AI导读AI论文: DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models
DeepSeek-V3.2是DeepSeek-AI推出的开源大语言模型,通过三大技术创新显著提升性能: DSA稀疏注意力将长文本计算复杂度从O(L²)降至O(Lk),保留128K上下文能力; 可扩展RL框架投入超预训练10%的计算量,使基础版推理性能比肩GPT-5,高计算变体DeepSeek-V3.2-Speciale在IMO/IOI等竞赛斩获金牌; 智能体任务合成生成1800+环境与8.5万+提
1. 一段话总结
DeepSeek-V3.2是DeepSeek-AI推出的开源大语言模型,核心突破在于通过DeepSeek Sparse Attention (DSA) 机制将长上下文场景下的计算复杂度从O(L2)O(L^2)O(L2)降至O(Lk)O(Lk)O(Lk)(k为选中token数),在保证性能的同时提升计算效率;依托可扩展强化学习(RL)框架(后训练计算量超预训练成本10%),其基础版在推理任务上与GPT-5表现相当,高计算变体DeepSeek-V3.2-Speciale更超越GPT-5,在2025年国际数学奥林匹克(IMO)、国际信息学奥林匹克(IOI)等竞赛中斩获金牌,推理能力比肩Gemini-3.0-Pro;此外,通过大规模智能体任务合成流水线(生成1800+个环境、85000+个复杂提示),模型在工具使用场景的泛化性与指令遵循能力显著提升,大幅缩小了开源模型与闭源前沿模型的性能差距,同时具备更低的推理成本(如H800 GPU上长序列解码成本低于DeepSeek-V3.1-Terminus)。
2. 思维导图(mindmap)
## DeepSeek-V3.2 核心概述
- 定位:平衡计算效率、推理能力与智能体性能的开源大模型
- 核心目标:缩小开源与闭源模型性能差距
## 一、关键技术突破
- 1. DeepSeek Sparse Attention (DSA)
- 组成:闪电索引器(计算I_{t,s},FP8实现,高效率)、细粒度token选择(Top-k选key-value)
- 优势:复杂度从O(L²)→O(Lk),保留长上下文性能
- 实例化:基于MLA的MQA模式(共享key-value跨查询头)
- 2. 可扩展RL框架
