分布式存储与GlusterFS介绍、集群实战指南
本文介绍了分布式存储系统GlusterFS的配置与应用。主要内容包括:1)分布式存储概念及其优势(扩容方便、性能提升、高可用);2)GlusterFS作为开源分布式文件系统的特点;3)常用RAID级别(0/1/5/6/10)及其特性比较;4)通过实验详细演示了GlusterFS集群部署流程,包括Replica(镜像)、Stripe(条带)、Distributed(分布式)等多种卷模式的创建与测试;
目录
1.分布式存储介绍
分布式存储可以看作拥有多台存储服务器连接起来的存储。把这多台存储服务器的存储合起来做成一个整体再通过网络进行远程共享。
常见的分布式存储开源软件有:GlusterFS,Ceph,HDFS,MooseFS等。
分布式存储一般都有以下几个优点:
1. 扩容方便,轻松达到PB级别或以上
2. 提升读写性能(LB)或数据高可用(HA)
3. 避免单个节点故障导致整个架构问题
2.Glusterfs介绍
glusterfs是一个免费,开源的分布式文件系统(它属于文件存储类型)。
3.raid介绍
raid级别有很多种,下面主要介绍常用的几种:
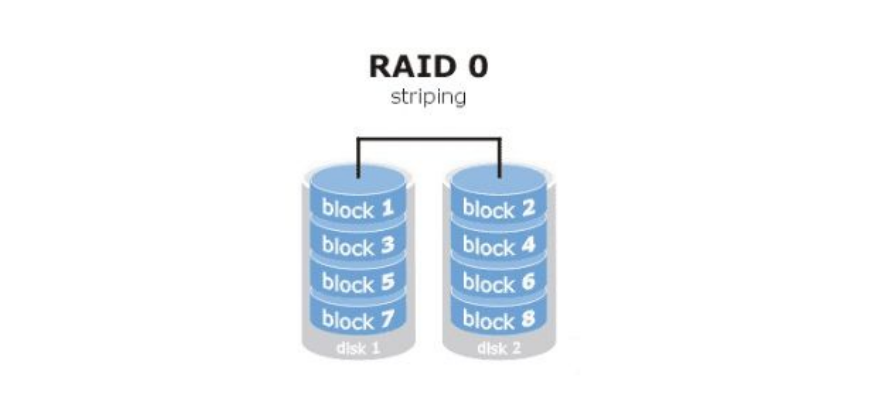
raid0
读写性能佳,坏了其中一块,数据挂掉,可靠性低(stripe条带化),磁盘利用率100%,实现了LB。
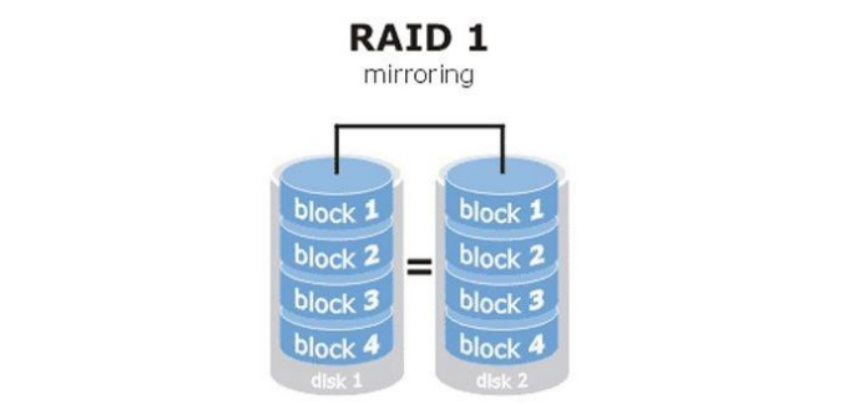
raid1
镜像卷,同一份数据完整的保存在多个磁盘上,写的性能不佳,可靠性高,读的性能还行,磁盘利用率50%,实现了HA。
