论文阅读:AIED 2025 Beyond Final Answers: Evaluating Large Language Models for Math Tutoring
以智能辅导系统为测试平台的自动化评估显示LLM最终答案正确率达85.5%(其中GPT-4o最高97.3%),人类 evaluator 交互式评估表明90%的对话具备高质量教学支持,但仅56.6%的对话完全正确;研究发现LLM虽在提示生成、灵活适配答案格式等方面有优势,却存在中间步骤错误、过度侧重最终答案等问题,结论是LLM目前无法脱离人类监督或额外保障机制独立作为数学智能辅导工具。研究主题:评估大
·
总目录 大模型相关研究:https://blog.csdn.net/WhiffeYF/article/details/142132328
https://arxiv.org/pdf/2503.16460
https://www.doubao.com/chat/35206744634053634
论文翻译:
速览
1. 一段话总结
本研究通过两种创新方法评估了ChatGPT系列(3.5 Turbo、4、4o、o1-mini、o1-preview)LLM在大学代数辅导中的表现:以智能辅导系统为测试平台的自动化评估显示LLM最终答案正确率达85.5%(其中GPT-4o最高97.3%),人类 evaluator 交互式评估表明90%的对话具备高质量教学支持,但仅56.6%的对话完全正确;研究发现LLM虽在提示生成、灵活适配答案格式等方面有优势,却存在中间步骤错误、过度侧重最终答案等问题,结论是LLM目前无法脱离人类监督或额外保障机制独立作为数学智能辅导工具。
2. 思维导图
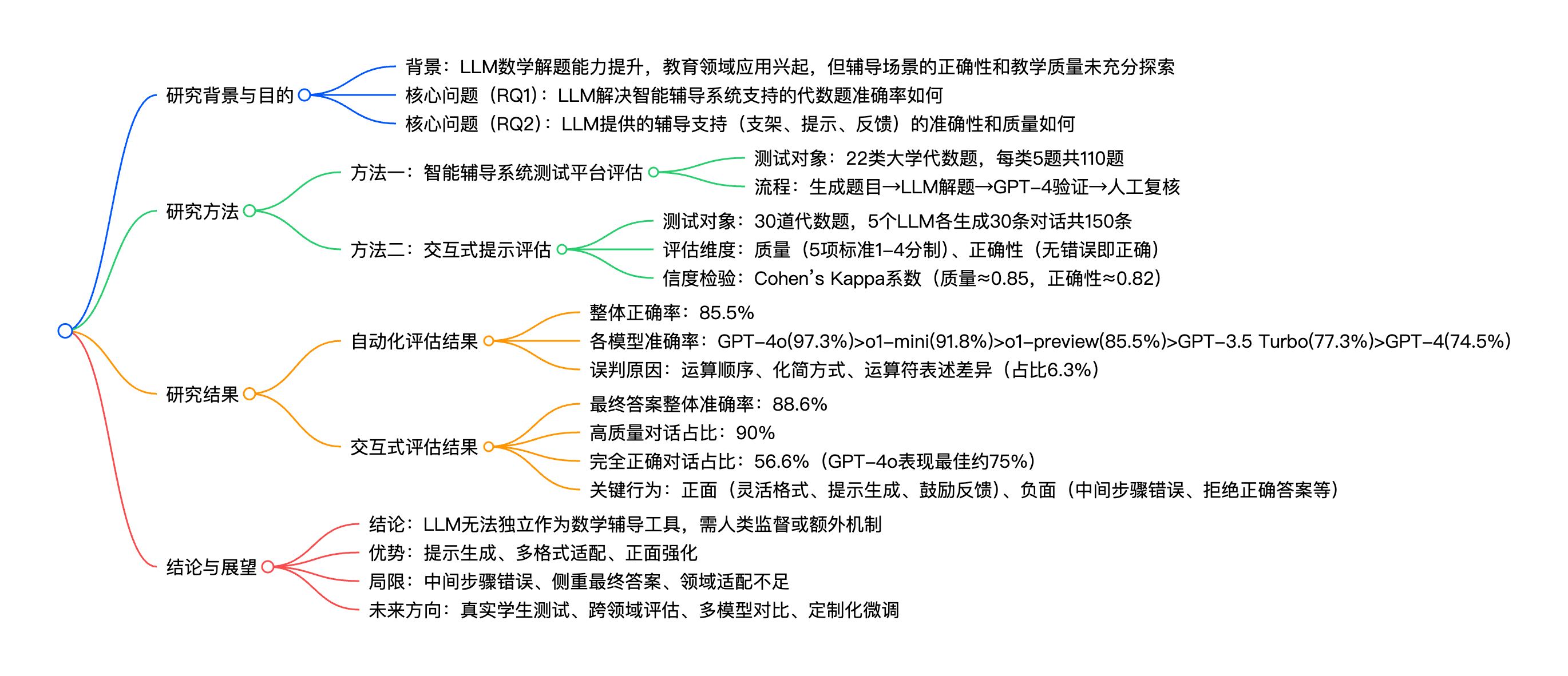
## 研究背景与目的
- 背景:LLM数学解题能力提升,教育领域应用兴起,但辅导场景的正确性和教学质量未充分探索
- 核心问题(RQ1):LLM解决智能辅导系统支持的代数题准确率如何
- 核心问题(RQ2):LLM提供的辅导支持(支架、提示、反馈)的准确性和质量如何
## 研究方法
- 方法一:智能辅导系统测试平台评估
- 测试对象:22类大学代数题,每类5题共110题
- 流程:生成题目→LLM解题→GPT-4验证→人工复核
- 方法二:交互式提示评估
- 测试对象:30道代数题,5个LLM各生成30条对话共150条
- 评估维度:质量(5项标准1-4分制)、正确性(无错误即正确)
- 信度检验:Cohen’s Kappa系数(质量≈0.85,正确性≈0.82)
## 研究结果
- 自动化评估结果
- 整体正确率:85.5%
