51c大模型~合集153
【AI前沿研究速览】多领域创新成果涌现,大模型与AIAgent技术取得突破性进展 视频生成加速与检测技术 华中科大团队提出EasyCache框架,通过动态缓存机制实现视频扩散模型2.2倍加速 北大与腾讯优图合作开发正交子空间分解方法,显著提升AI生成图像检测泛化能力 大模型开源与创新 月之暗面开源Kimi K2万亿参数模型,在多项基准测试超越GPT-4.1 采用MuonClip优化器解决训练稳定性
我自己的原文哦~ https://blog.51cto.com/whaosoft/14043299
#EasyCache
无需训练的视频扩散模型推理加速——极简高效的视频生成提速方案
论文作者团队简介:本文第一作者周鑫,共同第一作者梁定康,均为华中科技大学博士生,导师为白翔教授。合作者包括华中科技大学陈楷锦、冯天瑞、林鸿凯,旷视科技陈习武、丁宜康、谭飞杨和香港大学赵恒爽助理教授。
,时长00:05
在HunyuanVideo上,EasyCache在复杂场景下保持与原视频的一致外观,同时显著加速
1. 研究背景与动机
近年来,随着扩散模型(Diffusion Models)和扩散 Transformer(DiT)在视频生成领域的广泛应用,AI 合成视频的质量和连贯性有了飞跃式提升。像 OpenAI Sora、HunyuanVideo、Wan2.1 等大模型,已经能够生成结构清晰、细节丰富且高度连贯的长视频内容,为数字内容创作、虚拟世界和多媒体娱乐带来了巨大变革。
但与此同时,推理慢、算力消耗高的问题也日益突出。以 HunyuanVideo 为例,生成一个 5 秒、720P 分辨率的视频,单次推理在单张 H20 上需要 2 小时。这种高昂的资源代价,极大限制了扩散视频生成技术在实时互动、移动端和大规模生产场景的应用落地。
造成这一瓶颈的核心原因,是扩散模型在生成过程中需要多次迭代去噪,每一步都要进行完整的神经网络前向推理,导致大量冗余计算。如何在不影响视频质量的前提下,大幅提升推理效率,成为亟需突破的难点。
- 论文标题:Less is Enough: Training-Free Video Diffusion Acceleration via Runtime-Adaptive Caching
- 论文地址:https://arxiv.org/abs/2507.02860
- 代码地址(已开源): https://github.com/H-EmbodVis/EasyCache
- 项目主页:https://h-embodvis.github.io/EasyCache/

2. 方法创新:EasyCache 的设计与原理
本论文提出的 EasyCache,是一种无需训练、无需模型结构改动、无需离线统计的推理加速新框架。它的核心思想非常直接:在推理过程中,动态检测模型输出的 「稳定期」,复用历史计算结果以减少冗余推理步骤。
2.1 扩散过程的 「变换速率」 规律
扩散模型的生成过程可以理解为 「逐步去噪」:每一步都从当前潜变量出发,预测噪声并更新状态,逐渐还原出清晰的视频内容。将一个 step 内的全部 DiT blocks 看做一个函数,可以考虑某个 step 的 「方向导数」 的一阶近似:

为了便于分析,将其求均值和范数以简化为数值(变换速率,Transformation rate):

通过对扩散 Transformer 的内部特征分析,发现:
- 在去噪初期,模型输出变化剧烈,可能需要完整推理以捕捉全局结构;
- 但在中后期,模型的 「变换速率」 趋于稳定,行为近似线性,细节微调为主。

这种 「稳定性」 意味着,许多步骤的输出可以用之前某一步的结果做近似,大量冗余计算可以被跳过。
2.2 EasyCache 的自适应缓存机制
EasyCache 的具体实现流程如下:
(1)变换速率度量
定义每一步的 「变换速率」

,用于衡量当前输出对输入的敏感度。我们惊讶地发现,尽管整个模型的输入输出在时间步层面变化剧烈且呈现不同的变化模式,Kt在去噪后期却能保持相对稳定。
(2)自适应判据与缓存复用
- 设定累计误差阈值,动态累计每步的输出变化率(误差指标Et)。具体而言,假定Kt在局部为常数,可以通过下一个 step 的输入变化与Kt一起协同判断输出的变化率(局部稳定性判断),将预估的输出变化率累加可以作为累计误差估计。
- 只要Et低于τ,就直接复用上一次完整推理的变换向量,否则重新计算并刷新缓存。
- 前 R 步为 warm-up,全部完整推理,确保初期结构信息不丢失。
-

(3)无需训练与模型改动
EasyCache 完全在推理阶段生效,不需要模型重训练,也不需修改原有网络结构,可以做到 「即插即用」。
3. 实验结果与可视化分析
论文在 OpenSora、Wan2.1、HunyuanVideo 等多个主流视频生成模型上进行了系统实验,考察了推理速度与生成质量的平衡。
3.1 定量实验结果

- EasyCache 在 HunyuanVideo 上实现 2.2 倍加速,PSNR 提升 36%,SSIM 提升 14%,LPIPS 大幅下降,视频质量几乎无损。在 Wan2.1 上也取得了超过 2 倍的加速比。
-

- 在图像生成任务(如 FLUX.1-dev)同样可带来 4.6 倍加速,并提升 FID 等指标。
-

- EasyCache 与 SVG 等稀疏注意力技术可叠加,平均可达 3.3 倍加速,总体推理时长从 2 小时缩短到 33 分钟。
3.2 可视化对比
论文展示了不同方法生成的视频帧对比:
- 静态缓存和 TeaCache 等方法在细节、结构和清晰度上均有不同程度损失;
- EasyCache 生成的视频在视觉效果上与原始模型几乎一致,细节保留优秀,且无明显模糊或结构错乱。更多可视化请见:https://h-embodvis.github.io/EasyCache/
,时长00:05
在Wan2.1-14B上,EasyCache成功地保留了文字
,时长00:08
EasyCache能够在SVG的基础上进一步将加速倍数提高到三倍以上
4. 总结与未来展望
EasyCache 为视频扩散模型的推理加速提供了一种极简、高效、训练无关的新范式。它通过深入挖掘扩散过程的内在规律,实现了大幅提速且几乎无损的高质量视频生成,为扩散模型在实际应用中的落地提供了坚实基础。未来,随着模型和有关加速技术的持续提升,我们期望能进一步逼近 「实时视频生成」 的目标。
....
#不做人形、不跳舞~咖啡机器人
他家的xx智能凭什么在100+城市卖出400万杯咖啡?
新年刚开局,AI 行业就直接拉满强度。
在 CES 这个全球科技风向标上,机器人 × AI 成了真正的主角。在拉斯维加斯的霓虹灯下,中.国机器人军.团走到舞台中央——不靠堆概念,而是带着订单和规模化落地速度。

CES创新奖评委Chris Pereira 指出,中国厂商正在把新兴技术,快速转化为能量产、能交付、能在全球市场销售的成熟产品。
与此同时,AI 正退到幕后,成为产品底层能力,真正的竞争,落在实用性、设计与可靠执行力上。
在展会现场,最吸睛的依旧是「人形」。

波士顿动力(现在已经属于韩国现代集团)的新版Atlas亮相。
但在同一空间内,另一条路线也在同步展开。
在影智 XBOT 的透明橱窗前,人群一层层围拢过来。这是全球首个支持冷热双杯同出的xx机器人,也是目前一众xx智能中最落地的一种呈现。
有人举着手机录像,有人已经在讨论要把什么图案印在咖啡上。

影智 XBOT Lite 系列印花咖啡机器人——全球首个支持冷热双杯同出的xx机器人。
玻璃之后,两只机械臂分工协作,打奶、印花、出杯,动作连贯得像一段被反复打磨过的编舞。110 秒后,一杯冰美式和一杯热拿铁同时完成,杯面上浮现出由 AI 生成的专属印花——每一杯都不重样。

「这玩意儿太酷了。」队伍里有人忍不住感叹,「能在咖啡上打印照片,绝对是游戏规则改变者。」有人已经等不及拍照发社交平台。

机器人继续出杯,节奏稳定。「你能把公司 logo 印在咖啡上,这杯咖啡一下子就成专属的了,谁会不喜欢?」 有顾客说。「而且不用付小费——对顾客对老板都是好事。」 有人从更现实的角度补了一句。

喝完咖啡,又尝了旁边影智 XBOT 冰淇淋机器人做的冰淇淋,人群里笑声不断。「这哪是咖啡机?」有人指着橱窗笑道,「这是个能把人吸过来的娱乐中心。」

与多数人形机器人仍在努力「看起来很未来」不同,影智XBOT并不追求形似人类,而是成为一台可以全天候运转的生产工具——不跳舞、不表演,直接把一杯口感稳定、好喝的咖啡,端到你面前。
而这套逻辑,已经在真实世界里跑了很久。
从天安门广场、国家图书馆到成都锦里,影智XBOT经历的不是短暂的 show time,而是数百万次的反复出杯。
目前,影智XBOT已在 15 个以上国家、100多个城市落地,部署量超过 600 台,累计制作咖啡 400 万杯以上,在部分核心点位甚至实现了数月回本。
在xx智能普遍面临商业化难题的当下,影智XBOT用一组明确的数据证明:它是目前行业内商用落地速度最快的xx智能机器人之一。

2025年8月影智科技发布年度新品之一:影智XBOT Lite系列印花咖啡机器人。
回归商业常识:xx智能不等于「人形」
在当下关于xx智能的讨论中,「人形」几乎成了一种默认答案。但在「操刀」影智XBOT的影智科技看来,这条路径更多源于技术想象,而非商业理性。
这一判断,来自公司创始人唐沐长期积累的产品与商业经验。
作为 2022 年福布斯中国十佳设计师,唐沐曾掌舵腾讯用户体验设计中心(CDC),并担任小米生态链副总裁。他既是 QQ 头像、微信表情包等现象级符号的缔造者,也是小米路由器、小爱智能音箱等亿级爆款产品的重要推动者。

公司创始人唐沐和影智XBOT咖啡机器人。
长期站在技术、产品与规模化商业的交汇点,也塑造了他极其务实的产品观:一切产品必须从真实场景出发、目标要指向大众市场,并且要经得起规模化、可靠性与成本结构的严格检验。
这也构成了影智科技切入xx智能领域的基本原则——回归商业常识。先解决人的需求,解决人的问题,在一个足够垂直的场景中把事情做到极致,再去讨论所谓的「终极形态」。
在唐沐看来,机器人的进化路径不该从「像人」出发,而应回到「是否真正有用」。xx智能的价值,并不取决于外形是否拟人,而在于是否能够围绕具体问题展开,在真实环境中灵活适应、精准执行。
在大量现实的消费与服务场景中,工程复杂度高、成本更高并伴有不可控风险的人形设计,反而会成为商业化落地的负担。
至于「为什么是精品咖啡」,也是多条现实线索叠加后的选择。
挑市场,首先要足够大,其次必须是一个成长型市场,咖啡符合这两个前提。它本身是一个高度全球化、已被充分验证的成熟消费市场,而中国市场还在快速增长。
数据显示,2023 年我国人均年咖啡消费量约为 16.74 杯,几乎是 2016 年的两倍;到 2024 年,这一数字已提升至 22.24 杯以上。即便在瑞幸、库迪等品牌快速扩张的背景下,中国咖啡门店的整体密度,依然明显低于日本和韩国等成熟市场,增长空间可观。
需求持续走高的同时,供给侧却长期受制于人力瓶颈。
咖啡师培养周期长、流动性高,岗位留存率普遍偏低;在高度内卷的竞争环境中,咖啡店拼的是出单量与运营效率,对人力的挤压不断加剧,也放大了系统性的运营矛盾。
咖啡消费还呈现出明显的波峰与波谷。高峰期排队几乎成为常态,品质波动难以避免。尤其是在拉花这类对毫米级精度和连续轨迹高度敏感的操作中,人类不可避免的生理性抖动,会直接放大为线条断裂或形变。
而对大多数用户而言,他们关心的不是「谁在做咖啡」,而是出杯是否足够快、品质是否始终稳定。以出杯量为例,每天三百杯以上的稳定输出,对人类咖啡师而言几乎不可持续;而对机器人来说,这只是一个连续、可复制的标准工作负载。
在这样的背景下,大模型的出现,让产品「升维」——从底层重新定义一套面向消费服务场景的xx智能系统——成为可能。
市面上多数咖啡机,本质上仍是工业自动化设备,考虑的是「怎么把咖啡做完」。xx智能除了关心效率,还关心「这杯咖啡是给谁喝的、在什么情境下喝、怎样才算一次好的体验」。咖啡这一日常消费场景,第一次有机会迈入以用户体验为核心的重构阶段。
历经两年多研发,影智XBOT问世并成功出圈,唐沐也因此多了一个被媒体反复引用的标签:「xx智能消费机器人第一人」。
xx智能的「三位一体」:
为什么能做到万杯如一?
从原料开始,影智XBOT就在为「稳定性」服务。
目前,影智XBOT全部采用阿拉比卡咖啡豆,设备内设置两个豆仓:一个拼配豆,一个单品豆(瑰夏),以覆盖不同用户的口味偏好;牛奶则与蒙牛合作统一供应。无论是在北京、上海,还是成都,下单后端到手里的那杯咖啡,都能保持高度一致的风味。

这种「万杯如一」的表现,并不是靠单一环节实现,而是依赖一套完整的xx智能技术体系:负责理解与决策的「大脑」、统筹执行的操作系统(OS),以及完成精细物理动作的「小脑」。
影智XBOT的「大脑」,并不是传统点单系统,而是一套面向真实世界运行的xx智能餐饮大模型,核心目标是更好地理解用户需求。

当你说出一句模糊需求——比如「我想来一杯热带风情的咖啡」——系统会在毫秒级调取完整的饮品知识体系,覆盖公开菜单、配方逻辑与标准化制作 SOP,并理解「热带风情」意味着椰子、热带水果、冰感与较高甜度。
接下来,大模型会调用口味拼配算法,在现有原料约束下寻找最优解:比例如何控制?先加什么、后加什么,才能在不破坏咖啡骨架的前提下,呈现「热带」风味?
这些原本高度依赖咖啡师经验与手感的判断,被转化为一组可计算、可推演的决策过程。算法甚至「知道」一些已经被反复验证的美味公式,如生椰与拿铁是绝配。
最终,你的抽象需求会被翻译成一连串精确到秒的动作调用:咖啡液多少秒、椰乳多少秒,冰、糖与水如何配合。每一个动作,都是机器人已经掌握的能力模块,可以被反复调用、稳定复现。
在「揽客」上,AI 数字人承担「意图入口」的角色。它具备长记忆能力,能识别老顾客与偏好——「Hi,Thomas,还是要上次的橙 C 冰美式吗?」甚至能在连续对话中保持上下文一致。

数字人还能根据状态做出情境化推荐,如夜深时建议一杯 double 浓缩。结合 AIGC,用户「随口一说」的创意,也能被实时「打印」成咖啡印花。

将自拍变成独一无二的咖啡印花。
如果说「大脑」解决的是「逻辑上该怎么做」,那么影智XBOT操作系统(LU BAN OS)要解决的是在真实世界中能不能这么做——这是双臂机器人实现落地的关键一环。
它更像一套神经中枢。当「大脑」给出高层指令后,OS并非简单转发,而是介入执行层,在复杂的真实环境中进行全局编排:统一调度机械臂、咖啡机、奶泡器、糖浆泵、制冰机、印花机等设备,确保每一个步骤、每一个动作,都发生在安全、合理且可控的物理条件之内。
做出一杯咖啡,看似线性的流程,背后其实是一套高并发的任务调度系统。通过底层运动算法,OS实现了双机械臂的空间解耦与时间同步。即便在狭窄的操作空间内,两只手臂也能在毫秒级反馈下实时避障,像人类双手一样默契配合。
OS真正强大的地方,在于赋予了双臂「柔性作业」的能力。在不同调度策略下,双臂可以进行高度非对称的协同,互不干扰地同时制作两款完全不同的饮品。

在写字楼早高峰,OS可以同时处理一杯热美式和一杯冰拿铁,将单杯等待时间大幅压缩。
与此同时,OS还会持续监控设备状态,记录运行数据,提前识别潜在异常,并为下一单完成预准备,等等。正是这套全局感知与调度能力,使影智XBOT即便在无人值守的情况下,也能长期稳定地支撑高并发出杯。
当这套通用底座逐渐成熟,咖啡也就不再是它的唯一应用场景。冰淇淋、奶茶、鸡尾酒、面食,乃至教育、陪伴等更广泛的消费与服务领域,本质上都只是同一套xx智能系统之上的「技能插件」。
在此之下,「小脑」承担的是xx智能中最贴近物理世界的一层任务:在液体流动、奶泡阻力与原料状态不断变化的真实环境中,依然把口味与视觉表现锁定在同一标准,实现真正意义上的「万杯如一」。
在硬件层面,团队自研双六轴定制工业机械臂,重复定位精度达到±0.03 毫米;配合高精度运控算法,整体操作精度达到 0.1毫米,远超人类生理极限。
在萃取阶段,粉量误差被压缩至极小范围。糖浆添加与拉花动作被控制在毫米级精度。拉花时,机械臂的移动速度与喷头挤出节奏始终保持同步,一旦感知到液体阻力或流速偏移,系统便即时修正电机输出,确保线条连续、不抖动。

为了教会机器人各种餐饮手艺,比如「审美级」拉花能力,团队搭建了一套顶级红外光学动捕系统。

75秒内复刻大师级的拉花咖啡技艺。机器人6个小时就能掌握一款新的拉花方式,而人类咖啡师需要6个月。
通过 11 组高精度摄像头,将顶级咖啡师最细微的手部摆动与力度变化,以毫米级精度完整记录下来,再借助自研算法,将这些大师级技巧翻译为机械臂可执行的控制指令,还实现了跨型号的自动校准。
最终,原本只存在于老师傅经验中的「手感」,被沉淀为可规模复制、稳定复现的工业级能力。
设计美学 × 商业策略:
让xx智能真正成为一门生意
如果说,技术解决的是「能不能把事做对」,那么工业设计解决的,其实是「这东西能不能被真正用起来」。而后一个问题,才是 2B 商家是否掏出真金白银的分水岭。
商家的目标很简单,用尽可能确定、低摩擦的方式赚钱。因此,影智XBOT是否能够被设计成一台全年无休、稳定运转的生产设备,是否能持续替代人力,把那些琐碎、重复、长期消耗精力的管理问题一并吞掉,远比「看起来有多先进」更重要。
也正因如此,作为少数同时拿下 iF、红点 Best of the Best、IDEA、CMF 等国际设计大奖的团队,影智科技并没有把工业设计当作外观层面的加分项,而是将其视为一套用于降低商业摩擦成本的方法论。
这种思路,最先落到一个极其「现实」的指标上:空间效率。
通过高度紧凑的内部架构,影智XBOT将机械臂、咖啡机、制冰机、印花机等完整模块,压缩进约 1.35㎡–2.5㎡ 的占地范围内。在寸土寸金的商业环境中,这是直接影响坪效、租金模型,甚至点位是否成立的关键变量。

设计并未止步于「塞得下」,而是与商业运维深度绑定。
通过全模块化架构,将复杂硬件拆解为标准化服务组件,故障模块可在60 分钟内快拆更换;配合远程 OTA,实现系统、动作路径与配方的一键升级。同时,预留扩展接口,支持未来扩容料仓或接入其他服务设备,让单体机器不被功能锁死,具备持续演进的商业弹性。

在商业模式上,影智科技并未停留在「卖一台机器」,而是搭建了一套更贴近真实商业世界的三层结构:设备销售、联营模式,以及持续性的增值服务。
其中,「7S」服务体系是一个首创。通过将大量原本由运营者承担的风险前移至平台侧,释放出一个明确信号:咖啡机器人并不是在「与人抢工作」,而是在用技术降低创业门槛,让小生意重新变得可控。它瞄准的,正是那些有创业意愿、却缺乏技术、管理与抗风险能力的中小创业者——过去,这类人往往在高启动成本与不确定风险中迅速出局。
在传统「4S」基础上,「7S」补齐了三项关键能力:用数据运营替代经验判断;通过金融服务,将近 20 万元的初始投入拆解为更轻量的运营方案;通过回购与升级机制,赋予设备流动性与持续迭代空间,明确机器人是一种可持续优化的资产,而非一次性消耗品。

把xx智能先安放在当下
如果说人形机器人代表的是远方,那么影智科技更像是把xx智能先安放在当下。
它代表了另一类xx智能公司:不沉迷概念叙事,也不等待终极形态,而是用当下可行的技术,在复杂、开放、不可控的真实世界中,反复验证可复制的商业模式。
从底层运控算法、工业设计,到产品形态与商业模式,影智科技在一条全链路上不断打磨同一个问题——当xx智能真正进入现实生活,它如何成为一门成立的生意。至少在咖啡这门生意里,这个问题已经有了被市场验证的答案。
也许正是这些并不「人形」、却能持续运转的「中间态」产品,正在把xxx智能从想象中的未来,一步步带进现实世界。
....
#GDPO
挑战GRPO,英伟达提出GDPO,专攻多奖励优化
GRPO 是促使 DeepSeek-R1 成功的基础技术之一。最近一两年,GRPO 及其变体因其高效性和简洁性,已成为业内广泛采用的强化学习算法。
但随着语言模型能力的不断提升,用户对它们的期待也在发生变化:不仅要回答正确,还要在各种不同场景下表现出符合多样化人类偏好的行为。为此,强化学习训练流程开始引入多种奖励信号,每一种奖励对应一种不同的偏好,用来共同引导模型走向理想的行为模式。
但英伟达的一篇新论文却指出,在进行多奖励优化时,GRPO 可能不是最佳选择。

具体来说,在多奖励优化场景中,GRPO 会将不同的奖励组合归一化为相同的优势值。这会削弱训练信号,降低奖励水平。
为了解决这一问题,他们提出了一种新的策略优化方法 —— 组奖励解耦归一化策略优化(GDPO)。该方法通过对各个奖励信号分别进行归一化,避免了不同奖励之间被混合「抹平」,从而更真实地保留它们的相对差异,使多奖励优化更加准确,同时显著提升了训练过程的稳定性。

- 论文标题:GDPO: Group reward-Decoupled Normalization Policy Optimization for Multi-reward RL Optimization
- 论文链接:https://arxiv.org/pdf/2601.05242
- 代码链接:https://github.com/NVlabs/GDPO
- 项目链接:https://nvlabs.github.io/GDPO/
- HuggingFace 链接:https://huggingface.co/papers/2601.05242
在工具调用、数学推理和代码推理这三类任务上,论文将 GDPO 与 GRPO 进行了对比评测,既考察了正确性指标(如准确率、缺陷比例),也评估了对约束条件的遵守情况(如格式、长度)。结果显示,在所有设置中,GDPO 都稳定地优于 GRPO,验证了其在多奖励强化学习优化中的有效性和良好泛化能力。

GRPO 有什么问题?
目前,GRPO 主要被用于优化单一目标的奖励,通常聚焦于准确率。然而,随着模型能力的持续提升,近期研究越来越倾向于同时优化多个奖励 —— 例如在准确率之外,还考虑响应长度限制和格式质量,以更好地与人类偏好保持一致。现有的多奖励强化学习方法通常采用一种直接的策略:将所有奖励分量相加,然后直接应用 GRPO 进行优化。
具体而言,对于给定的问答对,行为策略会为每个问题采样一组响应。假设存在 n 个优化目标,则第 j 个响应的聚合奖励被计算为各目标奖励之和。随后,通过对群组级别的聚合奖励进行归一化,得到第 j 个响应的群组相对优势。
作者首先重新审视了这种将 GRPO 直接应用于多奖励强化学习优化的常见做法,并发现了一个此前被忽视的问题:GRPO 本质上会压缩奖励信号,导致优势估计中的信息损失。
为了说明这一点,他们从一个简单的训练场景开始,然后推广到更一般的情况。假设为每个问题生成两个 rollout 来计算群组相对优势,且任务涉及两个二值奖励(取值为 0 或 1)。因此,每个 rollout 的总奖励可取 {0, 1, 2} 中的值。
如图 2 所示,作者列举了一个群组内所有可能的 rollout 奖励组合。尽管在忽略顺序的情况下存在六种不同的组合,但在应用群组级奖励归一化后,只会产生两个唯一的优势组。具体来说,(0,1)、(0,2) 和 (1,2) 会产生相同的归一化优势值 (-0.7071, 0.7071),而 (0,0)、(1,1) 和 (2,2) 则全部归一化为 (0, 0)。

这揭示了 GRPO 优势计算在多奖励优化中的一个根本性局限:它过度压缩了丰富的群组级奖励信号。
从直觉上讲,(0,2) 应该比 (0,1) 产生更强的学习信号,因为总奖励为 2 意味着同时满足了两个奖励条件,而奖励为 1 仅对应达成一个。因此,当另一个 rollout 只获得零奖励时,(0,2) 应该产生比 (0,1) 更大的相对优势。这种局限性还可能因优势估计不准确而引入训练不稳定的风险。如图 5 所示,当使用 GRPO 训练时,正确率奖励分数在约 400 个训练步后开始下降,表明出现了部分训练坍塌。

近期,Dr.GRPO 和 DeepSeek-v3.2 采用了 GRPO 的一个变体,移除了标准差归一化项,使得优势直接等于原始奖励减去均值。尽管这些工作引入此修改是为了缓解问题级别的难度偏差,但乍看之下,这一改变似乎也能解决上述问题。具体而言,移除标准差归一化确实在一定程度上缓解了问题:(0,1) 和 (0,2) 现在分别产生 (-0.5, 0.5) 和 (-1.0, 1.0) 的不同优势值。
然而,当将此设置推广到更多 rollout(保持奖励数量固定)时,如图 3 所示,作者观察到这种修复方法相比标准 GRPO 仅略微增加了不同优势组的数量。在固定 rollout 数量为 4、逐步增加奖励数量的设置下,也观察到类似趋势 —— 不同优势组的数量仅有适度改善。作者还在第 4.1.1 节中实证检验了移除标准差归一化项的效果,发现这一修改并未带来更好的收敛性或更优的下游评估表现。

GDPO是怎么做的?
为了克服上述挑战,作者提出了群组奖励解耦归一化策略优化(GDPO),这是一种旨在更好地保持不同奖励组合之间区分度、并更准确地在最终优势中捕捉其相对差异的方法。
与 GRPO 直接对聚合奖励和进行群组级归一化不同,GDPO 通过在聚合之前对每个奖励分别进行群组级归一化来解耦这一过程。具体而言,GDPO 不是先将所有 n 个奖励相加再进行群组级归一化得到总优势,而是为第 i 个问题的第 j 个 rollout 的每个奖励分别计算归一化优势,如下所示:

用于策略更新的总体优势通过以下方式获得:首先将所有目标的归一化优势相加,然后对多奖励优势之和应用批次级优势归一化。这确保了最终优势的数值范围保持稳定,不会随着额外奖励的引入而增长。从实证角度,作者还发现这一归一化步骤能够改善训练稳定性。
通过分离每个奖励的归一化,GDPO 缓解了 GRPO 优势估计中存在的信息损失问题,如图 2 所示。从图中可以看到,当采用 GRPO 时,不同的奖励组合(如 (0,2) 和 (0,1))会导致相同的归一化优势,从而掩盖了它们之间的细微差异。相比之下,GDPO 通过为每种组合分配不同的优势值来保留这些细粒度差异。
作者通过在两种实验设置下比较 GDPO、GRPO 和「无标准差 GRPO」产生的不同优势组数量,进一步量化了 GDPO 的有效性,如图 3 所示。在两个奖励、rollout 数量变化的场景中,GDPO 始终产生显著更多的不同优势组,且随着 rollout 数量增加,差距不断扩大。另一方面,当固定 rollout 数量为 4 并增加奖励数量时,也呈现出类似的模式 ——GDPO 随着目标数量增长表现出逐步增大的优势粒度。这表明论文所提出的解耦归一化方法在所有强化学习设置中都能有效增加不同优势组的数量,从而实现更精确的优势估计。
除了这些理论改进之外,作者还观察到使用 GDPO 能够持续产生更稳定的训练曲线和更好的收敛性。例如,在工具调用任务中,GDPO 在格式奖励和正确率奖励上都实现了更好的收敛,如图 4(见实验部分)所示。GDPO 还消除了 GRPO 在数学推理任务中观察到的训练坍塌问题,如图 5(见实验部分)所示,使用 GDPO 训练的模型在整个训练过程中持续改善正确率奖励分数。实验部分的更多实证结果进一步证实了 GDPO 在广泛的下游任务上实现更强目标偏好对齐的能力。
到目前为止,论文假设所有目标具有同等重要性。然而在实际应用中,这一假设并不总是成立。在论文中,作者系统地概述了如何调整与不同目标相关的奖励权重,或修改奖励函数以强制优先考虑更重要的目标。论文还讨论了当底层奖励在难度上存在显著差异时,这两种设计选择的不同行为表现。具体内容可参见论文第三章。
实验结果如何?
在实验部分,作者首先在工具调用任务上评估 GDPO 与 GRPO 的效果,然后在数学推理任务上进行比较,最后将优化奖励数量扩展到三个,在代码推理任务上进行对比。
工具调用
从图 4 的训练曲线可以看到,GDPO 在所有运行中都能在格式奖励和正确率奖励上收敛到更高的值。尽管 GDPO 在格式奖励收敛所需步数上表现出更大的方差,但最终达到的格式合规性优于 GRPO。对于正确率奖励,GDPO 在早期阶段表现出更快的改善,并在后期达到比 GRPO 基线更高的奖励分数。

在表 1 的 BFCL-v3 评估中,GDPO 也持续提升了平均工具调用准确率和格式正确率。对于 Qwen2.5-Instruct-1.5B 的训练,GDPO 在 Live/non-Live 任务上分别取得了近 5% 和 3% 的提升,在整体平均准确率上提高了约 2.7%,在正确格式比例上提高了 4% 以上。3B 模型上也观察到类似的改进。

关于移除标准差归一化项的效果:从图 4 可以观察到,虽然「无标准差 GRPO」收敛到与 GDPO 相似且高于标准 GRPO 的正确率奖励,但它在格式奖励上完全失败。这导致在 BFCL-v3 上的正确格式比例为 0%(见表 2),表明模型未能学习所需的输出结构。这说明简单地移除标准差归一化项以增加优势多样性可能会给训练引入不稳定性。

数学推理
从图 5 中 DeepSeek-R1-1.5B 的训练曲线可以看到,模型倾向于最大化更容易的奖励。在本例中,长度奖励更容易优化,GRPO 和 GDPO 都在大约前 100 个训练步内达到满分长度奖励。长度奖励的快速上升伴随着正确率奖励的早期下降,表明这两个奖励存在竞争关系。

然而,从正确率奖励轨迹来看,GDPO 比 GRPO 更有效地恢复了正确率奖励。作者还观察到 GRPO 训练在 400 步后开始不稳定,正确率奖励分数逐渐下降,而 GDPO 则继续改善。此外,尽管两者都保持了近乎完美的长度分数,但 GRPO 的最大响应长度在约 400 步后开始急剧增加,而 GDPO 的最大响应长度则持续下降。图 9 和图 10 中 DeepSeek-R1-7B 和 Qwen3-4B-Instruct 的训练曲线也显示出类似的观察结果。

表 3 的基准测试结果表明,GDPO 训练的模型不仅在推理效率上比原始模型取得显著提升(AIME 上超长比例降低高达 80%),而且在大多数任务上也取得了更高的准确率。对于 DeepSeek-R1-1.5B,GDPO 在所有基准测试上都优于 GRPO,在 MATH、AIME 和 Olympiad 上分别取得了 2.6%/6.7%/2.3% 的准确率提升。DeepSeek-R1-7B 和 Qwen3-4B-Instruct 也呈现类似趋势,GDPO 在更具挑战性的 AIME 基准测试上将准确率提高了近 3%,同时将超长率分别降低至 0.2% 和 0.1%。

代码推理
作者在代码推理任务上检验 GDPO 在优化两个以上奖励时是否仍然优于 GRPO。如表 5 所示,在双奖励设置下,GDPO 在所有任务上都提升了通过率,同时保持相似的超长比例。例如,GDPO 在 Codecontests 上将通过率提高了 2.6%,而超长比例仅增加 0.1%;在 Taco 上取得了 3.3% 的通过率提升,同时将超长违规降低了 1%。

在三奖励设置下也呈现类似模式,GDPO 在所有目标上都实现了更有利的平衡,在保持与 GRPO 相似通过率的同时,显著降低了超长比例和 bug 比例。
总体而言,这些结果表明 GDPO 在奖励信号数量增加时仍然有效,在双奖励和三奖励配置中都始终比 GRPO 实现更优的跨目标权衡。
....
#Exploring the Vulnerabilities of Federated Learning: A Deep Dive into Gradient Inversion Attacks
联邦学习不再安全?港大TPAMI新作:深挖梯度反转攻击的内幕
本文第一作者郭鹏鑫,香港大学博士生,研究方向是联邦学习、大模型微调等。本文共同第一作者王润熙,香港大学硕士生,研究方法是联邦学习、隐私保护等。本文通讯作者屈靓琼,香港大学助理教授,研究方向包含 AI for Healthcare、AI for Science、联邦学习等 (个人主页:https://liangqiong.github.io/)。
联邦学习(Federated Learning, FL)本是隐私保护的「救星」,却可能因梯度反转攻击(Gradient Inversion Attacks, GIA)而导致防线失守。
近日,香港大学、香港科技大学(广州)、南方科技大学、斯坦福大学、加州大学圣塔克鲁兹分校的研究团队合作,在人工智能顶级期刊 IEEE TPAMI 上发表重磅工作,对 GIA 进行了全方位的分类、理论分析与实验评测,并提出了切实可行的防御指南。
- 论文标题: Exploring the Vulnerabilities of Federated Learning: A Deep Dive into Gradient Inversion Attacks
- 论文地址: https://ieeexplore.ieee.org/document/11311346
- 项目主页: https://pengxin-guo.github.io/FLPrivacy/
01 背景:联邦学习真的安全吗?
联邦学习(FL)作为一种隐私保护的协同训练范式,允许客户端在不共享原始数据的情况下共同训练模型。然而,近年来的研究表明,「不共享数据」并不等于 「绝对安全」。
攻击者可以通过梯度反转攻击(GIA),仅凭共享的梯度信息就能重建出客户端的私有训练数据(如人脸图像、医疗记录等)。尽管学术界提出了许多 GIA 方法,但一直缺乏对这些方法的系统性分类、深入的理论分析以及在大规模基准上的公平评测。
为了填补这一空白,本研究对 GIA 进行了抽丝剥茧般的深度剖析。

02 方法分类:GIA 的三大门派
研究团队首先对现有的 GIA 方法进行了系统性梳理,将其归纳为三大类:
1. 基于优化的攻击 (OP-GIA):
- 原理:通过迭代优化虚拟数据,使其产生的梯度与真实梯度之间的距离最小化。
- 代表作:DLG、Inverting Gradients、GradInversion 等。
2. 基于生成的攻击 (GEN-GIA):
- 原理:利用预训练的生成模型(GAN 或 Diffusion Model)作为先验,来生成近似的输入数据。
- 细分:优化隐向量 z、优化生成器参数 W、或训练逆向生成模型。
3. 基于分析的攻击 (ANA-GIA):
- 原理:利用全连接层或卷积层的线性特性,通过解析解(Closed-form)直接恢复输入数据。
- 特点:通常需要恶意的服务器修改模型架构或参数。
03 理论突破:误差边界与梯度相似性
不同于以往的经验性研究,本文在理论层面做出了重要贡献:
- Theorem 1(误差边界分析):首次从理论上证明了 OP-GIA 的重建误差与 Batch Size(批量大小)和图像分辨率的平方根呈线性关系。这意味着,Batch Size 越大、分辨率越高,攻击难度越大。

- Proposition 1(梯度相似性命题):揭示了模型训练状态对攻击的影响。如果不同数据的梯度越相似(例如在模型训练后期),攻击恢复数据的难度就越大。

04 实验发现:谁是真正的威胁?
研究团队在 CIFAR-10/100、ImageNet、CelebA 等数据集上,针对不同攻击类型进行了广泛的实验(涵盖 ResNet、ViT 以及 LoRA 微调场景)。

关键结论(Takeaways):
- OP-GIA 最实用,但受限多:它是最实用的攻击设置(无额外依赖),但效果受限于 Batch Size 和分辨率。且在 Practical FedAvg(多步本地训练)场景下,其威胁被大幅削弱。
- GEN-GIA 依赖重,威胁小:虽然能生成高质量图像,但严重依赖预训练生成器、辅助数据集或特定的激活函数(如 Sigmoid)。如果目标模型不用 Sigmoid,很多 GEN-GIA 方法会直接失效 。
- ANA-GIA 效果好,易暴露:通过修改模型架构或参数,ANA-GIA 可以实现精准的数据恢复。但这种「做手脚」的行为非常容易被客户端检测到,因此在实际中难以得逞 。
- PEFT (LoRA) 场景下的新发现:在利用 LoRA 微调大模型时,攻击者可以恢复低分辨率图像,但在高分辨率图像上往往失败。且预训练模型越小,隐私泄露风险越低 。

05 防御指南:三步走策略
基于上述深入分析,作者为联邦学习系统的设计者提出了一套「三阶段防御流水线」,无需引入复杂的加密手段即可有效提升安全性 :
1. 网络设计阶段:
- 拒绝 Sigmoid:避免使用 Sigmoid 激活函数(易被 GEN-GIA 利用)。
- 增加复杂度:采用更复杂的网络架构,增加优化难度。
2. 训练协议阶段:
- 增大 Batch Size:根据理论分析,大 Batch 能有效混淆梯度。
- 多步本地训练:采用 Practical FedAvg,增加本地训练轮数,破坏梯度的直接对应关系。
3. 客户端校验阶段:
- 模型检查:客户端在接收服务器下发的模型时,应简单校验模型架构和参数,防止被植入恶意模块(防御 ANA-GIA)。
06 总结
这项发表于 TPAMI 的工作不仅是对现有梯度反转攻击的一次全面体检,更是一份实用的联邦学习安全避坑指南。它告诉我们:虽然隐私泄露的风险真实存在,但通过合理的设计和协议规范,我们完全可以将风险控制在最低水平。
....
#华.人研究员创立视觉AI公司
在谷歌深耕14年,华人研究员创立视觉AI公司,计划融资5000万美元
最新消息,两名华人前谷歌资深研究员正创立一家全新的视觉 AI 公司,致力于打造能够同时理解和处理文本、图像、视频与音频的前沿 AI 模型。
这两位华人是:在 Google DeepMind 工作 14 年后离职的资深 AI 研究员 Andrew Dai(戴明博),以及前苹果 AI 研究科学家,曾在谷歌研究部门工作的 Yinfei Yang (杨寅飞)。
戴明博表示,这家名为 Elorian 的新公司目前正在与投资人洽谈,计划完成一轮约 5000 万美元的种子融资。知情人士透露,由前 CRV 普通合伙人 Max Gazor 于去年 10 月创立的风投机构 Striker Venture Partners 正在洽谈领投该轮融资。
戴明博本科毕业于英国剑桥大学计算机科学专业,随后在爱丁堡大学获得机器学习方向博士学位。在攻读博士期间,他曾两次在谷歌进行软件工程实习,博士毕业后于 2012 年正式加入谷歌,开启了长达 14 年的职业生涯,在公司内部从技术研发逐步成长为核心科研管理者。
在 Google DeepMind,他担任首席研究科学家 / 主任级别研究管理职务,负责领导与 Gemini 大型 AI 模型研发相关的数据团队工作,这一项目是 DeepMind 和 Google 在多模态大模型方向的重要战略成果。
作为深度学习与自然语言处理领域的资深研究人员,戴明博不仅在工业级 AI 项目中扮演关键角色,还与业内其他顶尖研究者合作发表过多篇学术论文,积累了丰富的科研和工程融合经验。
杨寅飞是一位资深的人工智能研究科学家,曾在 Apple AI/ML 担任研究科学家/多模态负责人,主要从事视觉与语言基础模型的研究与开发。
在加入苹果之前,他也曾在 Google Research 担任研究科学家,在自然语言处理、语义检索、多语言表示学习与多模态表示学习等方向有深入的研究与实践。 他还在 Amazon 和 Redfin 担任机器学习与计算机视觉相关的软件工程师/数据科学工程师,积累了丰富的工业研发经验。
他在视觉–语言联合表示和大规模多模态学习方面具有重要贡献,其代表性研究成果《Scaling up visual and vision-language representation learning with noisy text supervision》推动了多模态表示学习的发展。
值得注意的是,戴明博与杨殷飞目前都已在 LinkedIn 上将公司状态更新为「隐身(stealth)」,其中戴明博的资料显示其担任 CEO。就连戴明博的社交媒体上都标注了「隐身模式」。
在上周六的一次电话采访中,戴明博表示,Elorian 的核心目标是构建能够通过同时处理图像、视频与音频,对现实世界进行视觉理解与分析的多模态 AI 模型。虽然机器人也是其潜在应用方向之一,但公司还设想了更多应用场景,暂未对外披露具体细节。
参考链接:
https://sites.google.com/site/yinfeiyang/
https://www.linkedin.com/in/andrewdai
....
#FoundationMotion
无需人工标注,轻量级模型运动理解媲美72B模型,英伟达、MIT等联合推出FoundationMotion
当前的视频大模型发展迅速,但在面对复杂的空间移动和物理规律时,依然 “看不懂” 物体如何运动。
它们或许能描述视频中发生了什么,但如果你问它:“红色的车是在蓝色车转弯之前还是之后通过路口的?” 或者 “那个皮球的抛物线轨迹最高点在哪里?”,很多模型就开始 “胡言乱语” 了。
究其根本,在于高质量运动数据的极度匮乏。现有的数据集要么规模太小,要么依赖昂贵的人工标注,难以支撑模型去学习真实世界中细粒度的物理运动。
针对这一痛点,来自 MIT、NVIDIA、UC Berkeley 等机构的研究者提出了 FoundationMotion:一套完全不依赖人工标注的自动化数据管线。
令人惊讶的是,仅靠这套管线生成的数据微调后,15B 参数的视频模型竟在运动理解任务上,超越了 Gemini-2.5 Flash 以及 72B 参数的开源大模型:NVILA-Video-15B: 90.6% on AV-Car benchmark, Gemini-2.5-Flash: 84.1%,Qwen-2.5-VL-72B: 83.3%
- 项目主页: https://yulugan.com/projects/FoundationMotion.html
- 论文: https://arxiv.org/abs/2512.10927
- 代码: https://github.com/Wolfv0/FoundationMotion
视频模型的 “物理盲” 危机
2024 年至今,被认为是视频生成模型的爆发期。从 OpenAI 的 Sora 到各类国产模型,AI 已经能够生成极其逼真的动态画面。然而,在华丽的像素背后,一个长期被忽视的问题逐渐暴露出来:
这些模型并不真正理解物体的运动。
例如,在测试中研究人员发现:
- 它们可以生成高速行驶的赛车,却难以判断刹车究竟是发生在碰撞之前还是之后;
- 它们能描绘复杂的街景,却常常搞错行人的移动方向与相对位置关系。
比如我们上传一段一辆汽车在夜间行驶,变道,超过了前方车辆的视频给 Gemini 3 Pro Preview,问 “What is the primary driving behavior demonstrated by the ego vehicle in the video?”

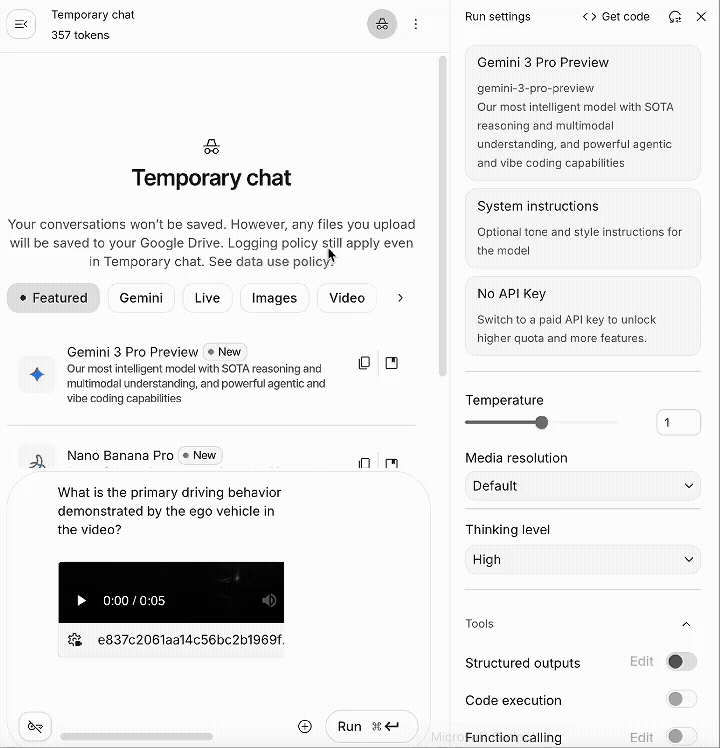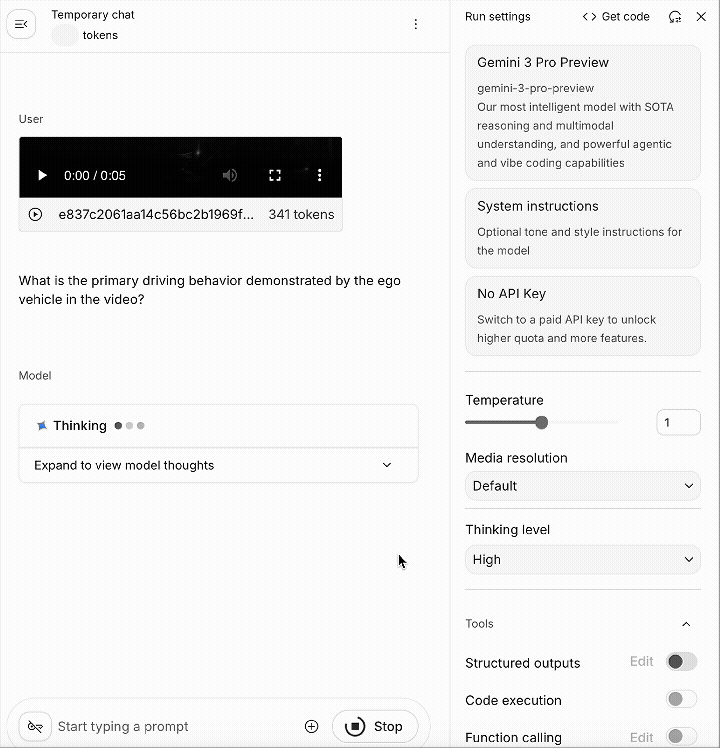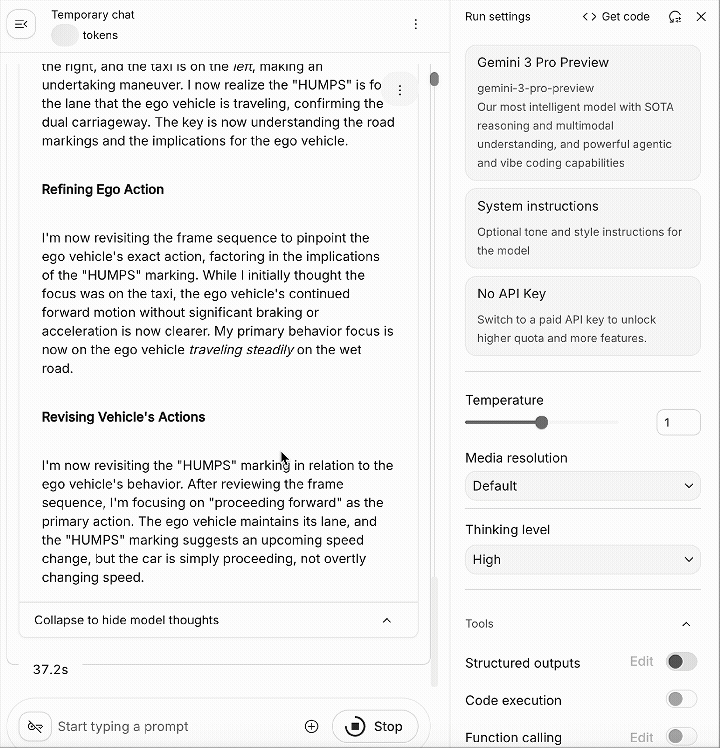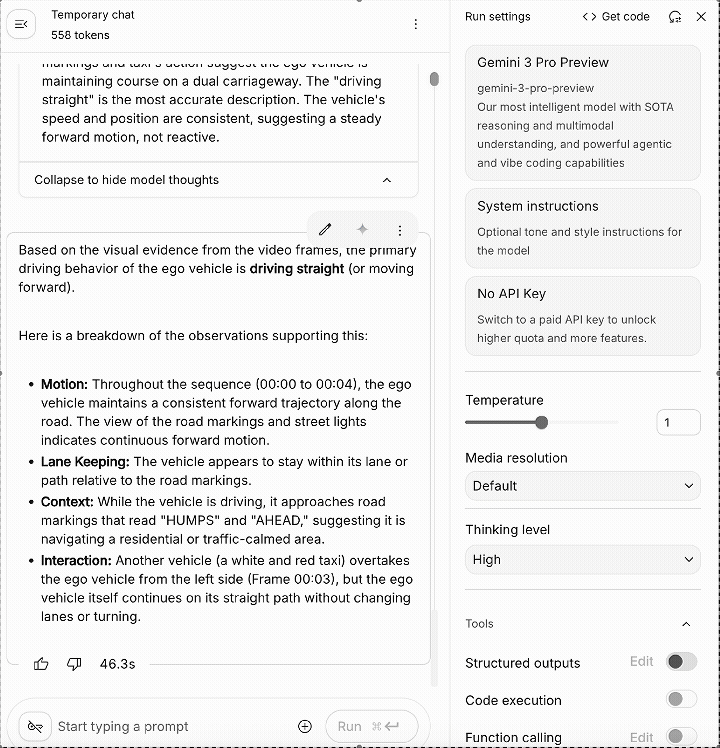
Gemini 3 Pro Preview 的回答是这辆车正在它的车道上行驶,完全没有理解这个视频最主要的运动:变道与超车。
正如心理学家 Barbara Tversky 在《Mind in Motion》中所指出的:空间与运动是人类理解世界的基础。 而这一能力,恰恰是当前视频模型最薄弱的部分。

问题的根源在于数据。现有视频数据要么只包含静态描述(如 “一只狗在草地上”),要么高度依赖昂贵、难以扩展的人工标注,使得大规模、细粒度的 “运动理解” 数据几乎无法获得。
FoundationMotion
一座全自动的 “运动数据工厂”
为了解决这一瓶颈,研究团队提出了 FoundationMotion—— 一套端到端、无需人工参与的自动化数据生成系统。
它的工作流程可以被形象地拆解为四步:

1 & 2. 预处理 & 先把 “运动” 精确地抓出来
首先,使用成熟的目标检测与跟踪模型,对视频进行逐帧分析,将人、车辆、手部、机械臂等关键物体转化为连续的时空轨迹(Trajectories)。
- 输入: 任何视频。
- 输出: 每个物体在视频中的精确运动坐标。
2. 把轨迹 “讲给” 语言模型听
仅有数字坐标对语言模型来说过于抽象,FoundationMotion 采用了多模态融合策略:
- 将轨迹转化为结构化的文本描述;
- 同时将视频帧与轨迹信息作为 Prompt 输入。
这相当于为模型提供了一份 “运动说明书”,让它不仅看到画面,还能结合坐标理解物体究竟是如何移动的。
3. 让模型生成标注与问题
研究团队利用 GPT-4o-mini,在轨迹与视频的基础上,自动生成两类高质量数据:
- 精细化运动描述:包含速度变化、方向、终止位置等细节;
- 多维度运动理解问答:覆盖动作识别、时序关系、动作 - 物体关联、空间位置以及重复计数等关键能力。
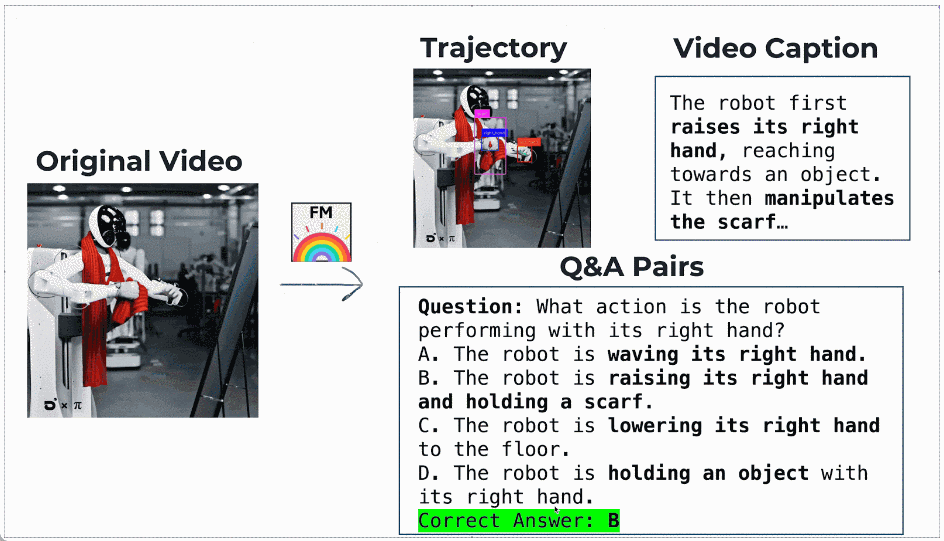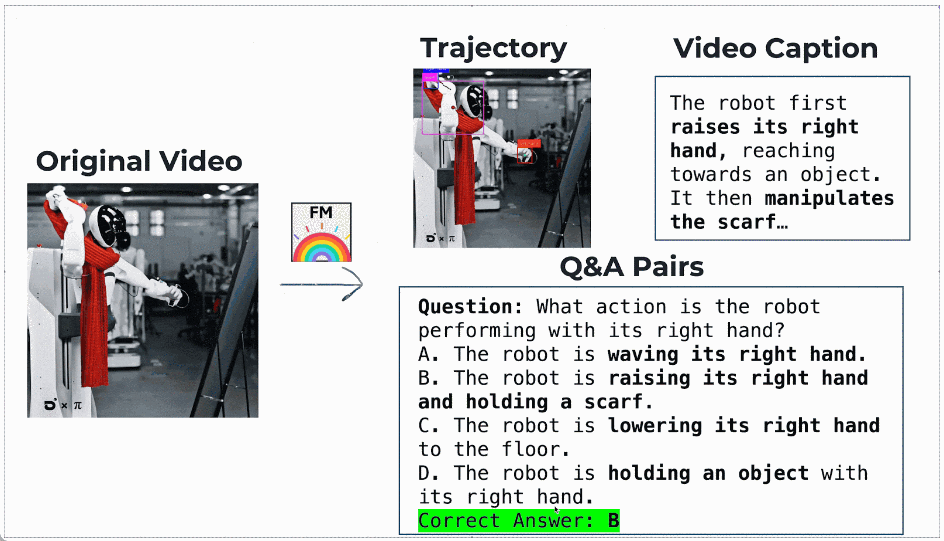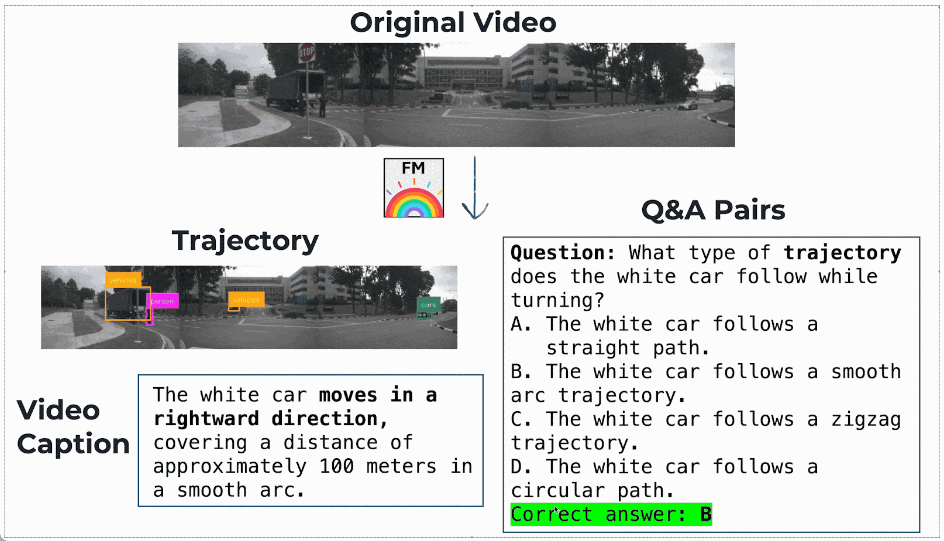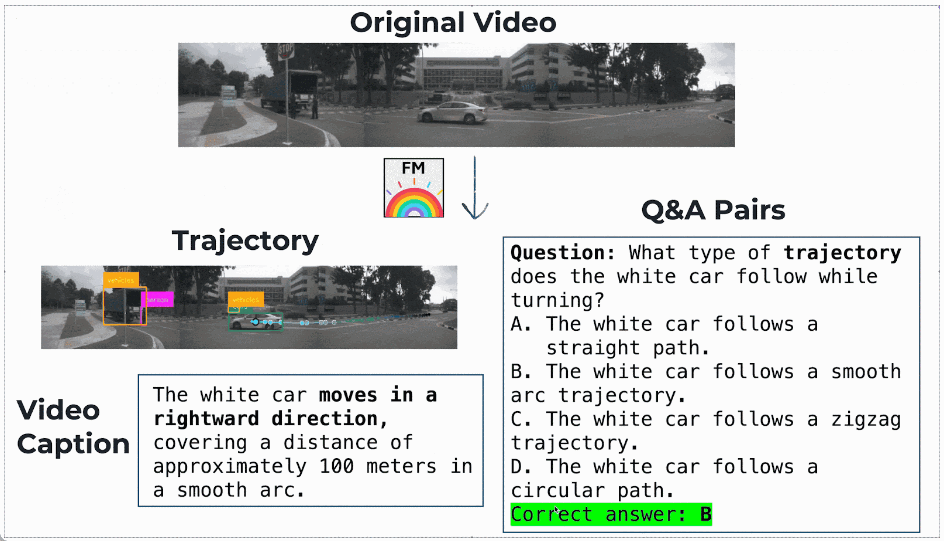
最终,团队基于 InternVid 构建了约 50 万条高质量运动理解数据,形成了 FoundationMotion 数据集。
数据样例:
小模型,击败大模型
在实验环节,研究人员使用 FoundationMotion 生成的数据微调了多个开源视频模型,包括 NVILA-Video-15B 与 Qwen2.5-7B。
结果显示,高质量数据带来的提升是巨大的:
- 越级挑战: 微调后的 7B/15B 模型在多个运动理解基准上,超越了 Gemini-2.5 Flash 与 Qwen2.5-VL-72B。
- 纯数据驱动: 这一提升不依赖额外的模型结构设计或复杂的推理策略,完全归功于数据的质量。
- 强泛化性: 在自动驾驶、机器人操作、日常活动等不同领域均具备良好表现。
- 无损通用能力: 在增强物理感知的同时,并未损害模型原本的通用视频理解能力。
通向 “物理 AI” 的关键一步
FoundationMotion 的意义远不止于刷榜。
在自动驾驶与机器人领域,“理解物体如何运动” 直接关系到系统的安全与决策能力。
FoundationMotion 提供了一条低成本、可扩展的路径,让 AI 能够通过观看海量视频,逐步建立对物理世界的直觉。这套管线未来可广泛用于:
- 视觉语言模型(VLM)
- 视觉 - 语言 - 动作模型(VLA)
- 世界模型(World Models)
这被认为是构建真正的xx智能(Embodied AI)的基础设施。
....
#Privacy on the Fly
手机传感器正在泄露隐私?PATN实时守护隐私安全
本文的作者分别来自西安交通大学和东京科学大学。第一作者宋天乐是来自西安交通大学的博士生,研究方向聚焦于人机交互行为安全,生物特征识别,隐私保护。通讯作者为西安交通大学蔺琛皓教授。
移动应用通过 Android 和 iOS 的接口能够获取加速度计、陀螺仪等运动传感器数据,这些数据支撑了活动识别、计步和手势交互等重要功能,已成为移动服务的关键基础。然而,传感器数据的细粒度特性也带来了隐私隐患。研究表明,其可以被用来推断用户性别、年龄等敏感属性,使用户在不知情的情况下遭受隐私泄露。因此,如何在保持传感器数据实用性的同时有效保护用户隐私,已成为移动应用生态中亟需解决的问题。
在 AAAI 2026 上,西安交通大学与东京科学大学提出了移动传感器隐私保护框架 PATN。该框架基于对抗攻击思想,通过微小扰动实现隐私保护同时不影响数据语义和时序结构。为应对实时防护和时间错位问题,PATN 设计了两大核心技术:利用历史传感器数据的生成网络实现未来扰动的即时预测与施加,解决实时扰动生成;引入历史感知 top-k 优化策略,缓解扰动与攻击序列的时间错位。该框架在多种数据场景下提供高保真、连续的隐私防护,有效抑制敏感属性推断,同时不影响正常应用功能,显著提升移动传感器隐私安全性。
- 论文标题:Privacy on the Fly: A Predictive Adversarial Transformation Network for Mobile Sensor Data
- 论文链接: https://arxiv.org/abs/2511.07242
- 代码链接: https://github.com/skysky4/PATN
问题定义

尽管现有隐私保护方法在传感器数据处理上已有成果,但仍存在显著局限。数据混淆和生成模型通常需缓存完整序列,难以满足实时防护需求;大多数对抗攻击方法假设可访问完整序列并按固定时间线生成扰动,而实际攻击可能随时发生,导致扰动与攻击错位,降低防护效果。由此可归纳出两大关键问题:
1. 实时扰动生成:如何在数据产生的瞬间生成未来方向的扰动,确保隐私防护能够零时延、连续地生效,而无需等待完整序列。
2. 防御与攻击的时间错位:如何保证在攻击时间与防御扰动存在偏移的情况下,扰动仍能有效覆盖目标窗口,实现持续可靠的隐私保护。
技术方法 - PATN
PATN 假设可访问开源隐私推断模型及其梯度,并利用历史传感器数据预测未来扰动,使其在最大程度干扰隐私推断的同时保持数据语义稳定。系统包含两部分:训练阶段,通过对抗效果、时间鲁棒性和平滑正则化三类损失联合优化,实现隐私保护与数据保真的平衡;设备端部署,将训练后的网络以本地方式运行,实现零时延扰动生成,从而满足实时传感器流的即时防护需求。

扰动范围:为避免扰动破坏传感器数据语义,作者对每个传感器维度的扰动幅度进行了严格限制。扰动被约束在该维度均值或标准差 5% 的范围内,确保其相对于原始信号足够微小。同时,在静态条件下测量了设备的自然传感器波动,将其作为额外的上限约束。最终,每个维度的扰动幅度取数据统计范围与自然波动范围的较小值,使扰动始终保持在用户难以察觉的正常噪声水平内。
基于历史数据的扰动生成模型:模型仅使用过去的传感器序列预测未来序列的对抗扰动,使系统在数据到达前即可提前构建防护,实现零未来依赖的实时隐私保护。模型采用序列到序列结构,由 LSTM 编码器和解码器组成。编码器提取历史序列的时序模式,将近期用户传感器动态压缩为潜在表示。解码器在不访问未来数据的情况下,自回归生成未来扰动序列:每个时间步既依赖编码器的潜在表示,也继承前一步输出,保证扰动在时间维度的连贯性。生成的扰动向量与传感器维度一一对应,可直接作用于未来数据流。
历史感知 top-k 优化策略:该策略将上一轮扰动与当前扰动拼接成新的长序列,并将其叠加到输入信号上,通过滑动窗口生成多个时间序列片段并计算对应的对抗损失,并从所有窗口损失中选取前 k 个最高值并取平均作为优化目标,使模型重点提升在 “最难防护” 的时间区域的攻击效果。通过该策略,使生成的扰动在时间上更加一致,并能在任意攻击窗口下保持稳定的隐私防护能力。
实验结果

作者在两个移动设备传感器数据集上全面评估了 PATN 的隐私保护性能。MotionSense 数据集包含用户在六种日常活动(走路、跳跃、坐、站立、上楼、下楼)下的加速度计和陀螺仪数据;ChildShield 数据集收集了用户在五类不同游戏场景下的加速度计和陀螺仪数据。隐私对抗模型采用卷积神经网络进行评估。
性能:对比现有的基线方法,在实时保护性能方面,PATN 明显优于传统方法。DP、UAP 等固定扰动策略以及 FGSM、PGD 等对抗攻击方法,均无法针对连续到达的实时传感器数据进行动态防护,且缺乏对未来数据的适应能力。PATN 通过历史数据预测生成扰动,实现零时延施加,同时保持数据的语义与时序结构,能够在连续数据流中持续有效地干扰隐私推断模型。


数据可用性:在数据可用性方面,PATN 同样优于现有方法(PrivDiffuser)。结果表明,在行为识别和步态检测等下游任务中,使用 PATN 扰动后的传感器数据几乎不影响任务性能,而 PrivDiffuser 会引入较大信号扭曲,从而降低下游任务精度。PATN 通过严格控制扰动幅度,既有效隐藏敏感信息,又保证数据在良性任务的可用性,实现隐私保护与应用性能的兼顾。

迁移性:在可迁移性方面,PATN 展现出良好的泛化能力和时间适应性。固定输出长度生成的扰动即可有效攻击不同输入长度的黑盒模型,无需针对每个模型重新优化。此外,面对结构完全不同的黑盒模型,PATN 依然维持较高的攻击成功率和 EER,证明其扰动对未知或更复杂模型同样稳健。
总结
本文提出了 PATN,一种基于历史数据的扰动生成框架,通过利用过去的传感器信号预测未来扰动,实现对实时数据的零延迟隐私保护,同时保持原始数据的时序与语义完整性。未来工作将拓展 PATN 在黑盒模型下的适用性,并覆盖更多敏感属性。
....
#斯坦福最火CS课
不让学生写代码,必须用AI
「0 代码」计算机课在教啥东西?
这就是现代的软件开发吗?
谁也想不到,斯坦福大学计算机系今年最热门的课程,居然明牌不鼓励你写代码。
近日,斯坦福大学新开设的课程《现代软件开发者》(CS146S: The Modern Software Developer)成为了 AI 圈里的热门话题。
在这门课上,主讲 Mihail Eric 告诉学生们,课程的主旨就是教你在不编写一行代码的情况下进行编程开发,「如果你能在整个课程中不写一行代码,那就太棒了。」这不是开玩笑,听课的学生必须在提交 Git 的作业里附带和 AI 的对话记录。
在这里,老师教的不是 AI 的原理或是调优方法,而是教你如何 Vibe Coding,具体来说是使用 Cursor 和 Claude 等 AI 代码工具,并在开发的过程中应对 AI 的幻觉。CS146S 在 9 月份第一次上线,直接被斯坦福的学生们挤爆,候补名单超过了 200 人,
看起来在快速发展的大语言模型(LLM)的冲击下,最令人焦虑的不再是 AI 写作业、写论文会不会认定为作弊,而是如何面对充满 AI 的世界了。
目前,CS146S 的 Slide 已经更新到了最后一周:Week 10: What's Next for AI Software Engineering,感兴趣的同学可以去观摩一下。
课程介绍
本课程历时 10 个月精心打造,是首个专注于人工智能软件原理与实践的课程。
课程主页:https://themodernsoftware.dev/
如果仔细看一下介绍,你会发现课程兼顾实用和有趣。课程资料非常齐全,涵盖完整的阅读材料、作业练习、示例代码、全套课件(PPT)等,并配套实践项目,让学习者不仅懂原理,还能真正做得出来。
当然,这门课程也有前置要求:你需要具备与 CS111 相当的编程经验(编程语言、操作系统和软件工程),与此同时推荐你已经修完了 CS221/229 的课程(高等数学、机器学习基础)。
课程安排
第一周:编码型 LLM 与 AI 开发导论。主要介绍 LLM 的基础知识,包括课程安排、LLM 的工作原理与有效提示方法。本周课程包含两次主题讲解:LLM 的构建流程,以及高级提示技巧。
第二周:编程 Agent 的内部结构。主题涵盖智能体的架构与组成、工具调用与函数调用机制,以及 MCP(模型上下文协议)的核心概念。
第三周:AI 集成开发环境(AI IDE)。本周聚焦于 AI 开发环境:包括上下文管理与代码理解、为智能体撰写 PRD,以及 IDE 的集成与扩展能力。
第四周:编码 Agent。本周主题涵盖如何管理 Agent 的自主性水平,以及人与 Agent 之间的协作模式。
第五周:聚焦现代终端(Modern Terminal)与 AI 的结合。AI 增强的命令行界面、终端自动化与脚本能力。
第六周:聚焦 AI 在测试与安全领域的应用。课程内容包括:如何进行安全意识驱动的氛围编码(secure vibe coding)、漏洞检测技术的发展历史,以及利用 AI 自动生成测试用例与测试套件。本周重点让学生理解安全编码理念与现代 AI 工具在测试中的作用。
第七周:探讨现代软件支持体系。主要内容包括如何评估并信任 AI 代码系统的可靠性、利用 AI 进行调试与诊断,以及通过智能化方式自动生成高质量文档。本周旨在帮助学生理解 AI 在软件维护与支持流程中的实际应用价值。
第八周:聚焦自动化 UI 与 App 构建。本周探讨 AI 如何让人人都能进行前端设计,并实现快速的 UI/UX 原型构建与迭代。
第九周:智能体在部署后的运行管理。AI 系统的监控与可观测性、自动化故障响应机制,以及问题分级处理与调试方法。本周旨在帮助学生理解如何确保智能体在真实环境中稳定、安全、高效地运行。
第十周:人工智能软件工程的未来发展方向。本部分内容聚焦软件开发职业的未来方向,探讨 AI 驱动下正在兴起的新型编码范式,并分析行业发展趋势与未来预测,帮助理解软件工程在 AI 时代将如何演变。
通过这十周的循序渐进学习,你会清晰看到自己从使用 AI 到构建 AI 驱动软件的转变,为成为未来的 AI 原生软件工程师打下扎实基础。
讲师介绍
Mihail Eric 是一名工程师、研究者与教育者,同时也是一家隐身创业公司 AI 部门负责人。除了《The Modern Software Developer》外,明年 Eric 还将教授一个面向专业开发者的公开版本课程,名为《AI Software Development: From First Prompt to Production Code》。
Eric 曾在斯坦福 NLP 小组(Stanford NLP Group)工作多年,与 Christopher Manning、Percy Liang 和 Christopher Potts 展开合作。
他热衷教育与知识传播:在其博客上,他撰写了许多关于机器学习、提示工程、MLOps、软件工程实践等高质量文章,帮助社区学习与成长。
虽然不让写代码的开发课已经开出来了,但你需要注意的是,掌握了有效的 AI 工具,并不意味着你可以跳过学习编程的步骤。
另外,Mihail Eric 也表示,AI 技术的发展速度很快,明年的 CS146S 内容可能会大不一样。
....
#300篇投稿50篇含幻觉,引用example.com竟也能过审
ICLR 2026还会好吗?
这届 ICLR 的烦心事还没有结束。
最近一段时间,对于 ICLR 2026 来说,真可谓是一波未平、一波又起。先是第三方机构对审稿意见的系统性统计发现,其中有 21% 完全由 AI 生成;后有 OpenReview 评审大开盒,波及到了 ICLR 2026 超过 10000 篇投稿。
今天,ICLR 2026 的审稿又被揭开一块遮羞布。事情是这样的:AI 生成内容检测平台 GPTZero 扫描了 300 篇投稿论文,发现其中有 50 篇在论文引用上至少包含一处明显的幻觉内容。

甚至有些幻觉引用还非常离谱,达到了匪夷所思的程度,就好像投稿者完全不检查一样。比如下面 GPTZero CTO 和联创 Alex Cui 在 X 分享的这个例子,投稿者给出的引用链接竟然是默认示例链接 example.com !

而在下面的例子中,作者名单就只是一串大写字母。

更令人担忧的是,这些存在幻觉内容的投稿已经经过了 3-5 名领域专家的同行评审,但他们中的绝大多数都未能识别出这些虚假的引用。
这意味着,如果这些投稿没有其他外部干预,就可能会被 ICLR 会议接收。部分投稿的平均分甚至达到了 8/10,这几乎可以确保它们被录用。
在实操过程中,GPTZero 列出了每篇论文中由检测工具标记、并由人工核实的具体幻觉示例。如下两篇论文,第一篇(TamperTok)的一篇引用论文确实存在,但所有作者都错了;第二篇(MixtureVitae)的一篇引用论文的前 3 位作者信息正确,而后七位作者不在论文中甚至是虚构出来的。

甚至还有「不存在的论文引用」。

50 篇存在幻觉内容的投稿完整如下:

上下滑动查看
存在幻觉的地方还包括:
- 作者和会议信息与引用论文相符,但标题略有不同,年份也有误;
- arXiv ID 是真实的,但引用论文的作者和标题都不同;
- 引用论文存在,但是作者和页码都是错误的;
- 能找到与 URL 对应的引用论文,但作者不匹配。
GPTZero 表示,根据 ICLR 的编辑政策,即使只有一处明确的幻觉内容,也构成伦理违规,可能导致论文被拒稿。「我们目前只扫描了 2 万篇投稿中的 300 篇,我们预计在未来几天内将发现数百篇包含幻觉内容的论文。」
科学期刊与学术会议已在 AI 重压下不堪重负
GPTZero 表示:「学期刊和学术会议正被生成式 AI、论文工厂(paper mills)和发表压力引发的投稿狂潮压垮。」
据统计,2016 年至 2024 年间,每年发表的科学文章数量激增了 48%,与此同时,撤稿和其他学术丑闻也层出不穷。许多科学会议和期刊都在苦于寻找合格的同行评审员,而评审员们则因日益增加的时间需求而感到「不堪重负」。
像 ICLR 这样的学术会议也面临着巨大的压力。ICLR 是全球最重要的人工智能研究人员年度盛会之一,然而最近许多会议投稿和同行评审都显示出 AI 撰写的迹象。这些迹象从行文冗长、滥用列举项,到伪造数据和「幻觉」,不一而足。
「幻觉检测」发现了什么?
GPTZero 表示,自今年 1 月推出「幻觉检测」(Hallucination Check)工具以来,他们已经测试了小罗伯特・肯尼迪(RFK Jr.)的「MAHA」报告、一份丑闻缠身的澳大利亚德勤(Deloitte Australia)报告以及数百份其他文件。
本周,他们用它扫描了提交给 OpenReview 的 300 篇 ICLR 论文样本集。
自动检测后,他们的工具标记了 90 篇论文,这些论文中至少包含一条在网上似乎不存在的引用。
经过人工核实,他们确定其中 50 篇论文至少包含一处真实的幻觉。
定义「幻觉」
鉴于问题的严重性 —— 毕竟这对研究人员和编辑都利害攸关,幻觉检测工具在设计上必须优先考虑准确性,提供每个来源评估的透明度,并采取审慎的态度。
GPTZero 在博客中介绍说:「它使用我们内部训练的 AI 智能体来标记文档中任何无法在网上找到的引用。这些被标记的引用并不自动等同于幻觉,因为许多档案文件或未发表的作品无法与在线来源匹配,但它们指出了哪些来源需要进一步的人工审查。」
与 ICLR 一样,GPTZero 提议由人工来判断一条有缺陷的引用究竟是 AI 生成的,还是传统错误的产物。
虽然界限可能很模糊,但他们将「幻觉」定义为:使用生成式 AI 产生的引用,这些引用似乎是对一个或多个真实来源的标题、作者和/或元数据进行了改写或拼凑。
如果一条有缺陷的引用只是单纯在网上找不到(且看起来合理,比如这个引用 Elara Voss, letter to author, October 12, 2024.),或者标题和作者明显与真实来源匹配(即使引用的其余部分极不准确),都不认为它是幻觉。
下表展示了基于以上方法论,真实引用、有缺陷的引用和幻觉引用之间的区别。(注:原文中差异部分以红色高亮显示,此处以文字内容呈现)。

类似于 GPTZero 的 AI 检测器,幻觉检测工具的假阴性率(漏报率)极低 —— 成功发现有缺陷引用的概率可达 99%。
并且由于此工具会标记任何无法在线验证的引用,因此假阳性率(误报率)会相对较高。
同行评审的未来
同行评审是学术出版的重要组成部分,但目前的体系让评审员和编辑们有些难以招架。
GPTZero 的幻觉检测为同行评审流程提供了两个关键益处。
- 将幻觉检测与 GPTZero 的 AI 检测器结合使用,允许用户同时检查 AI 生成的文本和可疑引用,甚至利用其中一个结果来验证另一个。
- 通过识别有缺陷的引用供人工审查,幻觉检测大大减少了验证文档来源所需的时间和人力。
GPTZero 表示:「我们希望,在 50 篇 ICLR 投稿中识别出这 50 个幻觉,能向那些面对投稿狂潮的人们展示幻觉检测的价值。我们的目标是让同行评审过程对每个人都更快、更公平、更透明。」
结语
如果在 AI 领域的顶级殿堂里,连基本的真实性都需要依靠另一款 AI 工具来艰难维系,这无疑是一种巨大的讽刺。
ICLR 的遭遇并非孤例,它是当下学术界大炼模型与发表压力双重挤压下的必然产物。
当生成一篇看似专业的论文只需要几秒钟,而验证它的真伪却需要耗费数小时,这种不对称的对抗正在击穿同行评审的防线。那些高达 8 分的幻觉论文,就像是潜伏在学术共同体中的特洛伊木马,嘲笑着现有的评价体系。
GPTZero 的检测结果是一个警告,也是一个契机。它提醒我们,在拥抱 AI 带来的效率红利时,必须建立起与之匹配的数字安检机制。否则,未来的学术会议可能不再是思想碰撞的火花,而变成了一场 AI 生成内容(AIGC)的自我狂欢。
我们期待 ICLR 能挺过这次水逆,但更期待整个学术界能以此为鉴:不要让劣币驱逐良币,更不要让幻觉成为常态。
参考链接:
https://gptzero.me/news/iclr-2026/
https://x.com/yaroslavvb/status/1997748956210868641
https://x.com/slashML/status/1997719788160954547
https://x.com/alexcdot/status/1997152905980268750
....
#Kimi-K2
深夜开源首个万亿模型K2,压力给到OpenAI,Kimi时刻要来了?
没想到,Kimi 的首个基础大模型开源这么快就来了。
昨晚,月之暗面正式发布了 Kimi K2 大模型并开源,新模型同步上线并更新了 API,价格是 16 元人民币 / 百万 token 输出。


这次发布赶在了最近全球大模型集中发布的风口浪尖,前有 xAI 的 Grok 4,下周可能还有谷歌新 Gemini 和 OpenAI 开源模型,看起来大模型来到了一个新的技术节点。或许是感受到了 Kimi K2 的压力,就在刚刚,奥特曼发推预告了自家的开源模型。不过,网友似乎并不看好。


本次开源的共有两款模型,分别是基础模型 Kimi-K2-Base 与微调后模型 Kimi-K2-Instruct,均可商用。
博客链接:https://moonshotai.github.io/Kimi-K2/
GitHub 链接:https://github.com/MoonshotAI/Kimi-K2
根据 Hugging Face 页面数据显示,Kimi K2 的下载量在前 20 分钟便接近了 12K。

从 LiveCode Bench、AIME2025 和 GPQA-Diamond 等多个基准测试成绩来看,此次 Kimi K2 超过了 DeepSeek-V3-0324、Qwen3-235B-A22B 等开源模型,成为开源模型新 SOTA;同时在多项性能指标上也能赶超 GPT-4.1、Claude 4 Opus 等闭源模型,显示出其领先的知识、数学推理与代码能力。



