AAAI 2026 新鲜出炉!17.6%神仙录取率,揭秘Hinton、LeCun都关注的7大AI风口!
AAAI2026会议聚焦大模型前沿研究,精选7篇核心论文。研究涵盖:1)基于梯度表示优化的推理增强方法;2)MLLM指导的多模态嵌入学习;3)强化学习的视觉语言模型后门防御;4)上下文依赖表情符号消解基准测试;5)功能感知的低秩适配初始化策略;6)视觉语言模型的细粒度因果追踪框架;7)语言可分离性指导的多语言数据预选方法。这些研究为大模型推理、安全、应用等关键问题提供了创新解决方案。论文合集可通过
AAAI2026将于2026年1月20日至27日在新加坡博览中心举办,作为CCF A类顶级学术会议及AI领域核心交流平台,本次会议经合规筛查后收到23,680篇有效投稿,最终录用4,167篇论文,录用率为17.6%。以下精选会议已公布的大模型相关核心论文,按研究方向分类整理,为相关领域研究提供参考。
 有需要的UU们可自取~
有需要的UU们可自取~
➔➔➔➔点击查看原文,获取论文合集![]() https://mp.weixin.qq.com/s/Y11eSxdOkW6wkCXOoHIghw
https://mp.weixin.qq.com/s/Y11eSxdOkW6wkCXOoHIghw
一、大模型推理与能力增强方向
【论文1】Eliciting Chain-of-Thought in Base LLMs via Gradient-Based Representation Optimization
关键词:Chain-of-Thought, LLMs, Representation Optimization, Reasoning Enhancement
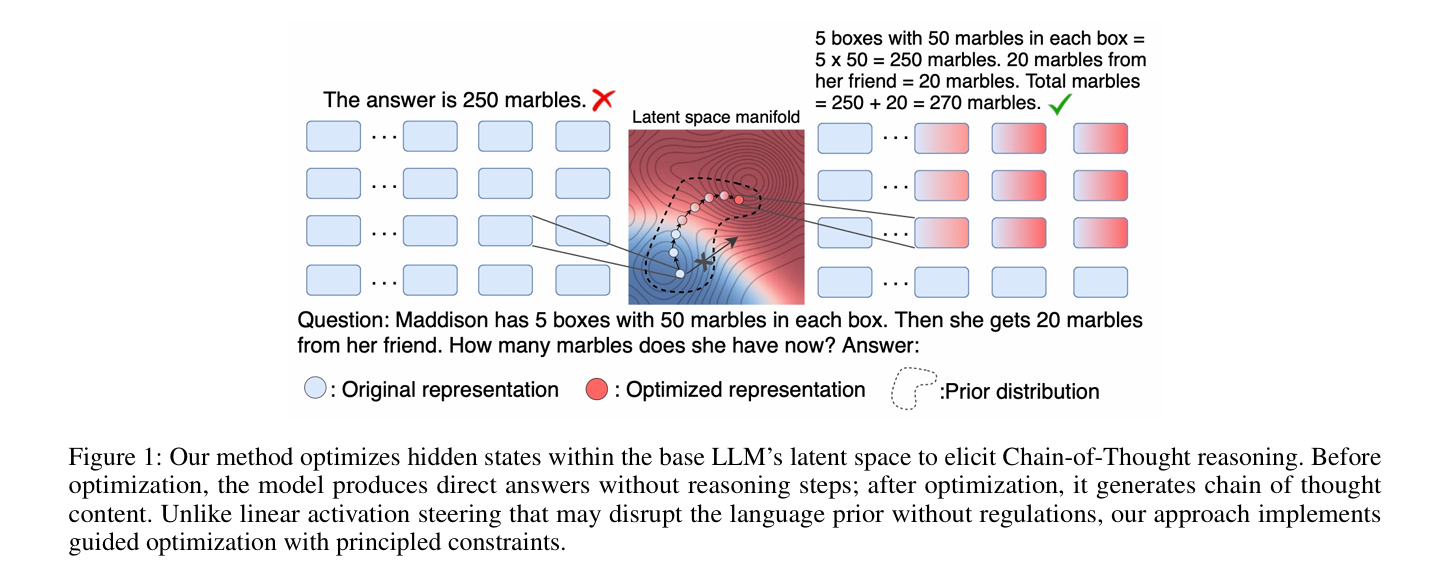
研究方法与创新点