- 各模型准确率:GPT-4o(97.3%)>o1-mini(91.8%)>o1-preview(85.5%)>GPT-3.5 Turbo(77.3%)>GPT-4(74.5%)
- 误判原因:运算顺序、化简方式、运算符表述差异(占比6.3%)
- 交互式评估结果
- 最终答案整体准确率:88.6%
- 高质量对话占比:90%
- 完全正确对话占比:56.6%(GPT-4o表现最佳约75%)
- 关键行为:正面(灵活格式、提示生成、鼓励反馈)、负面(中间步骤错误、拒绝正确答案等)
## 结论与展望
- 结论:LLM无法独立作为数学辅导工具,需人类监督或额外机制
- 优势:提示生成、多格式适配、正面强化
- 局限:中间步骤错误、侧重最终答案、领域适配不足
- 未来方向:真实学生测试、跨领域评估、多模型对比、定制化微调
3. 详细总结
一、研究概述
- 研究主题:评估大型语言模型(LLM)在数学辅导场景中的正确性与教学质量,聚焦大学代数领域
- 研究动机:LLM在数学解题(如GSM8K、MATH基准)中表现提升,Duolingo、可汗学院等已尝试应用,但辅导场景下的准确性、教学适配性仍缺乏系统评估,且LLM易产生“幻觉”可能误导学生
- 核心目标:回答两大问题(RQ1:LLM解题准确率;RQ2:LLM辅导支持的准确性与质量)
- 测试模型:ChatGPT系列5个模型(GPT-3.5 Turbo、GPT-4、GPT-4o、o1-mini、o1-preview)
二、研究方法
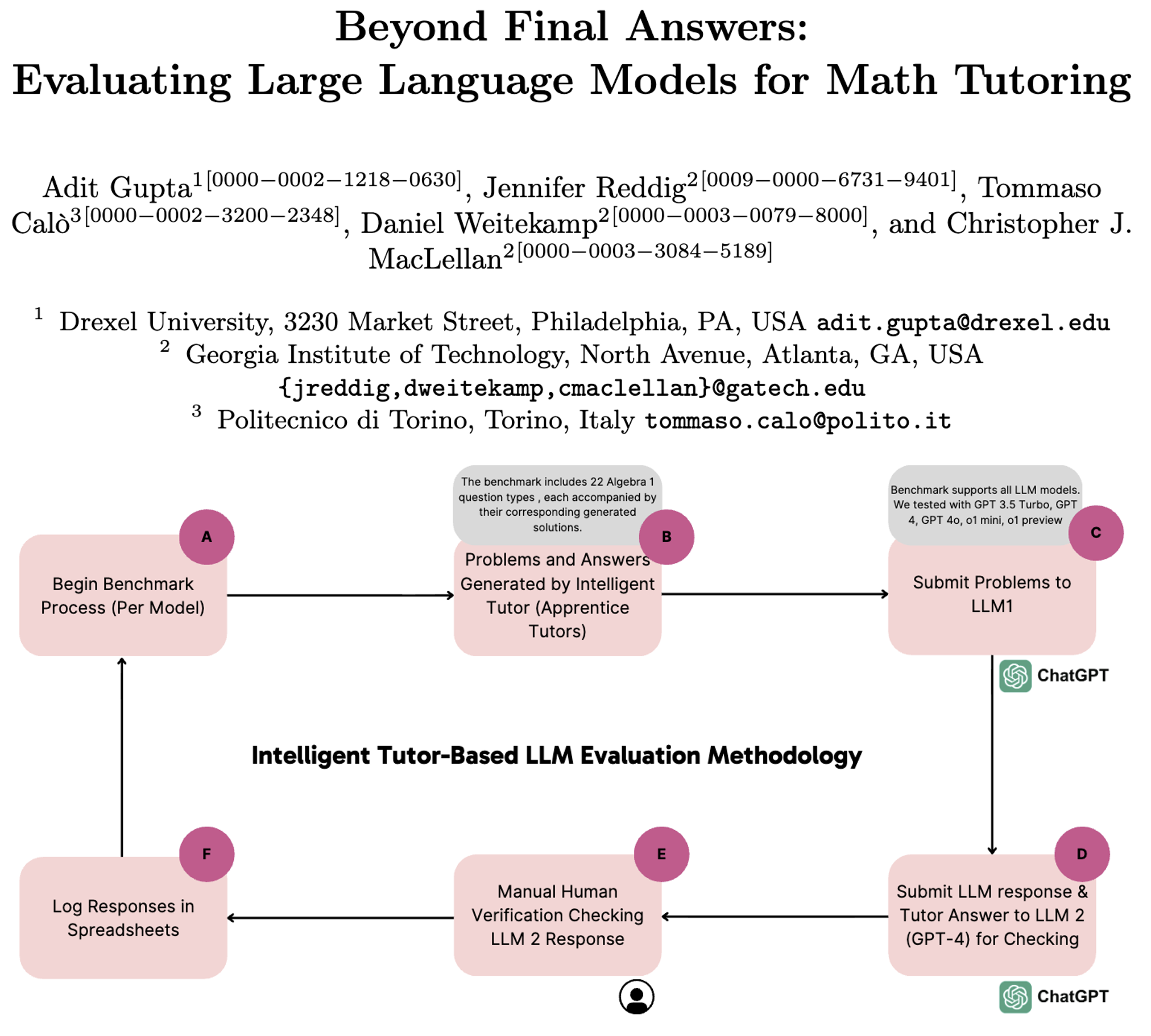
(一)方法一:智能辅导系统测试平台评估(自动化评估)
- 测试工具:Apprentice Tutors智能辅导平台(含22类大学代数题,涵盖根式、多项式因式分解、对数方程等)
- 测试规模:22类题型×5题=110道题,每道题含平台生成的标准分步解答
- 评估流程:
- 生成题目与标准解答;
- 向各LLM提交题目,要求分步解答并以LaTeX格式输出最终答案;
- 用GPT-4作为验证模型,判断LLM答案与标准解答是否一致;
- 人工复核验证模型的误判案例(如化简形式差异、运算顺序表述差异等);
- 记录并统计准确率。
(二)方法二:交互式提示评估(人工定性评估)
- 测试规模:30道代数题×5个模型=150条辅导对话
- 评估方式:
- evaluator 模拟学生,向LLM发送辅导请求(要求“不直接给答案,通过提问/提示引导理解”);
- 两位独立 reviewer 依据 rubric 评估对话:
- 质量评估:从5个维度(解释清晰度、反馈有效性、支架支持、解题策略指导、鼓励强化)按1-4分制打分,总分>10分为“高质量”;
- 正确性评估:判断对话中所有内容(含提示、步骤、反馈)是否完全无错误;