Kimi 展示了 K2 的一些实际应用案例,看起来它能自动理解如何使用工具来完成任务。它可以自动地理解所在的任务环境,决定如何行动,在下达任务指令时,你也不需要像以往那样为智能体列出详细的工作流程。
在完成复杂任务工作时,Kimi K2 会自动调用多种工具实现能力边界的扩展。昨天上线后,网友们第一时间尝试,发现可以实现不错的效果:
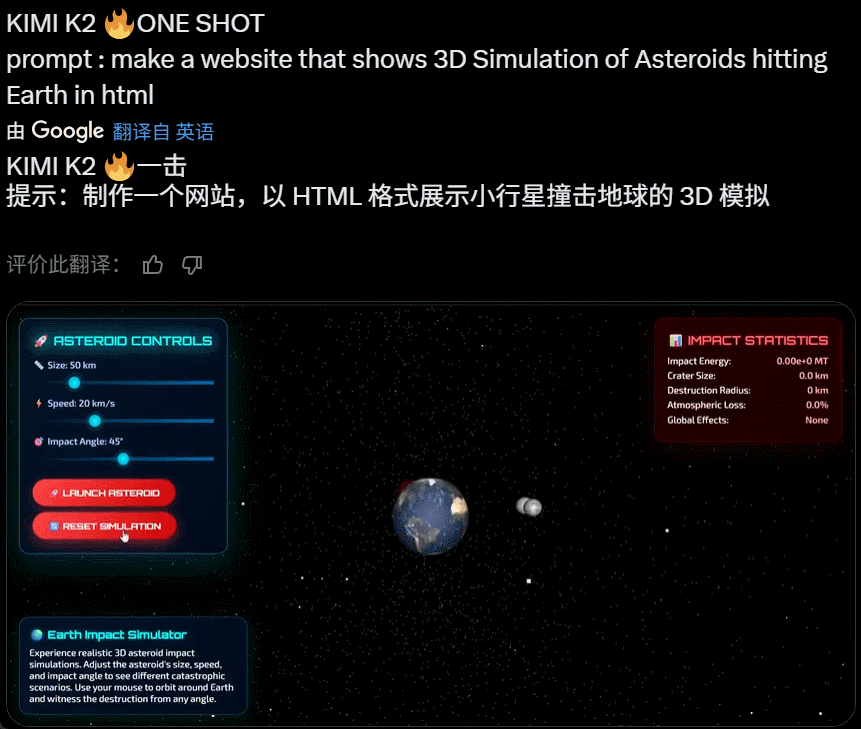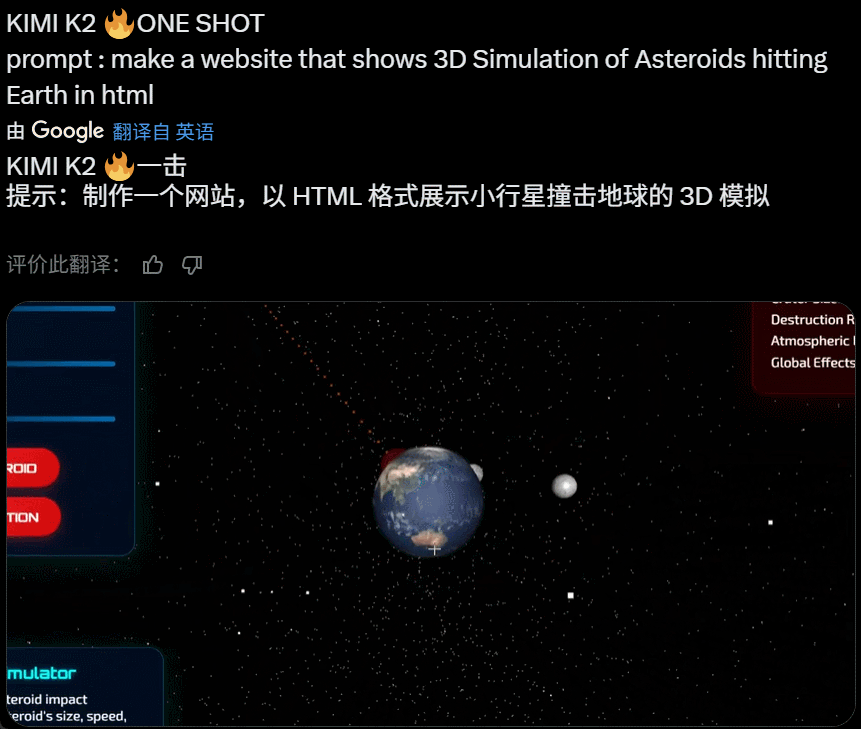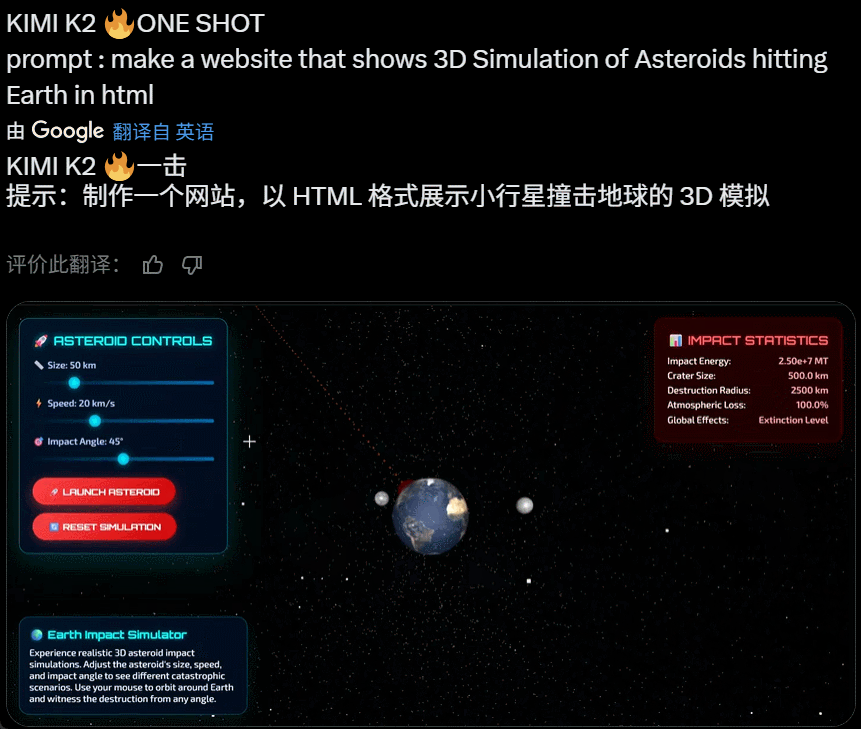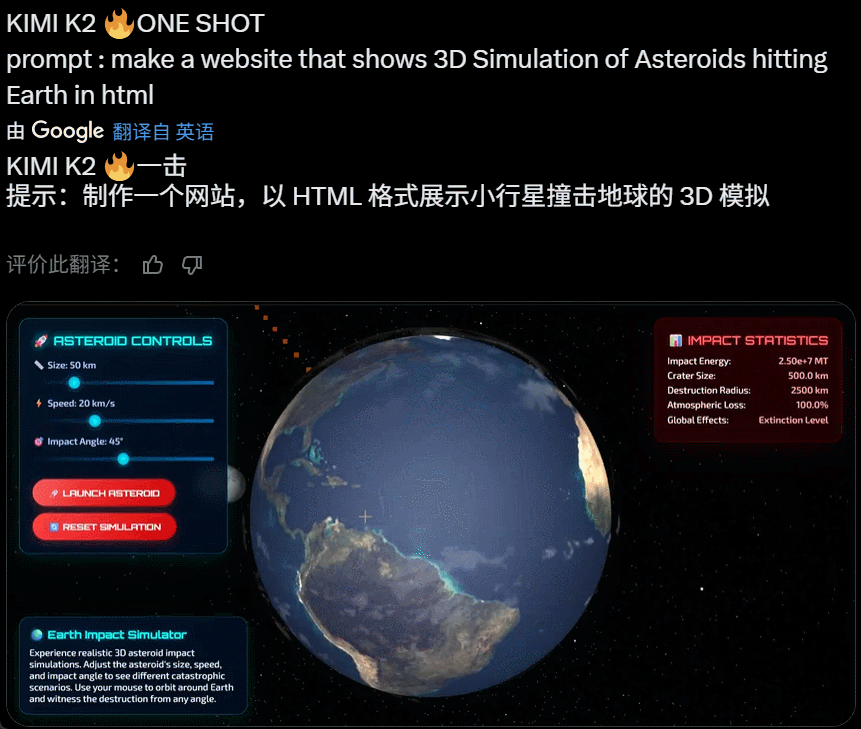
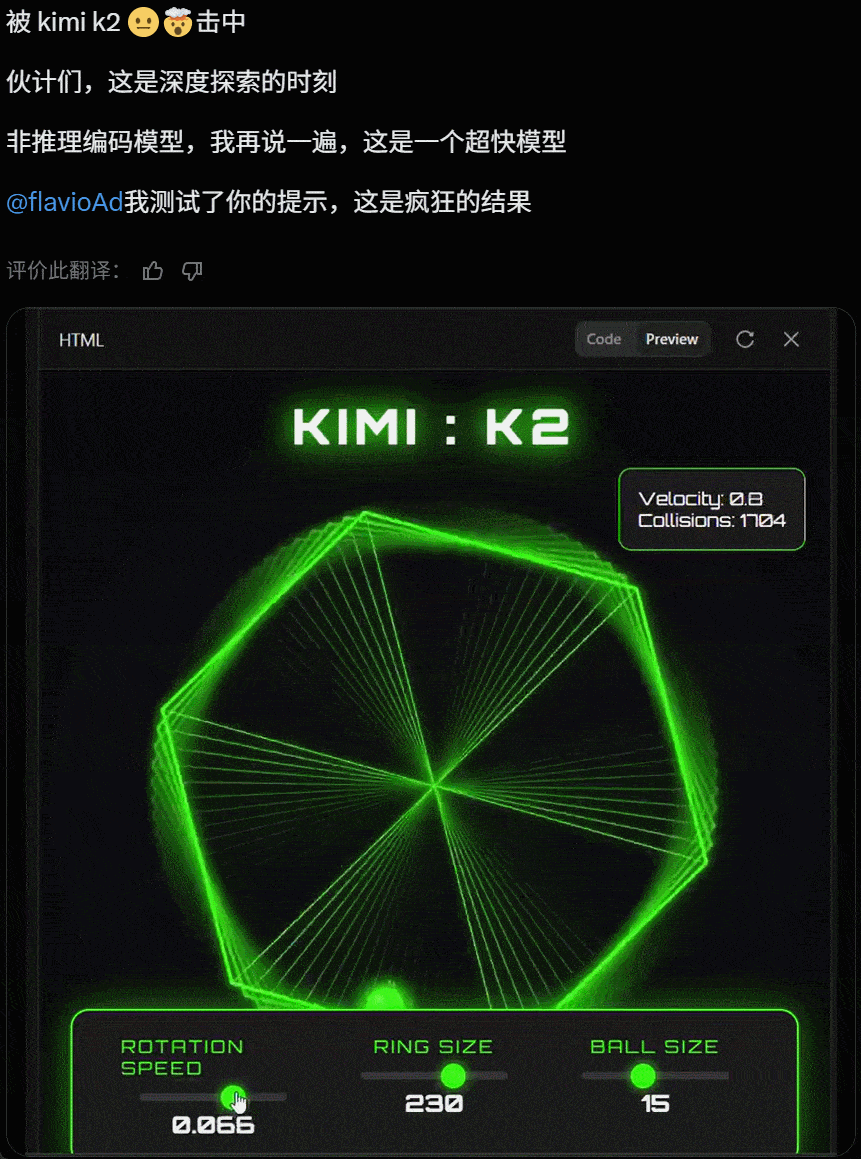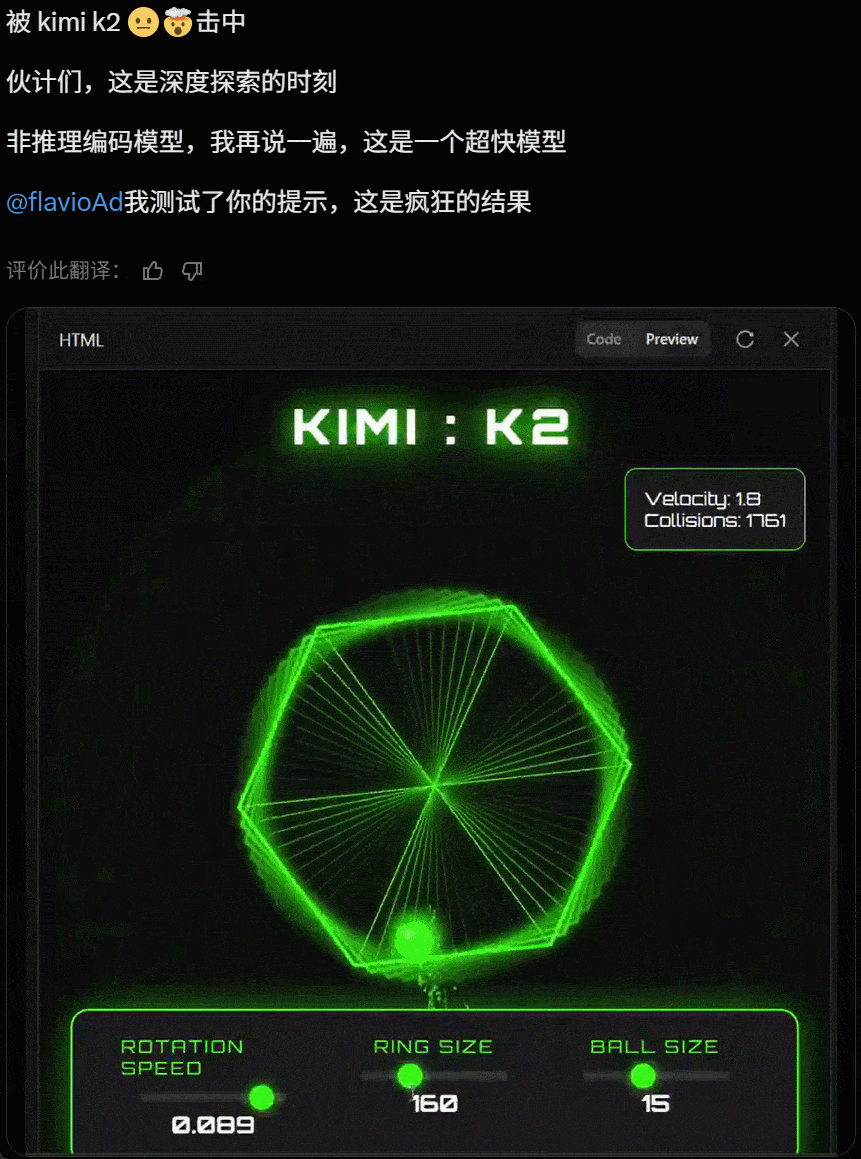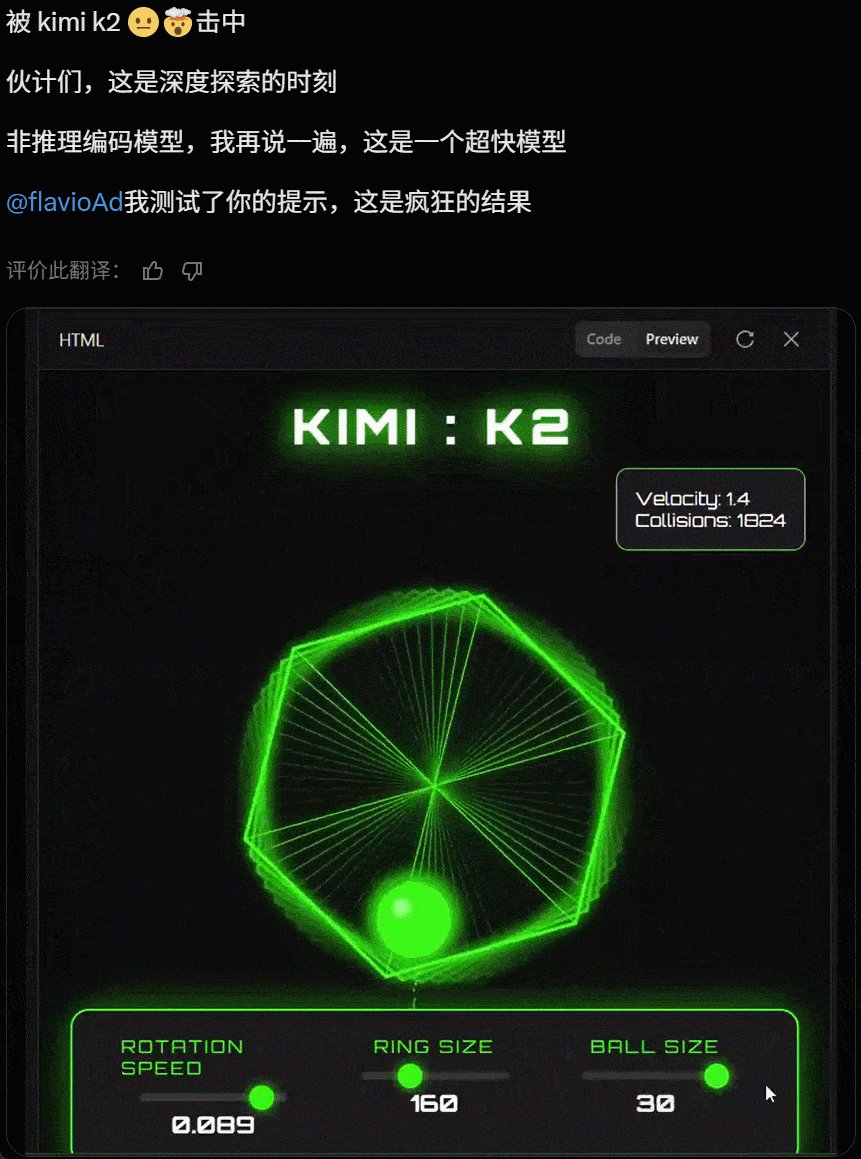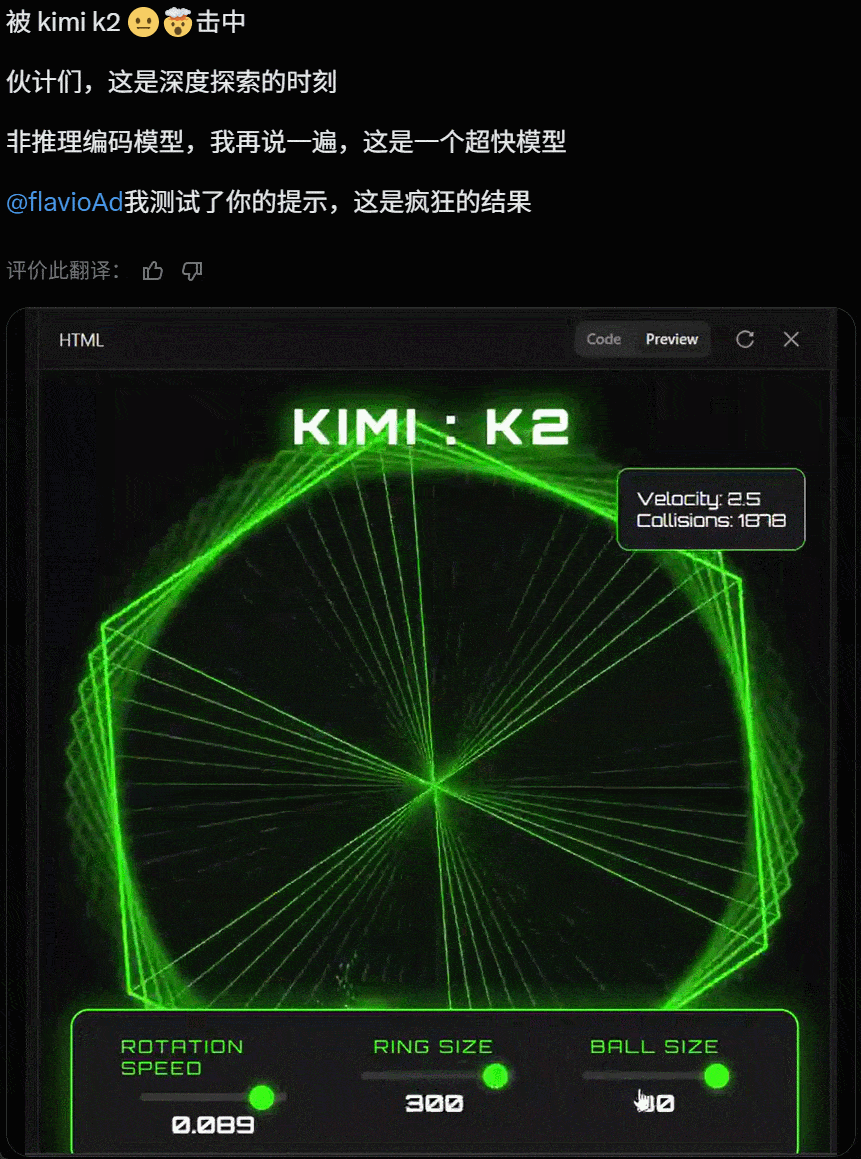
值得关注的是,就在昨天 Grok 4 发布后,人们第一时间测试发现其代码能力飘忽不定,但看起来 Kimi K2 的代码能力经住了初步检验。

网友使用 Claude Code 链接 Kimi K2,发现效果不错。
从网友第一时间的测试来看,K2 代码能力是个亮点,因为价格很低,大家发现它可能是 Claude 4 Sonnet 的有力开源平替。有网友直接说 K2 是代码模型的 DeepSeek 时刻:

HuggingFace 联合创始人 Thomas Wolf 也表示,K2 令人难以置信,开源模型正在挑战最新的闭源权重模型。

在技术博客中,Kimi 也介绍了 K2 训练中的一些关键技术。
预训练数据 15.5T tokens
没用传统 Adam 优化器
首先,为了解决万亿参数模型训练中稳定性不足的问题,Kimi K2 引入了 MuonClip 优化器。
Muon 优化器作为一种优化算法,可以帮助神经网络在训练过程中更好地收敛,提升模型准确性和性能。今年 2 月,月之暗面推出了基于 Muon 优化器的高效大模型 Moonlight,证明这类优化器在 LLM 训练中显著优于当前广泛使用的 AdamW 优化器。
此次,Kimi K2 在开发过程中进一步扩展 Moonlight 架构。其中基于 Scaling Laws 分析,月之暗面通过减少 Attention Heads 数量来提升长上下文效率,同时增加 MoE 稀疏性来提高 token 利用效率。然而在扩展中遇到了一个持续存在的挑战:Attention logits 爆炸会导致训练不稳定,而 logit 软上限控制和 query-key 归一化等现有方案对此的效果有限。
针对这一挑战,月之暗面在全新的 MuonClip 中融入了自己提出的 qk-clip 技术,在 Muon 更新后直接重新缩放 query 和 key 投影组成的权重矩阵,从源头上控制 Attention logits 的规模,实现稳定的训练过程。
改进后的 MuonClip 优化器不仅可以扩展到 Kimi K2 这样万亿参数级别的 LLM 训练,还将大幅度提升 token 效率。一个更具 token 效率的优化器更能提升模型智能水平,这正是当前业界(如 Ilya Sutskever)看重的延续 Scaling Laws 的另一关键系数。
Kimi K2 的实验结果证实了这一点:MuonClip 能够有效防止 logit 爆炸,同时保持下游任务的性能。官方称,Kimi K2 顺利完成 15.5T tokens 的预训练,过程中没有出现任何训练尖峰,形成了 LLM 训练的一套新方法。

token 损失曲线
因此,相较于原始 Muon,MuonClip 取长补短,进一步放大其在预训练过程中的优势。自大模型技术爆发以来,优化器的探索方向不再是热门,人们习惯于使用 Adam,而如果想要进行替换,则需要大量的验证成本。Kimi 的全新探索,不知是否会成为新的潮流。
其次,为了解决真实工具交互数据稀缺的难题,Kimi K2 采用大规模 Agentic 数据合成策略,并让模型学习复杂工具调用(Tool Use)能力。
本周四,我们看到 xAI 的工程师们在发布 Grok 4 时也强调了新一代大模型的多智能体和工具调用能力,可见该方向正在成为各家公司探索的焦点。
Kimi 开发了一个受 ACEBench 启发的综合 pipeline,能够大规模模拟真实世界的工具使用场景。具体来讲,该流程系统性地演化出涵盖数百个领域的数千种工具,包括真实的 MCP 工具和合成工具,然后生成数百个具有多样化工具集的智能体。

大规模 Agentic 数据合成概览
接下来,这些智能体与模拟环境、用户智能体进行交互,创造出逼真的多轮工具使用情景。最后,由一个大语言模型(LLM)充当评判员,根据任务评分标准(rubrics)评估模拟结果,筛选出高质量的训练数据。
一整套流程走下来,这种可扩展的 pipeline 生成了多样化、高质量的数据,有效填补特定领域或稀缺场景真实数据的空白。并且,LLM 对数据的评估与筛选有效减少低质量数据对训练结果的负面影响。这些数据层面的增强为大规模拒绝采样和强化学习铺平了道路。
最后,Kimi K2 引入了通用强化学习(General RL),通过结合 RL 与自我评价(self-judging)机制,在可验证任务与不可验证任务之间架起了一座桥梁。
在数学、编程等可验证任务上,我们可以根据正确答案、任务完成情况等可验证的奖励信号持续更新并改进对模型能力的评估。但是,传统强化学习由于依赖明确的反馈信号,因而在生成文本、撰写报告等不可验证任务中很难给出客观、即时的奖励。
针对这一局限,通用强化学习通过采用自我评价机制,让模型充当自己的评判员(critic),提供可扩展、基于 rubrics 的反馈。这种反馈替代了外部奖励,解决了不可验证任务中奖励稀缺的问题。 与此同时,基于可验证奖励的策略回滚(on-policy rollouts),持续对评判员进行更新,使其不断提升对最新策略的评估准确性。
这种利用可验证奖励来改进不可验证奖励估计的方式,使得 Kimi K2 既能高效地处理传统可验证任务,又能在主观的不可验证任务中自我评估,从而推动强化学习技术向更广泛的应用场景扩展。
从长远来看,Kimi K2 的这些新实践让大模型具备了在各种复杂环境中持续优化的能力,可能是未来模型智能水平继续进化的关键。
接下来,基模卷什么
Kimi 的发布,让我们想起前天 xAI 的 Grok-4 发布会,马斯克他们宣传自己大模型推理能力时,列出了基于通用 AI 难度最高的测试「人类最后的考试」Humanities Last Exam(HLE)上几个重要突破节点。
其中 OpenAI 的深度研究、Gemin 2.5 Pro 和 Kimi-Reseracher 都被列为了重要的突破:

Kimi-Researcher 在上个月刚刚发布,其采用端到端自主强化学习,用结果驱动的算法进行训练,摆脱了传统的监督微调和基于规则制或工作流的方式。结果就是,探索规划的步骤越多,模型性能就越强。
而在 Kimi K2 上,月之暗面采用了与 Grok 4 类似的大规模工具调用方式。
另外,我们可以看到,由于国内算力资源的紧缺局面,新一波大模型技术竞争已经逐渐放弃单纯的堆参数、算力规模扩大的方式,在推动模型 SOTA 的过程中,通过算法上的创新来卷成本和效率成为趋势。
....
#多视图自回归 (MVAR)
多视图生成新范式-利用自回归模型探索多视图生成
本文第一作者包括北京大学博士生胡珈魁与清华大学硕士生杨羽霄;通讯作者为北京大学助理教授卢闫晔与(前)百度视觉技术部刘家伦。
本文介绍并开发了一种自回归生成多视图图像的方法 MVAR 。其目的是确保在生成当前视图的过程中,模型能够从所有先前的视图中提取有效的引导信息,从而增强多视图的一致性。
MVAR 拉近了纯自回归方法与最先进的基于扩散的多视图图像生成方法的生成图像质量,并成为能够处理同时多模态条件的多视图图像生成模型。
- 论文地址:https://arxiv.org/pdf/2506.18527
- 代码地址:https://github.com/MILab-PKU/MVAR/
推理代码、权重、渲染的 GSO 及其配套的 Prompt 已全部开源。
背景与动机
根据人工指令生成多视图图像对于 3D 内容创作至关重要。主要挑战在于如何在多视图之间保持一致性,以及如何在不同条件下有效地合成形状和纹理。此前的工作主要使用 Diffusion 模型中自带的多视角一致性先验,促进多视角一致图像生成。但是 Diffusion 模型存在一些先天劣势:
- 绝大多数 Diffusion 模型同时多个视角;
- 单一 Diffusion 模型难以接受多模态控制条件;

如上图左所示,当使用 Diffusion 模型从相隔较远的视角合成图像时,参考图像和目标图像之间的重叠度会显著降低,从而削弱了参考引导的有效性。
在极端情况下,例如从前视角生成后视角图像,由于重叠纹理极少,视觉参考信息几乎可以忽略不计。这种有限的参考信息可能会导致模型生成的多视角图像不够一致。
为了解决这一局限性,我们提出采用自回归 (AutoRegressive, AR) 生成方法进行多视图图像生成。
如上图右所示,在基于 AR 的生成中,模型利用前 n-1 个视图的信息作为生成第 n 个视图的条件,从而允许模型利用先前生成的视图的信息。在从前视图参考生成后视图的场景中,AR 生成模型会从先前的视图中提取足够且相关的参考。
值得注意的是,AR 生成过程与人类观察 3D 物体的方式高度一致。人类也是按照一个特定且连续的路径观察物体的多个视角,而非如 Diffusion 一样同时观察多个视角。
受此概念的启发,我们提出了多视图自回归 (MVAR) 模型。
MVAR
MVAR 的主要目的是探究 AR 形式(此处的 AR 是狭义上的 AR 模型,仅仅指代 next token prediction 这一范式)的生成方法在多视角生成问题中的优势、劣势(及其对应的解决方案)。
我们将首先简单介绍什么是基于自回归的图像生成。
前置知识:什么是 AR 生成?
给定一个长度为 T 的序列 x,AR 模型试图根据以下公式推导其分布:

其中, x_i 表示序列 x 中的第 i 个数据点,

表示索引小于 t 的向量。训练 AR 模型 p_θ 意味着该模型将在大规模图像序列上学习如何优化

。
在一般的图像生成任务中,x 来源于视角编码器 ε(⋅) ,如:VQGAN、量化器 Q 、及其码本 Z 。从图像 I 到序列 x 的公式如下:

其中, lookup (Z,v) 表示从码本 Z 中检索第 v 个向量。 x 的上标 (i-1)*w+j 表示 x 被展平,即原本位于二维坐标 (i,j) 的数据被变换到其一维对应位置 (i-1)*w+j 。
多视角图像生成中的AR
多视角情况下,由于存在多张图象,其相对于一般的 2D 图像多出了一个维度,这一维度可以被简单的理解成「时间」维度。
与视频不同,视频的不同帧之间有固定的时序关系,多视角图像之间并没有固定的时序关系,我们可以从很多条不同的时序轨迹去合成多视角图像。这一问题我们将在后续讨论。
于是,我们可将上式进行简单的扩展,使得 AR 能够适配多视角图像生成:

其中, n 代表第 n 个视角。
AR模型生成多视角图像有何问题
多视图生成的多条件控制、有限的训练数据,为 AR 在多视角图像任务的应用带来了许多阻碍。本博文简要介绍了其中两点:
- 多模态条件控制。生成多视图图像的任务需要模型能够熟练地从各种条件中提取特征,并生成与给定条件保持一致的多视图图像。AR 模型中条件注入的方法尚未得到广泛研究,如:相机姿态、参考图像和几何形状。
- 有限的高质量数据。经验表明,AR 模型需要大量高质量数据(例如数十亿条文本)才能实现饱和的模型训练。然而,3D 物体与高质量多视图图像的样本匮乏,严重阻碍了 MVAR 模型训练的充分性。
MVAR给出的解决方案
我们分别针对这些问题给出了特定的解决方案。
多模态条件嵌入网络架构:文本、相机位姿、图像、几何。

我们通过一些架构设计解决多模态条件嵌入,并试图避免简单的 in-context 条件注入形式可能带来的多模态塌缩问题。MVAR 的具体的网络架构如上图所示,其基础模型架构参考了 LLaMa;对于不同的模态,我们使用的条件注入方法整理如下:
- 文本:分离式自注意力机制 (SSA);
- 相机位姿:位置编码(将相机位姿进行普朗克编码后);
- 参考图像:图像变换与逐 token 加法;
- 几何:in-context.
以上条件注入结构设计遵从以下核心原则:
- 与输出能大致逐像素匹配的(如:普朗克编码后的相机位姿、参考图像、深度图),使用逐像素加法进行条件注入;
- 完全不能逐像素匹配的(如:文本、几何),使用 in-context 条件注入。
具体来说,对于文本和几何,我们主要基于 in-context 条件注入形式,并引入了条件与内容分离的自注意力形式,公式如下:

其中

是文本特征,

是图像特征。 Concat(⋅) 在 token 维度上连接特征,而 Chunk(⋅) 是 Concat(⋅) 的逆运算。SSA 的宗旨是在引入条件的同时,不改变条件在 token 维度的分布。
对于相机位姿和参考图像,我们主要基于逐像素加法这一条件注入形式。
对于参考图像,其特征

在传入 MVAR 前,需要与相机位姿

进行交叉注意力,从而将第 n 个视角的参考图像特征图初步变换到第 m 个视角。
值得注意的是,相机位姿与参考图像的条件在 token 维度存在错位:
- 相机位姿用于提示 MVAR ,下一 token 应当生成何种视角下哪一 patch 的图像内容,所以其相对于生成的 token 需要进行错位。(类似 RAR 一文中的 target-aware position embedding)
- 参考图像用于告知 MVAR ,当前 token 的生成应当与给定的条件特征逐像素的对应,所以其与生成 token 并无错位。
数据增强
我们主要提出了适配自回归式生成的 Shuffle View (ShufV) 数据增强策略,他的动机在于通过使用不同 order 的相机路径作为训练从而增广有限的高质量数据。其公式如下:

其中 S 表示随机序列。

表示第 n 个视图的图像现在被用作训练序列 x 中的第

个视图。
由于 self attention 和 FFN 都具有置换等变性。因此,输入序列顺序的变化将导致模型中间特征序列顺序的相应变化。为了确保辅助条件(例如相机姿态和参考图像)能够有效地引导模型按照预定顺序生成图像,必须重新排列这些条件。这种重新排序将确保条件序列与输入序列的序列对齐。
我们认为 ShufV 在增广有限的高质量数据问题的同时,有助于缓解多模态条件控制中的部分问题:
AR 模型难以利用连续视图和当前视图之间的重叠条件。
使用 ShufV 进行数据增强时,视图的顺序不是固定的。假设输入序列 x 中存在两个视图 A 和 B。ShufV 使 MVAR 能够在训练阶段获得从视图 A 到视图 B 以及 视图 B 到视图 A 的转换。这允许模型利用当前视图和其他视图之间的重叠条件并有效地使用它们。
渐进式学习
最后,我们使用渐进式学习,将模型从仅接受文本条件的 text to multi-view image (t2mv) 模型泛化到 any to multi-view image (x2mv) 模型。
在 x2mv 模型的训练过程中,文本条件会被随机丢弃,而其他条件则会随机组合。当文本提示被丢弃时,它会被替换为与目标图像无关的语句。例如,可以使用诸如 「Generate multi-view images of the following <img>」 之类的 prompt 。在这种情况下,「<img>」 表示将在文本之后组合参考图像。如果后续元素是几何形状,则将 「<img>」 替换为 「<shape>」。这种渐进式学习使模型能够受到训练期间引入的新条件的影响,同时保持对文本提示的一定程度的遵循。
实验结果
MVAR 拉近了基于 AR 的多视角生成模型与现有的 Diffusion 模型的差距,并展示出更强的指令遵从与多视角一致性。

图生多视角图像
与一些先进的基于 Diffusion 的方法的数值指标比较如下:

其中,红色表示最优、蓝色表示次优。
MVAR 的表现上有着最高的PSNR、次优的SSIM,但在LPIPS这一感知指标上仍有些逊色。更高的PSNR意味着生成的视角与对应的GT能更好的进行颜色、形状、物体位置上的对齐;略低的 LPIPS 意味着 MVAR 在实际图像质量上可能相对于Diffusion略逊一筹。
我认为 MVAR 生成的图像感知质量较差的原因是因为 MVAR 使用的基础模型 LLamaGen 相比 Diffusion-based 方法使用的基础模型 SD 系列要差一些。不过随着现有基于 AR 的图像生成基础模型的发展,我相信基于 AR 的多视角生成的感知质量将会很快追上并超过已有 Diffusion-based 方法。

文生多视角图像

文+几何生多视角图像(纹理生成)
更多结果欢迎大家在 arxiv 查看,或在 github 上下载代码与权重自行生成。
未来工作
- 更优的标记器。本文未使用 3D VAE 的原因是:其编码过程中视图之间会进行信息交换,这与我们研究的核心动机相悖。我们将在未来专注于通过使用连续的因果 3D VAE 对多视图图像进行分词来提升性能。
- 统一生成和理解。本研究使用增强现实 (AR) 模型来完成多视图图像生成任务。在未来的工作中,我们希望利用自回归模型的通用学习能力来统一多视图生成和理解任务,尤其是在难以获得高精度 3D 数据的场景理解生成任务上。
....
#Fast-in-Slow
模拟大脑功能分化!北大与港中文发布Fast-in-Slow VLA,让“快行动”和“慢推理”统一协作

作者简介:由来自北京大学、香港中文大学、北京智源研究院、智平方的老师同学联合研究,作者包括博士生陈浩、刘家铭、顾晨阳、刘卓洋,通讯作者为北京大学仉尚航。北京大学 HMI 实验室长期致力于xx智能和多模态学习领域的研究,欢迎关注。
快执行与慢思考:
在机器人操控领域,实现高频响应与复杂推理的统一,一直是一个重大技术挑战。近期,北京大学与香港中文大学的研究团队联合发布了名为 Fast-in-Slow(FiS-VLA) 的全新双系统视觉 - 语言 - 动作模型。不同之前的快慢系统 VLA 方法需要初始化 / 引入一个全新的快速执行模块,该方法通过将快速执行模块嵌入预训练视觉 - 语言模型(VLM)中,实现快慢系统一体化的设计。同时,针对双系统设计了异构模态输入与异步运行频率的策略,使得 FiS-VLA 既能实现快速动作生成,也具备慢思考能力。该方法在多个仿真与真机平台上取得了优异表现。最令人瞩目的是,FiS-VLA-7B 可以实现高达 117.7Hz 的控制频率,大幅领先于现有主流方案,展示了其广阔的实际应用潜力。
论文链接: https://arxiv.org/pdf/2506.01953
项目主页: https://fast-in-slow.github.io/
代码链接: https://github.com/CHEN-H01/Fast-in-Slow
PKU HMI 实验室主页:https://pku-hmi-lab.github.io/HMI-Web/index.html
研究背景与挑战:
机器人操作系统的目标是在复杂环境中,依据传感器输入和语言指令,生成精确有效的控制信号。虽然近年来大规模的视觉 - 语言模型(VLMs)因其强大的预训练能力被引入到机器人领域,但其庞大的模型参数和较慢的推理速度,限制了其在高频控制任务中的实用性。
为此,一些研究引入 Kahneman 的 “双系统理论”:系统 1 代表快速、直觉式的决策系统,系统 2 代表缓慢但深度推理的系统。在这一理论的启发下,已有方法尝试构建双系统结构,即使用 VLM 作为系统 2 进行任务级理解,再使用额外的策略头(系统 1)进行动作预测。但现有设计中两个系统相对独立,无法充分共享系统 2 的预训练知识,导致协同效率低下,系统 1 缺乏对系统 2 语义推理结果的充分利用。
Fast-in-slow VLA (如何在慢系统中分化出执行模块)
FiS-VLA 提出一种创新结构,将 VLM 的末端几层 Transformer 模块直接重构为系统 1 执行模块,嵌入原有系统 2 内部,形成一个统一的高效推理与控制模型。系统 2 以低频率处理 2D 图像和语言指令,输出指导特征;系统 1 以高频率响应实时感知输入(状态、图像和点云),实现高效动作生成。
此外,FiS-VLA 采用双系统感知协同训练策略,一方面利用扩散建模增强系统 1 的动作生成能力,另一方面保留系统 2 的高维语义推理能力,确保整体推理执行的互补性。模型在超 86 万条轨迹的大规模机器人数据集上预训练,并在多个现实任务中微调优化,显著提升了任务完成率和控制频率。

1. 架构设计:FiS-VLA 基于 Prismatic VLM 架构,主要包括以下模块:视觉编码器(结合 SigLIP 与 DINOv2 两种视觉编码器)、轻量级 3D tokenizer(处理点云并共享视觉编码器提取空间特征)、大语言模型(使用 LLaMA2-7B,并将其最后 n 层 Transformer 模块重用于系统 1),以及若干 MLP 模块(用于模态融合和扩散建模)。系统 1 直接嵌入系统 2 中的高维表示空间,使其能继承预训练知识并实现高频执行,整个系统构成 “快中有慢、慢中有快” 的协同结构。
2. 双系统协作:FiS-VLA 的结构由两个组成部分构成:一个慢速的系统 2 和一个快速的系统 1,这一设计灵感来源于 Kahneman 提出的双系统理论。在 FiS-VLA 中,系统 2 会处理与任务相关的视觉观测(如图像)和语言指令,并将其转化为高维特征,这些特征来自大语言模型(LLM)的中间层。借鉴 “动作块化” 的方法,FiS-VLA 认识到在时间步 t 的输入可以为未来若干步的动作生成提供指导,因此 FiS-VLA 将系统 2 的中间层输出作为一个潜在的条件信号,为接下来的 H 步系统 1 的动作生成提供约束。相较而言,系统 1 专注于实时动作生成,它在每一个时间步上运行,接收当前的感知输入并输出动作,同时也利用周期性更新的来自系统 2 的高维语义理解结果。这样的行为模式类似于人类的直觉反应,使得系统 1 成为一个高频率的动作生成模块。为了使两个系统协同工作,FiS-VLA 研究了它们之间的运行频率比例,并在消融实验中测试了不同的动作预测视野,实质上是在探索系统 2 每运行一次,系统 1 应连续运行多少步。在训练阶段,FiS-VLA 采用异步采样的方式控制系统 2 的运行频率,使得系统 1 能够保持动作生成过程的时间一致性。
另外,FiS-VLA 采用异构模态输入设计。由于系统 1 与系统 2 在职责上存在根本差异,FiS-VLA 为其设计了异构的输入模态。系统 2 主要承担任务理解与语义推理的工作,作为一个在互联网上以图文数据大规模预训练而来的模型,它最适合接收语言指令与 2D 图像,以充分激发其语义建模能力。系统 1 则用于实时生成机器人动作,因此必须接收全面、低延迟的感知信息输入,包括当前时刻的 2D 图像、机器人的自身状态(如关节、位置等),以及通过相机参数从深度图还原出的 3D 点云信息。特别是 3D 信息对于识别空间关系与实现精细操作至关重要。最终,系统 1 会将这些输入模态与系统 2 输出的高维特征共同融合,作为条件输入进行动作生成。
3.FiS-VLA 双系统协同训练:系统 1 以扩散建模为核心,注入带噪动作作为训练变量,实现连续性动作生成;系统 2 则采用自回归预测保留推理能力,这两个训练目标联合优化 FiS-VLA。训练采用跨平台大规模轨迹数据(约 860K 条轨迹),并在微调阶段引入子任务语言指令增强任务适应性。
精度、速度、泛化!
1. 仿真测试: FiS-VLA 在 RLBench 仿真任务中平均成功率为 69%,显著优于 CogACT(61%)与 π0(55%),在 10 项任务中 8 项居首。在控制频率上,其在动作块大小为 1 时达到 21.9Hz,是 CogACT 的 2 倍以上。

,时长05:41
2. 真机测试:在真实机器人平台(Agilex 与 AlphaBot)中,FiS-VLA 在 8 项任务中平均成功率分别为 68% 与 74%,远超 π0 基线。在高精度操控任务如 “倒水”、“擦黑板”、“折毛巾” 等场景下展现显著优势。

,时长00:06
3. 泛化能力:在泛化测试中,面对未见物体、复杂背景与光照变化,FiS-VLA 准确率下降幅度远小于 π0,验证其双系统架构对视觉扰动的鲁棒性。

,时长00:07
4. 消融实验:消融实验表明,并非共享 Transformer 层数越多,系统 1 性能越强,在共享 Transformer 层数为 2 的时候,FiS-VLA 实现最佳性能;系统 1 接收机器人状态、图像与点云三种输入模态效果最佳;系统 1 和系统 2 协作的最佳频率比为 1:4;FiS-VLA 在不同 action chunk 值下性能稳定,而控制频率呈比例提升。特别当单步预测 8 个动作时,理论控制频率高达 117.7Hz;同时最后作者还研究了 FiS-VLA 的一系列变体(模型输入的变体)。


5. 真机实验可视化


,时长00:06
,时长00:05
总结与展望:
FiS-VLA 通过在统一 VLM 中嵌入执行模块,创新性地融合推理与控制,实现了高频、高精度、强泛化的机器人操控能力。作者讨论到,未来若引入动态调整共享结构与协同频率策略,将进一步提升其在实际任务中的自适应性与鲁棒性。
....
#OpenAI想收购的Windsurf,被谷歌DeepMind抢走了核心团队
就在所有人还在惊叹于月之暗面开源 Kimi K2 模型的同时,谷歌 DeepMind 却宣布截胡了 OpenAI 原本打算收购的 Windsurf。
诺贝尔奖得主、DeepMind 联创兼 CEO Demis Hassabis 与 DeepMind CTO Koray Kavukcuoglu 在 𝕏 上向 Windsurf CEO Varun Mohan、联合创始人 Douglas Chen 以及部分加入 DeepMind 团队的研发人员表示了欢迎。

推文中,谷歌 DeepMind 宣布 Mohan 和 Windsurf 的员工将专注于 DeepMind 的编程智能体和工具使用方面的 Gemini 项目。
科技媒体 The Verge 从谷歌发言人 Chris Pappas 那里得到了一份声明,其中写到:「Gemini 是目前最好的模型之一,我们一直在投资为其开发先进的开发者功能。我们非常高兴地欢迎 Windsurf 团队的一些顶尖 AI 编程人才加入谷歌 DeepMind,以推进我们在智能体编程方面的工作。」
加入 DeepMind 的 Windsurf CEO Varun Mohan 与联合创始人 Douglas Chen 也发布了一份声明,其中表示:「我们很高兴能与 Windsurf 团队的部分成员一起加入谷歌 DeepMind。我们为 Windsurf 过去四年取得的成就感到自豪,并期待看到它与他们世界一流的团队一起前进,开启新的发展阶段。」
至于达成这笔交易的具体金额,目前还没有人透露。作为参考,此前有报道称,OpenAI 将斥资 30 亿美元收购 Windsurf。
那么,OpenAI 与 Windsurf 的交易究竟出了什么问题?
据 Fortune 从 OpenAI 一位发言人获得的消息:OpenAI 在 5 月份与 Windsurf 达成的 30 亿美元收购协议的排他性期限已到期,Windsurf 可以自由选择其他方案。
这家初创公司由麻省理工学院校友于 2021 年创立,最初名为 Codeium,在宣布 OpenAI 收购前不久,于今年 4 月更名为 Windsurf。
事实上,在竞购 Windsurf 之前,OpenAI 曾与 Anysphere 洽谈收购 Cursor 事宜 —— 但据 TechCrunch 报道,由于 Cursor 不愿被收购,谈判最终破裂。
这一消息对 OpenAI 来说无疑又是一个新打击。
根据网友 𝕏 博主 @ns123abc 的盘点,OpenAI 最近受到的打击还真不少。

这个消息过于突然,整个 AI 行业乃至科技圈都沸腾了,甚至有人打趣地表示:Windsurf 的工程师可能自己也处于懵逼状态。

也有人认为,对 Windsurf 来说,谷歌是比 OpenAI 更好的选择。

不过,选择谷歌并不是对 Windsurf 所有员工都是好事。
据多家媒体披露:谷歌不会对 Windsurf 拥有任何控制权或股权,但将获得 Windsurf 部分技术的非独家许可。
也就是说,Windsurf 将继续作为一家独立创业公司运营,同时其团队的关键成员将加入谷歌 —— 对于没加入谷歌 DeepMind 的 Windsurf 员工,不仅一点好处也没有,高管和技术核心还都跑路了。

对于剩下的 Windsurf 团队,Windsurf 现任业务主管 Jeff Wang 将成为临时首席执行官,全球销售副总裁 Graham Moreno 将担任 Windsurf 新任总裁,该任命立即生效。

担任临时 CEO 的 Jeff Wang 在 Windsurf 官网和 𝕏 上发布了一份长文声明,其中称:「Windsurf 世界一流的团队大部分成员将继续为企业打造 Windsurf 产品,并帮助我们的客户最大限度地利用这项技术。」

上下滑动查看
不过,也有开发者对已经失去核心团队的 Windsurf 的未来表达了担忧:

对于 AI 行业这场愈演愈烈的人才抢夺大战,你有什么看法?
参考链接
https://windsurf.com/blog/windsurfs-next-stage
https://x.com/jeffwsurf/status/1943805677270622570
https://www.theverge.com/openai/705999/google-windsurf-ceo-openai
https://x.com/ns123abc/status/1943806065524507007
....
#生成式 AI 的发展方向
应当是 Chat 还是 Agent?
先看下Chat和Agent的差别。
Chat(聊天):纯粹的Chat,像是一个主要由“大脑和嘴”构成的智能体,专注于信息处理和语言交流。比如ChatGPT这样的系统,它能够理解用户的查询,给出有用和连贯的回答,但它本身不直接执行任务。
Agent(代理):像一个具有“手、脚”的智能体,它能够进行思考、决策,并且能执行具体的任务。
我们可以简单粗暴的理解为,Chat强调的是“说”,Agent强调的是“做”。
要你你选哪个?
这么讲吧,但凡人类对于躺平的美好追求还在,“让机器替我干活”的念头就不可能熄灭。
自ChatGPT发布后,从plugin的推出,到Function Calling再到Assistant API的面世,OpenAI这一系列动作就充分表明,有这么强大的LLM作为基本盘的情况下,人们就不可能仅仅满足于让它“嘚啵嘚”。
历史总是惊人的相似。从2014年亚马逊开创性推出Amazon Echo开始,智能音箱横空出世。一开始的智能音箱,也只是有个“嘴”,只能实现播放音乐、查询信息、设置提醒等功能。而且“脑子”还不太灵光。
但是随着阿里、百度、小米等科技巨头的纷纷加入,智能音箱在竞争中卷出了新高度。打通支付、和智能汽车、智能家居互通,智能音箱不断地突破和扩展功能边界,逐步坐到了智能家居生态的“大总管”位置上。
随着应用场景的持续拓展,智能音箱又延展到儿童教育、养老关怀等领域,深刻影响了人们的日常生活。
相信有一天,智能音箱会强大和多样化到一个程度,以至于“智能音箱”这个名字不再适合这个品类,那将是新一轮故事的开始。
同样惊人相似的,还有从单纯的AI智能语音助手、智能客服(只会说)到以AI+RPA为核心技术的的AI数字员工(会说又会做)的发展史。。。
这些,都是人工智能走向多元化和融合化的一个个缩影。
因此,随着技术水平的不断进步和场景化落地的不断挖掘,Chat和Agent的界限必定会越来越模糊,生成式 AI 会融合Chat和Agent的特点,形成既能进行高质量、高人格化对话,又能高效执行复杂任务的 AI 自动化系统,为人们提供融合、互补、多样化的解决方案。
AI Agent的崛起不仅仅是技术上的突破,更是对软件开发理念的一次深刻变革。
在传统的软件开发中,程序员需要预先定义所有的逻辑和规则,然后进行代码实现。而AI Agent的出现,要求我们对软件进行充分地“放权”:它由一颗大脑(LLM)来进行自主支配运行,并在运行时自动学习、适应和调优。这种前所未有的开发范式的转变,让程序员不得不重新思考软件开发的本质,也重新思考软件开发的未来。
典型的AI agent分为Memory(记忆)、Tools(外部工具) 、Planning(计划) 和Action(行动)四个模块。

当前学习AI Agent基本上分作两条路径:
基于OPenAI技术路线,以及基于开源技术路线。建议每个技术人员,都选择一条路,亲自趟一趟。
大模型爆发之后,AI Agent的发展也可谓是一日千里,各种项目层出不穷。

AutoGPT
项目地址:
https://github.com/Significant-Gravitas/AutoGPT
可以根据你设置的目标,将实现这个目标的任务进行拆解,再采用搜索、浏览网站、执行脚本等方式一条条去执行任务,帮你完成目标。
JARVIS
项目网址:
https://github.com/microsoft/JARVIS
一个非常有意思的“模型选择”Agent。它将用户要求拆解成子任务,再到Huggingface上选择合适的专家小模型执行任务,最后对结果进行处理和返回给用户。

由于JARVIS可以调用其它模型工具,因此它可以执行多模态任务。
MetaGPT
项目网址:
https://github.com/geekan/MetaGPT
MetaGPT是另一个开源人工智能体框架,试图模仿传统软件公司的结构。与ChatDev类似,Agent被分配产品经理、项目经理和工程师的角色,并且他们在用户定义的编码任务上进行协作。
工具、平台、社区的不断成熟,为个体开发者提供了一个全新的舞台。程序员与人工智能之间的距离从未如此之近。AI Agent的崛起,让有想法、有技术的人能够以前所未有的方式释放自己的创造力,打造出各种有趣、实用的AI原生应用。
....
#Orthogonal Subspace Decomposition for Generalizable Al-Generated Image Detection
北大和腾讯优图破解AI生成图像检测泛化难题:正交子空间分解
随着 OpenAI 推出 GPT-4o 的图像生成功能,AI 生图能力被拉上了一个新的高度,但你有没有想过,这光鲜亮丽的背后也隐藏着严峻的安全挑战:如何区分生成图像和真实图像?尽管目前有很多研究已在尝试解决这个挑战,然而这个挑战深层次的泛化难题一直没有得到合理的探究,生成图像和真实图像的区别真的是简单的 「真假二分类 」吗?
近日,北京大学与腾讯优图实验室等机构的研究人员针对这一泛化难题做了一些深层次的探究,研究表明 AI 生成图像检测任务远比 「真假二分类 」复杂!这里基于正交子空间的分解对该挑战提出了一种新的解决思路,实现了检测模型从 「记忆式背诵」 到 「理解式泛化」 的跨越,显著提升 AI 生成图像检测的泛化能力,具有理论深度与实践价值的双重突破。论文被 ICML2025 接收为 Oral (TOP ~1%)。
论文题目:Orthogonal Subspace Decomposition for Generalizable Al-Generated Image Detection
论文地址:https://openreview.net/pdf?id=GFpjO8S8Po
代码链接:https://github.com/YZY-stack/Effort-AIGI-Detection
文章摘要
我们设计了一种新的基于正交分解的高效微调方法,既保留原有大模型原有的丰富预训练知识,又 「正交」 地学习下游任务相关的新知识。同时,我们对当前检测模型泛化性失效的原因给出了深入的量化分析,最后也总结了一些能够泛化性成功的关键 Insight。
解决了什么问题
随着 AIGC 的爆火,区分生成图像和真实图像十分重要,无论是对 AI 安全还是促进生成(类似 GAN)都有益处。在该工作中,我们发现,AI 生成图像(AIGI)检测中的真假(Real-Fake)二分类,与普遍、标准的 「猫狗二分类」 不同的是,AIGI 的二分类是不对称的,即如果直接训练一个检测器,模型会非常快的过拟合到训练集里固定的 Fake Patterns 上,限制了模型对未见攻击的泛化性,如图 1 所示。

图1:真假二分类「不同于」猫狗分类等标准二分类,具有不对称性,即模型容易在很早期就快速过拟合到训练集的假类中(loss非常低),而真类此时基本完全没有学好(loss高)!
由于模型快速过拟合到了训练集里的 Fake 上,整体学习到的知识就会被训练集固定的 Fake Pattern 主导,但由于训练集里 fake 的单一性,导致整个模型的特征空间变得非常低秩(Low-Ranked)且高度受限(Highly Constrained),这也被现有工作证实,会限制模型的表达能力和泛化能力。图 2 是我们对现有直接做简单二分类的传统方法得到的模型特征的 t-SNE 分析图,可以看到 Unseen Fake 和 Unseen Real 被混杂在一起无法区分。

图 2:由于模型过拟合到了训练集有限的假类的pattern上,导致模型的特征空间被fake主导,导致特征空间高度低秩且受限,极大程度影响了模型的泛化性,即模型会把见过的fake pattern“牢牢记住”,当成假类,没有这些pattern的无论真假统统认为是真类。
接下来是具体量化分析结果,图 3 是我们对模型特征做了主成分分析(PCA)可视化,可以发现传统方法的特征空间的解释方差比率(Explained Variance Ratio)主要集中在前两个主成分上,这导致特征空间其实是低秩的。图 4 是我们用 PCA 主成分数量来量化模型的过拟合情况,可以发现无论是直接微调 CLIP 还是通过 CLIP+LoRA 的方式在 fake 检测任务上微调,都会导致模型预训练知识的遗忘(PCA 主成分数量显著降低)。

图 3:为了量化模型的「过拟合程度」,我们通过PCA的方式计算模型特征空间的主成分的数量。我们发现Naive训练的二分类器特征空间的信息仅仅用两个主成分就能表达,验证了其特征空间的高度受限。

