AI导读AI论文: CAD-Coder: Text-to-CAD Generation with Chain-of-Thought and Geometric Reward
现有方法多基于预定义命令序列(如DeepCAD、Text2CAD),存在三大问题:CAD-Coder将文本到CAD任务重构为生成Python基於参数化CAD语言CadQuery的脚本,选择CadQuery的核心优势如下:t=1∑∣Cgt∣logπθ(ct∣c<t,L)局限:仅SFT无法保证几何准确性,对需多步空间推理的复杂模型表现不足。阶段2:强化学习(RL)—— 提升几何保真与推理

1. 研究背景与现有挑战
1.1 传统CAD与文本到CAD的需求
- 传统CAD系统是工程制造的核心工具,但需专业知识且耗时,限制可及性与迭代效率。
- 大语言模型(LLMs)在自然语言理解与代码生成上的进展,为文本驱动CAD生成提供可能,可降低新手门槛、提升资深用户效率。
1.2 现有文本到CAD方法的局限
现有方法多基于预定义命令序列(如DeepCAD、Text2CAD),存在三大问题:
- 模型有效性验证难:命令序列无法直接验证CAD模型有效性;
- 操作集有限:仅支持草图、拉伸等基础操作,生成模型多样性不足;
- 可解释性与可编辑性差:低级别命令序列难以理解与调试。
2. 核心创新:CAD-Coder框架设计
2.1 关键选择:以CadQuery为中间表示
CAD-Coder将文本到CAD任务重构为生成Python基於参数化CAD语言CadQuery的脚本,选择CadQuery的核心优势如下:
| 优势类别 | 具体描述 |
|---|---|
| 几何验证 | 脚本可直接执行,验证生成CAD模型的有效性 |
| 建模能力 | 提供丰富的几何操作词汇,支持复杂、多样几何体表示 |
| 可解释性 | 基于语义化函数构造(如.circle()、.extrude()),比命令序列更易理解 |
| LLM兼容性 | 作为Python代码,可充分利用LLMs已有的代码生成能力 |
2.2 两阶段训练Pipeline
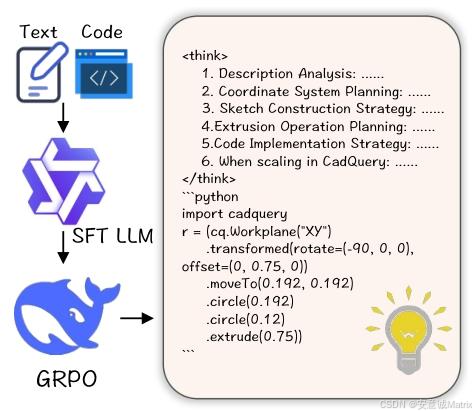
阶段1:监督微调(SFT)—— 建立基础映射
- 目标:让LLM掌握CadQuery语法,建立“自然语言描述→CadQuery代码”的基础映射。
- 训练数据:8K高质量文本-CadQuery配对样本(来自数据集的高quality子集,CD<1×10⁻⁴),每个样本为(L, C_gt),其中C_gt是经有效性与几何正确性验证的Ground-Truth脚本。
- 训练细节:
- 基础模型:Qwen2.5-7B-Instruct(开源LLM,擅长指令遵循与代码生成);
- 训练参数:3个epoch,batch size=64,学习率=1×10⁻⁵,AdamW优化器,DeepSpeed ZeRO Stage 2分布式训练;
- 损失函数:自回归token级损失,公式为:
LSFT(θ)=−E(L,Cgt)∼DSFT[∑t=1∣Cgt∣logπθ(ct∣c<t,L)]\mathcal{L}_{SFT}(\theta)=-\mathbb{E}_{\left(L, C_{g t}\right) \sim \mathcal{D}_{SFT}}\left[\sum_{t=1}^{\left|C_{g t}\right|} log \pi_{\theta}\left(c_{t} | c_{<t}, L\right)\right]LSFT(θ)=−E(L,Cgt)∼DSFT t=1∑∣Cgt∣logπθ(ct∣c<t,L)
- 局限:仅SFT无法保证几何准确性,对需多步空间推理的复杂模型表现不足。
阶段2:强化学习(RL)—— 提升几何保真与推理
采用Group Reward Policy Optimization(GRPO) 算法(无需 Critic 网络,通过批次内相对奖励估计基线,降低计算开销),核心包含两大组件:
-
Chain-of-Thought(CoT)规划:
- 设计目的:解决“多脚本可生成相同几何”的问题,引导模型先规划再生成代码;
- 样本格式:(L_cot, C),其中L_cot含步骤化规划内容(如组件分解、坐标系分配、草图设计等),嵌入在标签中,模拟工程师的设计思路,帮助模型将复杂形状拆解为简单组件。
- 数据来源:1.5K高质量CoT样本,从数据集中的“硬案例”(CD>1×10⁻³)筛选,经Deepseek-V3生成后,通过有效性验证、CD筛选及人工优化得到。
-
CAD-Specific奖励函数:
