多模态大模型病害检测
1、云服务器“算力自由”配置环境
1、选取RTX4090/24G
2、创建并激活虚拟环境 在终端(Terminal)输入以下命令
# 1. 创建名为 mobilevlm 的环境,指定 python 版本为 3.10 (推荐版本)
conda create -n mobilevlm python=3.10 -y
# 2. 激活环境 (以后每次登录都要先执行这一步)
conda activate mobilevlm
克隆模型底座仓库
git clone https://github.com/Meituan-AutoML/MobileVLM.git
cd MobileVLM
3、安装 PyTorch 虽然容器自带 PyTorch,但建议在虚拟环境中重新确认安装一遍,确保与 CUDA 版本对应(RTX 4090 通常对应 CUDA 11.8 或 12.1)
# 安装 PyTorch, TorchVision, Torchaudio
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
# 或者如果服务器是 CUDA 12.x,直接 pip install torch torchvision torchaudio 即可
通过nvcc --version即可查看CUDA的版本号,这里建议安装11.8更兼容(RTX 4090 配合 PyTorch 2.0.1 + CUDA 11.8 是非常稳定的组合,使用清华源安装pip install torch==2.0.1 torchvision==0.15.2 torchaudio==2.0.2 \ -i https://pypi.tuna.tsinghua.edu.cn/simple
综上还是建议使用CUDA的11.8版本,这样PyTorch更兼容。
4、安装 Flash-Attention (走捷径!)
# 1. 安装必要的打包工具
pip install packaging
# 2. 直接下载并安装适配 PyTorch 2.0.1 + CUDA 11.8 + Python 3.10 的预编译包
# (这个链接是 flash-attention 官方发布的历史版本)
pip install https://github.com/Dao-AILab/flash-attention/releases/download/v2.3.2/flash_attn-2.3.2+cu118torch2.0cxx11abiFALSE-cp310-cp310-linux_x86_64.whl
如果连接超时,将.whl文件下载到本地端进行安装:
github.com/Dao-AILab/flash-attention/releases/download/v2.3.2/flash_attn-2.3.2+cu118torch2.0cxx11abiFALSE-cp310-cp310-linux_x86_64.whl,然后执行pip install 文件名
最后进行验证:
python -c "import torch; import flash_attn; print(f'Torch: {torch.__version__}'); print(f'CUDA: {torch.version.cuda}'); print(f'FlashAttn: {flash_attn.__version__}'); print('Is CUDA available?', torch.cuda.is_available())"
可以输出得到库的信息
最后安装pip install -r requirments
2、下载 MobileVLM 预训练权重
1、安装下载工具:
pip install -U huggingface_hub
2、创建权重文件的储存位置
mkdir -p checkpoints/mobilevlm-1.7bmkdir -p checkpoints/mobilevlm-1.7b
3、设置镜像环境变量并下载 请直接复制下面整段代码在终端执行(这会下载 MobileVLM-1.7B 模型,大约 4-5GB):
import os
# 1. 强行在代码里设置国内镜像加速 (这一步最关键)
os.environ["HF_ENDPOINT"] = "https://hf-mirror.com"
try:
from huggingface_hub import snapshot_download
except ImportError:
print("错误:请先运行 pip install huggingface_hub")
exit()
print("========== 开始下载 MobileVLM-1.7B 模型 ==========")
print("正在连接镜像站,文件较大(约4-5GB),请耐心等待...")
# 2. 调用下载函数
snapshot_download(
repo_id="mtgv/MobileVLM-1.7B", # 官方模型ID
local_dir="checkpoints/mobilevlm-1.7b", # 下载到哪里
local_dir_use_symlinks=False, # 不使用软链接,直接下载实体文件
resume_download=True # 支持断点续传
)
print("========== 下载完成!==========")创建一个python文件来下载:
赋予脚本文件的权限:chmod +x 文件名
执行脚本安装:python +文件名
3、上传并处理数据
1、上传数据集:通过JupyterLab进行上传速度会快一点(目录:gpufree-data/)
2、解压缩unzip 加压缩包名字
3、删除套娃的文件名字:rm -rf plantvillage,只保留大写P开头的
4、在MobileVLM/下创建数据转换脚本文件:convert_data.py
import os
import json
import random
# ================= 配置区域 =================
# 这是你之前提到的数据存放位置,请确保解压后的文件夹就在这里
IMAGE_ROOT = "/root/gpufree-data/PlantVillage"
OUTPUT_JSON = "plant_disease_data.json"
# ===========================================
def generate_json():
print(f"正在扫描数据目录: {IMAGE_ROOT} ...")
