【GitHub开源AI精选】LLaVA-OneVision-1.5:面向多模态训练大众化的全开源框架
LLaVA-OneVision-1.5 是由 EvolvingLMMS-Lab 开发的全开源多模态框架,旨在通过高效训练和高质量数据实现多模态任务的高性能和低成本。该模型采用自研的 RICE-ViT 作为视觉编码器,结合 2D 旋转位置编码和区域感知注意力机制,支持可变输入分辨率。基于 Qwen3 的语言模型,通过三阶段训练流程(语言–图像对齐、高质量知识中期预训练和视觉指令对齐)进行优化。它在多
系列篇章💥
目录
前言
随着人工智能技术的飞速发展,多模态模型逐渐成为研究热点。LLaVA-OneVision-1.5 作为一款开源的多模态模型,通过高效训练和高质量数据实现了高性能、低成本和强复现性。它不仅在多模态任务中表现出色,还为社区提供了完整的代码、数据和模型资源,助力低成本复现和拓展。
一、项目概述
LLaVA-OneVision-1.5 是由 EvolvingLMMS-Lab 开发的全开源多模态框架,旨在通过高效训练和高质量数据实现多模态任务的高性能和低成本。该模型采用自研的 RICE-ViT 作为视觉编码器,结合 2D 旋转位置编码和区域感知注意力机制,支持可变输入分辨率。基于 Qwen3 的语言模型,通过三阶段训练流程(语言–图像对齐、高质量知识中期预训练和视觉指令对齐)进行优化。它在多模态基准测试中表现出色,成本可控,且全链条透明开放。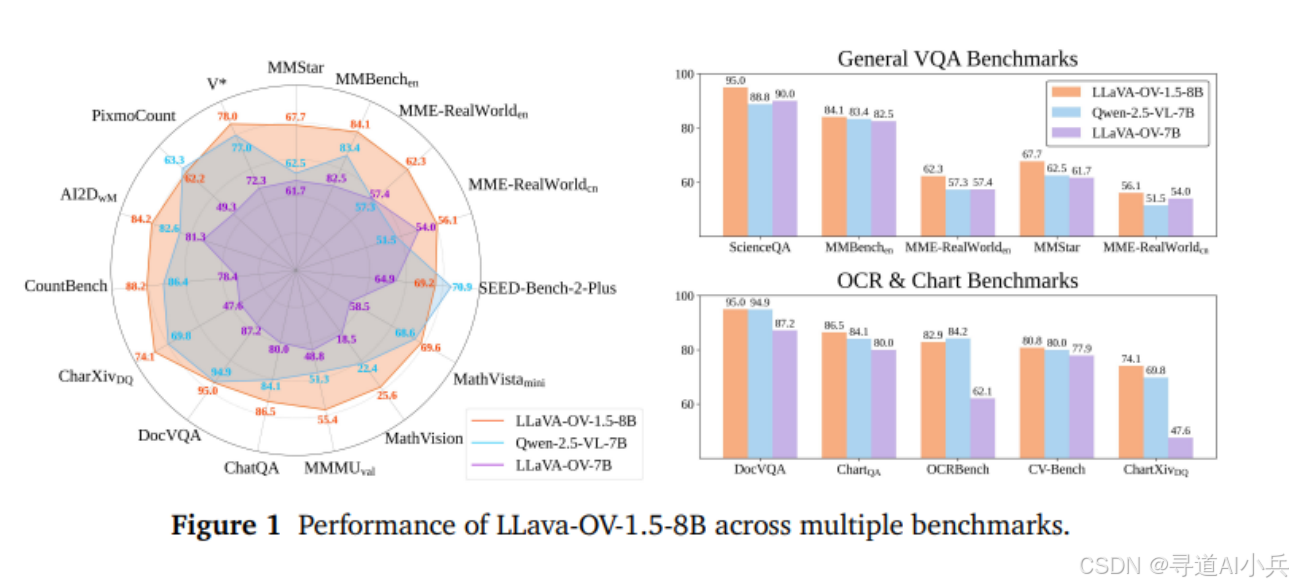
二、核心功能
(一)多模态理解与生成
LLaVA-OneVision-1.5 能够处理和理解图像、文本等多种模态的信息,并生成高质量的文本描述、回答问题或进行推理。这种能力使其在多模态任务中表现出色,能够为用户提供丰富的信息交互体验。例如,用户可以上传一张图片,模型不仅能识别其中的物体,还能生成详细的描述文本,帮助用户更好地理解图片内容。
(二)视觉问答(VQA)
该模型支持视觉问答功能,能够针对图像中的内容回答各种问题。它支持广泛的视觉任务,如物体识别、场景理解等。用户可以上传一张图片并提出问题,模型会根据图片内容给出准确的答案。这种功能在教育、智能客服等领域具有广泛的应用前景。
(三)图像描述生成
LLaVA-OneVision-1.5 可以为输入的图像生成准确且富有细节的描述文本。这一功能不仅能够帮助用户快速了解图像内容,还能为内容创作者提供创意灵感。例如,用户可以上传一张风景图片,模型会生成一段生动的描述,用户可以根据这段描述进一步创作诗歌或故事。
(四)指令遵循与执行
LLaVA-OneVision-1.5 具有良好的指令遵循能力,能够根据用户提供的指令执行相应的任务。无论是图像编辑、信息提取还是其他复杂的任务,模型都能准确理解并执行。这种能力使得模型在自动化任务处理方面具有很高的效率和准确性。
(五)跨模态检索
