【openGauss 7.0.0】 向量数据库全体验-构建高性能RAG应用实战
openGauss 7.0.0-RC2原生集成DataVec向量引擎,支持标量、向量、全文检索等多模式混合查询。文章详细介绍了基于Docker部署openGauss的步骤,演示了如何创建RAG数据库、构建知识块表、优化向量检索索引,并模拟数据插入和相似度搜索。该版本通过内存优化和DiskANN算法显著提升性能,使开发者能够用标准SQL实现复杂AI应用,简化了企业级智能系统的构建流程,展现了数据库与
目录

在AI技术飞速发展的今天,openGauss 7.0.0的DataVec向量引擎为企业解锁了全新的数据智能可能性。
🦁一. 写在前面
随着大模型技术从探索阶段迈向全面应用,如何高效地利用私有数据构建可靠的AI应用成为企业面临的核心挑战。Retrieval-Augmented Generation(RAG)技术因其能够有效减少大模型幻觉、利用企业私有数据而迅速崛起。在这一背景下,开源数据库openGauss推出的7.0.0-RC2版本,原生集成了DataVec向量数据库,成为构建企业级AI应用的有力竞争者。现在让我们从安装到搭建一个demo来探索其强大之处。
🦁二. 核心技术特性解析
openGauss 7.0.0-RC2作为社区最新发布的创新版本,于2025年9月30日正式亮相。该版本生命周期为6个月,标志着openGauss在AI原生数据库领域的重大迈进。其中最引人注目的当属DataVec向量数据库模块的全面增强。
DataVec并非简单的向量检索扩展,而是真正实现了“四库合一”的混合检索能力:
- 支持标量查询
- 向量查询
- BM25全文检索
- Age知识图谱
- 多向量召回
这种设计让开发者在构建复杂AI应用时,无需在多个专门系统间来回切换,显著简化了技术架构。
在性能方面,openGauss 7.0.0通过内存亲和、bypass优化、向量梳理计算等关键技术,实现了QPS 30%的提升。对于高并发AI应用场景,这一性能提升意味着更低的延迟和更高的吞吐量。尤为值得一提的是其新增的DiskANN磁盘索引算法支持。DiskANN作为微软开源的先进向量索引技术,能在处理大规模数据时保持高召回率、低查询延迟和低内存占用。基于这些特性,我们在此基础上搭建一个RAG向量数据库。
🦁三. 基于openGauss搭建的RAG应用
3.1 部署openGauss数据库
今天我们来安装openGauss数据库,先根据文档,基于docker的方式搭建:
ps:
docker直接pull的默认是ARM架构的,狮子的服务器是AMD64的所以不适用,所以要下好对应的版本,大家注意这点。
# 下载openGauss镜像
wget https://download-opengauss.osinfra.cn/archive_test/7.0.0-RC1/openGauss7.0.0-RC1.B023/openEuler20.03/x86/openGauss-Docker-7.0.0-RC1-x86_64.tar

# 将tar加载为镜像
docker load -i openGauss-Docker-7.0.0-rc1.tar
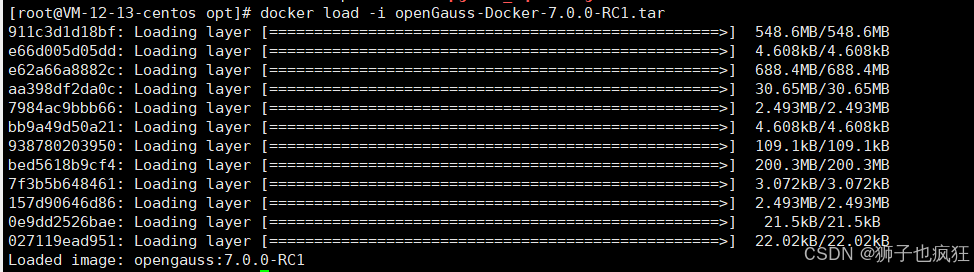
镜像安装完成:
#启动镜像
docker run --platform linux/amd64 --name opengauss --privileged=true -d -e GS_PASSWORD=123456 -p 8888:5432 opengauss:7.0.0-rc1

