【音频标注】- 大模型部署资源极致利用方案尝试(一)
摘要:本文探讨了大模型部署的资源优化方案,针对deepseek-R1 1.58Bit模型当前124G内存和11G显存(共48G)的利用不足问题,提出两个优化目标:实现显存极致占用的最佳部署方案,并测试不同参数量模型在该方案下的推理速度。当前测试显示模型推理速度约6汉字/秒,但资源利用率未达最优,后续将重点研究显存占满状态下的性能提升方案。
【音频标注】- 大模型部署资源极致利用方案尝试(一)
背景
deepseek-R1满血版 1.58 Bit模型落地部署 成功后,测试约 6汉字/秒,tokens速度测试貌似不准。内存占用124G(基本是满用),显存占用11G(共48G),显存明显没占满,效率没达到最极致。等资源占用效率达到极致后再
往下一步的目标:
(1)极致占满显存下的最佳方案;
(2)尝试这种最佳方案下的不同参数量模型的速度,考察实用性。
小结
Llamafile 代表了在使大型语言模型 (LLM) 更容易访问方面的重大进步,通过解决传统部署复杂性问题(如环境配置和硬件依赖)来实现这一目标。
极致占满显存下的最佳方案调研
回头看文档,当前 Bilibili 博主老师嫁接了Unsloth 和 KTransformer,让KTransformer能够运行经过Unsloth动态量化后的大模型文件。
但从文档“”的字里行间
因此,我们团队在深入研究KTransformers源码后,对V0.2版本的部分代码进行了修改,
并最终适配1.58bit Unsloth动态量化模型,使得最低可以在60G内存、14G显存下顺利运
