【LLM】使用DSA和改进GRPO的DeepSeek-V3.2模型
DSA 训练的两个阶段阶段一:Dense Warm-up先冻住主模型,只训练 Lightning Indexer训练目标是让 Indexer 的输出分布对齐主注意力的分布只训练了 1000 步,共 2.1B tokens阶段二:Sparse Training放开所有参数,让模型适应稀疏注意力模式继续用 KL 散度对齐 Indexer 和主注意力训练了 15000 步,共 943.7B tokens
note
- DSA(DeepSeek Sparse Attention):一种稀疏注意力机制,大幅降低长上下文的计算成本
- 后训练加码:把后训练的计算预算提到预训练的 10% 以上
- 大规模合成数据:生成了 1,800 个环境、85,000 个任务,全是合成的
- GRPO训练时的Off-Policy Sequence Masking:把偏离当前策略太远的负样本 mask 掉。直觉是:从自己的错误里学比从不相关的错误(高度偏离policy模型的错误case)里学更有效
- 模型三个局限:
- 世界知识不够丰富,训练算力有限,知识广度不如 Gemini-3.0-Pro
- Token 效率低:达到同样输出质量,需要生成更多 token
- 最难的任务还有差距,在最顶尖的复杂任务上,和 Gemini-3.0-Pro 还有差距
