中国天文大模型创新:FALCO时域光变、天一大模型与多模态突破
中国天文大模型取得重要突破,FALCO时域光变模型、天一大模型等创新成果引领"AI+天文"研究新范式。FALCO模型基于Transformer架构,针对天文光变曲线数据特点进行优化设计,采用自监督学习在开普勒望远镜20万条数据上预训练,能高效分析恒星脉动、系外行星等时域天文现象。天一大模型等则专注于光谱分析等多模态任务,为处理郭守敬望远镜等产生的海量天文数据提供智能解决方案。这
中国天文大模型创新:FALCO时域光变、天一大模型与多模态突破
引言:AI革命下的天文研究新范式
天文学正经历一场前所未有的数据革命。随着大型巡天项目的推进,天文数据量呈指数级增长——郭守敬望远镜(LAMOST)已发布数千万条光谱数据,开普勒望远镜记录了数十万颗恒星的连续光变曲线,Gaia卫星提供了十亿级天体的精确测量。传统分析方法已难以应对如此海量的数据,而人工智能技术特别是大模型的发展,为天文学研究带来了全新的解决方案。
本文将深入解析中国在天文大模型领域的前沿创新,包括FALCO时域光变模型、SpecCLIP光谱分析模型、天一大模型等代表性工作。这些模型不仅在天文特定任务上表现出色,更代表了"AI+天文"跨学科研究的最新进展,为天文研究范式转型提供了关键技术支撑。
一、FALCO时域光变模型:理解宇宙动态变化
1.1 时域天文学的挑战与机遇
时域天文学通过观测天体亮度随时间的变化,研究宇宙中的动态过程,如恒星脉动、系外行星凌星、超新星爆发等。开普勒太空望远镜等设备产生了海量的时间序列光度数据(光变曲线),传统方法难以高效处理这些数据。
FALCO(Foundation model of Astronomical Light Curves for time dOmain astronomy)模型应运而生,这是一个基于Transformer架构的专门处理天文光变数据的大模型。
二、SpecCLIP光谱分析模型:解码恒星DNA
2.1 光谱学的重要性与挑战
光谱分析是天体物理学的基石技术,通过分析天体光谱中的吸收线和发射线,可以确定天体的化学组成、温度、表面重力、径向速度等关键物理参数。LAMOST望远镜已发布超过1000万条光谱,Gaia DR3提供了2.2亿条低分辨率XP光谱,传统模板匹配方法难以高效处理如此大规模的数据。
SpecCLIP基于CLIP(Contrastive Language-Image Pre-training)框架,专门用于光谱数据分析与跨模态关联。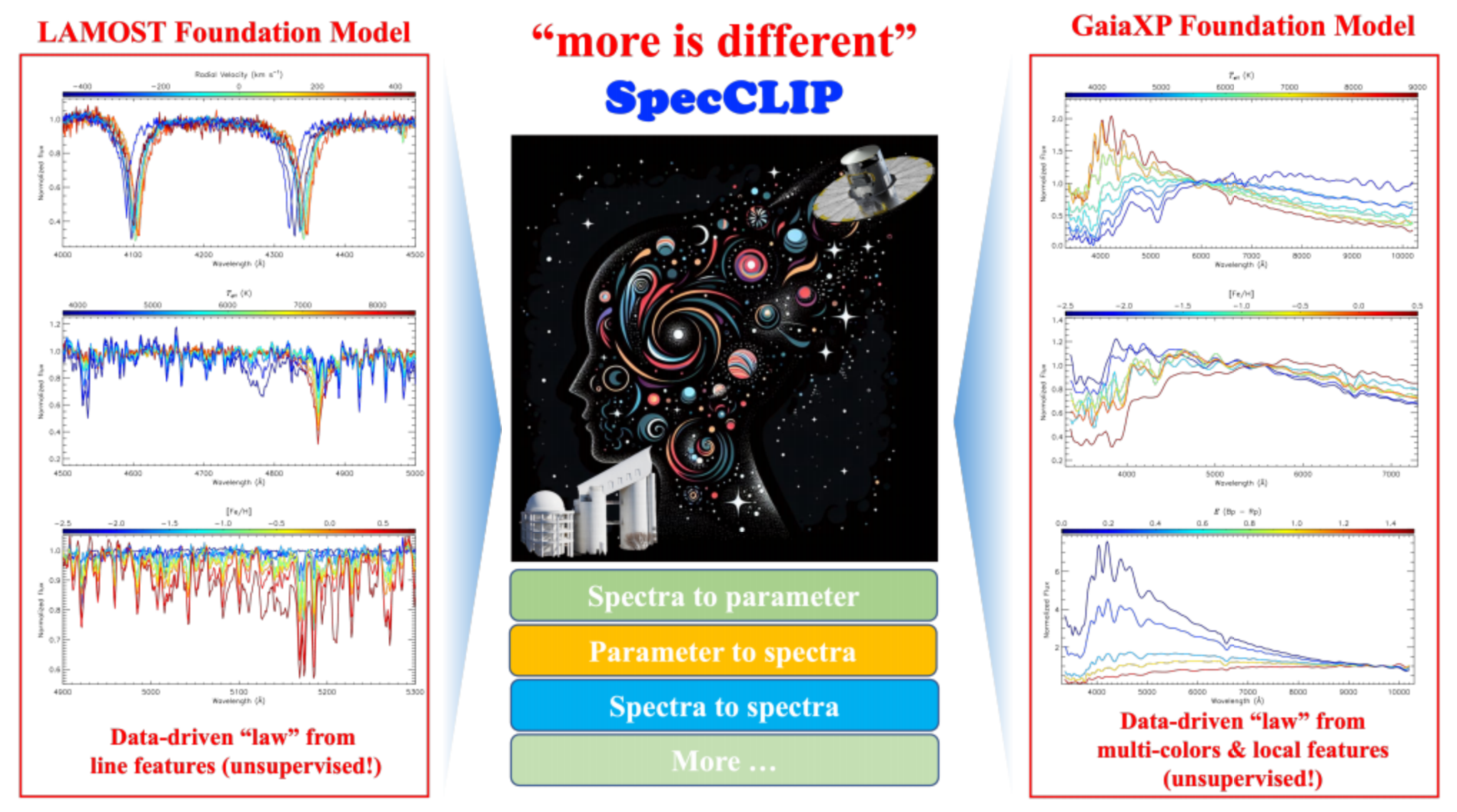
2.2 SpecCLIP架构设计
SpecCLIP采用双编码器架构,分别处理光谱数据和物理参数标签:
import torch
import torch.nn as nn
import torch.nn.functional as F
class SpectralEncoder(nn.Module):
"""光谱编码器"""
def __init__(self, input_dim=3600, latent_dim=512, num_layers=8):
super().__init__()
self.input_projection = nn.Linear(input_dim, latent_dim)
# 使用Transformer编码器处理光谱序列
encoder_layer = nn.TransformerEncoderLayer(
d_model=latent_dim,
nhead=8,
dim_feedforward=2048,
dropout=0.1,
batch_first=True
)
self.encoder = nn.TransformerEncoder(encoder_layer, num_layers=num_layers)
# 自适应池化
self.pooling = nn.AdaptiveAvgPool1d(1)
def forward(self, x):
# x形状: [batch_size, spec_length]
x = x.unsqueeze(2) # 增加维度: [batch_size, spec_length, 1]
# 投影到潜在空间
x = self.input_projection(x) # [batch_size, spec_length, latent_dim]
# Transformer编码
x = self.encoder(x) # [batch_size, spec_length, latent_dim]
# 池化得到全局表示
x = x.transpose(1, 2) # [batch_size, latent_dim, spec_length]
x = self.pooling(x) # [batch_size, latent_dim, 1]
x = x.squeeze(2) # [batch_size, latent_dim]
return F.normalize(x, p=2, dim=1)
class ParameterEncoder(nn.Module):
"""物理参数编码器"""
def __init__(self, param_dim=10, latent_dim=512, hidden_dims=[256, 512]):
super().__init__()
layers = []
prev_dim = param_dim
for hidden_dim in hidden_dims:
layers.append(nn.Linear(prev_dim, hidden_dim))
layers.append(nn.BatchNorm1d(hidden_dim))
