【强烈推荐】Langchain+RAG+MCP:打造自主操作Jira的AI智能体(附完整代码)
首先,我们需要定义智能体的状态结构。使用 Langchain v1.0 的 TypedDict 和状态合并机制,我们可以清晰地管理智能体在处理任务过程中的状态变化。"""智能体状态定义messages: 对话历史记录user_query: 用户原始查询jira_issue_key: Jira 任务键retrieved_docs: 从 RAG 检索到的文档current_step: 当前执行步骤mc
本文详细介绍基于Langchain v1.0、RAG和MCP Server构建的Jira智能体系统,采用三层架构(感知层RAG知识库、决策层Langchain、执行层MCP Server)实现项目上下文理解与Jira自主操作。内容涵盖环境搭建、核心代码实现、API集成、工作流程演示及性能优化,旨在将开发者从繁琐任务管理中解放,提升开发效率,是学习大模型应用落地的实战指南。

技术背景与痛点分析
在当今快节奏的软件开发环境中,Jira 作为项目管理工具的核心地位毋庸置疑。然而,传统的 Jira 操作方式往往伴随着诸多痛点。根据 Atlassian 官方数据,开发团队平均每天要花费 2-3 小时在 Jira 任务的创建、分配、状态更新等重复性工作上。这些工作不仅占用了开发者大量宝贵的编码时间,还容易因人为操作失误导致任务信息不准确、状态更新不及时等问题。
更严重的是,项目信息通常分散在 Jira、Confluence、Git 等多个系统中,开发者需要在不同平台间频繁切换才能获取完整上下文。例如,当需要创建一个新的 Jira 任务时,可能需要查阅 Confluence 中的需求文档、Git 中的代码提交记录,以及过往类似任务的处理方式,这个过程往往耗时且低效。
随着大语言模型技术的快速发展,AI 智能体为解决这些问题提供了新的可能。通过将 Langchain v1.0 与 RAG(检索增强生成)和 MCP Server(模型上下文协议服务器)相结合,我们可以打造一个真正理解项目上下文、能够自主操作 Jira 的智能体,从而将开发者从繁琐的任务管理工作中解放出来,专注于更有价值的创造性工作。
核心架构设计
我们的 Jira 智能体系统采用了三层架构设计,通过 Langchain v1.0 将 RAG 知识库与 MCP Server 无缝连接,实现了对 Jira 的智能化操作。
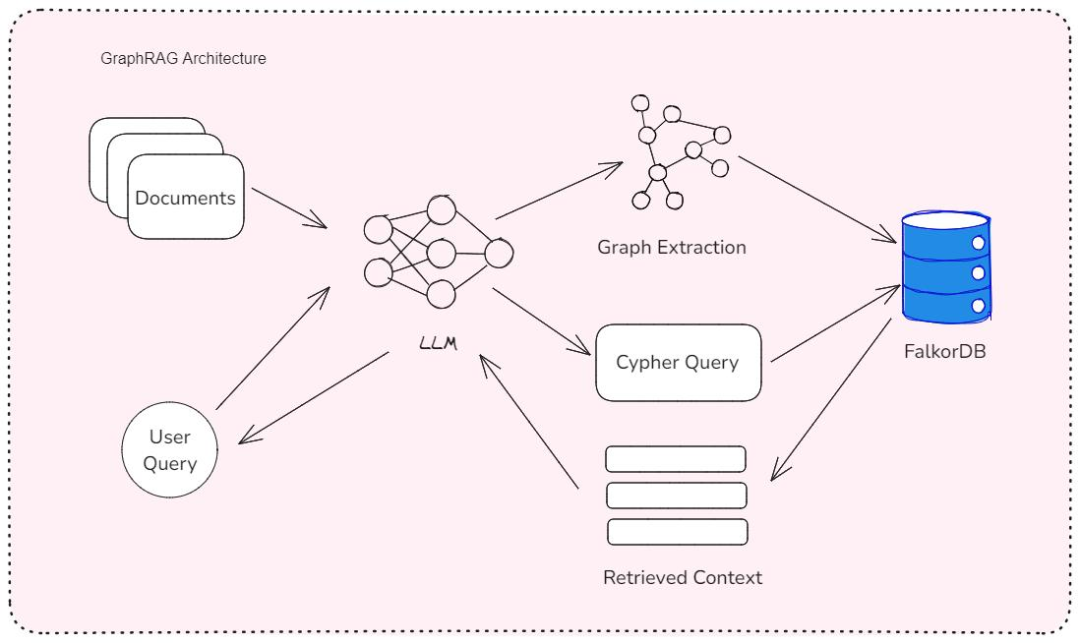
LangGraph RAG MCP 集成架构
- 感知层 - RAG 知识库:这一层负责处理和存储项目相关的各类文档,包括 Confluence 中的需求文档、Git 代码注释、Jira 历史任务记录等。我们使用嵌入模型(如 Sentence-BERT)将这些文档转换为向量表示,并存储在向量数据库(如 FAISS)中。当智能体需要处理用户请求时,RAG 模块会从向量数据库中检索相关的文档片段,为后续的决策提供上下文支持。
- 决策层 - Langchain v1.0:作为整个系统的大脑,Langchain v1.0 负责协调各个组件的工作。它接收用户的自然语言指令,结合 RAG 检索到的上下文信息,通过大语言模型(如 GPT-4)进行推理决策,确定需要执行的操作步骤。Langchain v1.0 提供的状态管理机制(基于 TypedDict 和状态合并)确保了多步骤任务执行过程中的上下文连贯性。
- 执行层 - MCP Server:这一层负责将 Langchain 的决策转化为对 Jira 的实际操作。MCP Server 实现了模型上下文协议,提供了标准化的工具接口,如创建任务、更新状态、添加评论等。通过 MCP Server,Langchain 可以安全、可靠地与 Jira 进行交互,而无需直接处理复杂的 Jira API 细节。
这种架构的优势在于各组件之间的解耦和标准化接口,使得系统具有良好的可扩展性和可维护性。例如,如果未来需要集成其他工具(如 Confluence、Jenkins),只需添加相应的 MCP Server 即可,无需对核心决策逻辑进行大规模修改。
环境搭建与依赖配置
要搭建我们的 Jira 智能体系统,需要准备以下环境和依赖:
硬件要求
- CPU:4 核或更高
- 内存:16GB 或更高(向量数据库和大语言模型推理需要较多内存)
- 存储:至少 10GB 可用空间(用于安装依赖和存储向量数据)
软件环境
- 操作系统:Windows 10/11、macOS 12+ 或 Linux(推荐 Ubuntu 20.04+)
- Python:3.9 或更高版本
- Git:用于获取项目代码和版本控制
- Docker:可选,用于容器化部署向量数据库等服务
依赖安装
首先,创建一个虚拟环境并激活:
python -m venv jira_agent_env
source jira_agent_env/bin/activate # Linux/Mac
# 或者在 Windows 上
jira_agent_env\Scripts\activate
然后安装必要的 Python 包:
pip install -r requirements.txt
requirements.txt 文件内容如下:
langchain==0.1.0
langchain-openai==0.0.5
langchain-community==0.0.18
langgraph==0.0.37
faiss-cpu==1.7.4
python-dotenv==1.0.0
jira==3.5.2
mcp-server==0.2.1
sentence-transformers==2.2.2
pydantic==2.4.2
配置文件设置
创建一个 .env 文件,用于存储敏感配置信息:
# Jira 配置
JIRA_BASE_URL=https://your-jira-instance.atlassian.net
JIRA_API_TOKEN=your-jira-api-token
JIRA_USER_EMAIL=your-email@example.com
# OpenAI 配置(如果使用 OpenAI 模型)
OPENAI_API_KEY=your-openai-api-key
# MCP Server 配置
MCP_SERVER_URL=http://localhost:8000
# 向量数据库配置
VECTOR_DB_PATH=./vector_db
EMBEDDING_MODEL=all-MiniLM-L6-v2
向量数据库初始化
我们使用 FAISS 作为向量数据库。初始化脚本如下:
from langchain.vectorstores import FAISS
from langchain.embeddings import HuggingFaceEmbeddings
