AnySplat:基于无约束视图的前馈 3D 高斯散射
25年9月来自中科大、上海AI实验室、香港中文大学、布朗大学、上海交大和香港大学的论文“AnySplat: Feed-forward 3D Gaussian Splatting from Unconstrained Views”。AnySplat,是一种用于从未经标定的图像集合中合成新视角的正向馈送网络。与需要已知相机姿态和逐场景优化的传统神经渲染流程,以及在密集视角计算量下难以应对的最近正向馈送
25年9月来自中科大、上海AI实验室、香港中文大学、布朗大学、上海交大和香港大学的论文“AnySplat: Feed-forward 3D Gaussian Splatting from Unconstrained Views”。
AnySplat,是一种用于从未经标定的图像集合中合成新视角的正向馈送网络。与需要已知相机姿态和逐场景优化的传统神经渲染流程,以及在密集视角计算量下难以应对的最近正向馈送方法不同,本文模型只需一次前向传递即可预测所有信息。一次前向传递即可生成一组 3D 高斯图元,这些图元编码场景几何形状和外观,以及每张输入图像对应的相机内参和外参。这种统一的设计能够轻松扩展到无需任何姿态标注的随意拍摄多视角数据集。在大量的零样本评估中,AnySplat 在稀疏和密集视角场景下均达到与姿态感知基线相同的质量,同时超越现有的无姿态方法。此外,与基于优化的神经网络相比,它显著降低渲染延迟,使得在不受约束的拍摄环境下也能实现实时新视角合成。
AnySplat 是一种基于 Transformer 的神经网络,专为快速 3D 场景重建而设计,尤其适用于新视角合成。给定未经校准的图像(从单个视角到数百个视角),AnySplat 可以直接预测一组紧凑表示重建场景的 3D 高斯基元。
问题设置
考虑单个 3D 场景的 N 个未标定视图,以图像 {I_i} 的形式给出,其中 I_i 是图像。AnySplat 的目标是通过预测以下参数来联合重建场景的几何形状和外观:a) 一组 G 个各向异性 3D 高斯函数,其中每个高斯函数由中心位置 Θ、正不透明度 σ、方向四元数 ρ、各向异性尺度 σ 和颜色嵌入 c 参数化,颜色嵌入 c 由 k 阶球谐系数表示,遵循 [Kerbl et al. 2023] 的做法;以及 2) 每个视图的相机参数,其中 p_i 编码图像 I_i 的内参和外参。形式上,本文模型实现一个映射 f_𝜽。
在两个核心任务上评估模型:新视图合成和多视图相机位姿估计。值得注意的是,该流程还会生成一些有用的副产品——例如全局点图、逐帧深度图和相关的置信度分数——这些副产品可以支持各种下游应用。
流程
如图展示框架的整体流程。简而言之,模型首先将一组未经标定的多视图图像编码为高维特征表示,然后将其解码为 3D 高斯参数及其对应的相机位姿。为了应对密集视图下每个像素高斯分布的线性增长,引入一个可微分的体素化模块,该模块将图元聚类成体素,从而显著降低计算成本并促进更平滑的梯度流动。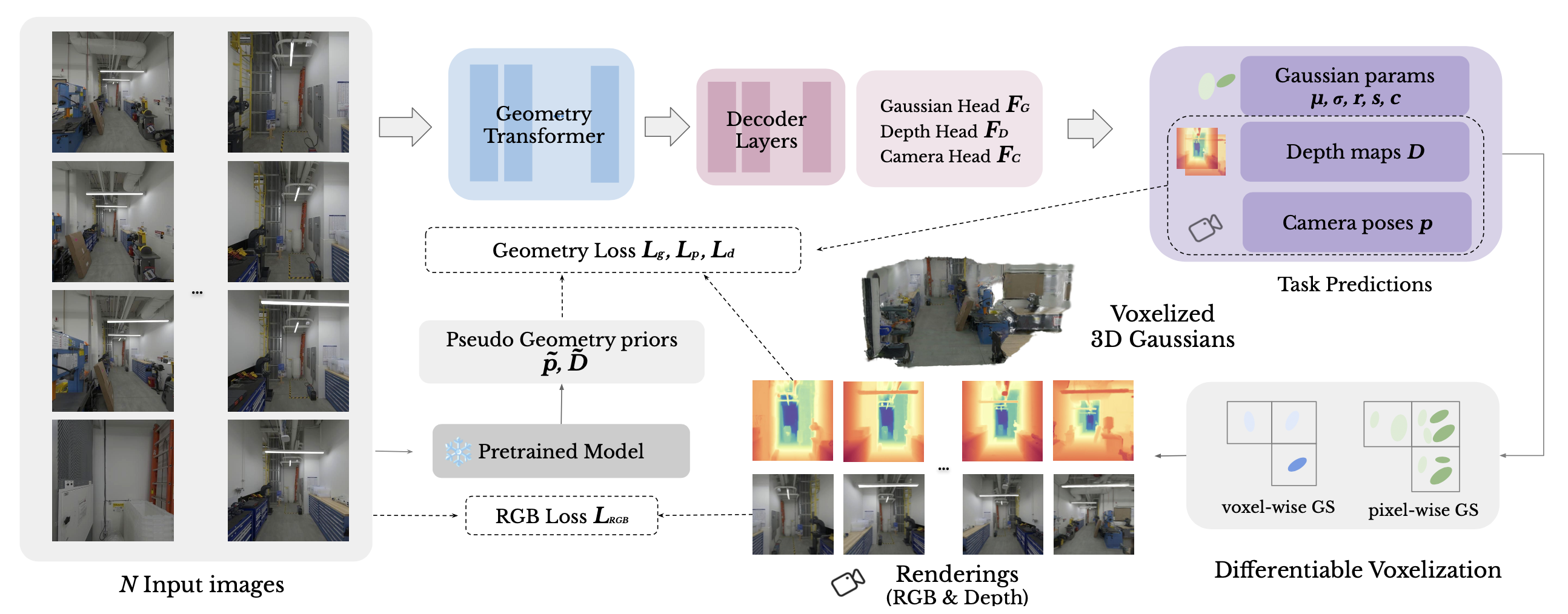
几何transformer。遵循 VGGT [Wang 2025a],首先使用 DINOv2 [Oquab et al. 2023] 将每幅图像 𝐼_i 分割成维度为 𝑑 的 𝑙_I = 𝐻 𝑊 /p2 个 tokens,其中 𝑝 = 14,𝑑 = 1024。对于每幅图像的 token 序列 𝑡𝐼_i,在其前面添加一个可学习的相机 token 𝑡g_𝑖 和四个配准 token tR_i;仅对于第一个视图,省略这些 token 的位置编码。来自所有 N 个视图的组合 token [tI_i; tg_i; tR_i] 由一个 L 层交替注意transformer处理:每一层对 token 应用帧注意,然后对所有视图联合应用全局注意。