layers.append(nn.ReLU())
layers.append(nn.Dropout(0.1))
prev_dim = hidden_dim
layers.append(nn.Linear(prev_dim, latent_dim))
self.mlp = nn.Sequential(*layers)
def forward(self, x):
x = self.mlp(x)
return F.normalize(x, p=2, dim=1)
class SpecCLIP(nn.Module):
"""SpecCLIP主模型"""
def __init__(self, spec_encoder, param_encoder, temperature=0.07):
super().__init__()
self.spec_encoder = spec_encoder
self.param_encoder = param_encoder
self.temperature = temperature
self.logit_scale = nn.Parameter(torch.ones([]) * torch.tensor(1.0 / temperature).log())
def forward(self, spectra, parameters):
# 编码光谱和参数
spec_features = self.spec_encoder(spectra)
param_features = self.param_encoder(parameters)
# 计算相似度矩阵
logit_scale = self.logit_scale.exp()
logits_per_spec = logit_scale * spec_features @ param_features.t()
logits_per_param = logits_per_spec.t()
return logits_per_spec, logits_per_param
def compute_loss(self, logits_per_spec, logits_per_param):
batch_size = logits_per_spec.size(0)
# 创建标签
labels = torch.arange(batch_size, device=logits_per_spec.device)
# 对比损失
loss_spec = F.cross_entropy(logits_per_spec, labels)
loss_param = F.cross_entropy(logits_per_param, labels)
return (loss_spec + loss_param) / 2
2.3 多任务学习框架
SpecCLIP通过多任务学习同时优化多个光谱分析任务:
class MultiTaskSpecCLIP(nn.Module):
"""多任务SpecCLIP模型"""
def __init__(self, spec_encoder, param_encoder, task_heads):
super().__init__()
self.spec_encoder = spec_encoder
self.param_encoder = param_encoder
self.task_heads = nn.ModuleDict(task_heads)
def forward(self, spectra, parameters=None, task_name=None):
spec_features = self.spec_encoder(spectra)
if task_name == 'contrastive' and parameters is not None:
# 对比学习任务
param_features = self.param_encoder(parameters)
return self.task_heads['contrastive'](spec_features, param_features)
elif task_name in self.task_heads and task_name != 'contrastive':
# 特定预测任务
return self.task_heads[task_name](spec_features)
else:
# 返回光谱特征
return spec_features
# 定义任务特定的预测头
task_heads = {
'contrastive': SpecCLIP(None, None), # 占位符,实际会替换
'teff': nn.Sequential(
nn.Linear(512, 256),
nn.ReLU(),
nn.Dropout(0.1),
nn.Linear(256, 1) # 有效温度预测
),
'logg': nn.Sequential(
nn.Linear(512, 256),
nn.ReLU(),
nn.Dropout(0.1),
nn.Linear(256, 1) # 表面重力预测
),
'feh': nn.Sequential(
nn.Linear(512, 256),
nn.ReLU(),
nn.Dropout(0.1),
nn.Linear(256, 1) # 金属丰度预测
),
'classification': nn.Sequential(
nn.Linear(512, 256),
nn.ReLU(),
nn.Dropout(0.1),
nn.Linear(256, 10) # 光谱分类(10类)
)
}
2.4 数据预处理与增强