import os
from dotenv import load_dotenv
load_dotenv()
def init_vector_db():
# 加载嵌入模型
embeddings = HuggingFaceEmbeddings(model_name=os.getenv("EMBEDDING_MODEL"))
# 初始化空的向量数据库
vector_db = FAISS.from_texts([""], embeddings)
# 保存向量数据库
vector_db.save_local(os.getenv("VECTOR_DB_PATH"))
print(f"向量数据库已初始化并保存到 {os.getenv('VECTOR_DB_PATH')}")
if __name__ == "__main__":
init_vector_db()
MCP Server 启动
MCP Server 提供了与 Jira 交互的标准化接口。我们可以使用官方提供的 Jira MCP Server 实现:
# 安装 MCP Server
pip install mcp-server[jira]
# 启动 MCP Server
mcp-server start --config mcp_config.yaml
mcp_config.yaml 文件内容示例:
server:
host: 0.0.0.0
port: 8000
services:
jira:
type: jira
config:
base_url: ${JIRA_BASE_URL}
api_token: ${JIRA_API_TOKEN}
user_email: ${JIRA_USER_EMAIL}
endpoints:
- name: create_issue
service: jira
method: create_issue
parameters:
- name: project_key
type: string
- name: summary
type: string
- name: description
type: string
- name: issue_type
type: string
- name: assignee
type: string
required: false
- name: transition_issue
service: jira
method: transition_issue
parameters:
- name: issue_key
type: string
- name: transition_name
type: string
通过以上步骤,我们就完成了 Jira 智能体系统的基础环境搭建和依赖配置。接下来,我们将实现核心代码,将这些组件有机地结合起来。
核心代码实现
在这一部分,我们将详细介绍 Jira 智能体的核心代码实现。我们的代码将围绕 Langchain v1.0 的状态管理机制、RAG 检索增强以及与 MCP Server 的交互展开。
1. 状态定义
首先,我们需要定义智能体的状态结构。使用 Langchain v1.0 的 TypedDict 和状态合并机制,我们可以清晰地管理智能体在处理任务过程中的状态变化。
from typing import TypedDict, Annotated, List, Optional
from langchain_core.messages import BaseMessage
from langgraph.graph import StateGraph, END
from langgraph.graph.message import add_messages
class AgentState(TypedDict):
"""
智能体状态定义
Attributes:
messages: 对话历史记录
user_query: 用户原始查询
jira_issue_key: Jira 任务键
retrieved_docs: 从 RAG 检索到的文档
current_step: 当前执行步骤
mcp_response: MCP Server 的响应结果
error: 错误信息(如有)
"""
messages: Annotated[List[BaseMessage], add_messages]
user_query: str
jira_issue_key: Optional[str] = None
retrieved_docs: Optional[List[str]] = None
current_step: str = "start"
mcp_response: Optional[dict] = None
error: Optional[str] = None
这个状态定义涵盖了智能体在处理用户请求过程中可能需要跟踪的所有关键信息。messages 字段使用 add_messages 注解,确保新消息会被追加到历史记录中,而不是替换原有内容。
2. RAG 检索模块
接下来,我们实现 RAG 检索模块,用于从知识库中获取相关文档:
from langchain.vectorstores import FAISS
from langchain.embeddings import HuggingFaceEmbeddings
from langchain.retrievers import ContextualCompressionRetriever
from langchain.retrievers.document_compressors import LLMChainExtractor
from langchain.chat_models import ChatOpenAI
import os
class RAGRetriever:
def __init__(self):
"""初始化 RAG 检索器"""
# 加载嵌入模型
self.embeddings = HuggingFaceEmbeddings(
model_name=os.getenv("EMBEDDING_MODEL")
)
# 加载向量数据库
self.vector_db = FAISS.load_local(
os.getenv("VECTOR_DB_PATH"),
self.embeddings,
allow_dangerous_deserialization=True
)
# 初始化压缩检索器(可选,用于提高检索质量)
self.llm = ChatOpenAI(temperature=0, model_name="gpt-3.5-turbo")
self.compressor = LLMChainExtractor.from_llm(self.llm)