- 基础算法:Group Relative Policy Optimization (GRPO)
- 改进策略:无偏KL估计、离策略序列掩码、保持MoE路由、保持采样掩码
- 计算投入:后训练成本超预训练10%
- 3. 大规模智能体任务合成
- 任务类型:代码智能体(24667任务)、搜索智能体(50275任务)等(表1)
- 流程:冷启动(统一推理与工具使用)→合成环境/提示→RL训练
- 上下文管理:仅新用户消息丢弃历史推理,保留工具调用记录
## 二、模型训练流程
- 1. 持续预训练(基于DeepSeek-V3.1-Terminus)
- 密集热身阶段:冻结主模型,训练索引器(1000步,2.1B token,KL损失)
- 稀疏训练阶段:优化全参数(15000步,943.7B token,选2048个key-value/token)
- 2. 后训练
- 专家蒸馏:6个领域(数学、编程等) specialist模型→生成领域数据
- 混合RL训练:融合推理、智能体、人类对齐训练,规避灾难性遗忘
- 3. 变体优化(DeepSeek-V3.2-Speciale)
- 训练调整:仅用推理数据,降低长度惩罚,融入DeepSeekMath-V2方法
- 定位:突破长度限制,冲击推理极限
## 三、性能评估
- 1. 基础版(DeepSeek-V3.2)
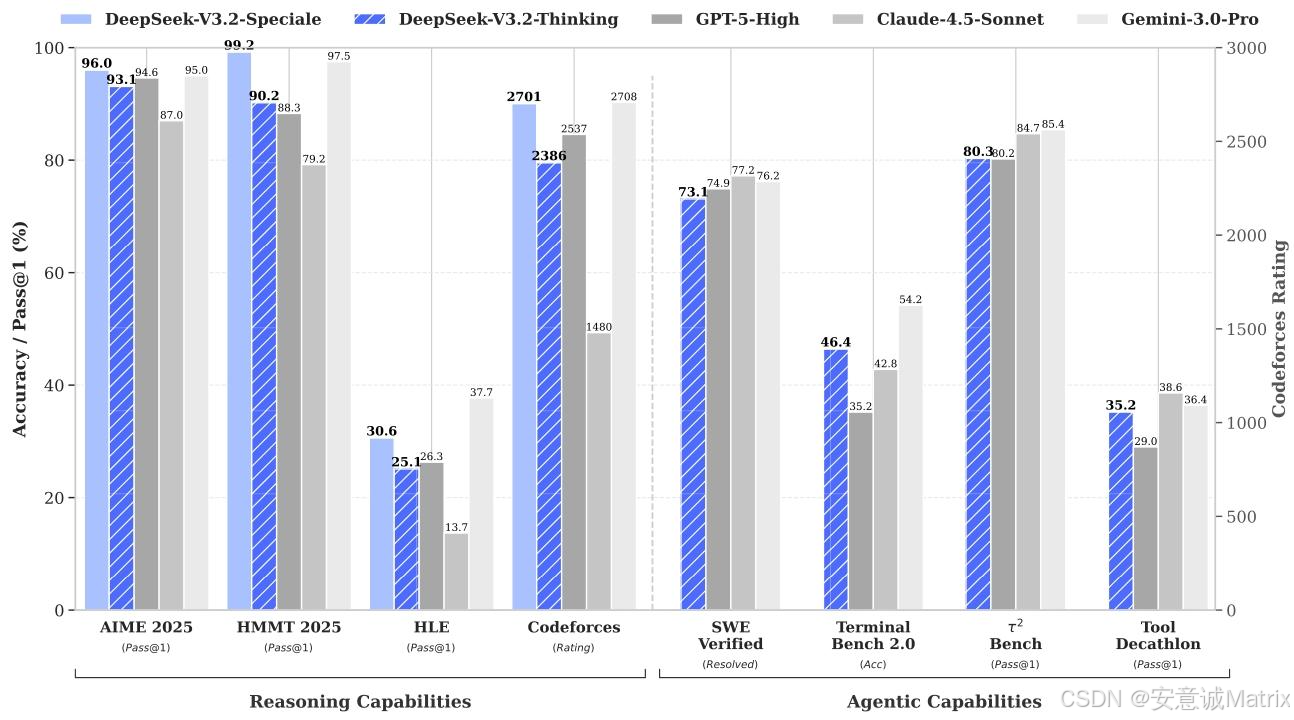
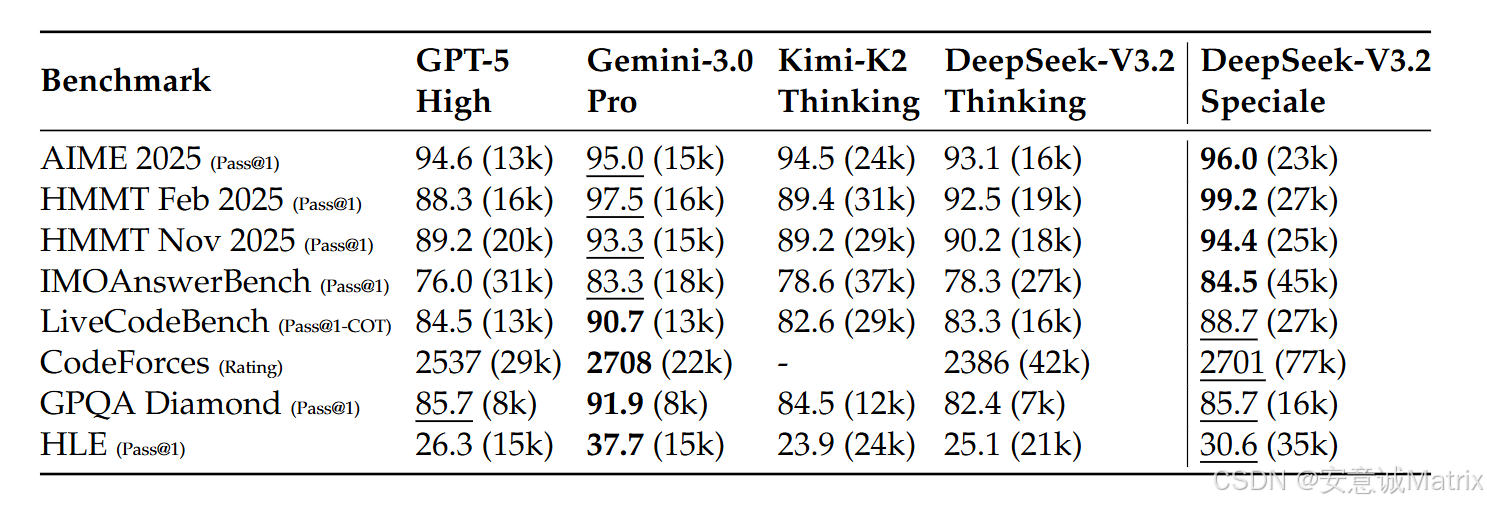
- 推理任务:MMLU-Pro 85.0、AIME 2025 93.1、LiveCodeBench 83.3
- 智能体任务:BrowseCompZh 65.0、Tool-Decathlon 35.2
- 效率:H800 GPU长序列解码成本低于V3.1-Terminus
- 2. 高计算变体(Speciale)
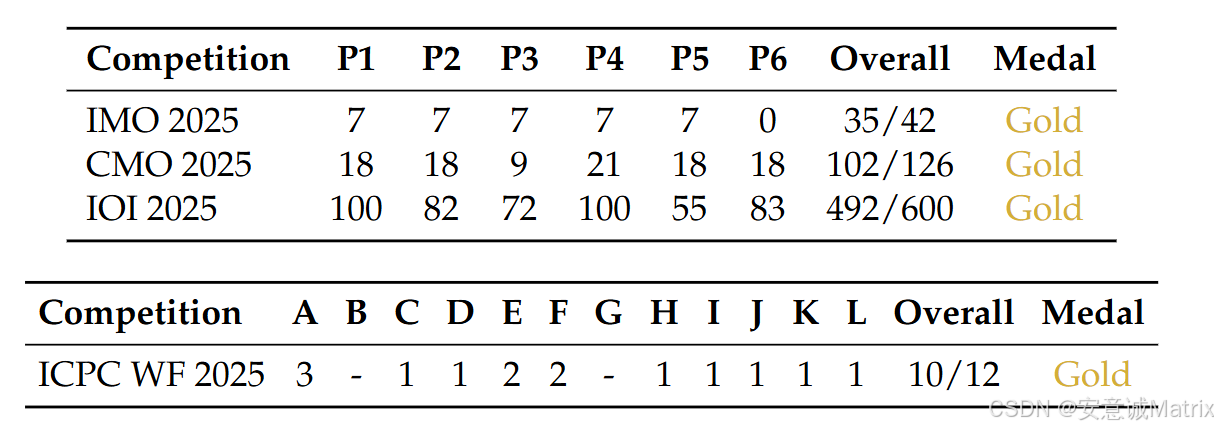
- 竞赛表现:IMO 35/42(金牌)、IOI 492/600(金牌)、ICPC WF 10/12(金牌)
- 基准测试:HMMT Feb 2025 99.2、Codeforces Rating 2701(比肩Gemini-3.0-Pro)
- 3. 消融实验
- 合成任务:RL训练后Tau2Bench、MCP-Mark性能显著提升
