51c视觉~YOLO~合集14
在智能交通系统领域,实时检测车辆事故的能力变得越来越重要。该项目利用先进的计算机视觉技术,采用最先进的对象检测模型 YOLOv11 来准确识别和分类车辆事故。主要目标是通过向紧急服务提供及时警报并实现更快的响应时间来提高道路安全。YoloV11 是 ultralytics 的 Yolo 最新版本,与以前的版本相比,有几个优点和最大的功能,有关更多信息,请查看官方 ultralytics yoloV
我自己的原文哦~ https://blog.51cto.com/whaosoft143/14017916
1、Yolo8
1.1、NVIDIA RTX 5070 Ti~YOLOv8分割模型实时优化
帧率达374 FPS~
在本文中,我们将带您全面了解如何使用 NVIDIA TensorRT 优化 YOLOv8 分割模型,并取得令人瞩目的成果。

使用 TensorRT FP16 和 YOLOv8s-seg,在 RTX 5070 Ti GPU 上实现了 374 FPS
在 GeForce RTX 5070 Ti 上,推理速度最高可达 374 FPS。我们将涵盖从数据集准备到模型导出和基准测试的所有内容,演示如何最大限度地发挥 GPU 的性能,以满足实时计算机视觉应用的需求。
应用案例?实时统计传送带上的苹果数量——这是一个既需要精度又需要速度的实际工业应用。
环境搭建
# 创建虚拟环境
python3 -m venv venv
source venv/ bin /activate
# 安装支持 CUDA 的 PyTorch
pip install --pre torch torchvision torchaudio --index-url https://download.pytorch.org/whl/nightly/cu128
# 安装 YOLOv8 及其依赖项
pip install ultralytics --no-deps
# 安装 TensorRT(CUDA 12.x 版本)
pip install tensorrt-cu12
# 重新安装 PyTorch 所需的 CUDA 运行时版本
pip install nvidia-cuda-runtime-cu12== 12.8 .90
# 安装可视化和实用程序
pip install opencv-python supervisor
# 验证安装
python -c "import torch; print(f'PyTorch: {torch.__version__}')"
python -c "import torch; print(f'CUDA Available: ' {torch.cuda.is_available()}')"
python -c "import tensorrt; print(f'TensorRT: {tensorrt.__version__}')"模型导出:PyTorch 到 TensorRT
将训练好的 YOLOv8 模型转换为针对 FP32、FP16 和 INT8 精度的优化 TensorRT 引擎。
#!/usr/bin/env python3
"""Export YOLOv8 to TensorRT engines (FP32, FP16, INT8)"""
from ultralytics import YOLO
import shutil
from pathlib import Path
import yaml
# Configuration
MODEL_PATH = "model/yolov8/yolov8s_seg_320.pt"
IMG_SIZE = 320
BATCH_SIZE = 1
CALIBRATION_IMAGES = "video-dataset/calibrate_image"
model_path = Path(MODEL_PATH).resolve()
model_dir = model_path.parent
model_base = model_path.stem
def create_calibration_yaml(image_folder):
"""Create YAML config for INT8 calibration"""
image_folder = Path(image_folder).resolve()
if not image_folder.exists():
print(f"Error: Calibration folder not found: {image_folder}")
return None
images = list(image_folder.glob("*.jpg")) + list(image_folder.glob("*.png"))
if len(images) == 0:
print(f"Error: No images found in: {image_folder}")
return None
print(f"Found {len(images)} calibration images")
yaml_path = image_folder.parent / "calibration.yaml"
yaml_content = {
'path': str(image_folder.parent),
'train': str(image_folder.name),
'val': str(image_folder.name),
'names': {0: 'object'}
}
with open(yaml_path, 'w') as f:
yaml.dump(yaml_content, f)
return str(yaml_path)
def export_precision(precision, **kwargs):
"""Export model to TensorRT engine"""
print(f"Exporting {precision.upper()}...")
YOLO(str(model_path)).export(
format="engine",
batch=BATCH_SIZE,
imgsz=IMG_SIZE,
**kwargs
)
# Rename to precision-specific name
src = model_dir / f"{model_base}.engine"
dst = model_dir / f"{model_base}_{precision}.engine"
shutil.move(str(src), str(dst))
size = dst.stat().st_size / (1024**2)
print(f"Saved: {dst.name} ({size:.1f} MB)")
return dst
# Export FP32
export_precision("fp32", half=False)
# Export FP16
export_precision("fp16", half=True)
# Export INT8
calib_yaml = create_calibration_yaml(CALIBRATION_IMAGES)
if calib_yaml:
export_precision("int8", int8=True, data=calib_yaml)
else:
print("Skipping INT8: Calibration setup failed")
print(f"\nAll engines saved in: {model_dir}")基准测试:衡量实际性能
这些帧率数值代表完整的推理延迟,包括:
- 预处理:调整大小、标准化、格式转换
- GPU推理: TensorRT前向传播
- 后处理:非极大值抑制、坐标转换、掩模生成
这并非纯粹的GPU计算性能trtexec指标(此类指标的数值会高出30-40%)。这些测量结果反映的是应用程序在生产环境中的实际性能。
#!/usr/bin/env python3
"""YOLOv8 TensorRT Benchmark: FP32 vs FP16 vs INT8 vs ONNX"""
import cv2
import numpy as np
from ultralytics import YOLO
import supervision as sv
import time
from pathlib import Path
# Configuration
VIDEO_PATH = "test_video.mp4"
OUTPUT_VIDEO = "benchmark_comparison.mp4"
MODEL_BASE = "model/yolov8/yolov8s_seg_320"
MODELS = {
"FP32": f"{MODEL_BASE}_fp32.engine",
"FP16": f"{MODEL_BASE}_fp16.engine",
"INT8": f"{MODEL_BASE}_int8.engine",
"ONNX": f"{MODEL_BASE}.onnx",
}
# Visualization settings
FONT = cv2.FONT_HERSHEY_DUPLEX
FONT_SCALE_TITLE = 1.4
FONT_SCALE_METRICS = 1.2
FONT_THICKNESS = 3
TEXT_COLOR = (0, 255, 255)
BG_COLOR = (0, 0, 0)
TEXT_PADDING = 10
# Initialize Supervision annotators
mask_annotator = sv.MaskAnnotator(opacity=0.5)
label_annotator = sv.LabelAnnotator(
text_scale=0.6,
text_thickness=2,
text_positinotallow=sv.Position.TOP_CENTER,
text_padding=5,
border_radius=3,
)
def put_text_with_background(img, text, position, font_scale=1.0, thickness=3):
"""Draw text with background"""
(text_width, text_height), baseline = cv2.getTextSize(
text, FONT, font_scale, thickness
)
x, y = position
padding = TEXT_PADDING
cv2.rectangle(
img,
(x - padding, y - text_height - baseline - padding),
(x + text_width + padding, y + baseline + padding),
BG_COLOR,
-1
)
cv2.putText(img, text, position, FONT, font_scale, TEXT_COLOR, thickness, cv2.LINE_AA)
def annotate_with_supervision(frame, results):
"""Apply mask segmentation and labels"""
detections = sv.Detections.from_ultralytics(results[0])
annotated = mask_annotator.annotate(
scene=frame.copy(),
detectinotallow=detections
)
labels = ["apple" for _ in range(len(detections))]
annotated = label_annotator.annotate(
scene=annotated,
detectinotallow=detections,
labels=labels
)
return annotated, len(detections)
def create_2x2_grid(frames, labels, inference_fps, apple_counts):
"""Create 2x2 comparison grid"""
h, w = frames[0].shape[:2]
for frame, label, fps, count in zip(frames, labels, inference_fps, apple_counts):
put_text_with_background(frame, label, (20, 50), FONT_SCALE_TITLE, FONT_THICKNESS)
put_text_with_background(frame, f"{fps:.0f} FPS", (20, 105), FONT_SCALE_METRICS, FONT_THICKNESS)
put_text_with_background(frame, f"Apples: {count}", (20, 155), FONT_SCALE_METRICS, FONT_THICKNESS)
top_row = np.hstack([frames[0], frames[1]])
bottom_row = np.hstack([frames[2], frames[3]])
return np.vstack([top_row, bottom_row])
# Load models
print("Loading models...")
models = {}
for name, path in MODELS.items():
if Path(path).exists():
models[name] = YOLO(path, task="segment")
print(f" Loaded: {name}")
# Process video
cap = cv2.VideoCapture(VIDEO_PATH)
fps_input = int(cap.get(cv2.CAP_PROP_FPS))
frame_width = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH))
frame_height = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
total_frames = int(cap.get(cv2.CAP_PROP_FRAME_COUNT))
# Initialize video writer
output_width = frame_width * 2
output_height = frame_height * 2
fourcc = cv2.VideoWriter_fourcc(*'mp4v')
out = cv2.VideoWriter(OUTPUT_VIDEO, fourcc, fps_input, (output_width, output_height))
# Tracking
model_names = list(models.keys())
inference_fps_trackers = {name: [] for name in model_names}
frame_count = 0
# Warmup (optional but recommended)
print("Warming up models...")
dummy_frame = np.zeros((frame_height, frame_width, 3), dtype=np.uint8)
for name in model_names:
for _ in range(10):
models[name](dummy_frame, verbose=False)
print("Processing video...")
while cap.isOpened():
ret, frame = cap.read()
if not ret:
break
frame_count += 1
result_frames = []
current_fps = []
current_counts = []
for name in model_names:
model = models[name]
# Measure inference time
inf_start = time.time()
results = model(frame, verbose=False)
inf_time = time.time() - inf_start
inf_fps = 1.0 / inf_time if inf_time > 0 else 0
# Annotate
annotated, apple_count = annotate_with_supervision(frame, results)
inference_fps_trackers[name].append(inf_fps)
current_fps.append(inf_fps)
current_counts.append(apple_count)
result_frames.append(annotated)
# Create grid
grid_frame = create_2x2_grid(result_frames, model_names, current_fps, current_counts)
out.write(grid_frame)
if frame_count % 30 == 0:
print(f"Processed: {frame_count}/{total_frames} frames")
cap.release()
out.release()
# Final results
print("\nBenchmark Results:")
print(f"{'Model':<10} {'Avg FPS':<12} {'Min FPS':<12} {'Max FPS':<12}")
print("-" * 50)
for name in model_names:
if inference_fps_trackers[name]:
avg = np.mean(inference_fps_trackers[name])
min_fps = np.min(inference_fps_trackers[name])
max_fps = np.max(inference_fps_trackers[name])
print(f"{name:<10} {avg:<12.0f} {min_fps:<12.0f} {max_fps:<12.0f}")
print(f"\nOutput saved: {OUTPUT_VIDEO}")了解 FPS 指标
了解这些 FPS 数值代表什么至关重要:
我们的测量结果(230–374 FPS)
start = time.time()
results = model(frame, verbose=False) # 包括预处理 + 推理 + 后处理
fps = 1.0 / (time.time() - start)包括:
- 图像预处理(调整大小、归一化、NHWC→NCHW)
- TensorRT GPU推理
- 后处理(NMS、坐标转换、掩模生成)
- Python 开销
纯 TensorRT(trtexec:~350-450 FPS)
trtexec --loadEngine=model.engine # GPU inference ONLY仅测量 GPU 前向传播,不进行任何预处理或后处理。
我们的测量结果(230–374 FPS)更能代表实际应用性能,因为生产系统始终需要预处理和后处理。这些trtexec数字仅反映了硬件性能,并不能反映实际部署场景。
部署建议
适用于桌面/服务器应用程序
- 使用:FP16 TensorRT
- 原因:速度、精度和模型尺寸的最佳平衡
- 预期:RTX 5070 Ti 显卡可达到 300+ FPS
适用于边缘设备(Jetson)
- 使用:INT8 TensorRT
- 原因:模型尺寸最小,精度损失最小
- 预期:性能取决于 Jetson 版本
为了最大程度的兼容性
- 用途:ONNX 运行时
- 原因:跨平台支持
- 权衡:比TensorRT慢约50%。
结 论
本指南演示了如何在 GeForce RTX 5070 Ti 上使用 NVIDIA TensorRT 和 YOLOv8 分割算法实现 374 FPS 的推理速度。主要内容如下:
- TensorRT 优化相比标准 ONNX 运行时可实现 2.2 倍的速度提升。
- FP16精度是生产部署的最佳选择。
- 正确的基准测试方法至关重要——衡量你的应用实际能做到什么。
- 实际推理过程包括预处理和后处理,而不仅仅是GPU计算。
....
1.2、YOLOv8~停车对齐检测
检查对象的对齐方式包括确保它正好位于需要的位置以及正确的位置和方向。对象的对齐和位置可能需要在各个领域中具有高水平的精度。例如,在制造过程中,即使是很小的不对中也会导致缺陷。同样,在机器人技术中,拾取物体等任务需要精确定位。
自动检查对象对齐的一种高级方法是使用计算机视觉。计算机视觉系统可以捕获图像或视频帧,并使用深度学习算法准确检测和分析物体的位置和方向。
在本文中,我们将探讨使用计算机视觉检测对齐的方法,包括其工作原理、传统技术和实际应用。
了解对象对齐
对象对齐可以分为两种主要类型:2D 对齐和 3D 对齐。2D 对齐侧重于将对象正确定位在平面上或二维平面内。这是为了确保对象相对于水平轴和垂直轴的正确方向,而不是从其预期位置倾斜或移动。2D 对齐的常见用途是图像拼接,其中将多个图像组合在一起以创建单个无缝全景图。
另一方面,3D 对齐处理在三维空间中定位对象。这更棘手,因为它还会检查对象是否沿 z 轴正确定向。点云配准等技术在这里发挥作用,并且经常使用迭代最近点 (ICP) 算法。它有助于对齐从不同角度捕获的 3D 模型或点云(3D 空间中数据点的集合)。3D 对齐通常用于机器人技术中,用于精确导航和处理对象。它还用于 3D 重建,以创建物体或场景的详细模型。
传统的比对检测技术
过去,传统的图像分析方法被广泛用于检测物体的对齐情况。这些技术在今天仍然很重要,并且是许多现代计算机视觉技术的构建块。让我们来看看三个关键的传统技术:边缘检测、特征匹配和参考标记。
边缘检测可以帮助您在图像中查找对象的边界或边缘。通过识别这些边缘,您可以确定对象相对于其他对象的位置或对齐方式。当对象具有清晰、锐利的边缘时,此方法效果很好。但是,当条件不完美时,这可能会很棘手。例如,当光线不足时,会出现杂色,或者对象的一部分被隐藏。一种用于边缘检测的流行算法是 Canny Edge Detection。在检测之前应用高斯模糊等技术或使用 Otsu 阈值等自适应方法有助于提高边缘检测的准确性。
特征匹配涉及比较不同图像之间的特定细节或关键点以检查对齐情况。它会在一张图像中寻找独特的特征,并尝试将它们与另一张图像中的相似特征相匹配。但是,当对象没有强烈、独特的特征,或者图像之间的比例、旋转或照明发生很大变化时,这可能具有挑战性。Scale-Invariant Feature Transform (SIFT) 和加速稳健特征 (SURF) 等常用方法通常用于特征匹配,尽管它们在恶劣条件下可能会有局限性。
参考标记是框架中的固定点或特征,用作测量对象对齐方式的锚点。当您需要准确且可重复的测量时,例如在 3D 计量中,这些标记特别有用。通过将这些标记放置在已知位置,您可以准确确定对象在 3D 空间中的位置、方向和缩放。
使用计算机视觉检测对齐的方法
计算机视觉可以使检测和测量物体的对齐变得更加简单。借助先进的算法和机器学习,我们可以准确确定物体在 2D 和 3D 空间中的方向、角度和位置。让我们探讨一下用于检测对齐的三种关键方法:对象方向检测、角度测量和姿态估计。
对象方向检测侧重于识别边缘和角落等关键特征,以了解对象的方向。这里使用的常用技术是主成分分析 (PCA)。PCA 通过简化图像数据和突出显示最重要的特征来提供帮助。它找到数据变化的主要方向(称为特征向量),并使用它们来确定对象的定向方式。例如,PCA 可以分析像素强度在图像中的分布情况,以创建更准确地反映对象真实位置的新轴。
确定物体的方向后,可以使用角度测量。可以计算检测到的方向与参考线之间的角度。在即使是很小的不对中也会导致问题的情况下,它非常方便。
姿势估计是一种更高级的技术,用于确定对象在 3D (3D) 空间中的方向和位置。它通常首先使用深度学习技术,例如卷积神经网络 (CNN),从图像中提取关键特征。然后,这些特征用于计算对象相对于照相机或观察点的 3D 方向和位置。数学模型(如透视 n 点 (PnP) 算法)有助于将图像中的 2D 点连接到相应的 3D 坐标。
除了对象方向检测、角度测量和姿势估计等方法外,您还可以使用对象检测和逻辑检查等更简单的方法来确定对齐方式。例如,您可以在图像或空间内设置预定义区域,并检查检测到的对象是否正确放置在这些区域内。在下一节中,我们将仔细研究其工作原理。
检测对象对齐:具体步骤
在此示例中,我们将演练使用计算机视觉检测对象对齐的过程。我们将要介绍的代码旨在检测和检查对象是否落在指定的多边形区域内。我们将使用这种方法来查看汽车是否正确停放在其位置内,方法是将停车位定义为面,并确保检测到的车辆完全位于这些区域内。
要自己尝试此操作,您需要一个图像来运行推理。我们使用了从 Internet 下载的图像。您可以使用同一图像,也可以使用自己的图像。让我们开始吧!
步骤 #1:安装必要的库并加载模型
首先,确保您已安装必要的 Python 库。我们将使用推理等库进行模型加载,使用 opencv 进行图像处理,并使用监督来处理检测和注释。
首先,安装推理库。
pip install inference接下来,导入必要的库:
import numpy as np
import supervision as sv
import cv2
import inference接下来,我们可以加载一个 YOLOv8 模型:
model = inference.get_model("yolov8x-640")步骤 #2:加载图像并运行推理
加载输入图像并使用 YOLOv8 模型检测其中的对象:
image = cv2.imread("path/to/image/file")
results = model.infer(image)[0]
detections = sv.Detections.from_inference(results)在这里,图像是使用 OpenCV 的 imread 函数加载的。然后,模型处理图像,并将结果转换为监督可用于管理检测的格式。
步骤 #3:为区域定义多边形
在此步骤中,我们定义了几个多边形,每个多边形都由一个坐标列表表示。这些多边形至关重要,因为它们定义了将检查对象对齐的区域。您可以使用 PolygonZone 创建这些多边形,该工具允许您在图像上绘制多边形并检索坐标。在此博客文章中了解有关如何使用它的更多信息。
以下代码片段定义了表示要检查对齐的区域的多边形。
polygons = [
np.array([[67, 416], [141, 416], [141, 273], [67, 278]]),
np.array([[140, 416], [208, 416], [208, 279], [135, 275]]),
...
# Add more polygons as needed
]步骤 #4:创建多边形区域和注释器
定义多边形后,我们现在可以创建区域和相应的注释器。我们创建一个 PolygonZone 对象列表,每个对象都与其中一个多边形相关联。triggering_anchors 参数设置为检查对象的所有四个角,确保它们位于定义的区域内。PolygonZone 类是定义这些区域的有用工具,它让我们可以轻松检查检测到的对象是否在这些区域内对齐。
zones = [
sv.PolygonZone(
polygon=polygon,
triggering_anchors=(sv.Position.TOP_LEFT,
sv.Position.TOP_RIGHT,
sv.Position.BOTTOM_LEFT,
sv.Position.BOTTOM_RIGHT),
)
for polygon in polygons
]接下来,我们创建注释器以直观地标记这些区域和检测到的对象。PolygonZoneAnnotator 和 BoxAnnotator 有助于将视觉元素添加到输出图像中。这些注释器将绘制多边形和边界框,并可以轻松查看对象的位置以及它们是否正确对齐。
zone_annotators = [
sv.PolygonZoneAnnotator(
zone=zone,
color=colors.by_idx(index),
thickness=2,
text_thickness=1,
text_scale=1
)
for index, zone
in enumerate(zones)
]
box_annotators = [
sv.BoxAnnotator(
color=colors.by_idx(index),
thickness=2
)
for index
in range(len(polygons))
]步骤 #5:应用注释并显示结果
最后,我们可以筛选检测结果,使其仅包含定义区域内的检测结果,应用注释并显示结果图像。
for zone, zone_annotator, box_annotator in zip(zones, zone_annotators, box_annotators):
mask = zone.trigger(detections=detections)
detections_filtered = detections[mask]
frame = box_annotator.annotate(scene=image, detections=detections_filtered)
frame = zone_annotator.annotate(scene=frame)
sv.plot_image(frame, (8, 8))这是输出图像。如您所见,标记为“0”的停车位有未正确对齐的车辆,而标记为“1”的停车位有车辆对齐并正确停放其中。

挑战和注意事项
使用计算机视觉检测对象对齐是一个强大的工具,但它也带来了一系列挑战。以下是一些关键挑战:
- 复杂对象的精度较低:具有不寻常形状或复杂设计的对象有时会混淆检测算法并导致对齐错误。纹理、颜色或表面条件的变化也会使算法更难一致地正确识别和对齐对象。
- 处理异常情况:算法可能会遇到困难,处理罕见或不寻常的情况,通常称为“边缘情况”,并且可能需要更多的训练数据来有效处理这些情况。
- 环境因素:光照的变化会产生阴影或高光,从而掩盖重要细节,并使对齐更难准确检测。繁忙或杂乱的背景也会混淆检测算法,而反光或透明表面可能会扭曲对象的外观并使过程复杂化。
- 实时处理:当需要实时进行对齐检测时,例如在装配线上,系统必须处理图像并快速做出决策。实时处理可能需要更昂贵的硬件来支持所需的处理能力。
- 集成挑战:将计算机视觉系统与现有机器和工作流程集成可能很复杂,需要仔细规划以确保一切顺利进行。
....
1.3、YOLOv8~关键点检测的仪表盘读数
整体流程:

2. 基于YOLOV8的表盘指针和刻度数标的目标检测和关键点检测
2.1 指标数据集的制作

我使用labelme进行yolov8数据集的制作。首先使用矩形框选指针的整体结构,然后使用控制点依次点选指标的尾部和头部。值得注意的是控制点的点选顺序应该保持一致。后续需要将labelme格式的标注文件转化成yolo格式。
2.2 刻度数标数据集的制作

2.3 模型训练

3. 基于Paddleocr的刻度OCR识别
3.1 使用Paddleocr的预训练模型
将上一步检测出的刻度数标进行OCR识别,这里我使用 Paddleocr,具体安装参考官方说明

3.2 剔除错误的OCR结果,以及选定最符合的表盘刻度
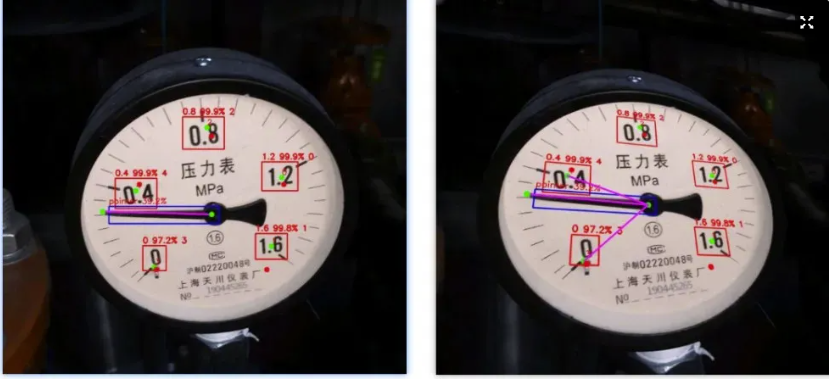
在需要检测的图片中,压力表的种类有很多,有的刻度范围在0-1.6,有的刻度范围在0-1。我们需要明确具体检测的压力表的正确刻度属于是哪一种。下面是我例举的在我的数据集中出现的4种情况。

以上是4种标准的压力表表盘的刻度分布。"1.6": 45 表示该表盘最大的刻度为1.6,极坐标的角度为45(以指针尾部关键点为原点,顺时针建立极坐标系)。可以看到,每种表盘的最大刻度都在图片的右下角45°,每种表盘的最小刻度0,都在图片的左下角45°。
将OCR检测的结果与标准刻度中的字符进行比较,只保留出现在标准刻度中的结果,并累计哪个表盘符合的刻度的数据最多,从而确定该表盘为最符合的表盘。
上图中错误检测出了MC这个框,需要去除。且正确检测出了0、0.8、1.2和1.6等4个刻度,与表盘一最为符合,从而确定该表盘为表盘一。
4. 图片透视变换
以指标尾部关键点为原点建立极坐标系,这里我假设每个仪表盘的最后一个刻度的角度为45°。
1、确定最后一个点的坐标:已知最后一个点在透视变换后的极坐标角度为45°,假设所有刻度点距离圆心距离为R,则最后一个点的坐标可以表示为(45°,R)可以根据该极坐标得出笛卡尔坐标系下的坐标。
2、确定其他三个点的坐标:这里一共有4个间隔平分整个270°量程,所以每个刻度夹角为270/4=67.5°,据此可以依次计算出其他三个点在变换后的坐标。
通过这种方式,可以确定四个刻度点在透视变换后图像中的坐标,并用这些坐标来进行透视变换。
使用opencv进行透视变换,具体使用了cv2.getPerspectiveTransform 函数,scr_point 是原始图片上的4点坐标,dst_point是变换后4点的坐标。