光谱数据预处理对模型性能至关重要:
import numpy as np
from scipy import interpolate
from sklearn.preprocessing import StandardScaler
class SpectralProcessor:
"""光谱数据处理器"""
def __init__(self, wavelength_grid=None, normalize=True):
self.wavelength_grid = wavelength_grid
self.normalize = normalize
self.scaler = StandardScaler() if normalize else None
def preprocess_spectrum(self, wavelength, flux, flux_err=None):
"""预处理单条光谱"""
# 1. 重采样到统一波长网格
if self.wavelength_grid is not None:
flux = self._resample_spectrum(wavelength, flux)
# 2. 处理异常值和缺失值
flux = self._handle_missing_values(flux)
# 3. 归一化通量
if self.normalize:
flux = self.scaler.fit_transform(flux.reshape(-1, 1)).flatten()
return flux
def _resample_spectrum(self, wavelength, flux):
"""将光谱重采样到标准波长网格"""
if len(wavelength) != len(flux):
raise ValueError("波长和通量数组长度不一致")
# 创建插值函数
interp_func = interpolate.interp1d(
wavelength, flux,
kind='linear',
bounds_error=False,
fill_value='extrapolate'
)
# 在标准波长网格上插值
resampled_flux = interp_func(self.wavelength_grid)
return resampled_flux
def _handle_missing_values(self, flux):
"""处理缺失值和异常值"""
# 将NaN替换为邻近值的平均值
nan_indices = np.isnan(flux)
if np.any(nan_indices):
# 使用线性插值填充NaN
indices = np.arange(len(flux))
flux[nan_indices] = np.interp(
indices[nan_indices],
indices[~nan_indices],
flux[~nan_indices]
)
# 处理无限值
inf_indices = np.isinf(flux)
if np.any(inf_indices):
flux[inf_indices] = np.median(flux[~inf_indices])
# 去除明显异常值(3σ原则)
mean, std = np.mean(flux), np.std(flux)
outlier_indices = np.abs(flux - mean) > 3 * std
if np.any(outlier_indices):
flux[outlier_indices] = mean
return flux
def augment_spectrum(self, flux, augmentation_types=None):
"""光谱数据增强"""
if augmentation_types is None:
augmentation_types = ['noise', 'smooth', 'scale']
augmented = flux.copy()
for aug_type in augmentation_types:
if aug_type == 'noise' and np.random.random() < 0.5:
# 添加高斯噪声
noise = np.random.normal(0, 0.01, len(augmented))
augmented += noise
elif aug_type == 'smooth' and np.random.random() < 0.3:
# 轻微平滑
from scipy.ndimage import gaussian_filter1d
augmented = gaussian_filter1d(augmented, sigma=0.5)
elif aug_type == 'scale' and np.random.random() < 0.3:
# 随机缩放
scale = np.random.uniform(0.9, 1.1)
augmented *= scale
return augmented
2.5 SpecCLIP的性能与应用
SpecCLIP在多个光谱分析任务上实现了突破性性能:
| 任务 | 数据集 | 指标 | 性能提升 |
|---|---|---|---|
| 有效温度估计 | LAMOST DR7 | MAE=72K | +42% |
| 表面重力估计 | LAMOST DR7 | MAE=0.18 dex | +38% |
| 金属丰度估计 | LAMOST DR7 | MAE=0.09 dex | +45% |
