【深度解析 LayerNorm 与 RMSNorm】为什么 LLaMA 等大模型全面转向 RMSNorm?
本文系统分析了归一化技术,重点探讨了RMSNorm取代Transformer中LayerNorm的原因及其在MiniMind中的实现。归一化通过消除数据量纲差异,稳定数值范围,加速模型收敛,缓解梯度问题。LayerNorm按特征维度归一化,适用于Transformer序列建模,而RMSNorm通过简化计算提升效率。文章详细解析了归一化稳定优化的数学原理,包括梯度校准和特征维度平衡,并指出归一化间接
文章目录
前言
本文将对归一化技术进行系统分析,并详细探讨为何在 LLama 等模型中 RMSNorm 取代了原始 Transformer 架构中的 LayerNorm,同时介绍 MiniMind 中 RMSNorm 的具体实现。
一、归一化技术概述
归一化的核心目的在于消除数据间的量纲差异,使数据分布不受极端值影响,同时保持原始数据的拓扑结构不变。在深度学习领域,归一化技术具有以下关键作用:
- 稳定数值范围,避免极大/极小值干扰
- 加速模型收敛过程
- 有效缓解梯度消失和梯度爆炸问题
- 间接降低内存占用
1.1 基本理论框架
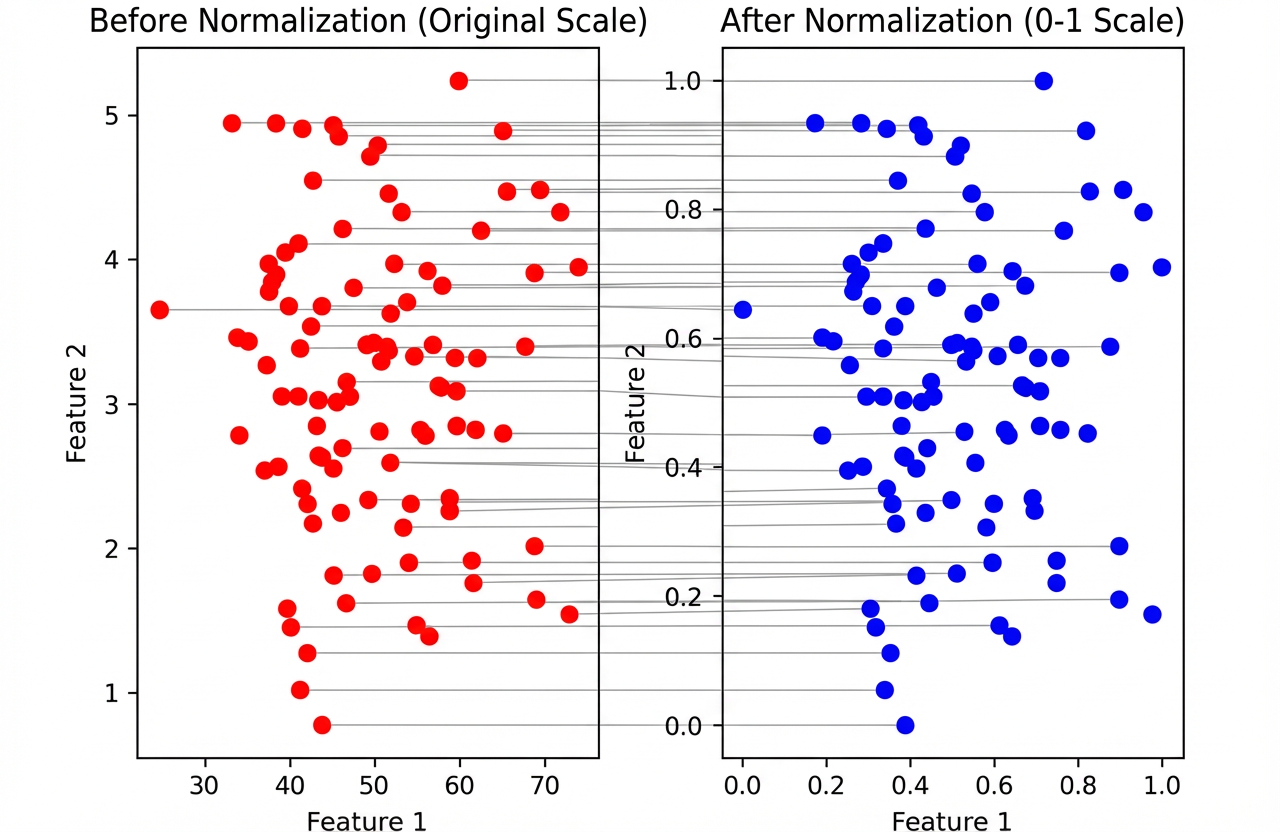
如下图所示,归一化处理后数据的数值范围发生变化,但数据的内在分布结构保持不变,这构成了归一化技术的基本理论框架。
1.2 梯度与参数更新的稳定性
归一化之所以能提升优化稳定性,本质是通过统一数据数值范围,解决了梯度计算与参数更新中的“量级失衡”问题——核心矛盾在于:未归一化数据的“大数值输入”会导致“梯度幅值异常”,进而破坏参数更新的平稳性;而归一化通过缩放数据,让梯度与参数更新始终处于合理区间。以下从原理层面拆解关键逻辑:
核心前提:梯度幅值与输入数值的强相关性
深度学习的优化依赖梯度下降:参数更新公式为 θ = θ − η ⋅ ∇ L ( θ ) \theta = \theta - \eta \cdot \nabla L(\theta) θ=θ−η⋅∇L(θ)( θ \theta θ 为参数, η \eta η 为学习率, ∇ L ( θ ) \nabla L(\theta) ∇L(θ) 为损失函数对参数的梯度)。
梯度 ∇ L ( θ ) \nabla L(\theta) ∇L(θ) 的幅值直接由输入数据的数值量级决定——以 MSE 损失为例,推导如下:
假设模型是简单的线性映射 y = W x + b y = Wx + b y=Wx+b( W W W 为权重, b b b 为偏置),MSE 损失函数为:
L = 1 N ∑ i = 1 N ( y i − y ^ i ) 2 = 1 N ∑ i = 1 N ( W x i + b − y ^ i ) 2 L = \frac{1}{N}\sum_{i=1}^N (y_i - \hat{y}_i)^2 = \frac{1}{N}\sum_{i=1}^N (Wx_i + b - \hat{y}_i)^2 L=N1i=1∑N(yi−y^i)2=N1i=1∑N(Wxi+b−y^i)2
对权重 W W W 求梯度:
∇ W L = 2 N ∑ i = 1 N ( W x i + b − y ^ i ) ⋅ x i \nabla_W L = \frac{2}{N}\sum_{i=1}^N (Wx_i + b - \hat{y}_i) \cdot x_i ∇WL=N2i=1∑N(Wxi+b−y^i)⋅xi