文章目录
一、DeepSeek-V3.2模型
效果: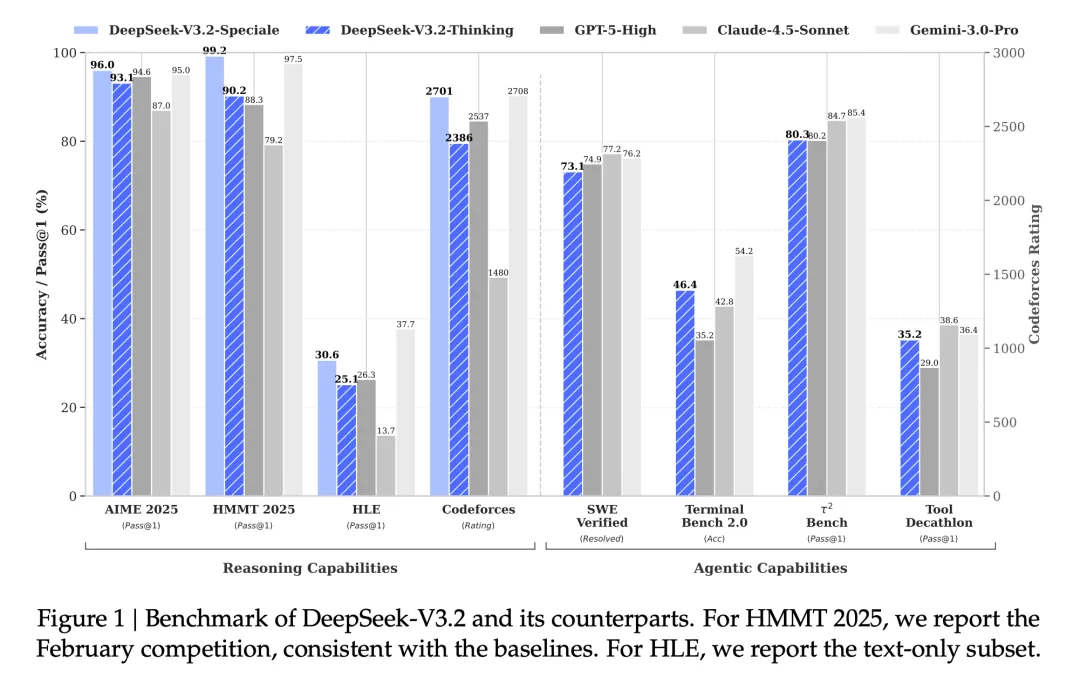
模型结构:
1、DSA部分
(1)通过DSA降低计算复杂度
传统的 Transformer 注意力机制是 O(L²) 复杂度,L 指的是序列长度。DeepSeek 的解决方案是 DSA,核心思路是:
并非每个 token 都看全部上下文,只看最相关的 k 个 token。这样计算量就变成 O(Lk),k 是个固定值(2048),不再随文本长度爆炸式增长。
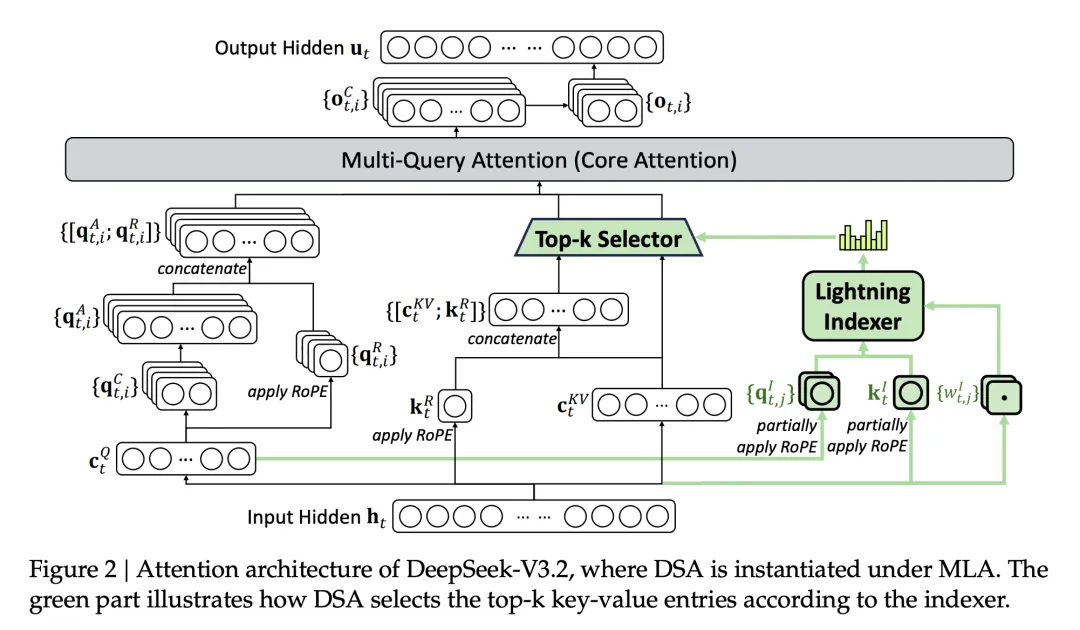
图2|DSA 架构。Lightning Indexer 快速筛选,Top-k Selector 精选 2048 个 token 做注意力计算
两个步骤:
- 第一步:Lightning Indexer。一个轻量级的打分器,给每个历史 token 打分,决定哪些值得关注。这个打分器用 ReLU 激活函数,可以跑在 FP8 精度,算力开销很小
- 第二步:Fine-grained Token Selection:根据 Lightning Indexer 的打分,只选 top-k 个 token 做真正的注意力计算。在 DeepSeek-V3.2 里,k = 2048。虽然 Lightning Indexer 本身还是 O(L²),但它比主注意力轻很多,整体效率大幅提升
