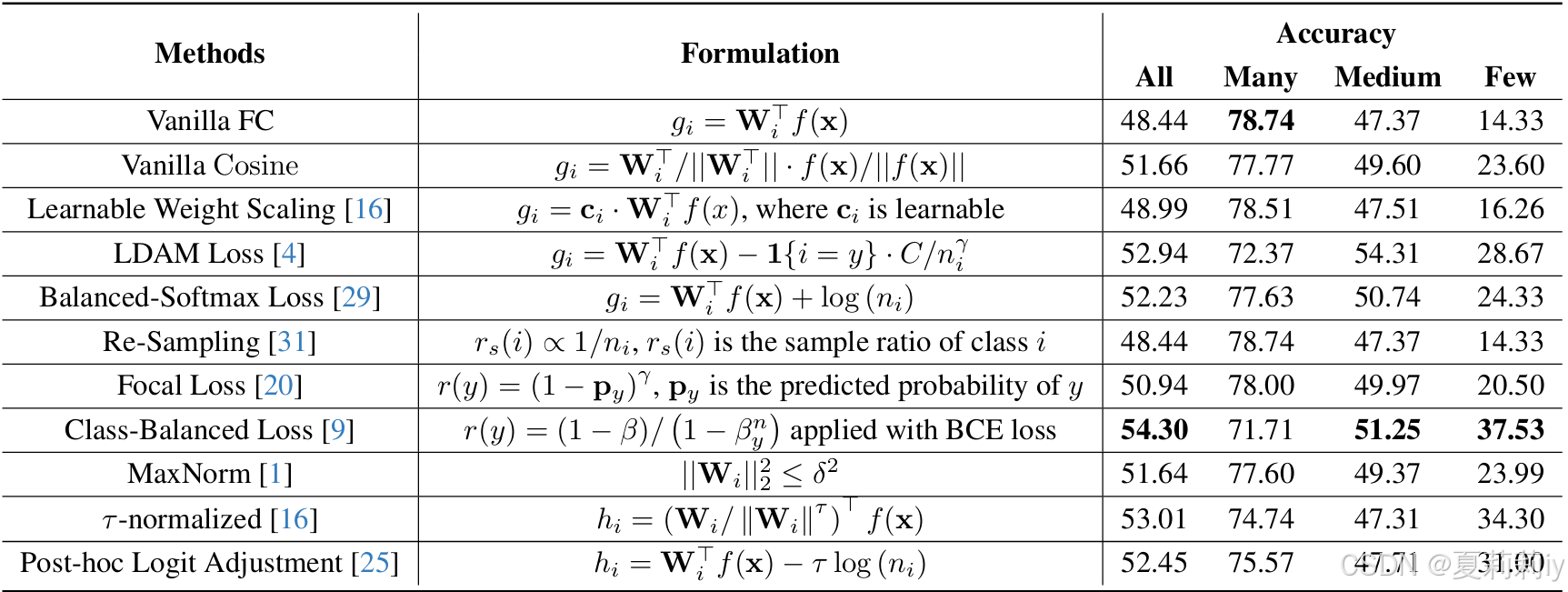
⑥CIFAR100-LT数据集下不同分类方法的测试:
2.4.2. Logits Magnitude
①先把权重换为独热编码:
然后让,
设为最终预测概率
②计算损失关于偏置的Hessian矩阵,并记为
:
其中是个半正定矩阵,因为对于任意
都有
③设正样本和负样本的logits分别为和
,定义Logits Magnitude
为正样本和负样本在样本
上的均值:
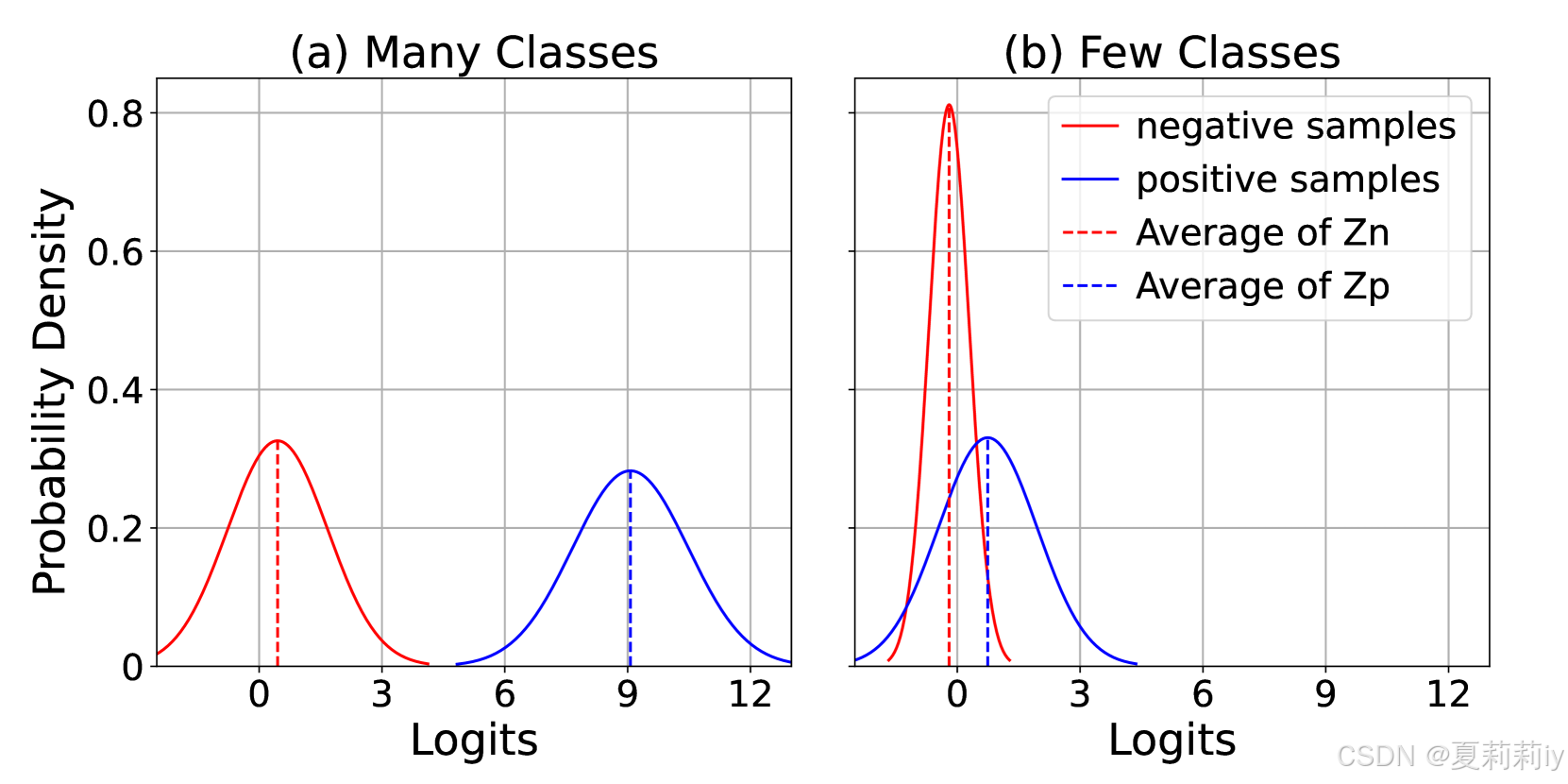