5. 读数计算
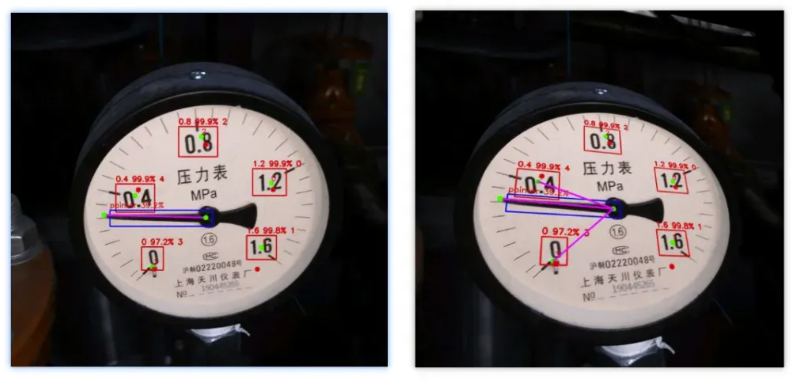

6. 算法优化
6.1 会有无法识别出刻度

如上图所示,只识别出了0.4这个刻度,而按照上面的读数算法需要要求指针位于两个刻度之间,然后根据夹角之间的比例进行计算。所以这种情况下,需要补全0刻度,让指针位于0-0.4之间。这里我默认指定0位于表盘中心右下方45°的位置。
....
1.4、YOLOv8+ Deepsort+Pyqt5车速检测系统
该系统通过YOLOv8进行高效的目标检测与分割,结合DeepSORT算法完成目标的实时跟踪,并利用GPU加速技术提升处理速度。系统支持模块化设计,可导入其他权重文件以适应不同场景需求,同时提供自定义配置选项,如显示标签和保存结果等。

1. 引言
随着城市交通压力的增加,智能交通系统(ITS)成为缓解交通拥堵、提高道路安全的重要手段。车辆检测与测速作为ITS的核心模块之一,对提升交通管理效率具有重要意义。YOLOv8和DeepSORT作为当前目标检测与跟踪领域的领先算法,其结合使用能够显著提升系统的实时性和准确性。本文提出了一种基于YOLOv8、DeepSORT和PyQt5的车速检测系统,旨在为交通管理和智能监控提供高效、可靠的解决方案。
2. 系统架构
2.1 YOLOv8算法介绍
通过单次前向传播即可预测图像中的目标位置和类别。其特点包括:
实时性能:YOLOv8专为实时应用设计,能够在视频流中快速检测目标。
高准确性:利用最新的卷积神经网络架构,在各种环境下保持高准确率。
易于集成:YOLOv8的输出可以直接用于后续的跟踪算法,无需复杂的预处理
2.2 DeepSORT算法介绍
DeepSORT算法的核心在于其对目标的外观特征和运动特征的联合使用,以及对目标匹配问题的优化处理。该算法通过融合目标检测的结果,结合匈牙利算法和卡尔曼滤波等技术,实现对多个目标的持续跟踪。
DeepSORT算法的主要步骤:
目标检测:DeepSORT算法依赖于目标检测器来确定视频中每一帧的目标位置。常用的目标检测器包括YOLO、Faster R-CNN等。检测器的输出通常包括目标的边界框(bounding box)和类别。
特征提取:DeepSORT使用深度学习模型来提取目标的外观特征。这些特征对于目标的再识别(re-identification,简称Re-ID)至关重要,因为即使目标在视频中被临时遮挡或丢失,这些特征也能帮助算法重新识别和关联目标。
匹配和跟踪:DeepSORT算法中的匹配过程涉及到计算检测框和预测框之间的相似度,并使用匈牙利算法来找到最优匹配。这个过程还包括卡尔曼滤波器的使用,它根据目标的历史运动信息来预测其在下一帧中的位置。
卡尔曼滤波:用于预测目标在下一帧中的位置。
匈牙利算法:用于计算检测框和预测框之间的最优匹配。
级联匹配:DeepSORT中的级联匹配是一种特殊的机制,它首先尝试将检测结果与高置信度的轨迹进行匹配,然后再与低置信度的轨迹进行匹配。这有助于提高匹配的准确性,尤其是在目标被遮挡或短暂消失时。
轨迹管理:DeepSORT维护每个目标的轨迹,并对新检测到的目标初始化新的轨迹。它还设置了确认状态(confirmed)和未确认状态(unconfirmed),以处理遮挡和临时丢失的情况。
DeepSORT算法流程:

通过深度学习提取特征并结合卡尔曼滤波预测目标轨迹。其优势在于:
对遮挡和遮挡恢复能力强。
准确性高:在MOT挑战赛中表现优异。
支持多目标跟踪:能够同时跟踪多个目标并计算其速度和轨迹。
谷歌原始deepsort 源码下载地址:
https://drive.google.com/drive/folders/1kna8eWGrSfzaR6DtNJ8_GchGgPMv3VC8
2.3 PyQt5界面设计
PyQt5是一种基于Python的跨平台GUI开发框架,用于构建用户友好的可视化界面。本系统通过PyQt5实现了以下功能:
显示实时检测结果。
提供自定义配置选项,如显示标签、保存结果等。
支持模块化导入其他权重文件进行识别和跟踪。
2.4 车速计算方法
车速计算是本系统的核心功能之一,通过以下步骤实现:
检测帧间距离:利用YOLOv8检测到的目标位置计算两帧之间的距离。
转换为实际距离:结合摄像头焦距和视场角将像素距离转换为实际距离。
计算速度:根据时间间隔计算目标速度。

3. 创新点
1. 高效GPU加速机制
YOLOv8和DeepSORT均支持GPU加速,显著提升了系统的实时性。在Jetson Nano设备上,YOLOv8的推理速度可达140FPS。
2. 模块化设计与扩展性
系统采用模块化设计,支持导入其他权重文件以适应不同场景需求。此外,用户可通过PyQt5界面自定义配置选项。
3. 实时性与准确性平衡
YOLOv8和DeepSORT的结合实现了高精度与实时性的平衡。YOLOv8确保了快速检测,而DeepSORT则保证了跟踪的准确性。
4. 结论与展望
本文提出的基于YOLOv8、DeepSORT和PyQt5的车速检测系统,在交通管理和智能监控领域展现了显著优势。其高效的检测与跟踪能力、友好的用户界面以及强大的扩展性,使其成为智慧城市建设和智能交通发展的重要工具。
未来研究方向包括:
提高模型泛化能力 :通过迁移学习进一步优化模型,使其能够适应更多样化的场景。
扩展应用场景 :将系统应用于无人机监控、工业自动化等领域,探索更多可能性。
引入边缘计算 :通过边缘计算设备部署系统,降低延迟并提高实时性。
融合多传感器数据 :结合激光雷达、毫米波雷达等传感器数据,进一步提升系统的鲁棒性和准确性。
....
2、Yolo11
2.1、自定义数据集~车辆事故检测
在智能交通系统领域,实时检测车辆事故的能力变得越来越重要。该项目利用先进的计算机视觉技术,采用最先进的对象检测模型 YOLOv11 来准确识别和分类车辆事故。主要目标是通过向紧急服务提供及时警报并实现更快的响应时间来提高道路安全。
YoloV11 是 ultralytics 的 Yolo 最新版本,与以前的版本相比,有几个优点和最大的功能,有关更多信息,请查看官方 ultralytics yoloV11 文章
https://docs.ultralytics.com/models/yolo11/?source=post_page-----a793d51cc4ba--------------------------------YOLOv11来了:将重新定义AI的可能性
本文项目涉及几个步骤,这是一个简单的原型级项目,步骤是
1. 数据准备 :数据选择和预处理
2. 模型训练 :使用 Yolov11 使用自定义数据训练模型
3. 模型评估 :在看不见的数据上评估模型的性能
4. 模型推理 :使用实际模型的 onnx 版本对看不见的数据进行推理
数据准备
数据准备和预处理是计算机视觉模型开发的关键步骤。这些步骤可确保模型能够有效地学习并很好地泛化到新数据。以下是它们重要性的关键原因:
1. 数据质量改进
2. 减少过拟合
3. 正确的标签处理
在对象检测或分割等任务中,确保标签(边界框、掩码或关键点)与预处理后的图像匹配对于准确训练至关重要。未对齐的标签会显著降低模型性能。
改进的性能指标
正确预处理的数据会在准确性、精度和召回率方面获得更好的性能。准备充分的数据使模型能够专注于有意义的特征并改进其预测。
总之,数据准备和预处理通过提高数据质量、降低计算复杂性、防止过度拟合和增强模型泛化,直接影响计算机视觉模型的成功。
在这个项目中,我从两个不同的来源获取了数据集
找到我带的 GITHUB 的源代码和数据集
https://github.com/varunpn7405/Vehicle_Accident_detection数据预处理
作为第一步,我们需要 删除空注释和相应的帧 ,我在整个模型开发过程中提供帮助
- 避免误导模型:对象检测模型经过训练,可以预测图像中对象的存在和位置。如果包含没有注释的图像(即没有任何标记对象的图像),则模型可能会错误地了解到许多图像不包含对象,从而降低其有效检测对象的能力。
- 提高训练效率:在没有注释的图像上进行训练会浪费计算资源,因为模型在处理图像时没有学习任何关于对象位置的有用信息。删除这些图像有助于将训练重点放在相关的信息数据上。
- 减少偏差:包含大量空白图像可能会使模型偏向于预测图像通常不包含对象,从而导致更高的假阴性率(即无法检测到存在的对象)。
- 防止过度拟合:对过多的空图像进行训练可能会导致模型对预测未来图像的“无对象”过于自信,这可能会损害其对存在对象的真实场景的泛化。
- 确保正确的损失计算:目标检测模型通常使用依赖于目标存在的损失(如分类和定位损失)。空图像可能会影响这些损失的计算方式,尤其是当模型期望每个图像至少有一个对象时,这可能会导致训练期间的不稳定。
import os,shutil
# Function to check if a file is empty
def is_empty_file(file_path):
return os.path.exists(file_path) and os.stat(file_path).st_size == 0
image_extensions = ['.jpg', '.jpeg', '.png']
path = os.getcwd()
inputPar = os.path.join(path, r'dataset')
outputPar = os.path.join(path, r'filtered')
if not os.path.exists(outputPar):
os.makedirs(outputPar)
folders = os.listdir(inputPar)
for folder in folders:
if folder in ["test","train","valid"]:
inputChild = os.path.join(inputPar, folder,"labels")
outputChild1 = os.path.join(outputPar, folder,"labels")
if not os.path.exists(outputChild1):
os.makedirs(outputChild1)
outputChild2 = os.path.join(outputPar, folder,"images")
if not os.path.exists(outputChild2):
os.makedirs(outputChild2)
files = os.listdir(inputChild)
for file in files:
annotation_path = os.path.join(inputChild, file)
# Check if the annotation file is empty
if not is_empty_file(annotation_path):
shutil.copy(annotation_path,os.path.join(outputChild1,file))
# Try to find and remove the corresponding image file
image_name = os.path.splitext(file)[0]
for ext in image_extensions:
image_path = os.path.join(inputPar,folder,"images", image_name + ext)
if os.path.exists(image_path):
shutil.copy(image_path,os.path.join(outputChild2,image_name + ext))然后下一个任务是我们的第二个数据集有 3 个类 Accident 、Car 和 Fire,我们只需要 Accident 实例,因此删除 Car 和 Fire 的注释,并删除图像和注释 yolo 文件(如果它仅包含属于 Car 和 Fire 的注释),则删除该文件
import os,shutil
image_extensions = ['.jpg', '.jpeg', '.png']
path = os.getcwd()
inputPar = os.path.join(path, r'accident detection.v10i.yolov11')
outputPar = os.path.join(path, r'accident detection.v10i.yolov11(Filtered))')
if not os.path.exists(outputPar):
os.makedirs(outputPar)
folders = os.listdir(inputPar)
clsfile = os.path.join(path, 'classes.txt')
with open(clsfile) as tf:
clsnames = [cl.strip() for cl in tf.readlines()]
for folder in folders:
if folder in ["test","train","valid"]:
inputChild = os.path.join(inputPar, folder,"labels")
outputChild1 = os.path.join(outputPar, folder,"labels")
if not os.path.exists(outputChild1):
os.makedirs(outputChild1)
outputChild2 = os.path.join(outputPar, folder,"images")
if not os.path.exists(outputChild2):
os.makedirs(outputChild2)
files = os.listdir(inputChild)
for file in files:
fileName, ext = os.path.splitext(file)
finput = os.path.join(inputChild, file)
with open(finput) as tf:
Yolodata = tf.readlines()
# for obj in Yolodata:
if not all(int(obj.split(' ')[0])==2 or int(obj.split(' ')[0])==1 for obj in Yolodata):
print(file)
new_yolo_data=[]
for obj in Yolodata:
if not (int(obj.split(' ')[0])==2 or int(obj.split(' ')[0])==1) :
new_yolo_data.append(obj)
with open(os.path.join(outputChild1,file),"w") as tf:
tf.writelines(new_yolo_data)
image_name = os.path.splitext(file)[0]
for ext in image_extensions:
image_path = os.path.join(inputPar,folder,"images", image_name + ext)
if os.path.exists(image_path):
shutil.copy(image_path,os.path.join(outputChild2,image_name + ext))
break过滤所有这些后,然后将两个数据集组合在一起,以获得用于训练和验证的合适数据集,该数据集应该是
以可视化的方式监控和验证整个数据集的标注质量,并编写相同的脚本
import os
from PIL import Image,ImageDraw,ImageFont
font = ImageFont.truetype("arial.ttf", 15)
path = os.getcwd()
inputPar = os.path.join(path, r'Dataset')
outputPar = os.path.join(path, r'Visualisation')
ifnot os.path.exists(outputPar):
os.makedirs(outputPar)
folders = os.listdir(inputPar)
cls_clr = {"Accident":"#eb0523"}
clsfile = os.path.join(path, 'classes.txt')
with open(clsfile) as tf:
clsnames = [cl.strip() for cl in tf.readlines()]
for folder in folders:
if folder in ["test","train","valid"]:
inputChild = os.path.join(inputPar, folder,"labels")
outputChild = os.path.join(outputPar, folder)
ifnot os.path.exists(outputChild):
os.makedirs(outputChild)
files = os.listdir(inputChild)
for file in files:
fileName, ext = os.path.splitext(file)
finput = os.path.join(inputChild, file)
with open(finput) as tf:
Yolodata = tf.readlines()
imgpath1 = os.path.join(inputPar,folder,"images", fileName + '.jpg')
# imgpath2 = os.path.join(inputPar,folder,"images", fileName + '.png')
if os.path.exists(imgpath1):
imgpath=imgpath1
# elif os.path.exists(imgpath2):
# imgpath=imgpath2
if os.path.exists(imgpath):
print("plotting >>",fileName + '.jpg')
img = Image.open(imgpath)
draw = ImageDraw.Draw(img)
width, height = img.size
for obj in Yolodata:
clsName = clsnames[int(obj.split(' ')[0])]
xnew = float(obj.split(' ')[1])
ynew = float(obj.split(' ')[2])
wnew = float(obj.split(' ')[3])
hnew = float(obj.split(' ')[4])
label=f"{clsName}"
# box size
dw = 1 / width
dh = 1 / height
# coordinates
xmax = int(((2 * xnew) + wnew) / (2 * dw))
xmin = int(((2 * xnew) - wnew) / (2 * dw))
ymax = int(((2 * ynew) + hnew) / (2 * dh))
ymin = int(((2 * ynew) - hnew) / (2 * dh))
clr = cls_clr[clsName]
tw, th = font.getbbox(label)[2:]
# draw bbox and classname::
draw.rectangle([(xmin,ymin),(xmax,ymax)],outline =clr,width=2)
txtbox = [(xmin,ymin-th),(xmin+tw,ymin)]
draw.rectangle(txtbox, fill=clr)
draw.text((xmin,ymin-th),label,fill='white',fnotallow=font)
fout = os.path.join(outputChild, imgpath.split("\\")[-1])
img.save(fout)
else:
print(f'{imgpath} >> img not found:'相同的 Project Config File 为
[
{
"name": "Accident",
"id": 3505802,
"color": "#f80b2b",
"type": "any",
"attributes": []
}
]我们不能直接上传像 coco 这样的注释,要在 cvat 上上传 Yolo,有一个特定的文件夹结构需要保留
然后重新格式化数据集以获得更好的训练,但这是可选的,为此我们可以使用 python 自动化脚本
import os
import shutil
from concurrent.futures import ThreadPoolExecutor
import time
startTime=time.time()
def copy_files(src_dir, dst_dir):
"""Copy files from src_dir to dst_dir."""
os.makedirs(dst_dir, exist_ok=True)
for file in os.listdir(src_dir):
shutil.copy(os.path.join(src_dir, file), os.path.join(dst_dir, file))
def process_folder(inputPar, outPar, folder):
"""Process 'images' and 'labels' subfolders within the given folder."""
if folder in ["train", "valid", "test"]:
inputChild = os.path.join(inputPar, folder)
for subfldr in ["images", "labels"]:
inputSubChild = os.path.join(inputChild, subfldr)
outChild = os.path.join(outPar, subfldr, folder)
if os.path.exists(inputSubChild):
copy_files(inputSubChild, outChild)
def main():
cPath = os.getcwd()
inputPar = r"data_set"
outPar = os.path.join(cPath, "Dataset")
folders = ["train", "valid", "test"]
with ThreadPoolExecutor() as executor:
executor.map(lambda folder: process_folder(inputPar, outPar, folder), folders)
if __name__ == "__main__":
main()
endTime=time.time()
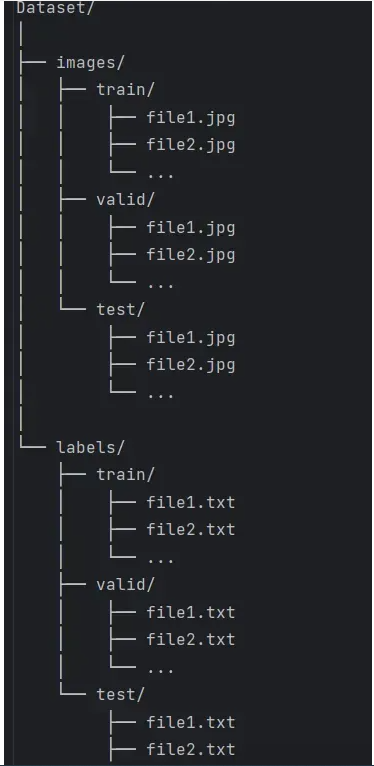
print("process Completed in !!",endTime-startTime)那么最终的数据集结构应该是这样的
训练
创建指定数据集路径和所有
import yaml
# Define the data configuration
data_config = {
'train': '/content/data_v2/images/train', # Replace with your train directory path
'val': '/content/data_v2/images/valid', # Replace with your train directory path
'nc': 1, # number of classes
'names': ['Accident']
}
# Write the configuration to a YAML file
with open('data.yaml', 'w') as file:
yaml.dump(data_config, file)安装 Ultralytics
pip install ultralytics训练模型
from ultralytics import YOLO
# Load a model
model = YOLO("yolo11n.pt")
# Train the model
train_results = model.train(
data="data.yaml", # path to dataset YAML
epochs=100, # number of training epochs do adjust as you need
imgsz=640, # training image size
)那么下一个关键步骤是将开发的模型转换为 ONNX(Open Neural Network Exchange),它有几个优点:
1. 跨平台兼容性
ONNX 是一种开放格式,受到 PyTorch、TensorFlow 和 Keras 等各种深度学习框架的支持。将 YOLO 模型转换为 ONNX 后,您可以跨多个平台(云、移动设备、边缘设备)部署它,而无需坚持使用单个深度学习框架。
2. 改进的推理性能
可以使用 ONNX Runtime 或 TensorRT 等运行时对 ONNX 模型进行优化以获得更好的性能,这大大加快了推理速度,尤其是在 NVIDIA GPU 和边缘设备等硬件上。这可以在对象检测任务中更快地进行实时预测。
3. 更轻松地在不同硬件上部署
转换为 ONNX 的 YOLO 模型可以使用兼容 ONNX 的运行时部署在各种硬件架构(CPU、GPU、FPGA 和自定义 AI 加速器)上。这种灵活性对于在不同环境(从数据中心到嵌入式系统)中部署模型至关重要。
4. 与其他 AI 工具的互操作性
ONNX 模型可以与一系列工具集成,以进行优化、量化和基准测试。这有助于减小模型大小、提高执行效率,并实现与适用于 Intel 硬件的 OpenVINO 等工具的兼容性。
5. 可扩展性
ONNX 格式允许批处理和并行化,这在跨多个设备或服务器扩展推理服务时非常有用。
6. 边缘和移动部署
通过将 YOLO 模型转换为 ONNX,您可以利用 TensorRT 和 ONNX Runtime for mobile 等框架,以优化性能在边缘设备、手机和 IoT 系统上高效部署模型。
7. 更轻松的模型优化
ONNX 提供了各种工具来简化模型修剪、量化和其他优化,以降低模型的计算成本,这对于在资源受限的设备上部署至关重要。
8. 标准化格式
使用 ONNX 有助于统一不同开发阶段和框架之间的模型生命周期,通过保持一致的开放标准格式来简化模型转换、验证和版本控制。
model.export(format="onnx") # creates 'best.onnx'测试图像上的推理:
import cv2
from ultralytics import YOLO
image_path=r"Accident detection model.v2i.yolov11(Empty Filtered)\train\images\Accidents-online-video-cutter_com-_mp4-41_jpg.rf.549dce3991b2ae74ae65274cc32d8eff.jpg" # Replace with your test image path
onnx_model = YOLO("best.onnx")
class_names=onnx_model.names
image = cv2.imread(image_path)
# Run inference
results = onnx_model(image)
# Extract predictions
for result in results:
boxes = result.boxes # get bounding boxes
for box in boxes:
x1, y1, x2, y2 = map(int, box.xyxy[0].tolist()) # Bounding box coordinates
conf = box.conf.item() # Confidence score
class_id = int(box.cls.item()) # Class ID
# Prepare the label text
label = f"{class_names[class_id]}: {conf:.2f}"
# Draw the bounding box (blue color, thickness of 2)
cv2.rectangle(image, (x1, y1), (x2, y2), (255, 0, 0), 2)
# Draw the label above the bounding box
font = cv2.FONT_HERSHEY_SIMPLEX
label_size, _ = cv2.getTextSize(label, font, 0.5, 1)
label_ymin = max(y1, label_size[1] + 10)
cv2.rectangle(image, (x1, label_ymin - label_size[1] - 10),
(x1 + label_size[0], label_ymin + 4), (255, 0, 0), -1) # Draw label background
cv2.putText(image, label, (x1, label_ymin), font, 0.5, (255, 255, 255), 1) # Put label text
# Save the image
output_path = "output_image.jpg"
cv2.imwrite(output_path, image)
print(f"Saved inference result to {output_path}")
现在我们可以绘制开发模型的准确率指标
{
"image_name_1": {
"bboxes": [
{"bbox": [xmin1, ymin1, xmax1, ymax1], "class": "cls1"},
{"bbox": [xmin2, ymin2, xmax2, ymax2], "class": "cls2"}
]
},
"image_name_2": {
"bboxes": [
{"bbox": [xmin3, ymin3, xmax3, ymax3], "class": "cls1"},
{"bbox": [xmin4, ymin4, xmax4, ymax4], "class": "cls2"},
{"bbox": [xmin5, ymin5, xmax5, ymax5], "class": "cls3"}
]
}
}为预测和真实值制作如上所示的 json,以计算性能指标,例如 Precision、Recall、F1 Score 和 Classification 报告,对于 Ground Truth
import os,json
from PIL import Image
img_data_dict={}
path = os.getcwd()
inputPar = os.path.join(path, r'Dataset')
folders = os.listdir(inputPar)
clsfile = os.path.join(path, 'classes.txt')
with open(clsfile) as tf:
clsnames = [cl.strip() for cl in tf.readlines()]
for folder in folders:
if folder in ["test"]:
inputChild = os.path.join(inputPar, folder,"images")
files = os.listdir(inputChild)
for file in files:
imgpath=os.path.join(inputChild,file)
img_data_dict[file]=[]
fileName, ext = os.path.splitext(file)
finput = os.path.join(inputPar,folder,"labels", fileName + '.txt')
with open(finput) as tf:
Yolodata = tf.readlines()
if os.path.exists(imgpath):
print("plotting >>",fileName + '.jpg')
img = Image.open(imgpath)
width, height = img.size
for obj in Yolodata:
clsName = clsnames[int(obj.split(' ')[0])]
xnew = float(obj.split(' ')[1])
ynew = float(obj.split(' ')[2])
wnew = float(obj.split(' ')[3])
hnew = float(obj.split(' ')[4])
# box size
dw = 1 / width
dh = 1 / height
# coordinates
xmax = int(((2 * xnew) + wnew) / (2 * dw))
xmin = int(((2 * xnew) - wnew) / (2 * dw))
ymax = int(((2 * ynew) + hnew) / (2 * dh))
ymin = int(((2 * ynew) - hnew) / (2 * dh))
bbx_dict={"Bbox":[xmin,ymin,xmax,ymax],"class":f"{clsName}"}
if file in img_data_dict:
img_data_dict[file].append(bbx_dict)
else:
print(f'{imgpath} >> img not found:')
with open("img_gt.json","w") as f:
json.dump(img_data_dict,f,indent=4)用于预测
import cv2,json,os
from ultralytics import YOLO
onnx_model = YOLO("best.onnx")
class_names=onnx_model.names
img_data_dict={}
path = os.getcwd()
inputPar = os.path.join(path, r'Dataset')
folders = os.listdir(inputPar)
for folder in folders:
if folder in ["test"]:
inputChild = os.path.join(inputPar, folder,"images")
files = os.listdir(inputChild)
for file in files:
img_data_dict[file]=[]
imgpath=os.path.join(inputChild,file)
image = cv2.imread(imgpath)
# Run inference
results = onnx_model(image)
# Extract predictions
for result in results:
boxes = result.boxes # get bounding boxes
for box in boxes:
x1, y1, x2, y2 = map(int, box.xyxy[0].tolist()) # Bounding box coordinates
conf = box.conf.item() # Confidence score
class_id = int(box.cls.item()) # Class ID
clsName=class_names[class_id]
bbx_dict={"Bbox":[x1, y1, x2, y2],"class":f"{clsName}"}
if file in img_data_dict:
img_data_dict[file].append(bbx_dict)
with open("img_pred.json","w") as f:
json.dump(img_data_dict,f,indent=4)但这里的问题是模型预测在任何时候都不准确,它可能导致在创建分类报告时产生问题(ytrue 和 ypred 的大小变化),因此平衡它们是非常必要的为此,如果需要,我们可以使用 python 脚本来更新两个 jsons
import json
def load_data(ground_truth_file, predictions_file):
withopen(ground_truth_file) as f:
ground_truth = json.load(f)
withopen(predictions_file) as f:
predictions = json.load(f)
return ground_truth, predictions
# Load data
ground_truth_file = 'img_gt.json'
predictions_file = 'img_pred.json'
ground_truth, predictions = load_data(ground_truth_file, predictions_file)
# Make a copy of the data
ground_truth_upd, predictions_upd = ground_truth.copy(), predictions.copy()
# Update the lists so they have the same length
for gt_key, pred_key in zip(ground_truth, predictions):
# Get the annotations for the current key
gt_annotations = ground_truth[gt_key]
pred_annotations = predictions[pred_key]
iflen(gt_annotations) != len(pred_annotations):
gt_len = len(gt_annotations)
pred_len = len(pred_annotations)
# Add padding to the smaller list
if gt_len < pred_len:
# Pad ground truth with empty boxes and None class
for _ inrange(pred_len - gt_len):
ground_truth_upd[gt_key].append({"Bbox": [0, 0, 0, 0], "class": None})
elif pred_len < gt_len:
# Pad predictions with empty boxes and None class
for _ inrange(gt_len - pred_len):
predictions_upd[pred_key].append({"Bbox": [0, 0, 0, 0], "class": None})
# Save updated data
withopen("img_gt_upd.json", "w") as f:
json.dump(ground_truth_upd, f, indent=4)
withopen("img_pred_upd.json", "w") as f:
json.dump(predictions_upd, f, indent=4)评估性能指标
import json
import numpy as np
import matplotlib.pyplot as plt
from sklearn.metrics import classification_report
defload_data(ground_truth_file, predictions_file):
with open(ground_truth_file) as f:
ground_truth = json.load(f)
with open(predictions_file) as f:
predictions = json.load(f)
return ground_truth, predictions
defiou(box1, box2):
# Calculate the intersection coordinates
xi1 = max(box1[0], box2[0])
yi1 = max(box1[1], box2[1])
xi2 = min(box1[2], box2[2])
yi2 = min(box1[3], box2[3])
# Calculate the area of intersection
intersection_area = max(0, xi2 - xi1) * max(0, yi2 - yi1)
# Calculate the area of both boxes
box1_area = (box1[2] - box1[0]) * (box1[3] - box1[1])
box2_area = (box2[2] - box2[0]) * (box2[3] - box2[1])
# Calculate the area of union
union_area = box1_area + box2_area - intersection_area
return intersection_area / union_area if union_area > 0else0
defcalculate_metrics(ground_truth, predictions, iou_threshold=0.5):
tp = 0# True Positives
fp = 0# False Positives
fn = 0# False Negatives
# For classification report
y_true = [] # Ground truth classes
y_pred = [] # Predicted classes
for image in ground_truth:
gt_boxes = ground_truth[image]
pred_boxes = predictions[image]
matched_gt = [False] * len(gt_boxes) # Track which ground truths have been matched
for pred in pred_boxes:
pred_box = pred['Bbox']
pred_class = pred['class']
# Append predicted class for report
best_iou = 0
best_gt_idx = -1
for idx, gt in enumerate(gt_boxes):
gt_box = gt['Bbox']
gt_class = gt['class']
# Only consider ground truths that match the predicted class
if gt_class == pred_class andnot matched_gt[idx]:
current_iou = iou(pred_box, gt_box)
if current_iou > best_iou:
best_iou = current_iou
best_gt_idx = idx
# Check if the best IoU exceeds the threshold
if best_iou >= iou_threshold and best_gt_idx != -1:
tp += 1# Count as true positive
matched_gt[best_gt_idx] = True# Mark this ground truth as matched
else:
fp += 1# Count as false positive
fn += matched_gt.count(False) # Count unmatched ground truths as false negatives
# Append ground truth classes for the report
y_true.extend(gt['class'] for gt in gt_boxes)
y_pred.extend(pred['class'] for pred in pred_boxes)
y_true = [label if label isnotNoneelse-1for label in y_true]
y_pred = [label if label isnotNoneelse-1for label in y_pred]
# Calculate precision, recall, F1 score
precision = tp / (tp + fp) if (tp + fp) > 0else0
recall = tp / (tp + fn) if (tp + fn) > 0else0
f1_score = 2 * (precision * recall) / (precision + recall) if (precision + recall) > 0else0
return tp, fp, fn, precision, recall, f1_score, y_true, y_pred
defplot_metrics(precision, recall, f1_score):
metrics = [precision, recall, f1_score]
labels = ['Precision', 'Recall', 'F1 Score']
plt.figure(figsize=(8, 5))
plt.bar(labels, metrics, color=['blue', 'orange', 'green'])
plt.ylim(0, 1)
plt.ylabel('Score')
plt.title('Performance Metrics')
plt.grid(axis='y')
for i, v in enumerate(metrics):
plt.text(i, v + 0.02, f"{v:.2f}", ha='center', va='bottom')
plt.show()
defmain(ground_truth_file, predictions_file):
ground_truth, predictions = load_data(ground_truth_file, predictions_file)
tp, fp, fn, precision, recall, f1_score, y_true, y_pred = calculate_metrics(ground_truth, predictions)
print(f"True Positives: {tp}")
print(f"False Positives: {fp}")
print(f"False Negatives: {fn}")
print(f"Precision: {precision:.2f}")
print(f"Recall: {recall:.2f}")
print(f"F1 Score: {f1_score:.2f}")
# Generate classification report
print("\nClassification Report:")
print(f"Length of y_true: {len(y_true)}")
print(f"Length of y_pred: {len(y_pred)}")
print(classification_report(y_true, y_pred))
# Plot metrics
plot_metrics(precision, recall, f1_score)
# Example usage
ground_truth_file = 'img_gt_upd.json'
predictions_file = 'img_pred_upd.json'
main(ground_truth_file, predictions_file)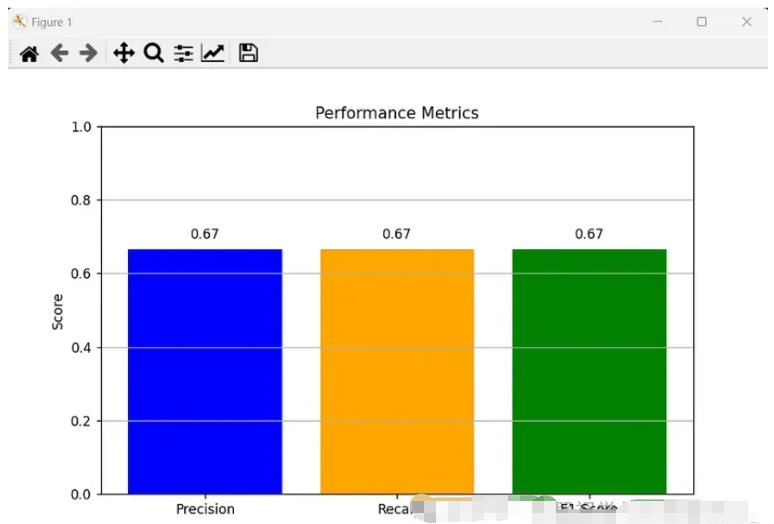
2.2、搭建YOLO11的Web端应用
Streamlit 简介
Streamlit是一个开源的Python框架,旨在帮助开发人员快速、轻松地构建交互式Web应用程序。以下是对Streamlit的基本特点:
- 无代码界面:Streamlit允许开发人员使用简单的Python代码创建复杂的Web应用程序,无需编写HTML、CSS或JavaScript。
- 实时交互:Streamlit应用程序能够响应用户的输入并立即更新,提供无缝的用户体验。
- 易于部署:使用一个简单的命令,即可将Streamlit应用程序部署到Heroku、AWS等云平台。
- 社区支持:Streamlit拥有一个活跃而充满活力的社区,提供全面的文档、教程和示例,以及论坛和讨论组,方便用户交流和学习。
YOLO11 简介
YOLO11请参考公众号前面的文章即可,下面是链接:
YOLOv11来了:将重新定义AI的可能性
实战 | YOLO11自定义数据集训练实现缺陷检测 (标注+训练+预测 保姆级教程)