行,至强3代CPU+DDR4+虚拟GPU运行时效果如下
看来,老师打通的也仅有一个 “1.58bit”。所以,基于当前框架,我想跑其它的动态量化模型貌似是不太行。
看来需要先补一下课(KTransformer、Unsloth、ollama.cpp)以明确各个工具的用法,再看看是否能让gpu性能拉满。
1. KTransformers
https://kvcache-ai.github.io/ktransformers/
KTransformers 是一个研究项目,专注于通过 CPU-GPU 异构计算实现大型语言模型的高效推理和微调。该项目已发展为两个核心模块:kt-kernel 和 kt-sft。
从以下日历中看出它支持的内容:
2025 年 11 月 6 日:支持 Kimi-K2-Thinking 模型推理(附教程)与微调(附教程)
2025 年 11 月 4 日:完成 KTransformers 微调功能与 LLaMA-Factory 工具的集成(附教程)
2025 年 10 月 27 日:支持昇腾 NPU(附教程)
2025 年 10 月 10 日:完成与 SGLang 框架的集成(附路线图、博客)
2025 年 9 月 11 日:支持 Qwen3-Next 模型(附教程)
2025 年 9 月 5 日:支持 Kimi-K2-0905 模型(附教程)
2025 年 7 月 26 日:支持 SmallThinker 模型与 GLM4-MoE 模型(附教程)
2025 年 7 月 11 日:支持 Kimi-K2 模型(附教程)
2025 年 6 月 30 日:支持三层(GPU - 内存 - 磁盘)前缀缓存复用功能