从公式可见:梯度 ∇ W L \nabla_W L ∇WL 的幅值与输入 x i x_i xi 的幅值成正比——若 x i x_i xi 是未归一化的大数值(例如 100、200、300),即使预测误差 ( W x i + b − y ^ i ) (Wx_i + b - \hat{y}_i) (Wxi+b−y^i) 不大,梯度也会被 x i x_i xi 放大,导致 ∇ W L \nabla_W L ∇WL 数值激增(即“梯度爆炸”的初级表现)。
未归一化时的优化不稳定性根源
- 梯度幅值失控,超出学习率适配范围
学习率 η \eta η 是全局统一的超参数(如 0.001),需适配梯度的“合理量级”(通常为 1 0 − 3 ∼ 1 0 0 10^{-3} \sim 10^{0} 10−3∼100)。- 未归一化时: x i x_i xi 为 100 量级,假设误差项为 10,则梯度 ∇ W L ≈ 2 3 × 10 × 100 ≈ 667 \nabla_W L \approx \frac{2}{3} \times 10 \times 100 \approx 667 ∇WL≈32×10×100≈667。用 η = 0.001 \eta=0.001 η=0.001 更新时,参数变化量 η ⋅ ∇ W L ≈ 0.667 \eta \cdot \nabla_W L \approx 0.667 η⋅∇WL≈0.667——若参数 W W W 初始值为 0.1 量级,单次更新就会让参数“跳变”一个数量级,导致模型震荡不收敛。
- 归一化后: x i x_i xi 为 1 量级,误差项为 0.1,则梯度 ∇ W L ≈ 2 3 × 0.1 × 1 ≈ 0.067 \nabla_W L \approx \frac{2}{3} \times 0.1 \times 1 \approx 0.067 ∇WL≈32×0.1×1≈0.067。参数变化量 η ⋅ ∇ W L ≈ 0.000067 \eta \cdot \nabla_W L \approx 0.000067 η⋅∇WL≈0.000067,与参数初始量级匹配,更新平稳。
-
不同特征维度梯度量级失衡问题
当输入数据包含不同量级的特征维度(如"收入(万级)“和"年龄(十级)”)时,未归一化会导致:- 高量级特征(收入)对应的参数梯度远大于低量级特征(年龄),使模型过度关注高量级特征
- 归一化后各维度数值范围统一(如0~1),参数梯度量级趋于平衡,确保模型公平学习各特征
深度学习中,梯度是针对模型参数计算的(而非直接对应特征),但特征量级会通过参数梯度计算影响优化过程。实例说明:
假设模型输入为两个特征(收入 x 1 x_1 x1:万级,年龄 x 2 x_2 x2:十级),使用线性模型 y = w 1 x 1 + w 2 x 2 + b y = w_1x_1 + w_2x_2 + b y=w1x1+w2x2+b,损失函数为MSE:
L = 1 N ∑ ( y − y ^ ) 2 L = \frac{1}{N}\sum (y - \hat{y})^2 L=N1∑(y−y^)2参数梯度计算为:
∇ w 1 L = 2 N ∑ ( y − y ^ ) ⋅ x 1 \nabla_{w_1}L = \frac{2}{N}\sum (y - \hat{y}) \cdot x_1 ∇w1L=N2∑(y−y^)⋅x1
