【自然语言处理与大模型】三种实现多模态技术的路线
当前多模态领域,尤其是在信息检索和处理场景下,最具代表性的三条主流技术路线。它们代表了三种不同的思想:空间对齐、路径并行和模态转换。
多模态技术的核心目标是让AI能够像人一样,通过融合文本、图像、声音、视频等多种信息渠道来理解世界。根据当前技术发展水平与实践经验,业界主要形成了三条主流技术路线,每种路线均有其特定的适用场景及相应的权衡考量。接下来,我将依次介绍各路线的核心思想、典型代表方案,以及各自的优势与局限。
一、统一向量空间检索
这是最经典、最符合直觉的路线,核心思想是“翻译官”。既然不同模态的语言不通,那就把它们都翻译成一种通用语言——向量。

典型代表是双塔模型 CLIP 模型,其中 OpenAI 开发的 CLIP 被广泛视为这一技术路线的标杆。CLIP 的核心能力在于将图像和文本映射到同一个语义向量空间中,从而实现以下功能:
- 通过文本查询直接检索相关图像;
- 通过图像查询匹配对应的描述文本;
- 跨模态(图像与文本)之间的语义相似度计算变得简洁而高效。
如果你对 CLIP 还不太熟悉,可以将其形象地理解为一个“跨模态翻译器”:它将图像“翻译”成一种表示其语义的向量,同时也将文本“翻译”成相同语义空间中的向量。随后,系统只需在这个共享的向量空间中比较图像向量与文本向量之间的距离或相似度,即可判断它们在语义上是否匹配。因此,CLIP 能够同时对图像和文本进行统一的语义编码。
工作流程如下:
① 编码:一个图片编码器将图片编码为向量V_img,一个文本编码器将文本编码为向量V_txt。
② 对齐:通过在海量图文对数据上进行对比学习,模型学会让“一张猫的图片”的向量V_img和“一只可爱的猫”这句话的向量V_txt在空间中无限接近。
③ 检索:当用户用文本查询时,将其编码为向量V_query,然后在数据库中计算V_query与所有图片向量的相似度(如余弦相似度),返回最相似的图片。
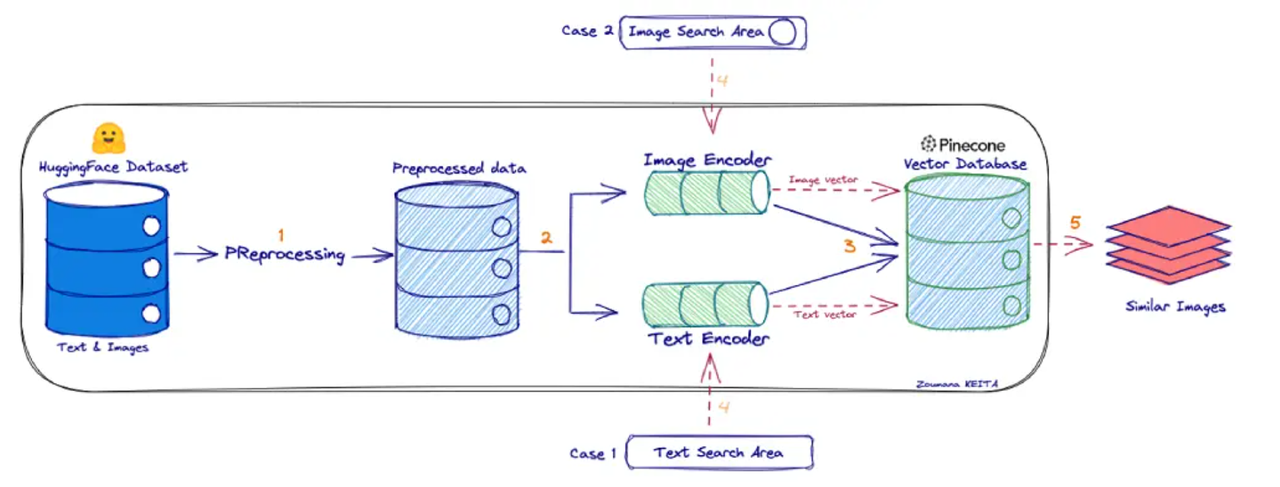
该技术路线的优势在于架构简洁:在检索阶段无需区分模态,只需将查询向量与统一的向量数据库进行比对即可。然而,其局限性也十分显著——训练一个能有效融合多种模态的统一模型极具挑战。目前的多模态嵌入模型通常仅在成对模态(如图像-文本)上表现良好,面对更多模态或复杂数据格式(例如自然图像、扫描文档、图表等)时,泛化能力明显不足。
因此,在实际应用中,这类方案往往依赖大量高质量的训练数据,并需进行精细调优;而对于包含特殊结构的信息(如数学公式、合成图表等),其效果可能不尽如人意。
值得注意的是,在多模态 RAG(Multimodal Retrieval-Augmented Generation)系统中,存在一个关键的设计权衡:即“直接使用多模态模型进行端到端解析与问答”与“采用检索+生成(RAG)范式”这两条路径之间的选择。这一抉择直接影响系统的性能、灵活性与可扩展性。
|
路径 |
核心流程 /机制 |
输入输出 |
优点 |
缺点 |
|
直接多模态解析+问答 |
给定图像 + 文本 prompt → 多模态模型(例如 Qwen-Omni、VL 模型)内部理解 + 推理 → 直接输出答案 |
输入可能是图像 + 文本,输出是文本(或语音) |
简洁,不需要检索模块、向量数据库、索引、召回等流程;适合实时交互 |
模型容量知识覆盖受限;容易 “忘记”长尾知识或外部知识;当问题涉及知识库内容或历史文档,模型可能石沉大海 |
|
检索增强(RAG)路线 |
先把知识库里的图文 / 多模态内容编码成向量、做索引、检索;给定用户 query(可能包含图 + 文本信息),检索最相关资料;把这些检索结果 + query 一起交给多模态、混合模型生成答案 |
有检索模块 + 向量数据库 + 编码器 + 生成模型 |
能显著扩展知识覆盖范围、增强外部知识支持、减少模型的“记忆负担”、提升答案可验证性 |
检索质量、向量表示对齐、模态差异对齐、查询、检索、融合策略设计复杂;若检索结果无关或噪声,会误导生成模型 |
二、多路并行检索
既然构建统一的多模态语义空间存在较大挑战,一种更务实的策略是:为每种模态分别构建独立的检索管道和向量索引。例如,文本使用文本向量索引,图像使用图像向量索引,音频则使用对应的音频向量索引。
在接收到用户查询时,系统可并行地将查询分发至各个模态的检索器,分别获取各自的 Top-K 相关结果,再将来自不同模态的检索结果进行融合,最终一并提供给生成模型作为上下文输入。
工作流程如下:
① 独立索引:建立图片索引(可以用图像特征向量)、文本索引(可以用倒排索引或文本向量)、音频索引(可以用音频指纹或声学特征)。
② 并行查询:用户输入“一段描述文字 + 一张参考图片”,系统会同时用文字去搜文本库,用图片去搜图片库。
③ 结果融合:将两路检索的结果进行打分、排序、去重。比如,可以给文本匹配到的结果和图片匹配到的结果赋予不同权重,然后生成一个最终的排序列表。