2025 年 5 月 14 日:支持英特尔锐炫(Intel Arc)显卡(附教程)
2025 年 4 月 29 日:支持 AMX-Int8、AMX-BF16 精度模式及 Qwen3MoE 模型(附教程)
2025 年 4 月 9 日:实验性支持 LLaMA 4 系列模型(附教程)
2025 年 4 月 2 日:支持多并发功能(附教程)
2025 年 3 月 15 日:支持 AMD 显卡的 ROCm 计算平台(附教程)
2025 年 3 月 5 日:支持 unsloth 1.58/2.51 比特权重及 IQ1_S/FP8 混合权重;在 24GB 显存下为 DeepSeek-V3 与 R1 模型实现 13.9 万长度上下文支持
2025 年 2 月 25 日:为 DeepSeek-V3 与 R1 模型适配 FP8 精度 GPU 内核;支持更长上下文长度
2025 年 2 月 15 日:支持更长上下文(24GB 显存下由 4K 拓展至 8K),推理速度小幅提升(+15%,最高可达 16 词 / 秒),同步更新文档及在线手册
2025 年 2 月 10 日:支持单卡(24GB 显存)/ 多卡及 382G 内存环境运行 Deepseek-R1 与 V3 模型,推理速度最高可提升 3~28 倍;具体案例及复现教程详见此处
2024 年 8 月 28 日:将 DeepseekV2 模型显存占用由 21G 降至 11G
2024 年 8 月 15 日:更新注入功能及多 GPU 部署的详细教程
2024 年 8 月 14 日:支持以 llamfile 作为线性后端