相机姿态预测。相机姿态估计对于通过新视角渲染进行几何体重建至关重要。精细化的相机token 𝑡ˆg_i 被送入相机解码器 𝐹_𝐶,该解码器由四个额外的自注意层和一个线性投影头组成,用于预测每个相机参数 𝑝_𝑖。与之前的工作类似,将第一个相机姿态设置为恒等变换,并将所有剩余姿态表示在该共享的局部坐标系中。
像素级高斯参数预测。如上图所示,采用基于 DPT 解码器 [Ranftl et al. 2021] 的双头设计来预测所有高斯参数。深度头 F_D 接收图像 token 𝑡ˆ𝐼_i 并输出逐像素深度图 𝐷_𝑖(以及相应的置信度 𝐶𝐷_i);然后,这些深度图通过预测的相机位姿 𝑝_𝑖 进行反投影,从而得到每个高斯参数的中心 {𝝁_g}。高斯头 F 将 DPT 特征通过 F_d(𝑡ˆ𝐼) 与浅层 CNN 提取的外观特征 F_a(𝐼) 相结合,并将它们之和输入到最终回归 CNN F_𝑏 中,以预测不透明度 𝜎_𝑔、方向 𝒓_𝑔、尺度 𝒔_𝑔、SH 颜色系数 𝒄_𝑔 以及每个高斯的置信度 𝐶_𝑔。
可微分体素化。现有的前馈 3DGS 方法通常为每个像素分配一个高斯函数,这对于稀疏视图输入(2-16 张图像)有效,但一旦使用超过 32 个视图,就会面临规模化带来的复杂度问题。为了解决这个问题,基于 [Lu,2024b] 的方法进行改进。 引入一个可微分的体素化模块,该模块将高斯中心 {𝝁_g} 聚类成大小为 𝜖 的 𝑆 个体素。
为了保持体素化的可微性,每个高斯中心还预测一个置信度 𝐶_𝑔。通过 softmax 函数将这些分数转换为体素内权重。
最后,任何像素级高斯属性 𝑎_𝑔(例如,不透明度或颜色)都被聚合到其对应的体素中。
流程的输出由每个体素 𝑽 ∈ {1,…,𝑆} 的高斯属性 {𝝁_v, 𝜎_v, 𝒓_v, 𝒔_v, 𝒄_v}_s 参数化。可以使用可微高斯光栅化[Kerbl et al. 2023; Ye et al. 2025]高效地渲染模型预测的高斯分布。这种策略显著减少需要处理的基元数量,并实现了端到端学习。
训练与推理
几何一致性增强。同时预测深度图和相机位姿会引入一些微妙的歧义,这些歧义源于多视图的对齐和聚合:当将单幅图像的预测结果提升到 3D 空间时,这些不一致性会在重建的点云中表现为分层结构,这些结构在原始点云中可能不易察觉,但在渲染视图中却会变得非常明显。这种分层不仅会降低视觉保真度,还会使输出无法达到人类感知质量标准。为了缓解这个问题,引入一种几何一致性损失,它强制渲染外观与底层深度预测保持一致,从而有效地平滑这些分层结构并恢复连贯的表面几何形状。
具体来说,强制对齐从DPT头部FD获得的深度图𝐷_𝑖和从3DGaussians渲染的深度图𝐷ˆ_𝑖。由于𝐷_𝑖在复杂区域(例如天空或反射表面)可能不可靠,用联合学习的置信度图𝐶D_𝑖,并且仅对置信度最高的𝑁%像素应用监督,以确保监督集中在最可信的预测上。对齐两个深度图。
此外,在缺乏来自新视角监督的情况下,模型倾向于过拟合上下文视角,以避免来自不同视角的干扰。这导致泛化能力差,并导致深度和相机预测失败。为了缓解这个问题,用一个强大的预训练Transformer网络[Wang et al. 2025a]来提取相机参数和场景几何信息,以实现稳定的训练。具体来说,用损失函数 L_p 对相机参数进行正则化。
然后,用损失函数 L_d 提取几何信息。实验结果表明,这种提取损失显著提高训练稳定性,并有助于避免收敛到较差的局部最小值。
训练目标。为了避免输入数据中的噪声并更好地扩展数据规模,AnySplat 的训练无需任何 3D 监督,而是采用伪标签训练方法。具体来说,给定一组未调整姿态且未标定的多视图图像 {𝐼_i} 作为输入,本方法首先预测它们的相机内参和外参。这些预测的参数首先用于投影高斯基元的位置,然后渲染以生成最终输出 {𝐼ˆ_i}。需要注意的是,尽管模型仅使用上下文视图进行训练,而没有使用新视图,但由于提取函数和强大的场景建模能力,AnySplat 在新视图渲染方面表现出色。