该模型支持基于文本查询图像或基于图像查询文本的跨模态检索功能。用户可以通过输入一段文本描述来查找相关的图像,或者上传一张图片来查找相关的文本信息。这种功能在信息检索和内容推荐领域具有重要的应用价值。
(六)长尾识别能力
LLaVA-OneVision-1.5 对数据中出现频率较低的类别或概念也能进行有效识别和理解。这种长尾识别能力使得模型在处理复杂多样的数据时更加鲁棒,能够更好地适应各种实际应用场景。例如,在医疗影像分析中,模型能够识别一些罕见疾病的特征,为医生提供辅助诊断。
(七)多语言支持
LLaVA-OneVision-1.5 支持多种语言的输入和输出,具备一定的跨语言理解和生成能力。这使得模型能够在全球范围内为不同语言的用户提供服务,极大地扩展了其应用范围。例如,用户可以用中文提问,模型可以用英文回答,或者反之。
(八)知识增强
LLaVA-OneVision-1.5 通过高质量的知识数据进行预训练,使模型具备更丰富的世界知识。这种知识增强能力使得模型在处理复杂的多模态任务时能够提供更准确、更有深度的答案。例如,在回答关于历史事件的问题时,模型能够结合丰富的历史知识给出详细的解释。
(九)高效训练与复现
LLaVA-OneVision-1.5 采用优化的训练策略和数据打包技术,实现高效的训练过程。同时,它提供了完整的代码、数据和模型资源,方便社区低成本复现和拓展。这种高效性和开放性使得模型能够快速迭代和优化,为研究人员和开发者提供了极大的便利。
三、技术揭秘
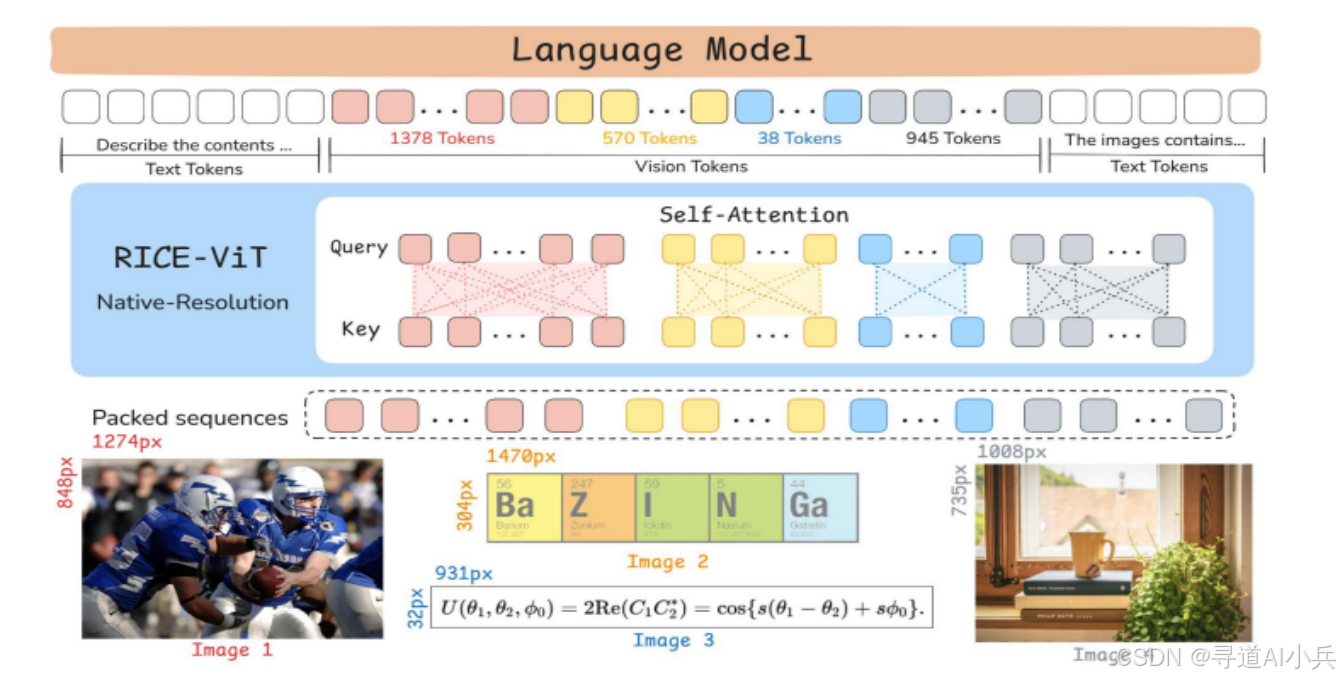
(一)视觉编码器
LLaVA-OneVision-1.5 采用自研的 RICE-ViT(Region-aware Cluster Discrimination Vision Transformer)作为视觉编码器。该编码器通过区域感知注意力机制和统一的区域簇判别损失,增强对图像中局部区域的语义理解。它还支持可变输入分辨率,使模型能够灵活处理不同尺寸的图像,从而提高其在多模态任务中的表现。
(二)投影器设计
为了实现视觉特征与语言特征的有效对齐,LLaVA-OneVision-1.5 使用多层感知机(MLP)作为投影器。该投影器将视觉特征映射到语言模型的文本嵌入空间,确保两种模态的特征在同一个空间中进行交互。这种设计不仅提高了特征对齐的准确性,还增强了模型的多模态融合能力。
(三)语言模型
LLaVA-OneVision-1.5 的语言模型基于 Qwen3,这是一个强大的语言生成和理解模型。Qwen3 提供了高质量的语言生成能力,支持多模态任务中的文本处理。通过结合视觉编码器的输出,语言模型能够生成与图像内容相关的文本描述,从而实现多模态任务的无缝交互。
(四)三阶段训练流程
LLaVA-OneVision-1.5 采用三阶段训练流程,逐步提升模型的多模态对齐能力和任务泛化能力。第一阶段是语言–图像对齐,通过大规模的预训练数据对齐语言和视觉模态。第二阶段是高质量知识中期预训练,进一步提升模型的知识水平。第三阶段是视觉指令对齐,通过指令微调数据增强模型的指令遵循能力。