- 信度检验:采用Cohen’s Kappa系数验证 reviewer 一致性(质量κ≈0.85,正确性κ≈0.82,均为强一致);
- 主题分析:归类LLM辅导行为的正面与负面模式。
三、研究结果
(一)自动化解题评估结果(仅看最终答案)
| 模型 | 题型数量 | 题目总数 | 正确题数 | 准确率 |
|---|---|---|---|---|
| GPT-3.5 Turbo | 22 | 110 | 85 | 77.3% |
| GPT-4 | 22 | 110 | 83 | 74.5% |
| GPT-4o | 22 | 110 | 107 | 97.3% |
| o1-mini | 22 | 110 | 101 | 91.8% |
| o1-preview | 22 | 110 | 94 | 85.5% |
| 整体平均 | 22 | 110 | 94 | 85.5% |
- 关键发现:6.3%的响应存在验证模型误判,原因包括运算顺序表述差异、化简程度不同、运算符符号差异(如“x” vs “*”)
(二)交互式辅导评估结果
| 模型 | 题目数量 | 最终答案准确率 | 高质量对话占比(平均) | 完全正确对话占比(平均) |
|---|---|---|---|---|
| GPT-3.5 Turbo | 30 | 90.0% | 90.0% | 50.0% |
| GPT-4 | 30 | 83.3% | 93.3% | 46.7% |
| GPT-4o | 30 | 93.3% | 90.0% | 75.0% |
| o1-mini | 30 | 86.7% | 83.3% | 50.0% |
| o1-preview | 30 | 90.0% | 93.3% | 61.7% |
| 整体平均 | 30 | 88.6% | 90.0% | 56.6% |
- 辅导行为主题分析(表4汇总):
- 正面行为(共14次):适配多格式答案(3次)、生成提示与例题(2次)、鼓励反馈(7次)、引导按步骤解题(2次);
- 负面行为(共26次):最终答案正确但中间步骤有误(6次)、可通过诱导获取答案(4次)、过度强调基础忽略特定方法(4次)、侧重最终答案而非步骤习得(3次)、拒绝正确答案(4次)、误判正确中间步骤(3次)、符号输入困难(2次)。
四、研究结论与展望
(一)核心结论
- LLM解题能力:自动化评估中整体最终答案准确率85.5%,GPT-4o表现最优(97.3%),但仍低于传统智能辅导系统的100%准确率;
- LLM辅导质量:90%的对话具备高质量教学支持(如清晰解释、合理支架),但仅56.6%的对话完全正确,约1/2的辅导会话存在错误;