2024 年 8 月 12 日:支持多 GPU 部署;新增支持 mixtral 87B、822B 模型;支持在 GPU 上实现 q2k、q3k、q5k 格式模型的反量化
2024 年 8 月 9 日:支持 Windows 原生系统运行
KTransformers 明确标注 “支持” 的所有模型(如下),均仅具备文本生成 / 理解能力,无图像、音频、视频等多模态处理能力:
• Kimi 系列:Kimi-K2、Kimi-K2-0905、Kimi-K2-Thinking
• 通义千问系列:Qwen3-Next、Qwen3MoE
• DeepSeek 系列:DeepSeek-V3、DeepSeek-R1、DeepseekV2
• Mixtral 系列:mixtral 87B、mixtral 822B
• 其他:LLaMA 4(实验性)、SmallThinker、GLM4-MoE
Transformers 的所有更新(如显存优化、硬件适配、框架集成)均服务于纯语言模型:
核心优化:三层缓存复用、FP8/Int8/AMX 精度加速、超长上下文支持(139K);
硬件适配:昇腾 NPU、AMD ROCm、Intel Arc GPU、Windows 原生;
生态集成:LLaMA-Factory、SGLang、llamfile 后端;
以上更新均未提及 “图像编码器集成”“跨模态注意力适配”“多模态数据处理接口” 等多模态模型必备的适配能力。
(1)SGLang
SGLang 是一款轻量级、高性能的大模型推理框架,核心定位是解决大模型推理阶段的 “动态提示管理 + 低延迟 + 高并发” 问题,专为对话式场景(多轮交互、动态上下文)设计,常与 vLLM、Transformers 等底层推理引擎配合使用。