(五)离线并行数据打包
为了提高训练效率,LLaVA-OneVision-1.5 采用离线并行数据打包技术。通过特征驱动的“概念均衡”策略构建预训练数据集,减少 padding 浪费,提高训练效率。这种数据打包方法不仅优化了数据的使用,还显著降低了训练成本。
(六)混合并行与长上下文优化
在训练过程中,LLaVA-OneVision-1.5 采用混合并行(张量并行、流水并行和序列并行)以及长上下文优化技术。这些技术提升了算力利用效率和显存效率,使得模型能够在大规模数据上高效训练。通过这些优化,模型能够处理更长的序列,从而提高其在复杂任务中的表现。
(七)数据构建与优化
LLaVA-OneVision-1.5 构建了大规模的预训练数据集和指令微调数据集。预训练数据集采用“概念均衡”策略,确保数据的多样性和高质量。指令微调数据集覆盖了多种任务类别,通过多源聚合和格式统一,确保数据的高质量和多样性。这些数据集为模型的训练提供了坚实的基础,使其在多模态任务中表现出色。
四、基准评测
LLaVA-OneVision-1.5 在多个基准测试中优于 Qwen2.5-VL。例如,在 MathVista mini、WeMath、MathVision、MMMU val、MMMU-Pro standard 和 MMMU-Pro vision 等任务中,LLaVA-OneVision-1.5-4B 均表现优于 Qwen2.5-VL-3B。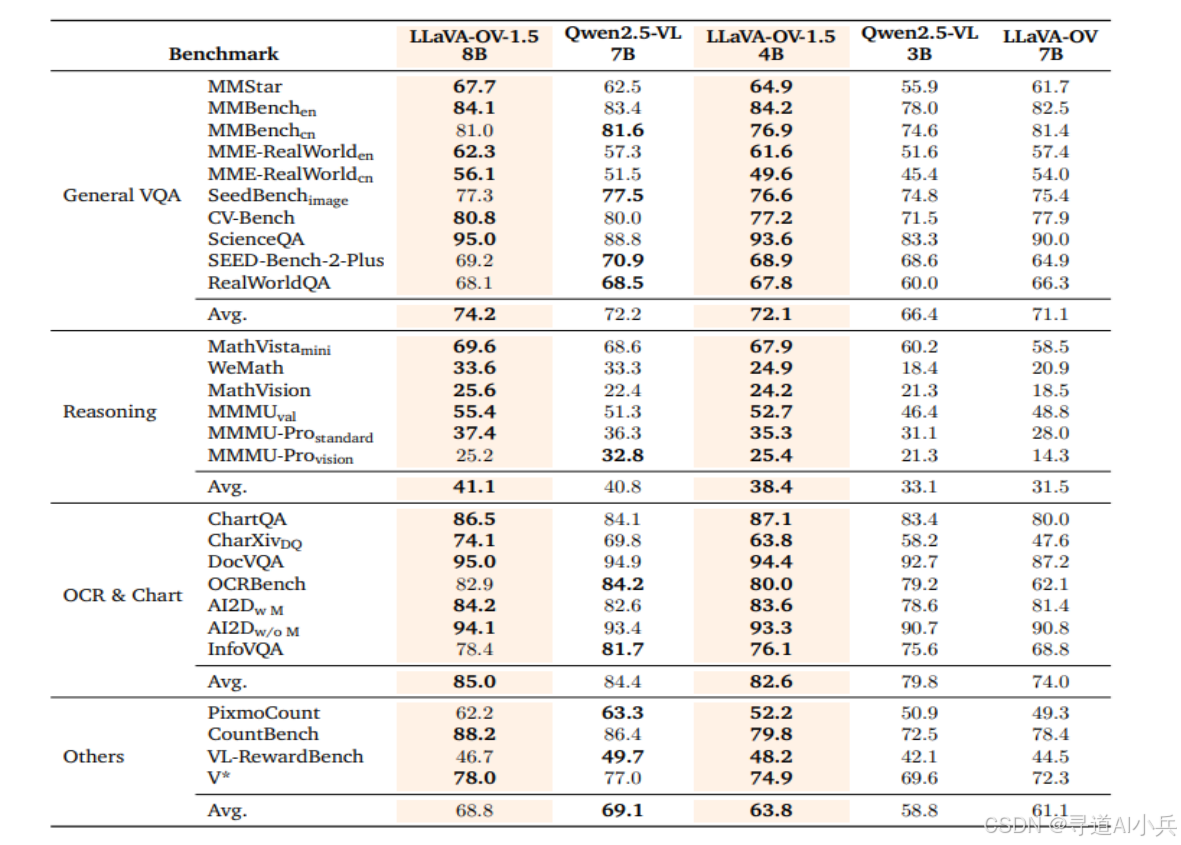
五、应用场景
(一)智能客服
LLaVA-OneVision-1.5 可广泛应用于智能客服领域。用户可上传图像或输入文本问题,模型快速理解并提供准确回答。例如,用户上传商品图片询问价格,模型能识别商品并给出详细信息。这不仅提升客服效率,还能改善用户体验,降低人力成本,适用于电商、金融等行业。
(二)内容创作
该模型为内容创作者提供强大支持。它能根据图像生成生动描述或创意文案,激发创作灵感。比如,输入一张风景照,模型生成诗意描述,创作者可据此撰写故事或诗歌。此外,它还能辅助视频脚本创作,根据分镜头草图生成详细脚本,提高创作效率和质量。
(三)教育辅助
在教育领域,LLaVA-OneVision-1.5 有诸多应用。教师可上传教学图片,模型生成详细解释,帮助学生理解复杂概念。例如,展示人体骨骼图,模型生成骨骼名称和功能描述。它还能根据教学大纲生成练习题和答案,减轻教师备课负担,提升教学互动性和趣味性。
(四)医疗影像分析
LLaVA-OneVision-1.5 能辅助医生解读医学影像,提供初步诊断建议。例如,上传 X 光片,模型识别异常并生成报告,指出可能疾病。它还能分析病理切片图像,辅助病理学家发现病变。这有助于提高诊断效率和准确性,尤其在偏远地区或资源紧张的医院,可快速提供初步诊断,为患者争取治疗时间。