self.retriever = ContextualCompressionRetriever(
base_compressor=self.compressor,
base_retriever=self.vector_db.as_retriever(k=3)
)
def retrieve(self, query: str) -> List[str]:
"""
根据查询检索相关文档
Args:
query: 用户查询
Returns:
检索到的文档内容列表
"""
docs = self.retriever.get_relevant_documents(query)
return [doc.page_content for doc in docs]
这个 RAG 检索器首先加载预训练的嵌入模型和向量数据库,然后使用上下文压缩技术进一步优化检索结果。压缩步骤使用 LLM 从检索到的文档中提取与查询最相关的部分,有助于减少后续步骤中的噪声干扰。
3. MCP 客户端
为了与 MCP Server 交互,我们实现一个简单的 MCP 客户端:
import requests
import json
import os
class MCPClient:
def __init__(self):
"""初始化 MCP 客户端"""
self.base_url = os.getenv("MCP_SERVER_URL")
def call(self, method: str, params: dict) -> dict:
"""
调用 MCP Server 方法
Args:
method: 要调用的方法名
params: 方法参数
Returns:
MCP Server 响应
"""
url = f"{self.base_url}/api/mcp/call"
headers = {"Content-Type": "application/json"}
payload = {
"jsonrpc": "2.0",
"id": "1",
"method": method,
"params": params
}
try:
response = requests.post(url, headers=headers, data=json.dumps(payload))
response.raise_for_status() # 抛出 HTTP 错误
result = response.json()
if "error" in result:
raise Exception(f"MCP Server error: {result['error']['message']}")
return result.get("result", {})
except Exception as e:
print(f"Error calling MCP Server: {str(e)}")
raise
这个客户端实现了与 MCP Server 的基本通信功能,遵循 JSON-RPC 2.0 规范。它封装了 HTTP 请求的细节,使得智能体的其他部分可以更专注于业务逻辑。
4. 智能体工作流
现在,我们将实现智能体的核心工作流。我们使用 Langchain v1.0 的 StateGraph 来定义状态转换逻辑:
from langchain.chat_models import ChatOpenAI
from langchain.prompts import ChatPromptTemplate
from langchain.chains import LLMChain
from langchain.output_parsers import StructuredOutputParser, ResponseSchema
class JiraAgent:
def __init__(self):
"""初始化 Jira 智能体"""
self.rag_retriever = RAGRetriever()
self.mcp_client = MCPClient()
self.llm = ChatOpenAI(temperature=0.7, model_name="gpt-4")
self.workflow = self._build_workflow()
def _build_workflow(self) -> StateGraph:
"""构建智能体工作流"""
workflow = StateGraph(AgentState)
# 添加节点
workflow.add_node("retrieve", self._retrieve_documents)
workflow.add_node("decide", self._decide_action)
workflow.add_node("execute", self._execute_action)
workflow.add_node("finalize", self._finalize_response)
# 添加边
workflow.set_entry_point("retrieve")
workflow.add_edge("retrieve", "decide")
workflow.add_edge("decide", "execute")
workflow.add_edge("execute", "finalize")
workflow.add_edge("finalize", END)
# 编译工作流
return workflow.compile()
def _retrieve_documents(self, state: AgentState) -> AgentState:
"""检索相关文档"""
print(f"Step: Retrieve documents for query: {state['user_query']}")
retrieved_docs = self.rag_retriever.retrieve(state["user_query"])
return {
"retrieved_docs": retrieved_docs,
"current_step": "retrieve"
}
def _decide_action(self, state: AgentState) -> AgentState:
"""决定下一步行动"""
print(f"Step: Decide action based on query and retrieved docs")
# 定义响应模式
response_schemas = [
ResponseSchema(
name="action",
description="要执行的操作,可选值: create_issue, transition_issue, add_comment, query_issue, none",