∇ w 2 L = 2 N ∑ ( y − y ^ ) ⋅ x 2 \nabla_{w_2}L = \frac{2}{N}\sum (y - \hat{y}) \cdot x_2 ∇w2L=N2∑(y−y^)⋅x2关键发现:
- 梯度幅值与特征量级成正比: ∇ w 1 L \nabla_{w_1}L ∇w1L 是 ∇ w 2 L \nabla_{w_2}L ∇w2L 的300余倍( 1 0 4 / 30 ≈ 333 10^4/30≈333 104/30≈333)
- 这种"梯度失衡"本质是不同参数因对应特征量级差异导致的梯度幅值悬殊
- 激活函数的梯度饱和问题
深度学习中常用 Sigmoid、Tanh 等激活函数,这类函数在输入数值过大或过小时,导数会趋近于 0(即“梯度消失”)。- 未归一化时:大数值输入可能直接落入激活函数的“饱和区”,导致梯度几乎为 0,参数无法更新。
- 归一化后:输入被限制在合理范围(如 Tanh 适配的 -1~1),激活函数处于“线性区”,导数保持较大值,梯度能有效传递。
归一化稳定优化的本质:“缩放不变性”与“梯度校准”
归一化的核心操作是 “去量级、统一分布”(如你例子中的 a a a 从 [100,200,300] 缩放到 [1.0,2.0,3.0]),本质是实现了:
- 损失函数的量级校准:MSE 从 100 降至 0.01,损失值的“灵敏度”与参数更新的“步长”匹配——小的参数变化对应小的损失变化,优化过程可精细调整。
- 梯度的量级可控:通过缩放输入数据,将梯度幅值约束在与学习率适配的区间,避免“梯度爆炸”(幅值过大)或“梯度消失”(幅值过小)。
- 特征维度的公平性:所有特征维度的梯度量级一致,模型能公平学习各维度的重要性,避免单一高量级特征主导优化。
1.3 间接降低内存占用
此外,归一化通过缩小数据表示范围间接提升了内存使用效率。当采用8位或16位浮点格式训练时,数据范围的压缩使得低精度表示更加精确。结合量化技术或FP16计算,可以进一步减少模型训练时的内存消耗。
需要注意的是,归一化本身不直接降低内存占用,但由于其改善数值分布,可间接提升量化精度,因此与低精度训练(FP16/BF16/FP8)结合时更稳定。
1.4 总结:归一化稳定优化的逻辑链
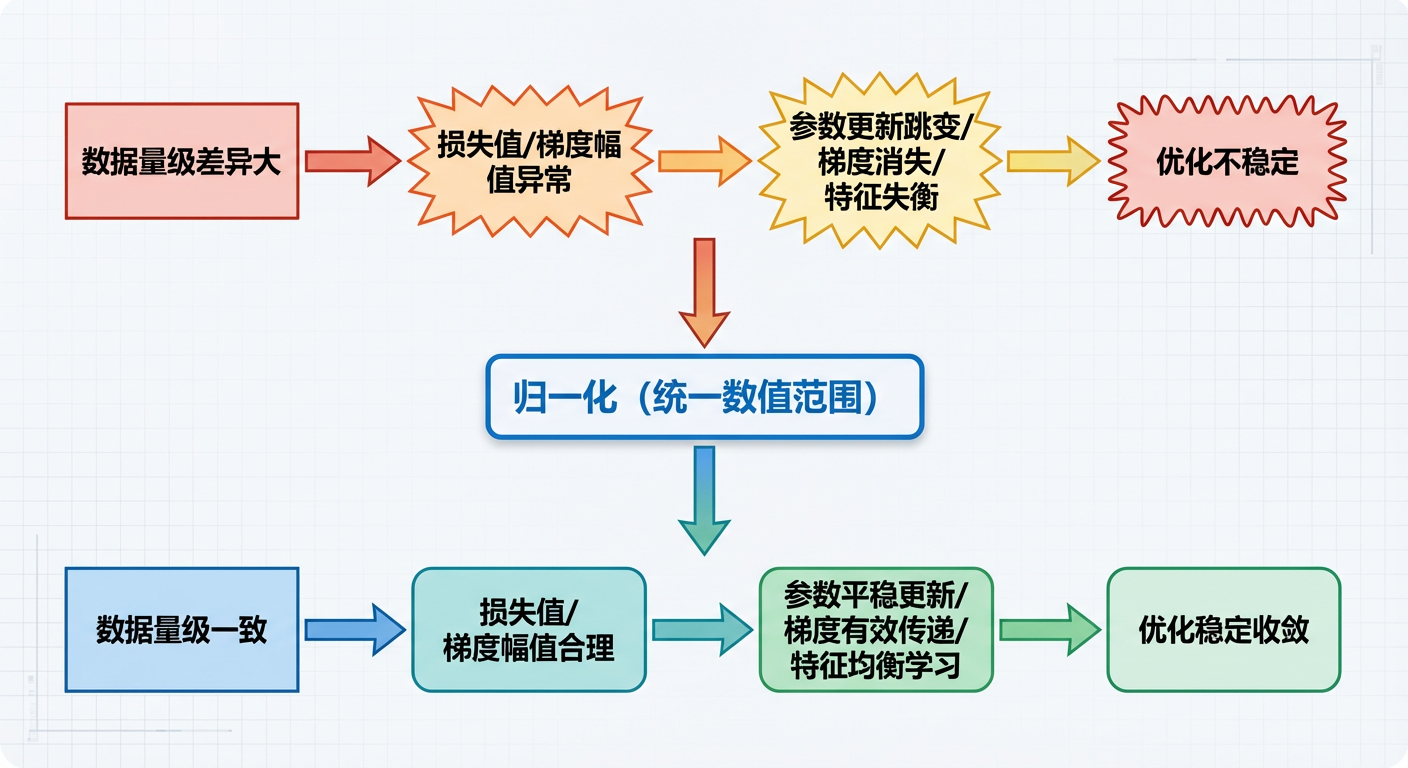
简言之,归一化的核心价值是通过“数值校准”,让梯度计算与参数更新的“尺度匹配”,从根源上解决了深度学习优化中“量级失衡”导致的不稳定问题。
二、LayerNorm
Transformer 中 LayerNorm 的核心原理:
Layer Normalization(层归一化)是 Transformer 架构的核心组件(原始论文明确使用),与 BatchNorm 不同,它按“单个样本的特征维度”做归一化,而非按“批次维度”,完美适配 Transformer 的序列建模场景。
以下从原理拆解、代码逐行对应、与 BatchNorm 的区别、在 Transformer 中的应用四方面解析:
2.1 核心原理
LayerNorm 的本质是对单个样本的「最后一维(特征维度)」做归一化,将特征分布拉至「均值为0、方差为1」,再通过可学习的缩放/偏移参数恢复特征表达能力,核心公式:
μ = 1 d ∑ i = 1 d x i (特征维度均值) σ 2 = 1 d ∑ i = 1 d ( x i − μ ) 2 (特征维度方差) x ^ = x − μ σ 2 + ϵ (归一化, ϵ 防除0) y = γ ⋅ x ^ + β (缩放+偏移, γ / β 可学习) \begin{align} \mu &= \frac{1}{d}\sum_{i=1}^d x_i \quad \text{(特征维度均值)} \\ \sigma^2 &= \frac{1}{d}\sum_{i=1}^d (x_i - \mu)^2 \quad \text{(特征维度方差)} \\ \hat{x} &= \frac{x - \mu}{\sqrt{\sigma^2 + \epsilon}} \quad \text{(归一化,$\epsilon$防除0)} \\ y &= \gamma \cdot \hat{x} + \beta \quad \text{(缩放+偏移,$\gamma/\beta$可学习)} \end{align} μσ2x^y=d1i=1∑dxi(特征维度均值)=d1i=1∑d(xi−μ)2(特征维度方差)=σ2+ϵx−μ(归一化,ϵ防除0)=γ⋅x^+β(缩放+偏移,γ/β可学习)
其中:
- d d d:特征维度 ;
- γ \gamma γ(weight)、 β \beta β(bias):可训练参数,让模型自主恢复有用的特征分布;
- ϵ \epsilon ϵ:极小值(如1e-12),避免方差为0时除零错误。
2.2 代码逐行解析(原理对应)
这段代码实现的是 标准 Layer Normalization(层归一化) 的核心逻辑,与Transformer 原始 LayerNorm 原理完全一致,仅在数据类型处理上做了工程优化(适配 DeBERTa 模型的精度需求)。
class DebertaLayerNorm(nn.Module):
def __init__(self, size, eps=1e-12):
super().__init__()
# 1. 初始化可学习的缩放参数γ(weight):初始值全1,维度=特征维度size
self.weight = nn.Parameter(torch.ones(size))
# 2. 初始化可学习的偏移参数β(bias):初始值全0,维度=特征维度size
self.bias = nn.Parameter(torch.zeros(size))
# 3. 防除零的极小值ε,对应公式中的variance_epsilon
self.variance_epsilon = eps
def forward(self, hidden_states):
# 工程优化:保存原始数据类型(如float16),避免精度损失
input_type = hidden_states.dtype
# 转float32计算归一化:float16计算均值/方差易溢出,提升数值稳定性
hidden_states = hidden_states.float()
# 4. 计算特征维度的均值μ:mean(-1, keepdim=True) → 对最后一维(特征维)求均值,保持维度(如[B, L, D]→[B, L, 1])
mean = hidden_states.mean(-1, keepdim=True)