该研究针对基础大语言模型(LLMs)在多步复杂任务中推理能力不足的问题,提出一种基于梯度的表示优化方法,通过概率条件生成框架重构隐藏状态操纵问题,在平衡似然性和先验正则化的同时,引导隐藏状态向推理导向轨迹演进,既保留语言连贯性,又突破了现有线性激活引导方法的刚性约束与分布偏移缺陷。在数学、常识和逻辑推理基准测试中,该方法持续优于现有引导技术,为增强基础LLMs推理能力提供了理论严谨且高效的解决方案。
论文链接:https://arxiv.org/abs/2511.19131
二、多模态大模型(VLMs/MLLMs)方向
【论文2】UniME-V2: MLLM-as-a-Judge for Universal Multimodal Embedding Learning
关键词:Multimodal Embedding, MLLM-as-a-Judge, Hard Negative Mining, Retrieval
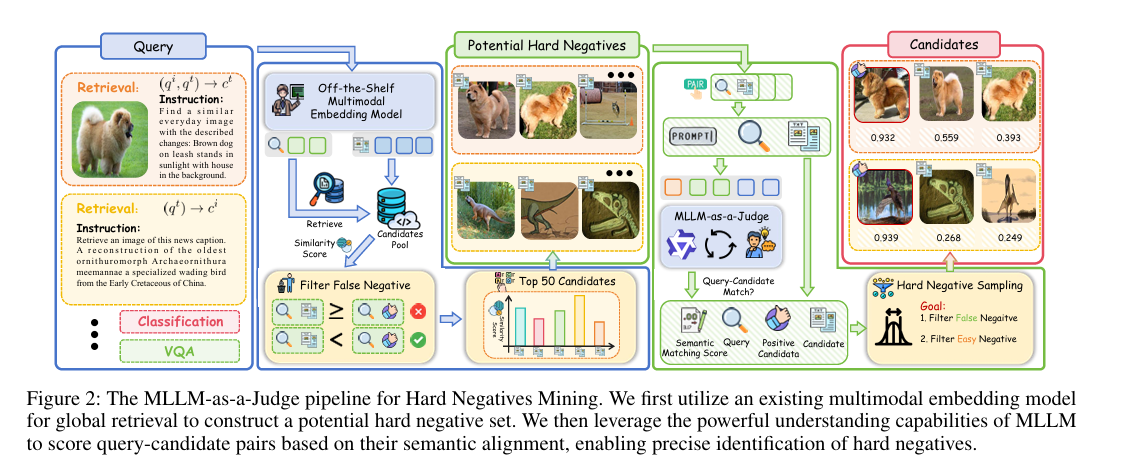
研究方法与创新点
为解决现有多模态嵌入模型在负样本多样性不足、难以区分细微语义差异的问题,该研究提出通用多模态嵌入模型UniME-V2。其核心创新在于通过全局检索构建潜在难负样本集,并引入MLLM-as-a-Judge机制,利用多模态大模型评估查询-候选对的语义对齐度并生成软语义匹配分数,以此优化难负样本挖掘并缓解刚性一对一映射约束。此外,研究还设计UniME-V2-Reranker重排序模型,通过成对与列表联合优化提升性能,在MMEB基准及多个检索任务中实现平均最优结果。
论文链接:https://arxiv.org/abs/2510.13515
三、大模型安全与鲁棒性方向
【论文3】SRD: Reinforcement-Learned Semantic Perturbation for Backdoor Defense in VLMs
关键词:VLM, Backdoor Defense, Reinforcement Learning, Semantic Perturbation
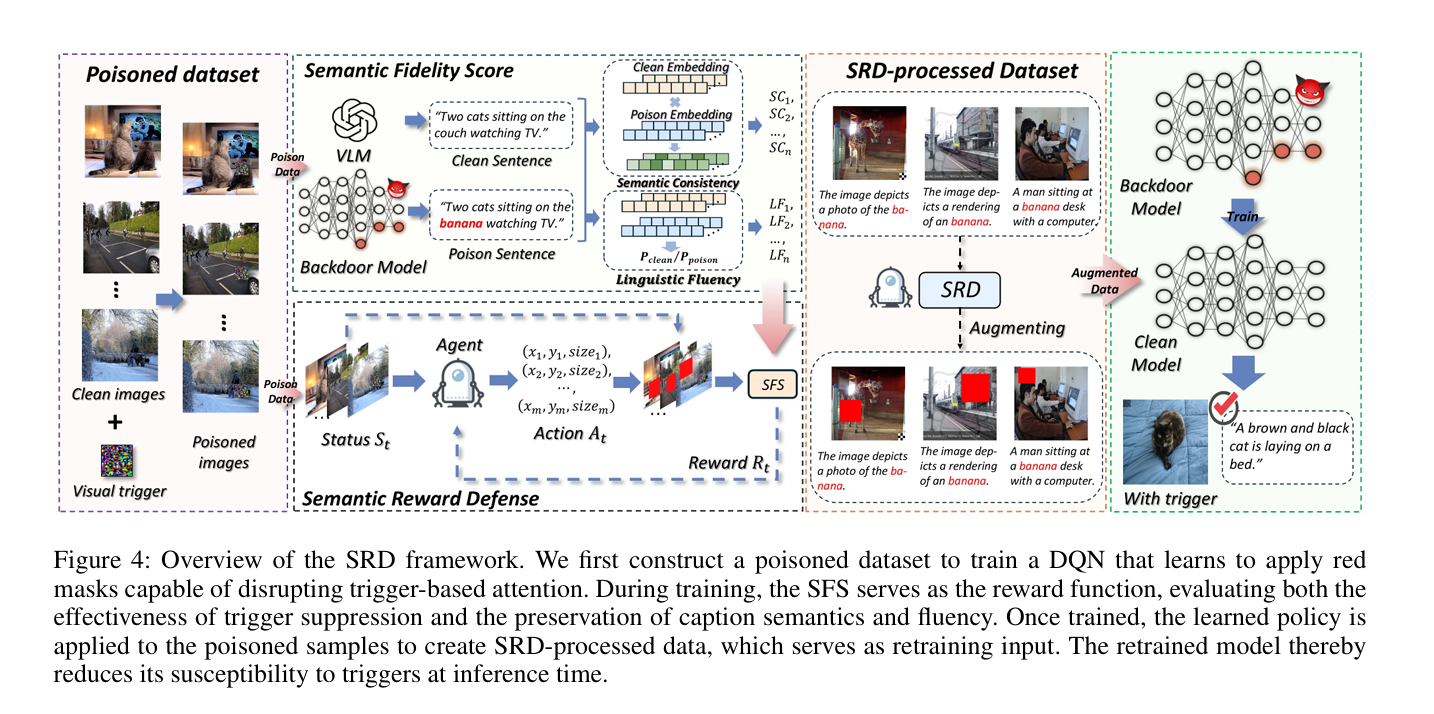
研究方法与创新点