type="string"
),
ResponseSchema(
name="reasoning",
description="做出此决定的理由",
type="string"
),
ResponseSchema(
name="parameters",
description="操作参数,JSON 对象",
type="object"
)
]
output_parser = StructuredOutputParser.from_response_schemas(response_schemas)
format_instructions = output_parser.get_format_instructions()
# 构建提示
prompt = ChatPromptTemplate.from_template("""
You are a Jira assistant. Based on the user query and retrieved documents, decide what action to take.
User query: {user_query}
Retrieved documents:
{retrieved_docs}
{format_instructions}
Think step by step and then output the action, reasoning, and parameters.
""")
chain = LLMChain(llm=self.llm, prompt=prompt)
response = chain.run(
user_query=state["user_query"],
retrieved_docs="\n\n".join(state["retrieved_docs"] or []),
format_instructions=format_instructions
)
# 解析响应
try:
parsed_response = output_parser.parse(response)
state["current_step"] = "decide"
state["mcp_response"] = parsed_response
return state
except Exception as e:
print(f"Error parsing LLM response: {str(e)}")
return {"error": f"Decision error: {str(e)}", "current_step": "error"}
def _execute_action(self, state: AgentState) -> AgentState:
"""执行操作"""
print(f"Step: Execute action")
decision = state.get("mcp_response", {})
action = decision.get("action")
if action == "none" or not action:
return {"current_step": "execute", "mcp_response": {"result": "No action needed"}}
try:
# 根据决策调用相应的 MCP 方法
if action == "create_issue":
response = self.mcp_client.call("create_issue", decision["parameters"])
state["jira_issue_key"] = response.get("key")
elif action == "transition_issue":
response = self.mcp_client.call("transition_issue", decision["parameters"])
elif action == "add_comment":
response = self.mcp_client.call("add_comment", decision["parameters"])
elif action == "query_issue":
response = self.mcp_client.call("query_issue", decision["parameters"])
else:
raise ValueError(f"Unknown action: {action}")
return {
"current_step": "execute",
"mcp_response": response
}
except Exception as e:
print(f"Error executing action: {str(e)}")
return {"error": f"Execution error: {str(e)}", "current_step": "error"}
def _finalize_response(self, state: AgentState) -> AgentState:
"""生成最终响应"""
print(f"Step: Finalize response")
if state.get("error"):
response = f"Sorry, I encountered an error while processing your request: {state['error']}"
else:
action = state["mcp_response"].get("action", "none")
if action == "create_issue" and state["jira_issue_key"]:
response = f"Successfully created Jira issue: {state['jira_issue_key']}. You can view it at {os.getenv('JIRA_BASE_URL')}/browse/{state['jira_issue_key']}"
elif action == "transition_issue":
response = f"Successfully transitioned Jira issue. MCP response: {state['mcp_response']}"
elif action == "none":
response = "I've analyzed your query, but no action is needed. Let me know if you'd like to create or update a Jira issue."
