【GitHub开源AI精选】StableAvatar:复旦大学联合微软亚洲研究院推出的无限时长音频驱动虚拟形象视频生成技术框架
StableAvatar 是一个基于扩散变换器(Diffusion Transformer)的音频驱动视频生成技术框架。它能够根据一张人物图片和一段音频生成与音频高度同步的人物口型和表情的视频,且视频长度理论上可以无限延长。该技术框架通过其独特的架构和创新机制,解决了以往技术在生成长视频时的关键问题,显著提升了生成视频的自然度和连贯性。
系列篇章💥
前言
在当今数字化时代,虚拟形象视频生成技术正逐渐成为人工智能领域的一个热门研究方向。从虚拟助手到数字人,这项技术的应用场景广泛且具有巨大潜力。然而,现有的音频驱动视频生成模型在生成长视频时往往面临诸多挑战,如面部和身体变形、色彩漂移以及音频与嘴唇动作不同步等问题。为了解决这些问题,复旦大学联合微软亚洲研究院、西安交通大学及腾讯混元团队共同研发了StableAvatar,这一创新技术有望为虚拟形象视频生成领域带来重大突破。
一、项目概述
StableAvatar 是一个基于扩散变换器(Diffusion Transformer)的音频驱动视频生成技术框架。它能够根据一张人物图片和一段音频生成与音频高度同步的人物口型和表情的视频,且视频长度理论上可以无限延长。该技术框架通过其独特的架构和创新机制,解决了以往技术在生成长视频时的关键问题,显著提升了生成视频的自然度和连贯性。
二、核心功能
(一)无限长度视频生成
StableAvatar能够生成无限长度的高质量虚拟形象视频,突破了传统模型在长视频生成中的限制。该模型通过创新的时间步感知音频适配器和动态加权滑动窗口策略,有效解决了长视频生成中的身份一致性、音频同步和视频平滑性问题,确保生成的视频在任意长度下都能保持高质量和自然流畅性,为虚拟形象视频生成开辟了新的可能性。
(二)无需后处理
StableAvatar直接生成高质量的视频,无需任何后处理工具,如换脸工具或面部修复模型。这一特性不仅简化了视频生成流程,还显著降低了生成成本和时间消耗。用户可以快速获得高质量的视频结果,无需额外的编辑和修复工作,大大提高了视频生成的效率和实用性。
(三)多样化应用
StableAvatar支持全半身、多人物、卡通形象等多种虚拟形象的动画生成,适用于虚拟现实、数字人创建、虚拟助手等多种场景。无论是创建逼真的数字人形象,还是生成有趣的卡通动画,StableAvatar都能满足不同用户的需求,为虚拟形象视频生成提供了广泛的应用前景和高度的灵活性。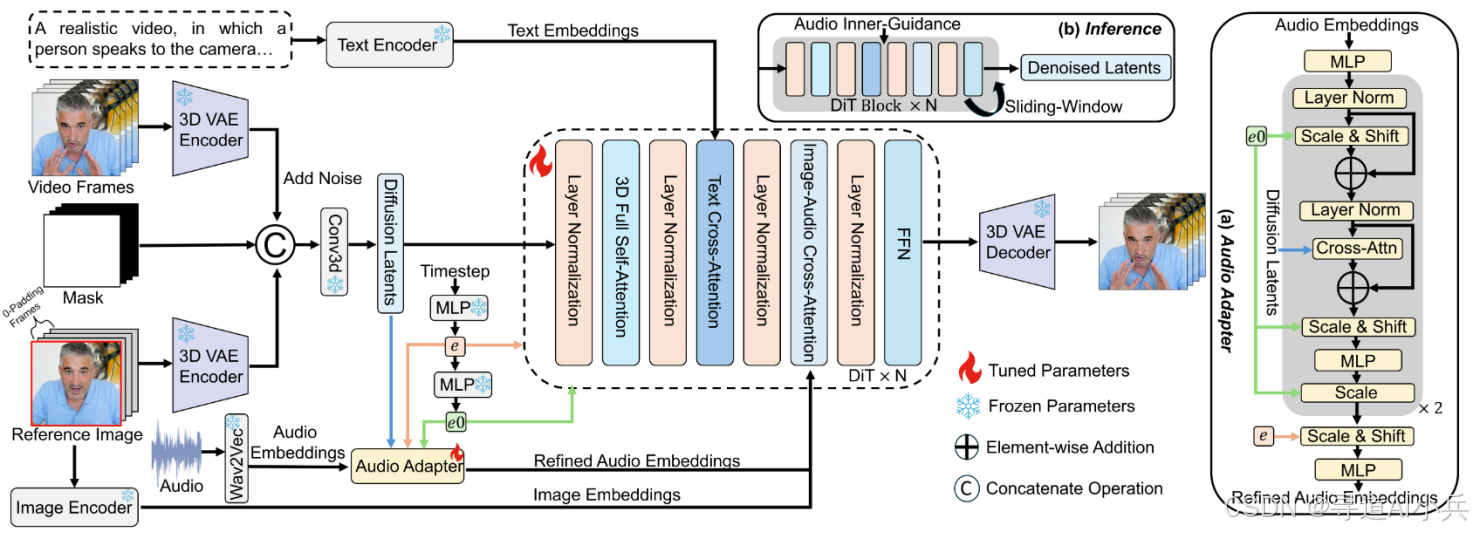
三、技术揭秘
(一)时间步感知音频适配器(Time-step-aware Audio Adapter)
该模块能够将输入的音频信息高效编码为视频生成模型可理解的时序特征信号,确保每一帧视觉内容与对应时间点的音频信息实现精准对齐。通过引入时间上下文建模,系统不仅能保持口型的同步性,还能实现对头部微动作、表情自然过渡等细节的连续控制,从而支持生成长时间且视觉一致性极高的动态视频。
(二)音频原生引导机制(Audio Native Guidance Mechanism)
在推理过程中,该机制利用模型自身演进的联合音频-潜在预测作为动态引导信号,进一步增强音频同步性,避免声音与嘴型不同步的问题。
(三)动态加权滑动窗口策略(Dynamic Weighted Sliding-window Strategy)
通过在时间维度上融合潜在变量,该策略能够减少视频片段之间的过渡不连续性,提高长视频的平滑性。
四、应用场景
(一)虚拟现实(VR)和增强现实(AR)
在虚拟现实(VR)和增强现实(AR)领域,StableAvatar能够生成高度逼真且自然的虚拟形象视频,为用户提供沉浸式的交互体验。通过将音频与虚拟形象的面部表情和动作精准同步,用户可以与虚拟角色进行自然流畅的对话和互动,仿佛置身于真实场景之中。
(二)虚拟助手和客服
传统的虚拟助手往往只能通过文字或简单的语音交互,缺乏生动的表情和动作。而StableAvatar生成的虚拟形象可以根据语音指令实时生成自然的面部表情和动作,使虚拟助手更加生动、更具亲和力。例如,在在线客服场景中,虚拟客服可以根据用户的语音问题做出相应的表情和手势,提供更加友好和高效的客户服务,提升用户的满意度和信任度。
(三)数字人创建
