ollama cloud 白嫖 kimi k2 额度
本文介绍了在Windows服务器上配置Ollama实现局域网共享AI模型的方法。通过修改Ollama监听配置、设置防火墙规则,使团队成员可通过浏览器或API访问KimiK2Thinking模型。文章详细说明了从环境变量配置到客户端测试的完整流程,并提供了常见问题解决方案。此外,还介绍了Ollama的常用命令和模型管理技巧,帮助用户高效利用本地算力或云模型额度,实现团队共享AI服务。
最近想共享 AI 模型服务,发现 Ollama 其实可以轻松实现局域网部署。今天就来分享如何在 Windows 服务器上配置 Ollama,让团队小伙伴都能使用 Kimi K 2 Thinking 模型,充分利用本地算力或云模型额度。
前置条件
-
一台装有 Windows 10/11 或 Windows Server 的服务器
-
服务器已安装 Ollama 注册且已安装云模型
-
管理员权限
-
局域网内其他电脑可以访问该服务器
ollama run kimi-k2-thinking:cloud第一步:配置 Ollama 监听所有网络接口
默认情况下,Ollama 只监听 localhost,我们需要修改配置让它监听所有网络接口。
方法一:CMD 命令行(推荐)
以管理员身份打开 CMD,执行:
setx OLLAMA_HOST "0.0.0.0:11434" /M-
setx:设置永久环境变量 -
/M:设置为系统级变量(需管理员权限) -
0.0.0.0表示监听所有可用的网络接口
方法二:PowerShell
[Environment]::SetEnvironmentVariable("OLLAMA_HOST", "0.0.0.0:11434", "Machine")第二步:重启 Ollama 服务
环境变量设置后需要重启服务才能生效:
-
打开任务管理器,结束所有
ollama.exe进程 -
从开始菜单重新启动 Ollama
-
更彻底的方式:直接重启服务器

ollama 免费用量查询
第三步:验证监听状态
重启后,检查 Ollama 是否正确监听:
netstat -ano | findstr :11434如果看到 0.0.0.0:11434 或 [::]:11434,说明配置成功!
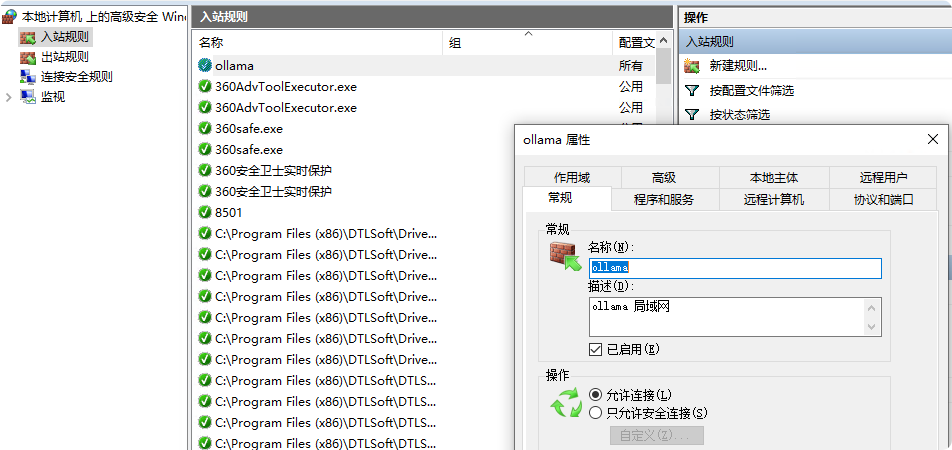
第四步:配置 Windows 防火墙(关键步骤)
这是最容易忽略的环节!环境变量只是让 Ollama 监听所有接口,但防火墙默认会阻止外部访问。
方式一:PowerShell 一键配置(推荐)
以管理员身份运行 PowerShell,执行:
New-NetFirewallRule -DisplayName "Ollama LAN Access" -Direction Inbound -Protocol TCP -LocalPort 11434 -Action Allow方式二:图形界面配置
-
按
Win + R,输入wf.msc打开高级安全 Windows 防火墙 -
右键 "入站规则" → "新建规则..."
-
选择 "端口" → "TCP" → 特定本地端口:
11434 -
选择 "允许连接" ,下一步
-
配置文件全选(域、专用、公用)
-
名称填写
Ollama LAN Access,点击完成
第五步:从客户端测试连接
在局域网其他电脑上,将 <server_ip> 替换为服务器 IP 地址:
浏览器测试
http://<server_ip>:11434/如果看到 Ollama is running 的提示,说明连接成功!
API 接口测试
PowerShell 测试代码(推荐):
curl -X POST http://<server_ip>:11434/api/generate ` -H 'Content-Type: application/json' ` -d '{"model":"kimi-k2-thinking:cloud","prompt":"你好,请做一个简单的自我介绍","stream":false}'curl 命令测试:
curl http://<server_ip>:11434/api/tags如果返回 JSON 格式的模型列表,说明一切配置正确!