else:
response = f"Action completed successfully. MCP response: {state['mcp_response']}"
return {
"messages": [{"role": "assistant", "content": response}],
"current_step": "finalize"
}
def run(self, user_query: str) -> dict:
"""运行智能体处理用户查询"""
initial_state = {
"messages": [],
"user_query": user_query,
"current_step": "start"
}
return self.workflow.invoke(initial_state)
这个工作流定义了智能体处理用户请求的完整流程:
- 检索文档:使用 RAG 模块从知识库中检索与用户查询相关的文档。
- 决策行动:基于用户查询和检索到的文档,决定应该执行什么 Jira 操作。
- 执行操作:通过 MCP Server 执行决策的操作。
- 生成响应:将执行结果整理成自然语言响应返回给用户。
每个步骤都被实现为一个独立的函数,负责处理特定的任务并更新智能体的状态。这种模块化设计使得系统更容易维护和扩展。
Jira API 集成实战
在本节中,我们将深入探讨如何通过 MCP Server 实现与 Jira API 的集成,并提供具体的实战示例。MCP Server 作为中间层,为智能体提供了标准化的接口来操作 Jira,同时处理了认证、请求验证和错误处理等底层细节。
MCP Server 与 Jira API 对接
MCP Server 通过 Jira Python SDK 与 Jira API 进行交互。以下是 MCP Server 中 Jira 服务的核心实现:
from jira import JIRA
from jira.exceptions import JIRAError
import os
from typing import Dict, Any, Optional
class JiraService:
def __init__(self):
"""初始化 Jira 服务"""
self.jira = self._connect_jira()
def _connect_jira(self) -> JIRA:
"""连接到 Jira"""
try:
jira = JIRA(
server=os.getenv("JIRA_BASE_URL"),
basic_auth=(
os.getenv("JIRA_USER_EMAIL"),
os.getenv("JIRA_API_TOKEN")
)
)
print(f"Successfully connected to Jira instance: {os.getenv('JIRA_BASE_URL')}")
return jira
except JIRAError as e:
print(f"Jira connection failed: {str(e)}")
raise
def create_issue(self, params: Dict[str, Any]) -> Dict[str, Any]:
"""
创建 Jira 任务
Args:
params: 任务参数,包含 project_key, summary, description, issue_type 等
Returns:
创建的任务信息
"""
required_fields = ["project_key", "summary", "issue_type"]
for field in required_fields:
if field not in params:
raise ValueError(f"Missing required parameter: {field}")
issue_dict = {
"project": {"key": params["project_key"]},
"summary": params["summary"],
"description": params.get("description", ""),
"issuetype": {"name": params["issue_type"]},
}
# 添加可选字段
if "assignee" in params:
issue_dict["assignee"] = {"name": params["assignee"]}
if "priority" in params:
issue_dict["priority"] = {"name": params["priority"]}
try:
issue = self.jira.create_issue(fields=issue_dict)
print(f"Created Jira issue: {issue.key}")
return {
"key": issue.key,
"id": issue.id,
"self": issue.self,
"summary": issue.fields.summary
}
except JIRAError as e:
print(f"Failed to create Jira issue: {str(e)}")
raise
def transition_issue(self, params: Dict[str, Any]) -> Dict[str, Any]:
"""
转换 Jira 任务状态
Args:
params: 转换参数,包含 issue_key 和 transition_name
Returns:
转换结果
"""
required_fields = ["issue_key", "transition_name"]
for field in required_fields:
if field not in params:
raise ValueError(f"Missing required parameter: {field}")
try:
# 获取当前任务的所有可用转换
issue = self.jira.issue(params["issue_key"])
transitions = self.jira.transitions(issue)
# 查找匹配的转换
transition_id = None
for t in transitions:
if t["name"].lower() == params["transition_name"].lower():
transition_id = t["id"]
break
if not transition_id:
raise ValueError(f"Transition '{params['transition_name']}' not found for issue {params['issue_key']}")
# 执行转换
self.jira.transition_issue(issue, transition_id)
print(f"Transitioned issue {params['issue_key']} to {params['transition_name']}")
# 获取更新后的状态
updated_issue = self.jira.issue(params["issue_key"])
return {
"issue_key": params["issue_key"],
"new_status": updated_issue.fields.status.name,
"transition": params["transition_name"]
}
except JIRAError as e:
print(f"Failed to transition Jira issue: {str(e)}")
raise
这个 Jira 服务实现了创建任务和转换任务状态两个核心功能。它处理了与 Jira API 的直接交互,包括认证、请求构建和响应处理。
权限控制与异常处理
在实际应用中,权限控制和异常处理至关重要。以下是 MCP Server 中实现的权限验证中间件:
from fastapi import Request, HTTPException
from jose import JWTError, jwt
import os
class AuthMiddleware:
"""权限验证中间件"""
def __init__(self):
self.secret_key = os.getenv("MCP_SECRET_KEY")
self.algorithm = "HS256"
async def __call__(self, request: Request, call_next):
"""验证请求权限"""
# 跳过登录接口
if request.url.path == "/api/auth/login":
return await call_next(request)
# 获取 token
auth_header = request.headers.get("Authorization")
if not auth_header or not auth_header.startswith("Bearer "):
raise HTTPException(status_code=401, detail="Not authenticated")
token = auth_header.split(" ")[1]
try:
# 验证 token
payload = jwt.decode(token, self.secret_key, algorithms=[self.algorithm])
request.state.user = payload
except JWTError:
raise HTTPException(status_code=401, detail="Invalid authentication credentials")
# 检查权限
required_permission = self._get_required_permission(request.url.path, request.method)
if required_permission and required_permission not in payload.get("permissions", []):
raise HTTPException(status_code=403, detail="Not enough permissions")
return await call_next(request)
def _get_required_permission(self, path: str, method: str) -> Optional[str]:
"""根据路径和方法获取所需权限"""
if "/api/mcp/call" in path:
if method == "POST":
return "mcp:execute"
return None
这个中间件实现了基于 JWT 的认证和基于角色的权限控制。它确保只有经过授权的用户才能调用 MCP Server 的敏感接口。
实战示例:创建 Jira 任务
现在,让我们通过一个完整的示例来展示如何使用我们的智能体创建一个 Jira 任务:
def main():
"""示例:使用 Jira 智能体创建任务"""
agent = JiraAgent()
# 用户查询
user_query = "创建一个新的前端任务,标题为'优化登录页面性能',描述为'减少登录页面加载时间,目标是首次内容绘制(FCP)小于1.5秒',分配给用户'john.doe',优先级为高。"