(2)DSA 训练的两个阶段
阶段一:Dense Warm-up
先冻住主模型,只训练 Lightning Indexer
训练目标是让 Indexer 的输出分布对齐主注意力的分布
只训练了 1000 步,共 2.1B tokens
阶段二:Sparse Training
放开所有参数,让模型适应稀疏注意力模式
继续用 KL 散度对齐 Indexer 和主注意力
训练了 15000 步,共 943.7B tokens
2、后训练
第一步:专家蒸馏(Specialist Distillation)
为每个任务领域训练一个专门的「专家模型」
六个领域:数学、编程、通用逻辑推理、通用智能体、代码智能体、搜索智能体
每个领域都支持 thinking 和 non-thinking 两种模式
每个专家都用大规模 RL 训练
训练好之后,用专家模型生成领域数据,给最终模型用
第二步:混合 RL 训练(Mixed RL Training)
把推理、智能体、人类对齐三类任务合并成一个 RL 阶段
用 GRPO(Group Relative Policy Optimization)算法
这样做的好处是:避免多阶段训练的灾难性遗忘
3、GRPO的改进
1、Unbiased KL Estimate:原来的 K3 estimator 在某些情况下会给低概率 token 分配过大的梯度权重,导致训练不稳定。DeepSeek 用重要性采样修正了这个问题