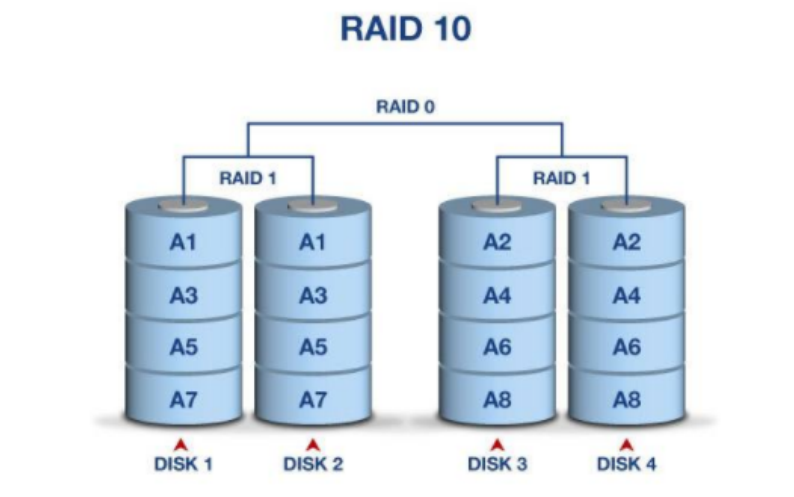
raid10
同时做raid 1 和 raid 0
raid5
由多块磁盘做raid 5,磁盘利用率为n-1/n, 其中一块放校验数据,允许坏一块盘,数据可以利用校验值来恢复。 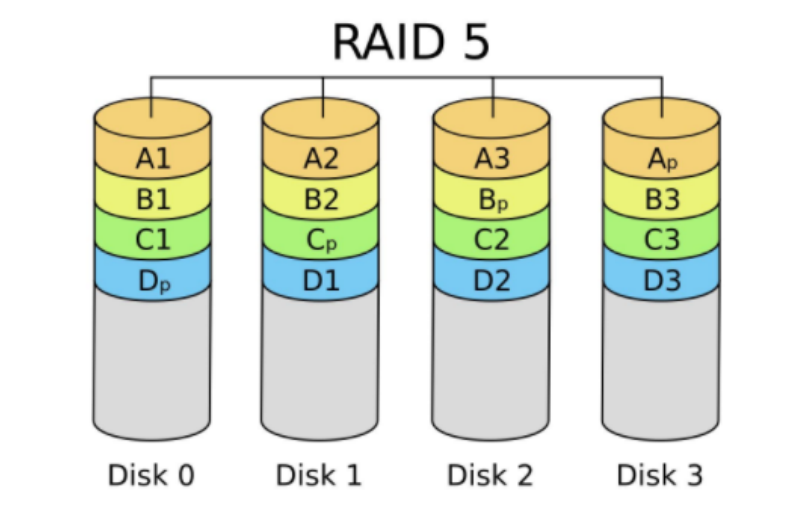
raid6
在raid5的基础上再加一块校验盘,进一步提高数据可靠性
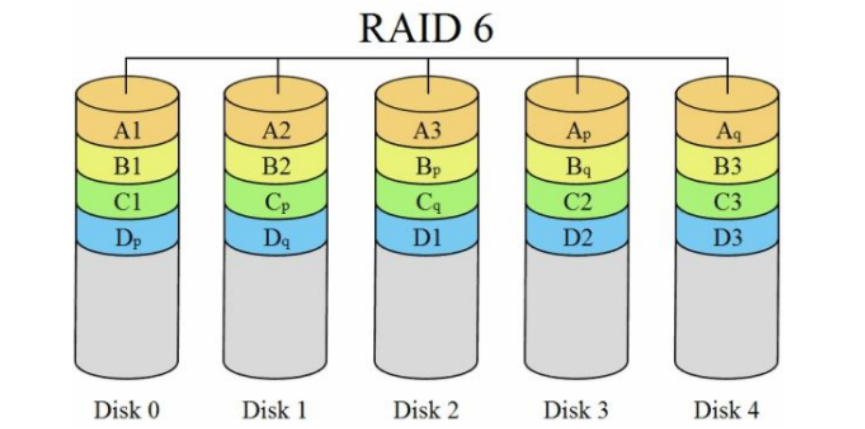
生产环境中最常用的为raid5和raid10
常见卷的模式
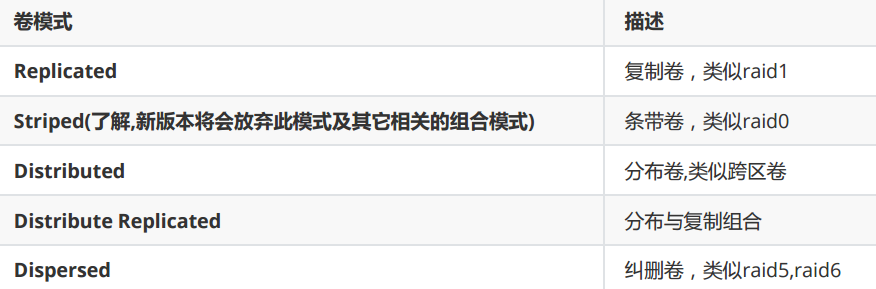
glusterfs看作是一个将多台服务器存储空间组合到一起,再划分出不同类型的文件存储卷给导入端使用。