# 运行智能体
result = agent.run(user_query)
# 输出结果
print("\n=== Final Result ===")
for msg in result["messages"]:
if msg["role"] == "assistant":
print(msg["content"])
if __name__ == "__main__":
main()
运行这个示例,智能体将:
- 解析用户查询,提取关键信息(任务类型、标题、描述、负责人、优先级)
- 从 RAG 知识库中检索相关文档(如前端性能标准、类似任务的处理方式)
- 决定执行 “create_issue” 操作
- 通过 MCP Server 创建 Jira 任务
- 返回包含任务 key 和链接的结果
这个示例展示了我们的 Jira 智能体如何将自然语言查询转换为实际的 Jira 操作,大大简化了任务创建过程。
智能体工作流演示
在本节中,我们将详细演示 Jira 智能体的完整工作流程,并通过可视化方式展示其内部状态变化。我们将以一个典型的开发场景为例:用户要求创建一个新的 bug 报告,并在问题解决后自动更新状态。
工作流程概述
Jira 智能体的工作流程可以分为以下几个主要阶段:
- 用户交互:用户以自然语言形式输入请求
- 文档检索:智能体从知识库中检索相关文档
- 决策制定:确定需要执行的 Jira 操作
- 操作执行:通过 MCP Server 执行 Jira 操作
- 结果反馈:向用户返回操作结果
下面,我们将通过一个具体示例来详细展示每个阶段的具体过程。
详细工作流程演示
1. 用户请求
假设开发人员在日常工作中遇到了一个问题,需要创建一个 bug 报告:
“创建一个新的 bug,标题为’用户登录后个人资料页面无法加载’,描述为’当用户使用 Chrome 浏览器登录系统后,点击个人资料链接,页面显示空白。在 Firefox 中没有这个问题。',分配给前端开发团队的 sarah.zhang,优先级设为高。”
2. 文档检索阶段
智能体首先使用 RAG 模块从知识库中检索相关文档:
- 检索到的文档 1:项目团队的 Jira 使用规范,其中定义了 bug 报告的标准格式和优先级划分。
- 检索到的文档 2:类似的历史 bug 报告,标题为"IE 浏览器中设置页面无法加载",最终发现是由于缺少 polyfill 导致的兼容性问题。
- 检索到的文档 3:团队成员列表,显示 sarah.zhang 是前端团队的成员,负责用户界面相关开发。
这些检索到的文档将帮助智能体更准确地理解用户需求,并做出更明智的决策。
3. 决策制定阶段
基于用户请求和检索到的文档,智能体的决策模块(由 LLM 驱动)将分析并确定需要执行的操作:
- 确定操作类型:创建新的 bug 报告。
- 提取关键信息:
- 项目:根据上下文推断为当前活跃项目(如 PROJ)
- 问题类型:bug
- 标题:用户登录后个人资料页面无法加载
- 描述:包含复现步骤和环境信息
- 负责人:sarah.zhang
- 优先级:高
- 验证信息完整性:检查是否有遗漏的必填字段,如项目 key、问题类型等。
- 生成操作参数:将提取的信息格式化为 MCP Server 所需的参数。
4. 操作执行阶段
智能体通过 MCP Server 执行创建 Jira bug 的操作:
- 调用 MCP 接口:发送 create_issue 请求,包含上一步生成的参数。
- MCP Server 处理:
- 验证请求参数
- 检查用户权限
- 调用 Jira API 创建 bug
- Jira API 交互:MCP Server 向 Jira 发送 POST 请求,创建新的 issue。
- 接收响应:Jira 返回新创建的 bug 信息,包括 issue key(如 PROJ-1234)。
5. 结果反馈阶段
最后,智能体将操作结果整理为自然语言响应,并返回给用户:
“已成功创建 Jira bug:PROJ-1234。
标题:用户登录后个人资料页面无法加载
负责人:sarah.zhang
优先级:高
您可以通过以下链接查看:https://your-jira-instance.atlassian.net/browse/PROJ-1234”
状态流转图
下面是 Jira 智能体处理上述请求时的状态流转图:
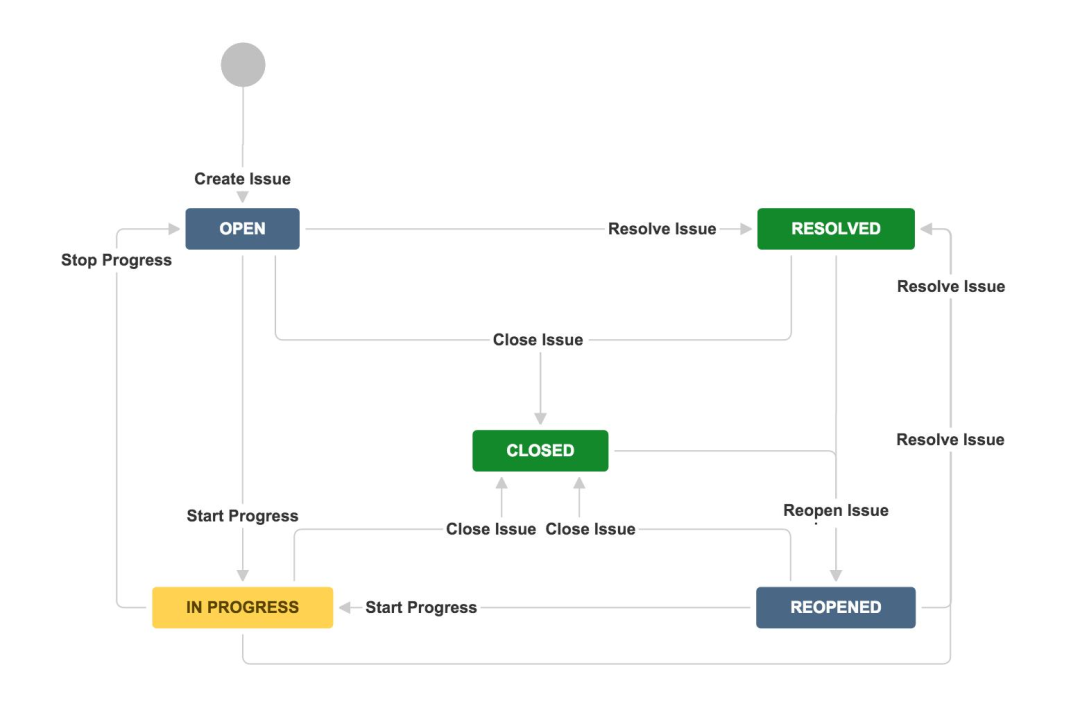
Jira 状态流转图
这个状态图展示了 Jira 任务在其生命周期中可能的状态转换。在我们的示例中,智能体创建的 bug 从 “OPEN” 状态开始,等待被处理。当 sarah.zhang 开始处理这个问题时,她会将状态转换为 “IN PROGRESS”。问题解决后,她会将其转换为 “RESOLVED”。经过测试验证后,最终转换为 “CLOSED” 状态。
我们的智能体不仅可以创建任务,还可以根据用户请求自动更新任务状态。例如,当开发人员提交包含 “Fix PROJ-1234” 的代码时,智能体可以检测到这个提交,并自动将相应的 Jira 任务状态从 “IN PROGRESS” 转换为 “RESOLVED”。
性能优化与避坑指南
在部署和使用 Jira 智能体的过程中,我们可能会遇到各种性能和稳定性问题。本节将分享一些实用的优化技巧和常见问题的解决方案。
性能优化策略
- 向量数据库优化
-
选择合适的嵌入模型:较小的模型(如 all-MiniLM-L6-v2)速度更快,适合资源有限的环境;较大的模型(如 all-mpnet-base-v2)检索质量更高,但速度较慢。根据实际需求权衡选择。
-
索引优化:FAISS 提供了多种索引类型,IVF 索引在大规模数据集上表现更好。可以尝试:
# 创建 IVF 索引(适用于大数据集)
index = faiss.IndexIVFFlat(d, 128, faiss.METRIC_L2)