- 上下文管理:Discard-all策略使BrowseComp得分达67.6
## 四、局限性与未来方向
- 局限性:世界知识广度滞后(预训练FLOPs不足)、token效率低(需更长轨迹)、复杂任务弱于闭源模型
- 未来方向:扩大预训练计算、优化推理链智能密度、改进基础模型与后训练流程
3. 详细总结
1. 引言:开源模型的核心挑战与解决方案
当前开源大模型与闭源模型(如GPT-5、Gemini-3.0-Pro)的性能差距持续扩大,核心瓶颈在于三点:
- 架构效率:传统vanilla attention在长序列场景计算复杂度过高,限制部署与后训练;
- 资源投入:后训练阶段计算量不足,难以支撑复杂任务性能;
- 智能体能力:工具使用场景的泛化性与指令遵循能力弱于闭源模型。
DeepSeek-V3.2通过DSA机制、可扩展RL框架、大规模智能体任务合成三大方案针对性解决上述问题。
2. 模型架构:DSA与效率优化
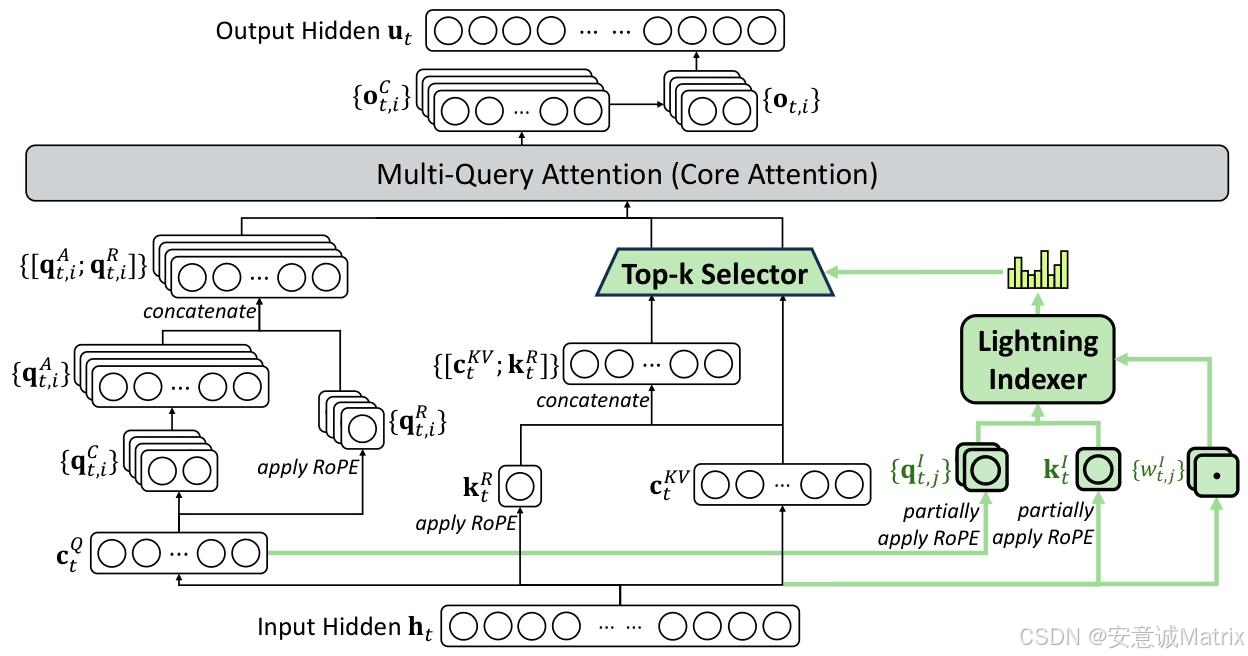
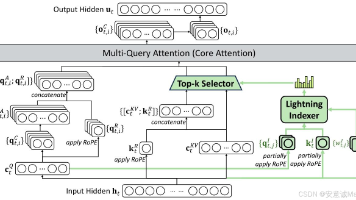
2.1 DeepSeek Sparse Attention (DSA)
DSA是核心架构创新,旨在平衡效率与长上下文性能,结构分为两部分:
- 闪电索引器:计算查询token hth_tht 与前文token hsh_shs 的索引得分 It,sI_{t,s}It,s(公式见文档),采用少量头(H^I)与FP8精度,计算效率极高;
- 细粒度token选择:基于Top-k索引得分筛选key-value对,仅用选中的csc_scs计算注意力输出utu_tut,将核心注意力复杂度从O(L2)O(L^2)O(L2)降至O(Lk)O(Lk)O(Lk)(k≪L)。
DSA基于MLA(Multi-Latent Attention)的MQA模式实例化,确保key-value跨查询头共享,进一步提升效率。
2.2 持续预训练
以DeepSeek-V3.1-Terminus(128K上下文)为基础,分两阶段训练:
| 训练阶段 | 目标 | 参数设置 | 数据量 |
|---|---|---|---|
| 密集热身阶段 | 初始化闪电索引器 | 冻结主模型,学习率1e-3,KL损失对齐注意力分布 | 1000步,2.1B token |