最后,用一组未调整姿态的图像来优化模型。最小化以下损失函数:
L = L_rgb + 𝜆_2 · L_𝑔 + 𝜆_3 · L_𝑝 + 𝜆_4 · L_𝑑
其中
L_rgb = MSE(𝐼, 𝐼ˆ)+𝜆_1 · Perceptual(𝐼, 𝐼ˆ)
测试-时的相机姿态对齐(仅用于计算渲染指标)。在推理过程中,上下文视图 I_c 和目标视图 I_t 均作为输入,其中 I_c ∩ I_t = ∅。假设 I_c 的第一帧与 I_c ∪ I_t 的第一帧相同。因此,I_c 的旋转以及 I_c ∪ I_t 的上下文部分保持不变;唯一的区别在于它们的尺度。为了解决这个问题,计算 I_c 的平均上下文尺度因子 s 和 I_c ∪ I_t 的平均尺度因子 sˆ。然后,将目标尺度乘以比值 s /sˆ 进行归一化。
后优化(可选)。还包含一个可选的后优化阶段,以进一步改进重建结果,尤其是在输入密集的情况下。在 AnySplat 预测初始高斯分布和相机参数后,首先剪枝不透明度值较低(小于 0.01)的高斯分布,然后渲染输入相机视图中的图像,并计算渲染图像和输入图像之间的均方误差 (MSE) 损失和结构相似性 (SSIM) 损失。反向传播高斯分布和相机参数的梯度。学习率设置如下:位置为 1.6e-4,缩放为 5e-3,旋转为 1e-3,不透明度为 5e-2,颜色为 2.5e-3,相机姿态为 5e-3。
实验设置
数据集。遵循 CUT3R [Wang et al. 2025b] 和 DUST3R [Wang et al. 2024c] 的常用做法,用来自九个公开数据集的图像来训练模型:Hypersim [Roberts et al. 2021]、ARKitScenes [Baruch et al. 2021]、BlendedMVS [Yao et al. 2020]、ScanNet++ [Yeshwanth et al. 2023]、CO3D-v2 [Reizenstein et al. 2021]、Objaverse [Deitke et al. 2023]、Unreal4K [Tosi et al. 2021]、WildRGBD [Xia et al. 2024] 和 DL3DV [Ling et al. 2024]。这些数据集涵盖合成内容和真实世界内容、室内和室外场景,以及从物体到城市尺度的各种场景。这种多样化的数据构成使模型能够接触到广泛的几何和外观变化,从而增强其对未知场景的泛化能力。
训练视图采样策略。视图采样策略对于确保模型的鲁棒性至关重要。根据数据集类型应用三种不同的策略。对于以物体为中心的数据集,例如 CO3D-v2 [Reizenstein et al. 2021]、Objaverse [Deitke et al. 2023] 和 WildRGBD [Xia et al. 2024],在选定的捕获序列中随机采样视图。对于序列数据集,例如 ARK-itScenes [Baruch et al. 2021] 和 DL3DV [Ling et al. 2022],采用随机采样策略。对于[Roberts et al. 2024],首先定义最小和最大时间间隔,然后在此范围内随机选择一个值来确定首帧和末帧之间的间隔;随后从该间隔内随机采样视图。对于像 Hypersim [Roberts et al. 2021]、BlendedMVS [Yao et al. 2020]、ScanNet++ [Yeshwanth et al. 2023] 和 Unreal4K [Tosi et al. 2021] 这样的无序数据集,基于姿态距离对视图进行采样。具体来说,随机选择一个参考帧,计算所有其他帧到该参考帧的姿态距离,并基于预定义的距离阈值对视图进行采样。