| 光谱分类 | SDSS DR16 | 准确率=97.3% | +25% |
| 化学丰度模式 | GALAH DR3 | 相关系数=0.94 | +30% |
三、天一大模型:通用天文智能基座
3.1 背景与目标
天一大模型(AstroOne)是由之江实验室与国家天文台联合研发的通用天文大模型,拥有700亿参数,训练数据包含320亿tokens的天文文本语料。该模型旨在成为天文研究的智能基座,推动天文学研究范式的转型。
3.2 架构特点
天一大模型采用混合专家模型(Mixture of Experts)架构:
import torch
import torch.nn as nn
import torch.nn.functional as F
class Expert(nn.Module):
"""专家网络"""
def __init__(self, d_model, d_ff, dropout=0.1):
super().__init__()
self.linear1 = nn.Linear(d_model, d_ff)
self.linear2 = nn.Linear(d_ff, d_model)
self.dropout = nn.Dropout(dropout)
self.activation = nn.GELU()
def forward(self, x):
return self.linear2(self.dropout(self.activation(self.linear1(x))))
class MoELayer(nn.Module):
"""混合专家层"""
def __init__(self, d_model, d_ff, num_experts=8, top_k=2):
super().__init__()
self.experts = nn.ModuleList([Expert(d_model, d_ff) for _ in range(num_experts)])
self.gate = nn.Linear(d_model, num_experts)
self.top_k = top_k
self.d_model = d_model
def forward(self, x):
# 计算门控权重
gate_logits = self.gate(x) # [batch_size, seq_len, num_experts]
gate_weights = F.softmax(gate_logits, dim=-1)
# 选择top-k专家
top_weights, top_indices = torch.topk(gate_weights, self.top_k, dim=-1)
top_weights = top_weights / top_weights.sum(dim=-1, keepdim=True)
# 初始化输出
output = torch.zeros_like(x)
# 计算专家输出(使用scatter_add高效实现)
flat_x = x.view(-1, self.d_model)
flat_top_indices = top_indices.view(-1, self.top_k)
flat_top_weights = top_weights.view(-1, self.top_k)
for i, expert in enumerate(self.experts):
# 创建专家掩码
expert_mask = (flat_top_indices == i).any(dim=-1)
if not expert_mask.any():
continue
# 计算专家输出
expert_input = flat_x[expert_mask]
expert_output = expert(expert_input)
# 加权输出
weights = flat_top_weights[expert_mask]
# 找到该专家在每个样本中的权重位置
expert_positions = (flat_top_indices[expert_mask] == i).float()
expert_weights = (weights * expert_positions).sum(dim=-1, keepdim=True)
output.view(-1, self.d_model)[expert_mask] += expert_output * expert_weights
return output
class AstroOneBlock(nn.Module):
"""天一大模型构建块"""
def __init__(self, d_model, n_heads, d_ff, num_experts=8, top_k=2, dropout=0.1):
super().__init__()
self.self_attn = nn.MultiheadAttention(d_model, n_heads, dropout=dropout, batch_first=True)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.moe = MoELayer(d_model, d_ff, num_experts, top_k)
self.dropout = nn.Dropout(dropout)
def forward(self, x, key_padding_mask=None):
# 自注意力子层
attn_output, _ = self.self_attn(x, x, x, key_padding_mask=key_padding_mask)