针对 DeepSeek-V3/R1 等超长上下文模型做了内存复用优化,24G 单卡更稳定
(2)llamfile 后端
llamfile 是一套大模型 “一键部署” 工具链,核心功能是将 LLaMA/Mixtral/Kimi-K2 等兼容模型(含权重 + 运行时依赖 + 推理引擎)打包成单一可执行文件(.llamfile),无需配置 CUDA/ROCm/Python 环境即可运行。
Llamafile 代表了在使大型语言模型 (LLM) 更容易访问方面的重大进步,通过解决传统部署复杂性问题(如环境配置和硬件依赖)来实现这一目标。在本质上,llamafile 利用 llama.cpp(一个高效的 C/C++ 推理引擎)来执行模型,同时使用 Cosmopolitan Libc 来创建跨平台的可执行文件,这些文件可以在 Ubuntu 24.04 等系统上原生运行,而无需额外安装。这是一种简化方法,但也提升了可移植性,让拥有像您的 RTX 4090(48GB 显存)、128GB 内存和 8TB 存储的硬件的用户能够轻松实验高级模型。
为了澄清您提到的 llamafile 描述:它将兼容模型(例如 LLaMA、Mixtral、Kimi-K2)打包成一个“.llamafile”可执行文件,其中包含所有必要组件——权重、依赖和引擎。如果可用,文件内部会处理加速,因此无需 CUDA/ROCm/Python 设置,这使其非常适合服务器上的“一键”部署。