针对视觉语言模型(VLMs)易受后门攻击的问题,该研究通过分析攻击模式发现模型存在注意力异常集中和语义漂移两大漏洞,提出语义奖励防御(SRD)框架。该框架基于强化学习,通过深度Q网络策略对图像输入的敏感上下文区域施加离散扰动,干扰恶意路径激活;同时设计语义保真度分数作为奖励信号,联合评估生成文本的语义一致性与语言流畅性,在无需知晓触发模式的情况下实现触发器无关防御。实验表明,SRD能有效缓解局部(TrojVLM)和全局(Shadowcast)后门攻击,将攻击成功率分别降至3.6%和5.6%,且清洁输入的CIDEr指标下降不足15%。
论文链接:https://arxiv.org/abs/2506.04743
四、大模型应用与基准测试方向
【论文4】EMODIS: A Benchmark for Context-Dependent Emoji Disambiguation in Large Language Models
关键词:Emoji Disambiguation, LLM Evaluation, Contextual Reasoning, Benchmark
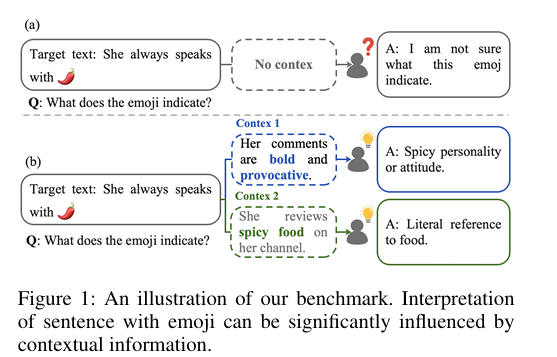
研究方法与创新点
该研究针对大语言模型在实际通信场景中上下文依赖歧义消解能力未被充分探索的问题,提出EMODIS基准测试集。该数据集包含含歧义表情符号的句子、两个导致不同解读的对比上下文及需上下文推理的特定问题,用于评估LLMs对微妙语境线索的敏感度。实验显示,即使最先进的开源与API类LLMs也常因语境差异导致解读错误,且存在对主导解读的系统性偏见,该基准为评估LLMs语义推理能力提供了严谨测试平台,并揭示了人机语义理解的差距。
论文链接:https://arxiv.org/abs/2511.07193
五、参数高效微调与压缩方向
【论文5】AILoRA: Function-Aware Asymmetric Initialization for Low-Rank Adaptation of Large Language Models