搭建YOLO11 Web应用
第一步:安装需要的库。
安装streamlit,指令:
pip install streamlit测试安装是否成功:
streamlit hello
安装ultralytics,指令:
pip install ultralytics下载YOLO11预训练模型:
https://github.com/ultralytics/ultralytics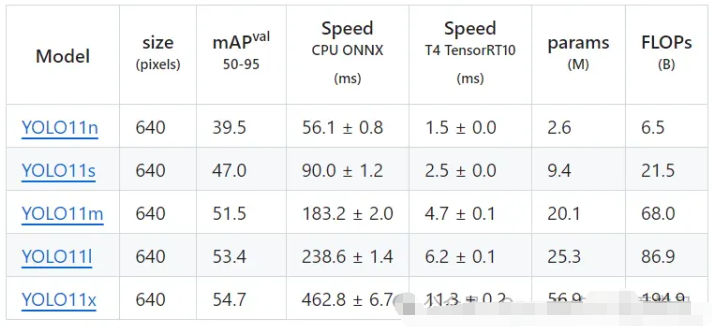
第二步:编写代码。
YOLO11目标检测代码:
from ultralytics import YOLO
import streamlit as st
import numpy as np
import cv2
from PIL import Image, ImageDraw, ImageFont
model = YOLO("yolo11s.pt")
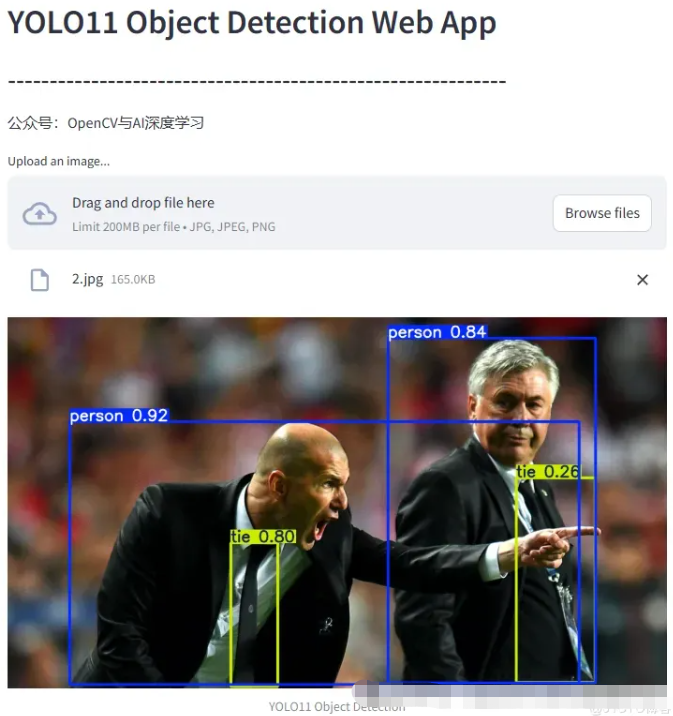
st.header('YOLO11 Object Detection Web App')
st.subheader('-'*60)
st.write('公众号:OpenCV与AI深度学习')
uploaded_file = st.file_uploader("Upload an image...", type=["jpg", "jpeg", "png"])
if uploaded_file isnotNone:
image = Image.open(uploaded_file)
results = model(image)
reulst_image = results[0].plot()
st.image(reulst_image, captinotallow="YOLO11 Object Detection", channels="BGR")YOLO11实例分割代码:
from ultralytics import YOLO
import streamlit as st
import numpy as np
import cv2
from PIL import Image, ImageDraw, ImageFont
model = YOLO("yolo11s-seg.pt")
st.header('YOLO11 Instance Segmentation Web App')
st.subheader('-'*60)
st.write('公众号:OpenCV与AI深度学习')
uploaded_file = st.file_uploader("Upload an image...", type=["jpg", "jpeg", "png"])
if uploaded_file isnotNone:
image = Image.open(uploaded_file)
results = model(image)
reulst_image = results[0].plot()
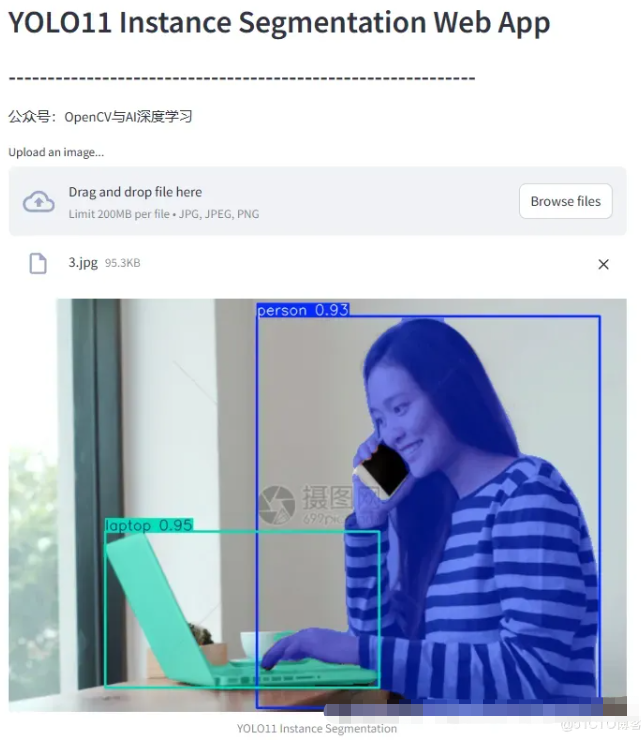
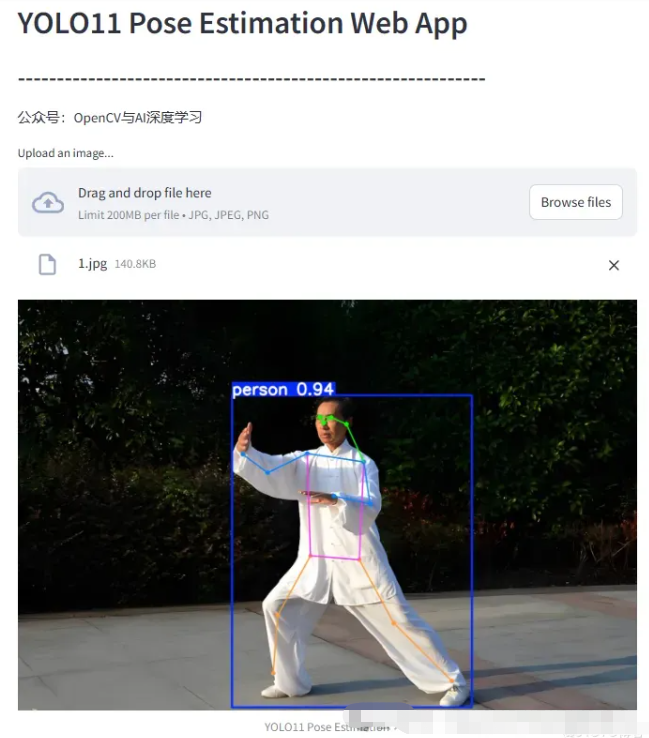
st.image(reulst_image, captinotallow="YOLO11 Instance Segmentation", channels="BGR")YOLO11姿态估计代码:
from ultralytics import YOLO
import streamlit as st
import numpy as np
import cv2
from PIL import Image, ImageDraw, ImageFont
model = YOLO("yolo11n-pose.pt")
st.header('YOLO11 Pose Estimation Web App')
st.subheader('-'*60)
st.write('公众号:OpenCV与AI深度学习')
uploaded_file = st.file_uploader("Upload an image...", type=["jpg", "jpeg", "png"])
if uploaded_file isnotNone:
image = Image.open(uploaded_file)
results = model(image)
reulst_image = results[0].plot()
st.image(reulst_image, captinotallow="YOLO11 Pose Estimation", channels="BGR")第三步:运行测试。
运行测试指令,cmd输入:
streamlitrunxxx.py
打开网页,上传图片测试:
目标检测:
实例分割:
姿态估计:
大家也可以尝试YOLO11图像分类或OBB检测任务,如果想搭建一个界面和功能更丰富的应用可以参考Streamlit开发手册,下面是网站:
http://cw.hubwiz.com/card/c/streamlit-manual/
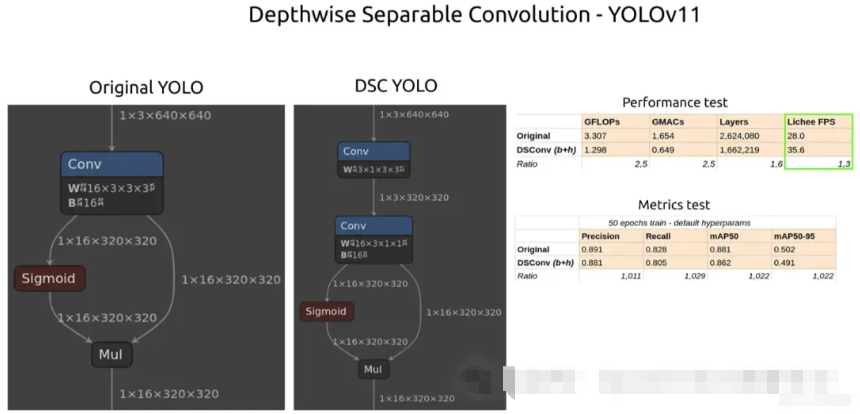
2.3、将 YOLOv11 的实时边缘 AI 速度提高 30%
1. 什么是深度可分离卷积(DSC)?
深度可分离卷积 (DSC) 是标准卷积的有效替代方案,可在保持有竞争力的精度的同时降低计算成本。DSC 不是同时在所有输入通道上应用 3D 卷积核,而是将作分为两个步骤:
- 深度卷积
- 逐点卷积 (1×1 conv)
与标准卷积相比,这种因式分解显着降低了乘法累加 (MAC) 运算的数量。
- 在 NPU(神经处理单元)上,这种减少直接转化为更高的吞吐量和更低的延迟,因为 NPU 专为高度并行和轻量级作而设计。
- 在 GPU/CPU
DSC 用于 MobileNet、FastDepth 等轻量级模型,在本文中,我们将为 YOLO 实现它。
2. 计算节省:Conv 与 DSConv
让我们计算标准卷积与深度可分离卷积在输入张量为 640 × 640 × 3 上,核大小为 3 × 3、步幅 1 和 32 个输出通道的运算次数。
标准卷积
- 输入:640 × 640 × 3
- 内核:3 × 3 × 3 × 32
- 每个输出位置的 MAC:3 × 3 × 3 × 32 = 864
- 输出尺寸:640 × 640 × 32 ≈ 13M positions
- MAC 总数 = 864 × 13,107,200 ≈ 11.3B operations
深度可分离卷积
深度步骤:
- 每个输入通道一个 3 × 3 内核(总共 3 个)
- 每个输出位置的 MAC:3 × 3 × 3 = 27
- 总计 = 27 × 13,107,200 ≈ 354M operations
逐点步骤:
- 1 × 1 × 3 × 32 个过滤器
- 每个输出位置的 MAC:96
- 总计 = 96 × 13,107,200 ≈ 1.26B operations
- 合并总 DSC = 354M + 1.26B = 1.61B operations
➡️ 减少:11.3B → 1.61B(~7× 计算次数减少)
这就是DSC对边缘NPU如此有吸引力的原因。
3. 在YOLOv11中实现DSC
源代码 — YOLO 代码库的模型配置和补丁可以在这里找到。
https://github.com/ret7020/YoloTuning要在YOLOv11中使用DSC,我们需要调整两部分:
- 模型架构:用深度可分离卷积替换一些标准卷积层(我们将替换主干网和头部中的 Convs 和 C3k2 块)。
- 代码更改:
模型架构更改(文件:configs/ds_cfg_backbone_and_head.yaml):
# Ultralytics 🚀 AGPL-3.0 License - https://ultralytics.com/license
# Ultralytics YOLO11 object detection model with P3/8 - P5/32 outputs
# Model docs: https://docs.ultralytics.com/models/yolo11
# Task docs: https://docs.ultralytics.com/tasks/detect
# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolo11n.yaml' will call yolo11.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.50, 0.25, 1024] # summary: 181 layers, 2624080 parameters, 2624064 gradients, 6.6 GFLOPs
s: [0.50, 0.50, 1024] # summary: 181 layers, 9458752 parameters, 9458736 gradients, 21.7 GFLOPs
m: [0.50, 1.00, 512] # summary: 231 layers, 20114688 parameters, 20114672 gradients, 68.5 GFLOPs
l: [1.00, 1.00, 512] # summary: 357 layers, 25372160 parameters, 25372144 gradients, 87.6 GFLOPs
x: [1.00, 1.50, 512] # summary: 357 layers, 56966176 parameters, 56966160 gradients, 196.0 GFLOPs
# YOLO11n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, DSConv, [64, 3, 2]] # 0-P1/2
- [-1, 1, DSConv, [128, 3, 2]] # 1-P2/4
- [-1, 2, DSC3k2, [256, False, 0.25]]
- [-1, 1, DSConv, [256, 3, 2]] # 3-P3/8
- [-1, 2, DSC3k2, [512, False, 0.25]]
- [-1, 1, DSConv, [512, 3, 2]] # 5-P4/16
- [-1, 2, DSC3k2, [512, True]]
- [-1, 1, DSConv, [1024, 3, 2]] # 7-P5/32
- [-1, 2, DSC3k2, [1024, True]]
- [-1, 1, SPPF, [1024, 5]] # 9
- [-1, 2, C2PSA, [1024]] # 10
# YOLO11n head
head:
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 2, C3k2, [512, False]] # 13
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 2, DSC3k2, [256, False]] # 16 (P3/8-small)
- [-1, 1, DSConv, [256, 3, 2]]
- [[-1, 13], 1, Concat, [1]] # cat head P4
- [-1, 2, DSC3k2, [512, False]] # 19 (P4/16-medium)
- [-1, 1, DSConv, [512, 3, 2]]
- [[-1, 10], 1, Concat, [1]] # cat head P5
- [-1, 2, DSC3k2, [1024, True]] # 22 (P5/32-large)
- [[16, 19, 22], 1, Detect, [nc]] # Detect(P3, P4, P5)因此,如果将此配置与原始 YOLO11 配置进行比较,您可以看到所有 Convs 和 C3k2 都被替换为深度可分离卷积替代方案。
但是,我们还需要在 YOLO 的代码库中使用 PyTorch 实现这些块。因此,您可以在我的存储库中的补丁中看到所有更改,但我将在这里描述主要更改。文件模块/block.py:
class DSConv(nn.Module):
"""The Basic Depthwise Separable Convolution."""
def __init__(self, c_in, c_out, k=3, s=1, p=None, d=1, bias=False):
super().__init__()
if p is None:
p = (d * (k - 1)) // 2
self.dw = nn.Conv2d(
c_in, c_in, kernel_size=k, stride=s,
padding=p, dilatinotallow=d, groups=c_in, bias=bias
)
self.pw = nn.Conv2d(c_in, c_out, 1, 1, 0, bias=bias)
self.bn = nn.BatchNorm2d(c_out)
self.act = nn.SiLU()
def forward(self, x):
x = self.dw(x)
x = self.pw(x)
return self.act(self.bn(x))这是一个简单 DSC 的实现,它处理的设置参数与 YOLO 中的原始 Conv 块相同。
DSC3k2 的实现分为两个阶段:
- DSBottleneck 实现
class DSBottleneck(nn.Module):
def __init__(self, c1, c2, shortcut=True, e=0.5, k1=3, k2=5, d2=1):
super().__init__()
c_ = int(c2 * e)
self.cv1 = DSConv(c1, c_, k1, s=1, p=None, d=1)
self.cv2 = DSConv(c_, c2, k2, s=1, p=None, d=d2)
self.add = shortcut and c1 == c2
def forward(self, x):
y = self.cv2(self.cv1(x))
return x + y if self.add else y- 和 DSC3k2
class DSC3k2(C2f):
def __init__(
self,
c1,
c2,
n=1,
dsc3k=False,
e=0.5,
g=1,
shortcut=True,
k1=3,
k2=7,
d2=1
):
super().__init__(c1, c2, n, shortcut, g, e)
if dsc3k:
self.m = nn.ModuleList(
DSC3k(
self.c, self.c,
n=2,
shortcut=shortcut,
g=g,
e=1.0,
k1=k1,
k2=k2,
d2=d2
)
for _ in range(n)
)
else:
self.m = nn.ModuleList(
DSBottleneck(
self.c, self.c,
shortcut=shortcut,
e=1.0,
k1=k1,
k2=k2,
d2=d2
)
for _ in range(n)
)4. 性能测试
我们将比较 LicheeRV Nano 上的自定义模型指标和推理速度 - 小型 SBC 与 SG2002 SoC 集成了 NPU,在 INT8 计算中性能为 1 TOPS。
本文不会介绍导出电路板模型的过程,但它与导出常规 YOLO 模型没有什么不同。
自定义模型只有 1 个类,并且在两个配置上都针对 50 个纪元进行了训练。50 个纪元不足以达到最大精度,但无论如何,我们将比较 DSConved 和 model 和原始之间的相对准确性。
此外,为了正确计算 DSC 模型的 MAC/FLOP,我对新块使用带钩子的 thop。
import torch
import torch.nn as nn
from thop import profile
from ultralytics import YOLO
from ultralytics.nn.modules import DSConv
from ultralytics.nn.modules.block import DSBottleneck, DSC3k, DSC3k2
def dsconv_flops_counter_hook(module, input, output):
x = input[0] # input tensor
Cin = module.dw.in_channels
Cout = module.pw.out_channels
Hout, Wout = output.shape[2], output.shape[3]
k = module.dw.kernel_size[0]
macs_dw = Hout * Wout * Cin * (k * k)
macs_pw = Hout * Wout * Cin * Cout
module.__flops__ = 2 * (macs_dw + macs_pw)
def dsbottleneck_flops_counter_hook(module, input, output):
flops = 0
for m in [module.cv1, module.cv2]:
x = input[0]
Cin = m.dw.in_channels
Cout = m.pw.out_channels
Hout, Wout = output.shape[2], output.shape[3]
k = m.dw.kernel_size[0]
macs_dw = Hout * Wout * Cin * (k * k)
macs_pw = Hout * Wout * Cin * Cout
flops += 2 * (macs_dw + macs_pw)
module.__flops__ = flops
def dsc3k_flops_counter_hook(module, input, output):
module.__flops__ = sum(getattr(m, "__flops__", 0) for m in module.modules())
config_name = "ds_cfg_all.yaml"
model = YOLO(config_name)
print(model.info())
model = model.model
dummy = torch.randn(1, 3, 640, 640)
flops, params = profile(model, inputs=(dummy,),
custom_ops={DSConv: dsconv_flops_counter_hook,
DSBottleneck: dsbottleneck_flops_counter_hook,
DSC3k: dsc3k_flops_counter_hook,
DSC3k2: dsc3k_flops_counter_hook})
print(f"Config: {config_name}:")
print(f"FLOPs: {flops/1e9:.3f} GFLOPs")
print(f"MACs: {flops/2/1e9:.3f} GMACs")我们可以看到,尽管使用了默认超参数和少量时期,但准确性并没有显着下降。同时,板上的推理速度也明显提高。
深度可分离卷积是 YOLOv11 部署在 NPU 或移动硬件上的强大优化。虽然它对 GPU/CPU 没有太大好处,但它大大减少了作和内存访问,使其成为边缘 AI 应用的理想选择。
2.4、YOLO11-CR
YOLOv8/10n/11n全被KO!YOLO11-CR凭CAFM+RCM模块,侧面脸+手机检测飙至87.17%
把YOLO11升级成YOLO11-CR——新增“卷积+注意力”融合模块与矩形校准模块,专门对付侧面脸、被遮挡脸和手机小目标;DSM数据集实测88.09% mAP@50,刷新疲劳检测精度,同时保持实时性能,为车载嵌入式场景提供即插即用的轻量方案。
本文主要解决了什么问题
- 基于视觉的驾驶员疲劳检测方法在复杂条件下(如部分遮挡、侧面面部姿态和弱光环境)的鲁棒性差问题。
- 小物体(如手机)或被遮挡目标检测效果不佳的问题。
- 多尺度特征建模有限,难以同时捕获局部细节和全局上下文信息的问题。
- 现有方法在计算成本和实时性能之间的平衡问题,特别是在嵌入式系统上的部署瓶颈。
本文的核心创新是什么
- 提出了卷积与注意力融合模块(CAFM),通过局部CNN特征与基于Transformer的全局上下文集成,增强特征表达能力和上下文理解。
- 引入了矩形校准模块(RCM),通过捕获水平和垂直上下文信息,提高空间定位精度,特别适用于侧面面部和手机等小物体检测。
- 基于YOLO11n构建了轻量级高效的YOLO11-CR模型,通过CAFM和RCM的协同作用,实现了在复杂驾驶场景下的高性能实时疲劳检测。
结果相较于以前的方法有哪些提升
- 在DSM数据集上实现了87.17%的精确率、83.86%的召回率、88.09%的mAP@50和55.93%的mAP@50-95,显著优于基线模型(如YOLOv8、YOLOv10n和YOLO11n)。
- 消融研究表明,CAFM模块使召回率提升了3.20%,RCM模块使精确率提升了1.62%,两者结合时在所有指标上均达到最佳性能,体现了模块间的互补性和协同效应。
- 在分类性能上,正常面部类别的mAP@50达到98.6%,侧面面部为89.1%,手机类别为76.3%,特别是在小物体和被遮挡目标检测上表现突出。
- 混淆矩阵和PR曲线分析显示,YOLO11-CR在分类敏感性和特异性上均有提升,尤其在手机检测上正确分类率达到85%,远高于对比模型。
局限性总结
- 手机类别的检测性能(精确率75.8%,召回率65.9%)仍低于正常面部和侧面面部,主要受限于小尺寸和部分遮挡的挑战。
- 型在低光照和极端遮挡条件下的鲁棒性有待进一步验证,当前实验主要基于DSM数据集,可能未覆盖所有真实驾驶场景。
- 尽管模型轻量化,但在嵌入式设备上的实时性能(FPS)并非最优,计算效率仍有提升空间。
- 研究未涉及时间建模和多模态数据集成(如热成像与可见光融合),这些可能是未来改进的方向。
导读
驾驶员疲劳检测对智能交通系统至关重要,因为它在减少道路交通事故方面发挥着关键作用。虽然基于生理和车辆动力学的方法提供了准确性,但它们通常是侵入性的、依赖硬件的,并且在真实环境中缺乏鲁棒性。基于视觉的技术提供了一种非侵入性和可扩展的替代方案,但仍然面临诸如小物体或被遮挡目标检测效果差以及多尺度特征建模有限等挑战。
为了解决这些问题,本文提出了YOLO11-CR,一种专为实时疲劳检测定制的轻量级高效目标检测模型。YOLO11-CR引入了两个关键模块:卷积与注意力融合模块(CAFM),它将局部CNN特征与基于Transformer的全局上下文集成以增强特征表达能力;以及矩形校准模块(RCM),它捕获水平和垂直上下文信息以提高空间定位精度,特别是对于侧面面部和手机等小物体。在DSM数据集上的实验表明,YOLO11-CR实现了 的精确率、 的召回率、 的mAP@ 50 和 的m @ ,显著优于 Baseline 模型。消融研究进一步验证了CAFM和RCM模块在提高敏感性和定位准确性方面的有效性。这些结果表明,YOLO11-CR为车内疲劳监测提供了实用且高性能的解决方案,在现实世界部署和未来涉及时间建模、多模态数据集成和嵌入式优化的增强方面具有强大潜力。
01 引言
随着车辆使用的全局快速扩张,疲劳驾驶已成为一个关键的公共安全问题。随着驾驶员和车辆数量的逐年增长,疲劳直接导致了约的交通事故,通常造成严重伤害或死亡。因此,及时检测和干预对于减轻这些风险至关重要,使实时准确的疲劳检测和警报系统的开发与部署成为增强整体交通安全及减少事故造成的伤害和死亡的基本策略。
当前驾驶员疲劳检测的方法可大致分为三类:基于生理信号的方法、基于车辆动力学的方法和基于视觉的技术。基于生理信号的技术,如脑电图,提供高准确性但需要侵入式测量,在信号整合方面面临计算复杂性,并且对环境和个体差异敏感。基于车辆动力学的方法,通过异常驾驶行为如转向角波动推理疲劳,允许非侵入式监测,但在不同驾驶条件和车辆型号上缺乏一致性。
基于视觉的方法因其非侵入性、易于部署和与实时应用的兼容性而越来越受欢迎。这些方法已从传统的手工特征方法发展到先进的深度学习框架。早期方法专注于使用手动设计的特征提取视觉线索,如眼睛状态、打哈欠和 Head 姿势。Deng等人开发了DriCare系统,该系统从视频帧中捕捉眨眼频率和打哈欠以推理疲劳状态,证明了基于视觉的非侵入式监测的可行性。Knapik等人提出了一种基于热成像的打哈欠检测方法,解决了可见光系统在不同光照条件下的局限性。Saurav等人和Lima等人通过结合卷积神经网络(CNNs)和支持向量机(SVMs)探索眼睛状态识别,实现了实时眨眼检测。这些方法虽然有效,但依赖于预定义特征,在部分遮挡或姿势变化等复杂场景中表现不佳。
将经典机器学习与特征提取机制相结合的混合模型也应运而生,以进一步提高基于视觉的方法的有效性。Magan等人结合了CNN、循环神经网络(RNNs)和模糊逻辑以增强疲劳监测,而Younes等人通过融合RNNs与3D CNNs实现了的检测准确率,突显了时空建模的价值。比较研究,如Norah等人,验证了MobileNet-V2作为最佳表现者,在增强数据集上达到了的准确率。Zhao等人将MediaPipe Face Mesh与MobileNetV3和LSTM相结合,在定制数据上实现了的准确率,展示了轻量级架构的潜力。
基于端到端目标检测框架的实施进一步提高了基于视觉的疲劳检测的功能和效率,其中YOLO模型使其能够进行实时推理。近年来,研究行人利用YOLO变体来检测与疲劳相关的场景,如闭眼、 Head 倾斜和手机使用。Guo等人提出了一种基于YOLOv5的驾驶员疲劳检测方法,在BioID上达到的mAP,在GI4E上达到的mAP,在GTX 1650上达到43 FPS。Wang等人提出了一种改进的YOLOv5模型,与原始模型相比,mAP提高了,而FPS仅下降了8.3。然而,随着模型性能要求的不断提高,基于早期YOLO版本的改进在复杂场景适应性和多维特征融合方面逐渐显示出局限性,这促使研究行人基于更新版本的YOLO模型进行更深入的探索。
值得注意的是,近期的研究集中于集成先进的注意力机制以应对这些挑战。例如,Li等人将通道空间注意力模块(CSAM)引入YOLOv4,通过动态加权通道和空间维度增强了小目标的特征表示。类似地,Chen等人提出了多尺度特征注意力网络(MFAN),该网络能够自适应地聚合不同尺度的特征,提高了在不同光照条件下疲劳线索的检测准确性。这些研究表明,注意力机制可以有效缓解传统CNN架构在捕捉细粒度细节方面的局限性。
随着YOLOv8的发布,研究采用了其增强的transformer Backbone 网络来捕获复杂的空间特征。Zhang等人构建了一个混合模型,将YOLOv8与LSTM时序模块相结合,通过整合时空上下文提高了微睡眠检测的敏感性。最近,YOLO11系列因其准确性和效率的平衡而受到关注。Huang等人开发了LWYOLO11,这是一个轻量级变体,在保持侧面人脸和手机检测精度的同时减少了计算负载。Deng等人将多尺度注意力机制整合到YOLOv6中,以提高在不同光照条件下对细微面部疲劳指标的敏感性。这些进展展示了一个向多目标、多尺度检测框架发展的趋势。YOLO模型在平衡高mAP与实时处理方面表现出色,使其适合在车载环境中部署。关键创新包括注意力机制、多尺度特征聚合和 Anchor-Free 点检测Head,这些创新增强了从面部表情到次要任务干扰等多种疲劳线索的识别能力。
然而,基于视觉的方法面临着关键障碍。在复杂条件下的鲁棒性,如被手或太阳镜部分遮挡、侧面面部姿态和弱光环境,仍然具有挑战性;例如,当被太阳镜遮挡时,标准模型难以检测闭眼状态。识别同时发生的行为(如使用手机和打哈欠)需要先进的时空推理能力,而许多模型缺乏这种能力。在有限数据集上训练的模型通常无法适应不同的驾驶环境、摄像头角度或驾驶员人口统计特征。尽管出现了轻量级模型,但在低功耗嵌入式系统上的实时性能仍然是广泛采用的 Bottleneck 。未来的研究应专注于增强被遮挡物体的特征表示,整合多模态传感(如热成像和可见光),并开发领域自适应模型。通过大规模实地试验进行时间建模和跨场景验证,对于弥合实验室准确性与现实世界可靠性之间的差距也至关重要。
为解决这些局限性,包括遮挡条件下的鲁棒性差、多尺度特征建模有限以及高计算成本。本文提出了YOLO11-CR,一种轻量级且高性能的检测模型。本文的主要贡献可总结如下:
- 设计卷积与注意力融合模块(CAFM)来替换C2PSA模块中的注意力层,形成增强的C2PSA_CAFM结构。该模块通过局部和全局分支整合CNN和Transformer以提取各自的特征,最终输出通过对这些流求和得到,用于建模局部-全局表示并增强特征表达能力和上下文理解。
- 引入矩形校准模块(RCM)来替代YOLO11n特定特征提取/融合阶段中的传统3×3和1×1卷积。RCM通过捕获水平-垂直全局上下文来增强YOLO11中的空间特征建模,实现更准确的多尺度目标定位/识别,并提高整体网络检测性能。
- 对YOLO11-CR进行微调和测试以用于疲劳检测场景,重点关注三个关键目标类别:正常面部、侧面面部和手机。
本文的其余部分组织如下:第2节详细介绍了提出的YOLO11-CR、CAFM的结构以及RCM的结构。第3节介绍了实验设置,包括数据集概述、训练超参数和评估指标。第4节对YOLO11-CR中的CAFM和RCM模块进行了消融研究,并对性能参数进行了全面分析。最后,本文在第5节进行了总结。
02 框架
为构建有效的疲劳驾驶检测系统,本文提出了YOLO11-CR,这是一种基于YOLO11的增强型单阶段目标检测框架,旨在解决驾驶员行为分析中的小尺度目标、部分遮挡和非正面面部朝向等挑战。如图1所示,YOLO11-CR集成了两个新颖的结构模块:CAFM和RCM,它们协同增强了多尺度表示学习、空间特征对齐以及复杂场景下的检测精度。采用典型的编码器-解码器设计,该网络包括用于分层特征提取的YOLO11n Backbone 网络、特征融合 Neck 和多尺度检测Head。检测目标被定义为正面面部、侧面面部和手机,它们作为疲劳检测系统中的关键语义线索。 Backbone 网络生成P3–P5 Level 的特征,分别以8、16和32的因子进行上采样,这些特征在传递到检测Head进行边界框回归和类别概率预测之前,会通过注意力增强表示进行增强。