④多数类样本和少数类样本的Logits均值和方差:
⑤当参数和
优化最优
和
时,可以有一系列的收敛点
,让
(这个替代需要证明,就是哪怕是
,求出来最后的
也是一样的):
⑥将随机量的期望设置为0
:
其中是确定数字所以期望等于自己,然后说明随意值
范数期望可以比原始值
更大。
下面那个期望是通过:
得到的
因此作者觉得通过Weight Norm改变模长可能是无效的
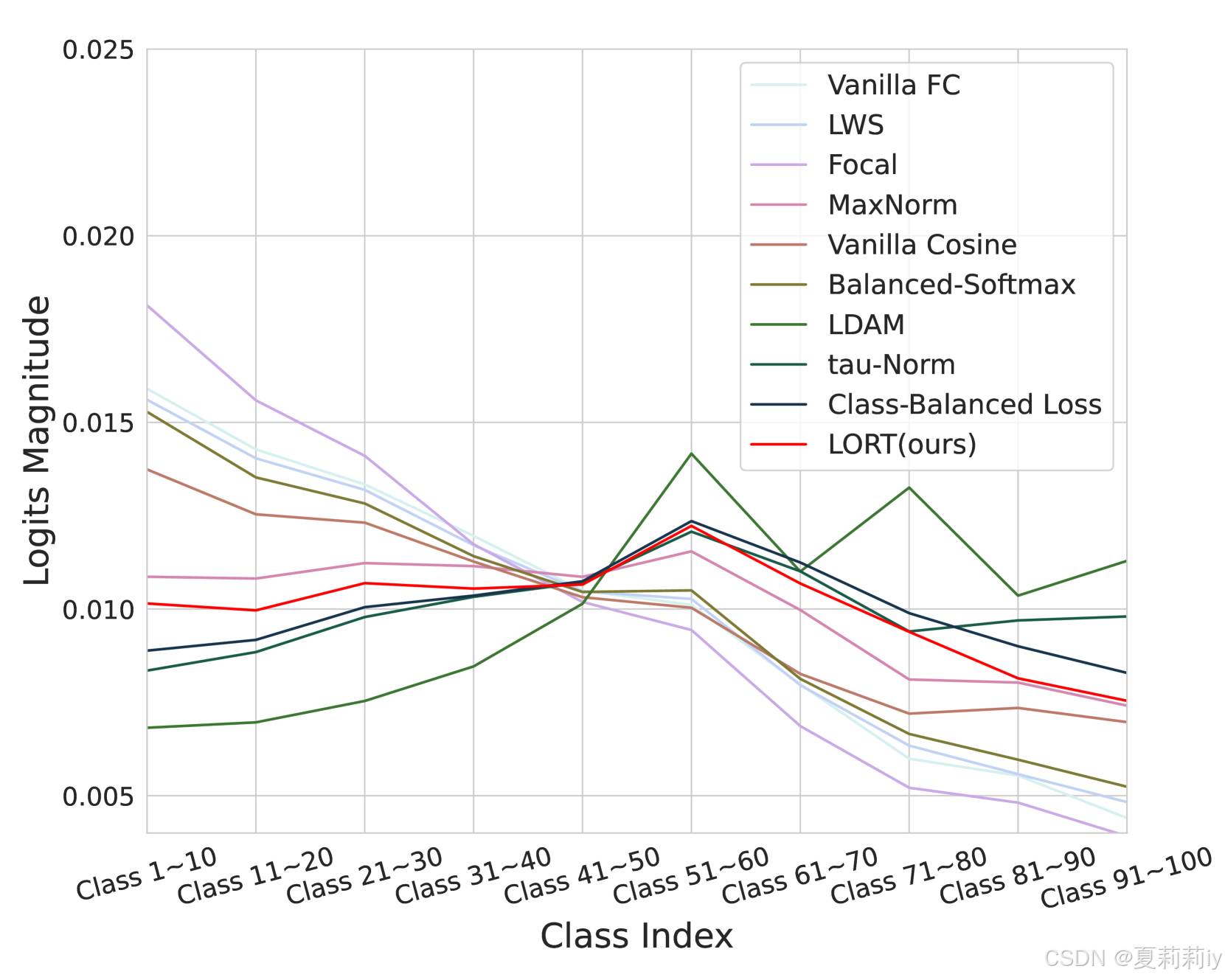
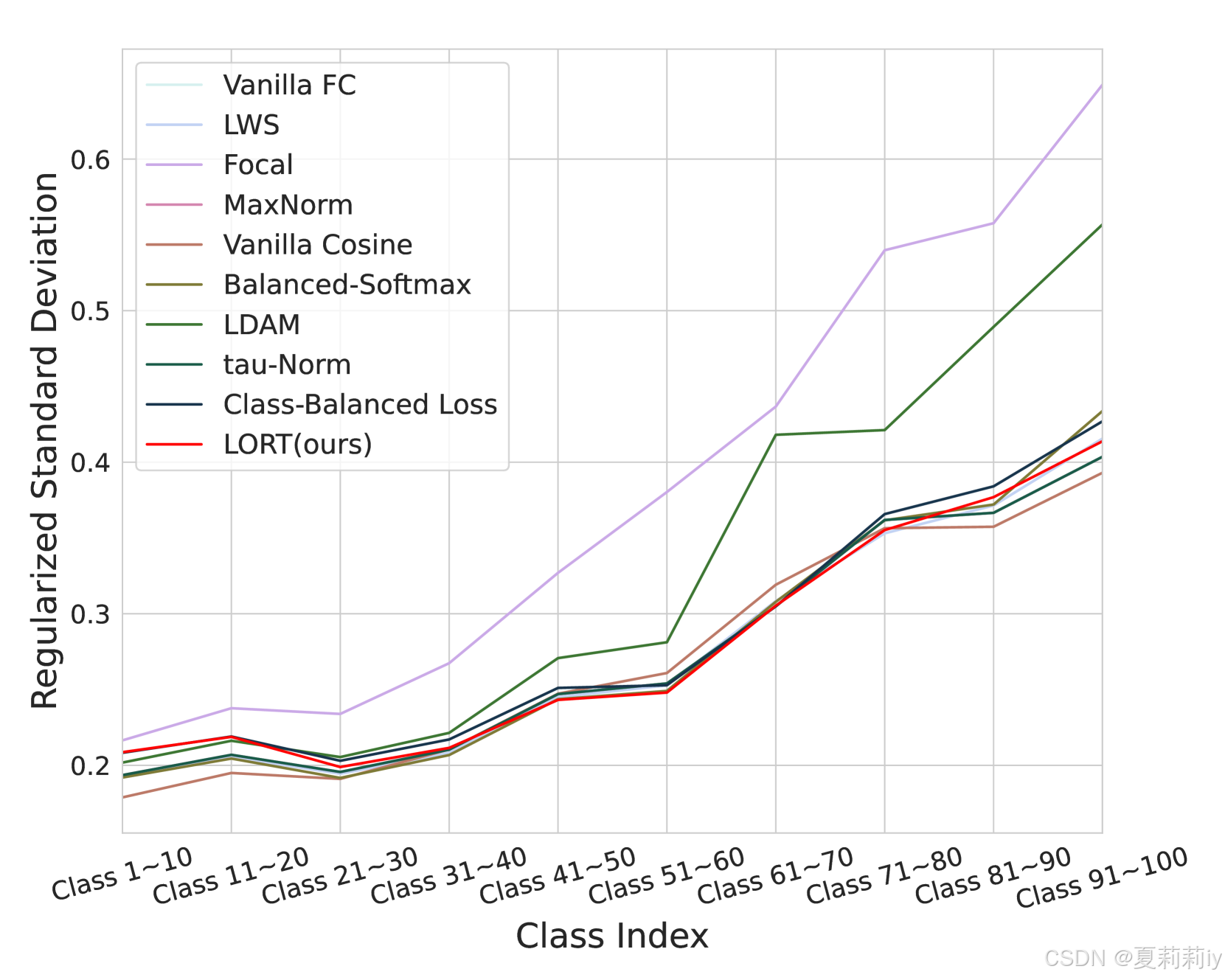