if not os.path.exists(IMAGE_ROOT):
print(f"【错误】找不到目录: {IMAGE_ROOT}")
print("请检查拼写,或者确认你是否已经解压了数据集。")
return
classes = os.listdir(IMAGE_ROOT)
data_list = []
# 简单的问答模板,增加多样性
questions = [
"这张图片里的植物怎么了?",
"请识别这张图中的作物病害。",
"<image>\n请描述这张图片。",
"图片显示的是什么病害?\n<image>"
]
count = 0
for class_name in classes:
class_path = os.path.join(IMAGE_ROOT, class_name)
# 跳过非文件夹的文件
if not os.path.isdir(class_path):
continue
# 简单的清洗:把 "Tomato___Bacterial_spot" 变成 "Tomato Bacterial spot"
disease_name = class_name.replace("___", " ").replace("_", " ")
images = os.listdir(class_path)
for img_name in images:
if not img_name.lower().endswith(('.jpg', '.jpeg', '.png', '.JPG')):
continue
img_path = os.path.join(class_path, img_name)
question = random.choice(questions)
if "<image>" not in question:
question = "<image>\n" + question
data_sample = {
"id": f"plant_{count:06d}",
"image": img_path,
"conversations": [
{
"from": "human",
"value": question
},
{
"from": "gpt",
"value": f"这张图片显示的是 {disease_name}。"
}
]
}
data_list.append(data_sample)
count += 1
if count > 0:
with open(OUTPUT_JSON, 'w', encoding='utf-8') as f:
json.dump(data_list, f, ensure_ascii=False, indent=2)
print(f"========== 成功!==========")
print(f"已生成训练数据: {OUTPUT_JSON}")
print(f"共包含图片: {count} 张")
else:
print("【警告】目录里虽然有文件夹,但没找到任何图片!请检查文件夹结构。")
if __name__ == "__main__":
generate_json()赋予脚本权限,然后python +文件名执行
成功后终端会显示成功,而且同等目录下会生成个.json文件
4、训练数据
1、创建启动脚本
在 MobileVLM 目录下,创建一个新的 Shell 脚本文件:
run_plant_finetune.sh
内容如下:
#!/bin/bash
# 1. 自动配置环境变量 (防止报错)
export LD_LIBRARY_PATH=/opt/conda/envs/mobilevlm/lib/python3.10/site-packages/nvidia/cudnn/lib:/opt/conda/envs/mobilevlm/lib/python3.10/site-packages/nvidia/cuda_nvrtc/lib:$LD_LIBRARY_PATH
export PYTHONPATH=$PWD:$PYTHONPATH
export HF_ENDPOINT=https://hf-mirror.com
export CUDA_VISIBLE_DEVICES=0
# 2. 启动训练
deepspeed mobilevlm/train/train_mem.py \
--deepspeed scripts/deepspeed/zero2.json \
--model_name_or_path checkpoints/mobilevlm-1.7b \
--version v1 \
--data_path plant_disease_data.json \
--image_folder / \
--vision_tower openai/clip-vit-large-patch14-336 \
--mm_projector_type ldpnet \
--tune_mm_mlp_adapter True \
--freeze_backbone False \
--image_aspect_ratio pad \
--group_by_modality_length False \
--bf16 True \
--output_dir checkpoints/mobilevlm-plant-result \
--num_train_epochs 3 \
--per_device_train_batch_size 8 \
--per_device_eval_batch_size 4 \
--gradient_accumulation_steps 1 \
--evaluation_strategy "no" \
--save_strategy "steps" \
--save_steps 500 \
--save_total_limit 1 \
--learning_rate 2e-5 \
--weight_decay 0. \
--warmup_ratio 0.03 \
--lr_scheduler_type "cosine" \
--logging_steps 1 \
--tf32 True \
--model_max_length 2048 \
--gradient_checkpointing True \
--dataloader_num_workers 4 \
--lazy_preprocess True \
--report_to tensorboard第一步:启动脚本训练:
# 1. 给脚本执行权限
chmod +x run_plant_finetune.sh
# 2. 启动!
./run_plant_finetune.sh
会出现兼容性报错需要先强制安装一个兼容的旧版本 (比如 0.19.4,既满足 >=0.15.1 又满足 <1.0)
pip install huggingface_hub==0.19.4
接下来Mobilevlm会先下载他的“眼睛”CLIP
接下来报错需要安装一个画图软件,用于描述训练过程:pip install tensorboard
最后再次执行就可以正常训练了,如下图所示: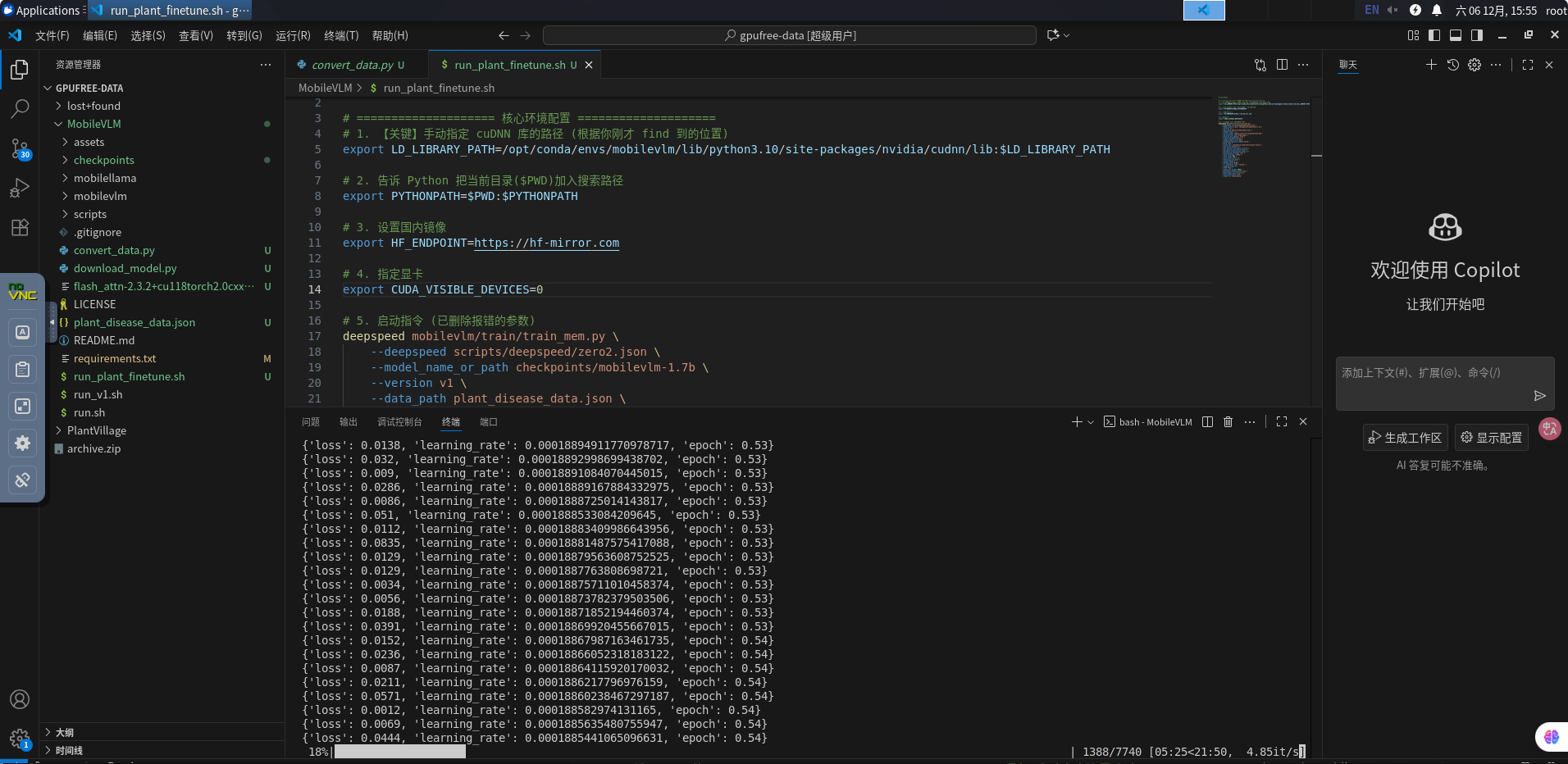
其中名词解释如下:
loss:标签值-模型检测值 他俩的差值,越小越好
learning_rate:学习精度,对于小样本数据精度稍微低一点2e-5就可以,太高了容易丢失之前掌握的内容,也称为模型崩塌
epoch:训练轮数,例如1.25,就是第二轮的25%了
右下角的int/s就是指一秒种训练批次的个数和预估时间
5、模型检测
1、训练完后会在MobileVLM下的checkpoints文件夹下出现一个mobileclm-plant-result下的checkpoint-7500,这就是我们训练后的模型文件,其中的pytorch_model.bin文件就是全量微调后的VLM大脑,但是现在还缺少眼睛和耳朵
2、耳朵:通过移植底座模型的耳朵:checkpoints下的mobilevlm-1.7b下的tokenizer.model和tokenizer_config.json文件一直到checkpoint-7500
3、眼睛:在checkpoint下创建一个json文件:preproccessor_config.json文件,内容如下:
{
"crop_size": {
"height": 336,
"width": 336
},
"do_center_crop": true,
"do_convert_rgb": true,
"do_normalize": true,
"do_resize": true,
"image_mean": [
0.48145466,
0.4578275,
0.40821073
],
"image_processor_type": "CLIPImageProcessor",
"image_std": [
0.26862954,
0.26130258,
0.27577711
],
"resample": 3,
"size": {
"shortest_edge": 336
}
}4、最后配置身份证,也就是checkpoint的config.json文件内容,内容如下:
{
"_name_or_path": "checkpoints/mobilevlm-1.7b",
"architectures": [
"MobileLlamaForCausalLM"
],
"bos_token_id": 1,
"eos_token_id": 2,
"freeze_mm_mlp_adapter": false,
"hidden_act": "silu",
"hidden_size": 2048,
"image_aspect_ratio": "pad",
"image_grid_pinpoints": null,
"initializer_range": 0.02,
"intermediate_size": 5632,
"max_position_embeddings": 2048,
"max_sequence_length": 2048,