Replicated卷 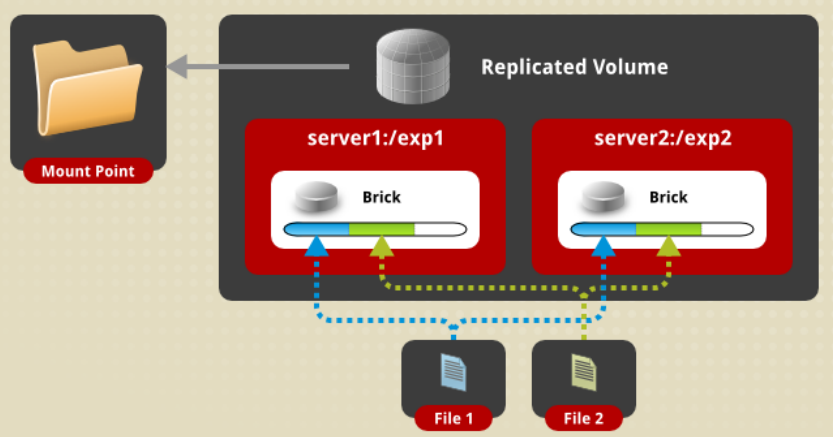
Striped卷
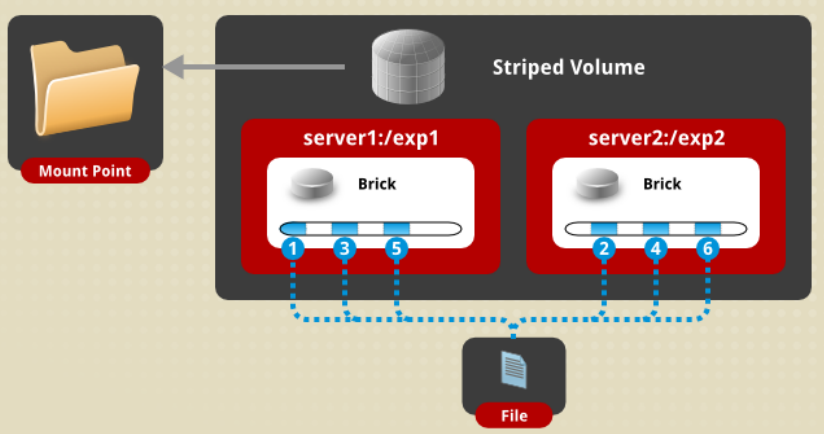
Distributed卷 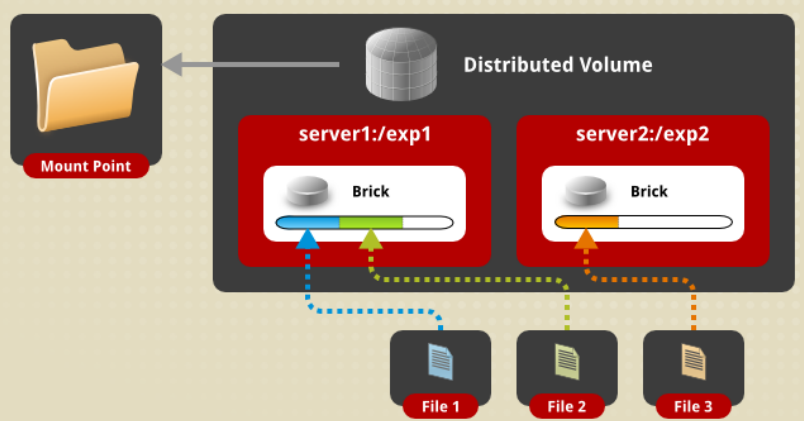
Distribute Replicated卷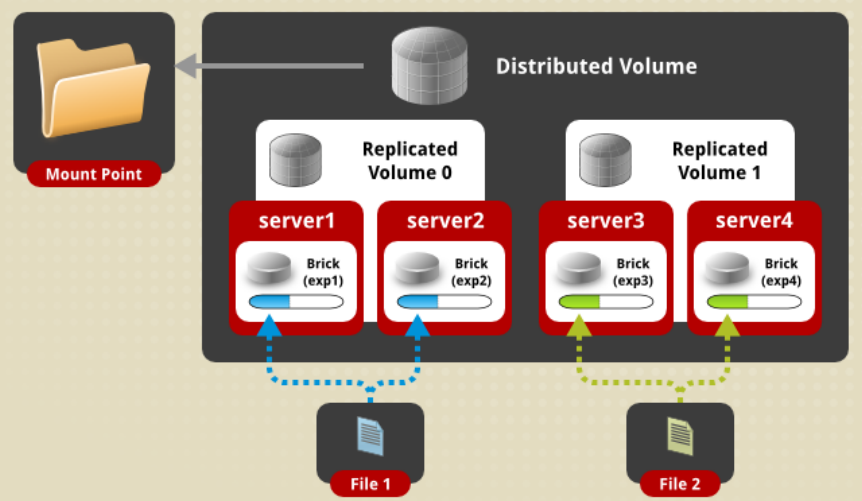
其它模式请参考官网: Gluster Docs
4.glusterfs集群实验示例
实验准备:
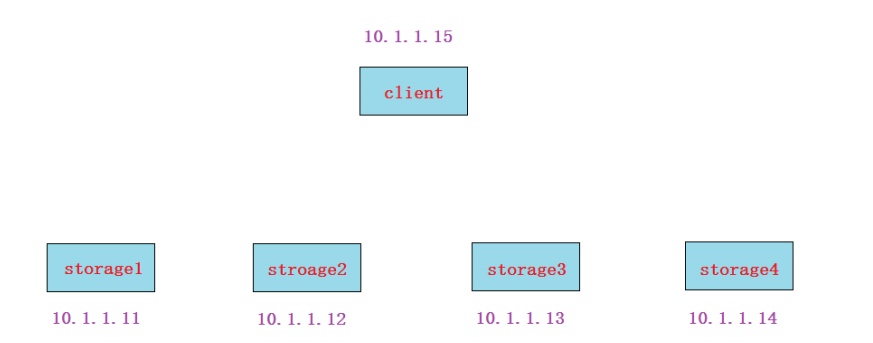
1. 所有节点设置静态IP
2. 所有节点都配置主机名及其主机名互相绑定(不是必须操作,方便使用)