2.1 卷积与注意力融合模块
为了解决在轻量高效的方式下同时捕获局部细粒度特征和全局上下文关系的基本挑战。受卷积操作和自注意力机制的互补优势启发,本节引入CAFM 来解决复杂检测场景的问题,如小目标检测、遮挡目标识别和疲劳特征提取。
如图2所示,CAFM由两个功能分支组成,局部分支旨在捕获对检测小尺度目标和保持边界精度至关重要的细粒度空间模式,通过卷积操作提取空间细节;全局分支则通过引入轻量级自注意力机制来解决卷积感受野有限的问题,以建模长距离空间依赖关系,这对于理解遮挡或分布特征至关重要。

给定输入特征图 ,局部分支依次应用 卷积 来调整通道维度并增强特征交互,然后应用通道混洗操作 来改善通道间信息 Stream,以及 深度卷积 来进一步提取空间局部特征,整个处理流程可以计算为:
虽然全局分支首先通过 卷积和深度 卷积生成 Query(Q)、键 和值 矩阵,然后通过在特征通道上计算注意力而非完整空间域来降低计算成本,最后应用公式化的缩放点积注意力:
其中 是一个可学习的缩放参数,用于控制softmax的锐度。然后,可以计算注意力增强的输出:
最后,融合输出 可以计算如下:
2.2 矩形校准模块
虽然传统的卷积操作和标准的注意力机制是有效的,但它们往往难以精确建模现实场景中常见的细长、轴向对齐和部分遮挡的结构,例如侧面人脸、手持物体或与疲劳相关的手势。为了应对这些挑战,RCM 被整合到网络中,如图3所示,RCM包含四个关键组成部分:轴向全局上下文聚合、形状自校准重建、局部-全局特征融合和残差细化。

为了建模矩形区域,RCM将2D全局注意力分解为水平池化(HP)和垂直池化(VP),其中水平池化沿每行平均特征响应以捕获水平上下文,垂直池化沿每列平均响应以捕获垂直上下文,这两个轴向全局上下文通过广播相加形成初始的粗略矩形注意力图,如下所示:
其中 是输入特征图,且 表示逐元素广播加法。
由于初始的矩形注意力图可能仍然粗糙或无法匹配实际物体轮廓, RCM 整合了一个形状自校准功能,通过一个涉及大核条带卷积的过程动态调整注意力形状,随后进行Batch Normalization和ReLU激活函数处理,该操作在数学上定义为:
其中 表示条带卷积, 表示BatchNorm和ReLU,而 是Sigmoid激活函数,用于将输出限制在 0 和 1 之间。
为了通过局部空间细节丰富重新校准的注意力,输入特征 首先通过一个 的深度卷积处理,然后将校准后的注意力图与局部精炼的特征图进行逐元素相乘。局部-全局特征融合可以计算如下:
其中 表示Hadamard乘法。通过局部-全局特征融合,最终特征能够确保保留关键的局部纹理细节,同时充分利用全局上下文信息,从而为精确检测提供强有力的支持。
受残差学习策略的启发,RCM 的输出通过一个轻量级MLP和批归一化层进行处理,并添加了一个残差连接:
其中 代表1个BatchNorm后接MLP变换,通过残差连接实现增强的特征重用和稳定的梯度流。

2.3 多尺度检测Head
多尺度检测Head在三种分辨率(P3, P4, P5)上运行,每个分辨率都嵌入了一个RCM块,用于在预测之前优化语义表示,其中最终的Detect模块在各个尺度上预测三个类别的类别概率和边界框,通过在 Backbone 网络尾部引入CAFM,并在检测尺度上引入RCM,YOLO11-CR通过融合注意力有效改善了正常面部的检测以捕获全局面部结构,通过矩形核改善侧面面部的检测以定位细长轮廓,并通过多尺度上下文和方向注意力改善手机的检测以抑制背景噪声和杂乱。
03 实验设置
为了验证所提出的YOLO11-CR模型在疲劳检测方面的有效性,作者设计并执行了一套全面的实验。本节详细介绍了实验设置,包括数据集选择、评估指标和实现细节。
3.1 实验数据集
为评估所提出的YOLO11-CR模型在检测疲劳相关行为方面的有效性,本研究采用了Driver State Monitoring (DSM)数据集,这是一个专门为驾驶员疲劳和分心检测整理的综合基准数据集。DSM数据集源自Ortega等人提出的公开可用的DMD数据集,该数据集是领域内最广泛采用的多模态驾驶员监测数据集之一。DSM数据集包含超过180,000张RGB图像,这些图像是从车载视频录像中提取的,涵盖了城市道路、高速公路和夜间驾驶等多种环境。数据是通过安装在仪表盘和天花板上的高清摄像头收集的,确保了正面和侧面视角的覆盖。如图4所示,数据集中的几个典型样本展示了所捕获行为的多样性,包括面部表情和侧面姿势。每张图像都标注了特定行为的标签,包括"正常驾驶"、"闭眼"、"打哈欠"、"低头"、"使用手机"和"侧视",详细的标签分布见表1。
该数据集包含边界框、面部标志和遮挡 Level 的标注,使得检测模型能够在不同的视觉条件下进行稳健评估。此外,该数据集还包含了各种人口统计特征,如不同年龄段、性别和配饰(例如太阳镜、帽子、 Mask ),使其成为需要在不同驾驶员间进行泛化的疲劳检测任务的理想选择。为了模型训练和评估的目的,该数据集按7:2:1的比例划分为训练集、验证集和测试集。

除了逐帧标注外,DSM数据集还支持时序分析,允许应用序列模型来检测渐进性疲劳症状,如眨眼频率降低或微睡眠。正如Ortega等人所强调的,其多模态结构和现实世界复杂性使其成为测试安全关键型汽车应用中疲劳检测系统的理想基准。
3.2 实现细节
所有实验均在使用配备AMD Ryzen 9 5950X CPU、NVIDIA GeForce RTX 3090 GPU和64 GB DDR5 RAM的高性能计算环境中进行。操作系统为Windows 11,实现使用Python 3.11.2和支持CUDA12.4的PyTorch 2.5.1完成。此配置确保了充足的计算资源,能够高效处理大规模训练任务。
在训练过程中,批量大小设置为64,并使用随机梯度下降(SGD)优化器,初始学习率为0.001。在训练过程中,使用余弦退火调度器动态调整学习率。SGD的动量系数设置为0.937,以促进稳定收敛。模型总共训练了100个轮次。未采用早停机制,使模型能够完成完整的训练计划并彻底探索优化景观。
为了增强泛化能力和鲁棒性,在训练过程中应用了数据增强技术。具体而言,采用了Mosaic增强和随机水平翻转来增加训练样本的多样性,并模拟各种真实世界的驾驶条件。
3.3 评估指标
为了评估所提出的YOLO11-CR模型的性能,采用了目标检测中的三个主要评估指标,例如:在 阈值为 0.5 时的平均精度均值 (mAP@50),在 阈值从 0.5 到 0.95 范围内的平均精度均值 (mAP@50-95),Precision和Recall。这些指标可以表示为:
其中 表示正确预测的真正例, 表示被错误预测为正例的假正例, 表示被错误预测为负例的假负例。 表示类别的数量。
04 实验结果与讨论
为了全面评估所提出的YOLO11-CR模型的有效性,作者进行了一系列与几个 Baseline 检测模型的对比实验。本节详细分析了结果,通过消融研究检验了各个模块增强的影响、分类检测精度、混淆矩阵洞察、精确度-召回率特性以及与最先进(SOTA)模型的比较。
4.1 消融实验
为了评估CAFM和RCM对整体性能提升的贡献,进行了一项消融研究。结果如表2所示。