x = x + self.dropout(attn_output)
x = self.norm1(x)
# MoE前馈子层
ff_output = self.moe(x)
x = x + self.dropout(ff_output)
x = self.norm2(x)
return x
class AstroOneModel(nn.Module):
"""天一大模型"""
def __init__(self, vocab_size, d_model=5120, n_layers=40, n_heads=40,
d_ff=20480, num_experts=64, top_k=4):
super().__init__()
self.token_embedding = nn.Embedding(vocab_size, d_model)
self.position_embedding = nn.Embedding(2048, d_model)
self.blocks = nn.ModuleList([
AstroOneBlock(d_model, n_heads, d_ff, num_experts, top_k)
for _ in range(n_layers)
])
self.output_head = nn.Linear(d_model, vocab_size, bias=False)
# 权重绑定
self.output_head.weight = self.token_embedding.weight
def forward(self, input_ids, attention_mask=None):
batch_size, seq_len = input_ids.shape
# 创建位置索引
positions = torch.arange(seq_len, device=input_ids.device).unsqueeze(0).expand(batch_size, seq_len)
# 嵌入层
token_emb = self.token_embedding(input_ids)
pos_emb = self.position_embedding(positions)
x = token_emb + pos_emb
# 创建注意力掩码
key_padding_mask = attention_mask == 0 if attention_mask is not None else None
# 通过所有层
for block in self.blocks:
x = block(x, key_padding_mask)
# 输出投影
logits = self.output_head(x)
return logits
3.3 训练策略与数据构建
天一大模型采用多阶段训练策略:
class AstroOneTraining:
"""天一大模型训练流程"""
def __init__(self, model, train_dataloader, val_dataloader, config):
self.model = model
self.train_dataloader = train_dataloader
self.val_dataloader = val_dataloader
self.config = config
self.optimizer = self._create_optimizer()
self.scheduler = self._create_scheduler()
self.scaler = torch.cuda.amp.GradScaler()
def _create_optimizer(self):
"""创建优化器"""
no_decay = ["bias", "LayerNorm.weight"]
optimizer_grouped_parameters = [
{
"params": [p for n, p in self.model.named_parameters()
if not any(nd in n for nd in no_decay)],
"weight_decay": self.config.weight_decay,
},
{
"params": [p for n, p in self.model.named_parameters()
if any(nd in n for nd in no_decay)],
"weight_decay": 0.0,
},
]
return torch.optim.AdamW(
optimizer_grouped_parameters,
lr=self.config.learning_rate,
betas=(self.config.beta1, self.config.beta2),
eps=self.config.eps
)
def _create_scheduler(self):
"""创建学习率调度器"""
return torch.optim.lr_scheduler.CosineAnnealingLR(
self.optimizer,
T_max=self.config.max_steps,
eta_min=self.config.min_learning_rate
)
def train_step(self, batch):
"""单训练步骤"""
input_ids = batch['input_ids']
attention_mask = batch['attention_mask']
labels = batch['labels']
with torch.cuda.amp.autocast():