3. 所有节点关闭防火墙,selinux
systemctl stop firewalld
systemctl disable firewalld
iptables -F
4. 所有节点时间同步(系统要一致都是中文或者都是英文)
时间同步服务器设置
vim /etc/ntp.conf

时间同步客户端设置
ntpdate 192.168.136.10

5. 所有节点(包括client)配置好yum(需要加上glusterfs官方yum源)
vim /etc/yum.repos.d/glusterfs.repo
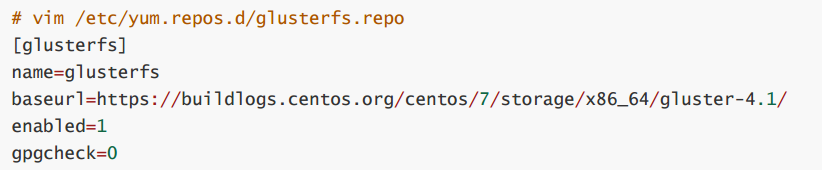
yum源说明:
可按照以上yum路径去查找 glusterfs5 或 glusterfs6 版本的yum源路径(目前我们使用4.1版),如果网速太慢,可下载提前准备好的包。
实验步骤:
1. 在所有storage服务器上安装相关软件包,并启动服务
2. 所有storage服务器建立连接, 成为一个集群
3. 所有storage服务器准备存储目录
4. 创建存储卷
5. 启动存储卷
6. client安装挂载软件
7. client挂载使用
实验过程:
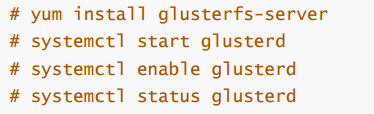
第1步, 在所有storage服务器上(不包括client)安装glusterfs-server软件包,并启动服务
下面的命令所有存储服务器都要做
yum install glusterfs-server
systemctl start glusterd
systemctl enable glusterd
systemctl status glusterd
分布式集群一般有两种架构:
有中心节点的 中心节点一般指管理节点,后面大部分分布式集群架构都属于这一种
无中心节点的 所有节点又管理又做事,glusterfs属于这一种.
第2步, 所有storage服务器建立连接,成为一个集群
4个storage服务器建立连接不用两两连接,只需要找其中1个,连接另外3个各一次
storage1上操作
gluster peer probe storage2
gluster peer probe storage3
gluster peer probe storage4

然后在所有存储上都可以使用下面命令来验证集群状态
gluster peer status
![]()
==注意==:
如果这一步建立连接有问题(一般问题会出现在网络连接,防火墙,selinux,主机名绑定等),如果想重做这一步,可以使用gluster peer detach xxxxx [force] 来断开连接,重新做。
第3步, 所有storage服务器准备存储目录(可以用单独的分区,也可以使用根分区)
storage服务器没有准备额外的硬盘,所以这里用根分区来做实验,但生产环境肯定是不建议数据盘和系统盘在一起的,最好有对立的硬盘或者分区。
所有的node都创建gv0目录,名字可以不一致
mkdir -p /data/gv0
![]()
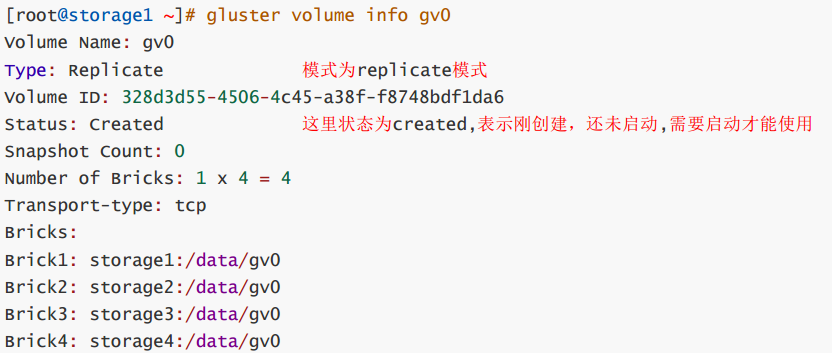
第4步, 创建存储卷(在任意一个storage服务器上做)
==注意==: 改变的操作(create,delete,start,stop)等只需要在任意一个storage服务器上操作,查看的操作(info)等可以在所有storage服务器上操作
因为在根分区创建所以需要force参数强制(其他分区不需要force)
replica 4表示是在4台上做复制模式(类似raid1)
gluster volume create gv0 replica 4 storage1:/data/gv0/storage2:/data/gv0/ storage3:/data/gv0/ storage4:/data/gv0/ force