图 4:我们通过PCA方法进一步计算原始CLIP特征空间的「有效维度」,以及通过LoRA、或者全参数微调(FFT),以及我们方法微调的主成分数量。我们方法在学习真假判别信息的同时,较好的保留了原有CLIP知识。
解法与思路
我们提出了一种基于 SVD 的显式的正交子空间分解方法,通过 SVD 构建两个正交的子空间,Principal 的主成分(对应 Top 奇异值)部分负责保留预训练知识,Residual 的残差部分(「尾部」 奇异值)负责学习新的 AIGI 相关知识,两个子空间在 SVD 的数学约束下严格正交且互不影响(图 5)。

图 5:我们方法的流程图。我们对原始层做SVD分解,得到其主奇异值对应的部分,以及“尾部”奇异值对应的部分。通过冻结主奇异值部分,同时微调尾部奇异值的残差部分,我们的方法能在学习真假判别信息的同时,较好的保留了原有CLIP知识。
图 6 是具体整个方法的算法流程,其主要对 ViT 模型每一层 Block 的线性层参数进行 SVD 分解,我们保留其奇异值较大的参数空间不动,微调剩余奇异值对应的参数空间,除了真假二分类损失函数外,这里还施加了两个正则化约束损失函数来限制微调的力度。

图 6:本文方法的算法流程图。
实验效果
通过我们提出的上述方法,能维持高秩的模型特征空间,最大程度的保留了原来的预训练的知识,同时学到了 Fake 相关的知识,因此取得更好的泛化性能。我们在 DeepFake 人脸检测和 AIGC 全图生成检测两个任务中均取得不错效果(表 1、表 2)

表 1:在人脸Deepfake Benchmark检测的效果。

表 2:在通用AI生图的检测效果。
此外,如图 7 所示,我们对原始的 CLIP-ViT 模型(Original)、全微调的 CLIP-ViT 模型(FFT)、LoRA 训练的 CLIP-ViT 模型(LoRA)以及我们提出的正交训练的 CLIP-ViT 模型(Ours)的自注意力图(Attention Map)进行了可视化。具体来说,从上到下是逐层 block 的自注意力图。对于 LoRA 而言,自注意力图从左到右依次使用原始权重 + LoRA 权重、原始权重、LoRA 权重生成的。对于我们的方法而言,自注意力图从左到右依次使用主成分权重 + 残差权重、主成分权重、残差权重生成的。这里,我们观察到语义信息主要集中在浅层的 Block 中,而我们提出的方法在自注意力图层面上确实实现了语义子空间与学习到的伪造子空间之间的正交性。这进一步说明了我们的方法能够在学习 Fake 特征的同时,更好地保留预训练知识。

图 7:对CLIP不同层做attention分析,发现我们保留的信息(主成分),跟模型学到的检测相关信息(残差部分),互不影响,相互正交,印证我们方法的有效性。
启发与展望
虽然检测任务表面上看是一个 Real 与 Fake 的二分类问题,但实际上 Real 与 Fake 之间的关系并不像猫狗分类那样完全独立,而是存在层级结构。也就是说,Fake 是从 Real 「衍生」 而来的。掌握这一关键的强先验知识,是检测模型实现良好泛化的核心原因。相反,如果像训练猫狗分类器那样简单地训练二分类模型,容易导致模型过拟合于固定的 Fake 特征,难以捕捉到这一重要的先验信息。
见图 8,模型(右侧)可以把不同的类别(Semantic 相同)聚到一起,并在每个 Semantic 子类别里做判别(假苹果 vs 真苹果),大大减小了判别复杂度,进而可以提升模型的泛化性(Rademacher Complexity 理论),这强调了语义对齐的重要性,即在一个对齐的语义子空间里(例如苹果的子空间里)区分 Real 和 Fake,可以大幅降低判别的复杂度,进而保证模型的泛化性。

图 8:本文最大的insight:真假类别并非对称关系,而是存在「层次化关系」!即假类是从真类来的,例如假猫其实是从真猫的分布学习而来的!因此无论是真猫还是假猫都属于猫的语义空间。由于我们的方法保留了CLIP原始主奇异值的部分,因此大部分语义信息全保留,进而能让我们的模型在猫的语义空间区分真猫和假猫,进而不会受到狗、人、猪等其他语义的影响,大大降低了模型判别复杂度,保证了泛化性。
在 AI 生成图像日益逼真的今天,如何准确识别 「真」 与 「假」 变得尤为关键。传统方法依赖训练集内的 Fake Pattern 匹配,该研究通过正交子空间分解,使模型能在真实图像的语义先验的基础上判别 Fake 信息,解决了生成图像检测中跨模型泛化性差的核心难题。此外,该研究成果提出的正交分解框架,还可迁移至其他 AI 任务(如微调大模型、OOD、域泛化、Diffusion 生成、异常检测等等),为平衡模型已有知识与在新领域的适应性提供了新的范式。
....
#首个面向AI作者的学术会议来了
第一作者必须是AI!斯坦福发起
AI 终于可以当「第一作者」了。
在 AI 已深度介入科研流程的今天,从提出假设到生成图表、撰写论文,它正逐步参与乃至重塑整个科学研究的方式。但讽刺的是,尽管我们在 CVPR、NeurIPS、ICLR、ICML 甚至 ACL 等顶会中看到 AI 无处不在,却几乎没有任何一个会议或期刊承认 AI 的「作者身份」——AI 被广泛使用,却从未被名正言顺地署名。
这一局面,终于被打破了。
斯坦福大学近日宣布,将于 2025 年举办一个史无前例的学术会议 —— 科学 AI 智能体开放会议(Agents4Science 2025),全称 Open Conference of AI Agents for Science。
它的投稿要求堪称颠覆:第一作者必须是 AI。
会议官网:https://agents4science.stanford.edu
更具体而言:「投稿论文应以 AI 系统为主要创作主体,由其主导假设生成、实验及撰写过程。AI 应被列为论文的唯一第一作者。人类研究者可作为共同作者参与,作用是支持或监督相关工作。向 Agents4Science 投稿的论文也可以同时或随后向其他会议投稿。投稿时,作者需详细说明 AI 在项目中的角色及参与程度。每位人类作者最多可参与 4 篇投稿论文。」
至于这些投稿的研究主题,会议并没有严格限定,只是表示:「我们欢迎来自科学、工程和计算等所有领域的投稿。」
还不仅如此,该会议的评审也主要是 AI,只是会由人类专家进行最终评估和选择。

首先,每篇论文将由多个 AI 系统进行评审,以避免单一模型的偏差。AI 评审组完成初评后,将由一个人类专家组成的评审委员会对优选出的论文进行复评。最后,由该人类评审委员会最终裁定 Spotlight 和 Oral 在内的各个奖项。
会议官网介绍了其目标:「通过透明的 AI 撰写的研究成果和 AI 驱动的同行评审探索 AI 驱动的科学发现的未来。」

具体包括:
探究:关于 AI 智能体进行科学探究的能力,仍有许多未知之处。通过创造透明的观察环境,希望能够了解 AI 在科学发现中的潜力和局限性,无论其产出是真正的创新还是具有指导意义的失败。
建立规范:随着 AI 系统的快速发展,需要制定归因、验证和伦理考量的标准。Agents4Science 是一个受控且低风险的环境,可供研究者在此开始制定这些规范,并公开探索 AI 在科学发现中的作用。
透明度:会议目标是清晰地描绘 AI 参与科学研究的方式,并将 AI 参与研究过程的情况公开发布。会议还会提供 AI 评审智能体生成的提示和评审结果,作为社区的开放资源。
作为首届 Agents4Science 会议,Agents4Science 2025 将于今年 10 月 22 日以线上虚拟会议的形式举办 —— 届时也将是 ICCV 2025 期间。
会议主席之一的 James Zou 表示,该会议将会公开所有提交的论文和评审,以便研究者和审阅者透明地研究 AI 的优势和局限。他表示:「我们预计 AI 会犯错误,公开研究这些错误将会很有启发!」

对于这个前所未有的学术会议,不少网友也表示了期待和投稿意愿:

会议基本信息
根据会议官网,我们简单整理了 Agents4Science 2025 会议的一些基本信息:
- 会议时间:2025 年 10 月 22 日
- 论文提交截止日期:2025 年 9 月 5 日,AOE 时间
- 论文评审结果发布日期:2025 年 9 月 29 日 AOE 时间
Agents4Science 2025 将以线上虚拟会议形式举行,包含受邀演讲、口头展示和小组讨论。

该会议共有 5 位会议主席,以下是对他们的简单介绍
- James Zou:斯坦福大学生物医学数据科学副教授,兼任计算机科学与电气工程副教授。他 2014 年在哈佛大学获得博士学位,曾在微软研究院工作。
- Owen Queen:斯坦福大学计算机科学博士生,致力于开发用于科学应用的强大且实用的 AI。
- Nitya Thakkar:斯坦福大学计算机科学专业博士生,研究兴趣是用于健康领域的 AI 和计算生物学。
- Eric Sun:斯坦福大学博士,即将前往 MIT 任职助理教授,研究兴趣包括衰老、人工智能 / 机器学习、空间生物学与单细胞生物学。
- Federico Bianchi:TogetherAI 资深研究科学家,致力于大型语言模型的后训练研究,主要是自我提升式和自进化式 AI 智能体。
目前,Agents4Science 2025 会议正在征集论文,感兴趣的作者可以考虑拉上你们的 AI 搭档一起在 OpenReview 上投稿了。
....
#搭各种AI Agent框架,应该往什么方向努力
Agent的狂欢基本已经结束了,不建议继续纯做这个,起码得加点多模态和ML,DL了。
具体可以看看各家公司的Agent都到什么水平了,比如网易逆水寒这种,别人已经纯商业赚钱了,你如果不如人家的,大概率还是很难。
现在LLM Agent的工作好几类,而我主要是关注游戏方面的,所以有些地方肯定是没写清楚或者有错误,还希望多多包涵。
博弈类
第一种可以称之为博弈类,或者MALLM类。
这类一般是以前做过MARL的人转战LLM Agent,把之前的MARL里面的方法拿过来各种套。大部分工作都会在矩阵博弈,overcook这种环境做,主要目标还是涨点啥的。个人不是很喜欢,不过做的人不少,毕竟科研也是工作的一种,能发文章的方向肯定是好方向,只不过找工作这个就不太实际了。
游戏类
第二种可以称之为游戏类,虽然博弈也叫Game,但这里指的还是真正有人玩的游戏,起码得有受众。
这类又可以细分,一类是构建文本化的环境,比如civrealm,LLM play sc2(我做的,自卖自夸一下),还有各种兵棋。这类主要考验你对这些游戏的掌握程度,通过各种接口想办法去保证游戏的文本空间的合理映射。
最近安波老师的多模态Agent cradle也很火,带领了一波多模态的浪潮,比如现在的黑神话悟空,也有人开始这么做了。
剩下的就是经典的打牌下棋了,这个也有不少,从象棋围棋到掼蛋,大家都做了一遍。
这一类的问题就是,上一波RL大火的时候,能训练的游戏基本都是超越人类的水平了,LLM/MLM Agent的优势和特点在哪里,这是需要解决的。
第三类可以说是各种xx智能,不过由于现在啥都叫xx智能了,我这里就只讲机器人了。这个领域我不熟悉,也没看过多少工作,但一般有真机的工作要更扎实一点,很多会议也要求有真机的。纯仿真里搞这些,就不大好了。
第四类是模拟类的,比如模拟一个人,模拟一个社会这种。
现在有的工作,比如斯坦福小镇,模拟Twitter,还有模拟选举什么的。其实和游戏类差不多,有的甚至就在游戏里面搞的。我们需要设计合理的机制,做好前后端接口,把一个真实的社会给仿真出来,尽可能让大模型像每一个性格迥异的人。
这里有几个问题很难解决。
第一是仿真器怎么做,斯坦福小镇的爆火就是他们可视化做的好,后续大家都在unity里开发了。
第二是怎么保证个性化和智力,大模型经过RLhf之后,很难让它细粒度的扮演一个人进行决策,主流的商业模型都会给出一个很中庸的回答,根本没法用。
第三是怎么支撑起几百,甚至几百万的Agent交互,这个很复杂,方法很多,但花的钱肯定不少。
当然有些人是没有前端渲染的工作,多快好省,这其实不太好,因为这个领域Demo胜过一切,你连一个好看的Demo都没有,别人肯定是不会浪费时间看你的工作。
第五个才是现在最有用的Agent,比如客服问答,RAG这种,做的人很多,很卷,但是真的能落地赚钱。这方面我完全不熟,希望有人补充。
第六个可以说是tool use之类的工作,比如HuggingGPT什么的,现在也很火,该赚钱的已经都在赚钱了,公司也非常看中这个,毕竟这些是真的能提升生产力。
第七个是自动化流水线,比如metagpt写代码,各种生物化学的Agent用来合成东西,发现和分析数据啥的。代码类现在吹得很凶,但效果还是很难做好,毕竟严重依赖基础模型。而ai for science这类的,主要靠py和science端的知识,cs的学生肯定是没这品味,也没这兴趣去搞这种(毕竟我就是生物本科,我感觉大部分做ai for science的同学,根本不了解真正的基础研究)。
Minecraft
发现忘记写Minecraft了,由于23年做他们的人太多了,特此把他从游戏类提出来单独写一下。
有三类,第一类纯RL,大家以前做的比较多,比如Minecraft有OpenAI做的那个,从视频里学习的。
第二类是纯LLM,这个就满天飞了,什么Voyager,Ghost in Minecraft,非常多,一般都是技能库,调用代码什么的,相信大家看过很多Demo了。当然最近也有1000个Agents的这种,这种其实主要是因为Minecraft本身游戏比较好,能支持这么Agent进去,有钱加上合理的设计,肯定能做出来。
第三种是LLM+RL,有设计reward的,有存储技能书的,也是一大堆,不少都中了顶会。
Minecraft竞争过于激烈,不建议大家再搞了,除非你有信心战胜10个清华博士全力开卷的能力。
总结
所以总结一下,大部分的Agent领域低垂得果实,都已经被摘完了*,22年底到23年的那种随便调调api,编点故事就乱发的美好时代已经过去了。当然对于老师来说,他们往往才开始了解,所以不懂这个竞争多惨烈,只能看到别人xxx都能发,我们为什么不能。
如果大家想继续做这个方向,那就得想清楚自己擅长什么。大模型的商业化实际上是依赖Agent的,没有公司支持的大模型研究,基本都是搞笑的,公司不但会提供商业场景,也会提供资源支持,而高校这种小打小闹,在如今是完全行不通的。
毕竟大模型就是个工程活,不要老觉着自己是在做科研,你和纯数,生化环材的比一下,就知道自己在做啥了。
....
#CEED-VLA
VLA 推理新范式!一致性模型 CEED-VLA 实现四倍加速!
本文第一作者为香港科技大学(广州)机器人系一年级博士生宋文轩,主要研究方向为VLA模型,共同第一作者是来自香港科技大学广州的研究助理陈家毅,项目leader为浙江大学和西湖大学联合培养博士生丁鹏翔,他们也是xx智能领域开源项目OpenHelix以及LLaVA-VLA的研究团队。通讯作者为香港科技大学广州的李昊昂教授,他是今年的CVPR2025 Best Paper Candidate的获得者。
,时长02:26
近年来,视觉 - 语言 - 动作(Vision-Language-Action, VLA)模型因其出色的多模态理解与泛化能力,已成为机器人领域的重要研究方向。尽管相关技术取得了显著进展,但在实际部署中,尤其是在高频率和精细操作等任务中,VLA 模型仍受到推理速度瓶颈的严重制约。
针对这一问题,部分研究提出采用 Jacobi 解码替代传统的自回归解码,以期提升推理效率。然而,由于 Jacobi 解码往往需要较多迭代次数,其加速效果在实践中较为有限。
为此,我们提出了一种一致性蒸馏训练(consistency distillation training)策略,使模型在每次迭代中能够同时预测多个正确的动作 token,从而实现解码加速。同时,我们设计了混合标签监督机制(mixed-label supervision),用于缓解蒸馏过程中可能产生的误差积累问题。
尽管上述方法带来了可接受的加速效果,我们进一步观察到:Jacobi 解码中仍存在若干低效迭代步骤,成为限制整体效率的关键瓶颈。为彻底解决该问题,本文提出一种提前退出(early-exit)解码策略,通过适度放宽收敛条件,进一步提升平均推理效率。
论文题目:CEED-VLA : Consistency Vision-Language-Action Model with Early-Exit Decoding
项目主页:https://irpn-eai.github.io/CEED-VLA/
论文链接: https://arxiv.org/pdf/2506.13725
代码链接: https://github.com/OpenHelix-Team/CEED-VLA
实验结果表明,我们所提出的方法在多个基线模型上实现了超过4 倍的推理加速,同时在仿真与真实机器人任务中均保持了较高的任务成功率。这些实验验证了本方法在加速机器人多模态决策过程中的高效性与通用性,展现出良好的应用前景。总的来说,我们做出以下三大贡献:
(1)我们提出了一种通用的加速方法 CEED-VLA,在保持操控性能的前提下显著提升了推理速度。
(2)我们引入了一种一致性蒸馏机制,并在自回归损失中结合混合标签监督,以有效保留高质量的动作序列。
(3)我们发现 Jacobi 解码存在低效迭代的瓶颈问题,进一步提出了早期退出(early-exit)解码策略,实现了 4.1 倍的推理加速与 超过 4.3 倍的解码频率提升。

图 1:不同解码方法加速效果对比
Method

图 2:CEED-VLA 模型架构示意图
我们提出的框架首先通过预训练的 VLA 模型(例如 LLaVA-VLA和OpenVLA)进行Jacobi Decoding生成训练Jacobi Trajectory数据集。随后,我们设计了一种高效的一致性蒸馏方式,并引入了一种新颖的混合标签监督方法,在同时保证精度和提高速度的前提下训练学生模型。最后,我们提出了Early-exit Decoding技术,以进一步提升推理速度。模拟环境与现实世界中的实验表明,在几乎不损失任务成功率的前提下,该方法显著提升了模型的推理速度和灵巧任务的成功率。
Consistency Training
对于目标 VLA 模型 ,为了捕捉 Jacobi 轨迹中的内在一致性以进行一致性训练,我们首先通过在机器人数据集C上使用 Jacobi Decoding对模型 进行动作预测,来采集完整的Jacobi轨迹。
一致性训练包含两个优化目标:一致性损失(Consistency Loss): 引导模型能够在单次forward过程中预测多个正确的 token,为了确保模型在轨迹中的任意一步都能生成与最终目标一致的动作,这里引入了 KL 散度作为一致性损失。简而言之,它要求模型在每一个中间步骤的预测,和最终预测结果之间保持一致,从而提高模型收敛效率。
混合标签的自回归监督损失(Mixed-label AR Supervision): 为了保留模型常规的自回归生成能力,CEED-VLA混合使用教师模型的数据以及Ground-truth数据进行监督,以保证动作精确性。最终的训练目标是两种损失的加权和。训练过程如下所示:

图4 一致性训练算法
Early-exit Decoding

图 5:四种解码方式迭代流程
Jacobi 解码允许并行输出动作token,在一定程度上提高了推理速度,但严格的收敛条件影响解码效率进一步提升。为此我们提出Early-exit Decoding策略:模型通过提前退出的方式输出中间预测结果,无需满足Jacobi iteration的收敛条件。得益于manipulation任务独特的结构,Early-exit Decoding显著提升了推理速度,同时保持了成功率,使得模型能够以更高频率控制机器人,满足实时任务需求。
仿真环境基准实验(Simulation Benchmark)

图 6:仿真环境主要实验结果
在最具挑战的长程任务CALVIN ABC-D和LIBERO-Long基准上的实验结果表明,CEED-VLA在几乎不损失任务成功率的前提下实现了4倍以上的推理速度和执行频率。
真实世界实验(Real World)

图 9:真机实验部署设置

图 10:叠毛巾任务上的对比
上图展示了 LLaVA-VLA 模型的真实表现。机械臂操作频率较低,难以完成如叠毛巾等灵巧操作任务,经常出现抓取失败或只抓到一边的情况,导致任务失败。下图展示了 CEED-VLA 模型的实验效果。得益于推理频率的提高,机械臂动作更加顺畅,成功完成了灵巧操作任务。

图 11:CEED-VLA 在真实世界中的实验结果。
CEED-VLA 显著提升了推理速度和控制频率,使模型能够学习并执行高频动作,因此相比基线在灵巧任务上的成功率大幅提升,超过 70%。
....
#深入解析 Flow Matching 技术
「流匹配」成ICML 2025超热门主题!网友:都说了学物理的不准转计算机
流体力学融入生成式 AI ,构建了一种非常简洁、优雅的形态。
众所周知,第 42 届国际机器学习大会(ICML)将于 7 月 13 日至 19 日在加拿大温哥华盛大举行。
在生成式 AI 领域,最新的前沿热点已经转向探索更高质量,更稳定,更简洁,更通用的模型形态。
流匹配(Flow Matching)技术正完美的踩中了每一个热点要素。
自从 FLUX 模型发布后,能够处理多种输入类型的流匹配架构逐渐成为目光焦点。
也因此有学者感慨,在 ICML 2025 的生成相关工作中,流匹配技术几乎无处不在。

流匹配技术虽说在生成式 AI 领域是前沿研究,但其核心概念来源于流体力学。
令人惊讶的是,物理领域的有关概念在近些年的确为生成领域的研究提供了很多新方向和新成果。
甚至薛定谔桥都能用在扩散生成领域!
在知乎相关技术解读专栏《深入解析 Flow Matching 技术》下,网友怒评:物理学专业的不准转计算机!

专栏标题:《深入解析 Flow Matching 技术》
专栏链接:https://zhuanlan.zhihu.com/p/685921518
本文参考研究者 Floor Eijkelboom 的最新推文,从原理入手,避免繁杂的数学公式,来介绍这一简洁优雅且高效的生成技术。
生成:噪声映射到数据
生成工作是一个逐步具象化的过程,从一个抽象的表示开始,通过不同的生成网络,最终生成出具有复杂细节的真实数据。在此过程中,我们希望从一个无序的「噪声分布」映射到不同的复杂的数据分布中,这种映射是高度非线性的,而且存在无限的可能性。

生成猫猫 由噪声向图像映射
从本质上讲,流匹配的核心思想非常简单:
学习将噪声转化为数据。
我们首先在噪声分布与数据分布之间选择一种插值方式(如图所示)。
流匹配会学习如何沿着这条插值路径移动每一个样本,将起始时刻(time 0)的噪声点逐步转化为终点时刻(time 1)对应的数据点。
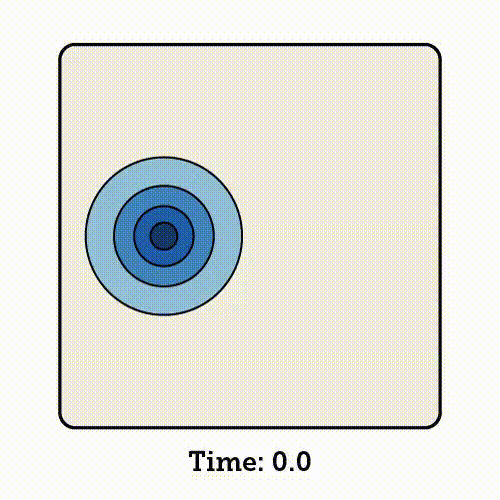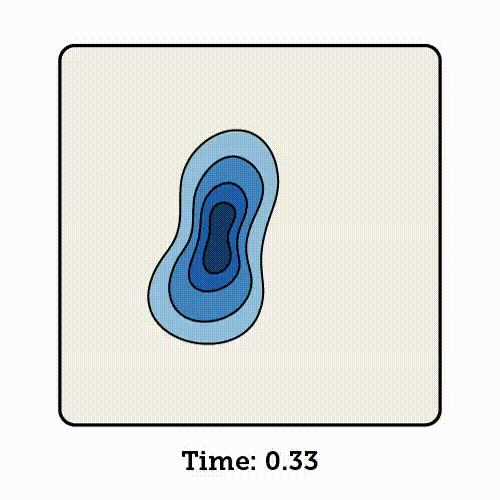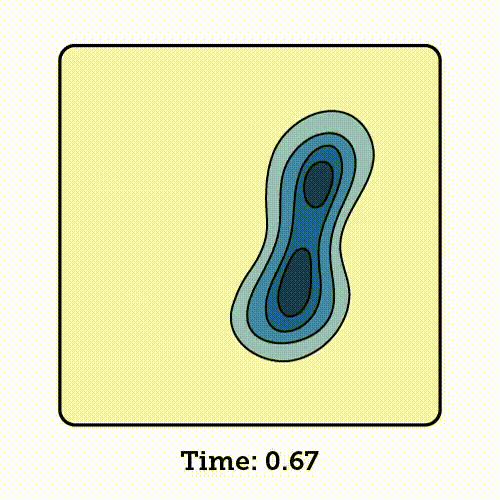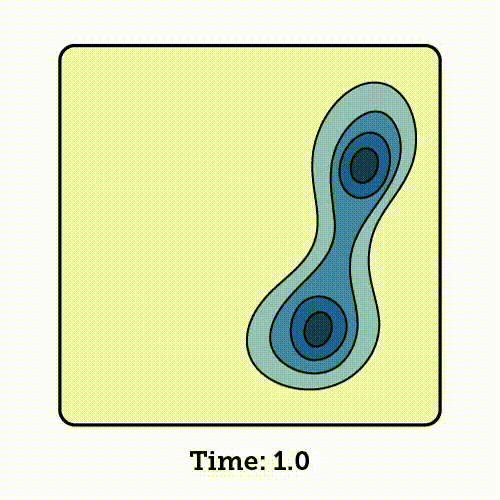
流匹配是基于归一化流(Normalizing Flows,NF)的生成模型。它通过一系列可逆的变量变换,将复杂的概率分布逐步映射为简单的分布;同时,也可以通过这些变换的逆过程,从简单分布中生成逼真的数据样本。
流匹配原理:流体力学
连续性方程
那么,噪声点向数据点的差值路径应当如何建立?
这个问题已经在流体动力学等领域中得到研究!
在流体中,追踪每一个微小粒子的运动轨迹是明显困难的。因此我们更关注的是:每个空间区域内平均存在多少水?这种平均量被称为密度。
为了研究密度的变化,物理学提供了一个重要工具:连续性方程(continuity equation)。
连续性方程建立在一个简单而基本的原理之上:质量既不会凭空产生,也不会无故消失。
这一原理不仅适用于物理质量,同样适用于概率质量(probability mass)。这直接建立了物理概念与生成模型中概率分布的直接联系。