2、Off-Policy Sequence Masking:把偏离当前策略太远的负样本 mask 掉。直觉是:从自己的错误里学比从不相关的错误(高度偏离policy模型的错误case)里学更有效
3、Keep Routing:MoE 模型的专家路由在推理和训练时可能不一致。DeepSeek 保存推理时的路由路径,训练时强制复用
4、Keep Sampling Mask:Top-p 采样时的截断 mask 也保存下来,训练时复用。保证采样策略和训练策略一致
二、大规模智能体数据合成
1、合成数据的做法

具体数据
代码智能体 24,667 个任务(真实环境,提取的提示)
搜索智能体 50,275 个任务(真实环境,合成的提示)
通用智能体 4,417 个任务(合成环境,合成提示)
代码解释器 5,908 个任务(真实环境,提取的提示)
最终得到了 1,827 个环境,4,417 个任务:
合成任务示例:三天旅行规划。约束条件复杂,验证容易,搜索空间大——典型的「难解易验」问题
任务很难解,但验证很简单——只要检查所有约束是否满足。这类「难解易验」的任务特别适合 RL。
2、合成数据带来的收益
用 V3.2-SFT 只在合成的通用智能体数据上做 RL,测试在 Tau2Bench、MCP-Mark、MCP-Universe 上的效果