这种方案的优势在于保留了各模态检索的专业性,无需依赖单一模型强行统一所有模态的表示。然而,其缺点同样显著:
首先,由于每种模态都返回各自的 Top-K 结果,候选片段数量会成倍增长,导致生成阶段可能需要处理大量跨模态信息,显著增加上下文复杂度;其次,生成模型必须具备强大的多模态理解能力,才能有效融合来自不同模态、不同来源的信息——若缺乏这种能力,多路检索的结果将难以被有效利用。
因此,多路并行方案本质上是将多模态对齐与融合的挑战从检索阶段转移至生成阶段,并带来了更高的计算开销和系统复杂性。在工程实践中,该方案通常仅用于小规模实验,或在配备强大多模态生成模型的场景下谨慎采用,尚未成为主流架构。
三、转化为统一模态(文本)处理
这是目前应用最广泛、也最为务实的方案:在预处理阶段将所有非文本模态的信息统一转化为文本表示。这种“以文本为统一基础”的策略,常被称为模态归一化。
工作流程如下:
① 模态转换:用户上传一张图片,系统首先调用一个图像描述模型,生成一段描述:“这是一张坐在白色盘子里的牛排,旁边配着烤蔬菜和酱汁。”
② 文本处理:将这段描述与用户输入的原始文本查询(如“如何烹饪五分熟?”)拼接在一起。
③ LLM推理:将完整的文本输入给一个强大的LLM,由LLM理解并生成最终答案。

通过上述处理,原本异构的多模态内容被转化为标准化的、可索引的文本块,随后即可直接利用成熟的文本向量检索技术(如基于嵌入的稠密检索)构建索引。在查询阶段,用户问题同样以文本形式编码为向量,用于检索相关文本片段,并将结果输入 LLM 生成最终答案。
该方法的核心优势在于架构简洁、工程实现成熟,能够充分复用现有文本 RAG 的基础设施与工具链,同时避免了训练和部署复杂多模态模型所带来的高昂成本与技术门槛。
例如,许多文档问答类产品在处理 PDF 文件时,会直接结合文本提取与 OCR 技术,将图文混排的内容统一转换为纯文本,进而构建文本索引。随后,大语言模型仅基于这些提取出的文字内容来理解和回答用户的问题。
对于包含大量文字的图像(如扫描文档、屏幕截图)以及结构化数据(如表格,通常被转换为文本形式进行表示)而言,这种方案在实践中相对有效。然而,其局限性也不容忽视:模态特有的语义信息和细节容易在转换过程中丢失。例如:
- OCR 无法捕捉图像中的视觉布局、图表结构或非文本图形所承载的语义;
- 表格转为纯文本后,可能丢失行列之间的对应关系与结构逻辑;
- 数学公式一旦转为线性文本,往往变得难以解析甚至不可读。
尽管存在这些信息损失,但在多模态大模型尚未广泛普及和成熟之前,该方法仍是工业界最稳妥、高效且易于落地的技术路径。实践中,它也常与大语言模型协同使用——例如先由 OCR 提取文字内容,再交由大模型基于文本上下文进行理解与问答,从而在可控成本下实现较好的实用效果。
四、技术路线对比
| 统一向量空间 | 多路并行检索 | 转化为统一文本模态 | |
|---|---|---|---|
| 核心思想 | 空间对齐,语义相通 | 各司其职,结果融合 | 万物归一,文本为王 |
| 技术依赖 | 多模态对比学习模型 | 单模态检索引擎 + 融合策略 | 描述性模型 + 大语言模型 |
| 优势 | 语义理解深,跨模态交互自然 | 灵活、鲁棒、可扩展 | 能最大化利用LLM,逻辑简单 |
| 挑战 | 训练成本高,存在模态鸿沟 | 缺乏深层交互,融合策略复杂 | 信息损失大,错误会向下传递 |
| 适用场景 | 语义驱动的跨模态检索、生成 | 大规模、高可用性的多模态搜索引擎 | 需要复杂逻辑推理的多模态问答 |

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 5
5 0
0- 0



 已为社区贡献16条内容
已为社区贡献16条内容

所有评论(0)