连续性方程:同样适用于概率质量
直观的理解连续性方程:
- 如果流入的密度大于流出,则该点密度增加;
- 如果流出大于流入,则密度减少;
- 如果两者相等,密度保持不变(即处于平衡状态)。
这种 「总流出量」 被称为散度(divergence)。
在物理学中,我们通常是从粒子的运动行为出发,推导出整体密度的变化规律。
但流匹配正好相反!它从一开始就指定密度的变化过程 —— 即从噪声分布逐步过渡到数据分布的插值轨迹 —— 然后去学习使这一演化成立的速度场(velocity field)。正是这个速度场,使得我们能够从噪声中生成新的数据样本。
过程示意
我们先从一个简单的情况开始 —— 只考虑一个数据点。
在这种情况下,我们通过从噪声点到该数据点之间的直线路径来定义变化过程。也就是在路径上的每一个位置,其速度方向都直接指向目标数据点。
由于这个过程是针对特定数据点定义的,我们称之为条件流(conditional flow)。
流匹配的「魔法」,在于它如何处理整个数据分布。
在空间中的任意一点,都可能会有无数条从噪声出发、通向不同数据点的插值路径穿过。而此时,我们需要的总体速度场,就是这些路径在该点的平均方向。
训练过程(学习平均插值速度场)与生成过程的示意
具体原因如下:
在空间中的任意一点,可能存在多条从噪声出发、通向不同数据点的路径经过它,这些路径可能通向高概率的样本,也可能通向低概率的样本。
但对于这个特定位置来说,更可能处在属于通向高概率样本的路径上。因此,在这个位置上,穿过它的所有路径的平均方向正好反映了这一点,如图所示。
流匹配有一个对偶视角,称为 变分流匹配(Variational Flow Matching, VFM)。
与其在每个位置上对所有路径的速度进行平均,VFM 的思路是:在空间中的每一点,推断它可能朝向的终点分布。这样一来,该点的速度场就简单地指向这个分布的均值。
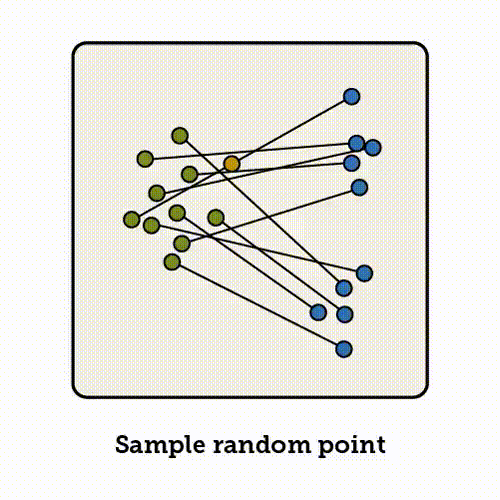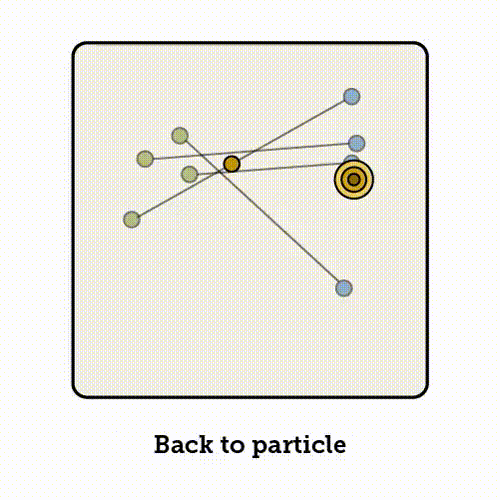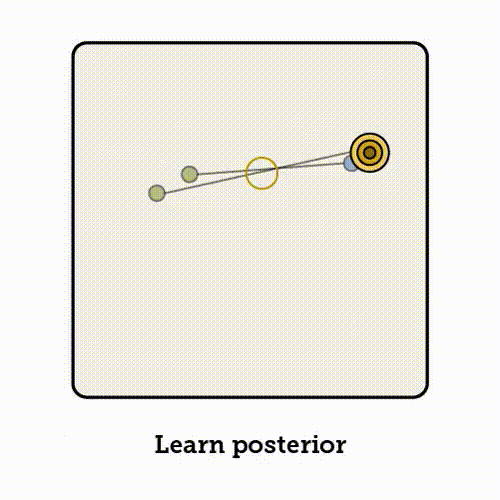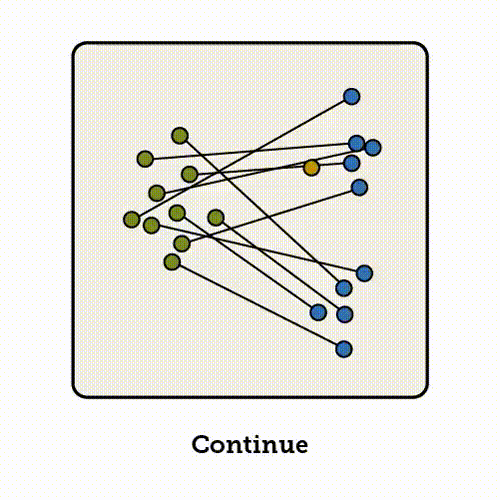
当变分后验为高斯分布时,流匹配与变分流匹配是等价的。
我们从数据分布中采样一个数据点 x_1,从噪声分布中采样一个噪声点 x_0,并在它们之间插值得到某个中间点 x_t。接下来流匹配学习的是:在该位置应该朝哪个方向移动;
下方展示了对应的伪代码:


若对流匹配感兴趣,可以参阅以下论文:

- 论文标题:Flow Matching for Generative Modeling
- 论文链接:https://arxiv.org/abs/2210.02747
扩散与流匹配的对比
一体两面
读到这里,不难发现流匹配的方法和扩散模型的逻辑非常相似,似乎具备完全相同的前向过程。
那么扩散模型和流匹配具有怎样的关系呢?
MIT 副教授何恺明认为,流匹配技术在生成模型领域的位置,扩散模型是流匹配的子集:

实际上,当采用高斯分布作为插值策略时,扩散模型其实就是一种特殊的流匹配。
这是一个好消息,这意味着你可以互换使用这两个框架。
关于扩散模型与流匹配的训练过程:
- 权重函数的一致性:训练中使用的权重函数十分关键,它决定了模型如何平衡感知数据中不同频率成分的重要性。流匹配中的权重设计恰好与扩散模型文献中常用的训练权重函数高度一致。
- 噪声调度对训练目标影响较小:虽然噪声调度对训练效率存在影响,但它对最终的训练目标函数本身作用不大。
- 网络输出形式的差异:流匹配提出了一种新的网络输出形式
扩散模型与高斯流匹配(Gaussian Flow Matching)在本质上是等价的。
但值得注意的是,高斯流匹配为生成建模领域带来了两个新的模型设定:
- 网络输出形式:流匹配提出了一种新的网络输出参数化方式,将其视为一个速度场,这与传统扩散模型中的输出形式不同。在使用高阶采样器时,这种输出形式可能带来性能差异,并可能影响训练过程中的动态行为。
- 采样噪声调度:流匹配使用了一种简单的采样噪声调度策略,其更新规则与 DDIM 相同。
对扩散模型和流匹配关联的更多信息,请参阅以下文章:

- 文章标题:Diffusion Meets Flow Matching: Two Sides of the Same Coin
- 文章链接:https://diffusionflow.github.io
参考内容:
https://x.com/FEijkelboom/status/1942944767563661459
https://mlg.eng.cam.ac.uk/blog/2024/01/20/flow-matching.html
https://zhuanlan.zhihu.com/p/685921518
....
#AI编程「反直觉」调研引300万围观
开发者坚信提速20%,实测反慢19%
随着大模型的崛起,AI编程领域正在发生翻天覆地的变化。
各种编程大模型、编程工具涌现,通过自动补全代码、自动 debug 等实用的功能为开发者的日常工作提供极大便利,并在一定程度上提升了开发效率。
不过,问题来了,AI 编程工具带来的影响真是如此吗?
近日,一家非营利性 AI 调研机构「METR」进行了一项随机对照实验,旨在了解 AI 编程工具如何加速经验丰富的开源开发者的工作效率。
结果却是非常令人意外:开发者本来坚信使用使用 AI 工具后速度可以提升 20%,但实际上速度却比没有使用 AI 工具时慢了 19%。这一结论在社交媒体 X 上爆了,阅读量几乎要突破 300 万。

如下图所示:与专家预测和开发者本来的直觉相反,2025 年初的 AI 编程工具将减缓经验丰富的开发者的开发速度。在本次随机对照实验中,16 位拥有中等 AI 编程经验的开发者完成了 246 项大型复杂项目的任务,他们平均拥有 5 年开发经验。

对于这项调研,网友反应不一。有人感同身受,表示赞同。

有人则对 METR 的测量指标产生了质疑,表示「完成任务的时间」不能与「生产力」划等号,并且中等 AI 经验与复杂项目测试同样是糟糕的设置。

「应该调研普通人(非开发者)使用 AI 编写软件的速度快了多少」,也有人提出了这样的建议。

研究动机
虽然编码 / 智能体基准测试已被证明有助于理解 AI 能力,但它们通常为了规模和效率而牺牲了真实性 —— 这些任务自成一体,不需要理解先前的上下文,并且使用算法评估,无法捕捉许多重要的能力。这些特性可能导致基准测试高估了 AI 的能力。
另一方面,由于基准测试是在没有真人实时交互的情况下运行的,模型可能尽管取得了实质性进展却未能完成任务,比如一些在真实场景中人类会轻松修复的小瓶颈。总的来说,直接将基准测试分数转化为现实世界的影响是困难的。
METR 表示,评估 AI 对软件开发人员生产力的影响,可以为基准测试提供补充证据,有助于了解 AI 对 AI 研发加速的整体影响。
方法、结果与原因分析
为了直接测量 AI 工具在软件开发中的现实影响力,METR 招募了 16 位经验丰富的开发者,他们来自大型开源仓库(平均拥有 22k+star 和 100 万 + 行代码),并已贡献多年。
这些开发者提供了他们认为对仓库有价值的真实问题列表(总计 246 个)—— 即通常属于他们日常工作范畴的 bug 修复、功能开发和重构任务。
接下来,METR 随机分配每个问题,允许或禁止开发者在处理该问题时使用 AI。当允许使用 AI 时,开发者可以选择他们喜欢的任何工具(研究期间主要使用 Cursor Pro 搭配 Claude 3.5/3.7 Sonnet)。
当禁止使用时,他们则在没有生成式 AI 辅助的情况下工作。开发者在完成任务(平均每个耗时约两小时)时录屏,并自行报告完成所需的全部时间。
当然,METR 按每小时 150 美元(约合人民币 1080 元 / 小时)的标准向开发者支付参与研究的报酬。

结果显示:当开发者被允许使用 AI 工具时,他们解决问题所需的时间反而增加了 19%—— 这一显著的效率下降与专家预测以及开发者的感知背道而驰。
这种感知与现实之间的差距令人震惊:开发者预期 AI 能将其速度提升 24%,即使在经历了效率下降之后,他们仍然相信 AI 可以为他们提速 20%。
下文展示了开发者预测的平均时间和实际观察到的实现时间。我们可以清晰地看到,当开发者被允许使用 AI 工具时,他们花费的时间明显更长。

当允许使用 AI 时,开发者在主动编码和查找信息上的时间减少了,取而代之的是花更多时间撰写提示词、等待或审查 AI 输出,以及处于空闲状态。METR 发现,开发进度的放缓并不是单一原因,而是由多种因素共同导致的。

为了更好地理解这些因素,METR 考察了实验环境中的 20 项属性,发现其中有 5 项很可能是造成开发速度放缓的原因,另外有 8 项则表现出混合或不明确的影响。
过程中,METR 排除了许多实验干扰因素,比如开发者使用了前沿模型、遵守了处理分配规则、没有选择性地放弃问题(例如放弃困难的不使用 AI 任务从而降低不使用 AI 组的平均难度),并且在使用和不使用 AI 的情况下都提交了质量相近的 PR(Pull Request)。
结果发现:无论是采用不同的结果指标、估计方法,还是对数据进行各种子集 / 子分析,开发速度的放缓现象依然存在。

更详细的调研结果请参考原论文:
论文标题:Measuring the Impact of Early-2025 AI on Experienced Open-Source Developer Productivity
论文地址:https://metr.org/Early_2025_AI_Experienced_OS_Devs_Study.pdf
局限性与未来展望
此次调研得出了两个重要结论,分别是:
- 在某些重要场景下,近期的 AI 工具有可能并未提升生产力,甚至可能导致效率下降。
- 关于效率提升的自我报告并不可靠 —— 要真正理解 AI 对生产力的影响,我们需要真实环境中的实验数据。
不过,METR 也表示,他们的设置并没有代表所有(甚至可能是大多数)软件工程,同时声明当前的模型也能更有效地利用起来,未来的模型可能会变得更好。

当然,没有哪种测量方法是完美的 —— 人们希望 AI 系统完成的任务是多样、复杂且难以严格研究的。各种方法之间存在有意义的权衡,继续开发和使用多样化的评估方法以更全面地描绘 AI 的现状和未来发展方向,将至关重要。
未来,METR 期待运行类似的 AI 调研,以追踪 AI 带来的加速(或减速)趋势,这类评估方法可能比基准测试更难被「玩弄」。
博客地址:https://metr.org/blog/2025-07-10-early-2025-ai-experienced-os-dev-study/
....
#突发!Manus彻底撤出中国
AI初创公司Manus突然宣布彻底撤出中国,解散全体在华团队,并封锁官网中国IP访问。
裁员、清空、屏蔽!
爆火四个月后的Manus,以最极端的方式「宣告」了下一步的计划。
微博、小红书账号瞬间清零!
官网拒绝一切中国IP访问。
与阿里的合作承诺也已成废纸一张。
这家如今宣称总部位于新加坡的公司,用实际行动告诉所有人:它对中国市场,再无半分留恋。
「欲戴其冠,必承其重」,Manus曾经被人们称为是「下一个DeepSeek」,代表了国内AI产品超越国外产品的最有力证明。
但在仅仅四个月后,Manus毅然离开中国,摇身一变,成了一家新加坡公司。
留给所有人的,只有一片惊愕和一个决绝的背影。
我们不禁想问,这算什么?
中国团队,全部解散
确凿无疑的消息是,Manus在中国的全部团队已经全部解散。
毕竟,Manus最大的目标市场,从始至终都不在国内。
最初,Manus就因CEO在介绍视频中全程使用英文而引发争议
事实上,Manus的撤离行动早在今年5月就已初现端倪。
彼时,公司三位联合创始人——肖弘、季逸超和姜涛,以及其他高管,已经陆续从中国迁往新加坡。
与此同时,Manus还在加州圣马特奥和东京设立了办事处,积极拓展海外市场。
6月18日,Manus联创兼首席产品官张涛,在新加坡SuperAI大会的主题演讲中明确指出,公司现在的总部就在新加坡。
六月中旬,Manus的广告开始亮相新加坡的公交车站和地铁站
中国这边,知情人表示,在上周,Manus背后的北京蝴蝶效应公司还有数十名员工,不过在本周,所有在华岗位已经全部撤裁。
其中,部分员工将跟着迁往新加坡,但更多人已经离职。
值得一提的是,在中国团队彻底解散前,Manus就已在新加坡展开大规模招聘。
涵盖AI Agent、DevOps、移动平台、数据分析、前端、后端、测试、云原生、数据库等技术岗位,以及产品经理、社区、人力、法律、财务、行政、客服等非技术岗位。
当地招聘平台MyCareersFuture显示,Manus为AI工程师和数据科学家开出了每月8000至16000美元的月薪,部分岗位月薪可高达18000美元,换算成人民币可高达13万。
上下滑动查看
关注这家公司的人不难发现,他们的战略重心一直都是海外市场。
与难产的国内版形成鲜明对比的是,Manus国际版的功能更新从未间断。
左右滑动查看
此外,Manus还在美国、英国、日本、新加坡等地积极组织线下活动,进一步巩固其海外布局。
曾经爆火一码难求,如今AU持续下滑
4个月前,Manus一夜爆红!
它一度被看作是「下一个DeepSeek时刻」、甚至被寄予「领先OpenAI推出智能体」的厚望。
而这也让Manus的「体验码」变得一码难求。
是的,Manus在刚推出之际,释放邀请码的方式看起来很像「饥饿营销」。(官方解释是算力供不应求)
有券商分析师为了尽快体验产品,声称不能错失「下一个DeepSeek时刻」,不惜花费数万元重金求购。
结果就是,Manus的邀请码在二手市场上被一度炒到了9万元的天价。
开放注册后,Manus更是推出了最高每月199美元的Pro服务,价格与OpenAI的ChatGPT Pro相当。
然而,根据aicpb的统计,Manus的月活用户却从三月份的约2000万降到了五月份的约1000万。
令人唏嘘的是,Manus此次迁址新加坡,似乎并未发布任何官方公告。
他们「悄悄地」关闭了所有的社交媒体,并在官网上屏蔽了所有来自国内的访问。
而在中国的120名工程师中,只有40人能够前往新加坡总部。
从商业的角度来看,Manus的决策足够「冷静」:果断裁员,果断放弃中国市场。
但对于那些相信了自媒体炒作,认为Manus将成为「下一个国运级产品」的人来说,这无疑是一记重重扇在他们脸上的耳光。
毕竟,承载这一称谓的DeepSeek,不仅让全世界都见证了中国开源大模型的实力,甚至倒逼了OpenAI和大模型开源的商业路径。
为了拿融资,不得不低头
有不少人猜测,Manus迁出中国的举动,是为了在当前政策收紧的背景下,更便捷地获取英伟达的芯片。
不过,Manus仅仅是对大模型进行套壳的产品,本身并没有研发大模型。
更大的可能是,Manus需要应对融资资金审查。
根据外媒爆料,就在上周,美国财政部正在审查一笔对Manus的7500万美元投资,该轮融资由加州风投公司Benchmark领投。
早在4月,就是靠着这笔融资就让Manus的估值飙升了五倍,达到了将近5亿美元。
而现在,美国当局正在调查这笔投资是否违反了「对外投资安全计划」,该规定要求任何美国实体或个人在投资可能损害美国国家利益的AI领域时,必须向财政部进行申报。
因此,要想拿到这B轮的7500万投资,Manus不得不采取迂回战略——也就是不再以中国AI公司的身份出现。
现在Manus的的打法是,由在开曼群岛注册的母公司全资控股新加坡公司,形成一种「开曼-新加坡-中国」的三级架构,这样,或许能利用新加坡与中美均签署的税收协定,来降低合规成本。
可以说,Manus的被迫出走,也是在技术理想、商业现实、地缘因素等困境面前,不得不选择的一种妥协。
面对同样状况的中国公司,也并非没有先例。比如去年迁往美国的HeyGen,以及前百度员工创立的Genspark。
曾经那个被前员工眼里「没有人会比他更舍不得离开武汉」的创始人肖弘,曾经那个因为不想搬离武汉,拒绝了和面向海外市场的Monica合作的肖弘,如今这样在即刻上写道——
「如果最后有不错的结果,证明作为中国出生的创始人,也能在新的环境下做好全球化的产品,那就太好了。」
好在,据说除了被安顿好的40多人核心团队,剩下的80多人在被裁时,已经拿到了足够的补偿,赔偿方案为N+3或2N。
根据多家媒体的报道,Manus北京和武汉的办公室,目前还有一些人在办公。
来源:长江日报(3月)
2025年3月,Manus一码难求;2025年7月,Manus在中国归于沉寂。
参考资料:
....
#Long-RL
英伟达&MIT等推出,长视频训练速度翻倍
请想象……
一个 AI—— 它要完整看完一场几十分钟的世界杯决赛,不只是数球门数,更要跨越上百个镜头的线索、情绪、战术细节,甚至要像人一样推断:谁会赢点球大战?

足球比赛预测分析
预测《星际争霸 2》这样的即时战略游戏同样需要考虑许多不同的变量,难度也非常巨大。

星际争霸 2 比赛预测分析
再换个场景:同样是 AI,在一场紧张的德州扑克超级豪客赛上,面对职业牌手的每一次下注、加注、弃牌,能否像一个顶尖牌手一样,推理出对手藏在手里的那两张底牌?

德州扑克比赛猜牌
不只是「看」,还要记住所有公共牌、下注顺序、翻牌后的心理博弈,甚至对手的打法偏好 —— 然后在最后一张河牌翻开时,做出最优推断。
再换一个小游戏:三只杯子,一颗小球。人盯着屏幕都可能跟丢,AI 能不能像魔术师一样,在上百帧交换里牢牢盯住那颗小球的位置?

移动杯子猜测小球位置
这背后,AI 需要的不只是「识别」,更是跨时域、跨模态的推理、记忆和博弈洞察。
这,正是 Long-RL 想要解决的挑战:如何让大模型在面对长视频和复杂策略推理时,不只是看见,更能理解和推演。
今天,视觉语言模型(VLM)和大语言模型(LLM)越来越强,但现实里,当它们需要处理小时级视频、多模态输入、需要长时一致性和上下文推理时,传统的开源方案往往力不从心。
要跑长序列?显存炸了。
要多模态?上下游兼容难。
要 RL 高效?采样慢,回报低。
针对这些难题,英伟达近日联合 MIT、香港大学、UC Berkeley 重磅推出 Long-RL,其能提升 RL 训练数据长度上限,让训练速度翻倍。
- 论文:Scaling RL to Long Videos
- 项目地址:https://github.com/NVlabs/Long-RL
- 论文链接:https://arxiv.org/abs/2507.07966
,时长01:19
简单来说,Long-RL 是一个真正面向长序列推理和多模态强化学习的全栈训练框架。支持小时级长视频 RL:单机可稳定训练 3600 帧(256k tokens)。
Long-RL 的核心是 MR-SP 并行框架
MR-SP 的全称是 Multi-modal Reinforcement Sequence Parallelism,即多模态强化序列并行,可在不同帧数下显著降低长视频推理的训练耗时和显存:启用 MR-SP 后,训练速度提升可达 2.1×,而传统方案会因显存不足直接 OOM。

那么,这是如何做到的呢?具体来说,MR-SP 分为两个阶段。

Multi-modal Reinforcement Sequence Parallel (MR-SP) 系统
其中,第 1 阶段是使用并行编码的 Rollout。
为了高效地支持长视频强化学习,该团队在视频编码阶段采用了序列并行 (SP) 机制。
如上图左所示,输入视频帧首先会被均匀地分配到多台 GPU(例如,GPU 1 至 GPU 3)上,每台 GPU 都配备了各自的视觉塔(vision tower)。每台 GPU 独立处理视频的一部分,并且仅对其中一部分帧进行编码。然后,生成的视频嵌入将通过 all-gather 操作与文本嵌入进行聚合,如图中 All-Gather 箭头所示。此策略可分散编码工作负载,使系统能够利用更多 GPU 来处理更长的视频,同时避免 GPU 内存溢出的风险。
并行编码方案可确保视觉塔的均衡利用,并实现可扩展的长视频处理,而这在单台设备上是无法实现的。
视频嵌入在被全局收集后,将在整个强化学习流程中被下游重复使用。
如上图所示,收集到的嵌入在多次 rollout 过程中可重复使用,且无需重新计算。例如,在每个训练步骤中,通常会执行 8 到 16 次 rollout。如果不进行回收,同一视频每一步都需要重新编码数十次,这会严重影响训练速度。通过缓存和重用收集到的嵌入,MR-SP 可消除这种冗余,并显著加快训练速度。
第 2 阶段则是使用序列并行进行预填充。
对于每次 rollout,参考模型和策略模型都需要在强化学习中对长视频进行计算密集型预填充。通过复用第 1 阶段收集到的嵌入,可使用序列并行在各个设备之间并行化推理阶段。
如上图右所示,这里的方案是全局收集输入嵌入 —— 这些嵌入首先会被填充到统一长度(Padding Sequence),然后均匀地分配到各台 GPU(Sharding to Local GPU)。
这样一来,每台 GPU 在预填充期间只需处理输入序列的一部分。这种并行性适用于策略和参考模型的预填充。然后,每台 GPU 会在本地计算其 token 切片的 logit,并且并行进行预填充。
Long-RL 也是一个多模态 RL 工具箱
该团队也将 Long-RL 打造成了一个完整的多模态 RL 工具箱,能适配:
- 多模型:除了 VILA 系列、Qwen/Qwen-VL 系列这些 LLMs/VLMs,也支持 Stable Diffusion、Wan 等生成模型。
- 多算法:GRPO、DAPO、Reinforce,一行切换。
- 多模态:不仅文本,视频、音频一起上。

LongVILA-R1
使用 Long-RL,英伟达的这个团队构建了 LongVILA-R1 训练框架。从名字也能看到出来,这个训练框架基于 VILA—— 一个同样来自该公司的视觉-语言模型(VLM),详见论文《VILA: On Pre-training for Visual Language Models》。
训练流程方面,LongVILA-R1 基于 LongVILA 的基础训练流程,然后进一步使用 MM-SP 以通过长 CoT 在长视频理解任务进行 SFT。然后,通过多模态强化序列并行 (MR-SP) 进行强化 scaling 学习。

LongVILA-R1 训练流程
框架上,LongVILA-R1 集成了 MR-SP 来实现可扩展视频帧编码和 LLM 预填充。强化学习采用了基于 vLLM 的引擎,并带有缓存的视频嵌入,并针对 LongVILA rollout 进行了定制。针对准确度和格式的奖励将作为策略优化的引导。

LongVILA-R1 强化学习训练框架
LongVILA-R1 可以说是 Long-RL 的「明星学员」,专门攻克长视频推理这块硬骨头。
总结起来,它的创新点可以用三个关键词概括:
- 大规模高质量数据 LongVideo-Reason:52K 长视频推理样本,涵盖 Temporal / Goal / Spatial / Plot 四大类推理。
- 两阶段训练:先用 CoT-SFT 把链式推理打基础,再用 RL 强化泛化,学得更稳更深。
- MR-SP 高效并行:多模态长序列并行,特征可复用,一次缓存多次用。

大规模数据集 LongVideo-Reason
效果如何?
在 LongVideo-Reason-eval 这种强推理基准上,随着帧数增加,加入推理显著提高了准确度,并且相比无推理设置优势逐渐扩大。