(五)智能驾驶
在智能驾驶系统中,LLaVA-OneVision-1.5 可理解道路场景,辅助决策。例如,识别交通标志、行人和障碍物,为自动驾驶车辆提供实时信息。它还能分析复杂路况,预测其他车辆行为,帮助车辆提前做出安全决策。这不仅提升驾驶安全性,还能优化驾驶路线,提高交通效率。
(六)图像编辑与设计
LLaVA-OneVision-1.5 为图像编辑和设计带来便利。用户可上传图像并输入指令,如“将照片背景替换为海滩”,模型自动完成编辑。它还能根据设计需求生成创意元素,如为海报添加特效文字。这降低了图像处理门槛,使非专业用户也能轻松完成高质量设计,广泛应用于广告、媒体等行业。
六、快速使用
使用 Hugging Face 快速启动示例:
from transformers import AutoTokenizer, AutoProcessor, AutoModelForCausalLM
from qwen_vl_utils import process_vision_info
model_path = "lmms-lab/LLaVA-OneVision-1.5-8B-Instruct"
# default: Load the model on the available device(s)
model = AutoModelForCausalLM.from_pretrained(
model_path, torch_dtype="auto", device_map="auto", trust_remote_code=True
)
# default processor
processor = AutoProcessor.from_pretrained(model_path, trust_remote_code=True)
messages = [
{
"role": "user",
"content": [
{
"type": "image",
"image": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-VL/assets/demo.jpeg",
},
{"type": "text", "text": "Describe this image."},
],
}
]
# Preparation for inference
text = processor.apply_chat_template(
messages, tokenize=False, add_generation_prompt=True
)
image_inputs, video_inputs = process_vision_info(messages)
inputs = processor(
text=[text],
images=image_inputs,
videos=video_inputs,
padding=True,
return_tensors="pt",