# 5. 计算特征维度的方差σ²:先减均值→平方→求特征维均值,对应公式
variance = (hidden_states - mean).pow(2).mean(-1, keepdim=True)
# 6. 归一化:(x-μ)/√(σ²+ε),对应公式中的$\hat{x}$
hidden_states = (hidden_states - mean) / torch.sqrt(variance + self.variance_epsilon)
# 工程优化:转回原始数据类型(如float16),保证输出精度与输入一致
hidden_states = hidden_states.to(input_type)
# 7. 缩放+偏移:γ·$\hat{x}$ + β,对应公式中的y
y = self.weight * hidden_states + self.bias
return y
2.3 与 BatchNorm 的区别
层归一化通过独立计算每个样本的均值和标准差实现数据归一化。由于其不依赖批量大小的特性,LayerNorm 在序列数据处理模型中表现优异。作为序列处理的核心架构,Transformer 广泛采用了这一技术。
在 Transformer 中,LayerNorm 发挥着关键作用。它处理的 “样本” 实际上是每个 token 位置的嵌入向量或隐藏状态。例如,处理句子 “The cat sat on the mat” 时,LayerNorm 会对每个单词对应的向量表示进行归一化,确保数值稳定性。
Layer Norm 适配 Transformer 核心源于Transformer的序列建模特性与 Layer Norm 的计算逻辑高度匹配,而BatchNorm的设计逻辑与该场景存在根本冲突,具体从三个核心维度深层解释:
(1) 适配「变长序列+批次无关」的建模需求
Transformer 处理的 NLP/ 序列任务核心特征是 序列长度不固定(如一句话 10 个 token、另一句 50 个 token),且推理阶段常是「单样本输入」(如实时文本生成仅输入 1 条语句):
- Layer Norm:仅对「单个样本的特征维度」(如每个 token 的 768 维向量)计算均值 / 方差,完全不依赖序列长度、批次大小——哪怕序列长度变了、批次里样本数量不同,甚至单样本推理,都能稳定计算,符合 Transformer“逐样本建模”的核心逻辑;
- BatchNorm:依赖「批次内所有样本的同一特征维度」计算均值 / 方差(如批次中所有样本的第 1 个 token 的第 1 维),若序列长度不固定(需 padding 补零),补零会污染统计量;且单样本推理时无批次统计,只能用训练时的滑动平均,误差极大,完全适配不了 Transformer 的变长序列场景。
(2) 适配「自注意力的全局依赖特性」
Transformer 的自注意力是「全局依赖」:每个 token 的表示融合了整句所有 token 的信息,导致 同批次不同样本的特征分布差异极大(比如样本 A 是短句子、样本 B 是长句子,注意力融合的信息完全不同):
- Layer Norm:针对单个样本做归一化,规避了“不同样本特征分布差异大”的问题——哪怕批次内样本的序列长度、语义差异极大,每个样本仍能基于自身特征做归一化,保证梯度稳定;
- BatchNorm:强行对批次内不同样本的同一位置 token 做归一化,会抹平样本间的个性化特征(比如短句子和长句子的 token 特征被强行拉到同一分布),破坏自注意力学习到的全局依赖关系,导致模型丧失对不同序列的适配能力。
