【openGauss × Dify】| 依托openGauss 与Dify打造你的高性能AI助手
本文介绍了如何利用openGauss DataVec向量引擎与Dify平台构建智能问答助手。openGauss DataVec作为内置于数据库的向量引擎,支持融合查询和统一技术栈;Dify则提供便捷的LLM应用开发流程。文章详细讲解了从环境部署、模型配置到知识库构建的全过程,包括Dify服务的启动、AI模型接入、知识文档向量化存储等关键步骤,最终实现基于RAG技术的智能问答应用。该方案结合了ope
一. 写在前面
在人工智能技术飞速发展的今天,如何快速、高效地构建一个能够理解和处理私有知识的智能助手,成为许多开发者与企业的核心需求。本文将带你深入了解如何将openGauss向量引擎DataVec的强大数据检索能力,与Dify的便捷LLM应用开发流程相结合,打造一个高性能的智能助手平台。
二. 为何选择openGauss DataVec与Dify?
在构建RAG(检索增强生成)应用时,技术组件的选择至关重要。openGauss DataVec与Dify的组合,为我们提供了一条兼具高性能与低成本的路径。openGauss DataVec作为一个深度集成于openGauss数据库内核的向量引擎,它并非一个独立的向量数据库,而是将向量计算能力内化为数据库的原生能力。这种设计带来了两大显著优势:
-
融合查询:允许在单次查询中,同时执行向量的相似性搜索和传统关系型数据的条件过滤,无需进行复杂的数据同步与跨系统关联。
-
统一技术栈:降低了系统的复杂度和运维成本,开发者使用熟悉的SQL语法即可操作向量数据。
Dify作为一个开源的大语言模型应用开发平台,其核心优势在于将LLM应用的开发、部署和工作流编排过程变得可视化且易于上手。它集成了检索增强生成(RAG)引擎,能智能地为大模型提供相关信息,显著提升回答的准确性与相关性。组合的协同效应在于,Dify负责整个AI应用的编排与呈现,而openGauss DataVec则作为其下坚实的数据基石,负责处理海量非结构化数据的高速检索。这种组合让开发者可以更专注于业务逻辑本身。
现在让我们从0-1搭建这个AI利器。
三. 搭建你的智能问答助手
3.1 环境准备与部署
获取Dify源码:从Dify的GitHub发布页面(例如本文示例使用的1.1.0版本)获取源码压缩包。自1.1.0版本起,Dify正式提供了对openGauss的支持。