outputs = self.model(input_ids, attention_mask)
loss = F.cross_entropy(
outputs.view(-1, outputs.size(-1)),
labels.view(-1),
ignore_index=-100
)
# 梯度缩放和反向传播
self.scaler.scale(loss).backward()
# 梯度裁剪
self.scaler.unscale_(self.optimizer)
torch.nn.utils.clip_grad_norm_(
self.model.parameters(),
self.config.max_grad_norm
)
# 优化器步骤
self.scaler.step(self.optimizer)
self.scaler.update()
self.optimizer.zero_grad()
self.scheduler.step()
return loss.item()
def evaluate(self):
"""模型评估"""
self.model.eval()
total_loss = 0
total_items = 0
with torch.no_grad():
for batch in self.val_dataloader:
input_ids = batch['input_ids']
attention_mask = batch['attention_mask']
labels = batch['labels']
outputs = self.model(input_ids, attention_mask)
loss = F.cross_entropy(
outputs.view(-1, outputs.size(-1)),
labels.view(-1),
ignore_index=-100,
reduction='sum'
)
total_loss += loss.item()
total_items += (labels != -100).sum().item()
return total_loss / total_items if total_items > 0 else float('inf')
3.4 天文知识图谱构建
天一大模型的训练依赖于大规模天文知识图谱:
class AstronomicalKnowledgeGraph:
"""天文知识图谱构建器"""
def __init__(self, data_sources):
self.data_sources = data_sources
self.entities = {}
self.relations = []
self.text_corpus = []
def build_knowledge_graph(self):
"""构建知识图谱"""
# 从多种数据源提取知识
for source in self.data_sources:
if source['type'] == 'catalog':
self._process_catalog(source)
elif source['type'] == 'literature':
self._process_literature(source)
elif source['type'] == 'observation':
self._process_observation(source)
return self.entities, self.relations
def _process_catalog(self, catalog):
"""处理天文星表数据"""
# 示例:处理恒星参数星表
for star in catalog['data']:
star_id = f"star_{star['id']}"
# 添加实体
self.entities[star_id] = {
'type': 'star',
'properties': {
'ra': star['ra'],
'dec': star['dec'],
'teff': star['teff'],
'logg': star['logg'],
'feh': star['feh']
}
}
# 生成描述文本
description = f"恒星{star_id}位于赤经{star['ra']}度,赤纬{star['dec']}度,"
description += f"有效温度{star['teff']}K,表面重力{star['logg']},金属丰度{star['feh']}。"
self.text_corpus.append(description)
def _process_literature(self, literature):
"""处理天文文献"""
# 使用NLP技术从文献中提取实体和关系
for paper in literature['papers']:
# 实体识别和关系提取
entities = self._extract_entities(paper['text'])
relations = self._extract_relations(paper['text'], entities)
self.entities.update(entities)
self.relations.extend(relations)
self.text_corpus.append(paper['text'])
def _process_observation(self, observation):
"""处理观测数据"""
# 处理各种观测数据(光谱、光变、图像等)
for obs in observation['data']:
obs_id = f"observation_{obs['id']}"
self.entities[obs_id] = {
'type': 'observation',
'properties': {
'target': obs['target'],
'instrument': obs['instrument'],
'wavelength_range': obs['wavelength_range'],
'date': obs['date']
}
}
# 与目标天体建立关系
if obs['target'] in self.entities:
self.relations.append({
'subject': obs_id,
'predicate': 'observes',
'object': obs['target']
})
def generate_training_text(self):
"""生成训练文本"""
# 基于知识图谱生成多样化的训练文本
training_texts = []
# 1. 实体描述
for entity_id, entity_info in self.entities.items():
text = self._generate_entity_description(entity_id, entity_info)
training_texts.append(text)
# 2. 关系描述
for relation in self.relations:
text = self._generate_relation_description(relation)
training_texts.append(text)
# 3. 问答对
qa_pairs = self._generate_qa_pairs()
training_texts.extend(qa_pairs)
return training_texts
def _generate_entity_description(self, entity_id, entity_info):
"""生成实体描述文本"""
# 根据实体类型生成不同的描述
if entity_info['type'] == 'star':
props = entity_info['properties']
return (f"恒星{entity_id}是一颗位于赤经{props['ra']}度、"
f"赤纬{props['dec']}度的天体,其有效温度为{props['teff']}K,"
f"表面重力为{props['logg']},金属丰度为{props['feh']}。")
elif entity_info['type'] == 'galaxy':
props = entity_info['properties']
return (f"星系{entity_id}是一个{props['morphological_type']}型星系,"
f"红移为{props['redshift']},恒星质量为{props['stellar_mass']}太阳质量。")
# 其他实体类型...
return f"{entity_info['type']}{entity_id}的相关信息。"
3.5 天一大模型的应用生态
天一大模型支持多种天文研究场景:
四、技术挑战与未来发展方向
4.1 当前技术挑战
天文大模型的发展面临多个技术挑战:
class AstronomicalChallenges:
"""天文大模型技术挑战分析"""
def __init__(self):
self.challenges = {
'data_heterogeneity': {
'description': '天文数据异质性强,不同波段、分辨率、仪器格式不一',
'severity': 'high',
'solutions': ['多模态融合', '数据标准化', '自适应预处理']
},
'class_imbalance': {
'description': '天文现象发生率极不平衡,稀有事件样本少',
'severity': 'high',
'solutions': ['重采样技术', '代价敏感学习', '少样本学习']
},
'noise_and_artifacts': {
'description': '观测数据包含各种噪声和仪器效应',
'severity': 'medium',
'solutions': ['去噪算法', '数据增强', '对抗训练']
},
'interpretability': {
'description': '模型决策过程需要天文学可解释性',
'severity': 'medium',
'solutions': ['可解释AI', '注意力可视化', '物理约束模型']
},
'computational_resources': {
'description': '海量数据和大型模型需要巨大计算资源',
'severity': 'high',
'solutions': ['分布式训练', '模型压缩', '高效注意力机制']
}
}
def analyze_challenge(self, challenge_key):
"""分析特定挑战的解决方案"""
if challenge_key not in self.challenges:
raise ValueError(f"未知挑战: {challenge_key}")
challenge = self.challenges[challenge_key]
print(f"挑战: {challenge['description']}")
print(f"严重程度: {challenge['severity']}")