⑦模型对头类、中类、尾类的判别能力(Logits Magnitude)越平衡,整体准确率越高。(根据图1来看,我认为作者言下之意是对于每个大类的类,σ越小越好)
⑧logits magnitude对标准差的正则化:
2.5. Method
2.5.1. Deep Dive into Logits Magnitude
①作者发现每个类都得到了类似的logits magnitude:
②相对类别logits波动性:
③考虑一个独立影响每个类的类随机扰动
,这个扰动和logits的标准差有关,如
且
,其中
是随机变量且期望为0
④扰动下概率的期望:
在类别平衡的数据集里,正则化的标准差都几乎相似,且不同类别不正则化的标准差
接近0
⑤去掉了扰动的求和,将扰动单独提出来
其中可以被视为一个常数
,对于均衡的数据集,扰动对所有类别的影响恒定:
对于类别不均衡的数据集,每个类的
可能完全不一样。如果
(类
的正则化标准差大),
(类
的扰动更大)。
⑥当遵从正态分布,有:
⑦作者需要改变logits分布,所以提出了logits retargeting approach (LORT)
2.5.2. Logits Retargeting
①LORT:
其中是控制负类概率的常数,可以被称为标签平滑超参数
作者设计的LORT相当于一个标签概率平滑,如
时:
其实就是正常的交叉熵;
如
时:
上面
的真标签就给自己分配稍低一点的概率,给所有别的不属于这个标签的类加一点概率;
如作者认为这个
可以大一点比如
:
这样真实类别就会为自己分配极少的概率
2.6. Experiments
①长尾图像分类数据集:CIFAR100-LT,ImageNet-LT,iNaturalist2018
②设备:GeForce RTX 3090 (24GB)和A100-PCIE (40GB)
2.6.1. Datasets and Implementation Details