- 获取Dify源码:从Dify的GitHub发布页面直接下载:https://github.com/langgenius/dify/archive/refs/tags/1.1.0.zip

- 配置Dify:创建目录并解压源码后,进入Dify的docker目录,复制环境配置文件并编辑。
- 使用文本编辑器(如vim)打开.env文件,找到VECTOR_STORE配置项,将其值修改为openGauss,这是告诉Dify使用openGauss作为其向量存储的关键一步。

- 后面加载项目会自动下载openGauss依赖:
- 启动服务:在docker目录下,执行一条命令即可启动所有依赖服务,如下:
sudo docker-compose up -d
- 执行完就会下载对应的依赖:
- 安装完成:

3.2 在Dify中配置AI模型与服务
Dify服务启动后,下一步就是接入AI大脑。
-
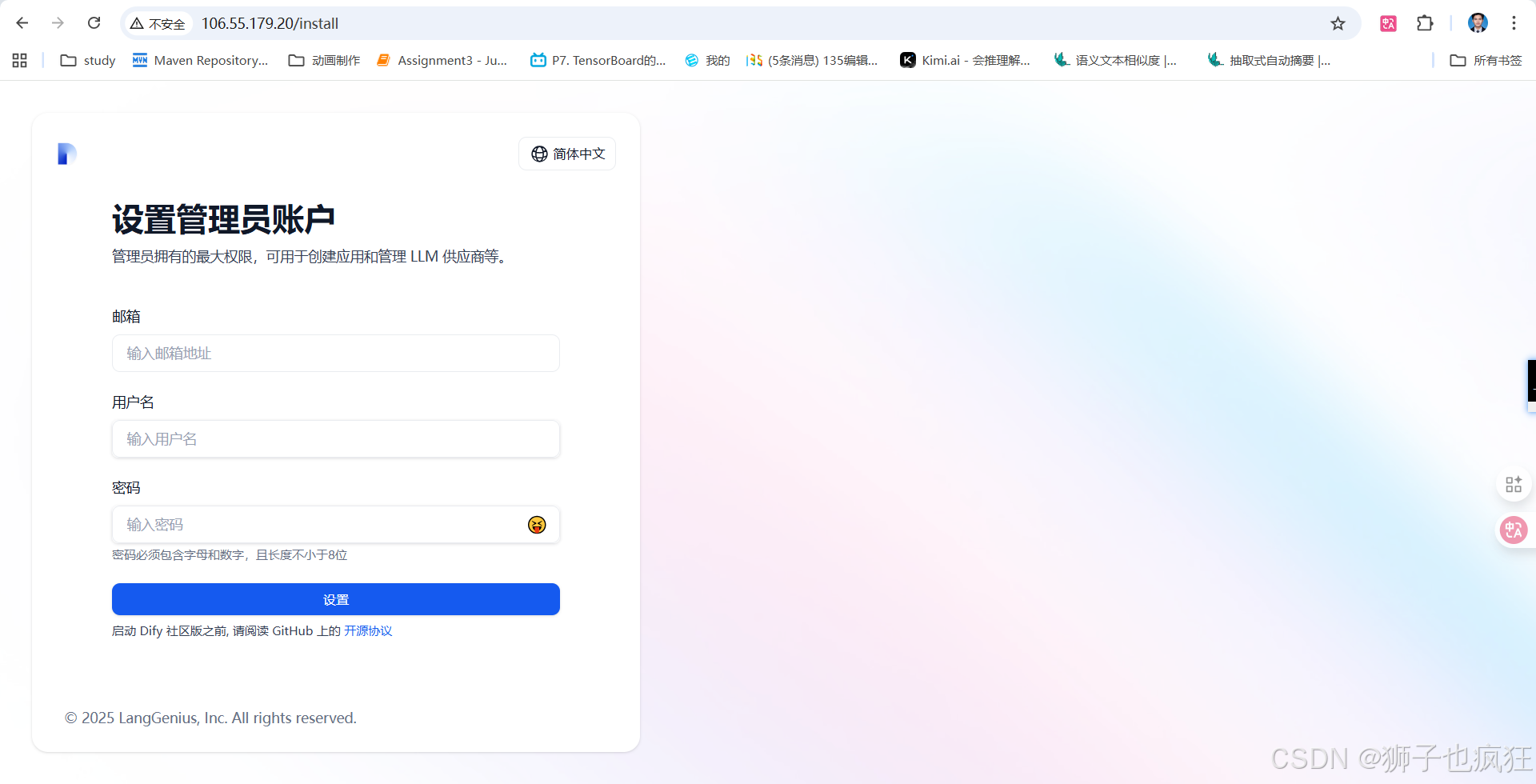
访问与初始化:在浏览器中访问Dify的Web服务地址(例如 http://106.55.179.20),创建管理员账户并登录。