将RCM模块添加到 Baseline 模型中导致了精确率( )和 的增加,同时召回率( )也有轻微改善。这表明RCM主要增强了模型的定位能力,使边界框回归更加准确。矩形校准有效地将预测框对齐到人脸和移动设备的自然长宽比,从而提高了检测的精确率,同时不降低召回率。
集成CAFM模块使Recall显著提升了 ,而与 Baseline 相比,Precision略微下降了( )。这表明CAFM增强了特征提取能力,使其能够捕捉更多具有挑战性或部分被遮挡的物体。然而, Precision的轻微下降意味着特征融合过程可能会引入更多的误报,尤其是在区分小型手持设备与背景噪声时。
当同时集成CAFM和RCM时,模型在Precision、Recall、 和mAP@ 指标上同时达到了最高值。组合模型不仅仅是简单汇总了各自的改进,而是进一步增强了整体鲁棒性,这表明CAFM和RCM之间存在强烈的互补关系。CAFM提高了检测灵敏度,而RCM优化了空间校准,从而在检测灵敏度和定位精度两方面都带来了显著提升。
鉴于手机类别通常涉及小尺寸物体,召回率和精度的综合提升表明YOLO11-CR在检测小型、被遮挡和非正面目标方面特别有效。这验证了先进的多尺度特征融合和自适应空间校准对于改善现实世界条件下的驾驶员监控系统至关重要的直觉。
总体而言,消融研究证实了这两个模块都独特且协同地贡献于YOLO11-CR模型的增强性能。
4.2 按类别性能分析
为了进一步研究模型在不同疲劳相关类别上的有效性,计算了每个类别的评估指标,如表3所示,可以观察到模型在正常面部类别上取得了出色的检测性能,Precision为 ,Recall为 ,以及极高的mAP@50为 。这表明模型在捕捉清晰、正面的面部特征方面具有很强的能力,即使在不同的环境条件下。

侧面人脸类别的检测性能略低,特别是在Recall( )方面,这表明由于可区分特征较少和面部外观变化较大,侧面姿势的检测更具挑战性。尽管如此,达到的mAP@ 50 为 ,对于实际应用而言仍然令人满意。
手机类别在三个类别中表现出最低的检测指标,其精确率为 ,召回率为 ,mAP@50-95仅为 。这主要是因为手机在图像中通常尺寸较小,并且经常被手或方向盘部分遮挡,使其更难以检测。尽管面临这些挑战,YOLO11-CR模型仍然保持了合理的性能,这得益于CAFM带来的增强特征提取能力以及RCM实现的自适应空间调整。
4.3 混淆矩阵分析
为了获得更深入的模型性能见解,对四个评估模型的归一化混淆矩阵进行了分析,如图5所示。每个混淆矩阵展示了在四个类别上的预测准确率:侧面人脸 (pface)、正面人脸 (nface)、手机和背景。

在所有模型中,pface类别始终表现出最高的分类准确率,其中 YOLO11-CR达到了 的正确预测率,优于YOLOv8、YOLOv10n和YOLO11n。这表明正面人脸因其独特且易于识别的特征,相对更容易被检测到。对于nface类别,YOLO11-CR表现出 的正确分类率,高于YOLOv10n的( )和YOLO11n的( ),并略微超过 YOLOv8的( )。这一结果突显了YOLO11-CR在处理部分面部视图方面的改进鲁棒性,这可能是由于CAFM模块增强了全局-局部特征提取能力。
手机类别的检测性能在各模型之间显示出显著差异。YOLO11-CR达到了 的正确分类率,显著优于YOLOv8( )、YOLOv10n ( )和YOLO 。这突显了该模型在检测小目标和被遮挡物体方面的增强能力,这是RCM模块自适应空间校准的直接好处。在所有模型中,背景类别表现出相对较低的分类一致性,这是由于真实驾驶环境的多样性和复杂性所预期的。然而,YOLO11-CR保持了相当高的真阴性率,最大程度地减少了与疲劳无关区域的假阳性。
总体而言,混淆矩阵分析进一步证实,YOLO11-CR显著提高了分类敏感性(对于侧脸和手机等具有挑战性的类别具有更高的Recall)和分类特异性(在背景区域中具有更低的误报率),从而实现了平衡且稳健的性能,适用于现实世界的驾驶员监控应用。
4.4 Precision-Recall曲线分析
为了进一步评估不同模型的检测性能,分析了每个模型的精确率-召回率(PR)曲线,如图6所示。PR曲线描绘了在不同检测阈值下Precision和Recall之间的关系,全面展示了模型在平衡敏感性和特异性方面的稳健性。

YOLO11-CR模型在所有比较模型中获得了最有利的PR曲线轨迹。如图6(d)所示,与YOLOv8、YOLOv10n和YOLO11n相比, YOLO11-CR在整个召回率值范围内保持了更高的精确度。具体而言,即使在高召回率水平(例如,召回率 )下,YOLO11-CR仍保持了 以上的精确度,这证明了其在检测疲劳相关行为时的鲁棒性,且没有明显的性能下降。相比之下,随着召回率的增加, YOLOv8和YOLOv10n表现出更陡峭的精确度下降,特别是在手机类别中,物体尺寸和遮挡复杂性带来了更大的挑战。YOLOv8尽管实现了相对较高的召回率,但在召回率超过 后表现出精确度的显著下降,这表明在宽松阈值下有更高的假阳性率。
YOLO11-CR,YOLO11n,YOLOv10n和YOLOv8分别达到了 、 和 的mAP@50,进一步支持了基于PR曲线的这些观察结果。值得注意的是,YOLO11-CR和YOLOv8之间的性能差距在手机类别中尤为明显,其中YOLO11-CR达到了 的手机mAP,而YOLOv8仅为 。这突显了CAFM和RCM在增强小目标检测方面的有效性。
总体而言,PR曲线分析证实了YOLO11-CR模型具有优越的precision-recall平衡性和稳定性,确认了其在疲劳检测任务中实现高灵敏度和可靠性的有效性。
4.5 与SOTA的比较
最后,为了评估所提出的YOLO11-CR模型的有效性,作者与几个SOTA模型进行了对比实验,包括YOLOv8、YOLOv10n和YOLO11n。表4总结了这些模型在DSM数据集测试子集上的精确率、召回率、mAP@50、mAP@50-95、参数量、GLOPs和FPS等性能指标。尽管YOLO11-CR的FPS指标不是最优的,但考虑到所有其他性能指标都是最佳的,它在效率和准确性之间取得了理想的平衡。

图7展示了不同YOLO系列模型在驾驶场景图像上的疲劳检测结果。每一行对应一组来自驾驶场景的测试样本,涵盖了车内人脸和手持物体等复杂工况。YOLOv8、YOLOv10n和YOLOv11n在手持目标检测中都不可避免地存在漏检或误检问题。相比之下,本文提出的YOLO11-CR模型有效解决了手机等长条形物体的漏检和误检问题,实现了更高的检测精度。

5. 结论
本文介绍了基于改进的YOLO11模型(称为YOLO11-CR)的轻量级、高精度疲劳驾驶检测系统的设计和优化。通过将CAFM和RCM集成到基础YOLO11架构中,所提出的模型显著增强了特征提取能力和空间定位精度,特别是对于小规模和被遮挡的物体。
在DSM数据集上的广泛实验评估表明,YOLO11-CR在关键性能指标上始终优于 Baseline 模型,实现了 的精确率、 的召回率、 的mAP@50和 的mAP@50-95。每类性能分析、混淆矩阵评估和PR曲线比较进一步验证了所提出系统在现实世界疲劳检测场景中的鲁棒性和可靠性。消融研究确认 CAFM和RCM模块提供了互补的增强,其中CAFM提高了检测灵敏度,而RCM优化了空间对齐。它们的组合集成带来了显著的协同性能提升。
总体而言,YOLO11-CR为实时疲劳监测提供了一个实用、高效且鲁棒的解决方案,在智能车载安全系统中具有强大的部署潜力。
参考
[1]. YOLO11-CR: a Lightweight Convolution-and-Attention Framework for Accurate Fatigue Driving Detection
2.5、C#~YOLOv11目标检测
主要介绍在C#中使用YOLOv11实现目标检测
YOLOv11介绍
YOLO11的介绍和使用这里不再赘述,请参考公众号下面两篇文章即可:
上面文章详细介绍了YOLO11相关知识,也包括如何训练自己的YOLO11目标检测模型,后续将不在赘述。
C#中使用YOLOv11
【1】环境和依赖项。
需先安装VS2022最新版(17.12.0),.NetFramework8.0,然后新建项目(需自行安装并使用Microsoft.NET.UpgradeAssistant升级工具将项目升级到.Net8.0),nuget安装YoloSharp,YoloSharp介绍:
https://github.com/dme-compunet/YoloSharp
最新版为6.0.1,本文只演示CPU版本,GPU版本可以自行尝试。
【2】YoloV11模型转换。
将下载的(或自己训练好的)YoloV11模型转为onnx格式,这里模型使用官网下载的yolo11s.pt,转换代码如下:
from ultralytics import YOLO
# Load a model
model = YOLO("yolo11s.pt") # load an official model
# Export the model
model.export(format="onnx")
转换后生成onnx模型文件yolo11s.onnx。
【3】编写C#推理代码。
将转换后的onnx模型和测试图片准备好,使用下面代码加载即可预测:
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
using Compunet.YoloSharp;
using Compunet.YoloSharp.Plotting;
using SixLabors.ImageSharp;
using Compunet.YoloSharp.Data;
namespaceYolo_CSharp
{
internalclassProgram
{
staticvoidMain(string[] args)
{
//Load the YOLO predictor
using var predictor = new YoloPredictor("yolo11s.onnx");
predictor.Configuration.SuppressParallelInference = true;
predictor.Configuration.KeepAspectRatio = true;
predictor.Configuration.Confidence = 0.3F;
var results = predictor.Detect("2.jpg");
usingvar image = SixLabors.ImageSharp.Image.Load("2.jpg");
usingvar ploted = results.PlotImage(image);
ploted.Save("cc.jpg");
Console.WriteLine(results);
}
}
}【4】推理结果对比
使用python版本.pt模型推理和转换后的onnx模型在C#下推理结果对比如下:
python-yolo11s.pt


C#-yolo11s.onnx


对比来看准确率相当,可以使用。
【5】扩展延伸
搭配OpenCvSharp和WinForm就可以做一个简单的界面程序了,效果如下(预训练模型和自己训练的模型):


2.6、YOLOv11~将重新定义AI的可能性
Ultralytics YOLOv11的问世标志着人工智能领域,尤其是计算机视觉领域的一个突破性时刻。随着 Ultralytics YOLOv11 的发布,人工智能历史上的一个分水岭已经到来。这在计算机视觉领域尤其如此。延续 YOLO(You Only Look Once)系列的强大传统,这一新版本旨在提高实时对象检测和图片分割能力,实现前所未有的效率和性能水平。
https://www.ultralytics.com/zh/blog/ultralytics-yolo11-has-arrived-redefine-whats-possible-in-aiYOLO 进化简述
YOLO 系列自诞生以来,不断推动着物体检测技术的前沿发展。每次迭代都有实质性的改进:
- YOLOv1(2016):首个将对象检测概念化为单一回归问题的模型。
- YOLOv2(2017):使用批量标准化和锚框提高精度。
- YOLOv3(2018):通过更高效的主干架构提高功效。
- YOLOv4(2020):引入了 Mosaic 数据增强和新颖的损失函数等进步。
- YOLOv5(2020):强调性能和以用户为中心的功能的增强。
- YOLOv6(2022):美团开源,专门针对自动配送应用进行了优化。
- YOLOv7(2022):引入了增强功能,包括姿势估计。
- YOLOv8(2023):提高了对各种视觉 AI 应用的适应性。
Ultralytics 致力于通过结合最先进的方法来提高速度、精度和用户友好性,从而增强 YOLOv11 的进步。
探索 YOLO11
YOLO11 是一种更强大、更灵活的模型,可将计算机视觉提升到新的水平,它为 YOLO 家族开启了新纪元。该模型在计算机视觉任务(如姿势估计和实例分割)的性能和准确性方面比 Ultralytics YOLOv8 有所改进。它的架构经过了微调,功能也得到了扩展。“我们的目标是开发 YOLO11,创建一个为实际应用提供强大功能和实用性的模型,”Ultralytics 创始人兼首席执行官 Glenn Jocher 解释道。由于其精度和效率的提高,它是一种多功能工具,可以根据不同行业的特定需求进行调整。我热切期待 Vision AI 社区将使用 YOLO11 开发和实施独特的解决方案,以提升计算机视觉。
YOLO11支持的计算机视觉任务的概述:
- 对象检测:识别并精确定位图片或视频帧中的对象,用边界框勾勒出它们,用于监控、自动驾驶和零售分析等用途。实例分割需要在像素级别识别和勾勒出图像中的离散对象。它对医学成像和制造业缺陷识别等应用大有裨益。
- 图像分类:将整张照片分配到已建立的类别,使其适用于电子商务中的产品分类或野生动物监视等应用。
- 姿势估计:识别图像或视频帧中的某些重要点以监控运动或姿势,有利于健身追踪、运动分析和医疗保健应用。
- 定向物体检测:(OBB)识别具有特定方向角的物体,有助于更准确地定位旋转物体,特别有利于航空成像、机器人和仓库自动化应用。
- 对象跟踪:观察并追踪连续视频帧中对象的动作,这对于众多实时应用来说至关重要。

YOLOv11 的主要特点
1. 无与伦比的速度和精度:
YOLOv11 的设计目标是在不牺牲精度的情况下实现快速运行。自动驾驶汽车、安全系统和工业自动化只是实时应用的几个例子,这些应用可以从该模型架构优化的快速推理时间中受益。需要快速决策的情况需要在速度和准确性之间取得平衡。
其次,卓越的物体检测技能。
2. 高级物体检测功能:
YOLOv11 的一个显著改进是其在复杂环境中的物体检测功能。得益于其广泛的特征提取技术,该模型能够容忍遮挡并比早期版本更好地区分重叠物体。拥挤环境中的应用(如城市监控或事件监控)依赖于此功能。
3. 应用多功能性:
- 实例分割:区分图像中的各个对象。
- 姿势估计:识别人体姿势以用于体育分析和医疗保健应用。
- 跟踪:跨框架跟踪移动物体,以进行交通监控或库存管理。
这种多功能性使 YOLOv11 可应用于从医疗保健到农业的各个领域。
YOLO11 有何不同?
YOLO11 在 YOLOv9 和 YOLOv10 的创新基础上进行了扩展,集成了卓越的架构框架、精炼的特征提取方法和优化的训练协议。YOLO11 以其速度、准确性和效率的出色结合而著称,是 Ultralytics 迄今为止开发的最熟练的模型之一。YOLO11 凭借其增强的设计,提供了卓越的特征提取,能够精确识别图像中的重要模式和细节,从而更正确地捕捉复杂元素,尤其是在困难条件下。
值得注意的是,YOLO11m 在 COCO 数据集上获得了更高的平均精度 (mAP) 得分,尽管使用的参数比 YOLOv8m 少 22%,这使其在不影响性能的情况下具有更高的计算效率。这表明它在以更高的效率运行的同时产生了更精确的结果。此外,YOLO11 的处理速度有所提高,推理时间比 YOLOv10 快了约 2%,使其适用于实时应用。
它旨在管理复杂的活动,同时优化资源利用率并提高广泛模型的性能,使其非常适合严格的 AI 计划。增强管道的改进优化了训练过程,使 YOLO11 能够适应各种任务,无论项目规模如何。
YOLO11 的处理能力极其高效,非常适合部署在云端和边缘设备上,可在多种情况下提供灵活性。YOLO11 不仅是一种增强功能;它是一种明显更精确、更高效、适应性更强的模型,经过优化设计,可应对各种计算机视觉挑战。YOLO11 具有足够的适应性,可适应各种计算机视觉应用,包括自动驾驶、监控、医疗成像、智能零售和工业用例。
详细介绍可参考:
https://www.ultralytics.com/zh/blog/ultralytics-yolo11-has-arrived-redefine-whats-possible-in-ai3、Yolo12
3.1、YOLOv12好在哪里?
「当YOLO遇上Attention」细数YOLO多个版本,YOLOv12究竟好在哪里?
本文系统回顾了YOLOv12的创新之处,重点分析了其引入的区域注意力机制(A²)、残差高效层聚合网络(R-ELAN)和FlashAttention等关键技术,如何有效解决传统CNN在长距离依赖建模上的不足,并显著提升实时目标检测的精度与效率。
本文主要解决了什么问题
1. 实时目标检测中的效率与精度权衡:YOLOv12通过引入注意力机制和优化计算资源,解决了传统卷积神经网络(CNN)在捕获长距离依赖关系上的局限性,同时保持了实时性能。
2. 高计算开销的注意力机制挑战:通过设计区域注意力模块(A2)、FlashAttention等技术,有效降低了注意力机制的计算复杂度和内存开销。
3. 深度网络训练中的梯度阻断问题:通过残差高效层聚合网络(R-ELAN),改善了深层模型的梯度传播,提升了训练稳定性与收敛速度。
本文的核心创新是什么
1. 区域注意力模块(A2):将特征图划分为大小相等且不重叠的块,显著降低自注意力的计算复杂度,同时保留较大的感受野。
2. 残差高效层聚合网络(R-ELAN):通过引入残差连接和优化特征融合策略,解决了传统ELAN架构中梯度阻断的问题,增强了深层模型的训练稳定性。
3. FlashAttention集成:通过重构计算以更好地利用GPU高速内存(SRAM),减少内存访问开销,提升推理速度。
4. 多层感知器(MLP)比例优化:将MLP扩展比例从4降低至1.2,避免不必要的计算开销,平衡效率与性能。
结果相较于以前的方法有哪些提升
1. 准确性提升:YOLOv12-N实现了40.6%的mAP,超越YOLOv10-N(38.5%)和YOLOv11-N(39.4%),同时保持更低的推理延迟。
2. 推理速度优化:YOLOv12-S的推理延迟为2.61毫秒,比RT-DETR-R18/RT-DETRv2-R18快约42%,仅使用36%的计算量和45%的参数。
3. 计算效率改进:YOLOv12-L在88.9 GFLOPs的情况下实现53.7%mAP,优于YOLOv11-L(86.9 GFLOPs,53.3%mAP),表明其更高的计算效率。
局限性总结
1. 硬件约束下的边缘部署挑战:尽管YOLOv12在高端GPU上表现出色,但其对内存和计算资源的需求限制了其在低功耗边缘设备(如NVIDIA Jetson Nano、树莓派)上的应用。
2. 训练复杂性增加:基于注意力的模块需要更多的FLOPs和内存带宽,导致训练成本高昂,尤其对于GPU资源有限的用户。
3. 数据集依赖性:YOLOv12的优越精度依赖于大规模数据集(如MS COCO和OpenImages),但在小规模或分布不平衡的数据集上表现可能受限。
4. 任务扩展的局限性:当前YOLOv12主要专注于2D目标检测,尚未充分探索3D目标检测、实例分割和全景分割等更复杂的场景理解任务。
通过上述分析,YOLOv12在实时目标检测领域取得了显著进步,但未来仍需进一步研究以解决硬件适应性和任务扩展等方面的挑战。
导读
YOLO(You Only Look Once)系列一直是在实时目标检测领域领先的框架,持续在速度和准确性之间取得平衡。然而,将注意力机制集成到YOLO中一直具有挑战性,因为注意力机制的计算开销较高。YOLOv12引入了一种新颖的方法,成功地将基于注意力的增强功能与实时性能相结合。本文全面回顾了YOLOv12的架构创新,包括用于计算高效自注意力的区域注意力机制、用于改进特征聚合的残差高效层聚合网络,以及用于优化内存访问的FlashAttention。此外,作者将YOLOv12与之前的YOLO版本和竞争性目标检测器进行基准测试,分析其在准确性、推理速度和计算效率方面的改进。通过这一分析,作者展示了YOLOv12如何通过优化延迟-准确性权衡和优化计算资源来推动实时目标检测的发展。
1 引言
实时目标检测是现代计算机视觉的核心技术,在自动驾驶[1, 2, 3, 4]、机器人[5, 6, 7]和视频监控[8, 9, 10]等应用中发挥着关键作用。这些领域不仅要求高精度,还需要低延迟性能以确保实时决策。在各类目标检测框架中,YOLO(You Only Look Once)系列已成为主流解决方案[11],通过持续优化卷积神经网络(CNN)架构[12, 13, 14, 15, 16, 17, 18, 19, 20, 21],在速度与精度之间取得了平衡。然而,基于CNN的检测器面临一个基本挑战——其捕获长距离依赖关系的有限能力,这对于理解复杂场景中的空间关系至关重要。这一局限性促使研究行人加强对注意力机制的研究,特别是视觉Transformer(ViTs)[22, 23],后者在全局特征建模方面表现出色。尽管具有这些优势,ViTs存在二次方计算复杂度[24]和内存访问效率低下[25, 26]的问题,使其难以部署于实时场景。
为解决这些局限性,YOLOv12 [27] 引入了一种以注意力为中心的方法,通过整合关键创新来提升效率,同时保持实时性能。通过将注意力机制嵌入YOLO框架中,它成功地在CNN基础检测器和基于transformer的检测器之间架起了桥梁,而未牺牲速度。这是通过以下几个架构增强实现的,这些增强优化了计算效率,改进了特征聚合,并细化了注意力机制:
- 区域注意力(A2):一种新颖的机制,通过划分空间区域来降低自注意力的复杂性,在保持较大感受野的同时提升计算效率。这使得基于注意力的模型能够在速度上与卷积神经网络(CNN)相媲美。
- 残差高效层聚合网络(R-ELAN):对传统ELAN的增强,通过引入残差捷径和改进的特征聚合策略,旨在稳定大规模模型的训练,确保更好的梯度流和优化。
- 架构优化:通过多项结构改进,包括集成FlashAttention以实现高效内存访问、移除位置编码以简化计算,以及优化MLP比例以平衡性能和推理速度。
这篇综述系统性地考察了YOLOv12中的关键架构进展,包括注意力机制、特征聚合策略和计算优化的集成。为了进行结构化分析,本文组织如下:第2节概述了YOLO架构的技术演进,重点介绍了推动YOLOv12发展的进步。第3节详细描述了YOLOv12的架构设计,包括其 Backbone 特征提取过程和检测Head。第4节探讨了模型的关键创新,包括A2模块、R-ELAN以及其他为提高效率而进行的增强。第5节展示了基准评估,比较了YOLOv12与前代YOLO版本以及当前最先进的目标检测器的性能。第6节讨论了YOLOv12支持的各种计算机视觉任务。第7节就模型效率、部署考虑以及YOLOv12在现实应用中的影响进行了更广泛的讨论。第8节分析了当前挑战并概述了未来的研究方向。最后,第9节总结全文,概括了YOLOv12对实时目标检测的贡献及其在该领域进一步发展的潜力。
2 YOLO 架构的技术演进
YOLO系列通过持续的建筑创新和性能优化,彻底改变了实时目标检测领域。YOLO的发展可以通过其不同版本进行追溯,每个版本都引入了重大进展。
YOLOv1(2015)[11]由Joseph Redmon等人开发,引入了单阶段目标检测的概念,优先考虑速度而非精度。该方法将图像划分为网格,并直接从每个网格单元预测边界框和类别概率,从而实现实时推理。与双阶段检测器相比,此方法显著降低了计算开销,尽管在定位精度方面存在一些权衡。
YOLOv2(2016)[12],由Joseph Redmon开发,通过引入 Anchor 框、批量归一化和多尺度训练增强了检测能力。 Anchor 框使模型能够预测不同形状和大小的边界框,提高了其检测多样化物体的能力。批量归一化稳定了训练并提升了收敛性,而多尺度训练使模型对不同的输入分辨率更加鲁棒。
YOLOv3(2018)[13],由Joseph Redmon再次改进,通过Darknet-53 Backbone 网络、特征金字塔网络(FPN)和逻辑分类器进一步提升了准确率。Darknet-53提供了更深、更强大的特征提取能力,而FPN使模型能够利用多尺度特征以提升小目标检测性能。逻辑分类器取代了softmax用于类别预测,实现了多标签分类。
YOLOv4(2020)[14]由Alexey Bochkovskiy等人开发,集成了CSPDarknet、Mish激活函数、PANet和Mosaic数据增强。CSPDarknet在保持性能的同时降低了计算成本,Mish激活函数改善了梯度传播,PANet增强了特征融合,Mosaic数据增强增加了数据多样性。
YOLOv5(2020)[15]由Ultralytics开发,通过引入PyTorch实现,标志着关键性的转变。这极大地简化了训练和部署,使YOLO对更广泛的受众更加易用。它还引入了自动 Anchor 点学习,在训练过程中动态调整 Anchor 框大小,并集成了数据增强的进步。从Darknet到PyTorch的转变是一个重大变化,极大地促进了该模型的人气。
YOLOv6(2022)[16]由美团开发,专注于效率,采用了EfficientRep Backbone 网络、神经架构搜索(NAS)和RepOptimizer。EfficientRep优化了模型的架构以提升速度和精度,NAS自动化了最优超参数的搜索,RepOptimizer通过结构重参化减少了推理时间。
YOLOv7(2022)[17]由Wang等人开发,通过扩展高效层聚合网络(E-ELAN)和重新参数化卷积进一步提高了效率。E-ELAN增强了特征集成和学习能力,而重新参数化卷积降低了计算开销。
YOLOv8 (2023) [18],由Ultralytics开发,引入了C2f模块、任务特定检测Head和无需 Anchor 框的检测。C2f模块增强了特征融合和梯度流,任务特定检测Head支持更专业的检测任务,无需 Anchor 框的检测消除了预定义 Anchor 框的需求,简化了检测过程。
YOLOv9 (2024) [19],由王建尧等人开发,引入了广义高效层聚合网络(GELAN)和可编程梯度信息(PGI)。GELAN提升了模型学习多样化特征的能力,而PGI有助于避免深度网络训练过程中的信息损失。
YOLOv10 (2024) [20] 由多个研究贡献者开发,强调双重标签分配、无NMS检测和端到端训练。双重标签分配增强了模型处理模糊目标实例的能力,无NMS检测降低了计算开销,端到端训练简化了训练过程。之所以表述为“多个研究贡献者”,是因为此时对于这一特定版本,尚未存在单一、普遍认可且持续获得认可的开发者或组织,与先前版本不同。
YOLOv11(2024)[21]由Glenn Jocher和Jing Qiu开发,重点关注C3K2模块、特征聚合和优化训练流程。C3K2模块增强了特征提取能力,特征聚合提升了模型整合多尺度特征的能力,优化训练流程减少了训练时间。与YOLOv10类似,开发者信息不够集中,更具协作性。
YOLOv12(2025)[27],最新迭代版本,在集成注意力机制的同时保持了实时效率。它引入了A2、残差高效层聚合网络(R-ELAN)和FlashAttention,并采用混合CNN-Transformer框架。这些创新提升了计算效率,优化了延迟-精度权衡,超越了基于CNN和基于Transformer的目标检测器。
YOLO模型的演进体现了从基于Darknet的架构[11, 12, 13, 14]向PyTorch实现的转变[15, 16, 17, 18, 19, 20, 21],以及最近向混合CNN-Transformer架构的发展[27]。每一代模型都在速度和准确性之间取得了平衡,并融合了特征提取、梯度优化和数据效率方面的进步。图1展示了YOLO架构的演进过程,突出了各版本中的关键创新。

