LlamaIndex 查询引擎与自定义查询引擎的实现
在现代的人工智能与机器学习应用中,如何高效地查询与处理大规模数据已成为一个至关重要的问题。LlamaIndex作为一个强大的数据索引和查询框架,不仅提供了简洁且高效的查询接口,还允许开发者根据自身需求进行高度定制的查询引擎开发。本文将详细介绍LlamaIndex的查询引擎的基本概念和使用方法,并通过具体示例讲解如何实现自定义查询引擎,以支持检索增强生成(RAG)等复杂应用场景。
目录
前言
在现代的人工智能与机器学习应用中,如何高效地查询与处理大规模数据已成为一个至关重要的问题。LlamaIndex作为一个强大的数据索引和查询框架,不仅提供了简洁且高效的查询接口,还允许开发者根据自身需求进行高度定制的查询引擎开发。本文将详细介绍LlamaIndex的查询引擎的基本概念和使用方法,并通过具体示例讲解如何实现自定义查询引擎,以支持检索增强生成(RAG)等复杂应用场景。
1. LlamaIndex 查询引擎概述
LlamaIndex的查询引擎是其核心组件之一,负责接受用户的自然语言查询,并返回相关的查询结果。通过结合数据索引和高效的检索算法,LlamaIndex能够在大规模数据中迅速定位到与用户查询相关的信息。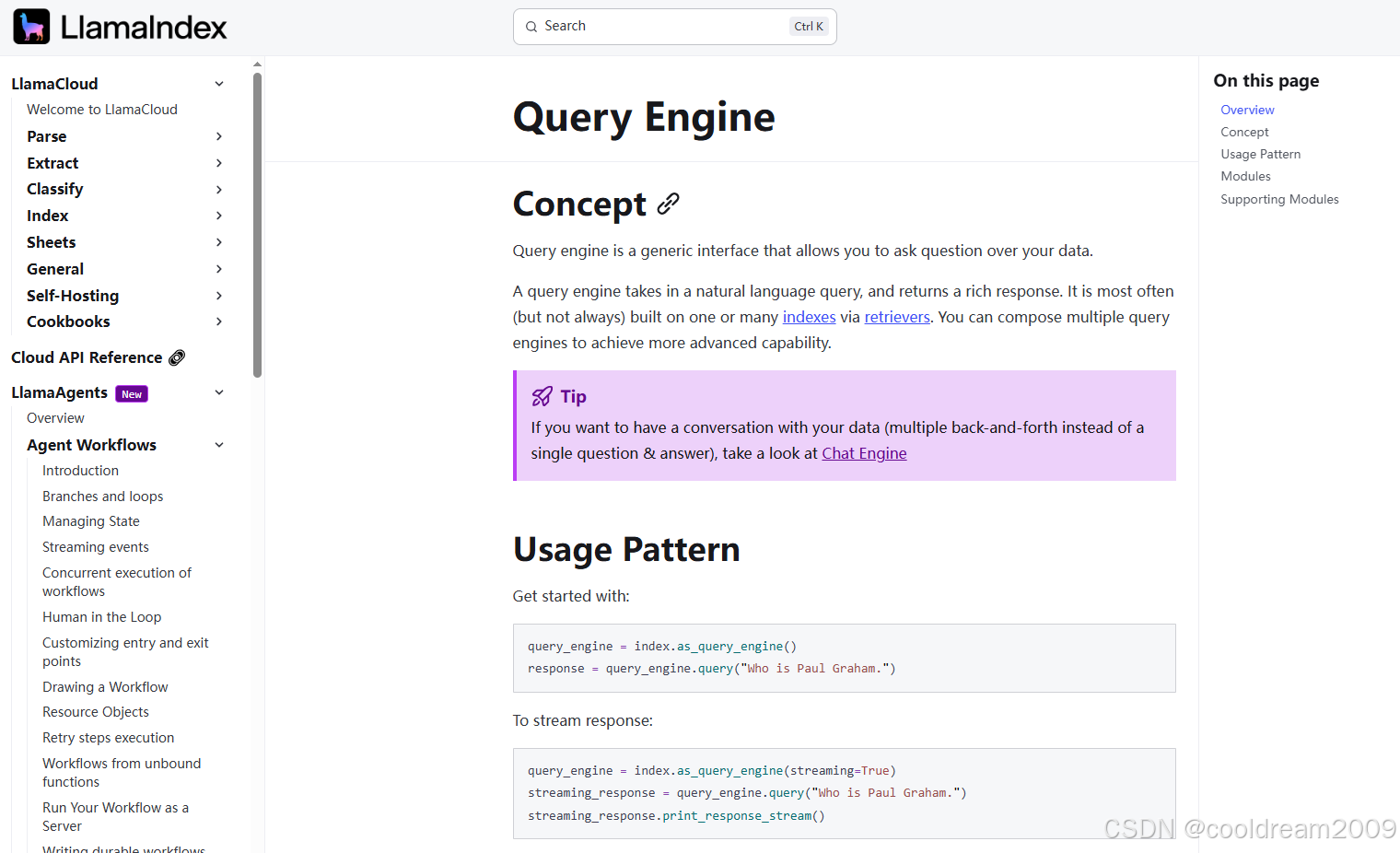
1.1 查询引擎的基本概念
查询引擎提供了一个通用的接口,使得用户可以通过自然语言向数据集进行查询。它的工作原理是基于预先构建的索引,通过检索器查找相关数据,并返回相应的响应。
在LlamaIndex中,查询引擎通常依赖于以下几个步骤:
- 数据加载与索引构建:将数据加载到索引中,确保数据在检索时能够高效地查询。
- 检索过程:通过检索器查询相关的数据节点。
- 响应生成:根据检索到的节点生成回答,可能需要通过外部模型(如LLM)进行进一步的合成。
LlamaIndex的查询引擎支持两种主要的查询模式:标准查询模式和流式查询模式。
1.2 标准查询模式
这是最常见的查询方式,用户将一个查询字符串输入查询引擎,查询引擎返回相关结果。
将索引转换为查询引擎
query_engine = index.as_query_engine()
提出查询
response = query_engine.query("Paul Graham 是谁?")
打印响应结果
print(response)
该查询返回一个标准的响应对象,包含了所有相关信息,通常适用于常规的查询场景。
1.3 流式查询模式
流式查询模式则允许查询引擎逐步返回查询结果。这对于需要实时反馈或处理大量数据的场景尤为重要。
将索引转换为流式查询引擎
query_engine = index.as_query_engine(streaming=True)
提出查询
streaming_response = query_engine.query("Paul Graham 是谁?")
打印流式响应
streaming_response.print_response_stream()
这种方式能够高效地处理大规模查询,并提供实时更新的结果。
2. LlamaIndex 自定义查询引擎
LlamaIndex不仅提供了标准的查询引擎,它还允许用户根据具体的业务需求,自定义查询引擎的行为。这对于构建复杂的应用程序(如RAG、智能代理等)至关重要。
2.1 自定义查询引擎的概念
自定义查询引擎是LlamaIndex提供的一种扩展方式,允许用户根据需要构建完全定制化的查询引擎。用户可以通过定义查询引擎的初始化参数以及实现查询逻辑,来满足复杂的数据检索需求。
在LlamaIndex中,自定义查询引擎继承自 CustomQueryEngine 类,并实现 custom_query 方法。这使得开发者可以将检索和响应合成等操作封装成自定义的逻辑。