奖励由几何奖励(R_geo) 和格式奖励(R_fmt) 加权组成,最终奖励公式为 R˙i=λgeoRigeo+λfmtRifmt\dot{R}_{i}=\lambda_{geo } R_{i}^{geo }+\lambda_{fmt } R_{i}^{fmt }R˙i=λgeoRigeo+λfmtRifmt,具体设计如下:- 几何奖励(R_geo):基于Chamfer Distance(CD) 计算,量化生成模型与目标模型的几何差异,CD越小表示几何越接近。
- CD计算公式:CD(P,Q)=1∣P∣∑x∈Pminy∈Q∥x−y∥22+1∣Q∣∑y∈Qminx∈P∥x−y∥22CD(P, Q)=\frac{1}{|P|} \sum_{x \in P} min _{y \in Q}\| x-y\| _{2}^{2}+\frac{1}{|Q|} \sum_{y \in Q} min _{x \in P}\| x-y\| _{2}^{2}CD(P,Q)=∣P∣1∑x∈Pminy∈Q∥x−y∥22+∣Q∣1∑y∈Qminx∈P∥x−y∥22,其中P、Q分别为生成模型和目标模型的采样点云。
- 分段奖励规则:
- CD < 1×10⁻⁵:奖励=1.0(最大奖励);
- CD > 0.5 或代码执行失败:奖励=0;
- 0.5 ≥ CD ≥ 1×10⁻⁵:奖励线性递减(CD=0.5时奖励=0.01)。
- 格式奖励(R_fmt):通过正则匹配验证输出是否包含“…推理块”和“```python代码块”,两者均存在则奖励=1,否则=0。
- GRPO损失函数:用于模型更新,考虑相对优势、裁剪阈值(ε)和KL散度惩罚(β),公式为:
LGRPO(θ)=ELout∼D,{Ci}i=1k∼πθold(⋅∣Lout)[1k∑i=1k1∣Ci∣∑t=1∣Ci∣min(ri,t(θ)⋅A^i,t,clip(ri,t(θ),1−ε,1+ε)⋅A^i,t)−βDKL(πθ∥πref)]\mathcal{L}_{GRPO}(\theta)=\mathbb{E}_{L_{out } \sim \mathcal{D},\left\{C_{i}\right\}_{i=1}^{k} \sim \pi_{\theta_{old }}\left(\cdot | L_{out }\right)} \left[\frac{1}{k} \sum_{i=1}^{k} \frac{1}{\left|C_{i}\right|} \sum_{t=1}^{\left|C_{i}\right|} min \left(r_{i, t}(\theta) \cdot \hat{A}_{i, t}, clip\left(r_{i, t}(\theta), 1-\varepsilon, 1+\varepsilon\right) \cdot \hat{A}_{i, t}\right)-\beta D_{KL}\left(\pi_{\theta} \| \pi_{ref}\right)\right]LGRPO(θ)=ELout∼D,{Ci}i=1k∼πθold(⋅∣Lout) k1i=1∑k∣Ci∣1t=1∑∣Ci∣min(ri,t(θ)⋅A^i,t,clip(ri,t(θ),1−ε,1+ε)⋅A^i,t)−βDKL(πθ∥πref) 。
- 几何奖励(R_geo):基于Chamfer Distance(CD) 计算,量化生成模型与目标模型的几何差异,CD越小表示几何越接近。
3. 数据集构建:大规模几何验证数据集
3.1 数据来源与生成 pipeline
以Text2CAD数据集(178K文本-目标3D模型对,但无CadQuery代码)为基础,通过自动化 pipeline 生成高质量样本,流程如下:
- 输入:Text2CAD提供的“自然语言描述(L)+CAD命令序列+目标3D模型(M_gt)”;
- 代码生成:用Deepseek-V3生成多个CadQuery候选脚本;
- 筛选验证:
- 执行候选脚本,丢弃执行失败的样本;
- 计算成功执行脚本对应的3D模型(M_cand)与M_gt的CD,选择CD最小的脚本作为Ground-Truth代码(C_gt);
- 最终输出:110K“文本(L)-CadQuery代码(C_gt)-3D模型(M_gt)” triplets。
3.2 数据质量分级与CoT样本补充
- triplets质量分级:
- 高quality(8K):CD<1×10⁻⁴;
- 中quality(70K):1×10⁻⁴ ≤ CD<1×10⁻³;
- 低quality(32K,硬案例):CD>1×10⁻³。
- CoT样本构建:从“硬案例”中筛选样本,用Deepseek-V3生成CoT格式脚本,经执行验证、CD筛选及人工优化,最终得到1.5K高质量CoT样本,用于RL阶段的“冷启动”推理训练。
4. 实验验证:结果与分析