①imbalanced ratio (IR)计算公式:
其中都只算训练集的
2.6.2. Benchmark Results
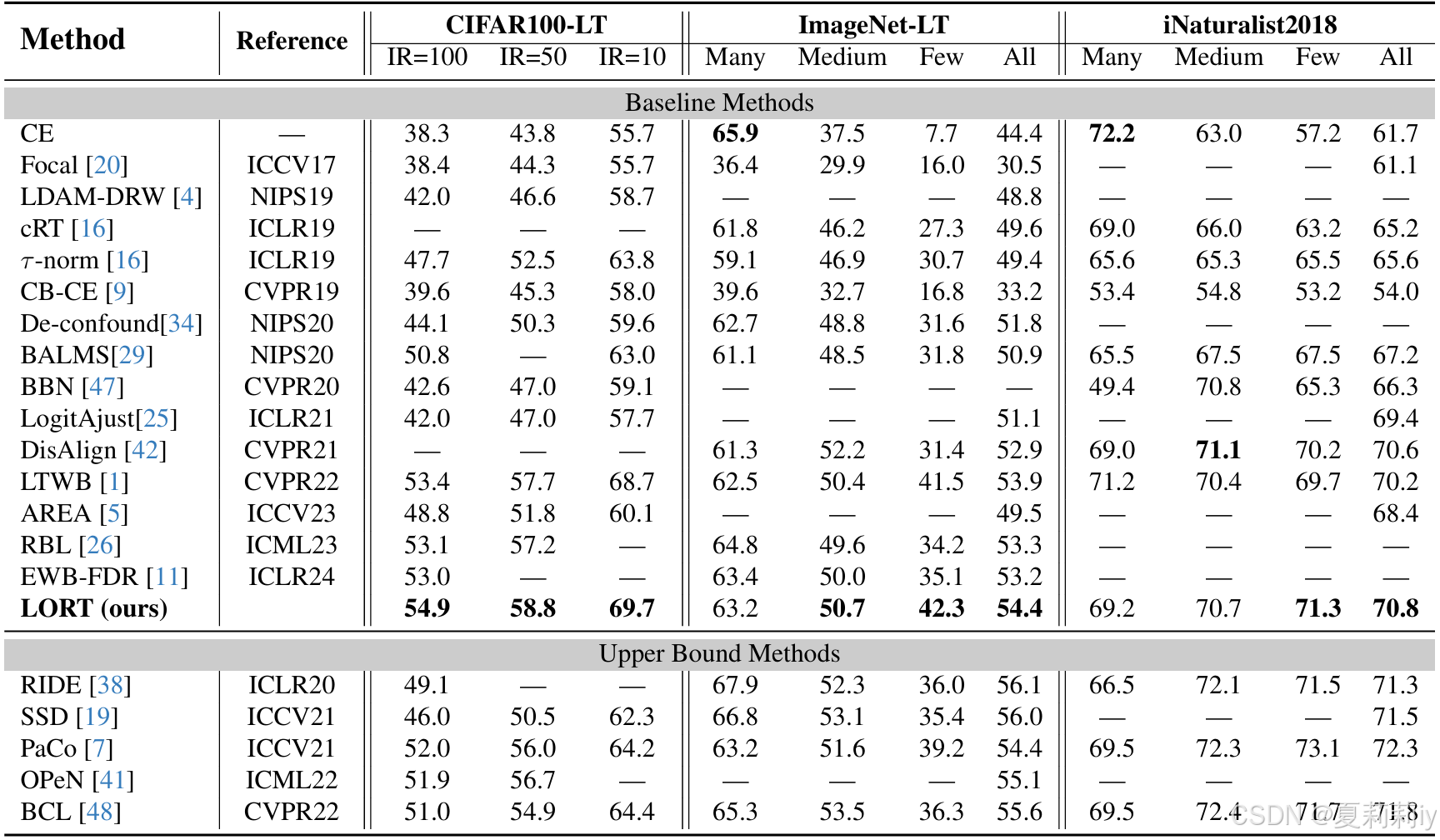
①实验:
②不同类别的Logit Magnitude和归一化标准导数:
2.6.3. Ablation Study
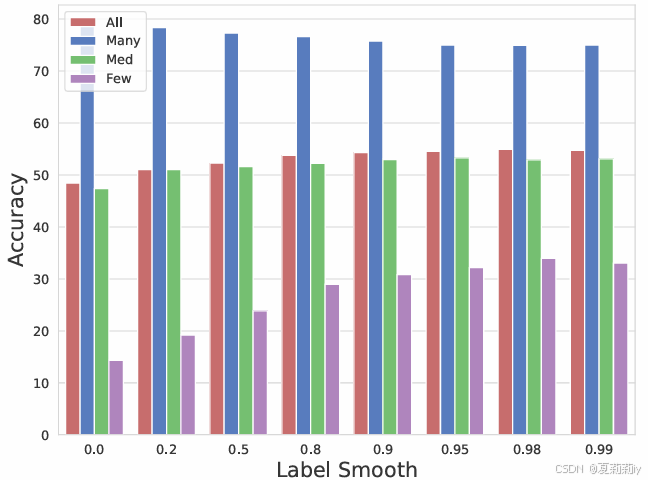
①标签平滑值实验:
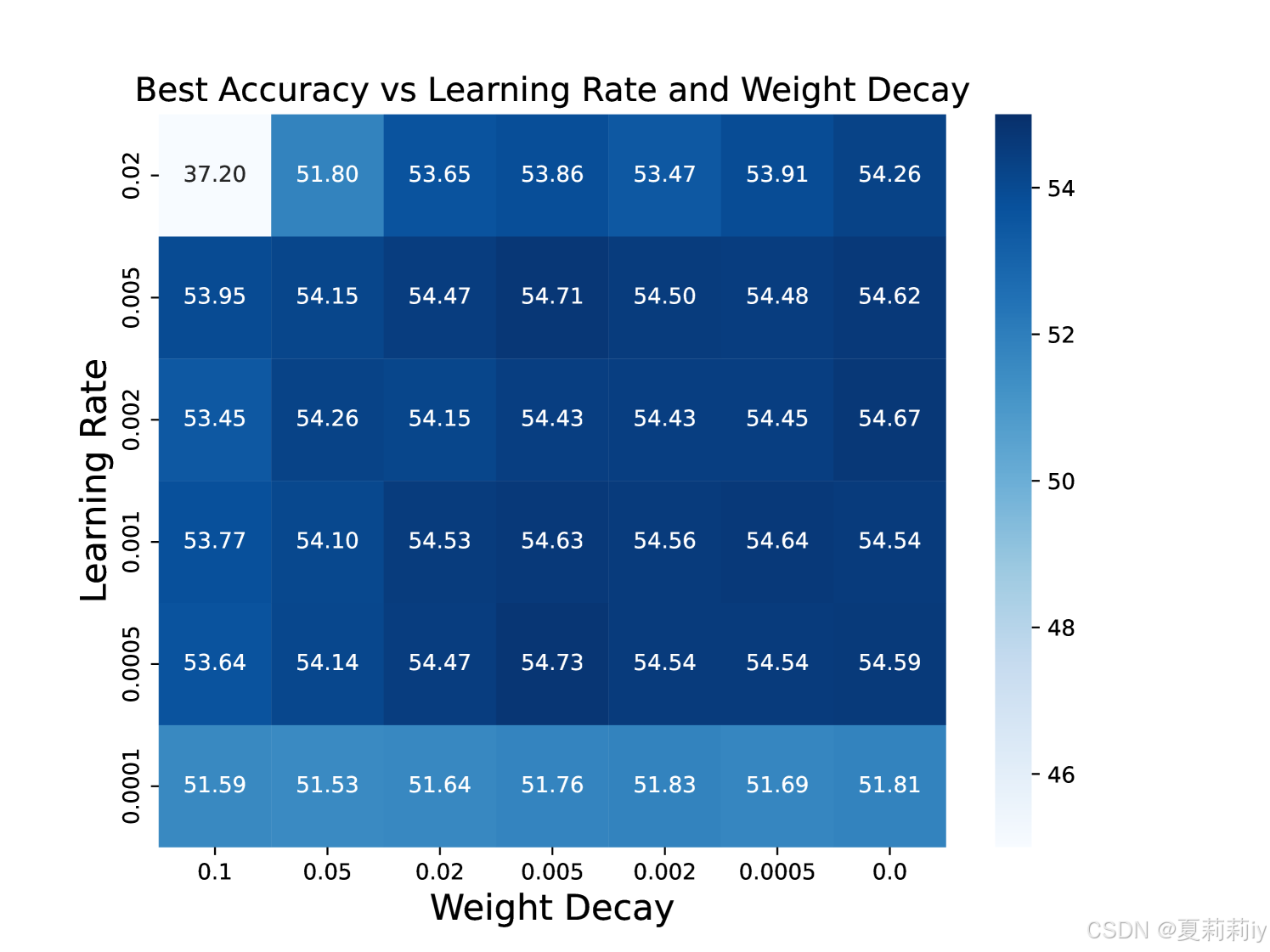
②在不同学习率和weight decay上的不敏感性:
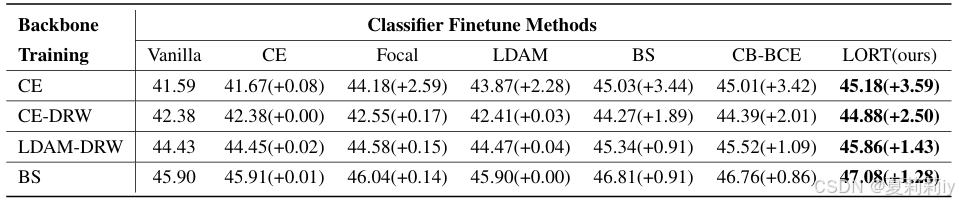
③对不同主干的提升:
reassuringly adv.令人放心的;安慰地;鼓励地
malleable adj.可塑的;有延展性的;可锻造的;易受影响(或改变)的;易成型的;可轧压的
2.7. Conclusion
~

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 29
29 0
0- 0



 已为社区贡献33条内容
已为社区贡献33条内容

所有评论(0)