所有storage服务器上都可以查看
gluster volume info gv0

第5步, 启动存储卷
gluster volume start gv0

gluster volume info gv0 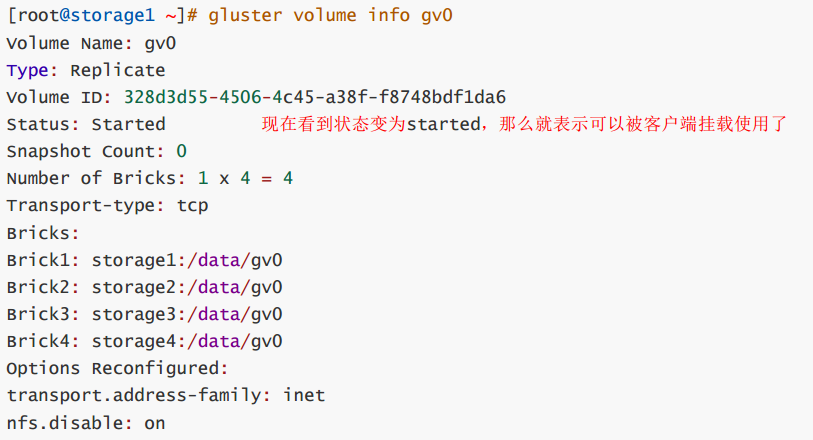
第6步, client安装软件
客户端上操作
yum -y install glusterfs glusterfs-fuse ![]()
说明:fuse(Filesystem in Userspace): 用户空间文件系统,是一个客户端挂载远程文件存储的模块。
第7步, client挂载使用
==注意==:客户端也需要在/etc/hosts文件里绑定存储节点的主机名,才可以挂载(因为我前面做的步骤是用名字的)
mkdir /test0
mount -t glusterfs storage1:gv0 /test0 
replica卷测试
读写测试方法:在客户端使用dd命令往挂载目录里写文件,然后查看在storage服务器上的分布情况
(==注意: 读写操作请都在客户端进行,不要在storage服务器上操作==)
echo qingmei > f1.txt
dd if=/dev/zero of=/test0/f2.txt bs=1M count=10

1. 读写测试结果: 结果类似raid1
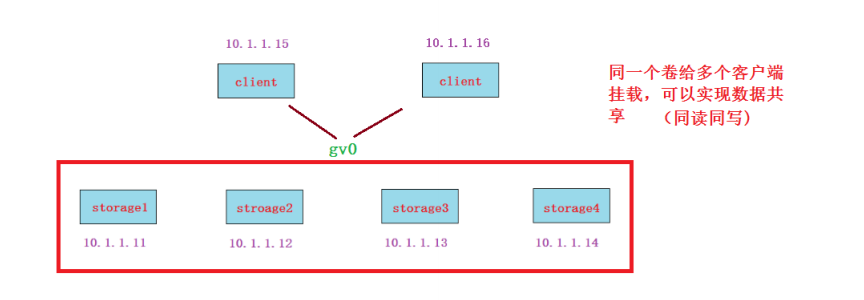
2. 同读同写测试: 可以再开一台虚拟机做为client2,两个客户端挂载gv0后实现同读同写(文件存储类型的特点)
运维思想:搭建OK后,你要考虑性能,稳定, 高可用,负载均衡,健康检查, 扩展性等如果某一个节点挂了,你要考虑是什么挂了(网卡,服务,服务器关闭了),如何解决?
请测试如下几种情况:
1. 将其中一个storage节点关机
客户端需要等待10几秒钟才能正常继续使用,再次启动数据就正常同步过去
2. 将其中一个storage节点网卡down掉
客户端需要等待10几秒钟才能正常继续使用,再次启动数据就正常同步过去
结论: 作为一名运维工程师,HA场景有不同的挂法:
服务器关闭,网卡坏了,网线断了,交换机挂了等等
卷的删除
第1步: 先在客户端umount已经挂载的目录(在umount之前把测试的数据先删除)
rm -rf *
umount /test0