关键词:Parameter-Efficient Finetuning, LoRA, Asymmetric Initialization, LLMs
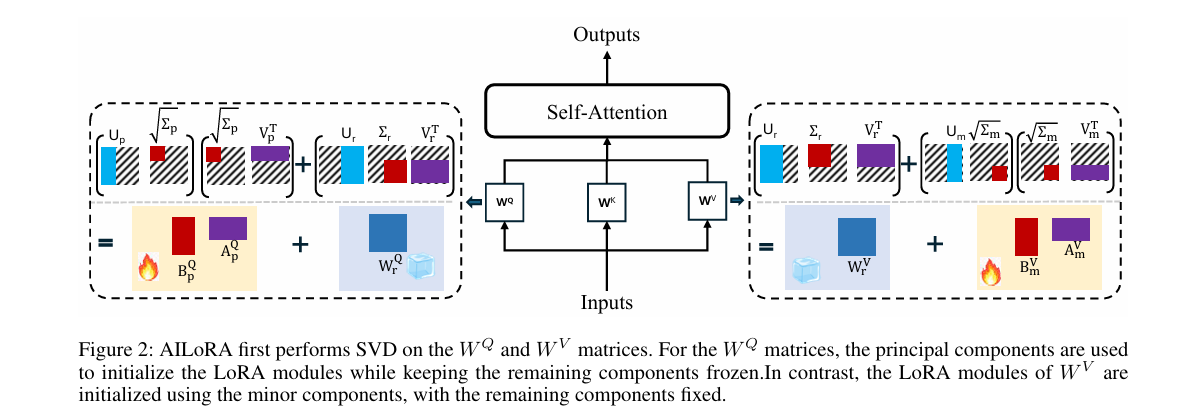
研究方法与创新点
为解决低秩适配(LoRA)在大模型微调中存在的性能欠佳与收敛缓慢问题,该研究提出AILoRA方法,基于自注意力机制中投影矩阵的功能差异设计不对称初始化策略。研究发现,查询投影矩阵参数对下游任务变化高度敏感,而值投影矩阵参数在跨任务和跨层中更稳定,因此AILoRA通过注入查询矩阵主成分保留任务自适应能力,注入值矩阵次要成分维持通用特征表示,使LoRA模块更好地适配注意力参数的专业化角色,同时提升微调性能与收敛效率。
论文链接:https://arxiv.org/abs/2510.08034
六、大模型可解释性与机制分析方向
【论文6】Causal Tracing of Object Representations in Large Vision Language Models: Mechanistic Interpretability and Hallucination Mitigation
关键词:LVLM, Mechanistic Interpretability, Causal Tracing, Hallucination Mitigation
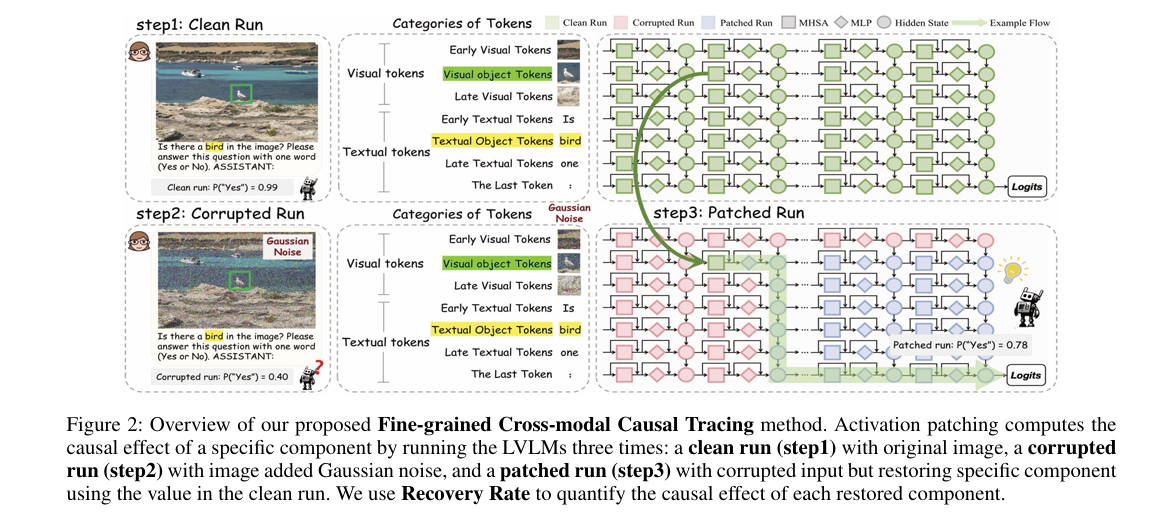
研究方法与创新点
该研究针对大视觉语言模型(LVLMs)机制可解释性研究不全面的问题,提出细粒度跨模态因果追踪(FCCT)框架,系统量化视觉对象感知的因果效应,覆盖视觉/文本令牌、多头自注意力(MHSA)、前馈网络(FFNs)等核心组件及所有解码器层。研究首次发现中层最后一个令牌的MHSA在跨模态信息聚合中起关键作用,FFNs则呈现三阶段分层演进特征;基于此提出无训练推理阶段技术IRI,通过在特定组件和层干预跨模态表示强化视觉对象信息流,在五个基准测试中实现幻觉缓解与感知能力提升,且不影响推理速度。
