【VLM】vLLM-Omni多模态推理框架
今天的生成式模型已经远不止“文本输入、文本输出”:新的模型可以同时理解和生成文本、图像、音频、视频,背后也不再是单一自回归架构,而是由编码器、语言模型、扩散模型等异构组件拼接而成。随着模型进化为可以“看、听、说”的全能代理(omni agents),底层推理系统也不得不同时面对:真·全模态:一条请求里既有文本,又有图片、音频甚至视频,输出形式也不再单一。超越自回归:扩散 Transformer(D
note
一、vLLM-Omni推理
GitHub 仓库:https://github.com/vllm-project/vllm-omni
文档站点:https://vllm-omni.readthedocs.io/en/latest/
vLLM 一直专注于为大语言模型(LLM)提供高吞吐、低显存的推理能力。但今天的生成式模型已经远不止“文本输入、文本输出”:新的模型可以同时理解和生成文本、图像、音频、视频,背后也不再是单一自回归架构,而是由编码器、语言模型、扩散模型等异构组件拼接而成。
随着模型进化为可以“看、听、说”的全能代理(omni agents),底层推理系统也不得不同时面对:
- 真·全模态:一条请求里既有文本,又有图片、音频甚至视频,输出形式也不再单一。
- 超越自回归:扩散 Transformer(Diffusion Transformer, DiT)等 并行生成模型 需要不同于 LLM 的调度和内存管理策略。
- 异构推理流水线:一次调用往往会经过“多模态编码 → LLM 推理 → 扩散生成”等多个异构组件,资源分配和调度更像一条复杂的作业流水线,而不是单一模型调用。
vLLM-Omni引入了一个完全解耦的流水线架构,让不同阶段可以按需分配资源,并通过统一调度衔接起来。在这套架构中,一个 omni-modality 推理请求大致会经过三类组件:
• 模态编码器(Modality Encoders):负责高效地把多模态输入编码成向量或中间表示,例如 ViT 视觉编码器、Whisper 等语音编码器。
• LLM 核心(LLM Core):基于 vLLM 的自回归文本/隐藏状态生成部分,可以是一个或多个语言模型,用于思考、规划和多轮对话。
• 模态生成器(Modality Generators):用于生成图片、音频或视频的解码头,例如 DiT 等扩散模型。
二、用 OmniStage 抽象描述整个工作流
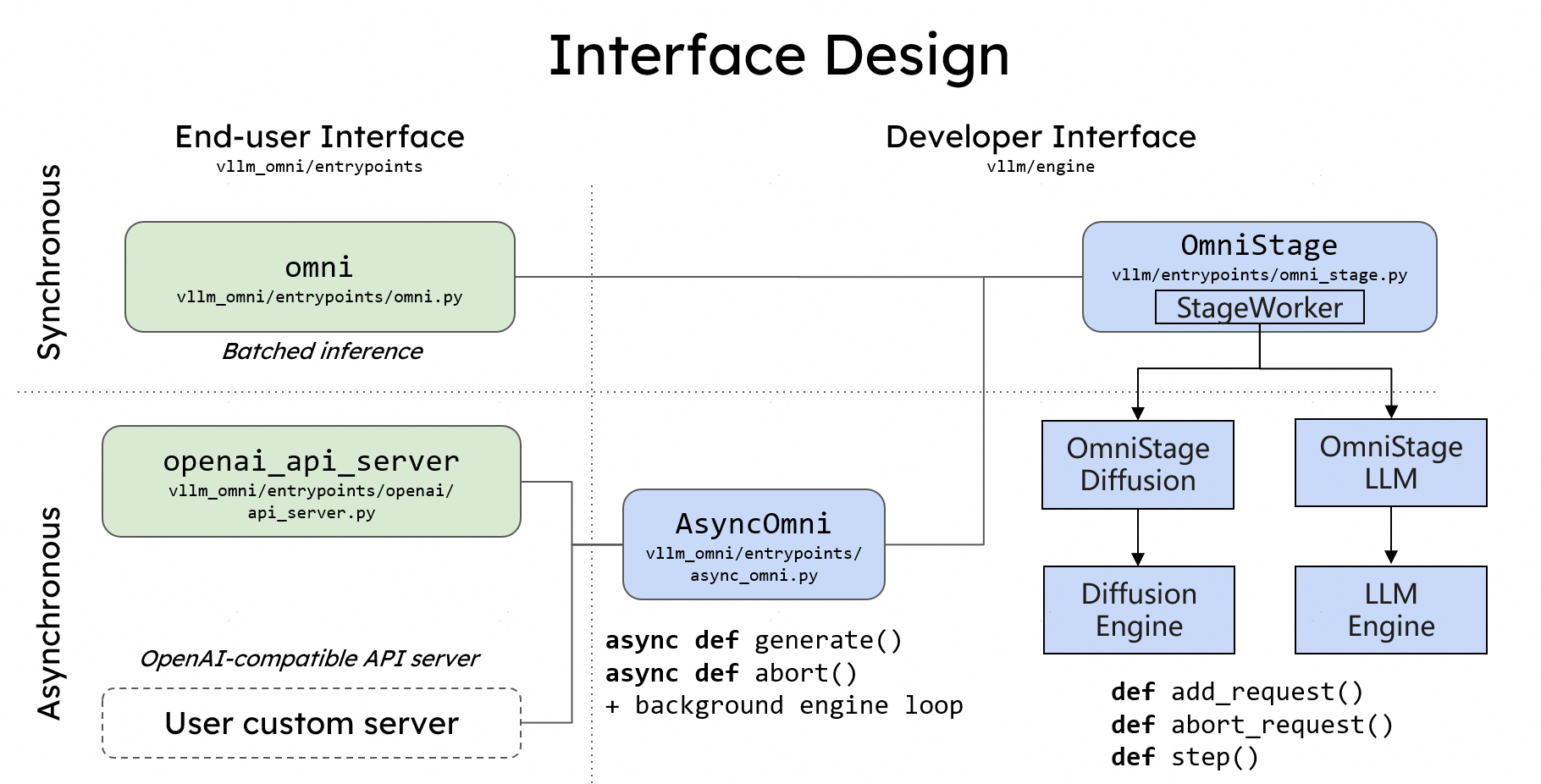
vLLM-Omni 提供了一个称为 OmniStage 的抽象,用来描述和拼接各种 omni-modality 模型:
• 可以把多模态编码器、LLM、扩散生成头等视为不同的 Stage;
• 通过 OmniStage 定义数据在各个 Stage 之间的流动方式;
• 当前已支持 Qwen-Omni、Qwen-Image 等代表性 omni 模型,后续会持续扩展。
对于需要快速验证新模型、新架构的研究/工程团队来说,这个抽象可以让你更容易地在“生产可用”与“研究探索”之间切换,而不必每次都从零搭一套分布式推理系统。
Reference
[1] https://blog.vllm.ai/2025/11/30/vllm-omni.html
[2] vLLM-Omni 上线:多模态推理更简单、更快、更省
[3] https://docs.vllm.ai/projects/vllm-omni/en/latest/user_guide/examples/offline_inference/qwen3_omni/

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 4
4 0
0- 0



 已为社区贡献79条内容
已为社区贡献79条内容

所有评论(0)