第六步:使用 Cherry Studio 可视化连接
对于不熟悉命令行的用户,Cherry Studio 是绝佳的客户端工具。
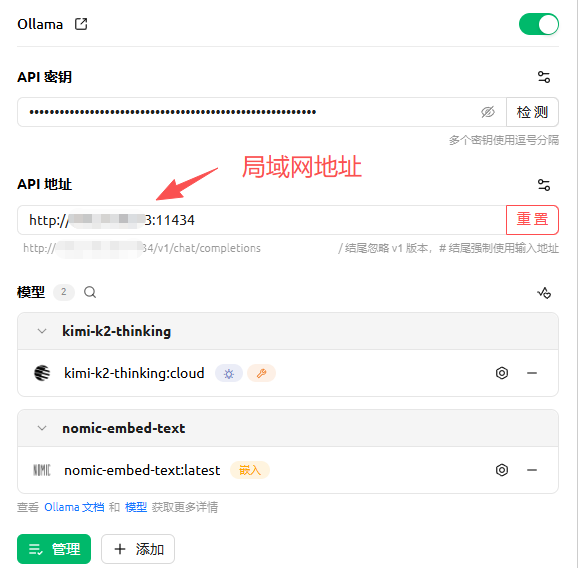
配置步骤
-
下载并安装 Cherry Studio
-
进入设置 → 模型服务 → 添加自定义 OpenAI 接口
-
API 地址填写:
http://<server_ip>:11434/v1 -
API 密钥:随便填写(Ollama 不要求认证,但不能为空)
-
模型名称:填入你在服务器上运行的模型名,如
kimi-k2-thinking:cloud -
点击测试,成功后即可使用
注意事项
-
IP 地址固定:建议为服务器设置静态 IP,避免重启后 IP 变化
-
网络发现:确保服务器和客户端在同一网段,且能互相 ping 通
-
模型权限:如果使用的是云模型(如 Kimi 的 API),注意额度消耗
-
安全性:在公共网络环境下,建议添加认证机制或限制访问 IP 范围
-
性能考虑:多人同时使用时,注意服务器显存和内存占用
常见问题排查
|
问题现象 |
可能原因 |
解决方案 |
|---|---|---|
|
客户端无法连接 |
防火墙未放行 |
检查服务器防火墙入站规则 |
|
连接被拒绝 |
Ollama 未监听 0.0.0.0 |
确认环境变量设置并重启服务 |
|
能访问但无响应 |
模型未下载 |
在服务器上执行 |
|
间歇性断开 |
IP 地址变化 |
为服务器设置静态 IP |
ollama 常用命令
模型生命周期管理
-
拉取(下载)模型
ollama pull <模型名>[:标签]例:ollama pull llama3.1:8b若本地已存在同版本会自动跳过;不写标签默认 latest 。 -
查看本地已下载
ollama list或简写ollama ls显示名称、ID、大小、最后修改时间。 -
删除本地模型
ollama rm <模型名>例:ollama rm llama2立即释放磁盘空间。 -
复制模型(快速做备份/改名)
ollama cp <源> <目标>例:ollama cp llama2 my-llama2。 -
查看模型元数据
ollama show <模型名>输出参数、量化方式、占用路径等。
运行与会话控制
-
启动交互式对话
ollama run <模型名>例:ollama run qwen:7b首次运行若本地无镜像会自动先 pull 。 -
单次非交互推理
ollama run <模型名> "提示词"例:ollama run mistral "用中文解释量子计算"。 -
查看正在跑的模型
ollama ps列出进程、已占显存/内存。 -
停止模型(释放显存)
ollama stop <模型名>例:ollama stop deepseek-r1:8b。
自定义模型 / 参数
-
创建专属模型A) 先写描述文件
cat > Modelfile <<EOFFROM llama3.1:8bSYSTEM "你是一位运维专家"PARAMETER temperature 0.6PARAMETER num_ctx 4096EOFB) 构建并命名
ollama create myops -f ModelfileC) 运行ollama run myops。 -
运行时临时改参
ollama run llama3.1:8b --temperature 0.8 --num_predict 200。
服务与调试
-
手动启动后台服务
ollama serve默认监听 11434,提供 HTTP API;如已设 systemd 可省略。 -
查看所有可用命令
ollama help或ollama --help。 -
查看版本
ollama -v。
五、一条完整工作流示例
# 1. 先看本地有什么ollama list# 2. 下载并跑 8B 模型ollama run llama3.1:8b# 3. 退出对话后,想长期保留自定义版ollama create llama3-8b-cn -f ./Modelfile# 4. 以后直接跑自定义版ollama run llama3-8b-cn# 5. 不使用时清理ollama stop llama3.1:8b && ollama rm llama3.1:8b总结
通过以上步骤,我们成功将 Ollama 服务部署为局域网共享资源。团队成员无需每人重复配置环境,即可通过 Cherry Studio 等客户端轻松使用 Kimi K 2 Thinking 模型。对于小团队来说,这是充分利用已有硬件资源和云模型免费额度的绝佳方案。
如果你有任何问题或更好的优化建议,欢迎在评论区交流!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 33
33 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)