Llamafile支持所有llama.cpp兼容的GGUF格式模型,可从Hugging Face下载预构建.llamafile文件或转换GGUF模型。您的硬件(RTX 4090 48GB显存、128GB内存、Ubuntu 24.04)适合量化版本(Q4/Q5),大型模型需MoE卸载。预计可部署数十种,覆盖文本生成、代码、视觉等任务。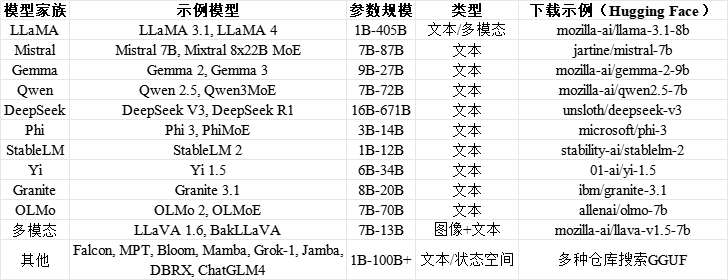
更多家族包括:StarCoder(代码)、Vigogne(法语)、BERT、Koala、Aquila、Refact、PLaMo、Command-R、SEA-LION、Snowflake-Arctic MoE、Smaug、Bitnet、Flan T5、Open Elm、SmolLM、EXAONE、FalconMamba、Jais、Bielik、RWKV-6、GigaChat、Trillion、Ling、LFM2、Hunyuan、BailingMoeV2。
进镜像网站查看
https://hf-mirror.com/mozilla-ai
发现这个项目 mozilla-ai 下,基于 “.llamafile”可执行文件 的一键部署,已支持64个模型如下: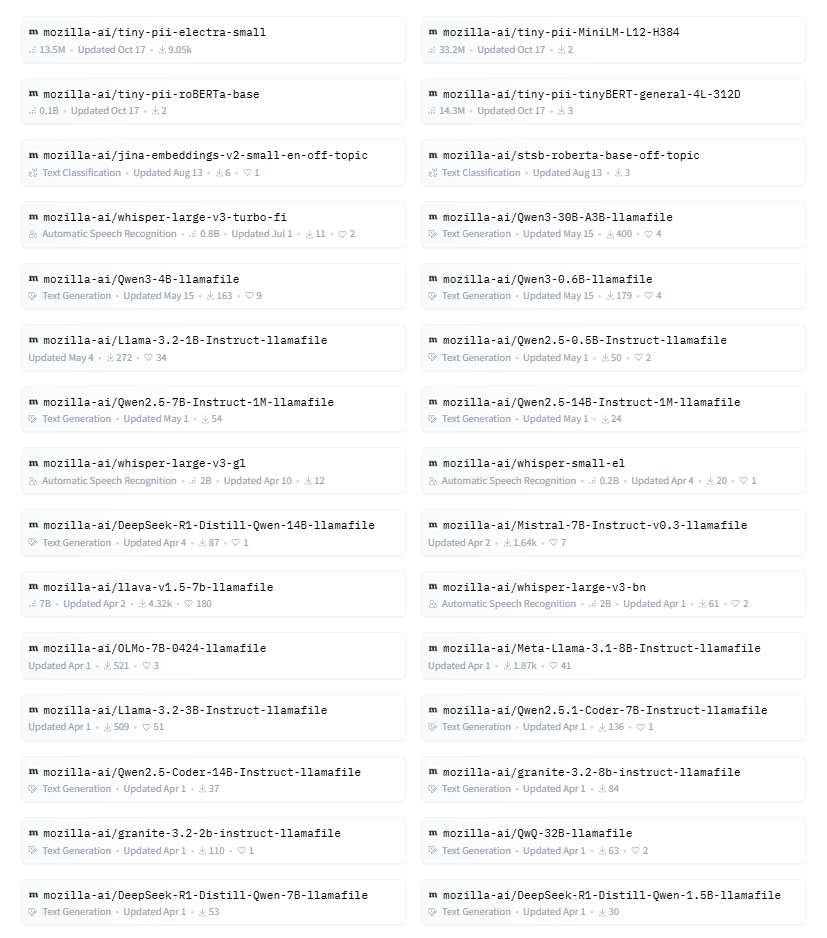
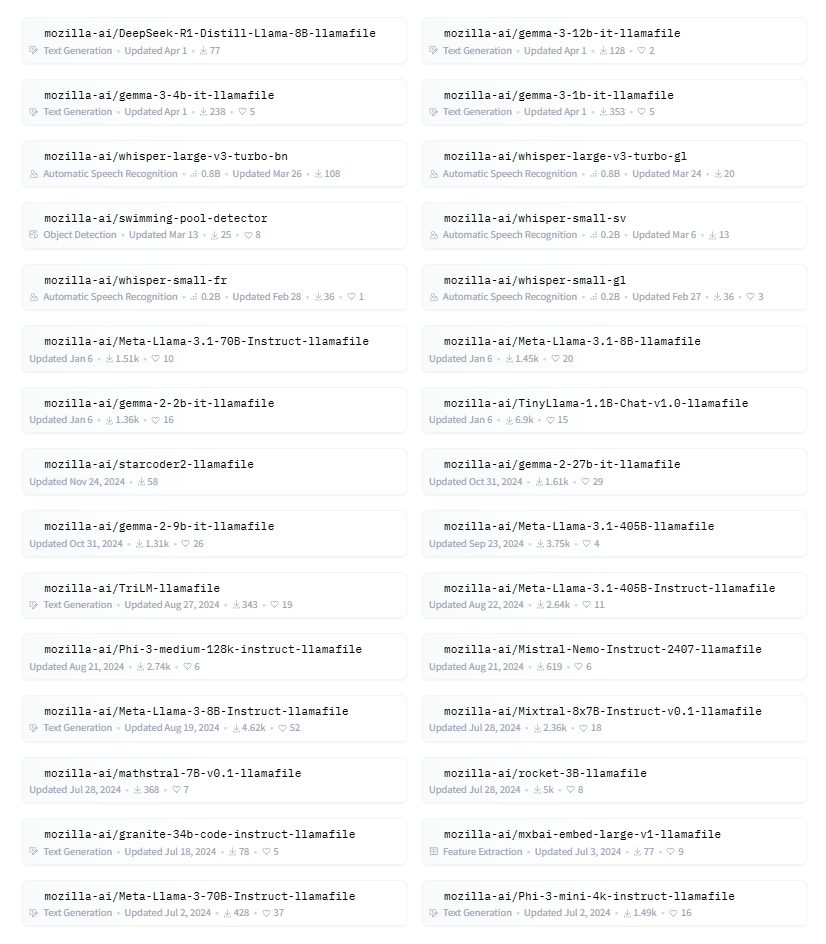

这64个模型,整体说明如下: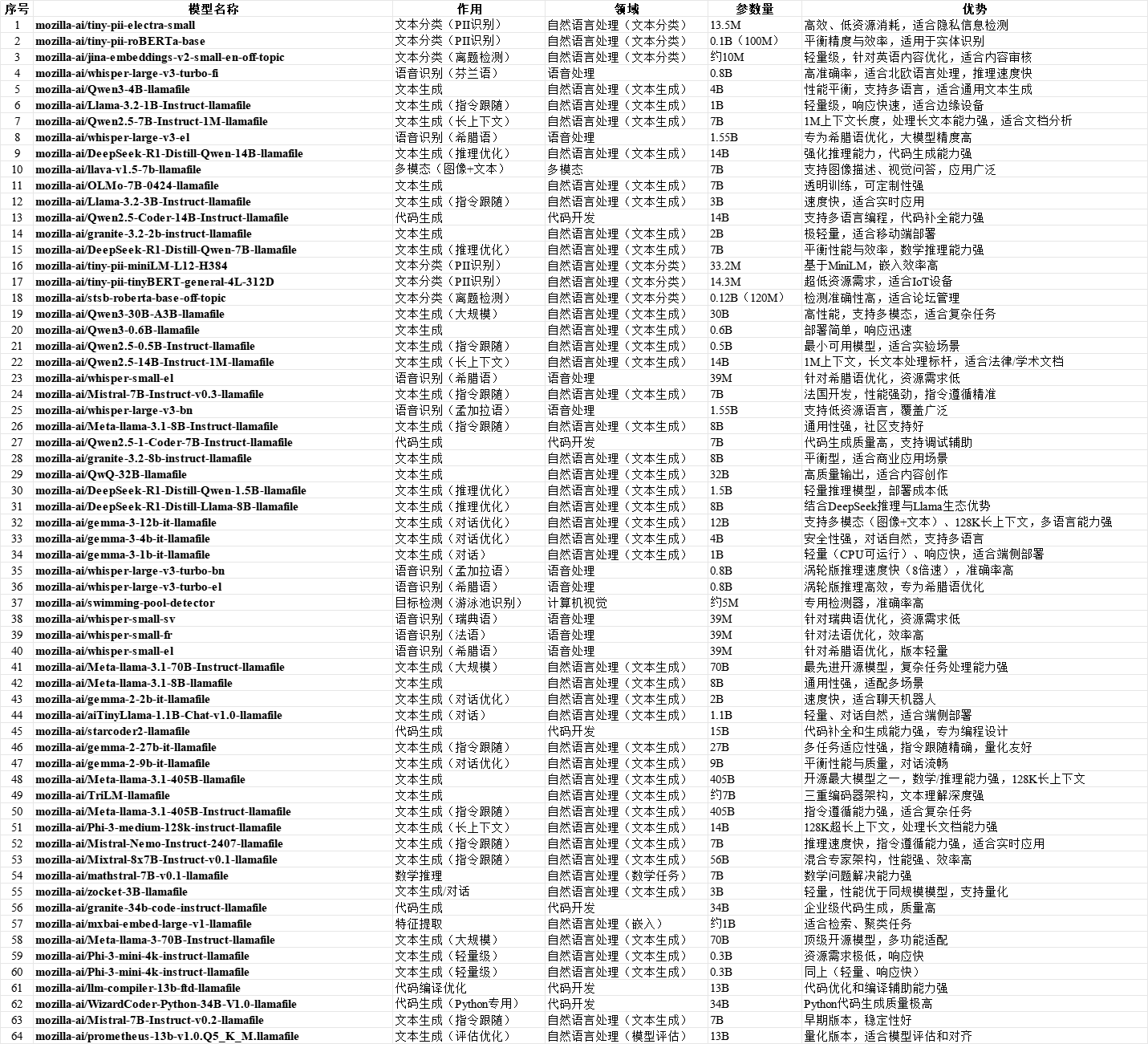
模型涉及:文本分类、语音识别、文本生成、多模态、代码生成、数学推理、特征提取。我关注一些特殊功能:音频、多模态、大参数等。