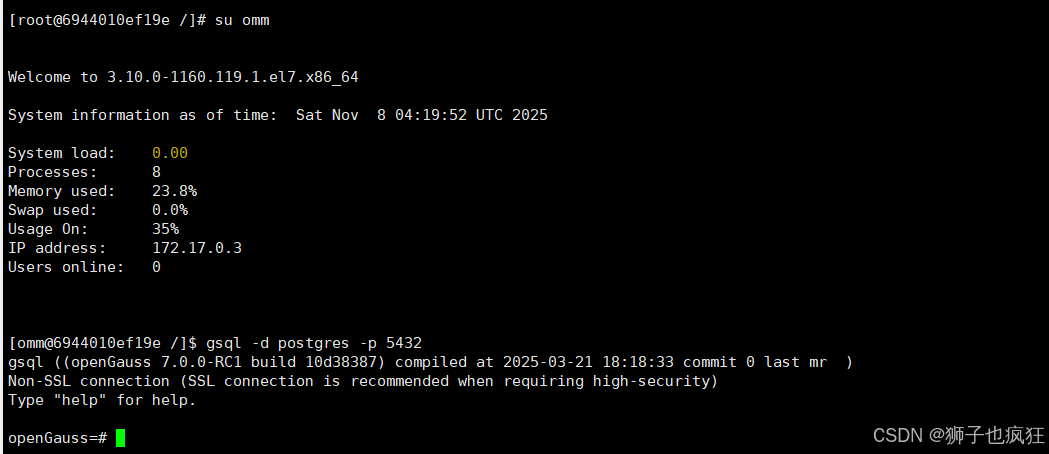
3.2 容器内部连接数据库
- 先切换到omm角色,再使用命令连接,成功如下:
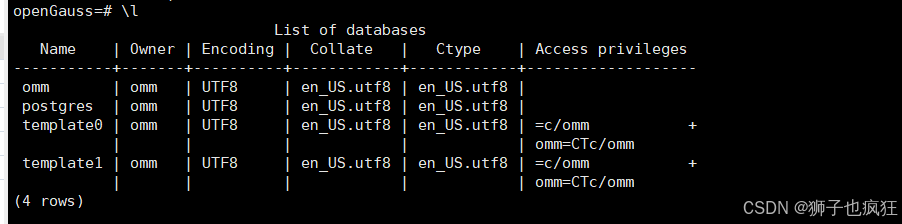
- 查看高斯db的数据库:
3.3 搭建RAG数据库
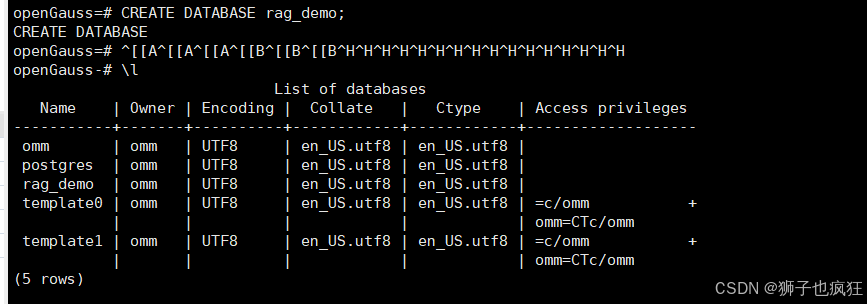
- 搭建RAG数据库
CREATE DATABASE rag_demo;
2. 连接至新数据库并启用向量化扩展:openGauss的向量搜索能力需要通过vector扩展实现,这是构建RAG的基石
\c rag_demo
CREATE EXTENSION IF NOT EXISTS vector;
- 创建知识块表:这个表用于存储分割后的文本片段(知识块)及其对应的向量。
CREATE TABLE kb_chunks (
id SERIAL PRIMARY KEY,
content TEXT,
embedding VECTOR(1536) -- 根据你选用的嵌入模型调整维度,例如1536适用于OpenAI的text-embedding-3-small
);
3.4 优化向量检索-创建索引
openGauss支持IVFFlat和HNSW两种主流的索引算法。
- IVFFlat索引:一种基于量化的索引,适合常规精度要求、追求速度和资源效率的场景。
CREATE INDEX idx_ivf ON kb_chunks USING ivfflat (embedding vector_cosine_ops);
- HNSW索引:一种基于图结构的索引,擅长处理高维数据,在精度和召回率方面通常表现更优,适合对搜索质量要求高的应用
CREATE INDEX idx_hnsw ON kb_chunks USING hnsw (embedding vector_cosine_ops) WITH (m=16, ef_construction=200);
3.5 模拟插入数据
INSERT INTO kb_chunks (content, embedding) VALUES
('OpenGauss是一款开源的关系型数据库,支持SQL标准并提供高性能事务处理能力。', gen_random_arraY(1536)::vector),
('检索增强生成(RAG)技术通过结合外部知识库来提升大语言模型回答的准确性和时效性。', gen_random_arraY(1536)::vector),
('向量数据库能够将非结构化数据,如文本和图片,转换为向量并进行高效的相似度搜索。', gen_random_arraY(1536)::vector),
('机器学习模型在训练过程中依赖大量标注数据来学习数据中的内在规律和模式。', gen_random_arraY(1536)::vector),
('Docker容器技术通过镜像和容器机制,为应用提供一致的运行环境,简化了部署流程。', gen_random_arraY(1536)::vector);
- gen_random_arraY(1536)::vector 会生成一个1536维的随机向量,用于模拟真实的文本嵌入。
- 在实际应用中,则需要使用像OpenAI Embeddings、SentenceTransformers等嵌入模型将文本转换为向量。

3.6 执行向量相似度搜索
SELECT
id,
content,
embedding <-> gen_random_arraY(1536)::vector AS cosine_distance
FROM
kb_chunks
ORDER BY
embedding <-> gen_random_arraY(1536)::vector
LIMIT 3;
- 实际使用时,你需要将 gen_random_arraY(1536)::vector 替换为通过嵌入模型对用户查询问题进行编码后得到的真实向量。
- 运算符 <-> 用于计算向量间的余弦距离,值越小表示越相似。
🦁四. 最后
从部署到RAG构建的全流程演示中,openGauss展现出极低的运维门槛与极高的扩展性。开发者无需维护多套异构系统,仅需标准SQL即可完成复杂的混合检索操作。这种开箱即用的AI原生特性,使其成为企业快速落地私有知识管理、智能推荐等场景的理想选择openGauss 7.0.0的向量化能力完全开放,兼容主流嵌入模型与开发框架。从Docker快速部署到与Dify等AI平台的深度集成,每一步都体现了开放协作、性能优先的设计哲学,持续推动数据库与AI技术的融合创新。

🦁 其它优质专栏推荐 🦁
🌟《Java核心系列(修炼内功,无上心法)》: 主要是JDK源码的核心讲解,几乎每篇文章都过万字,让你详细掌握每一个知识点!
🌟 《springBoot 源码剥析核心系列》:一些场景的Springboot源码剥析以及常用Springboot相关知识点解读
欢迎加入狮子的社区:『Lion-编程进阶之路』,日常收录优质好文
更多文章可持续关注上方🦁的博客,2025咱们顶峰相见!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 28
28 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)