| 稀疏训练阶段 | 适配稀疏注意力模式 | 优化全参数,学习率7.3e-6,选2048个key-value/token | 15000步,943.7B token |
2.3 性能与成本验证
- Parity评估:在短/长上下文任务上与DeepSeek-V3.1-Terminus性能持平,AA-LCR推理模式得分高4分,Fiction.liveBench多指标领先;
- 推理成本:H800 GPU上,长序列(128K)解码成本显著低于V3.1-Terminus(图3),短序列通过掩码MHA模式进一步优化效率。
3. 后训练:强化学习与专家蒸馏
3.1 专家蒸馏
为6个核心领域构建specialist模型(均基于V3.2基础 checkpoint微调),覆盖数学、编程、通用推理、智能体任务(编码/搜索)等,支持“思考模式”(长推理链)与“非思考模式”(直接响应)。训练后,基于蒸馏数据的模型性能仅略低于specialist,且通过后续RL可消除差距。
3.2 混合RL训练(GRPO优化)
采用GRPO算法,将推理、智能体、人类对齐训练融合为单阶段,规避多阶段训练的灾难性遗忘。关键改进策略包括:
- 无偏KL估计:修正K3估计器,消除梯度偏差,稳定训练;
- 离策略序列掩码:过滤KL散度超阈值的负优势序列,减少误导性更新;
- 保持MoE路由:固定推理阶段的专家路由路径,避免训练-推理不一致;
- 保持采样掩码:复用预训练阶段的top-p/top-k掩码,确保动作空间一致。
3.3 高计算变体:DeepSeek-V3.2-Speciale
- 训练调整:仅用推理数据,降低长度惩罚,融入DeepSeekMath-V2的数学证明方法;
- 核心优势:在高难度竞赛中斩获金牌,基准测试性能超越GPT-5,比肩Gemini-3.0-Pro;
- 不足:token效率低(如Codeforces推理需77k token,高于Gemini-3.0-Pro的22k)。
4. 智能体能力:任务合成与上下文管理
4.1 思考上下文管理
针对工具调用场景优化上下文利用:
- 仅当新用户消息加入时,丢弃历史推理内容;若仅追加工具输出,保留推理记录;
- 始终保留工具调用与结果历史,避免重复推理,提升token效率。
4.2 冷启动与大规模任务合成
- 冷启动:通过设计系统提示,让模型在推理过程中嵌入工具调用,实现“推理-工具”协同的初始数据积累;