结果是:显著提升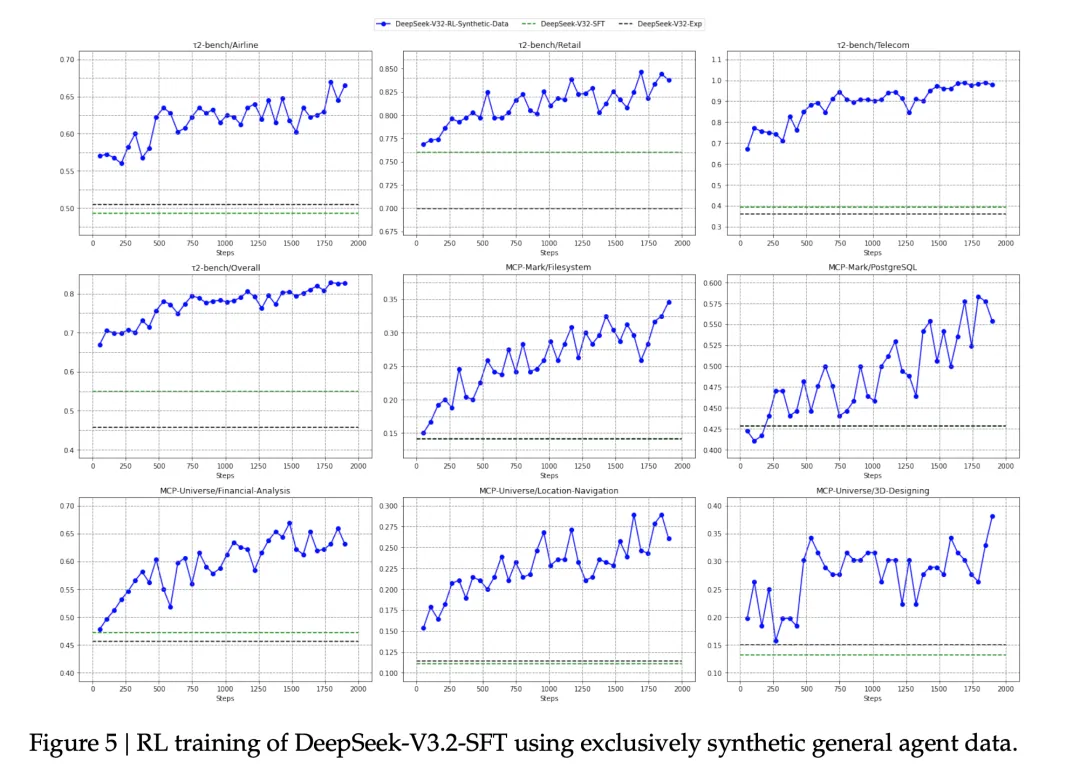
三、Thinking in Tool-Use
1、保存历史推理结果
推理和工具调用融合。DeepSeek-R1 证明了「thinking」对解决复杂问题很有帮助。但 R1 的策略是:第二轮消息到来时,丢弃之前的推理内容。这在工具调用场景下很浪费——每次工具返回结果,模型都要重新推理一遍。
DeepSeek-V3.2 的设计是:
• 只有新的用户消息到来时才丢弃推理内容
• 如果只是工具返回结果,保留推理内容
• 丢弃推理内容时,工具调用历史保留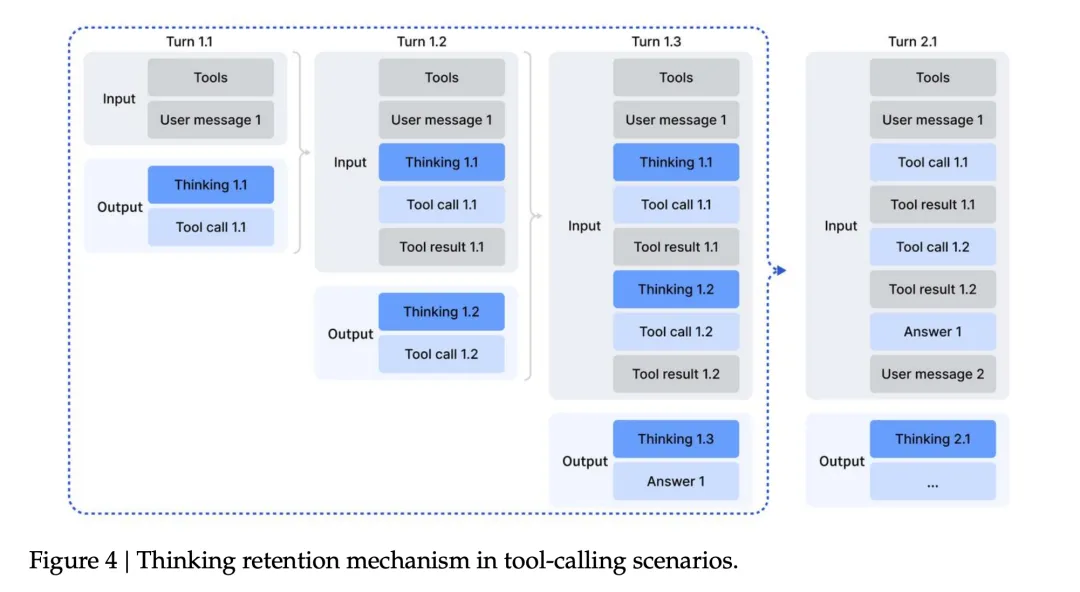
2、Cold-Start
冷启动SFT,让模型学会在think思考链中使用工具调用,但在最终答案中不调用工具:
四、模型效果
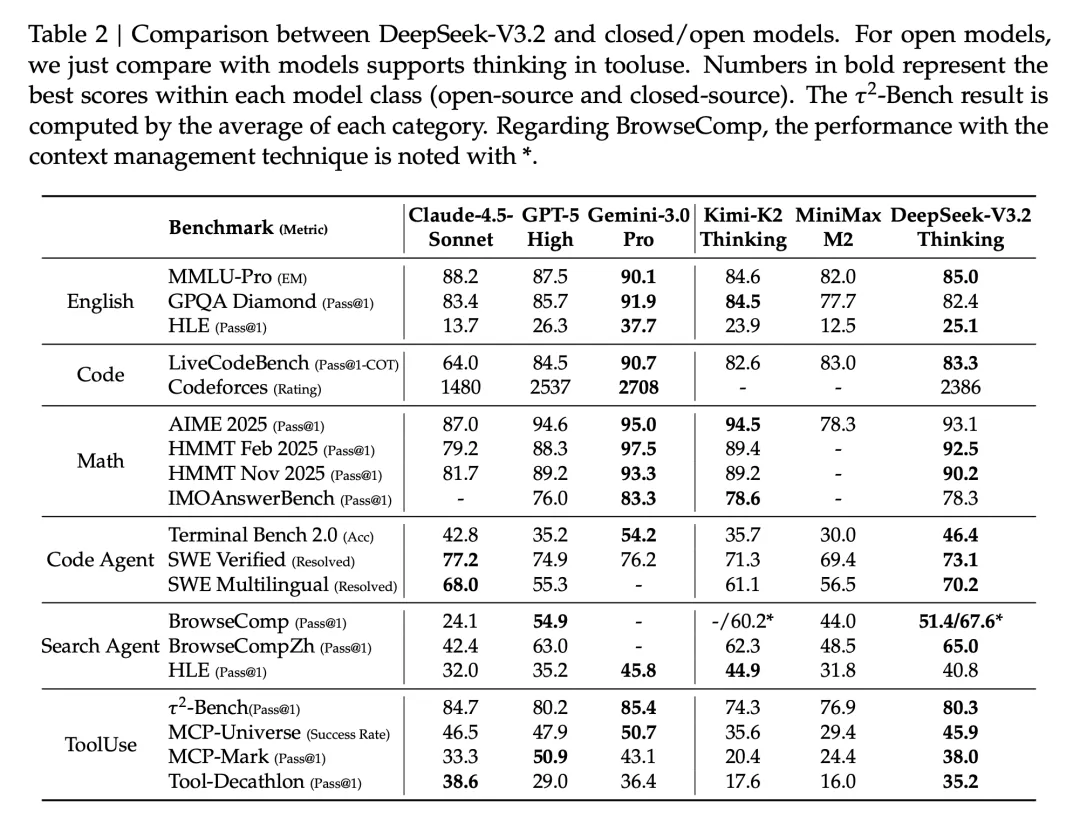
Token 效率,是 DeepSeek-V3.2 的一个短板。举个例子,在 Codeforces 中,Gemini-3.0-Pro 用 22k tokens 拿 2708 分,DeepSeek-V3.2 用 42k tokens 才拿 2386 分,Speciale 版本用 77k tokens 拿 2701 分