自定义查询引擎有两种常见的实现方式,分别是基于检索增强生成(RAG)的查询引擎和基于LLM字符串生成的查询引擎。
2.2 基于RAG的查询引擎
RAG(Retrieval-Augmented Generation)是一种结合信息检索与文本生成的技术,它通过检索相关文档来增强生成模型的能力。在LlamaIndex中,您可以通过自定义查询引擎实现RAG功能。
from llama_index.core.query_engine import CustomQueryEngine
from llama_index.core.retrievers import BaseRetriever
from llama_index.core.response_synthesizers import BaseSynthesizer
class RAGQueryEngine(CustomQueryEngine):
"""RAG 查询引擎。"""
retriever: BaseRetriever
response_synthesizer: BaseSynthesizer
def custom_query(self, query_str: str):
进行信息检索
nodes = self.retriever.retrieve(query_str)
合成响应
response_obj = self.response_synthesizer.synthesize(query_str, nodes)
return response_obj
在这个实现中,RAGQueryEngine 先通过检索器获取相关节点,再通过响应合成器生成最终回答。这种方式使得查询引擎不仅能检索相关内容,还能根据检索结果生成更具上下文相关性的回答。
2.3 基于LLM的查询引擎
另一种实现方式是通过直接调用大语言模型(LLM)生成查询答案。例如,使用OpenAI的GPT模型进行问答生成。
from llama_index.llms.openai import OpenAI
from llama_index.core import PromptTemplate
qa_prompt = PromptTemplate(
"Context information is below.\n"
"---------------------\n"
"{context_str}\n"
"---------------------\n"
"Given the context information and not prior knowledge, "
"answer the query.\n"
"Query: {query_str}\n"
"Answer: "
)
class RAGStringQueryEngine(CustomQueryEngine):
"""RAG 字符串查询引擎。"""
retriever: BaseRetriever
response_synthesizer: BaseSynthesizer
llm: OpenAI
qa_prompt: PromptTemplate
def custom_query(self, query_str: str):
进行信息检索
nodes = self.retriever.retrieve(query_str)
context_str = "\n\n".join([n.node.get_content() for n in nodes])
调用 LLM 完成查询并生成回答
response = self.llm.complete(
qa_prompt.format(context_str=context_str, query_str=query_str)
)
return str(response)