实现细节。将交替注意transformer的层数设置为 L = 24,并使用来自 VGGT [Wang et al. 2025a] 的权重初始化几何transformer和深度 DPT 头,而其余层则随机初始化。在训练过程中,冻结图像块嵌入权重。该模型总共约有 8.86 亿个参数。为了实现可微分的体素化,将体素大小 ε 设置为 0.002。
用 AdamW 优化器训练模型 15000 次迭代。采用余弦学习率调度器,峰值学习率为 2e-4,并设置 1000 次迭代的预热阶段。对于从 VGGT 初始化的层,学习率乘以 0.1。在 16 个 NVIDIA A800 GPU 上训练 AnySplat 模型约两天。为了节省 GPU 内存并加速训练,使用 FlashAttention、bfloat16 精度和梯度检查点。为了保证训练的稳定性,在前 1000 次迭代后,如果总损失超过 0.2,会跳过相应的优化步骤。在每次迭代中,首先随机选择一个训练数据集,每个数据集都根据预定义的权重进行采样。从选定的数据集中,随机抽取 2 到 24 帧,同时保持每个 GPU 的抽样总数恒定为 24 帧。最大输入分辨率设置为长边 448 像素。宽高比在 0.5 到 1.0 之间随机变化。此外,应用固有增强,将每张图像随机中心裁剪至其原始尺寸的 77% 到 100%。图像还通过随机翻转进行增强。对于训练目标,设置 𝜆1 = 0.05,𝜆2 = 0.1,𝜆3 = 10.0,𝜆4 = 1.0。
基线。用先前最先进的无姿态前馈方法(包括 Flare [Zhang et al. 2025] 和 NoPoSplat [Ye et al. 2024])建立稀疏视图的新视图合成基线。对于每个评估数据集,为每个场景选择三个稀疏视图子集。值得注意的是,以往的方法需要在评估过程中进行后优化步骤,以将预测的相机位姿与真实值对齐。然而,这种方法经常失败——尤其是在训练视图重叠有限的情况下——甚至可能因为过拟合训练期间不可见的区域而降低性能。为了确保公平比较,提出一种更稳健的对齐策略:将第一个预测的相机固定为基准,并将所有其他预测的旋转变换到该参考坐标系中。对于平移对齐,计算相机距离的中值,并估计一个相对缩放因子来对齐预测的平移和真实值。对于提出的密集视图新视图合成基线方法,将其与 3D 高斯 Splatting [Kerbl et al. 2023] 和 Mip-Splatting [Yu et al. 2024a] 进行比较,后两者均使用 3 万次迭代进行训练。我们使用 32、48 和 64 个视角进行训练,并分别选择 4、6 和 8 个视角进行评估。训练和测试视角基于相机距离进行联合采样。由于 COLMAP [Schönberger 和 Frahm 2016] 在稀疏视图条件下通常不可靠,用 VGGT 来校准输入图像并生成用于初始化的点云。
评价指标。为了评估新视图合成的质量,计算预测图像与真实图像之间的 PSNR、SSIM [Wang 2004] 和 LPIPS [Zhang 2018] 值。此外,为了评估预测的相对图像位姿的准确性,用 AUC 指标,该指标衡量不同角度阈值下准确率曲线下的面积。在评估中,将阈值设置为 5、10、20 和 30。此外,为了评估多视图几何一致性,报告两个广泛使用的深度一致性指标:绝对平均相对误差 (AbsRel) 和 𝛿1 准确率,后者衡量的是像素百分比。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 19
19 0
0- 0



 已为社区贡献224条内容
已为社区贡献224条内容

所有评论(0)