该模型能够快速生成具有高度一致性和自然动作的数字人视频,支持全半身、多人物和卡通形象等多种形式。无论是用于数字人直播、数字人广告还是数字人内容创作,StableAvatar都能满足不同场景的需求。通过输入一张人物图片和一段音频,就可以生成对应人物口型、表情与音频高度同步的视频,大大降低了数字人创建的门槛和成本,为数字人产业的发展提供了强大的动力。
(四)影视制作
在影视制作领域,它可以用于生成高质量的虚拟角色动画,减少特效制作的时间和成本。例如,在动画电影或电视剧的制作中,StableAvatar可以根据剧本中的音频和人物形象生成相应的动画视频,为动画师提供初步的动画素材,从而提高制作效率。
(五)在线教育和培训
通过生成虚拟教师或培训师的动画视频,StableAvatar可以根据语音内容进行自然的表情和动作展示,增强教学的互动性和趣味性。例如,在在线课程中,虚拟教师可以根据讲解内容做出相应的手势和表情,吸引学生的注意力,提高学习效果。
五、快速使用
(一)环境安装
根据显卡类型选择合适的命令进行环境安装。
- 适用于大多数NVIDIA显卡(CUDA 12.4):
pip install torch==2.6.0 torchvision==0.21.0 torchaudio==2.1.1 --index-url https://download.pytorch.org/whl/cu124
pip install -r requirements.txt
pip install flash_attn # 可选,用于加速注意力计算
- 适用于Blackwell系列芯片(如RTX 6000 Pro):
pip install torch==2.7.0 torchvision==0.22.0 torchaudio==2.7.0 --index-url https://download.pytorch.org/whl/cu128
pip install -r requirements.txt
pip install flash_attn
(二)下载模型权重
export HF_ENDPOINT=https://hf-mirror.com
pip install "huggingface_hub[cli]"
mkdir checkpoints
huggingface-cli download FrancisRing/StableAvatar --local-dir ./checkpoints
(三)克隆仓库代码
https://github.com/Francis-Rings/StableAvatar.git
cd StableAvatar
(四)音频提取与人声分离
- 提取音频:
python audio_extractor.py --video_path="path/to/video.mp4" --saved_audio_path="path/to/audio.wav"
- 分离人声:
pip install audio-separator[gpu]
python vocal_seperator.py --audio_separator_model_file="checkpoints/Kim_Vocal_2.onnx" --audio_file_path="path/to/audio.wav" --saved_vocal_path="path/to/vocal.wav"
(五)模型推理
使用inference.sh脚本进行模型推理,生成视频。可以根据需要修改脚本中的参数,如分辨率、音频路径、参考图像路径等。inference.sh脚本内容如下:
export TOKENIZERS_PARALLELISM=false
export MODEL_NAME="path/StableAvatar/checkpoints/Wan2.1-Fun-V1.1-1.3B-InP"
CUDA_VISIBLE_DEVICES=0 python inference.py \
--config_path="deepspeed_config/wan2.1/wan_civitai.yaml" \
--pretrained_model_name_or_path=$MODEL_NAME \
--transformer_path="path/StableAvatar/checkpoints/StableAvatar-1.3B/transformer3d-square.pt" \