"mm_hidden_size": 1024,
"mm_projector_lr": null,
"mm_projector_type": "ldpnet",
"mm_use_im_patch_token": true,
"mm_use_im_start_end": false,
"mm_vision_select_feature": "patch",
"mm_vision_select_layer": -1,
"mm_vision_tower": "openai/clip-vit-large-patch14-336",
"model_type": "mobilevlm",
"num_attention_heads": 16,
"num_hidden_layers": 24,
"num_key_value_heads": 16,
"pad_token_id": 0,
"pretraining_tp": 1,
"rms_norm_eps": 1e-06,
"rope_scaling": null,
"rope_theta": 10000.0,
"tie_word_embeddings": false,
"torch_dtype": "bfloat16",
"transformers_version": "4.33.1",
"tune_mm_mlp_adapter": true,
"use_cache": false,
"use_mm_proj": true,
"vision_tower_type": "clip",
"vocab_size": 32001
}
5、最终进行模型检测,检测代码如下,但是图片的地址需要自行更改,建议采用绝对路径更加保险一些:
import sys
import os
import torch
from PIL import Image
# 防止报错找不到模块
sys.path.append(os.getcwd())
from mobilevlm.model.mobilevlm import load_pretrained_model
from mobilevlm.conversation import conv_templates, SeparatorStyle
from mobilevlm.utils import disable_torch_init
from mobilevlm.utils import process_images
# ================= 🔧 用户配置区域 (只改这里) =================
# 1. 你的模型路径 (训练好的 checkpoint)
MODEL_PATH = "checkpoints/mobilevlm-plant-result/checkpoint-7500"
# 2. 你要检测的图片路径 (支持绝对路径或相对路径)
# 示例:"/root/data/test.jpg"
IMAGE_PATH = "/root/gpufree-data/PlantVillage/feb16fe07d4ddafb50a412a6a4fee6e5.jpeg"
# 3. 你想问的问题 (默认即可)
QUESTION = "这张图片里的植物怎么了?"
# ==============================================================
def predict():
# --- 1. 初始化与加载模型 ---
disable_torch_init()
print(f"正在加载模型: {MODEL_PATH} ...")
