OUC AI Lab 第七章:ViT & Swin Transformer
本文介绍了ViT和Swin Transformer两种基于Transformer的视觉模型。ViT通过将图像分割为patches,添加class token和位置信息后输入Transformer Encoder进行处理。Swin Transformer则针对目标检测任务改进,采用层次化特征图和窗口注意力机制,通过W-MSA和SW-MSA交替计算,在降低计算量的同时保持窗口间信息交互。两种模型都成功
第七章:ViT & Swin Transformer
VIT
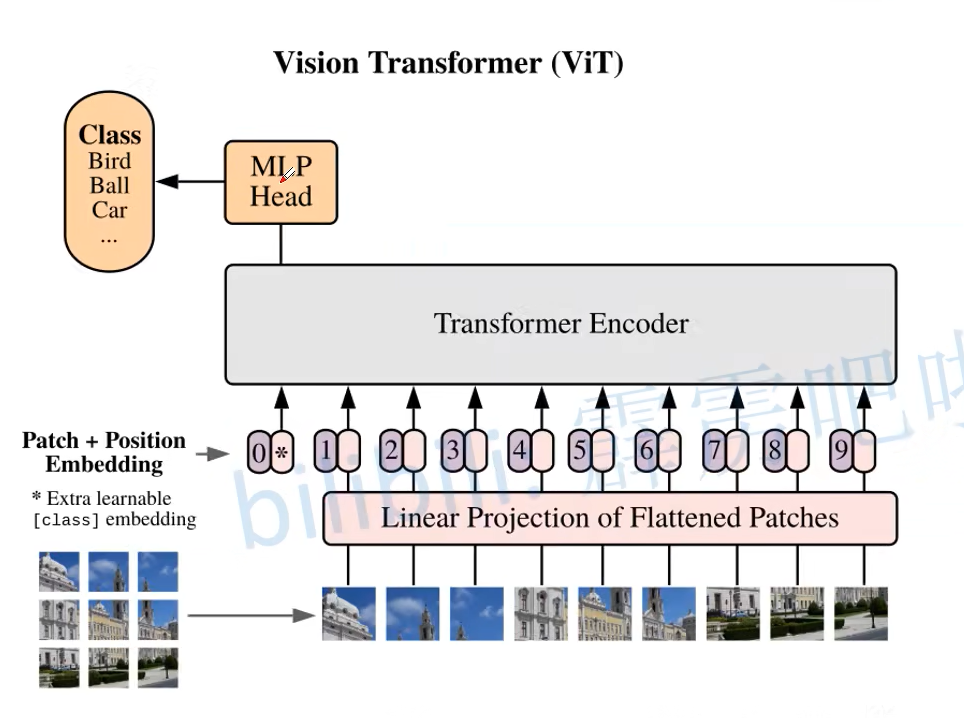
vit的流程图如下所示
transformer输入的二维的[batch,seq,emb],也就是批次,语句长度,每个字被映射成的向量。
而要想在cv领域也使用transformer,整体的思路是
1 将输入图像分为不同大小的patches
假设输入的图像大小为224*224*3,那么如果我们想要划分为的patches是16*16的形状,那么显然一共会有14*14=196个patches,然后我们还想要每个patches映射为786维的token(注意这里的token长度是自己定义的)
如何划分为patches呢?只需要使用16x16且步长为16的卷积核就好了,这样就实现了每次卷积一个patch,隐含了拆分patch的操作
如何映射到786维呢?只需要将out_channel设置为786即可
2 将patches输入到Linear Projection of Flattened Pathes中,这实际上就是一个embedding层
通过步骤一,原大小为[224,224,3]的输入经过卷积核就得到了[14,14,786]的输出,再将高宽展平就得到了需要的[196,786]
self.proj = nn.Conv2d(3, 768, kernel_size=16, stride=16)
使用
x = self.proj(x).flatten(2).transpose(1, 2)
即可展平为196,并将channel移动到最后,变为[batch,196,786]
3 将得到的向量添加一个class_token到最前面,当作这个图片的类别
这里是需要初始化一个一维向量,和模型一起训练,到最后的classification的时候就只需要把这一维给拿出来就好了
这样形状就从[196,786]变为[197,786]
cls_token = self.cls_token.expand(x.shape[0], -1, -1)
x = torch.cat((cls_token, x), dim=1) # [B, 197, 768]
4 给这些向量添加位置信息
self.pos_embed = nn.Parameter(torch.zeros(1, num_patches + self.num_tokens, embed_dim))
x = self.pos_drop(x + self.pos_embed)
这里只是相加,没有维度方向的拼接
5 将添加了class_token和位置信息的token输入到Transformer Encoder中
Transformer Encoder的模块流程图如下所示
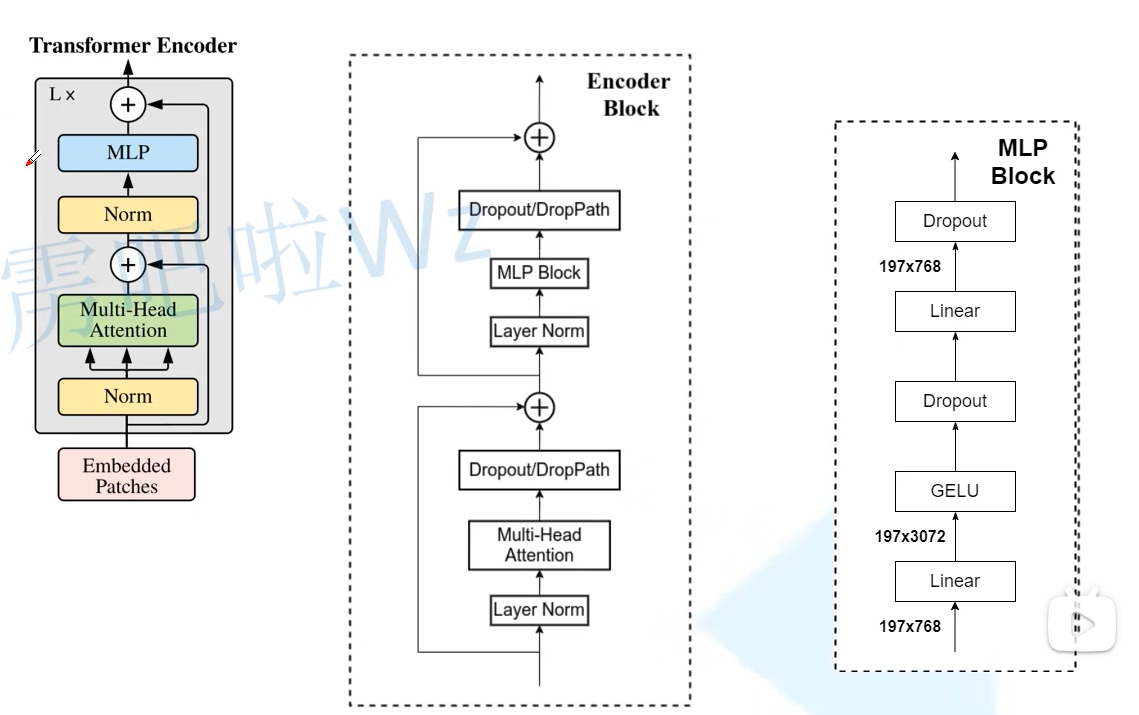
Transformer Encoder是由多个Encoder Block堆叠而成的
添加位置信息的x经过堆叠而成的blocks
x = self.blocks(x)
而blocks需要重复调用Block