大参数有:mozilla-ai/Meta-llama-3.1-405B-llamafile、mozilla-ai/Meta-llama-3-70B-Instruct-llamafile
代码生成有:mozilla-ai/WizardCoder-Python-34B-V1.0-llamafile 等
多模态有:mozilla-ai/llava-v1.5-7b-llamafile、mozilla-ai/Qwen3-30B-A3B-llamafile、mozilla-ai/gemma-3-12b-it-llamafile。
进入 路径 https://hf-mirror.com/mozilla-ai/Meta-Llama-3.1-405B-Instruct-llamafile/tree/main 下,可见: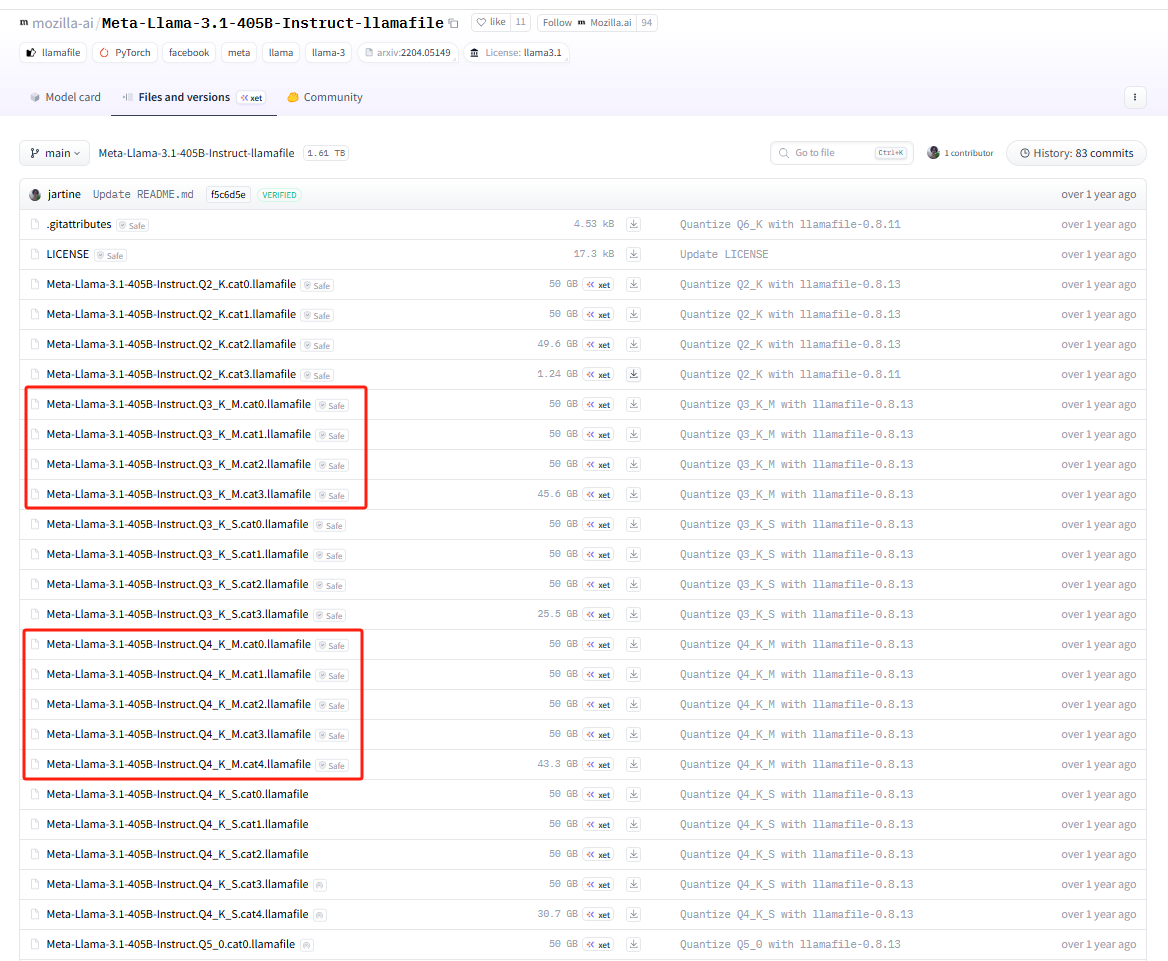
K_M 是资源有限的条件下的一键部署文件。Q5_K_M/Q5_K_S 这类后缀中,S(Small)和 M(Medium)是 GGUF/GPTQ 量化标准中「K-quant 算法」的变体,核心是同一量化位宽(如 Q5)下,对模型权重的压缩策略、精度、显存占用 做的差异化设计,二者属于「同级别量化位宽下的不同优化版本」。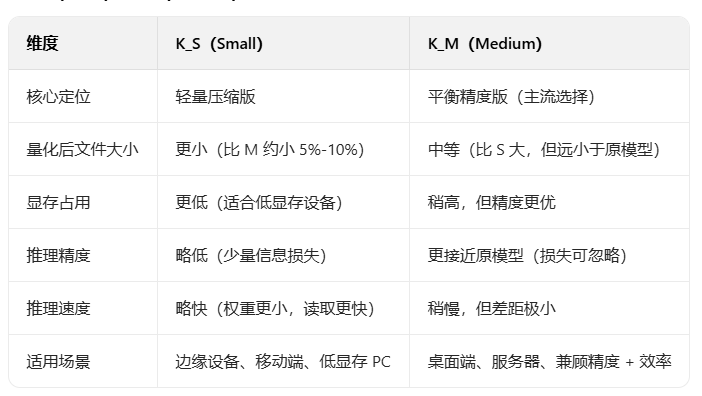
或者,进入另一个路径,其中有几个很实用的大参数模型可下载,并一键部署。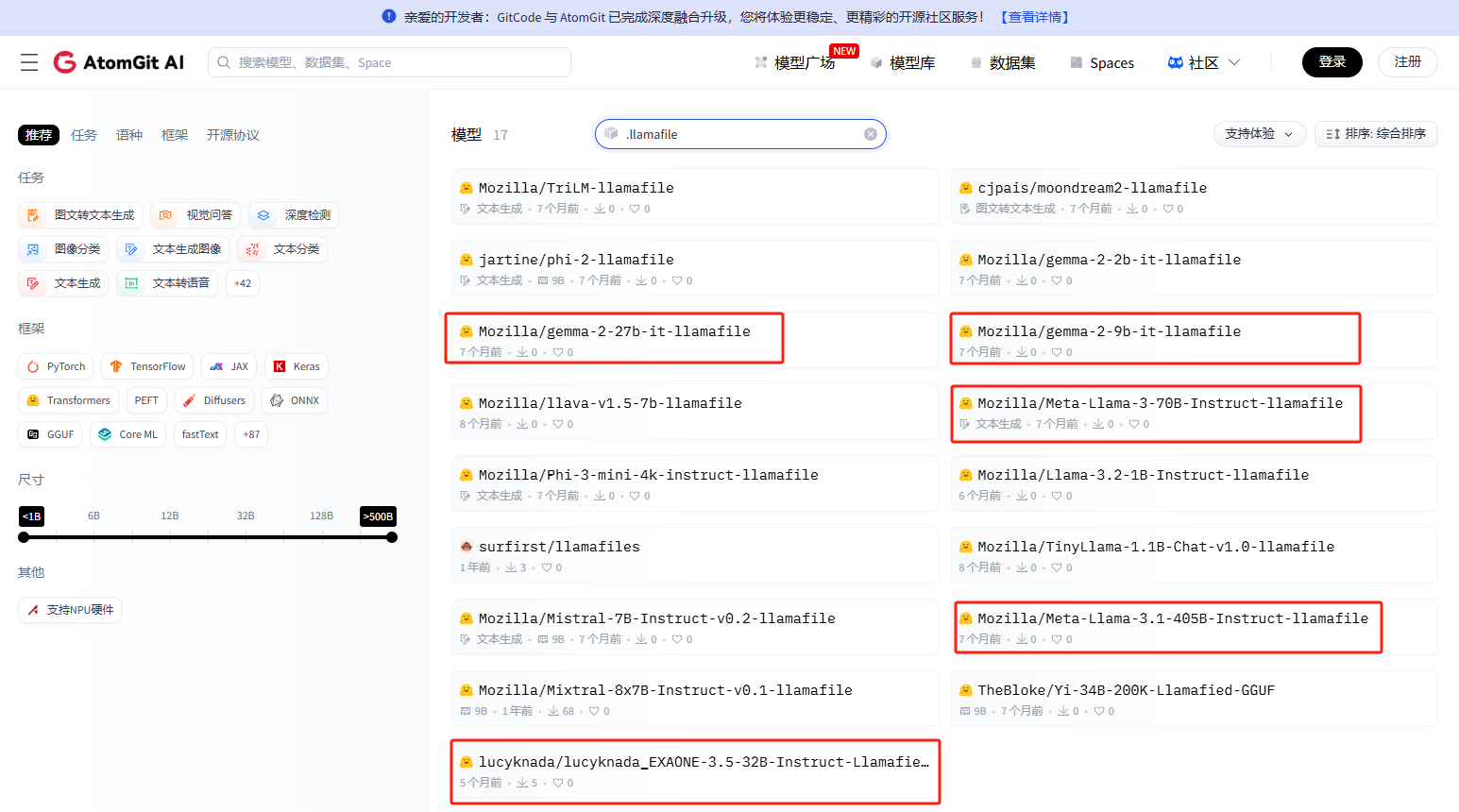
(3)更进一步:动态量化 + .llamafile