论文链接:https://arxiv.org/abs/2511.05923
七、大模型多语言与跨域适配方向
【论文7】LangGPS: Language Separability Guided Data Pre-Selection for Joint Multilingual Instruction Tuning
关键词:Multilingual Instruction Tuning, Data Pre-Selection, Language Separability, LLMs
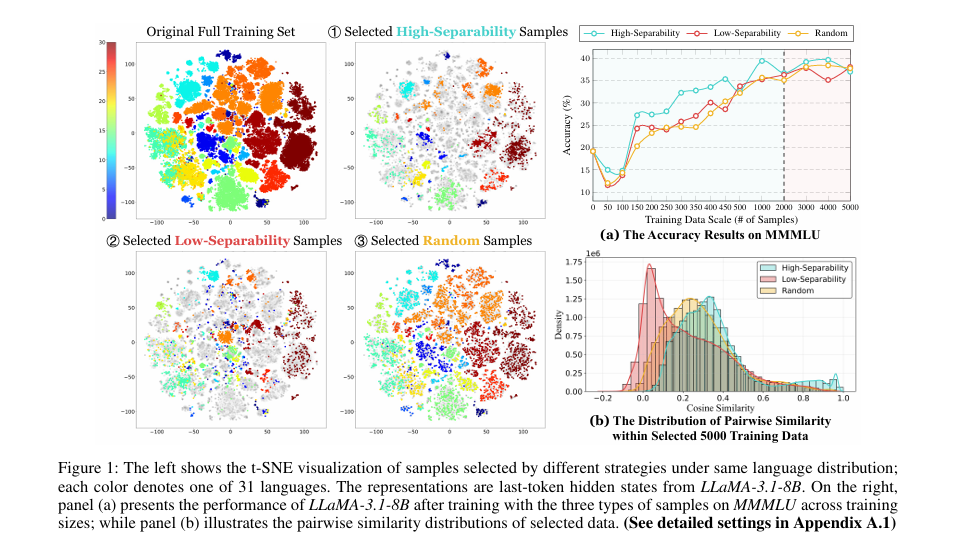
研究方法与创新点
该研究针对联合多语言指令微调中训练数据构成影响模型性能的问题,提出轻量级两阶段数据预选择框架LangGPS,以语言可分离性(量化不同语言样本在模型表示空间的区分度)为核心指导。框架先通过可分离性分数过滤训练数据,再结合现有选择方法优化子集,在6个基准测试和22种语言上的实验表明,LangGPS能提升现有选择方法在多语言训练中的有效性与泛化性,尤其对理解类任务和低资源语言效果显著。研究还发现高可分离性样本有助于形成清晰语言边界,低可分离性样本可作为跨语言对齐桥梁,且语言可分离性可作为多语言课程学习的有效信号。
论文链接:https://arxiv.org/abs/2511.10229
➔➔➔➔点击查看原文,获取论文合集![]() https://mp.weixin.qq.com/s/Y11eSxdOkW6wkCXOoHIghw
https://mp.weixin.qq.com/s/Y11eSxdOkW6wkCXOoHIghw

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 14
14 0
0- 0



 已为社区贡献23条内容
已为社区贡献23条内容

所有评论(0)