- 关键局限:LLM易在中间步骤出错、过度侧重最终答案、教学方法不够精准(如忽略指定解题方法);
- 核心建议:LLM目前不适合独立作为数学智能辅导工具,需人类监督或与现有智能辅导系统整合(如负责提示生成、反馈优化)。
(二)LLM的优势与局限
| 优势 | 局限 |
|---|---|
| 生成多样化提示与额外例题 | 中间步骤易出错,正确率仅56.6% |
| 适配多种答案格式 | 过度侧重最终答案,忽视步骤习得 |
| 提供正面强化与鼓励反馈 | 教学方法不精准,易忽略特定策略 |
| 交互式对话灵活适配学生疑问 | 可能拒绝正确答案,产生误导 |
(三)未来研究方向
- 开展真实学生参与的测试,评估LLM辅导对学习成果的实际影响;
- 扩展评估领域(如护理教育),验证LLM跨学科辅导适配性;
- 纳入更多模型(如Google Gemini、Anthropic Claude)及定制化微调模型的对比;
- 探索LLM与智能辅导系统的整合方案,强化正确性保障。
4. 关键问题
问题1:LLM在大学代数解题中的最终答案准确率如何?不同模型表现差异如何?
- 答案:整体平均准确率为85.5%(基于110道题的自动化评估);模型间表现差异显著,其中GPT-4o准确率最高(97.3%),其次是o1-mini(91.8%)、o1-preview(85.5%)、GPT-3.5 Turbo(77.3%),GPT-4表现最差(74.5%)。需注意,该结果仅针对最终答案,未考虑中间解题步骤的正确性。
问题2:LLM作为交互式数学辅导工具时,教学质量和内容正确性的表现如何?
- 答案:教学质量方面,90%的LLM辅导对话被评为高质量(符合教学最佳实践,如清晰解释、合理支架支持、鼓励反馈);内容正确性方面,仅56.6%的对话完全无错误,约一半的辅导会话存在中间步骤误判、拒绝正确答案、过度强调基础等问题。其中GPT-4o的完全正确对话占比最高(75%),平衡了质量与正确性。
问题3:当前LLM能否独立作为数学智能辅导工具?若不能,核心局限与可行应用方式是什么?
- 答案:不能,核心局限包括:1. 中间步骤正确率低(仅56.6%的对话完全正确),易误导学生形成错误认知;2. 教学方法不够精准,过度侧重最终答案而非步骤习得;3. 准确率(85.5%-97.3%)低于传统智能辅导系统的100%。可行应用方式为:作为现有教育技术的补充,负责提示生成、多格式答案适配、正面强化反馈等环节,同时需搭配人类监督或智能辅导系统的专家模型,保障内容正确性。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 8
8 0
0- 0



 已为社区贡献74条内容
已为社区贡献74条内容

所有评论(0)