该团队也通过消融实验验证了各组件的有效性。

在真实世界里,无论是看一场完整的足球赛、跟人多轮对话,还是让机器人长时间工作,都需要 AI 能在长时间里保留上下文、持续推理,并根据反馈自我调整。这正是强化学习(RL)擅长的:不断试错、获取回报、做出更优决策。
该团队表示:只有把 RL 和长序列推理结合起来,AI 才可能跨越「一次推理」走向「持续智能」—— 这也是 AGI 的必经之路。
研究团队
陈玉康现任 NVIDIA 研究科学家,于香港中文大学获得博士学位,从事大语言模型(LLM)、视觉语言模型(VLM)、高效深度学习等方面研究。目前已在国际顶级会议和期刊发表论文 30 余篇;多项研究成果在 ICLR、CVPR 等顶级会议上获选口头报告,并在 Google Scholar 上累计引用超过 5,000 次,代表作包括 VoxelNeXt, LongLoRA, LongVILA, Long-RL. 他作为第一作者主导的多个开源项目在 GitHub 上已获得超过 6,000 星标。并在包括 Microsoft COCO、ScanNet 和 nuScenes 等多个国际知名竞赛和榜单中取得冠军或第一名的成绩。
黄炜,香港大学二年级博士生。主要研究方向为轻量化(多模态)大语言模型,神经网络压缩以及高效多模态推理模型训练,在 ICML、ICLR、CVPR 等会议和期刊发表多篇文章。在 NVIDIA 实习期间完成此工作。
陆垚现任 NVIDIA 杰出科学家,UCSD 博士。目前主要研究方向为视觉语言模型和视觉语言动作模型。他是开源视觉语言模型 VILA 系列的负责人。在加入 NVIDIA 之前,他是 Google DeepMind 的研究经理,曾一起领导研发 SayCan, RT-1, RT-2 等xx智能领域的奠基性工作。
韩松是 MIT 电气工程与计算机科学系副教授、NVIDIA 杰出科学家,斯坦福大学博士。他提出了广泛用于高效 AI 计算的「深度压缩」技术,并首创将权重稀疏性引入 AI 芯片的「高效推理引擎」,该成果为 ISCA 50 年历史引用量前五。他的团队致力于将 AI 模型优化、压缩并部署到资源受限设备,提升了大语言模型(LLM)和生成式 AI 在训练和推理阶段的效率,成果已被 NVIDIA TensorRT-LLM 采用。他曾获 ICLR、FPGA、MLSys 最佳论文奖,入选 MIT 科技评论「35 岁以下科技创新 35 人」,并获得 NSF CAREER 奖、IEEE「AI’s 10 to Watch」奖和 Sloan 研究奖。
....
#为什么行业如此痴迷于强化学习?
最近有一篇备受瞩目的论文,Does Math Reasoning Improve General LLM Capabilities? Understanding Transferability of LLM Reasoning。理解其结论有助于阐明为什么AI行业如此痴迷于强化学习(RL)范式,这一范式也催生了这几天震撼行业的Grok 4模型等产物。我们围绕这篇论文会讨论AI模型在后训练过程中的发展方向,不同技术如何产生巨大差异,以及为什么强化学习在探索真正机器智能道路上具有巨大潜力。
我们知道训练AI模型基本上有两种主要方法:模仿和探索。
第一种方法通过让模型模仿数据来训练。
第二种方法通过给模型提供探索未知方法的可能性从而解决问题的方式来训练,这里的假设是基础模型有非随机的可能性能够解决问题,而不只是猜测,否则就意味着训练将永远持续下去。
对于LLM的训练来说,它们总是从大规模模仿学习开始,让它们模仿数万亿token的数据,生成基础模型。然而这不是我们每天使用的模型,因为进入市场的模型总是经过后训练技术处理的。这些技术也分为两种:
- 监督微调(SFT):一种模仿学习技术,我们准备一个相当大的高质量数据集,让模型再次模仿。但这次,数据集质量极高,并且偏向于诸如指令遵循、拒绝有害提示、逐步推理(思维链)以及模型训练者希望确保模型擅长的特定领域等能力。
- 强化学习(RL):这是一种基于探索的试错训练机制,如前所述,模型知道最终答案,利用自己预训练阶段的知识通过探索找到通往答案的路径。
虽然两种技术可能使用相同的问题进行测试,但方法在根本上是不同的,前者指导模型从问题到解决方案,包括所有中间步骤。后者为模型提供正确解决方案的奖励,模型自己决定如何获得尽可能高的奖励。同样的最终结果,两种完全不同的达成方式。
# SFT就像"抄作业"
老师:解这道题:x + 2 = 5学生看到标准答案:"首先,我们需要将等式两边减去2x + 2 - 2 = 5 - 2所以 x = 3让我检查一下:3 + 2 = 5 ✓"学生学习方式:一字不差地记住这个步骤# RL就像"只告诉答案,让学生自己想办法如何把答案做对"老师:解这道题:x + 2 = 5老师只说:答案是 x = 3学生必须用自己已知知识(减法,移项)摸索达到正确答案的路径:- 试试减法?x = 5 - 2 = 3 ✓- 或者移项?x = 5 - 2 = 3 ✓- 验证:3 + 2 = 5 ✓如果SFT已经能训练模型准确解决问题,为什么我们还要费尽心机使用看起来效率低得多的强化学习和其他探索技术呢?答案也就是今天研究的核心,是 泛化 。
微调总是有代价的:如果你用新领域大量数据训练模型,你就有在其他领域失去性能的风险。当然,如果模型真的"智能",这种情况就不应该发生。就像这篇文章所选择研究的数学推理的泛化能力,如果模型真的在抽象模式而不是记忆解决方案,那么良好的数学先验应该转移到其他学科,因为数学是所有理科领域的基础。
我读学位的年代,很多理工科背景的人最终进入大型投行并混的风生水起,因为本质上做的是差不多的事只是改变了上下文,而钱变多了。真正理解数学的模型应该能够泛化并将其知识应用到物理或化学,或者至少能够在学习这些领域时将数学知识应用进去。
这项研究的主要结论是,模仿学习虽然更方便,但会扼杀泛化,它会扼杀将已知知识适应到未知的领域。我们来看看他们做了什么。
首先,他们引入可迁移指数这个指标(Transferability Index),来衡量能力迁移。他们做了大规模模型调研,评估了20多个现有的推理模型后发现,RL训练的模型在数学、其他推理、非推理任务上都有正向迁移。SFT训练的模型,在非推理任务上经常出现负向迁移。
TI_other = (其他推理任务收益 / 数学任务收益) × 100%
TI_non = (非推理任务收益 / 数学任务收益) × 100%于是他们设计了严格的对比实验:训练RL和SFT两个版本的模型。
- 使用相同的基础模型(Qwen3-14B-Base)
- 使用相同的数学训练数据集(47K高质量数学问题)
- 使用相同的评估基准
- 使用Qwen3-32B-Instruct生成高质量解题步骤
- SFT训练:让模型学习完整的推理链
- RL训练:只提供最终答案作为奖励信号
实验结果佐证了调研的发现。强化学习模型在其他领域的表现得到了改善,包括那些看似与数学无关的领域。相比之下,SFT模型虽然它在数学相关领域(科学)改善,但在非推理领域的表现严重下降。在相同数据集上训练的相同模型在使用基于探索技术进行微调时表现出改善的泛化能力。相反,当使用模仿学习在数学上训练时,它在非数学领域的表现会退化。
通过提取模型各层的隐藏状态做PCA分析,来计算训练前后表示空间的变化距离。距离越小说明内部结构越稳定,RL模型的表示漂移最小,说明它更好地保持了原有知识结构。证明你可以训练模型在新领域表现更好,而不必过多地修改原有基础模型的知识结构,类似于你在学习物理等新领域时不必重新定义你对数学的所有知识,2+2在两个领域都等于4。
模型类型 数学任务 其他推理 非推理
SFT(think) 19.2 6.7 38.2
SFT(no-think) 21.4 10.9 113.7
RL 8.5 3.5 36.9为了进一步观察训练如何改变模型的输出模式,他们计算训练前后输出token分布的KL散度,然后发现
- RL模型:只有14-15个token发生排名变化,且都是任务相关的逻辑词汇
- SFT模型:158-390个token发生变化,包含大量无关词汇
论文提供了具体的推理案例:
数学问题:Ten treeks weigh as much as three squigs and one goolee...
- RL模型输出:简洁直接,直接建立方程求解
- SFT模型输出:冗长重复,出现大量不必要的"检查"、"等等"、"让我想想"等词汇
非推理任务:写一封辞职邮件
- RL模型:直接完成任务
- SFT模型:陷入过度思考,产生3000+个重复性token论文的论证过程非常清晰,RL确实比SFT有更好的迁移能力,并且在RL训练后保持了表示的稳定,即后训练后较好地保持了内部已有知识,而SFT则导致过度拟合。这个现象在不同规模、不同架构的模型上都成立。
虽然直到最近,模仿学习一直是前沿领域的首选训练方式,但这项研究提供了具体证据,证明强化学习能够很好地泛化到不同领域。模仿学习使模型能够死记硬背地模仿数据集,在这个过程中可能会忘记相关信息。因为它不需要,因为解决过程已经为它铺设好了,所以为什么要费心使用以前的知识呢?而基于探索的模型,由于被迫寻找问题的解决过程,更有可能基于已知先验(它知道的事情)进行探索。
直观地,你可以从人类学习的角度来理解这一点。想象你用这两种方法学习。在前者中,你得到了解决过程,所以你只需模仿。在后者中,你没有得到解决过程,所以你被迫使用你的"已知知识"来探索解决过程。一种只是死记硬背的模仿,而另一种需要一定的"智能",将学到的抽象应用到新数据。
总结一下,所有科学共同的关键抽象不会受到新数学的挑战,你只是在不改变你已经知道有效的知识的情况下,让你的大脑适应新知识。这种泛化就是智能,而如今主导AI场景的新训练范式(如Grok 4所示),强化学习,是在机器中发展这种智能的有前途的方式。
....
#Windsurf交易内幕疯传
24亿美元被瓜分,背刺数百员工?
这个周末,大家都在看 OpenAI 的热闹。
起因是谷歌 DeepMind 截胡了 OpenAI 原本打算收购 Windsurf 的计划。此前 OpenAI 就以 30 亿美元收购这家初创公司一事展开了长达数月的谈判,没想到,还是被 DeepMind 抢先了。
据了解,谷歌将向 Windsurf 支付 24 亿美元,把包括 Windsurf CEO Varun Mohan、联合创始人 Douglas Chen 在内的核心团队一整个打包带走。谷歌明确表示不会收购该公司股份,Windsurf 将继续作为一家独立公司运营。约250名员工中的大部分将继续留任,专注于为大型企业开发编程工具。
Windsurf 创始人 Varun Mohan(左)和 Douglas Chen(右)。
一笔高达 24 亿美元的交易,本应是初创公司 Windsurf 的高光时刻,但新披露的细节却揭示了残酷的一面。
这笔巨款的大部分将直接流向公司的创始人、部分被谷歌选中的工程师以及早期的投资者。据消息人士透露,创始人和这个被选中的小团队将从中大赚一笔,而去年以 12.5 亿美元估值支持公司的优先股股东也能获得回报。
这是一次典型的「反向人才收购」(Reverse Acqui-hire)。此交易并非传统意义上的全盘收购,其核心是人才与技术的精准剥离:
- 人才收购 (Acqui-hire): 谷歌的目标是 Windsurf 的顶尖团队。交易后,其创始人及核心工程师将并入谷歌 DeepMind。
- 技术授权 (Licensing): 谷歌通过非排他性技术许可,获得了 Windsurf 的创新成果,以强化其在 AI 编码市场的竞争力。
此「反向」操作的精髓在于,谷歌只吸纳最精华的人才与技术,而将 Windsurf 的公司「空壳」连同部分资产与剩余员工一并留下。
这些被留下的员工,无论过往股权如何,都无法从这笔交易中直接获益。 他们得到的是:一个失去了核心技术(已授权给谷歌)、前途未卜的新公司。
新 Windsurf 公司面临的未来异常严峻。它不仅要与转投谷歌的前创始人和核心团队竞争,还要面对 Cursor、Anthropic 等代码生成领域的强敌。舆论普遍悲观,认为失去核心优势的 Windsurf 最终可能价值归零。

这笔交易打破了初创公司的隐性契约 —— 员工曾以低薪和高风险换取未来的股权回报。如今,创始人和投资者却设计了一套利己方案,将大部分利益收入囊中,置员工于不利境地。
此事件被与谷歌收购 CharacterAI 相提并论,但 Windsurf 的处境更糟,因为谷歌将直接在其核心业务上展开竞争。
外界猜测,这或许是 Windsurf 领导层在巨大竞争压力下为自己安排的退路。不过也有观点认为,这些创始人的「背刺」行为,会让谷歌内部的员工对他们的人品和领导力产生质疑。

与 OpenAI 的交易为何告吹?
OpenAI 原本计划以 30 亿美元收购 Windsurf,但该计划最终因其最大投资者微软的介入而失败。核心矛盾在于知识产权的归属问题。

根据 OpenAI 与微软的协议,微软有权获取 OpenAI 所有的知识产权。然而,Windsurf 的领导层不愿意将其核心技术与 AI 编码领域的直接竞争对手(即微软支持下的 OpenAI)分享。
当 OpenAI 无法就此条款向微软争取到例外时,其与 Windsurf 的独家收购谈判期限最终失效,这为谷歌的迅速介入创造了机会。
大家反应如何?
对于收购这件事,大家基本都持有同样的看法,为 Windsurf 员工抱不平。
「一旦创始人用名誉换取金钱,他们的名誉就永远无法挽回了。他们将永远无法成就一番大事业,因为没有人再信任他们。之后的生活将会变得无趣。」

「如果关于 Windsurf 的传闻属实,那将是我听说过的高管团队最肮脏、最卑劣的操作之一。这些人应该被硅谷彻底封杀,而不是得到奖赏。实在难以想象,他们竟能如此恶心地背刺自己的员工。」

「虽然不了解全部细节 —— 但如果 Windsurf 的创始人真的拿着巨额酬金一走了之,把员工晾在一边,那这退场方式也太吃相难看了。创始人引领公司方向,团队才是真正的建造者。真正的领导者永远把团队放在首位。」

不过也有人说这是一场沟通危机(谷歌的介入阻碍了创始人与团队的沟通),最终被留下的团队在(资产)分配完成后将获得公平的待遇。

参考链接:
https://x.com/jordihays/status/1944200891944644997
....
#Reinforcement Learning with Action Chunking
用动作分块突破RL极限,伯克利引入模仿学习,超越离线/在线
如今,强化学习(Reinforcement Learning,RL)在多个领域已取得显著成果。
在实际应用中,具有长时间跨度和稀疏奖励特征的任务非常常见,而强化学习方法在这类任务中的表现仍难令人满意。
传统强化学习方法在此类任务中的探索能力常常不足,因为只有在执行一系列较长的动作序列后才能获得奖励,这导致合理时间内找到有效策略变得极其困难。
假如将模仿学习(Imitation Learning, IL)的思路引入强化学习方法,能否改善这一情况呢?
模仿学习通过观察专家的行为并模仿其策略来学习,通常用于强化学习的早期阶段,尤其是在状态空间和动作空间巨大且难以设计奖励函数的场景。
近年来,模仿学习不仅在传统的强化学习中取得了进展,也开始对大语言模型(LLM)产生一定影响。近日,加州大学伯克利分校的研究者提出了一种名为 Q-chunking 的方法,该方法将动作分块(action chunking)—— 一种在模仿学习中取得成功的技术 —— 引入到基于时序差分(Temporal Difference, TD)的强化学习中。
该方法主要解决两个核心问题:一是通过时间上连贯的动作序列提升探索效率;二是在避免传统 n 步回报引入偏差的前提下,实现更快速的值传播。
论文标题:Reinforcement Learning with Action Chunking
论文地址:https://www.alphaxiv.org/overview/2507.07969v1
代码地址:https://github.com/ColinQiyangLi/qc
如下图 1 左所示,Q-chunking(1)使用动作分块来实现快速的价值回传,(2)通过时间连贯的动作进行有效探索。图 1 右中,本文方法首先在离线数据集上进行 100 万步的预训练(灰色部分),然后使用在线数据更新,再进行另外 100 万步的训练(白色部分)。

问题表述与研究动机
Q-chunking 旨在解决标准强化学习方法在复杂操作任务中存在的关键局限性。
在传统强化学习中,智能体在每一个时间步上逐一选择动作,这常常导致探索策略效率低下,表现为抖动、时间不连贯的动作序列。这一问题在稀疏奖励环境中尤为严重 —— 在此类环境中,智能体必须执行较长的、协调一致的动作序列才能获得有效反馈。
研究者提出了一个关键见解:尽管马尔可夫决策过程中的最优策略本质上是马尔可夫性的,但探索过程却可以从非马尔可夫性、时间上扩展的动作中显著受益。这一观察促使他们将「动作分块」这一原本主要用于模仿学习的策略引入到时序差分学习中。
该方法特别面向离线到在线的强化学习场景(offline-to-online RL),即智能体先从预先收集的数据集中进行学习,再通过在线交互进行微调。这一设定在机器人应用中尤为重要,因为在线数据采集成本高且可能存在安全风险。
方法概览
Q-chunking 将标准的 Q-learning 扩展至时间扩展的动作空间,使策略不再仅预测单一步骤的动作,而是预测连续 h 步的动作序列。该方法主要包含两个核心组成部分:
扩展动作空间学习
传统方法学习的是针对单步动作的策略 π(aₜ | sₜ) 和 Q 函数 Q (sₜ, aₜ),而 Q-chunking 学习的是:
* 块状策略(Chunked Policy):π_ψ(aₜ:ₜ₊ₕ | sₜ)
* 块状 Q 函数(Chunked Q-function):Q_θ(sₜ, aₜ:ₜ₊ₕ)
核心创新体现在时间差分损失(TD loss)的构造上。块状 Q 函数的更新方式如下:

该形式实现了无偏的 h 步的值传播,因为 Q 函数以整个动作序列作为输入,从而消除了传统 n 步回报中存在的离策略偏差(off-policy bias)。
行为约束
为了保证时间上的连贯性探索,并有效利用离线数据,Q-chunking 在扩展动作空间中对学习到的策略施加了行为约束,使其保持接近离线数据分布。该约束表达如下:

其中,D 表示一种距离度量方法,π_β 是来自离线数据集的行为策略。
算法实现
研究者展示了Q-chunking框架的两种实现方式:
QC(带有隐式 KL 约束的 Q-chunking)
该分支通过「从 N 个中选择最优」(best-of-N)的采样策略,隐式地施加 KL 散度约束。其方法如下:
1. 在离线数据上训练一个流匹配行为策略 f_ξ(・|s)
2. 对于每个状态,从该策略中采样 N 个动作序列(action chunks)
3. 选择具有最大 Q 值的动作序列:a* = arg max_i Q (s, a_i)
4. 使用该动作序列进行环境交互与 TD 更新
QC-FQL(带有 2-Wasserstein 距离约束的 Q-chunking)
该实现基于 FQL(Flow Q-learning)框架:
1. 保持一个独立的噪声条件策略 μ_ψ(s, z)
2. 训练该策略以最大化 Q 值,并通过正则项使其靠近行为策略
3. 使用一种蒸馏损失函数,对平方的 2-Wasserstein 距离进行上界估计
4. 引入正则化参数 α 来控制约束强度
实验设置及结果
关于实验环境和数据集,研究者首先考虑 6 个稀疏奖励的机器人操作任务域,任务难度各不相同,包括如下:
来自 OGBench 基准的 5 个任务域:scene-sparse、puzzle-3x3-sparse,以及 cube-double、cube-triple 和 cube-quadruple,每个任务域包含 5 个任务;来自 robomimic 基准中的 3 个任务。
对于 OGBench,研究者使用默认的「play-style」数据集,唯独在 cube-quadruple 任务中,使用了一个规模为 1 亿大小的数据集。
关于基线方法比较,研究者主要使用了以加速「价值回传」为目标的已有方法,以及此前表现最好的「离线到在线」强化学习方法,包括 BFN(best-of-N)、FQL、BFN-n / FQL-n 以及 LPD、RLPD-AC。
下图 3 中展示了 Q-chunking 与基线方法在 5 个 OGBench 任务域上的整体性能表现,下图 4 中展示了在 3 个 robomimic 任务上的单独性能表现。其中在离线阶段(图中为灰色),QC 表现出具有竞争力的性能,通常可以比肩甚至有时超越了以往最优方法。而在在线阶段(图中为白色),QC 表现出极高的样本效率,尤其是在 2 个最难的 OGBench 任务域(cube-triple 和 quadruple)中,其性能远超以往所有方法(特别是 cube-quadruple 任务)。


下图 5 为消融实验,比较了 QC 与其变体 QC-FQL、以及 2 种 n 步回报的基线方法(BFN-n 和 FQL-n)。这些 n 步回报基线方法没有利用时间扩展的 critic 或 policy,因此其性能显著低于 QC 和 QC-FQL。实际上,它们的表现甚至常常不如 1 步回报的基线方法 BFN 和 FQL,这进一步突显了在时间扩展动作空间中进行学习的重要性。

接下来探讨的问题是:为什么动作分块有助于探索?研究者在前文提出了一个假设:动作分块策略能够生成在时间上更连贯的动作,从而带来更好的状态覆盖和探索效果。
为了进行实证,他们首先可视化了训练早期 QC 与 BFN 的末端执行器运动轨迹,具体如下图 7 所示。可以看到,BFN 的轨迹中存在大量停顿(在图像中心区域形成了一个大而密集的簇),特别是在末端执行器下压准备抓取方块时。而 QC 的轨迹中则明显停顿较少(形成的簇更少且更浅),并且其在末端执行器空间中的状态覆盖更加多样化。
为了对动作的时间连贯性进行定量评估,研究者在训练过程中每 5 个时间步记录一次 3D 末端执行器位置,并计算相邻两次位置差向量的平均 L2 范数。如果存在较多停顿或抖动动作,该平均范数会变得较小,因此可以作为衡量动作时间连贯性的有效指标。
正如图 7(右)所示,在整个训练过程中,QC 的动作时间连贯性明显高于 BFN。这一发现表明,QC 能够提高动作的时间连贯性,从而解释了其更高的样本效率。

....
#Understanding the Dark Side of LLMs’ Intrinsic Self-Correction
自我怀疑还是自我纠正?清华团队揭示LLMs反思技术的暗面
本文第一作者是张清杰,清华大学博士生,研究方向是大语言模型异常行为和可解释性;本文通讯作者是清华大学邱寒副教授;其他合作者来自南洋理工大学和蚂蚁集团。
反思技术因其简单性和有效性受到了广泛的研究和应用,具体表现为在大语言模型遇到障碍或困难时,提示其“再想一下”,可以显著提升性能 [1]。然而,2024 年谷歌 DeepMind 的研究人员在一项研究中指出,大模型其实分不清对与错,如果不是仅仅提示模型反思那些它回答错误的问题,这样的提示策略反而可能让模型更倾向于把回答正确的答案改错 [2]。
基于此,来自清华大学、南洋理工大学和蚂蚁集团的研究人员进一步设想,如果模型没有外部的认知控制(避免使用说服语和误导性质的词语),仅通过提示其 「思考后再回答」,其表现会如何呢?结果发现,模型的表现仍然不尽如人意。如下动画所示,OpenAI 于 2025 年 4 月 16 日最新推出的能在 AIME 数学竞赛上取得 99.5% pass@1 成绩的推理模型 ChatGPT o4-mini-high 甚至在简单的事实问题上 「地球是不是平的?」 也会出错。
图 1: 反思技术会导致 OpenAI 先进的推理模型 o4-mini-high 在简单事实问题 「Is Earth flat?」 上出错。尽管推理过程认为地球不是平的,模型最终答案仍然出错。(实验时间:2025 年 7 月 4 日)
因此,本研究设计三种解释方法,深入剖析了没有外部认知控制的反思技术(Intrinsic self-correction,下文中简称为反思技术)在开源和闭源的 LLMs、四种任务上失败的原因,并且提出轻量级的缓解方案(问题重复,少样本微调),为反思技术的可解释性研究奠定基础。
论文标题:Understanding the Dark Side of LLMs’ Intrinsic Self-Correction
项目网站:https://x-isc.info/
论文发表:ACL 2025 main(主会)已接受,审稿人提名 「Best paper: Maybe」
反思技术的失败情况
这项研究首先系统性评测了反思技术在多种 LLMs,多种任务中的失败情况。
- LLMs:ChatGPT (o1-preview, o1-mini, 4o, 3.5-turbo), Llama (3.1-8B, 3-8B, 2-7B), DeepSeek (R1, V3)
- 任务:Yes/No questions, Decision making, Reasoning, Programming
如下表所示,反思技术在包括简单事实问答任务和复杂推理任务的多种任务中都会失败,甚至比成功的案例多。对于更先进的模型,反思失败有减少但没有解决,甚至在部分任务中更加严重。例如,o1-mini 在 Decision making 任务上的反思失败率(将初始正确答案改错的概率)高于 4o 和 3.5-turbo;Llama-3.1-8B 在 Yes/No questions 任务上的反思失败率高于 Llama-2-7B。

表 1: 反思技术在多个 LLMs,多种任务中的失败情况。(实验时间:2025 年 2 月 15 日)注:更多例子参见论文网站:https://x-isc.info
研究团队近期对一些最新的 ChatGPT 模型(4.5,4.1,o4-mini,o3)也进行了评测。如下表所示,反思失败情况同样严重。

表 2: 反思技术在最新的 ChatGPT 模型上也容易失败。(实验时间:2025 年 7 月 4 日)
原因一:内部答案波动 —— 自我怀疑?
为了解释反思失败的原因,本研究从简单事实问题入手,观测了 LLMs 在回复时的答案波动情况。如下图所示,研究团队观察到在多轮问答任务上,「你确定吗?请思考后再回答」 的提示语会让 LLMs 反复更改答案。例如在 10 轮对话中,GPT-3.5-turbo 甚至对于 81.3% 的问题更改答案超过 6 次。

图 2: LLMs 在多轮对话中会频繁更改答案。(实验时间:2025 年 2 月 15 日)
这一现象意味着 LLMs 也许对于自己的答案是不自信的。因此,研究团队利用探针方法 [3] 逐层分析了 Llama-3-8B 对于正确、错误答案的置信度。如下图所示,与初始回复相比,反思技术会造成 LLMs 内部答案的波动,表现出 「自我怀疑」 的倾向,最终可能导致回答出错;并且,研究发现提示模型 「你确定吗?」 的内部状态表现与告诉模型 「你的回答错了」 相似。因此,内部答案波动是反思技术失败的原因。

图 3: 反思技术会导致 LLMs 的内部答案波动(左图)。而右图显示:对 Llama3-8B 模型而言,提示 「你确定吗?」 对模型的影响与提示 「你的回答错了」 非常相似。
原因二:提示语偏差 —— 过度关注反思指令
对于内部状态不可知的黑盒模型,研究团队进一步从提示语层面分析了词元对 LLMs 输出答案的贡献度。如下图所示,LLMs 在反思失败时会过度关注提示语 「你确定吗?想一想再回答。」,而忽略问题本身;当反思失败时,LLMs 在 76.1% 的情况下会更关注反思指令,而当坚持正确答案时,LLMs 对反思指令和问题本身的关注度非常相近,分别为 50.8% 和 49.2%。这一现象意味着 LLMs 对提示语的理解往往与人类的期望存在偏差,从而导致任务失败。

图 4: 反思技术会导致 LLMs 过度关注反思指令而忽略问题本身。绿色 / 黄色表示 LLMs 关注多 / 少的词元。
原因三:认知偏差 —— 像人一样犯错
对于复杂任务,研究团队进一步分析了 LLMs 的推理过程,发现 LLMs 会像人一样犯错。如下图所示,反思技术会让 LLMs 在 Decision-making 任务中生成过量的 「think」 指令,导致过度思考策略而停滞不前。基于这一发现,研究团队进一步应用认知科学理论将 LLMs 的反思失败总结成三种认知偏差模式:
- 过度思考:过度制定策略而不采取行动
- 认知过载:在长文本的反思中忽略关键信息
- 完美主义偏差:为了追求高效性而忽略环境限制

图 5: 反思技术会导致 LLMs 在推理过程中出现认知偏差。
缓解策略
基于反思失败的原因,研究团队进一步设计了两种简单有效的缓解策略:
- 问题重复:基于原因二中 LLMs 更关注反思指令而忽略初始问题的发现,研究团队在反思提示语的最后附上初始问题以引导 LLMs 维持对初始问题的关注。
- 少样本微调:基于原因一中反思引起 LLMs 内部状态的异常波动,以及原因三中 LLMs 在推理过程中的认知偏差,研究团队认为反思失败是一种异常行为 [4],并非知识匮乏。因此,不引入知识的少样本(4-10 个样本)微调可纠正反思失败的异常行为。
实验结果如下表所示,两种策略皆可有效缓解反思失败,少样本微调的效果更好;并且,由于反思失败是一种异常行为而非知识匮乏,在简单任务上的少样本微调效果可以泛化到复杂任务上。

表 3:问题重复和少样本微调可有效缓解反思失败。(实验时间:2025 年 2 月 15 日)
总结
该研究系统性评测了 LLMs 反思技术的失败,发现这种现象在多个 LLMs、多种任务上广泛存在,甚至先进的推理模型(ChatGPT o4-mini-high)在基本事实问题(「Is Earth flat?」)上也会出错。进而,研究团队揭示了反思失败的三种原因:内部答案波动,提示语偏差,认知偏差。基于这些原因,研究团队设计了两种简单有效的缓解反思失败的策略:问题重复和少样本微调。反思技术究竟引向自我纠正还是自我怀疑,这仍然是一个悬而未决的问题。
参考文献
[1] Reflexion: Language agents with verbal reinforcement learning, NIPS 2023.
[2] Large language models cannot self-correct reasoning yet, ICLR 2024.
[3] Eliciting latent predictions from transformers with the tuned lens, arXiv 2023.
[4] https://openai.com/index/chain-of-thought-monitoring/
....

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
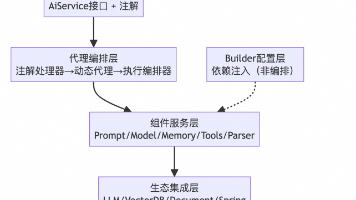
 4
4 0
0- 0



 已为社区贡献109条内容
已为社区贡献109条内容

所有评论(0)