DeepSeek Sparse Attention架构解析:让长上下文大模型推理又快又准
DSA的本质,是用“轻量索引筛选+高效注意力计算”的组合,解决了长上下文大模型的“性能-效率”矛盾。这张架构图里的每个模块,都在围绕“少算但算对”这个目标设计——而这,正是开源大模型能追上闭源前沿的关键技术之一。
长上下文能力是大模型落地的关键特性之一,但传统Transformer的Vanilla Attention机制,会带来**O(L²)**的计算复杂度(L是序列长度)——当序列拉长到128K甚至更长时,推理成本会飙升到难以承受的地步。
DeepSeek-V3.2中提出的DeepSeek Sparse Attention(DSA),正是为解决这个痛点而生。今天我们就通过架构图,拆解DSA如何在“保留长上下文性能”的同时,把计算复杂度压到O(Lk)(k是选中的token数,远小于L)。
DSA架构总览:稀疏化+高效注意力的组合拳
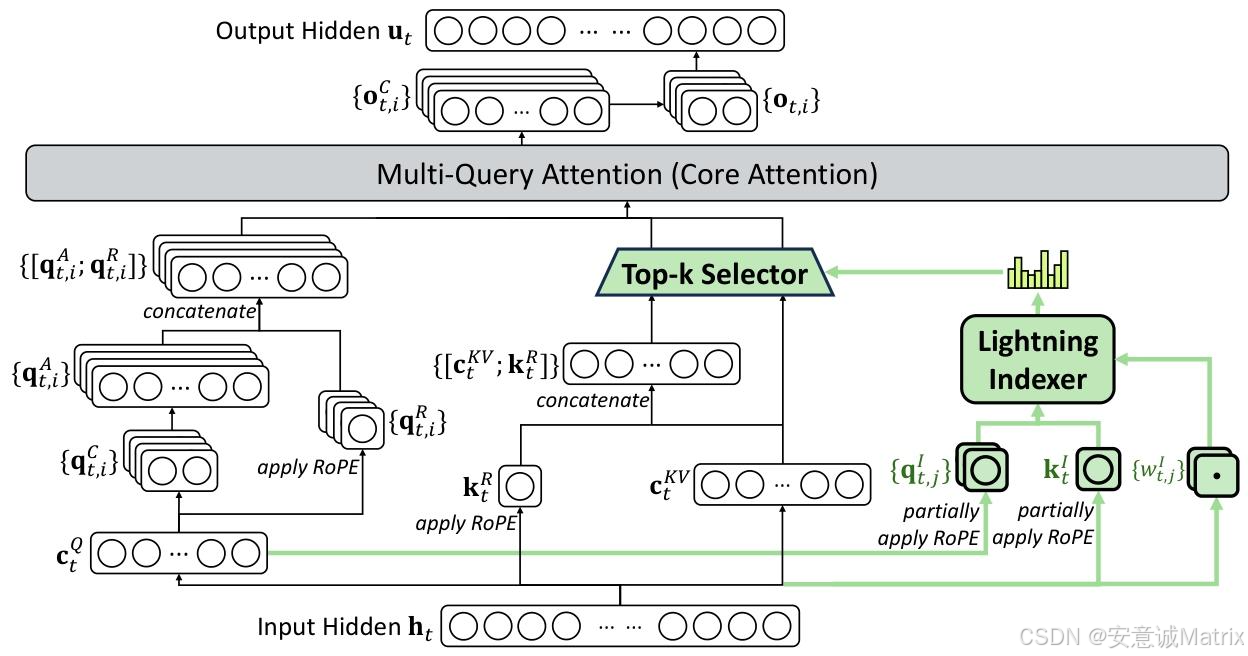
这张图展示的是DSA的核心流程:从输入隐藏状态h_t出发,通过闪电索引器筛选关键token、Top-k选择缩小计算范围、再结合**多查询注意力(MQA)**完成高效计算,最终输出隐藏状态u_t。
整个流程的核心逻辑是:只对“对当前查询有价值的少数token”做注意力计算,既避免了全序列计算的冗余,又能保留关键信息的交互。
模块拆解:从输入到输出的每一步
我们沿着数据流,逐一解析图中的核心组件:
1. 输入处理:拆分多分支特征
架构的起点是输入隐藏状态h_t(大模型中某一层的输入向量序列)。从h_t会拆分出3类核心特征,分别服务于“查询计算”“键值计算”“稀疏索引”三个分支:
- 查询分支:生成
c_t^Q(查询特征),后续会转换为查询向量q_t,i^C,再通过**RoPE(旋转位置编码)**添加位置信息,得到q_t,i^R; - 键值分支:生成
c_t^KV(键值特征)和k_t(键向量),k_t同样会通过RoPE添加位置信息,得到k_t^R; - 稀疏索引分支:生成
q_t,j^I(索引查询)、k_t^I(索引键)和w_t,j^I(索引权重),这部分是“筛选关键token”的基础。
2. 闪电索引器:快速锁定关键token
**Lightning Indexer(闪电索引器)**是DSA的“大脑”——它的作用是快速判断:前文哪些token对当前查询h_t是重要的?
它的工作流程很轻量:
- 用“稀疏索引分支”的
q_t,j^I(部分RoPE编码)、k_t^I(部分RoPE编码)和w_t,j^I做快速计算,得到每个前文token的重要性得分(图中右侧的柱状图); - 之所以叫“闪电”,是因为它用了少量注意力头+低精度(FP8)实现,计算成本远低于传统Attention。
3. Top-k Selector:缩小计算范围
拿到“重要性得分”后,**Top-k Selector(Top-k选择器)**会从所有前文token中,挑选出得分最高的k个(比如DeepSeek-V3.2中k=2048)。
这一步是“稀疏化”的关键:传统Attention要和所有L个token计算交互,而DSA只和这k个token交互——直接把计算复杂度从O(L²)压到了O(Lk)(k远小于L,比如L=128K时,k=2048仅为L的1.6%)。
4. 核心注意力:多查询注意力(MQA)提效
经过Top-k筛选后,剩下的“关键token键值对”会进入**Multi-Query Attention(MQA,多查询注意力)**模块——这是DSA的“计算核心”。
MQA的设计本身就是为了效率:它让多个查询头(Query Head)共享同一个键值头(Key-Value Head),既能减少内存占用,又能加快推理速度。
在这个模块中,“查询分支”生成的{q_t,i^A; q_t,i^R}(拼接后的查询向量),会和Top-k筛选后的键值对做注意力计算,最终得到中间输出{o_t,i^C},再处理为最终的输出隐藏状态u_t。
为什么DSA能兼顾“效率”与“性能”?
很多稀疏Attention方案会牺牲性能换效率,但DSA通过两个设计避免了这个问题:
- 闪电索引器的准确性:通过KL损失对齐“索引得分”与“真实注意力分布”,确保筛选出的token是真的“关键”;
- 两阶段训练适配:先“密集热身”初始化索引器,再“稀疏训练”适配全模型,让模型习惯用稀疏方式学习有效交互。
这也是为什么DeepSeek-V3.2在128K长序列任务上,性能能和传统Attention的模型持平,但推理成本(比如H800 GPU上的解码成本)却显著降低。
实际效果:DeepSeek-V3.2的落地价值
这套架构直接支撑了DeepSeek-V3.2的核心优势:
- 长上下文推理成本比前代(V3.1-Terminus)更低;
- 基础版在MMLU-Pro等推理任务上追平GPT-5,高计算变体(Speciale)甚至在IMO/IOI等竞赛中拿了金牌。
总结
DSA的本质,是用“轻量索引筛选+高效注意力计算”的组合,解决了长上下文大模型的“性能-效率”矛盾。这张架构图里的每个模块,都在围绕“少算但算对”这个目标设计——而这,正是开源大模型能追上闭源前沿的关键技术之一。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 5
5 0
0- 0



 已为社区贡献57条内容
已为社区贡献57条内容

所有评论(0)