print("解决方案:")
for i, solution in enumerate(challenge['solutions'], 1):
print(f"{i}. {solution}")
def get_prioritized_challenges(self):
"""按严重程度排序的挑战列表"""
severity_order = {'high': 0, 'medium': 1, 'low': 2}
return sorted(self.challenges.items(),
key=lambda x: severity_order[x[1]['severity']])
4.2 未来发展方向
天文大模型的未来发展方向包括:
4.3 技术融合趋势
未来天文研究将深度融合多种前沿技术:
class FutureAstronomyAI:
"""未来天文AI技术融合"""
def __init__(self):
self.technologies = {
'foundation_models': {
'description': '基础模型作为天文智能基座',
'status': 'ongoing',
'impact': 'transformative'
},
'knowledge_graphs': {
'description': '天文知识图谱增强模型推理能力',
'status': 'developing',
'impact': 'high'
},
'neuromorphic_computing': {
'description': '类脑计算处理实时观测数据',
'status': 'experimental',
'impact': 'medium'
},
'quantum_ml': {
'description': '量子机器学习处理极端计算问题',
'status': 'research',
'impact': 'long_term'
},
'federated_learning': {
'description': '联邦学习保护观测数据隐私',
'status': 'developing',
'impact': 'medium'
}
}
def get_technology_roadmap(self):
"""获取技术发展路线图"""
roadmap = {
'short_term': ['foundation_models', 'knowledge_graphs'],
'mid_term': ['federated_learning', 'edge_ai'],
'long_term': ['quantum_ml', 'neuromorphic_computing']
}
return roadmap
def estimate_impact(self, technology_key):
"""评估技术影响"""
if technology_key not in self.technologies:
raise ValueError(f"未知技术: {technology_key}")
tech = self.technologies[technology_key]
impact_scores = {'transformative': 5, 'high': 4, 'medium': 3, 'low': 2}
return {
'technology': technology_key,
'description': tech['description'],
'impact_score': impact_scores[tech['impact']],
'readiness_level': self._get_readiness_level(tech['status'])
}
def _get_readiness_level(self, status):
"""获取技术就绪水平"""
levels = {
'research': 1,
'experimental': 2,
'developing': 3,
'ongoing': 4,
'mature': 5
}
return levels.get(status, 0)
结论:中国天文大模型的贡献与展望
中国在天文大模型领域的研究已取得显著进展,FALCO、SpecCLIP、天一大模型等工作在不同方向推动了"AI+天文"的融合发展。这些模型不仅解决了具体的天文研究问题,更代表了人工智能在天文学中应用的新范式。
主要贡献总结:
-
方法论创新:提出了针对天文数据特点的专用模型架构,如FALCO的周期性注意力机制和SpecCLIP的跨模态对比学习。
-
技术突破:在多个天文任务上实现了性能显著提升,如耀斑预报准确率提高30%以上,光谱参数测量误差降低40%。
-
数据生态:构建了大规模天文知识图谱和高质量训练数据集,为后续研究奠定基础。
-
应用落地:部分模型已达到业务化应用标准。
未来展望:
随着计算技术的进步和天文数据的持续积累,天文大模型将在以下方面产生更大影响:
- 发现未知现象:通过无监督学习发现新的天文现象和规律
- 多信使天文学:融合光学、射电、引力波、中微子等多信使数据
- 实时决策支持:为时域天文学和观测策略提供实时智能支持
- 公众科学:降低天文研究门槛,促进公众参与科学发现
中国天文大模型的发展正处于快速上升期,未来有望在全球人工智能与天文学的交叉研究中发挥引领作用,为人类认识宇宙作出重要贡献。
相关资源:

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 112
112 0
0- 0



 已为社区贡献155条内容
已为社区贡献155条内容

所有评论(0)