- 大规模任务:生成1800+个环境、85000+个提示,覆盖代码(24667任务)、搜索(50275任务)、通用智能体(4417任务)等,支持RL训练的泛化性提升。
4.3 搜索智能体的上下文扩展
针对128K上下文限制,提出三种测试时扩展策略(图6):
| 策略 | 原理 | BrowseComp得分 | 效率优势 |
|---|---|---|---|
| Summary | 总结溢出轨迹,重新启动推理 | 60.2 | 步骤从140→364,效率低 |
| Discard-75% | 丢弃前75%工具历史 | - | 平衡效率与性能 |
| Discard-all | 重置工具历史,保留用户指令 | 67.6 | 效率高,接近并行基线 |
| Parallel-fewest-step | 采样N条轨迹,选最短路径 | - | 性能优但计算成本高 |
5. 性能评估结果(核心数据)
| 任务类型 | 基准测试 | DeepSeek-V3.2 | GPT-5 High | Gemini-3.0-Pro | 备注 |
|---|---|---|---|---|---|
| 推理 | MMLU-Pro (EM) | 85.0 | 87.5 | 90.1 | 开源模型领先 |
| 数学 | AIME 2025 (Pass@1) | 93.1 | 94.6 | 95.0 | Speciale达96.0 |
| 编程 | Codeforces (Rating) | 2386 | 2537 | 2708 | Speciale达2701 |
| 智能体(中文) | BrowseCompZh (Pass@1) | 65.0 | 63.0 | - | 超越GPT-5 |
| 工具使用 | Tool-Decathlon (Pass@1) | 35.2 | 29.0 | 36.4 | 接近Gemini-3.0-Pro |
6. 局限性与未来方向
- 当前局限:1. 世界知识广度滞后(预训练FLOPs少于闭源模型);2. token效率低(需更长推理链);3. 复杂任务性能仍弱于Gemini-3.0-Pro;
- 未来计划:1. 扩大预训练计算量,弥补知识差距;2. 优化推理链“智能密度”,提升token效率;3. 改进基础模型与后训练流程,强化复杂任务能力。
4. 关键问题与答案
问题1:DeepSeek-V3.2在架构上的核心创新是什么?该创新如何平衡长上下文场景的计算效率与模型性能?