)
inputs = inputs.to("cuda")
# Inference: Generation of the output
generated_ids = model.generate(**inputs, max_new_tokens=1024)
generated_ids_trimmed = [
out_ids[len(in_ids) :] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)
]
output_text = processor.batch_decode(
generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False
)
print(output_text)
七、结语
LLaVA-OneVision-1.5 作为一款开源的多模态模型,不仅在技术上实现了创新,还通过高效的训练策略和高质量的数据构建,为多模态任务提供了强大的支持。它为社区提供了完整的代码、数据和模型资源,助力低成本复现和拓展。希望本文能够帮助读者更好地了解 LLaVA-OneVision-1.5 的技术细节和应用场景。
项目地址
- Github 地址:https://github.com/EvolvingLMMs-Lab/LLaVA-OneVision-1.5
- HuggingFace 模型库:https://huggingface.co/collections/lmms-lab/llava-onevision-15-68d385fe73b50bd22de23713
- arXiv 技术论文:https://arxiv.org/pdf/2509.23661
- 在线体验 Demo:https://huggingface.co/spaces/lmms-lab/LLaVA-OneVision-1.5

🎯🔖更多专栏系列文章:AI大模型提示工程完全指南、AI大模型探索之路(零基础入门)、AI大模型预训练微调进阶、AI大模型开源精选实践、AI大模型RAG应用探索实践🔥🔥🔥 其他专栏可以查看博客主页📑
😎 作者介绍:资深程序老猿,从业10年+、互联网系统架构师,目前专注于AIGC的探索(CSDN博客之星|AIGC领域优质创作者)
📖专属社群:欢迎关注【小兵的AI视界】公众号或扫描下方👇二维码,回复‘入群’ 即刻上车,获取邀请链接。
💘领取三大专属福利:1️⃣免费赠送AI+编程📚500本,2️⃣AI技术教程副业资料1套,3️⃣DeepSeek资料教程1套🔥(限前500人)
如果文章内容对您有所触动,别忘了点赞、⭐关注,收藏!加入我们,一起携手同行AI的探索之旅,开启智能时代的大门!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 23
23 0
0- 0



 已为社区贡献47条内容
已为社区贡献47条内容

所有评论(0)