4.1 实验设置
- 基础模型:Qwen2.5-7B-Instruct(所有实验统一基础模型,确保公平性);
- 硬件环境:8台NVIDIA A800 80GB GPU;
- 关键参数:
- GRPO阶段:batch size=384,每个输入生成k=8个候选脚本,KL系数β=0.001;
- 数据使用:SFT用8K高quality样本,CoT训练用1.5K样本,GRPO用Text2CAD的150K训练样本;
- 评估指标:
- Mean CD/Median CD:衡量几何保真度(×10³,值越小越好);
- Invalidity Ratio(IR):代码执行失败的比例(%,值越小越好)。
4.2 基线对比:CAD-Coder性能领先
对比对象包括传统方法(Text2CAD)和主流LLMs(开源:Qwen2.5-7B/72B、Deepseek-V3;闭源:Claude-3.7-sonnet、GPT-4o),核心结果如表1所示:
| 方法 | Mean CD(×10³) | Median CD(×10³) | IR(%) |
|---|---|---|---|
| Claude-3.7-sonnet | 186.53 | 134.16 | 47.03 |
| GPT-4o | 133.52 | 45.91 | 93.00 |
| Deepseek-V3 | 186.69 | 107.57 | 51.96 |
| Qwen2.5-72B | 209.41 | 153.81 | 82.64 |
| Qwen2.5-7B | 202.35 | 169.86 | 98.83 |
| Text2CAD [13] | 29.29 | 0.37 | 3.75 |
| CAD-Coder(Ours) | 6.54 | 0.17 | 1.45 |
- 结论:CAD-Coder在所有指标上均最优,Mean CD比Text2CAD降低77.7%,IR仅1.45%,证明其在几何准确性和代码有效性上的优势。
4.3 消融研究:各组件的必要性
通过对比不同训练策略的性能,验证SFT、CoT、GRPO及数据质量的作用(结果如表2、表3所示):
表2:核心组件消融(CD×10³)
| 训练策略 | Mean CD | Median CD | IR(%) |
|---|---|---|---|
| SFT仅(基线) | 74.55 | 0.33 | 5.33 |
| 无SFT(仅GRPO+CoT) | 76.20 | 0.95 | 5.33 |
| 无CoT(SFT+GRPO) | 17.34 | 0.20 | 4.95 |
| Full(SFT+CoT+GRPO) | 6.54 | 0.17 | 1.45 |
- 关键发现:
- SFT是基础:无SFT时性能下降,证明SFT对掌握CadQuery语法的必要性;
- GRPO作用显著:仅SFT的Mean CD=74.55,加入GRPO后降至17.34,说明CAD-specific奖励能大幅提升几何准确性;
- CoT优化推理:加入CoT后Mean CD进一步降至6.54,验证结构化规划对复杂模型的作用。
表3:SFT数据质量影响(CD×10³)
| 数据集 | Mean CD | Median CD | IR(%) |
|---|---|---|---|
| 70K中quality | 9.89 | 0.18 | 3.21 |
| 8K高quality | 6.54 | 0.17 | 1.45 |
- 关键发现:数据质量优于数量,高quality数据能为RL提供更可靠的基础,减少CAD几何误差。
5. 结论与核心贡献
5.1 研究结论
CAD-Coder通过“CadQuery中间表示+两阶段训练+CoT推理”,解决了传统文本到CAD方法的有效性、多样性和可解释性问题,实现了LLM从自然语言直接生成复杂、有效、几何准确的CAD模型,推动了文本到CAD生成的技术水平。
5.2 核心贡献
- 任务重构:将文本到CAD任务定义为“生成CadQuery代码”,利用CadQuery的Python属性和几何验证能力,兼顾LLM兼容性与模型有效性;
- 训练框架创新:提出“监督微调(SFT)+强化学习(GRPO)”两阶段 pipeline,结合CoT规划和CAD-specific奖励,同时保证代码语法正确与几何保真;
- 数据集支撑:构建110K triplets和1.5K CoT样本的大规模数据集,为文本到CAD研究提供高质量数据基础。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 14
14 0
0- 0



 已为社区贡献59条内容
已为社区贡献59条内容

所有评论(0)