训练速度飙升5倍!Unsloth动态量化让大模型微调告别“卡脖子”
Unsloth 是一个革命性的大型语言模型(LLM)高效微调框架。它通过独家手动推导并编写的GPU内核,在不改变硬件的前提下,实现了训练速度的2-5倍提升,同时显存占用最高可减少80%**。其核心的动态量化(Dynamic 2.0)技术,能在几乎不损失模型性能的情况下(如Qwen3模型性能损失<1%),将模型压缩至极小的体积,极大地降低了个人开发者和研究者的硬件门槛。

还在为大模型微调的速度慢、显存爆而烦恼?Unsloth的黑科技让你在消费级GPU上也能轻松玩转百亿参数模型!
摘要
Unsloth 是一个革命性的大型语言模型(LLM)高效微调框架。它通过独家手动推导并编写的GPU内核,在不改变硬件的前提下,实现了训练速度的2-5倍提升,同时显存占用最高可减少80%。其核心的动态量化(Dynamic 2.0)技术,能在几乎不损失模型性能的情况下(如Qwen3模型性能损失<1%),将模型压缩至极小的体积,极大地降低了个人开发者和研究者的硬件门槛。
一、 痛点破局:为何我们需要Unsloth?
大语言模型的微调一直是资源密集型的“贵族游戏”。传统的微调方法不仅耗时漫长,动辄需要数天甚至数周,更对昂贵的GPU显存提出了极高要求,让许多研究者和中小企业望而却步。Unsloth的出现,正是为了打破这一僵局。
它并非简单地堆砌优化技巧,而是从底层重新推导计算密集型数学步骤,并手写高性能GPU内核,从而实现极致的效率飞跃。这意味着,你无需购买新的硬件,仅需改变导入模型的一行代码,就能让整个训练流程脱胎换骨。
二、 核心技术揭秘:速度与效率的魔法
1. 极速微调引擎
Unsloth的核心是经过极致优化的训练循环。官方数据显示,其微调速度相比传统方法(如Hugging Face标准流程)提升了2到5倍。这意味着原本需要10小时的训练任务,现在可能仅需2-5小时即可完成,极大地加速了实验迭代周期。
2. 动态量化黑科技(Dynamic Quantization v2)

这是Unsloth的“王牌”技术。它能在微调和推理前,将模型权重动态量化为4-bit精度,从而将模型体积和显存占用压缩到极致。
-
性能表现惊人:以最新的Qwen3模型为例,根据Unsloth官方博客和arXiv论文(2505.02214)的研究,其4-bit动态量化版本性能损失不到1%,在许多任务上几乎与原始全精度模型持平。
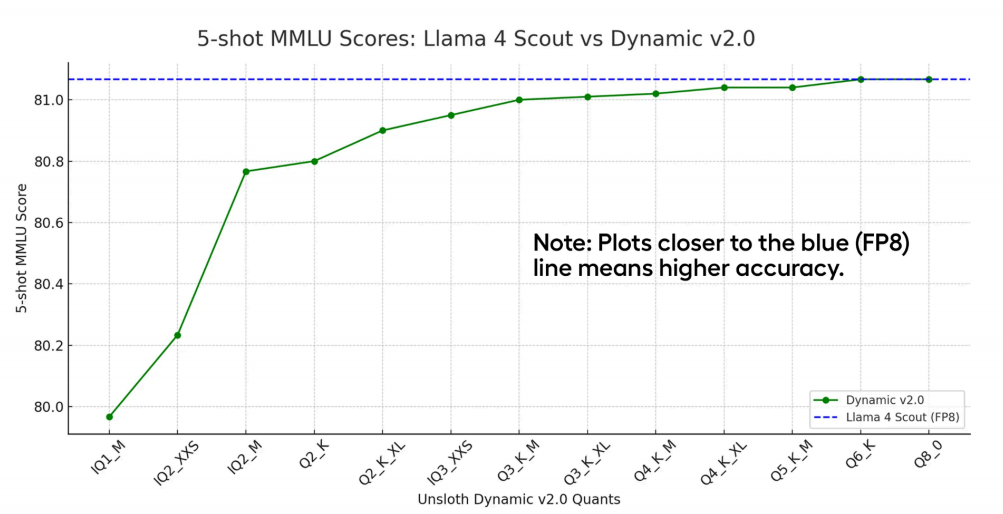

-
显著降低门槛:这使得在RTX 3090/4090等消费级显卡上微调70亿甚至更大量级的模型成为可能,显存占用最高可减少80%。
重要提示:动态量化是一把双刃剑。其优势是极致压缩,但劣势在于,量化后的模型目前仅支持单GPU运行,无法利用多卡并行来进一步扩大训练吞吐量。这在高批量生产化微调场景下是一个需要考虑的限制。
3. 无缝的生态兼容
Unsloth完美融入现有的AI开发生态。它与 Hugging Face transformers、peft、trl 等库无缝结合。你现有的监督微调(SFT)或直接偏好优化(DPO)训练脚本,通常只需修改一行模型加载代码即可切换到Unsloth,学习成本极低。
# 传统加载方式
# from transformers import AutoModelForCausalLM
# model = AutoModelForCausalLM.from_pretrained("model_name")
# 使用Unsloth加速(示例)
from unsloth import FastLanguageModel
model, tokenizer = FastLanguageModel.from_pretrained(
model_name = "unsloth/meta-llama-3.1-8b",
max_seq_length = 2048,
dtype = None, # 自动检测
load_in_4bit = True, # 启用4-bit量化
)
三、 核心优势与适用场景
- 极致的个人友好性:开源免费,对Colab、Kaggle等免费环境支持良好,是学生、个人研究者和创业公司的福音。
- 广泛的模型支持:全面支持Llama、Mistral、Qwen、Gemma等主流开源模型家族,紧跟社区前沿。
- 完整的微调支持:不仅支持SFT,还支持更高效的DPO、ORPO等对齐方法,帮助你训练出更“听话”的模型。
最适合Unsloth的场景:
- 个人或小团队在有限资源(单卡)下进行模型微调实验。
- 需要快速进行多次迭代,验证不同数据或提示词效果的场景。
- 希望以最小成本对模型进行定制化,并将其部署在资源受限的边缘环境。
四、 快速开始
使用Unsloth的流程异常简单:
- 安装:
pip install unsloth - 加载模型:使用
FastLanguageModel.from_pretrained加载你的模型(建议启用4-bit)。 - 配置训练:使用
get_peft_model应用LoRA等参数高效微调配置。 - 开始训练:几乎可以沿用你原有的
transformers训练器(Trainer)代码。
你可以在几分钟内,就将一个现有的项目迁移到Unsloth上,并立即感受到速度的提升。
总结
Unsloth通过其底层硬核优化和创新的动态量化技术,真正实现了大模型微调的“平民化”。它虽非解决所有规模化生产问题的银弹(例如存在单卡限制),但对于绝大多数寻求效率突破、受限于计算资源的开发者和研究者而言,无疑是当前最具吸引力的工具之一。
如果你还在为微调的速度和显存发愁,不妨立即尝试Unsloth,亲身体验这种“飞一般”的感觉。
立即访问GitHub,开始你的极速微调之旅吧!
👉 https://github.com/unslothai/unsloth
希望这篇介绍能帮助您!如果您在微调过程中有任何心得或问题,欢迎在评论区交流讨论。
本文为原创内容,版权归作者所有,转载需注明出处。
标签:#大模型微调 #Unsloth #动态量化 #AI效率工具

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 21
21 0
0- 0



 已为社区贡献19条内容
已为社区贡献19条内容

所有评论(0)