答案:核心创新是DeepSeek Sparse Attention (DSA) 机制,通过“闪电索引器+细粒度token选择”实现效率与性能的平衡:
- 闪电索引器:采用少量注意力头(H^I)与FP8精度计算查询token与前文token的索引得分It,sI_{t,s}It,s,计算成本远低于传统attention,同时通过ReLU激活与KL损失对齐主注意力分布,确保索引准确性;
- 细粒度token选择:仅保留Top-k索引得分对应的key-value对(k=2048),将核心注意力计算复杂度从O(L2)O(L^2)O(L2)降至O(Lk)O(Lk)O(Lk)(k≪L,如L=128K时,k=2048可大幅减少计算量);
- 性能保障:通过两阶段持续预训练(密集热身初始化索引器,稀疏训练适配全模型),DSA在长上下文任务(如AA-LCR、Fiction.liveBench)上性能不低于传统attention的DeepSeek-V3.1-Terminus,同时H800 GPU推理成本显著降低(如128K序列解码成本低于V3.1-Terminus)。
问题2:DeepSeek-V3.2-Speciale作为高计算变体,在关键竞赛与基准测试中表现如何?与闭源前沿模型(如Gemini-3.0-Pro)相比,其核心优势与不足是什么?
答案:
- 竞赛表现:在2025年顶级竞赛中均获金牌,具体为:
- IMO(数学):35/42分(满分42);
- IOI(信息学):492/600分,排名第10;
- ICPC世界总决赛(编程):解决10/12题,排名第2;
- CMO(中国数学奥赛):102/126分(满分126)。
- 基准测试表现:
- 数学:HMMT Feb 2025 Pass@1达99.2%(超越Gemini-3.0-Pro的97.5%);
- 编程:Codeforces Rating 2701(与Gemini-3.0-Pro的2708接近);
- 推理:AIME 2025 Pass@1 96.0%(超越GPT-5的94.6%)。
- 优势与不足:
- 优势:作为开源模型,首次在顶级竞赛中达到闭源模型(Gemini-3.0-Pro)的推理水平,打破闭源模型在高难度任务中的垄断;
- 不足:token效率低,如Codeforces推理需77k token(Gemini-3.0-Pro仅22k),部署成本与 latency 更高。
问题3:为提升工具使用场景的智能体能力,DeepSeek-V3.2设计了哪些大规模任务合成策略?这些策略如何解决开源模型在智能体泛化性与指令遵循上的短板?
答案:核心策略是“冷启动+大规模环境/提示合成+针对性RL训练”,具体如下:
- 冷启动策略:通过差异化系统提示,让模型在推理过程中嵌入工具调用(如编程任务中,用标签包裹推理链,同时调用代码执行工具),实现“推理-工具”协同的初始数据积累,为后续RL提供基础轨迹;
- 大规模任务合成:生成1800+个任务环境与85000+个复杂提示,覆盖三类核心场景:
- 真实环境任务:如代码智能体(24667个GitHub issue-PR对,构建可执行验证环境)、搜索智能体(50275个基于真实搜索API的任务);
- 合成环境任务:如通用智能体(4417个自定义工具场景,如行程规划),确保任务难度“易验证、难解决”;
- RL训练适配:将合成任务数据用于混合RL训练(GRPO算法),同时通过“思考上下文管理”(仅丢弃新用户消息的历史推理)减少无效计算,提升指令遵循准确性。
解决短板的逻辑:开源模型的泛化性短板源于训练数据场景单一,而大规模合成任务覆盖真实/合成环境、多语言/多领域,使RL训练能学习到通用工具使用逻辑;同时,冷启动与上下文管理确保模型能稳定遵循“推理-工具-响应”的指令流程,避免工具调用与任务目标脱节。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 4
4 0
0- 0



 已为社区贡献57条内容
已为社区贡献57条内容

所有评论(0)