Speciale 版本为了达到更高性能,输出 token 数明显更多: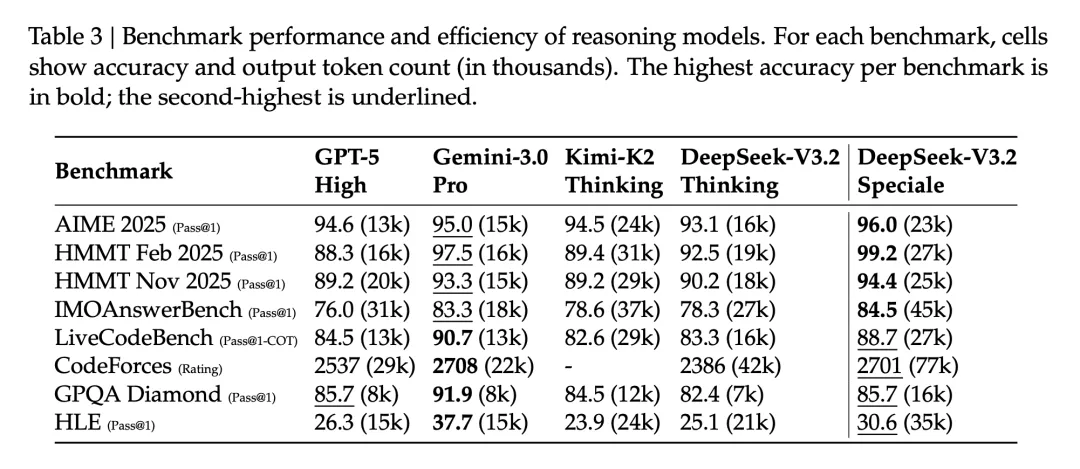
五、上下文管理策略
DeepSeek 试了几种策略:
- Summary:超限后总结轨迹,重新开始
- Discard-75%:丢弃前 75% 的工具调用历史
- Discard-all:丢弃所有工具调用历史(类似 Anthropic 的 new context tool)
- Parallel-fewest-step:并行采样多个轨迹,选步数最少的
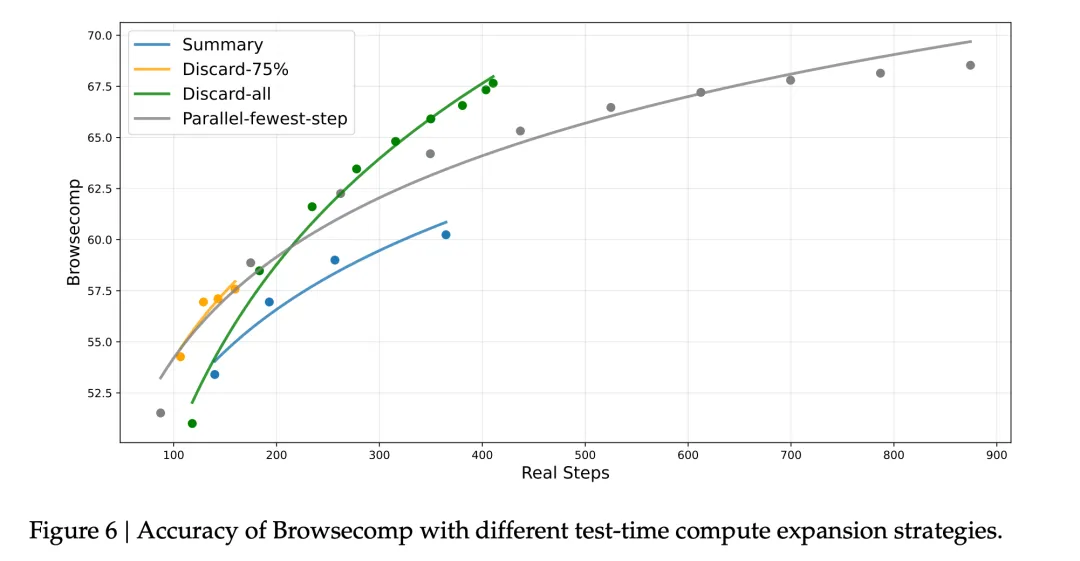
结果有点反直觉:
最简单的 Discard-all 效果最好,BrowseComp 从 53.4% 提升到 67.6%
Summary 效率最低,虽然也能提升性能
Reference
[1] 《DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models》
[2] DeepSeek-V3.2|技术报告解读
[3] DeepSeekV3.2后训练:稳定压倒一切

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 23
23 0
0- 0



 已为社区贡献96条内容
已为社区贡献96条内容

所有评论(0)