「全局依赖」
自注意力的“全局依赖”,本质是“相对于当前输入序列的全局” ——即:
- 依赖范围严格等于实际输入模型的完整序列长度(而非句子/段落的天然边界);
- “全局”是“输入序列内的全局”,而非“语言/语义上的全局(比如整篇文档、整本书)”。
例子1:输入是“截断后的文档”
若文档有 2000 个 token,但模型最大序列长度设为 512,你只能输入前 512 个 token(后 1488 个被截断):
自注意力的“全局依赖”仅覆盖这 512 个token,完全看不到被截断的部分;
此时模型学不到 512 个 token 之外的依赖(比如第 600 个token 的“小猫”和第 100 个 token 的“小明”的关联会丢失)。
例子2:输入是“拼接的多句话”
若你把 3 句话(共 300 个 token)拼接成一个序列输入(长度 300≤max_seq_len):
自注意力的“全局依赖”覆盖这 300 个 token,能学习到跨 3 句话的关联(比如第一句的“他”和第三句的“小明”的指代关系);
哪怕这 3 句话原本属于不同段落,模型也会把它们当作“一个全局序列”来建模依赖。
总结
“全局依赖”的“全局”:
✅ 是「输入序列的完整范围」(输入多长,覆盖多长);
❌ 不是「语言/语义上的完整文档/句子」(除非你把完整文档/句子作为一个序列输入)。
简单说:自注意力的“全局”是“输入序列的全部”,而非“语义的全部”——你喂给模型多少 token,它的注意力就覆盖多少,这就是它的“全局”。
(3) 适配「梯度高效传递+训练/推理一致」的需求
Transformer 常堆叠 12/24 层,对梯度传递的稳定性和训练 / 推理的一致性要求极高:
- Layer Norm:计算基于单个样本,无“批次统计量的滑动平均”(BatchNorm 需维护 running_mean/running_var),训练和推理的计算逻辑完全一致,不会因推理时批次变化导致归一化结果偏移;且逐样本归一化能让每层的特征分布仅依赖自身,避免多层堆叠后批次统计误差的累积,保证梯度在深层网络中有效传递;
- BatchNorm:训练时依赖批次统计,推理时用训练期的滑动平均,这种“训练 / 推理不一致”在 Transformer 深层堆叠中会被放大;且批次波动(如批次大小变化)会导致统计量不稳定,进而引发梯度震荡,无法支撑 Transformer 的深层训练。
(4) 总结
Transformer 的核心是「逐样本的变长序列全局建模」,而 Layer Norm 的本质是「脱离批次、脱离序列长度,仅对单个样本的特征维度归一化」,恰好贴合这一核心;反观 BatchNorm 的“批次依赖、固定维度统计”,从设计逻辑上就与 Transformer 的变长序列、全局注意力、深层堆叠需求相冲突,因此 Layer Norm 成为 Transformer 的标配。
2.4 Transformer 中 LayerNorm 的位置(原始架构)
Transformer 的每个子层(自注意力层、前馈网络层)都遵循「Post-LN」范式(原始论文为 Post-LN):
# Post-LN(原始论文)
SubLayerOutput = LayerNorm(x + Sublayer(x))