YOLOv12的架构优化将注意力机制嵌入YOLO框架中,从而提升了计算效率并实现了高速推理。下一节将详细分析这些改进,并通过多个检测任务对YOLOv12的性能进行基准测试。
3 YOLOv12架构设计
YOLO框架通过引入一个统一的神经网络,革新了目标检测领域,该网络在一次前向传播中同时执行边界框回归和目标分类[28]。与传统的两阶段检测方法不同,YOLO采用端到端的方法,使其在实时应用中表现出极高的效率。其全微分设计允许无缝优化,从而在目标检测任务中提升了速度和准确性。
YOLOv12架构的核心由两个主要组件构成: Backbone 网络和 Head 网络。 Backbone 网络作为特征提取器,通过一系列卷积层处理输入图像,生成不同尺度的层次化特征图。这些特征捕捉了目标检测所需的必要空间和上下文信息。 Head 网络负责细化这些特征,并通过多尺度特征融合与定位生成最终预测。通过上采样、拼接和卷积操作的结合, Head 网络增强了特征表示,确保对小、中、大目标进行稳健检测。YOLOv12的 Backbone 网络和 Head 网络架构如图1所示。
3.1 主干网络:特征提取
YOLOv12的主干网络通过一系列卷积层处理输入图像,逐步降低其空间维度,同时增加特征图的深度。该过程始于一个初始卷积层,用于提取Low-Level特征,随后通过多个卷积层进行下采样以捕获层次化信息。第一阶段应用一个步长为2的卷积来生成初始特征图,接着通过另一个卷积层进一步降低空间分辨率,同时增加特征深度。
随着图像通过 Backbone 网络,它利用C3k2和A2C2F等专用模块进行多尺度特征学习。C3k2模块增强特征表示的同时保持计算效率,A2C2F模块则改进特征融合以实现更好的空间和上下文理解。 Backbone 网络继续这一过程,直至生成三个关键特征图:P3、P4和P5,每个特征图代表不同尺度的特征提取。这些特征图随后被传递给检测Head进行进一步处理。
3.2 Head :特征融合与目标检测
YOLOv12的 Head 负责融合多尺度特征并生成最终的目标检测预测。它采用了一种特征融合策略,结合 Backbone 网络不同层级的信息,以提升小、中、大目标检测的准确性。这通过一系列上采样和拼接操作实现。该过程始于最高分辨率的特征图(P5)使用最近邻插值方法进行上采样,然后与相应的低分辨率特征图(P4)进行拼接,以创建精细化的特征表示。融合后的特征通过A2C2F模块进一步处理,以增强其表达能力。
对下一个尺度进行类似的处理,通过上采样细化后的特征图并将其与低尺度特征(P3)连接。这种层次融合确保了Low-Level和High-Level特征都对最终检测做出贡献,从而提高了模型检测不同尺度物体的能力。
特征融合后,网络进行最终处理以准备进行检测。经过优化的特征再次进行下采样,并在不同层次进行融合,以增强目标表示。C3k2模块应用于最大尺度(P5/32-large),以确保保留高分辨率特征的同时降低计算成本。这些处理后的特征图随后被传递到最终的检测层,该层对不同的目标类别进行分类和定位预测。其 Backbone 网络和 Head 架构的详细分解在算法1中正式描述。

4 YOLOv12架构创新
YOLOv12引入了一种以注意力为中心的实时目标检测新方法,弥合了传统卷积神经网络与基于注意力的架构之间的性能差距。与之前主要依赖卷积神经网络以提高效率的YOLO版本不同,YOLOv12在不牺牲速度的前提下集成了注意力机制。这是通过三个关键架构改进实现的:A2模块、R-ELAN以及整体模型结构的增强,包括FlashAttention和多层感知器(MLP)中计算开销的减少。以下将详细阐述这些组件:
4.1 区域注意力模块
注意力机制的有效性传统上受到其高计算成本的阻碍,特别是在自注意力操作中与二次复杂度相关的问题 [29]。缓解这一问题的常见策略是线性注意力 [30],它通过使用更高效的转换来近似注意力交互,从而降低复杂度。然而,尽管线性注意力提高了速度,但它存在全局依赖退化 [31]、训练过程中的不稳定性 [32] 以及对输入分布变化的敏感性 [33]。此外,由于其低秩表示约束 [34, 32],它难以在高分辨率图像中保留细粒度细节,从而限制了其在目标检测中的有效性。
为解决这些局限性,YOLOv12引入了A2模块,该模块保留了自注意力机制的优势,同时显著降低了计算开销[27]。与传统全局注意力机制通过计算整个图像的交互不同,区域注意力将特征图分割成大小相等且不重叠的块,可以是水平或垂直方向。具体而言,一个维度为 的特征图被分割成 个大小为 或 的块,无需其他注意力模型(如Shifted Window[35]、Criss-Cross Attention[36]或Axial Attention[37])中可见的显式窗口分割方法。这些方法通常会增加额外的复杂性并降低计算效率,而A2通过简单的reshape操作实现分割,在保持大感受野的同时显著提升了处理速度[27]。这种方法如图2所示。

尽管A2将感受野缩小至原始尺寸的 ,但它仍然在覆盖范围和效率方面超越了传统的局部注意力方法。此外,其计算成本几乎减半,从 (传统自注意力复杂度)降至 。这种效率提升使得YOLOv12能够更有效地处理大规模图像,同时保持鲁棒的检测精度[27]。
4.2 基于残差高效层聚合网络的模型(R-ELAN)
特征聚合在提升深度学习架构中的信息流方面发挥着关键作用。之前的YOLO模型采用了高效层聚合网络(ELAN)[17],该网络通过将卷积层的输出分割成多个并行处理流,并在重新合并之前优化特征融合。然而,这种方法引入了两个主要缺点:梯度阻断和优化困难。这些问题在更深层次模型中尤为明显,输入与输出之间缺乏直接残差连接阻碍了有效的梯度传播,导致收敛缓慢或不稳定。
为应对这些挑战,YOLOv12引入了R-ELAN,这是一种新型增强技术,旨在提升训练稳定性和收敛速度。与ELAN不同,R-ELAN集成了残差快捷连接,通过一个缩放因子(默认设置为0.01)将输入直接连接到输出[27]。这确保了梯度流的平滑性,同时保持了计算效率。这些残差连接借鉴了视觉Transformer中的层缩放技术[38],但它们被专门适配于卷积架构,以防止延迟开销,这通常会影响注意力密集型模型。
- CSPNet(跨阶段部分网络):CSPNet通过将特征图分为两部分来改进梯度流并减少冗余计算,其中一部分通过一系列卷积进行处理,而另一部分保持不变,然后将其合并。这种部分连接方法在保持表征能力的同时提高了效率[39]。
- ELAN(高效层聚合网络):ELAN通过引入更深层次的特征聚合扩展了CSPNet。它在初始的卷积之后使用了多个并行卷积路径,这些路径被连接起来以丰富特征表示。然而,缺乏直接残差连接限制了梯度流,使得更深的网络更难训练[17]。
- C3k2:ELAN的改进版本,C3k2在特征聚合过程中引入了额外的变换,但仍然继承了ELAN的梯度阻塞问题。虽然它提高了结构效率,但并未完全解决深度网络面临的优化挑战[21, 19]。
- R-ELAN:与ELAN和C3k2不同,R-ELAN通过引入残差连接重构特征聚合。R-ELAN并非先分割特征图并独立处理各部分,而是提前调整通道维度,在通过 Bottleneck 层之前生成统一的特征图。
该设计通过减少冗余操作,同时确保有效的特征集成,显著提高了计算效率[27]。
在YOLOv12中引入R-ELAN带来了多项优势,包括更快的收敛速度、改进的梯度稳定性以及降低优化难度,尤其对于大尺度模型(L-和X-scale)。先前版本在标准优化器如Adam和AdamW [17] 下常面临收敛失败的问题,但R-ELAN有效缓解了这些问题,使YOLOv12在深度学习应用中更加鲁棒 [27]。
4.3 其他改进和效率提升
YOLOv12在介绍A2和R-ELAN之后,还包含了一些额外的架构改进来提升整体性能:
- • 高效卷积设计:为提升计算效率,YOLOv12策略性地保留那些具有优势的卷积层。它不使用带有层归一化(LN)的全连接层,而是采用结合批归一化(BN)的卷积操作,这更适合实时应用[27]。这使得模型能够在引入注意力机制的同时,保持类似CNN的效率。
- • 移除位置编码:与传统的基于注意力机制的架构不同,YOLOv12摒弃了显式的位置编码,而是在注意力模块中采用大核尺寸的分离卷积()[27],称为位置感知器。这确保了空间感知性,同时不增加不必要的复杂性,从而提高了效率和推理速度。
- • 优化MLP比例:传统视觉Transformer通常使用MLP扩展比例为4,这在实时设置中会导致计算效率低下。YOLOv12将MLP比例降低至1.2[27],确保 FFN 不会主导整体运行时间。这一改进有助于平衡效率与性能,避免不必要的计算开销。
- • FlashAttention集成:基于注意力机制的模型中的一个关键 Bottleneck 是内存效率低下[25, 26]。YOLOv12集成了FlashAttention,这是一种通过重构计算以更好地利用GPU高速内存(SRAM)来减少内存访问开销的优化技术。这使得YOLOv12在速度上能与CNNs相媲美,同时利用了注意力机制的优势建模能力。
5 YOLOv12基准测试评估
评估目标检测模型的性能需要对准确性和计算效率进行全面分析。YOLOv12在MS COCO 2017目标检测基准[40]上进行了评估,该基准数据集是用于评估目标检测模型的标准数据集。其性能与之前的YOLO版本以及RT-DETR和RT-DETRv2等最先进的检测模型进行了比较。评估考虑了关键指标,如平均精度均值(mAP)、推理延迟和FLOPs,为YOLOv12在实际应用中的有效性提供了见解。结果在图4中进行了可视化,并在后续章节中详细阐述,突出了YOLOv12在准确性、速度和计算效率方面的进步。

5.1 延迟与准确率
推理速度是实时目标检测应用中的关键因素,响应性至关重要。图4(a)中的结果表明,YOLOv12在保持具有竞争力的或更优延迟的同时,实现了比以往YOLO模型更高的mAP。例如,最小变体YOLOv12-N达到了40.6%mAP,超越了YOLOv10-N(38.5%)和YOLOv11-N(39.4%),在T4 GPU上的推理时间为1.64 ms。较大的YOLOv12-X模型实现了55.2%mAP,比其前身YOLOv11-X提高了0.6%,展示了模型改进在准确性和计算效率方面的有效性。这种跨模型尺寸的持续改进突显了YOLOv12架构和优化策略的有效性。
值得注意的是,YOLOv12在推理速度方面始终优于RT-DETR模型。YOLOv12-S的运行速度比RT-DETR-R18/RT-DETRv2-R18快约42%,同时仅使用36%的计算量和45%的参数。具体而言,YOLOv12-S的延迟为2.61毫秒,而RT-DETR-R18/RT-DETRv2-R18的延迟为4.58毫秒,这凸显了YOLOv12在降低延迟的同时保持或提升检测精度的效率。这些改进表明YOLOv12非常适合对时间敏感的应用,如自动驾驶、监控和机器人技术,在这些领域快速处理至关重要。
5.2 FLOPs 与准确率
一个关键的观察是YOLOv12在不同模型尺寸上表现出高效的扩展性。虽然增加FLOPs通常会导致更高的精度,但YOLOv12始终在相同或更少FLOPs的情况下优于先前模型,这进一步证实了其架构优化的优势。例如,YOLOv12-L实现了53.7%mAP,使用了88.9 GFLOPs,而YOLOv11-L实现了53.3%mAP,使用了86.9 GFLOPs。这一趋势表明,即使在计算约束下,YOLOv12也能保持高效率,使其适合部署在资源受限的硬件上,如边缘设备和移动平台,其中功耗效率是首要考虑因素。
5.3 速度比较和硬件利用率
YOLOv12在推理速度和硬件利用方面的效率提升在多个平台上都十分明显。表2提供了在RTX 3080、RTX A500和RTX A6000 GPU上,以FP32和FP16精度进行推理延迟的比较分析,将YOLOv12与YOLOv9 [19]、YOLOv10 [20]和YOLOv11 [21]进行了基准测试。为确保一致性,所有实验均在相同的硬件上进行。此外,YOLOv9和YOLOv10使用Ultralytics代码库 [41]进行了评估。

实验结果突出表明,YOLOv12在推理速度上显著优于YOLOv9,同时保持了与YOLOv10和YOLOv11相当的效率。值得注意的是,在RTX 3080 GPU上,YOLOv12-N的推理时间为1.7毫秒(FP32)和1.1毫秒(FP16),相较于YOLOv9的2.4毫秒(FP32)和1.5毫秒(FP16)实现了提升。此外,在NVIDIA T4 GPU上,YOLOv12-S的推理延迟为2.61毫秒,进一步巩固了其在同类实时目标检测模型中最快之一的地位。这种效率水平确保了YOLOv12适用于对延迟敏感的应用场景。
除了GPU基准测试之外,图5还提供了关于准确率、模型参数和CPU延迟之间权衡的额外比较见解。图5(a)展示了准确率-参数的权衡关系,其中YOLOv12建立了一个主导边界,超越了之前的YOLO版本,包括YOLOv10,其架构更为紧凑。图5(b)展示了在CPU上的准确率-延迟性能,其中YOLOv12实现了更高的效率,在Intel Core i7-10700K@ 3.80 GHz 上评估时超越了其前身。