# 加载模型 (默认配置)
tokenizer, model, image_processor, context_len = load_pretrained_model(
MODEL_PATH,
load_8bit=False,
load_4bit=False,
device="cuda"
)
# 【核心】强制转换模型为 BFloat16 以匹配训练精度
model = model.to(device="cuda", dtype=torch.bfloat16)
# 自动修复 Tokenizer (防止 CUDA 报错)
if len(tokenizer) != model.config.vocab_size:
tokenizer.add_tokens(["<image>"], special_tokens=True)
model.resize_token_embeddings(len(tokenizer))
# --- 2. 处理图片 ---
if not os.path.exists(IMAGE_PATH):
print(f"❌ 错误: 找不到图片 {IMAGE_PATH}")
return
image = Image.open(IMAGE_PATH).convert('RGB')
image_tensor = process_images([image], image_processor, model.config)
# 图片转 BFloat16
if type(image_tensor) is list:
image_tensor = [img.to(model.device, dtype=torch.bfloat16) for img in image_tensor]
else:
image_tensor = image_tensor.to(model.device, dtype=torch.bfloat16)
# --- 3. 构建 Prompt ---
conv = conv_templates["v1"].copy()
conv.append_message(conv.roles[0], "<image>\n" + QUESTION)
conv.append_message(conv.roles[1], None)
prompt = conv.get_prompt()
# 编码输入
input_ids = tokenizer_image_token(prompt, tokenizer, -200, return_tensors='pt').unsqueeze(0).cuda()
# --- 4. 推理生成 ---
print("正在分析图片...")
with torch.inference_mode():
output_ids = model.generate(
input_ids,
images=image_tensor,
do_sample=False, # 关闭随机采样,让结果更稳定 (Greedy Search)
temperature=0.0, # 温度设为0,输出最可能的答案
max_new_tokens=512,
use_cache=True,
)
input_token_len = input_ids.shape[1]
outputs = tokenizer.batch_decode(output_ids[:, input_token_len:], skip_special_tokens=True)[0]
# --- 5. 输出结果 ---
print("\n" + "="*20 + " 检测结果 " + "="*20)
print(outputs.strip())
print("="*50 + "\n")
# 辅助函数: 处理 Prompt 中的特殊 Token
def tokenizer_image_token(prompt, tokenizer, image_token_index, return_tensors=None):
prompt_chunks = [tokenizer(chunk).input_ids for chunk in prompt.split('<image>')]
def insert_separator(X, sep):
return [ele for sublist in zip(X, [sep]*len(X)) for ele in sublist][:-1]
input_ids = []
offset = 0
if len(prompt_chunks) > 0 and len(prompt_chunks[0]) > 0 and prompt_chunks[0][0] == tokenizer.bos_token_id:
offset = 1
input_ids.append(prompt_chunks[0][0])
for x in insert_separator(prompt_chunks, [image_token_index] * (offset + 1)):
input_ids.extend(x[offset:])
if return_tensors is not None:
if return_tensors == 'pt':
return torch.tensor(input_ids, dtype=torch.long)
return input_ids
if __name__ == "__main__":
predict()检测结果如下: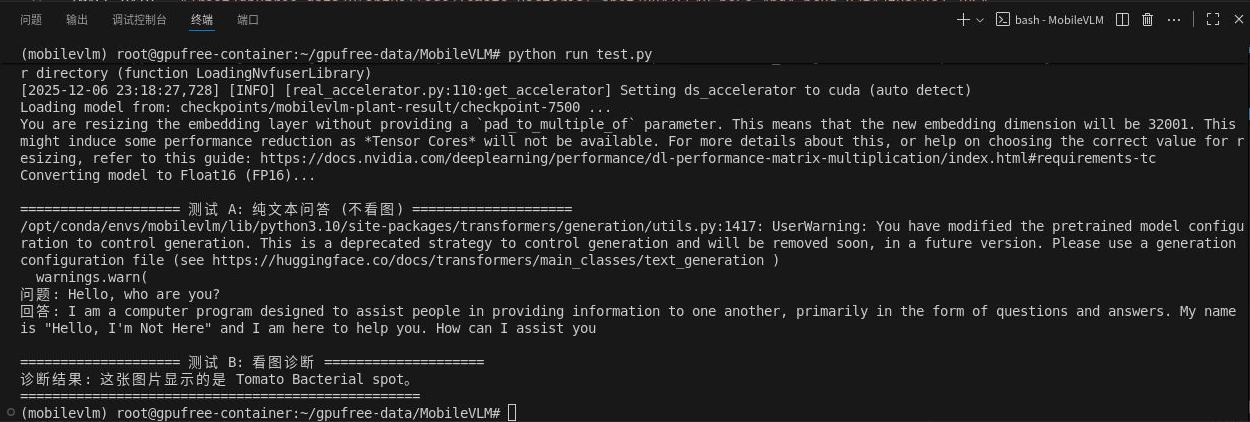

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 19
19 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)