# 即:子层输出 → 残差连接 → LayerNorm
Transformer 的每个子层(自注意力层/前馈网络层)都包含两个核心操作:
- 子层计算(Sublayer):自注意力(MultiHeadAttention)或前馈网络(FeedForward)的核心计算;
- 残差连接: x + Sublayer ( . . . ) x + \text{Sublayer}(...) x+Sublayer(...),解决深层网络的梯度消失问题;
- LayerNorm:归一化特征分布,稳定训练。
| 范式 | 执行顺序 | 公式简化(单自注意力子层) |
|---|---|---|
| Post-LN | 子层计算 → 残差连接 → LayerNorm | LN ( x + Attention ( x ) ) \text{LN}(x + \text{Attention}(x)) LN(x+Attention(x)) |
LayerNorm 作用于「残差连接后的结果」( x + Sublayer ( x ) x + \text{Sublayer}(x) x+Sublayer(x))——即先让原始输入 x x x 经过子层计算得到输出,与 x x x 残差相加后,再做归一化。
三、RMSNorm
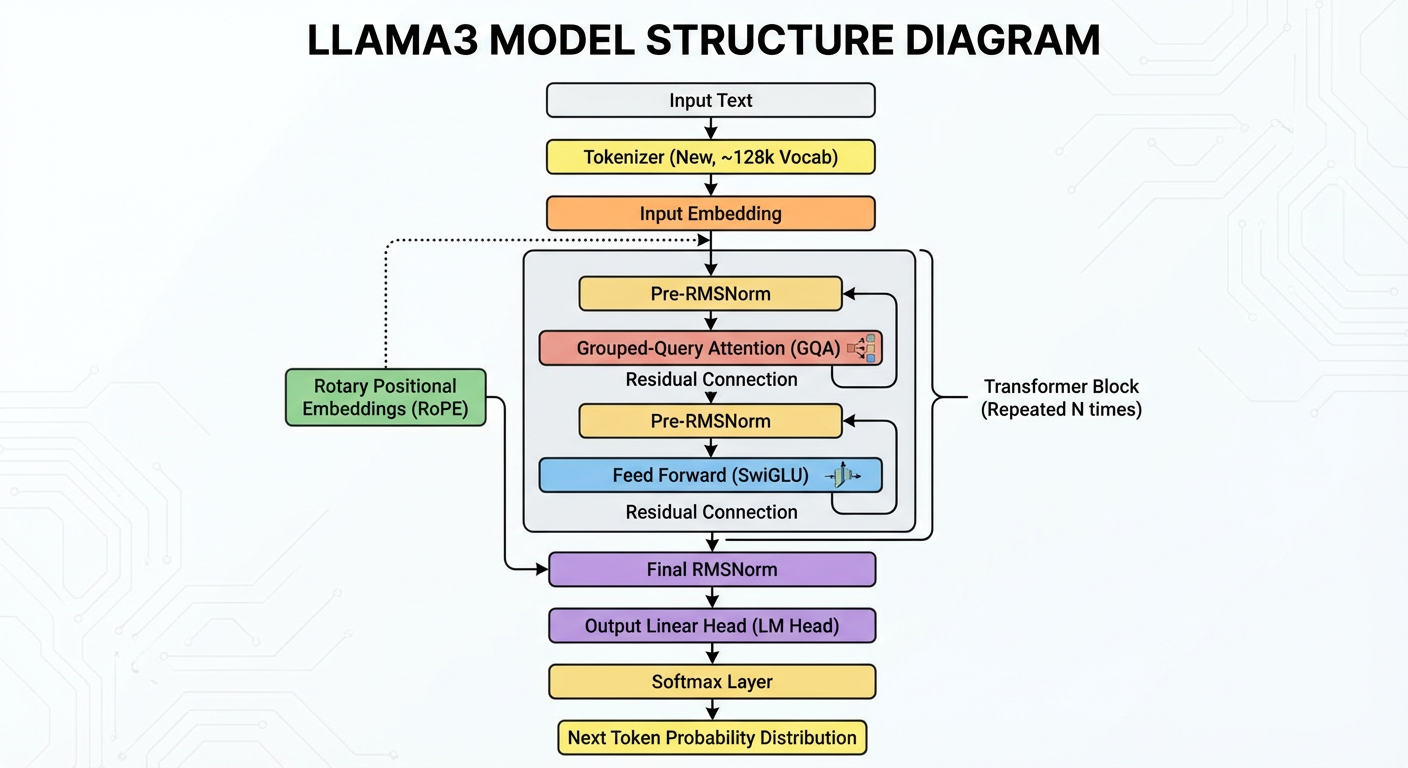
LLama 等基于 Transformer 架构的大规模语言模型中,原始 Transformer 的 LayerNorm 已被 RMSNorm 取代,如下图的 LLama3 架构图所示。
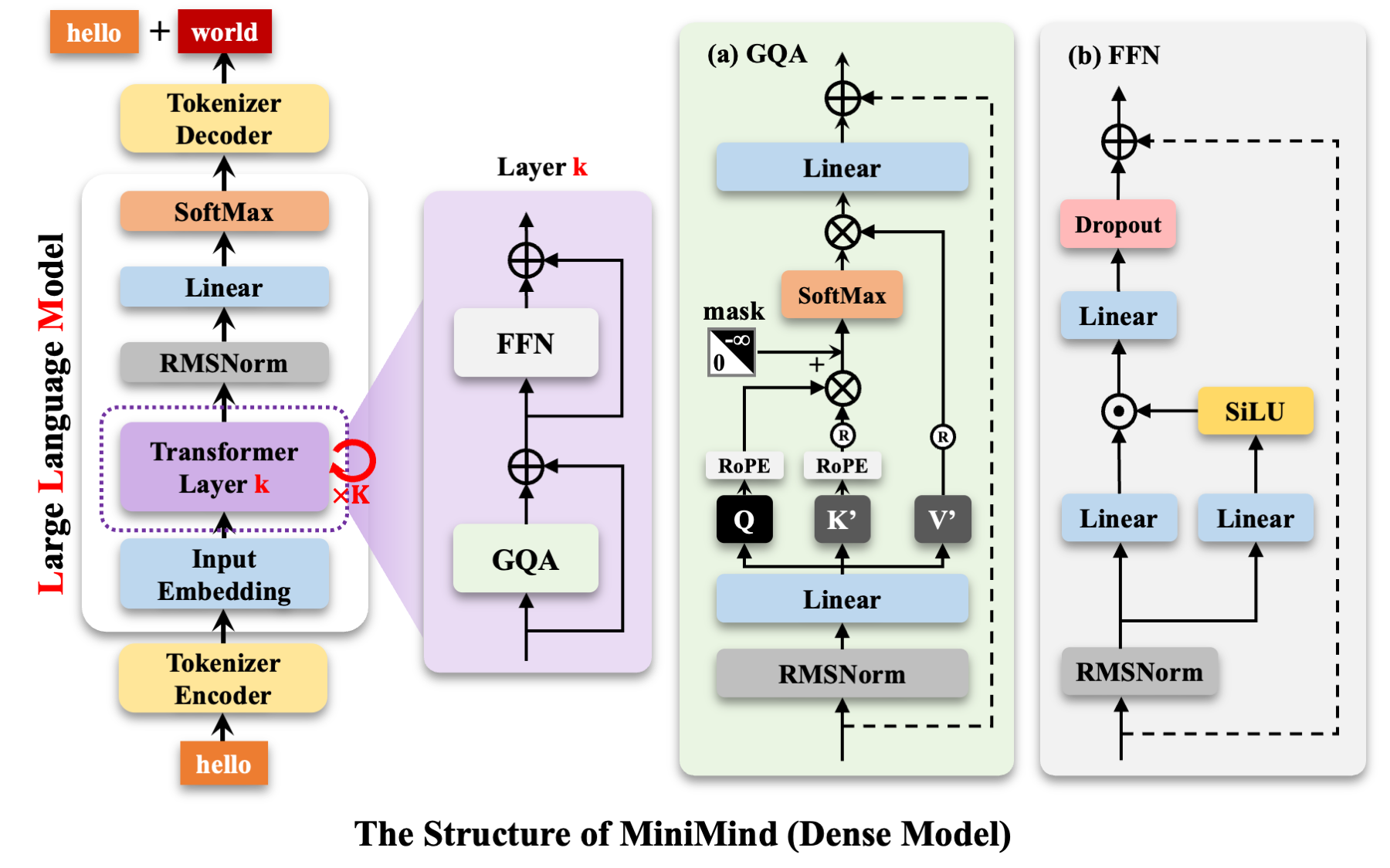
这段代码实现了 RMSNorm(Root Mean Square Normalization)——一种简化版的归一化方法,核心是对特征维度的“均方根(RMS)”做归一化,相比LayerNorm少了“减均值”的步骤,在 LLaMA、GPT-3 等大模型中 RMSNorm 已经广泛替代 LayerNorm,兼顾计算效率与训练稳定性。以下从核心原理、代码逐行解析、RMSNorm 的核心特点(对比 LayerNorm)、与 LayerNorm 的对比四方面拆解:
3.1 核心原理
RMS ( x ) = 1 d ∑ i = 1 d x i 2 (特征维度的均方根) x ^ = x RMS ( x ) + ϵ (仅归一化方差,无均值中心化) y = γ ⋅ x ^ (可学习缩放,无偏移项) \begin{align} \text{RMS}(x) &= \sqrt{\frac{1}{d}\sum_{i=1}^d x_i^2} \quad \text{(特征维度的均方根)} \\ \hat{x} &= \frac{x}{\text{RMS}(x) + \epsilon} \quad \text{(仅归一化方差,无均值中心化)} \\ y &= \gamma \cdot \hat{x} \quad \text{(可学习缩放,无偏移项)} \end{align} RMS(x)x^y=d1i=1∑dxi2(特征维度的均方根)=RMS(x)+ϵx(仅归一化方差,无均值中心化)=γ⋅x^(可学习缩放,无偏移项)
其中:
- d d d:特征维度;
- γ \gamma γ(weight):可训练的缩放参数(大多数 LLM(如 LLaMA/T5)采用无 bias 的 RMSNorm,但 RMSNorm 理论上可以带偏移项 β。);