-
配置大语言模型(LLM):在Dify的设置界面,你可以添加所需的大模型(我这里装了硅基流动的大模型)。
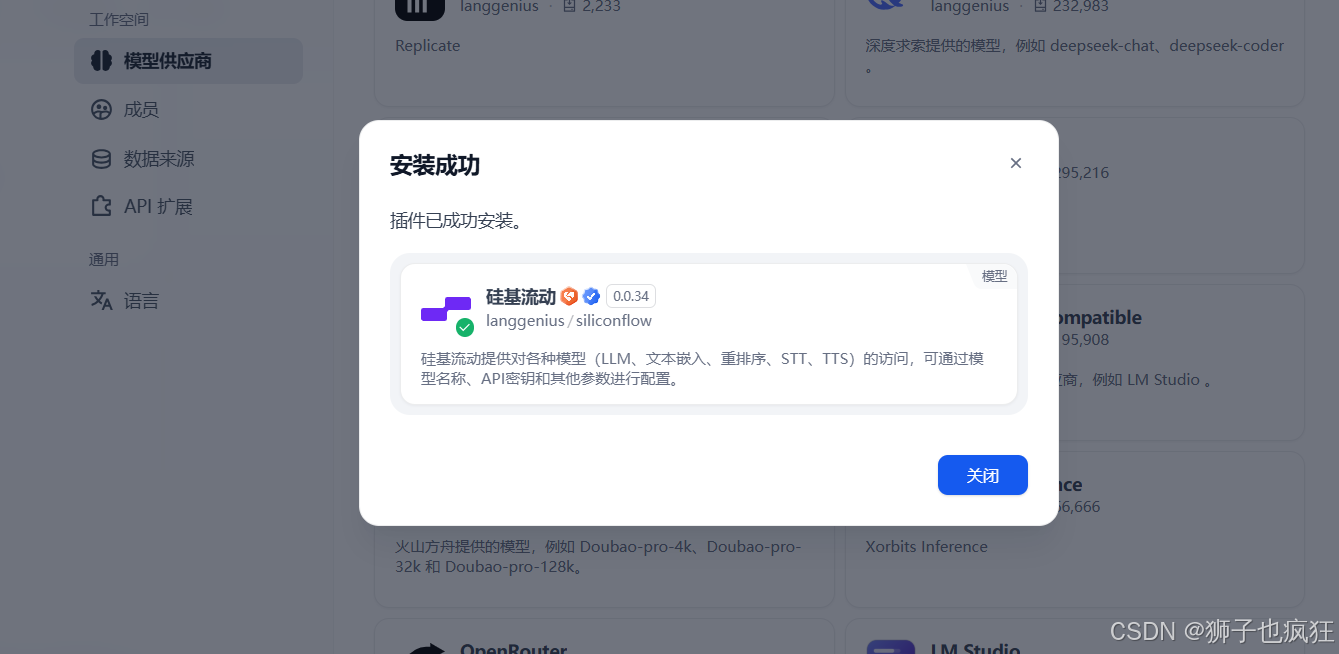
-
配置嵌入模型(Embedding Model):嵌入模型负责将文本转换为向量。同样在模型供应商设置中,添加一个Text Embedding类型的模型,这对于RAG功能至关重要。
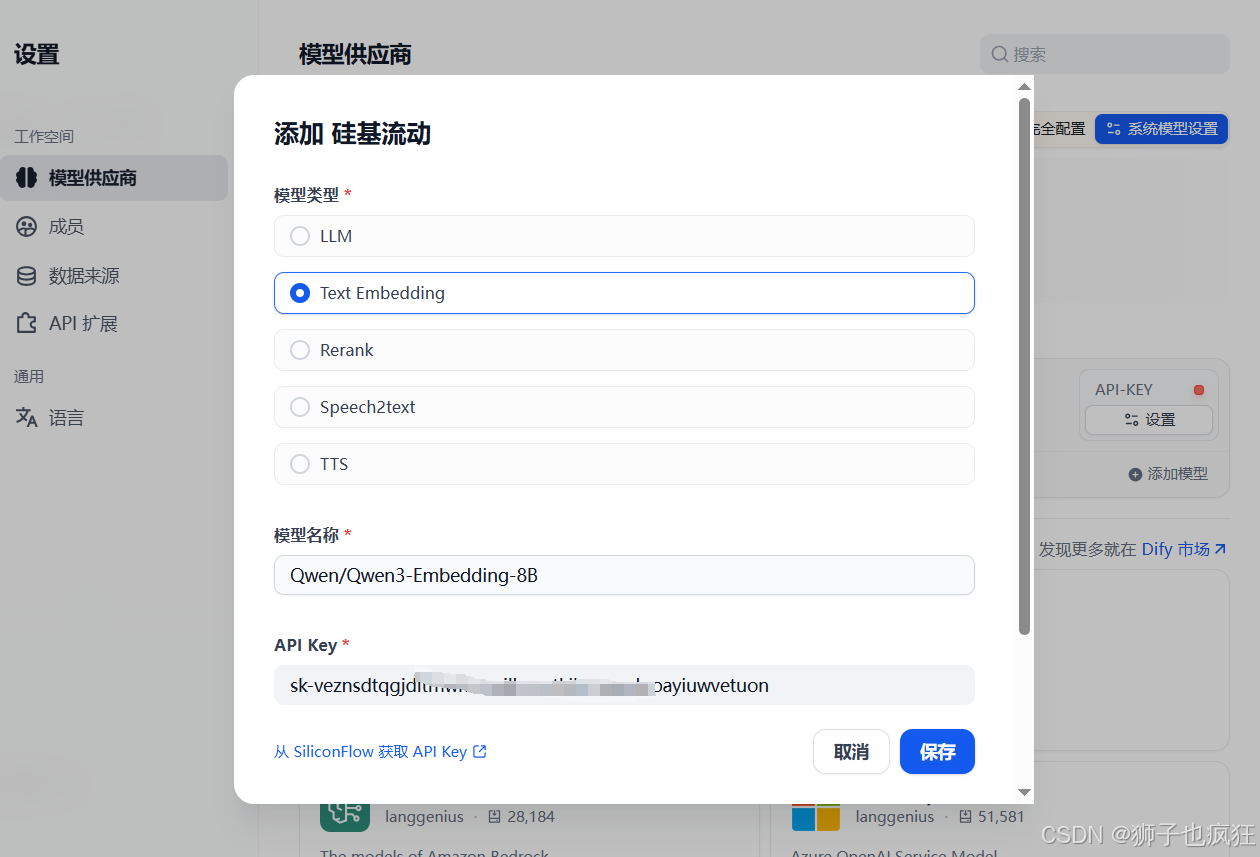
3.3 构建您的专属知识库
知识库是智能助手能够回答专业问题的基础。
-
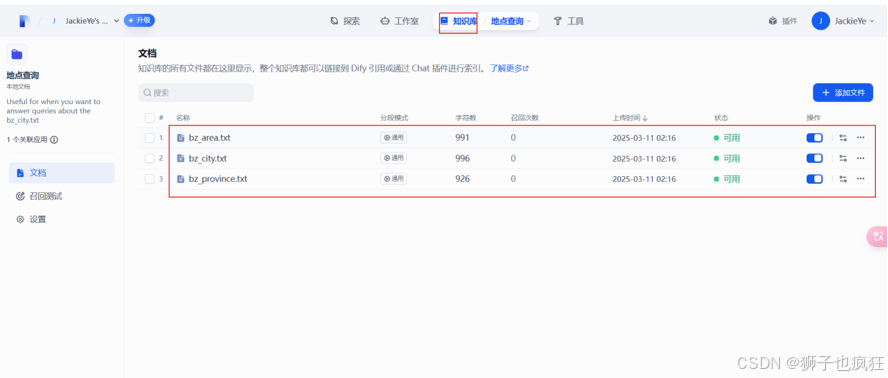
导入知识:在Dify平台的“知识库”界面,点击“创建知识库”并上传你的文档(如PDF、Word等)。Dify支持从本地文件、在线文档等多种数据源导入知识。这里导入一些数据库表txt文件。
-
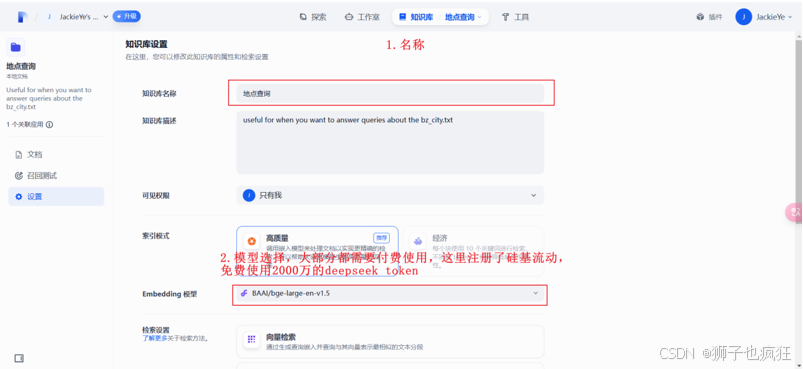
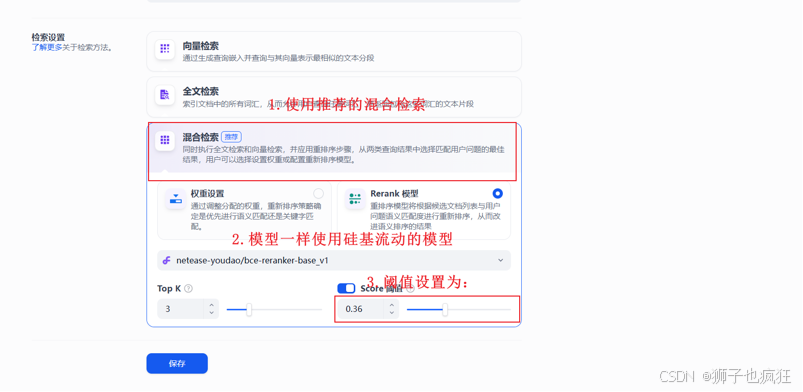