第2步: 在任一个storage服务器上使用下面的命令停止gv0并删除,我这里是在storage1上操作。
gluster volume stop gv0
gluster volume delete gv0
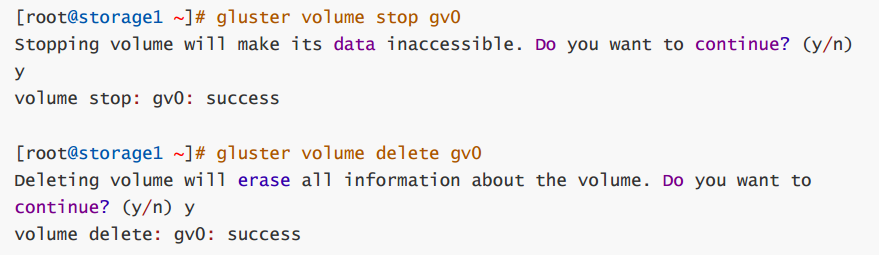
第3步: 在所有storage服务器上都可以查看,没有gv0的信息了,说明这个volumn被删除了
gluster volume info gv0

stripe模式(条带)
第1步: 再重做成stripe模式的卷(重点是命令里的stripe 4参数)(在任一个storage服务器上操作, 我这里是在storage1上操作)
gluster volume create gv0 stripe 4 storage1:/data/gv0/storage2:/data/gv0/ storage3:/data/gv0/ storage4:/data/gv0/ force
第2步: 启动gv0(在任一个storage服务器上操作, 我这里是在storage1上操作)
gluster volume start gv0
![]()
第3步: 客户端挂载
mount -t glusterfs storage1:gv0 /test1
![]()
第4步:读写测试
读写测试结果: 文件过小,不会平均分配给存储节点。有一定大小的文件会平均分配。类似raid0。
磁盘利率率100%(前提是所有节点提供的空间一样大,如果大小不一样,则按小的来进行条带)
大文件会平均分配给存储节点(LB)
没有HA,挂掉一个存储节点,此stripe存储卷则不可被客户端访问
distributed模式
第1步: 准备新的存储目录(所有存储服务器上都要操作)
mkdir -p /data/gv1
![]()
第2步: 创建distributed卷gv1(不指定replica或stripe就默认是Distributed的模式, 在任一个storage服务器上操作, 我这里是在storage1上操作)
gluster volume create gv1 storage1:/data/gv1/storage2:/data/gv1/ storage3:/data/gv1/ storage4:/data/gv1/ force
第3步: 启动gv1(在任一个storage服务器上操作, 我这里是在storage1上操作)
gluster volume start gv1
gluster volume info gv1

第4步: 客户端挂载
mount -t glusterfs storage1:gv1 /test1![]()
读写测试结果: 测试结果为随机写到不同的存储里,直到所有写满为止。
利用率100%
方便扩容
不保障的数据的安全性(挂掉一个节点,等待大概1分钟后,这个节点就剔除了,被剔除的节点上的数据丢失),其他磁盘数据还在
不提高IO性能(读写)
distributed-replica模式
第1步: 准备新的存储目录(所有存储服务器上都要操作)
mkdir -p /data/gv2
![]()
第2步: 创建distributed-replica卷gv2(在任一个storage服务器上操作, 我这里是在storage1上操作)
gluster volume create gv2 replica 2 storage1:/data/gv2/storage2:/data/gv2/ storage3:/data/gv2/ storage4:/data/gv2/ force