确实有一些动态量化一键部署的文件可用。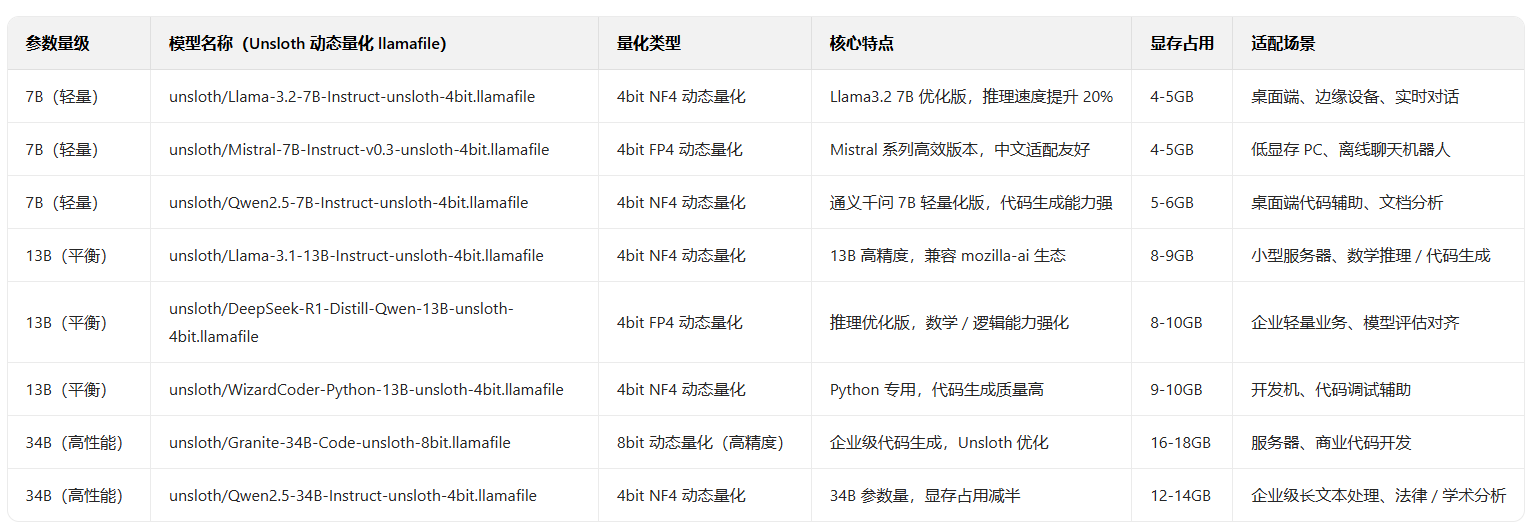
并不多。不过,更值得一提的是,看到有一个项目,只需要 5 行代码,就能够自己制作基于 unsloth 动态量化的一键部署文件。
https://github.com/Mozilla-Ocho/llamafile
from unsloth import FastLanguageModel
import llamafile_pack # 内置打包工具
# 1. 加载模型并做 Unsloth 4bit 动态量化
model, tokenizer = FastLanguageModel.from_pretrained(
model_name="你的模型名(如mozilla-ai/Qwen2.5-14B-Instruct)",
load_in_4bit=True, # 动态量化为4bit NF4
device_map="auto"
)
# 2. 一键打包为 llamafile
llamafile_pack.pack(
model=model,
tokenizer=tokenizer,
output_file="custom-unsloth-4bit.llamafile" # 输出一键部署文件
)
(4)LLaMA-Factory
2. Unsloth
3. ollama.cpp
4. Ollama

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 2
2 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)