在 RAGStringQueryEngine 中,查询引擎通过调用大语言模型生成回答。该方法不依赖于复杂的响应对象,而是直接生成纯文本的答案。
3. 实践示例:使用自定义查询引擎
通过实践示例,我们可以进一步了解如何使用LlamaIndex的自定义查询引擎进行复杂查询处理。
3.1 使用基于RAG的查询引擎
synthesizer = get_response_synthesizer(response_mode="compact")
query_engine = RAGQueryEngine(
retriever=retriever, response_synthesizer=synthesizer
)
response = query_engine.query("What did the author do growing up?")
print(str(response))
在这个例子中,RAGQueryEngine 通过检索相关节点并合成响应,返回了作者成长过程中的一些重要经历:
The author worked on writing and programming outside of school before college. They wrote short stories and tried writing programs on an IBM 1401 computer using an early version of Fortran. They also mentioned getting a microcomputer, building it themselves, and writing simple games and programs on it.
3.2 使用基于LLM的查询引擎
llm = OpenAI(model="gpt-3.5-turbo")
query_engine = RAGStringQueryEngine(
retriever=retriever,
response_synthesizer=synthesizer,
llm=llm,
qa_prompt=qa_prompt,
)
response = query_engine.query("What did the author do growing up?")
print(str(response))
在这个例子中,RAGStringQueryEngine 通过OpenAI的GPT模型生成了以下答案:
The author worked on writing and programming before college. They wrote short stories and started programming on the IBM 1401 computer in 9th grade. They later got a microcomputer and continued programming, writing simple games and a word processor.
4. 结语
LlamaIndex的查询引擎是构建智能应用的重要工具。它不仅能够处理基本的自然语言查询,还支持自定义扩展,可以实现更复杂的检索和生成任务。无论是在RAG场景下,还是通过LLM实现纯文本生成,LlamaIndex的自定义查询引擎都能够满足各种需求。通过本文的讲解,您可以更好地理解如何构建适合自己业务需求的查询引擎,并在实际项目中实现高效的数据检索与响应生成。
参考资料

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 8
8 0
0- 0



 已为社区贡献61条内容
已为社区贡献61条内容

所有评论(0)