第3步: 启动gv2(在任一个storage服务器上操作, 我这里是在storage1上操作)
gluster volume start gv2
![]()
第4步: 客户端挂载
mount -t glusterfs storage1:gv2 /test1 ![]()
第5步:读写测试
读写测试结果: 4个存储分为两个组,这两个组按照distributed模式随机。但在组内的两个存储会按replica模式镜像复制。
特点:结合了distributed与replica的优点:可以扩容,也有HA特性
dispersed模式
disperse卷是v3.6版本后发布的一种卷模式,类似于raid5/6
第1步: 准备新的存储目录(所有存储服务器上都要操作)
mkdir -p /data/gv3
![]()
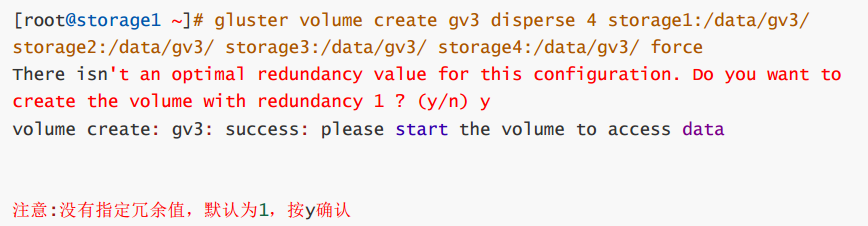
第2步: 创建卷gv3(在任一个storage服务器上操作, 我这里是在storage1上操作)
gluster volume create gv3 disperse 4 storage1:/data/gv3/storage2:/data/gv3/ storage3:/data/gv3/ storage4:/data/gv3/ force
第3步: 启动gv3(在任一个storage服务器上操作, 我这里是在storage1上操作)
gluster volume start gv3
gluster volume info gv3 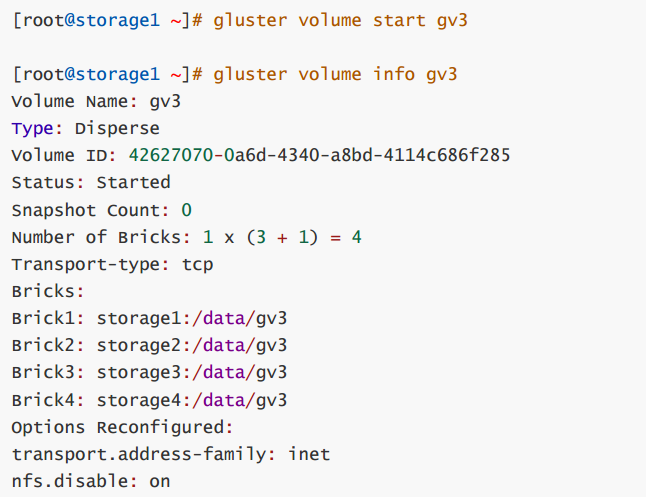
第4步: 客户端挂载
mount -t glusterfs storage1:gv3 /test1![]()
第5步:读写测试
读写测试结果: 写100M,每个存储服务器上占33M左右。因为4个存储1个为冗余(与raid5一样)。
如果想要实现2个冗余,则最少需要5台存储服务器
gluster volume create gv4 disperse 4 redundancy 2 storage1:/data/gv4/storage2:/data/gv4/ storage3:/data/gv4/ storage4:/data/gv4/ force

5.在线裁减与在线扩容
在线裁减要看是哪一种模式的卷,比如stripe模式就不允许在线裁减。下面我以distributed卷来做裁减与扩容
在线裁减(注意要remove没有数据的brick,一般不会裁剪硬盘)
gluster volume remove-brick gv1 storage4:/data/gv1 force

在线扩容
gluster volume add-brick gv1 storage4:/data/gv1 force

4个存储节点想扩容为5个存储节点怎么做?
第5个存储服务器安装服务器软件包,启动服务,然后gluster peer probe storage5加入集群只有distributed模式或带有distributed组合的模式才能在线扩容brick
glusterfs小结:
属于文件存储类型,优点:可以数据共享 缺点: 速度较低
replica卷:类似raid1,数据镜像,可以指定多个副本(HA)
stripe卷:类似raid0,提升IO性能(LB)
distributed卷:在多个磁盘中随机存储,可以在线扩容
dispersed卷:类似raid5/raid6,防止单点故障(HA),提升IO性能(LB)
distributed-replica卷:结合distributed和replica的优点(HA和可扩容)

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 2
2 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)