这些改进通过集成FlashAttention得到进一步促进,FlashAttention优化了GPU内存访问(SRAM利用率)并减少了内存开销,从而实现了更高的吞吐量和更低的内存消耗。通过解决内存访问 Bottleneck ,YOLOv12能够进行更大批量的处理,并高效地处理高分辨率视频流,使其特别适用于需要即时反馈的实时应用,例如增强现实、交互式机器人和自主系统。
YOLO12支持的关键计算机视觉任务
6.1 实时目标检测
YOLO系列始终以实时目标检测为优先,通过每次迭代提升了速度与准确性的平衡。YOLOv1引入了单次检测的基本概念[11],使模型能够通过单次评估直接从完整图像中预测边界框和类别概率。虽然其速度具有突破性,但其准确性因定位误差而受损。YOLOv2通过引入批量归一化、 Anchor 框和多尺度训练改进了这一点,显著提升了精度和召回率[12]。
后续版本如YOLOv3[13]和YOLOv4[14]引入了 Anchor 框(anchor boxes)和特征金字塔网络(feature pyramid networks)以增强检测能力。随后的模型包括YOLOv5和YOLOv6,在保持卷积架构基础的同时进行了优化以提高效率。值得注意的是,YOLOv6引入了BiC和SimCSPSPPF模块[16],进一步提升了速度和精度。YOLOv7和YOLOv8通过集成E-ELAN和C2f模块[17, 18]进一步优化了框架,以实现更强大的特征提取能力。
YOLOv9引入了GELAN进行架构优化和PGI进行训练改进[19],实现了更好的梯度流并增强了对抗小目标检测的鲁棒性。YOLOv10和YOLOv11转向减少延迟和提升检测效率,其中YOLOv11引入了C3K2模块和轻量级深度可分离卷积来加速检测[42]。
沿着这一轨迹,YOLOv12通过集成注意力机制[27]在实时性能上达到了或超越了其前代模型,此前认为这种机制对于此类应用来说过于缓慢。FlashAttention的引入解决了内存 Bottleneck 问题,使得注意力过程与传统卷积方法一样迅速,同时提高了检测精度。值得注意的是,YOLOv12-N实现了40.6%的mAP,推理延迟为1.64毫秒,在精度和速度两方面均优于YOLOv10-N和YOLOv11-N。
6.2 物体定位
目标定位一直是YOLO模型的核心,每个版本都在不断优化其边界框回归能力。YOLOv1最初将目标检测表述为回归问题[11],直接从图像中预测边界框,而不依赖区域 Proposal 。然而,它缺乏基于 Anchor 点的机制,导致定位精度不一致。YOLOv2引入了 Anchor 框和高分辨率分类器,提升了定位精度[12]。
YOLOv3和YOLOv4采用基于 Anchor 框的检测方法,虽然有效,但由于预定义的 Anchor 框尺寸,偶尔会导致边界框不准确[13, 14]。YOLOv5和YOLOv6转向 Anchor-Free 框方法和双层特征融合,提高了定位精度[15, 16]。YOLOv7和YOLOv8在动态标签分配[17]和增强损失函数[18]等方面的进一步优化,延续了这一趋势。YOLOv9通过改进特征聚合策略并引入更先进的分配策略来减少错位,从而提升了定位精度[19]。
YOLOv10和YOLOv11通过引入C3K2模块和无非极大值抑制(NMS-free)训练改进了检测Head,优化了边界框预测[20, 21]。YOLOv12[27]通过引入A2提升了目标定位能力,A2能够捕获更广泛的感受野,从而实现更精确的定位。FlashAttention的应用降低了内存开销,进一步提高了边界框回归的精度,因此在保持快速推理速度的同时,在定位精度上超越了前代版本。
6.3 多尺度目标检测
在相同图像中检测不同尺寸的物体一直是YOLO系列的研究重点。YOLOv1和YOLOv2由于多尺度特征提取能力有限,在小目标检测方面存在困难[11,12]。YOLOv4引入了FPN[14]以促进多尺度检测。YOLOv5和YOLOv6通过CSPNet[43]和SimCSPSPPF[16]等改进优化了不同尺度的性能。YOLOv7和YOLOv8引入了C2f模块以提升特征提取能力,增强了多尺度检测性能[17,18]。
YOLOv9引入了GELAN,通过优化不同分辨率下的空间特征进一步提升了多尺度检测能力[19]。YOLOv10和YOLOv11则专注于加速特征聚合并采用轻量级检测Head,从而提升了性能,尤其对于小目标[20, 21]。
YOLOv12通过集成A2 [27]提升了多尺度目标检测能力,A2能够在无需复杂窗口划分的情况下保持较大的感受野,同时保留了检测速度。性能指标表明,YOLOv12-N在小型目标上实现了20.2%的mAP,在中型目标上实现了45.2%的mAP,在大型目标上实现了58.4%的mAP,在所有尺度上均优于先前模型。
6.4 优化特征提取
有效的特征提取是目标检测的基础,而每一次YOLO的迭代都致力于提升这一过程。YOLOv1依赖于全连接层,这限制了其对未见过的物体尺度的泛化能力[11]。YOLOv2将这些层替换为更深层的卷积层和批量归一化,从而提高了效率[12]。YOLOv3和YOLOv4则采用了基于Darknet的 Backbone 网络,尽管这些网络功能强大,但计算量较大[13, 14]。
YOLOv5和YOLOv6引入了CSPNet[15]和SimCSPSPPF[16]以优化特征学习并减少冗余。YOLOv7和YOLOv8中E-ELAN和C2f模块的实现使特征提取更加高效[17, 18]。YOLOv9引入了GELAN,进一步优化了梯度流,并允许更好地利用特征图[19]。
YOLOv10和YOLOv11通过引入C3K2模块和轻量级卷积进一步优化了特征流[20, 21]。YOLOv12引入了R-ELAN[27],增强了梯度流和特征融合。FlashAttention的应用解决了内存效率问题,实现了更快更有效的特征提取。这些创新最终在速度和精度之间取得了卓越的平衡,将YOLOv12置于实时检测性能的前沿。
6.5 实例分割
YOLO系列中实例分割的演进体现了从基于网格的简单检测向高质量、像素级目标轮廓划分的转变,同时保持了实时性能。
早期的模型YOLOv1、YOLOv2和YOLOv3专门设计用于边界框检测,缺乏分割能力[11, 12, 13]。YOLOv5的引入带来了重大进展,通过整合轻量级的全卷积ProtoNet实现了实例分割[15]。这使得能够生成原型 Mask ,并与检测输出结合,在保持高速性能的同时生成像素级精确的分割 Mask 。
YOLOv6专注于架构改进,如RepVGG和CSPStackRep模块,通过不直接添加分割分支来增强特征提取[16]。YOLOv7引入了专门的分割变体(YOLOv7-Seg),在保持实时效率的同时生成高质量 Mask [17]。YOLOv8通过 Anchor-Free 点分割头和改进的 Backbone 网络进一步优化分割,实现了更高的精度和鲁棒的分割 Mask [18]。YOLOv10引入了自适应 Mask 分辨率、特征对齐模块以减少 Mask 框错位,以及选择性Transformer元素以捕获长距离依赖关系[20]。这些改进显著提升了分割质量,同时保持了计算效率。YOLOv11通过交叉阶段部分与空间注意力(C2PSA)模块进一步优化分割,提高了在杂乱环境中对相关区域的关注[42]。
虽然YOLOv12没有引入专门的实例分割框架,但某些架构增强措施——例如改进的注意力机制以及通过R-ELAN进行特征聚合——可能有助于更有效地区分物体边界[27]。FlashAttention通过减少内存开销,也可能有助于更精细的物体感知。然而,由于缺乏具体的基准测试或关于YOLOv12分割性能的明确文档,其在该领域的优势仍属于探索性而非已确认的改进。
7 讨论
YOLOv12在目标检测领域实现了重大进步,它基于YOLOv11的坚实基础,同时融入了前沿的架构增强。该模型在准确性、速度和计算效率之间取得了精妙的平衡,使其成为适用于不同领域实时计算机视觉应用的理想解决方案。
7.1 模型效率与部署
YOLOv12引入了多种模型尺寸,从纳米(12n)到超大型(12x),支持在多种硬件平台上部署。这种可扩展性确保YOLOv12能够在资源受限的边缘设备和高性能GPU上高效运行,在保持高精度的同时优化推理速度。纳米和小型变体显著降低了延迟,同时保留了检测精度,使其成为自动驾驶导航[44, 45]、机器人[5]和智能监控[46, 47, 48]等实时应用的理想选择。
7.2 架构创新与计算效率
YOLOv12引入了多项关键架构改进,提升了特征提取和处理效率。R-ELAN优化了特征融合和梯度传播,使得网络结构能够更深且更高效。此外,引入分离卷积减少了参数数量,同时保持空间一致性,从而在极低的计算开销下提升了特征提取能力。
YOLOv12中的一项突出优化是采用FlashAttention驱动的基于区域的注意力机制,该机制在提升检测精度的同时降低了内存开销。这使得YOLOv12能够更精确地定位目标,特别是在杂乱或动态环境中,而无需牺牲推理速度。这些架构改进共同提升了mAP,同时保持了实时处理效率,使该模型在需要低延迟目标检测的应用中表现出色。
7.3 性能提升与硬件适应性
基准测试评估证实,YOLOv12在准确性和效率方面均优于之前的YOLO版本。YOLOv12m变体在参数数量减少25%的情况下,实现了与YOLOv11x相当或更优的mAP,展现了显著的计算效率提升。此外,YOLOv12s等小型变体具有更低的推理延迟,适用于边缘计算和嵌入式视觉应用[49]。
从硬件部署角度来看,YOLOv12具有高度可扩展性,表现出与高性能GPU和低功耗AI加速器的兼容性。其优化的模型变体允许在自动驾驶、工业自动化、安防监控和其他实时应用中进行灵活部署[50,51,52]。该模型的内存高效利用和低计算开销使其成为资源约束严格环境中的实用选择。
7.4 更广泛的影响和意义
YOLOv12中引入的创新具有广泛的多行业影响。其以较低的运算开销实现高精度目标检测的能力,使其在自主导航、安全和实时监控系统等领域尤为珍贵。此外,该模型的微小目标检测[53]改进增强了其在医学影像和农业监测中的实用性,在这些领域,检测细粒度视觉细节至关重要。
此外,YOLOv12的高效处理流程确保了其在云端、边缘和嵌入式AI系统中的无缝部署,进一步巩固了其作为领先实时检测框架的地位。随着对高速、高精度视觉模型的需求不断增长,YOLOv12在可扩展和高效的目标检测技术方面树立了新的标杆。
8 挑战与未来研究方向
尽管YOLOv12在架构和效率方面取得了显著进步,但仍存在若干挑战,亟待深入研究。解决这些局限性对于优化其在实际应用中的部署,并拓展YOLOv12在标准目标检测之外的能力至关重要。
8.1 硬件约束和边缘设备的部署
YOLOv12集成了注意力机制和FlashAttention以提升准确率,但这些增强带来了更高的计算需求。尽管该模型在高端GPU上实现了实时性能,但在低功耗边缘设备如移动处理器、嵌入式系统和物联网设备上部署它仍然是一个挑战[54]。
一个关键限制是内存 Bottleneck 。基于注意力机制的架构由于需要大量特征图和矩阵乘法,导致VRAM使用量较高。这使得在资源受限的设备上高效运行YOLOv12变得困难,例如NVIDIA Jetson Nano、树莓派和基于ARM的微控制器[55]。通过模型压缩技术如低秩分解[56]和权重剪枝[57]优化内存占用,可以帮助缓解这一问题。
另一个挑战是推理延迟。虽然YOLOv12相比于完整的Vision Transformer [22, 23]减少了注意力开销,但在边缘硬件上仍落后于纯基于CNN的YOLO版本。结构化剪枝、知识蒸馏和量化(例如int8)等策略能够提升嵌入式AI加速器上的实时性能 [58]。
此外,未来的研究可以探索针对硬件的特定优化,以提升YOLOv12在不同平台上的效率。诸如层级优化[59]、高效卷积核[60]以及FPGA/DSP实现等技术,可以使模型更适应低功耗设备[61]。
8.2 训练复杂性与数据集依赖性
YOLOv12的准确率提升是以增加训练复杂度和更高数据集依赖为代价的。与早期为轻量级训练优化的YOLO模型不同,YOLOv12引入了注意力机制和更深层次的特征聚合,这导致计算需求更高。
一个主要的挑战是训练成本。基于注意力的模块需要显著更多的FLOPs和内存带宽,导致训练成本高昂,尤其对于GPU资源有限的科研行人而言。注意力权重的低秩分解、梯度预训练权重和高效的损失函数等技术有助于降低计算开销[62]。
另一个问题是数据效率。YOLOv12的优越精度很大程度上归功于在MS COCO和OpenImages等大规模数据集上进行训练。然而,在许多实际应用中,例如医学影像[63]和工业缺陷检测[28],数据集通常规模较小或分布不平衡。探索自监督学习、半监督训练。
领域自适应技术[64, 65, 66]能够提升YOLOv12在低数据环境下的性能。
此外,超参数敏感性仍然是一个挑战。YOLOv12需要对学习率、注意力头数和 Anchor 框大小等参数进行大量调整,这可能会带来较高的计算成本。未来的研究可以探索使用NAS等技术[67]进行自动化超参数调整,以提高可用性和效率。
8.3 超越目标检测的扩展
YOLOv12主要用于2D目标检测,而许多新兴应用需要超越简单边界框的更High-Level场景理解。将YOLOv12扩展到3D目标检测、实例分割和全景分割可能开辟新的研究机会。
在3D目标检测方面,自动驾驶[3]和机器人[68]等应用需要能够预测深度感知3D边界框的模型。当前的基于Transformer的模型如DETR3D和BEVFormer利用多视角输入和激光雷达融合[69]。将YOLOv12扩展以处理立体图像或激光雷达数据,可以使它适用于3D感知任务。
以实例分割为例,YOLOv12缺少专门的分割头。现有的解决方案如YOLACT和SOLOv2通过集成轻量级 Mask 分支实现实时实例分割[70]。YOLO的未来迭代可以引入并行分割分支以提升像素级目标界定能力。
此外,全景分割[71],它结合了实例分割和语义分割,已成为计算机视觉中的一个日益增长的研究领域。尽管当前的YOLO模型不支持这项任务,但在保持YOLO效率的同时集成基于transformer的分割头,将能够实现一个统一的目标检测和分割框架。
9 结论
在本综述中,作者对YOLOv12进行了深入分析,它是实时目标检测器YOLO家族的最新演进。通过集成A2模块、R-ELAN和FlashAttention等创新技术,YOLOv12有效平衡了准确性与推理速度之间的权衡。这些改进不仅解决了早期YOLO版本和传统卷积方法中固有的局限性,还拓展了实时目标检测所能达到的边界。
作者追溯了YOLO架构的技术演进,并详细阐述了YOLOv12中的结构优化,包括其优化的 Backbone 网络和检测Head。全面的基准测试评估表明,YOLOv12在多个指标上实现了卓越性能,包括延迟、准确性和计算效率,使其既适合高性能GPU,也适合资源受限的设备。
尽管YOLOv12标志着显著的进步,但作者的综述也指出了几个仍然存在的挑战,例如边缘部署的硬件限制和训练复杂性。总体而言,YOLOv12在实时目标检测方面迈出了重要一步,结合了卷积和基于注意力方法的优势。其可扩展的设计和增强的效率不仅适用于广泛的应用,还为计算机视觉领域的进一步创新铺平了道路。
参考
[1]. A REVIEW OF YOLOV12: ATTENTION-BASED ENHANCEMENTS VS. PREVIOUS VERSIONS
3.1、YOLOv12智能交通分析
项目目的
在大城市,监控交通流量并立即检测违规行为有助于减少交通事故并优化城市交通。该项目旨在:
- 检测紧急车道违规并识别阻碍紧急车辆的车辆。
- 分析基于车道的交通流速和拥堵情况,以确定交通状况。
- 对车辆进行计数并对类型进行分类,以提供有关不同车辆类型的数据。
该系统可以集成到智能城市管理中,有助于创建公平高效的交通系统。
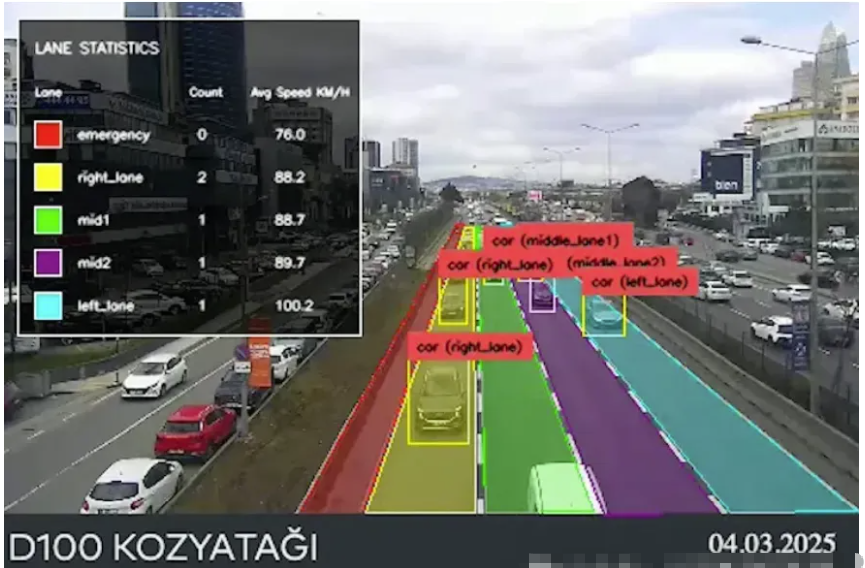
import json
import cv2
import numpy as np
import supervision as sv
from ultralytics import YOLO
from collections import defaultdict
from typing import Dict, List, Optional, Set, Tuple, Iterable
import argparse
from tqdm import tqdm
####################################
# 1) CONSTANTS AND CONFIG
####################################
JSON_PATH = "/Users/bahakizil/Desktop/firedetection/polygons.json"
VIDEO_INPUT = "/Users/bahakizil/Desktop/firedetection/emniyett.mp4"
VIDEO_OUTPUT = "output_lane_detection.mp4"
MODEL_PATH = "/Users/bahakizil/Desktop/firedetection/best.pt"
# Define the detection region (from the polygon.json data)
DETECTION_REGION = {
"x": 340,
"y": 220,
"width": 340,
"height": 180
}
# Define colors
try:
# Using ColorPalette if available
COLORS = sv.ColorPalette.from_hex([
"#FF0000", # Red for emniyet_seridi
"#FFFF00", # Yellow for sag_serit
"#00FF00", # Green for orta_serit1
"#800080", # Purple for orta_serit2
"#00FFFF", # Cyan for sol_serit
"#FFFFFF" # White for generic
])
except:
# Fallback to BGR colors
COLORS = {
"emniyet_seridi": (0, 0, 255), # Red in BGR
"sag_serit": (0, 255, 255), # Yellow in BGR
"orta_serit1": (0, 255, 0), # Green in BGR
"orta_serit2": (128, 0, 128), # Purple in BGR
"sol_serit": (255, 255, 0), # Cyan in BGR
"yol": (255, 255, 255) # White in BGR
}
####################################
# 2) LANE DETECTOR CLASS
####################################
class LaneDetector:
def __init__(self) -> None:
# Load polygons from JSON
self.lane_polygons = {}
self.lane_names = []
self.detection_zone = None # Will store the detection zone polygon
self.vehicle_counts = defaultdict(int) # Counter for vehicles in each lane
self.road_names_box = None # Will store the polygon for road names (id 7)
# Add tracking for vehicle speeds in each lane
self.lane_speeds = defaultdict(list) # Store speeds of vehicles in each lane
self.lane_average_speeds = defaultdict(float) # Store average speed for each lane
self.load_polygons()
def load_polygons(self) -> None:
try:
with open(JSON_PATH, "r") as f:
data = json.load(f)
except FileNotFoundError:
raise FileNotFoundError(f"JSON file not found: {JSON_PATH}")
boxes = data.get("boxes", [])
if not boxes:
raise ValueError("No 'boxes' found in JSON or empty.")
# Get original dimensions
original_width = data.get("width", 504)
original_height = data.get("height", 354)
# Get video dimensions for scaling
cap = cv2.VideoCapture(VIDEO_INPUT)
width = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH))
height = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
cap.release()
# Calculate scaling factors
scale_x = width / original_width
scale_y = height / original_height
# Create a list of all points for the combined detection zone
all_points = []
# Translate lane names
translated_lane_names = {
"emniyet_seridi": "emergency_lane",
"sag_serit": "right_lane",
"orta_serit1": "middle_lane1",
"orta_serit2": "middle_lane2",
"orta_seri2": "middle_lane2", # Fix potential typo
"sol_serit": "left_lane",
"yol": "road"
}
# Process each box/polygon
for box in boxes:
label = box.get("label", "unknown")
box_id = box.get("id", "")
# Translate the label to English if it exists in our dictionary
if label in translated_lane_names:
label = translated_lane_names[label]
# Debug output for box ID 7
if (box_id == "7"):
print(f"Found box ID 7 with label: {label}")
if "points" in box:
print(f"Points: {box['points']}")
# Handle different formats of polygons in the JSON
if "points" in box:
# Polygon with points
points = box["points"]
# Scale points
scaled_pts = []
for point in points:
if isinstance(point, list) and len(point) == 2:
px, py = point
sx = px * scale_x
sy = py * scale_y
scaled_pts.append([sx, sy])
all_points.append([sx, sy]) # Collect all points for detection zone
# Check if this is the road names box (id 7)
if box_id == "7":
if scaled_pts:
self.road_names_box = np.array(scaled_pts, dtype=np.int32)
print(f"Box ID 7 scaled points: {scaled_pts}")
continue # Skip adding this to lane_polygons
# Only store valid polygons
if scaled_pts:
# For new format, ensure we handle duplicate labels properly
if label in self.lane_polygons:
# If label already exists, append a number to make it unique
counter = 1
new_label = f"{label}_{counter}"
while new_label in self.lane_polygons:
counter += 1
new_label = f"{label}_{counter}"
label = new_label
self.lane_polygons[label] = np.array(scaled_pts, dtype=np.int32)
if label not in self.lane_names: # Avoid duplicates
self.lane_names.append(label)
elif all(k in box for k in ["x", "y", "width", "height"]):
# Rectangle format (x, y, width, height)
x = float(box["x"]) * scale_x
y = float(box["y"]) * scale_y
w = float(box["width"]) * scale_x
h = float(box["height"]) * scale_y
# Create a rectangle polygon
rect_points = [
[x, y], # top-left
[x + w, y], # top-right
[x + w, y + h], # bottom-right
[x, y + h] # bottom-left
]
# Check if this is the road names box (id 7)
if box_id == "7":
self.road_names_box = np.array(rect_points, dtype=np.int32)
continue # Skip adding this to lane_polygons
# For new format, ensure we handle duplicate labels properly
if label in self.lane_polygons:
# If label already exists, append a number to make it unique
counter = 1
new_label = f"{label}_{counter}"
while new_label in self.lane_polygons:
counter += 1
new_label = f"{label}_{counter}"
label = new_label
self.lane_polygons[label] = np.array(rect_points, dtype=np.int32)
if label not in self.lane_names: # Avoid duplicates
self.lane_names.append(label)
# Add these points to all_points for detection zone
all_points.extend(rect_points)
# Create detection zone
# If there's a polygon labeled "emniyet_seridi" with id="6", use it as the detection zone
detection_zone_found = False
for box in boxes:
original_label = box.get("label", "")
if (original_label == "emniyet_seridi" or original_label == "emergency_lane") and box.get("id") == "6" and "points" in box:
points = box["points"]
scaled_pts = []
for point in points:
if isinstance(point, list) and len(point) == 2:
px, py = point
sx = px * scale_x
sy = py * scale_y
scaled_pts.append([sx, sy])
if scaled_pts:
self.detection_zone = np.array(scaled_pts, dtype=np.int32)
detection_zone_found = True
break
# If no specific detection zone was found, create one from all lane polygons
if not detection_zone_found:
if "road" not in self.lane_polygons:
# Use the DETECTION_REGION values if no polygons were loaded
if not all_points:
x = DETECTION_REGION["x"] * scale_x
y = DETECTION_REGION["y"] * scale_y
w = DETECTION_REGION["width"] * scale_x
h = DETECTION_REGION["height"] * scale_y
self.detection_zone = np.array([
[x, y], # top-left
[x + w, y], # top-right
[x + w, y + h], # bottom-right
[x, y + h] # bottom-left
], dtype=np.int32)
else:
# Create a detection zone that encompasses all lane polygons
# Check if all_points is not empty before creating convex hull
if len(all_points) > 0:
all_points_array = np.array(all_points, dtype=np.int32)
hull = cv2.convexHull(all_points_array)
self.detection_zone = hull
else:
# Fallback if no points were processed
self.detection_zone = np.array([
[0, 0],
[width, 0],
[width, height],
[0, height]
], dtype=np.int32)
else:
self.detection_zone = self.lane_polygons["road"]
print(f"Loaded {len(self.lane_polygons)} polygons: {', '.join(self.lane_names)}")
if self.road_names_box is not None:
print("Found road names box (id 7)")
def determine_lane(self, point):
"""Determine which lane a point is in"""
for lane_name, polygon in self.lane_polygons.items():
if self.is_point_in_polygon(point, polygon):
return lane_name
return "unknown"
def is_point_in_polygon(self, point, polygon):
"""Check if a point is inside a polygon using OpenCV"""
return cv2.pointPolygonTest(polygon, point, False) >= 0
def is_in_detection_zone(self, bbox):
"""Check if the center of a bounding box is within the detection zone"""
x1, y1, x2, y2 = bbox
center = ((x1 + x2) / 2, (y1 + y2) / 2)
return self.is_point_in_polygon(center, self.detection_zone)
def count_vehicle(self, lane_name):
"""Increment the count for a vehicle in a lane"""
self.vehicle_counts[lane_name] += 1
def reset_counts(self):
"""Reset all lane counts to zero"""
self.vehicle_counts = defaultdict(int)
def add_vehicle_speed(self, lane_name, speed):
"""Add a vehicle speed to the lane's speed list"""
self.lane_speeds[lane_name].append(speed)
# Update the average speed for this lane
self.update_average_speed(lane_name)
def update_average_speed(self, lane_name):
"""Update the average speed for a lane"""
if self.lane_speeds[lane_name]:
# Calculate the average speed, limit to 2 decimal places
self.lane_average_speeds[lane_name] = round(
sum(self.lane_speeds[lane_name]) / len(self.lane_speeds[lane_name]),
2
)
def reset_speeds(self):
"""Reset all lane speed tracking data"""
self.lane_speeds = defaultdict(list)
self.lane_average_speeds = defaultdict(float)
####################################
# 3) TRAFFIC FLOW MANAGER
####################################
class DetectionsManager:
def __init__(self) -> None:
self.tracker_id_to_zone_id: Dict[int, int] = {}
self.counts: Dict[int, Dict[int, Set[int]]] = {}
def update(
self,
detections_all: sv.Detections,
detections_in_zones: List[sv.Detections],
detections_out_zones: List[sv.Detections],
) -> sv.Detections:
for zone_in_id, detections_in_zone in enumerate(detections_in_zones):
for tracker_id in detections_in_zone.tracker_id:
self.tracker_id_to_zone_id.setdefault(tracker_id, zone_in_id)
for zone_out_id, detections_out_zone in enumerate(detections_out_zones):
for tracker_id in detections_out_zone.tracker_id:
if tracker_id in self.tracker_id_to_zone_id:
zone_in_id = self.tracker_id_to_zone_id[tracker_id]
self.counts.setdefault(zone_out_id, {})
self.counts[zone_out_id].setdefault(zone_in_id, set())
self.counts[zone_out_id][zone_in_id].add(tracker_id)
if len(detections_all) > 0:
detections_all.class_id = np.vectorize(
lambda x: self.tracker_id_to_zone_id.get(x, -1)
)(detections_all.tracker_id)
else:
detections_all.class_id = np.array([], dtype=int)
return detections_all[detections_all.class_id != -1]
def initiate_polygon_zones(
polygons: List[np.ndarray],
triggering_anchors: Iterable[sv.Position] = [sv.Position.CENTER],
) -> List[sv.PolygonZone]:
return [
sv.PolygonZone(
polygnotallow=polygon,
triggering_anchors=triggering_anchors,
)
for polygon in polygons
]
####################################
# 4) VIDEO PROCESSOR CLASS
####################################
# Add traffic flow zone definitions (adjust these coordinates to match your road layout)
ZONE_IN_POLYGONS = [
# Example zones - adjust these for your specific video
np.array([[100, 300], [200, 300], [200, 200], [100, 200]]), # Left entry
]
ZONE_OUT_POLYGONS = [
# Example zones - adjust these for your specific video
np.array([[100, 100], [200, 100], [200, 50], [100, 50]]), # Left exit (Exit 1)
]
class LaneVehicleProcessor:
def __init__(
self,
source_weights_path: str,
source_video_path: str,
target_video_path: Optional[str] = None,
confidence_threshold: float = 0.1,
iou_threshold: float = 0.7,
):
# Initialize detector
self.lane_detector = LaneDetector()
# Configuration
self.conf_threshold = confidence_threshold
self.iou_threshold = iou_threshold
self.source_video_path = source_video_path
self.target_video_path = target_video_path
# Get video info
self.video_info = sv.VideoInfo.from_video_path(source_video_path)
# Load YOLO model
self.model = YOLO(source_weights_path)
# Initialize tracker
self.tracker = sv.ByteTrack()
# Initialize zones
self.zone_in_polygons = []
self.zone_out_polygons = []
# Initialize annotators with thinner font settings
self.box_annotator = sv.BoxAnnotator(color=COLORS, thickness=1)
self.label_annotator = sv.LabelAnnotator(
text_color=sv.Color.WHITE,
text_padding=5,
text_thickness=1
)
self.trace_annotator = sv.TraceAnnotator(
color=COLORS,
positinotallow=sv.Position.CENTER,
trace_length=10,
thickness=1
)
# Expanded vehicle labels to detect - include all possible vehicle types
self.vehicle_labels = {
"car", "motorcycle", "bus", "truck", "bicycle",
"train", "boat", "airplane", "van", "scooter",
"vehicle", "motorbike", "lorry", "pickup", "suv",
"minivan", "trailer", "tractor", "ambulance", "taxi",
"police", "firetruck", "garbage truck", "limousine"
}
# Silently process class information without printing to terminal
if isinstance(self.model.names, dict):
available_classes = set(self.model.names.values())
# Filter vehicle_labels to only those present in model
self.vehicle_labels = self.vehicle_labels.intersection(available_classes)
self.vehicle_class_ids = [idx for idx, name in self.model.names.items()
if name in self.vehicle_labels]
else:
available_classes = set(self.model.names)
# Filter vehicle_labels to only those present in model
self.vehicle_labels = self.vehicle_labels.intersection(available_classes)
self.vehicle_class_ids = [idx for idx, name in enumerate(self.model.names)
if name in self.vehicle_labels]
# Initialize traffic flow zones
self.zones_in = initiate_polygon_zones(ZONE_IN_POLYGONS, [sv.Position.CENTER])
self.zones_out = initiate_polygon_zones(ZONE_OUT_POLYGONS, [sv.Position.CENTER])
self.detections_manager = DetectionsManager()
def process_video(self, display_while_saving: bool = True, target_fps: int = 30):
# Get frame generator
frame_generator = sv.get_video_frames_generator(
source_path=self.source_video_path
)
# Ensure target path has .mp4 extension
if self.target_video_path and not self.target_video_path.lower().endswith('.mp4'):
self.target_video_path = self.target_video_path + '.mp4'
print(f"Adding .mp4 extension to target path: {self.target_video_path}")
with sv.VideoSink(self.target_video_path, self.video_info) as sink:
total_frames = self.video_info.total_frames
# Get original video frame rate
source_fps = self.video_info.fps
# Calculate frame skip factor based on source and target fps
skip_factor = max(1, int(source_fps / target_fps))
print(f"Source video: {source_fps} fps")
print(f"Target playback: {target_fps} fps")
print(f"Processing every {skip_factor} frame(s)")
# Create progress bar
pbar = tqdm(total=total_frames, desc="Processing video")
frame_count = 0
for frame in frame_generator:
# Process only every skip_factor frame
if frame_count % skip_factor == 0:
annotated_frame = self.process_frame(frame)
# Write the visualized frame
sink.write_frame(annotated_frame)
# Display frame while processing if requested
if display_while_saving:
cv2.imshow("Lane Detection", annotated_frame)
if cv2.waitKey(1) & 0xFF == ord("q"):
break
# Update progress bar for every frame
pbar.update(1)
frame_count += 1
# Close progress bar
pbar.close()
print(f"Video processing complete! Saved to: {self.target_video_path}")
print(f"Processed {frame_count // skip_factor} frames out of {frame_count} total frames")
# Close window automatically after video is done
cv2.destroyAllWindows()
def process_frame(self, frame: np.ndarray) -> np.ndarray:
# Reset lane counts for this frame
self.lane_detector.reset_counts()
# Use standard YOLO detection
results = self.model(
frame, verbose=False, cnotallow=self.conf_threshold, iou=self.iou_threshold
)[0]
detections = sv.Detections.from_ultralytics(results)
# Filter by vehicle class
if len(detections) > 0:
class_ids = detections.class_id
mask = np.isin(class_ids, self.vehicle_class_ids)
detections = detections[mask]
# Filter detections by detection zone
if len(detections) > 0:
in_zone = [
self.lane_detector.is_in_detection_zone(bbox)
for bbox in detections.xyxy
]
detections = detections[in_zone]
# Track vehicles
detections = self.tracker.update_with_detections(detections)
# Create copy of original detections before zone processing
# Fix: manually create a copy since Detections has no copy() method
if len(detections) > 0:
original_detections = sv.Detections(
xyxy=detections.xyxy.copy(),
cnotallow=detections.confidence.copy() if detections.confidence is not None else None,
class_id=detections.class_id.copy() if detections.class_id is not None else None,
tracker_id=detections.tracker_id.copy() if detections.tracker_id is not None else None
)
else:
original_detections = sv.Detections.empty()
# Process zone detections for traffic flow analysis
detections_in_zones = []
detections_out_zones = []
# Check which detections are in entry and exit zones
for zone_in, zone_out in zip(self.zones_in, self.zones_out):
detections_in_zone = detections[zone_in.trigger(detectinotallow=detections)]
detections_in_zones.append(detections_in_zone)
detections_out_zone = detections[zone_out.trigger(detectinotallow=detections)]
detections_out_zones.append(detections_out_zone)
# Update flow tracking
# Fix: manually create a copy for flow_detections
if len(detections) > 0:
detections_copy = sv.Detections(
xyxy=detections.xyxy.copy(),
cnotallow=detections.confidence.copy() if detections.confidence is not None else None,
class_id=detections.class_id.copy() if detections.class_id is not None else None,
tracker_id=detections.tracker_id.copy() if detections.tracker_id is not None else None
)
flow_detections = self.detections_manager.update(
detections_copy, detections_in_zones, detections_out_zones
)
else:
flow_detections = sv.Detections.empty()
# Generate simplified labels and count vehicles per lane
labels = []
vehicle_count_by_lane = defaultdict(int)
# Generate consistent vehicle speeds based on tracker ID
# This ensures each vehicle maintains the same speed across frames
vehicle_speeds = {}
if len(original_detections) > 0:
for i, tracker_id in enumerate(original_detections.tracker_id):
class_id = int(original_detections.class_id[i])
# FIX: Validate class_id before accessing model.names
if isinstance(self.model.names, dict):
# Dictionary-style model.names (common in YOLO)
if class_id in self.model.names:
class_name = self.model.names[class_id]
else:
class_name = f"unknown_{class_id}"
else:
# List-style model.names
if 0 <= class_id < len(self.model.names):
class_name = self.model.names[class_id]
else:
class_name = f"unknown_{class_id}"
label = f"{class_name}" # Simplified to just show class name
# Count vehicles in each lane
x1, y1, x2, y2 = map(float, original_detections.xyxy[i])
center = ((x1 + x2) / 2, (y1 + y2) / 2)
lane_name = self.lane_detector.determine_lane(center)
self.lane_detector.count_vehicle(lane_name)
vehicle_count_by_lane[lane_name] += 1
# Generate consistent speed based on tracker ID
# Use tracker_id to ensure consistent speed per vehicle
np.random.seed(int(tracker_id) % 10000) # Consistent seed for each tracker ID
# Generate speeds based on vehicle type
if class_name.lower() in ["truck", "bus", "lorry", "trailer"]:
# Slower vehicles
speed = np.random.randint(60, 85)
elif class_name.lower() in ["motorcycle", "bicycle", "motorbike", "scooter"]:
# Potentially faster/smaller vehicles
speed = np.random.randint(70, 100)
elif lane_name.startswith("emergency") or lane_name.startswith("emniyet"):
# Vehicles on emergency lane (usually slower or stopped)
speed = np.random.randint(30, 60)
else:
# Regular cars
speed = np.random.randint(70, 120)
# Add some variance based on lane position
if "left" in lane_name or "sol" in lane_name:
# Left lanes typically have faster traffic
speed += np.random.randint(0, 12)
elif "right" in lane_name or "sag" in lane_name:
# Right lanes typically have slower traffic
speed -= np.random.randint(0, 10)
# Store speed for this vehicle
vehicle_speeds[tracker_id] = speed
# Update lane speeds
self.lane_detector.add_vehicle_speed(lane_name, speed)
labels.append(label)
# Annotate frame
return self.annotate_frame(frame, original_detections, labels, flow_detections)
def annotate_frame(
self, frame: np.ndarray, detections: sv.Detections,
labels: List[str], flow_detections: sv.Detections = None
) -> np.ndarray:
annotated_frame = frame.copy()
# Enhanced text calculation based on resolution
resolution_wh = (frame.shape[1], frame.shape[0])
base_font_scale = sv.calculate_optimal_text_scale(resolution_wh)
# Thinner text settings
font_scale = base_font_scale * 0.7
line_thickness = max(1, int(base_font_scale * 2))
# Utility function for anti-aliased text with thinner lines
def draw_text_aa(image, text, pos, font_scale, color, thickness, bg_color=None, padding=0):
font = cv2.FONT_HERSHEY_SIMPLEX
# Get text size
(text_width, text_height), baseline = cv2.getTextSize(text, font, font_scale, thickness)
# Draw background if specified
if bg_color is not None:
p1 = (pos[0] - padding, pos[1] + baseline + padding)
p2 = (pos[0] + text_width + padding, pos[1] - text_height - padding)
cv2.rectangle(image, p1, p2, bg_color.as_bgr(), -1)
# Draw text with anti-aliasing
cv2.putText(image, text, pos, font, font_scale, color.as_bgr(), thickness, cv2.LINE_AA)
return image
# Draw lane polygons with different colors - enhanced visibility
for i, lane_name in enumerate(self.lane_detector.lane_names):
polygon = self.lane_detector.lane_polygons[lane_name]
color_idx = i % len(COLORS.colors)
color = COLORS.colors[color_idx]
# Skip drawing emniyet_seridi with id="6" as it's too large and used as detection zone
if lane_name == "emergency_lane" and any(
np.array_equal(polygon, self.lane_detector.detection_zone)
for polygon in [self.lane_detector.lane_polygons[n] for n in self.lane_detector.lane_names]
):
continue
# Draw filled polygon with enhanced transparency
annotated_frame = sv.draw_filled_polygon(
scene=annotated_frame,
polygnotallow=polygon,
color=color,
opacity=0.3 # Increased opacity for better visibility
)
# Draw outline with increased thickness
annotated_frame = sv.draw_polygon(
scene=annotated_frame,
polygnotallow=polygon,
color=color,
thickness=line_thickness # Dynamic thickness based on resolution
)
# Draw lane statistics in top-left corner
# Create a semi-transparent background for better readability - make it wider for speed data
stats_bg_height = (len(self.lane_detector.lane_names) + 2) * 25 + 10 # +2 for title and header row
stats_bg_width = 200 # Increased width to fit speed data
bg_rect = np.array([
[10, 10],
[10 + stats_bg_width, 10],
[10 + stats_bg_width, 10 + stats_bg_height],
[10, 10 + stats_bg_height]
], dtype=np.int32)
annotated_frame = sv.draw_filled_polygon(
scene=annotated_frame,
polygnotallow=bg_rect,
color=sv.Color.BLACK,
opacity=0.7
)
annotated_frame = sv.draw_polygon(
scene=annotated_frame,
polygnotallow=bg_rect,
color=sv.Color.WHITE,
thickness=1
)
# Draw title
title_text = "LANE STATISTICS"
annotated_frame = draw_text_aa(
annotated_frame,
title_text,
(20, 30),
base_font_scale * 0.8,
sv.Color.WHITE,
1,
None,
padding=0
)
# Draw column headers with carefully positioned columns
header_text = "Lane Count Avg Speed KM/H"
annotated_frame = draw_text_aa(
annotated_frame,
header_text,
(20, 55), # Position below title
base_font_scale * 0.6, # Slightly smaller than title
sv.Color.WHITE,
1,
None,
padding=0
)
# Draw each lane statistic in order - with added speed info
for i, lane_name in enumerate(self.lane_detector.lane_names):
color_idx = i % len(COLORS.colors)
color = COLORS.colors[color_idx]
count = self.lane_detector.vehicle_counts[lane_name]
avg_speed = self.lane_detector.lane_average_speeds[lane_name]
# Y-position for this line, shift down to account for header row
y_pos = 80 + i * 25 # Start lower to account for header
# Draw colored square indicator
square_size = 15
square_top_left = (20, y_pos - square_size + 5)
square_bottom_right = (20 + square_size, y_pos + 5)
# Draw colored square
cv2.rectangle(annotated_frame, square_top_left, square_bottom_right,
color.as_bgr(), -1)
# Draw square outline
cv2.rectangle(annotated_frame, square_top_left, square_bottom_right,
sv.Color.WHITE.as_bgr(), 1)
# Get shortened lane name for display
short_name = lane_name
if len(lane_name) > 10:
if lane_name.startswith("emergency"):
short_name = "emergency"
elif lane_name.startswith("middle"):
short_name = "mid" + lane_name[-1:]
elif lane_name.startswith("right"):
short_name = "right"
elif lane_name.startswith("left"):
short_name = "left"
# Layout settings for precise column alignment
lane_col_width = 15 # Width for lane name column
count_col_pos = 115 # Starting position for count column
speed_col_pos = 160 # Starting position for speed column
# Draw lane name (left aligned)
lane_text = f"{short_name}"
annotated_frame = draw_text_aa(
annotated_frame,
lane_text,
(45, y_pos),
base_font_scale * 0.7,
sv.Color.WHITE,
1,
None,
padding=0
)
# Draw count (right aligned under "Count" header)
count_text = f"{count}"
annotated_frame = draw_text_aa(
annotated_frame,
count_text,
(count_col_pos, y_pos),
base_font_scale * 0.7,
sv.Color.WHITE,
1,
None,
padding=0
)
# Draw average speed (right aligned under "Avg Speed" header)
if avg_speed > 0:
speed_text = f"{avg_speed:.1f}"
else:
speed_text = "--"
annotated_frame = draw_text_aa(
annotated_frame,
speed_text,
(speed_col_pos, y_pos),
base_font_scale * 0.7,
sv.Color.WHITE,
1,
None,
padding=0
)
# Check for vehicles on emergency lane and draw warning
emergency_lane_vehicles = 0
emergency_vehicle_detections = []
if len(detections) > 0:
for i, xyxy in enumerate(detections.xyxy):
x1, y1, x2, y2 = map(int, xyxy)
center = ((x1 + x2) / 2, (y1 + y2) / 2)
lane_name = self.lane_detector.determine_lane(center)
# Check if vehicle is on emergency lane - support both Turkish and English names during transition
if lane_name == "emergency_lane" or lane_name == "emniyet_seridi":
emergency_lane_vehicles += 1
emergency_vehicle_detections.append(xyxy)
# If any vehicles detected on emergency lane, show warning with thinner text
if emergency_lane_vehicles > 0:
for xyxy in emergency_vehicle_detections:
x1, y1, x2, y2 = map(int, xyxy)
# Draw red warning border around the vehicle with thinner line
cv2.rectangle(annotated_frame, (x1, y1), (x2, y2),
(0, 0, 255), line_thickness) # Using standard line thickness
# Add warning text with thinner lines
warning_text = "WARNING! EMERGENCY LANE"
warning_pos = (int(x1), int(y1-15))
# Use anti-aliased text with thinner lines
annotated_frame = draw_text_aa(
annotated_frame,
warning_text,
warning_pos,
base_font_scale * 1.0,
sv.Color.WHITE,
1,
sv.Color.RED,
padding=8
)
# Draw global warning with thinner text
global_warning = f"ALERT! {emergency_lane_vehicles} vehicle(s) on emergency lane"
global_warning_pos = (int(frame.shape[1]/2 - 250), 60)
annotated_frame = draw_text_aa(
annotated_frame,
global_warning,
global_warning_pos,
base_font_scale * 1.2,
sv.Color.WHITE,
1,
sv.Color.RED,
padding=15
)
# Draw vehicle detections with thinner text
if len(detections) > 0:
# Configure annotators with thinner lines
self.box_annotator = sv.BoxAnnotator(
color=COLORS,
thickness=1
)
# Thinner text for labels
self.label_annotator = sv.LabelAnnotator(
text_color=sv.Color.BLACK,
text_scale=font_scale * 1.0,
text_thickness=1,
text_padding=5
)
self.trace_annotator = sv.TraceAnnotator(
color=COLORS,
positinotallow=sv.Position.CENTER,
trace_length=10,
thickness=1
)
# Draw traces with improved parameters
annotated_frame = self.trace_annotator.annotate(
scene=annotated_frame,
detectinotallow=detections
)
# Draw bounding boxes with improved parameters (no labels yet)
annotated_frame = self.box_annotator.annotate(
scene=annotated_frame,
detectinotallow=detections
)
# Custom labels with thinner text formatting
custom_labels = []
for i, (xyxy, label) in enumerate(zip(detections.xyxy, labels)):
# Determine which lane the vehicle is in
x1, y1, x2, y2 = map(int, xyxy)
center = ((x1 + x2) / 2, (y1 + y2) / 2)
lane_name = self.lane_detector.determine_lane(center)
# Better formatting with more readable structure
full_label = f"{label} ({lane_name})" if label else lane_name
custom_labels.append(full_label)
# Now draw the labels using the separate LabelAnnotator
annotated_frame = self.label_annotator.annotate(
scene=annotated_frame,
detectinotallow=detections,
labels=custom_labels
)
return annotated_frame
if __name__ == "__main__":
# Create a fresh parser with a unique name to avoid conflicts
lane_detection_parser = argparse.ArgumentParser(
descriptinotallow="Lane Detection and Traffic Flow Analysis with YOLO"
)
lane_detection_parser.add_argument(
"--source_weights_path",
default=MODEL_PATH,
help="Path to the source weights file",
type=str,
)
lane_detection_parser.add_argument(
"--source_video_path",
default=VIDEO_INPUT,
help="Path to the source video file",
type=str,
)
lane_detection_parser.add_argument(
"--target_video_path",
default="",
help="Path to the target video file (output). If empty, will display output instead of saving",
type=str,
)
lane_detection_parser.add_argument(
"--display",
actinotallow="store_true",
help="Display video while processing (even when saving)",
default=False
)
lane_detection_parser.add_argument(
"--confidence_threshold",
default=0.1,
help="Confidence threshold for the model",
type=float,
)
lane_detection_parser.add_argument(
"--iou_threshold",
default=0.7,
help="IOU threshold for the model",
type=float
)
# Parse arguments and proceed
args = lane_detection_parser.parse_args()
# Print processing mode for clarity
if args.target_video_path:
print(f"Processing video and saving to: {args.target_video_path}")
else:
print("Processing video for display only (not saving)")
# Print model selection
print(f"Using model: {args.source_weights_path}")
# Ensure target_video_path is set if not provided
if not args.target_video_path:
args.target_video_path = "output_lane_detection.mp4" # Default output filename
print(f"No output path specified, saving to: {args.target_video_path}")
elif not args.target_video_path.lower().endswith('.mp4'):
args.target_video_path += '.mp4'
print(f"Processing video and saving to: {args.target_video_path}")
print("Video will be displayed during processing and will close automatically when finished")
processor = LaneVehicleProcessor(
source_weights_path=args.source_weights_path,
source_video_path=args.source_video_path,
target_video_path=args.target_video_path,
confidence_threshold=args.confidence_threshold,
iou_threshold=args.iou_threshold
)
processor.process_video(display_while_saving=True) # Force display to be True使用的技术及方法
该项目是使用深度学习和计算机视觉模型 YOLOv12N 构建的。该模型使用来自 Roboflow Universe 的大型车辆数据集进行了 250 个 epoch 的训练。
Roboflow Polygon 工具集成
- 基于区域的检测:Roboflow 的多边形工具用于标记闭路电视录像中的车道和道路。
- 柔性区域分析:每条车道都经过单独分析,以跟踪车辆并测量速度。
实时处理
- 闭路电视视频分析:该模型分析了伊斯坦布尔 Kozyatagi 闭路电视摄像机的实时镜头。
- NVIDIA 优化:该模型可以转换为 .onnx 或 .engine 格式,以便在 NVIDIA 驱动的设备上高效运行。
技术细节:代码和结构
该项目采用模块化方法。以下是关键组件:
1. LaneDetector 类
- 加载多边形数据:从 JSON 文件中读取泳道区域并缩放它们以匹配视频分辨率。
- 确定泳道位置:使用其边界框检查检测到的车辆是否在车道内。
- 跟踪车辆数量和速度:计算车辆数量并计算每条车道的平均速度。
2. LaneVehicleProcessor 类
- 集成 YOLO 和 ByteTrack:YOLO 检测车辆,而 ByteTrack 跨帧跟踪它们。
- 分析检测区域:将检测到的车辆与预定义的车道区域进行比较。
- 显示流量数据:使用 OpenCV 和 Supervision 库在视频上叠加实时数据。
3. 流量管理
- 入口和出口区域:跟踪车辆进出的车道。
- 速度估计:为车辆分配随机但真实的速度值。
- 紧急车道警告:检测应急车道上的车辆并发出警告。
结果和未来改进
该项目为使用 CCTV 录像的交通监控提供了实时解决方案。收集的数据可以:
- 改进交通管理系统以更好地控制拥堵。
- 通过自动检测减少交通违规和事故。
- 确保应急车辆能够更快地到达目的地。
未来的增强功能
- 模型优化:将 YOLOv12N 转换为 .onnx 或 .engine 格式以获得更好的实时性能。
- 数据集扩展:使用来自不同角度和天气条件的图像进行训练,以提高准确性。
- 高级分析:使用机器学习对流量模式进行预测建模。
源码下载:
🔗 GitHub: https://github.com/bahakizil/Vehicle_Detection
🔗 GitHub Proje: https://github.com/bahakizil/Smart-Traffic-Analysis-With-Yolo
🔗 Roboflow: https://universe.roboflow.com/ktaivleschool-6njsd/cctv_cars_bike_detection-gi3nf/dataset/6....
4、Yolo13
4.1、超图增强~实时目标检测
清华等开源YOLOv13
实时目标检测领域YOLO系算法迎来新成员YOLOv13, 标配N/S/L/X不同规模的模型,性能更强,调用简单,可通过Ultralytics包直接测试和训练。
今日arxiv论文 YOLOv13: Real-Time Object Detection with Hypergraph-Enhanced Adaptive Visual Perception 介绍了YOLOv13的具体设计和实验结果,该研究由多个顶尖机构的团队共同完成,主要作者包括Mengqi Lei, Siqi Li, Yihong Wu, Han Hu, You Zhou, Xinhu Zheng, Guiguang Ding, Shaoyi Du, Zongze Wu, 和 Yue Gao。他们分别来自清华、太原理工、北京理工、深圳大学、香港科技大学(广州)、西安交通大学等研究机构。
YOLO系列算法的进化路径
YOLO(You Only Look Once)系列因其在速度与精度之间的卓越平衡,已成为实时目标检测领域的标杆。其发展历程体现了目标检测技术从追求速度到兼顾精度,再到精细化结构设计的演进。
- 早期探索 (YOLOv1 - YOLOv3):YOLOv1首次将目标检测视为一个单次回归问题,实现了端到端的快速检测。YOLOv2通过引入锚框(anchor-based predictions)和DarkNet-19骨干网络提升了检测精度。YOLOv3则采用了更深的DarkNet-53骨干网和三尺度预测(three-scale predictions),显著增强了对小目标的检测能力。
- 集成与优化 (YOLOv4 - YOLOv8):这一时期的YOLO模型广泛集成了当时主流的先进技术。例如,CSP(Cross Stage Partial)、SPP(Spatial Pyramid Pooling)、PANet等模块被陆续引入,并逐渐开始采用无锚框(anchor-free)的检测头,以进一步平衡模型的吞吐量与准确率。
- 效率与部署 (YOLOv9 - YOLOv11):近期版本更侧重于模型的轻量化和端到端部署的便捷性。例如,YOLOv11在保持“骨干-颈部-头部”模块化设计的同时,采用了更高效的C3k2单元,并加入了带局部空间注意力的卷积块(C2PSA),以增强对小尺寸和被遮挡目标的检测效果。
- 引入注意力机制 (YOLOv12):YOLOv12标志着注意力机制的全面融入,它引入了轻量级的区域注意力(Area Attention, A2)和Flash Attention,旨在以高效的方式实现全局和局部语义建模,提升了模型的鲁棒性和精度。
研究目的与动机
尽管YOLO系列不断进化,但论文作者指出,现有的模型在信息建模上仍存在共性局限。无论是YOLOv11及之前的卷积架构,还是YOLOv12引入的自注意力机制,其信息聚合方式本质上都受限于以下两点:
- 局部性限制:卷积操作在固定的感受野内聚合信息。
- 成对关系建模:自注意力机制的核心是建立特征间的成对关系(pairwise correlation)。
这两种模式都难以捕捉多个实体之间共同形成的、更复杂的“多对多”高阶关联(high-order correlations),导致模型在处理具有复杂空间和语义关系的场景时性能受限。因此,本研究的核心目的在于,通过引入能有效建模全局、高阶视觉关联的机制,来提升YOLO系列模型在复杂场景下的检测精度和鲁棒性。
提出的方法
为实现上述目标,论文提出了YOLOv13模型,其核心包含三大创新:

a. 基于超图的自适应相关性增强机制 (HyperACE)
YOLOv13的最核心创新,旨在有效捕捉特征间潜在的高阶关联。

- 基本原理:该机制借鉴了超图(Hypergraph)的理论。与普通图中一条边只能连接两个顶点不同,超图中的一条“超边”(Hyperedge)可以同时连接多个顶点,这使其天然适合建模“多对多”的关系。
- 自适应超边生成:为克服传统超图方法依赖手工设定参数的不足,HyperACE设计了一个可学习的超边生成模块。该模块能根据输入的视觉特征,自适应地学习并构建超边,动态地探索不同特征顶点之间的潜在关联。
- 超图卷积:在生成自适应超边后,通过超图卷积操作进行特征聚合与增强。每条超边先从其连接的所有顶点处聚合信息,形成高阶特征;随后,这些高阶特征再被传播回各个顶点,从而完成对顶点特征的更新与增强。
b. 全流程聚合与分发范式 (FullPAD)
为了最大化HyperACE增强后特征的效用,作者设计了FullPAD这一新的网络信息流范式。
- 工作流程:FullPAD首先从骨干网络中汇集多尺度特征,并将其送入HyperACE模块进行处理。随后,通过专门的“FullPAD通道”,将这些经过高阶关联增强的特征重新分发至网络的多个关键位置,包括骨干网与颈部的连接处、颈部网络内部、以及颈部与检测头的连接处。
- 设计目的:这种设计旨在打破传统YOLO架构中单向的信息流,实现全网络范围内的信息协同与精细化流动,从而改善梯度传播并提升最终的检测性能。
c. 深度可分离卷积轻量化设计
为保证模型的高效率,YOLOv13采用深度可分离卷积(Depthwise Separable Convolution, DSConv)作为基础单元,设计了一系列轻量化模块(如DSConv, DS-Bottleneck, DS-C3k, DS-C3k2),用于替代标准的大核卷积。这些模块被广泛应用于模型的骨干和颈部网络中,在基本不牺牲模型性能的前提下,显著降低了参数量和计算复杂度(FLOPs)。

主要实验结果
研究团队在MS COCO数据集上进行了广泛的实验,以验证YOLOv13的有效性。
- 性能对比:与现有模型相比,YOLOv13在不同尺寸上均表现出优势。例如,YOLOv13-N的mAP达到了41.6%,相较于YOLOv12-N和YOLOv11-N分别提升了1.5%和3.0%。
-

- 模块有效性验证:消融实验证明了核心模块的必要性。在YOLOv13-S模型中,若移除HyperACE模块,其AP50:95指标会下降0.9%。这证实了高阶关联建模的有效性。
-

- 轻量化效果:实验表明,使用DS系列模块替换标准卷积,可以在mAP几乎不变的情况下,大幅减少模型复杂度。
-

- 泛化能力测试:YOLOv13同样在PASCAL VOC 2007测试集上表现出色,验证了其跨域泛化能力。
-

总结与资源
YOLOv13通过引入自适应超图计算,有效地增强了模型对全局高阶视觉关系的建模能力。结合创新的FullPAD信息流范式和深度可分离卷积的轻量化设计,该模型在保持高效率的同时,实现了当前最优的检测性能。
开源贡献:作者已将YOLOv13的代码和预训练模型开源,便于社区研究和使用。
- 论文链接:https://arxiv.org/abs/2506.17733
- 代码链接:https://github.com/iMoonLab/yolov13

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 19
19 0
0- 0



 已为社区贡献109条内容
已为社区贡献109条内容

所有评论(0)