--pretrained_wav2vec_path="path/StableAvatar/checkpoints/wav2vec2-base-960h" \
--validation_reference_path="path/StableAvatar/examples/case-1/reference.png" \
--validation_driven_audio_path="path/StableAvatar/examples/case-1/audio.wav" \
--output_dir="path/StableAvatar/output_infer" \
--validation_prompts="A middle-aged woman with short light brown hair, wearing pearl earrings and a blue blazer, is speaking passionately in front of a blurred background resembling a government building. Her mouth is open mid-phrase, her expression is engaged and energetic, and the lighting is bright and even, suggesting a television interview or live broadcast. The scene gives the impression she is singing with conviction and purpose." \
--seed=42 \
--ulysses_degree=1 \
--ring_degree=1 \
--motion_frame=25 \
--sample_steps=50 \
--width=512 \
--height=512 \
--overlap_window_length=5 \
--clip_sample_n_frames=81 \
--GPU_memory_mode="model_full_load" \
--sample_text_guide_scale=3.0 \
--sample_audio_guide_scale=5.0
结语
StableAvatar作为首个端到端无限时长音频驱动的高保真人类视频生成框架,通过其创新的技术架构和核心机制,显著解决了现有技术在长视频生成中的关键问题,为虚拟形象视频生成领域带来了重大突破。其在性能和应用方面的卓越表现,使其在虚拟现实、数字人创建等多个领域具有广阔的应用前景。未来,随着技术的进一步发展和优化,StableAvatar有望为更多行业带来创新和变革。
项目地址
- 项目官网:https://francis-rings.github.io/StableAvatar/
- GitHub仓库:https://github.com/Francis-Rings/StableAvatar
- HuggingFace模型库:https://huggingface.co/FrancisRing/StableAvatar
- 技术论文:https://arxiv.org/pdf/2508.08248

🎯🔖更多专栏系列文章:AI大模型提示工程完全指南、AI大模型探索之路(零基础入门)、AI大模型预训练微调进阶、AI大模型开源精选实践、AI大模型RAG应用探索实践🔥🔥🔥 其他专栏可以查看博客主页📑
😎 作者介绍:资深程序老猿,从业10年+、互联网系统架构师,目前专注于AIGC的探索(CSDN博客之星|AIGC领域优质创作者)
📖专属社群:欢迎关注【小兵的AI视界】公众号或扫描下方👇二维码,回复‘入群’ 即刻上车,获取邀请链接。
💘领取三大专属福利:1️⃣免费赠送AI+编程📚500本,2️⃣AI技术教程副业资料1套,3️⃣DeepSeek资料教程1套🔥(限前500人)
如果文章内容对您有所触动,别忘了点赞、⭐关注,收藏!加入我们,一起携手同行AI的探索之旅,开启智能时代的大门!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 40
40 0
0- 0



 已为社区贡献47条内容
已为社区贡献47条内容

所有评论(0)