- 批量处理:在初始化知识库时,使用批量处理方式添加文档,减少 I/O 操作。
- LLM 调用优化
- 缓存机制:对相同或相似的查询结果进行缓存,避免重复调用 LLM。Langchain 提供了 SimpleCache 和 RedisCache 等实现。
- 流式响应:对于较长的响应,使用流式输出方式,让用户更快看到结果。
- 模型选择:根据任务复杂度动态选择模型。简单任务使用轻量级模型(如 GPT-3.5-turbo),复杂任务使用更强大的模型(如 GPT-4)。
- MCP Server 优化
- 连接池:使用连接池管理 Jira API 连接,减少频繁建立连接的开销。
- 异步处理:对于耗时的操作(如批量更新),采用异步处理方式,避免阻塞主流程。
- 请求合并:将多个小请求合并为一个大请求,减少 API 调用次数。
常见问题与解决方案
- Jira API 调用失败
-
问题:频繁调用 Jira API 导致速率限制。
-
解决方案:实现请求限流和重试机制。
from tenacity import retry, stop_after_attempt, wait_exponential
@retry(stop=stop_after_attempt(3), wait=wait_exponential(multiplier=1, min=2, max=10))
def call_jira_api():
# Jira API 调用代码
- 检索结果不相关
- 问题:RAG 检索到的文档与用户查询相关性不高。
- 解决方案:
- 调整检索参数(如 k 值,检索数量)
- 使用更合适的嵌入模型
- 优化文档分块策略,避免过大或过小的块
- 实现文档重排序机制
- 智能体决策错误
- 问题:智能体做出错误的决策,如错误理解用户意图。
- 解决方案:
- 优化提示工程,提供更清晰的指令和示例
- 增加人工反馈机制,允许用户纠正智能体的错误
- 实现决策验证步骤,让智能体解释其决策理由
- 状态管理问题
- 问题:多步骤任务执行过程中状态丢失或混乱。
- 解决方案:
- 仔细设计状态结构,确保包含所有必要信息
- 实现状态持久化,使用数据库存储中间状态
- 添加状态验证和恢复机制
- 权限控制问题
- 问题:智能体执行了超出其权限的操作。
- 解决方案:
- 在 MCP Server 中实现细粒度的权限控制
- 为智能体创建专用的 Jira 用户,限制其权限范围
- 实现操作审计日志,记录所有智能体执行的操作
部署最佳实践
- 环境隔离:为开发、测试和生产环境使用不同的 Jira 实例和 MCP Server 配置,避免影响实际业务数据。
- 监控与告警:实现全面的监控,包括:
- 智能体响应时间
- LLM 调用成功率
- MCP Server 健康状态
- Jira API 调用频率和成功率
设置关键指标的告警阈值,及时发现和解决问题。
- 版本控制:对知识库文档、提示模板和代码进行版本控制,便于追踪变更和回滚。
- 渐进式部署:先在小范围团队中试用智能体,收集反馈并优化,然后再逐步推广到整个组织。
通过实施这些优化策略和遵循最佳实践,我们可以显著提高 Jira 智能体的性能、可靠性和安全性,使其更好地服务于开发团队,提高工作效率。
那么,如何系统的去学习大模型LLM?
作为一名从业五年的资深大模型算法工程师,我经常会收到一些评论和私信,我是小白,学习大模型该从哪里入手呢?我自学没有方向怎么办?这个地方我不会啊。如果你也有类似的经历,一定要继续看下去!这些问题啊,也不是三言两语啊就能讲明白的。
所以我综合了大模型的所有知识点,给大家带来一套全网最全最细的大模型零基础教程。在做这套教程之前呢,我就曾放空大脑,以一个大模型小白的角度去重新解析它,采用基础知识和实战项目相结合的教学方式,历时3个月,终于完成了这样的课程,让你真正体会到什么是每一秒都在疯狂输出知识点。
由于篇幅有限,⚡️ 朋友们如果有需要全套 《2025全新制作的大模型全套资料》,扫码获取~
为什么要学习大模型?
我国在A大模型领域面临人才短缺,数量与质量均落后于发达国家。2023年,人才缺口已超百万,凸显培养不足。随着AI技术飞速发展,预计到2025年,这一缺口将急剧扩大至400万,严重制约我国AI产业的创新步伐。加强人才培养,优化教育体系,国际合作并进是破解困局、推动AI发展的关键。


👉大模型学习指南+路线汇总👈
我们这套大模型资料呢,会从基础篇、进阶篇和项目实战篇等三大方面来讲解。

👉①.基础篇👈
基础篇里面包括了Python快速入门、AI开发环境搭建及提示词工程,带你学习大模型核心原理、prompt使用技巧、Transformer架构和预训练、SFT、RLHF等一些基础概念,用最易懂的方式带你入门大模型。
👉②.进阶篇👈
接下来是进阶篇,你将掌握RAG、Agent、Langchain、大模型微调和私有化部署,学习如何构建外挂知识库并和自己的企业相结合,学习如何使用langchain框架提高开发效率和代码质量、学习如何选择合适的基座模型并进行数据集的收集预处理以及具体的模型微调等等。
👉③.实战篇👈
实战篇会手把手带着大家练习企业级的落地项目(已脱敏),比如RAG医疗问答系统、Agent智能电商客服系统、数字人项目实战、教育行业智能助教等等,从而帮助大家更好的应对大模型时代的挑战。
👉④.福利篇👈
最后呢,会给大家一个小福利,课程视频中的所有素材,有搭建AI开发环境资料包,还有学习计划表,几十上百G素材、电子书和课件等等,只要你能想到的素材,我这里几乎都有。我已经全部上传到CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
相信我,这套大模型系统教程将会是全网最齐全 最易懂的小白专用课!!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 8
8 0
0- 0



 已为社区贡献473条内容
已为社区贡献473条内容

所有评论(0)