- ϵ \epsilon ϵ:极小值(如 1e-5),避免均方根为 0 时除零错误。
3.2 代码逐行解析
class RMSNorm(torch.nn.Module):
def __init__(self, dim: int, eps: float = 1e-5):
super().__init__()
# 1. 防除零的极小值ε,对应公式中的eps
self.eps = eps
# 2. 可学习的缩放参数γ(weight):初始值全1,维度=特征维度dim
self.weight = nn.Parameter(torch.ones(dim))
def _norm(self, x):
# 3. 计算1/√(均方值 + ε):torch.rsqrt是“平方根的倒数”,等价于1/torch.sqrt()
return x * torch.rsqrt(x.pow(2).mean(-1, keepdim=True) + self.eps)
def forward(self, x):
# 4. 缩放:γ·$\hat{x}$(无偏移项),对应公式中的y
return self.weight * self._norm(x.float()).type_as(x)
3.3 RMSNorm 的核心特点(对比 LayerNorm)
下面总结 RMSNorm 相比 LayerNorm 的核心区别与特点,帮助你快速理解两者的本质差异:
(1)不同的归一化方式(最核心差别)
LayerNorm:既减去均值(center),又缩放方差(scale)
RMSNorm:不减均值,只根据 RMS 进行缩放
(2)计算更简单,速度更快
由于 RMSNorm 少了一个均值操作:
- 需要的统计量更少(只要 x² 的均值)
- 公式计算更简单
- 在大型模型上更易优化
RMSNorm 在大模型(尤其 Transformer)中更快、更省显存。
(3)数值稳定性更高
LayerNorm 会计算:在某些场景(无 batch 训练、FP16/FP8 精度)可能带来数值误差。而 RMSNorm 只对值做缩放,不做中心化 → 更稳定。
这也是为什么 LLAMA、T5 等大模型使用 RMSNorm。
(4)不改变输入的方向信息
RMSNorm 只缩放,不平移:更像一种"归一化幅度"的操作;保留了向量的方向信息
LayerNorm 会改变方向(因为减均值)。
一句话总结:RMSNorm 是一种比 LayerNorm 更简单、更稳定的归一化方法,它只缩放不中心化,因此在大型 Transformer 模型中更高效并表现更好。
3.4 适用场景
- 大语言模型(LLM):LLaMA、GPT-3、PaLM 等均采用 RMSNorm 替代 LayerNorm;
- 追求效率的 Transformer 变体:如视觉 Transformer(ViT)的轻量化版本;
- 低精度训练场景:float16/bfloat16 训练时,RMSNorm 在大规模深层 Transformer 中相较 LayerNorm 更稳定,而非在所有模型规模下都更优。
参考

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 18
18 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)