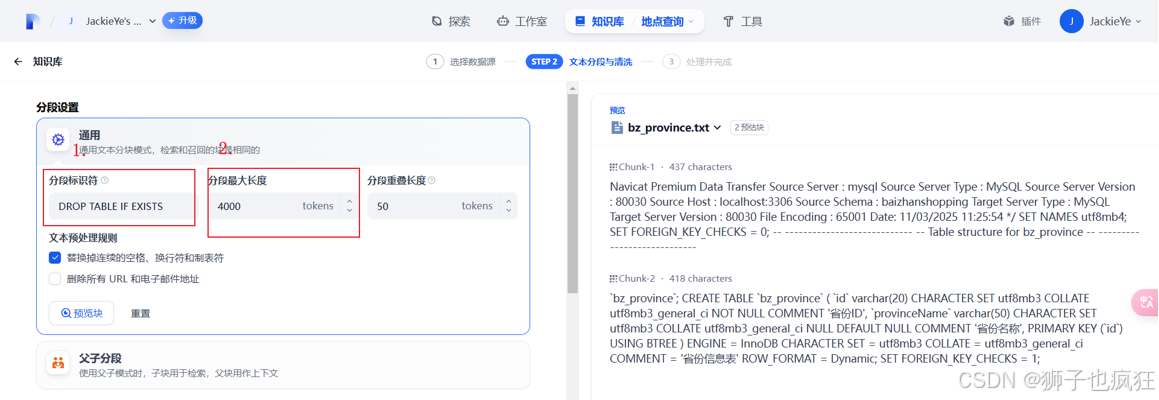
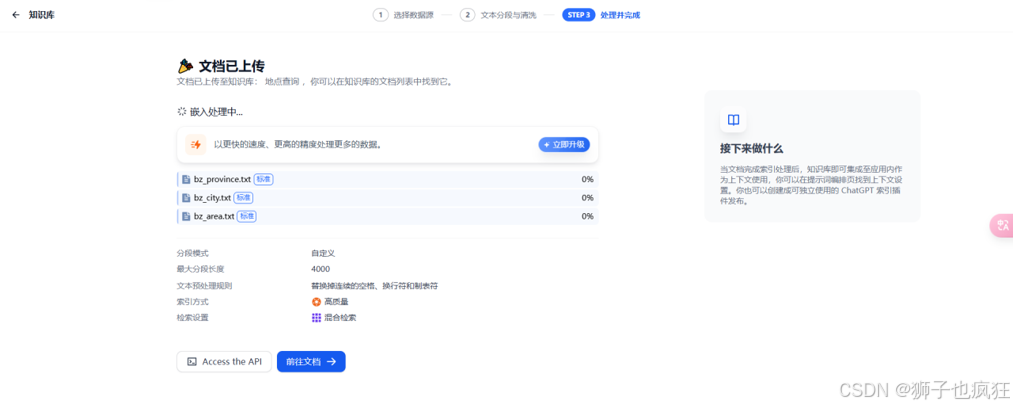
处理与向量化:在导入时,确保选择之前配置好的嵌入模型,然后点击“保存并处理”。Dify的后台服务会自动对文档进行文本提取、分割,并通过嵌入模型将文本块转化为向量,最后将这些向量数据存储至你已配置的openGauss DataVec数据库中。
3.4 创建应用并进行对话测试
最后,我们将知识库能力封装成一个可用的应用。
-
创建AI应用:在Dify中,选择创建基于“对话”类型的新应用。
-
启用RAG并关联知识库:在应用编排界面,找到“上下文”或“RAG”相关配置,启用该功能并关联你在上一步创建的知识库。
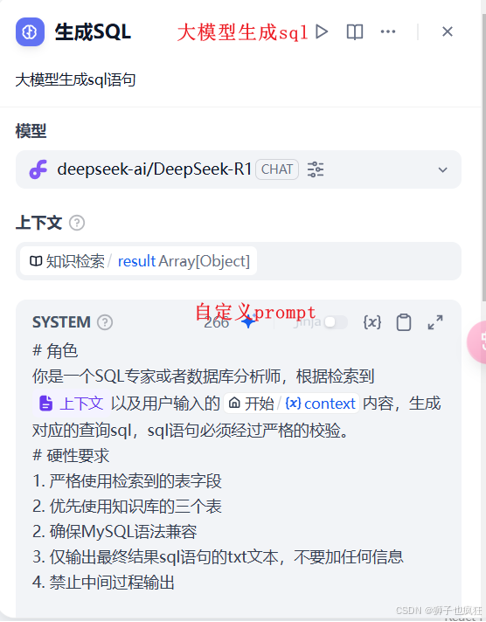
-
测试与优化:进入应用的聊天窗口,提出问题进行测试。你可以尝试询问一些知识库内的专业知识,并观察助手能否给出准确的回答。根据回答效果,可以返回去调整知识库的分块大小、相似度阈值等参数以优化性能。
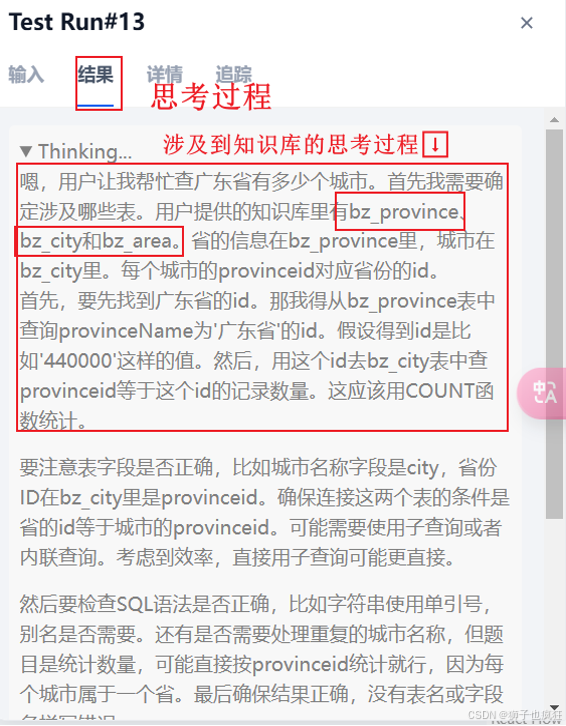
四. 性能优化与最佳实践
openGauss数据库凭借其卓越的向量检索能力和智能化设计,为AI助手的性能提升提供了强大支撑。
-
在向量索引选型方面,openGauss支持HNSW等高性能索引结构,确保在高精度查询场景下获得毫秒级响应,其独特的IVF-PQ量化索引技术更能在海量数据场景中实现内存占用与查询效率的完美平衡。
-
其次,openGauss DataVec模块的融合查询功能展现了令人惊艳的工程智慧,仅需单个SQL查询即可同时完成向量相似度匹配和结构化字段的精准过滤,这种原生支持多模态检索的能力让复杂查询变得异常高效。
openGauss与Dify平台的深度整合为构建企业级智能应用开辟了新范式。通过其工作流引擎和智能Agent机制,开发者能轻松实现从知识检索、计算分析到报告生成的完整AI pipeline,这种开箱即用的智能化特性让复杂业务场景的落地变得前所未有的简单。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 12
12 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)