self.blocks = nn.Sequential(*[
Block(dim=embed_dim, num_heads=num_heads, mlp_ratio=mlp_ratio, qkv_bias=qkv_bias, qk_scale=qk_scale,
drop_ratio=drop_ratio, attn_drop_ratio=attn_drop_ratio, drop_path_ratio=dpr[i],
norm_layer=norm_layer, act_layer=act_layer)
for i in range(depth)
])
而在Block中需要调用Atten和MLP Block,也就是上图中Encoder Block的下半部分和右边的MLP Block
def forward(self, x):
x = x + self.drop_path(self.attn(self.norm1(x)))
x = x + self.drop_path(self.mlp(self.norm2(x)))
return x
Atten就是transformer的多头注意力,首先需要构建生成qkv的模块
self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)
这里生成dim * 3的维度,是因为在这里qkv矩阵是一起生成的,实际上也可以构建三个nn.Linear(dim, dim , bias=qkv_bias),也是一样的
B, N, C = x.shape //B=batch,N=197,C=786
# qkv(): -> [batch_size, 197, 3 * 786]
# reshape: -> [batch_size, 197, 3, num_heads, 786//num_heads]
# permute: -> [3, batch_size, num_heads, 197, 786//num_heads]
qkv = self.qkv(x).reshape(B, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
在这里,如果有num_heads个头,则需要将token分成num_heads份,最后再拼接起来
q, k, v = qkv[0], qkv[1], qkv[2]
这里因为上面把3换到了最前面,就可以分成qkv了,这里的3是刚刚linear里的3
attn = (q @ k.transpose(-2, -1)) * self.scale
# [batch_size, num_heads, 197, 197]
attn = attn.softmax(dim=-1)
attn = self.attn_drop(attn)
# @: multiply -> [batch_size, num_heads, 197, 786//num_heads]
# transpose: -> [batch_size, 197, num_heads, 786//num_heads]
# reshape: -> [batch_size, 197, 786]
x = (attn @ v).transpose(1, 2).reshape(B, N, C)
这里就是注意力的操作了
后面再经过一个融合层更好的融合一下,再经过MLP Block层就完成了一个Block
return self.pre_logits(x[:, 0])
最后将x的class token返回并通过一个class层即可
Swin-Transformer
Swin-Transformer是针对目标检测的模型,相比起VIT有几点不同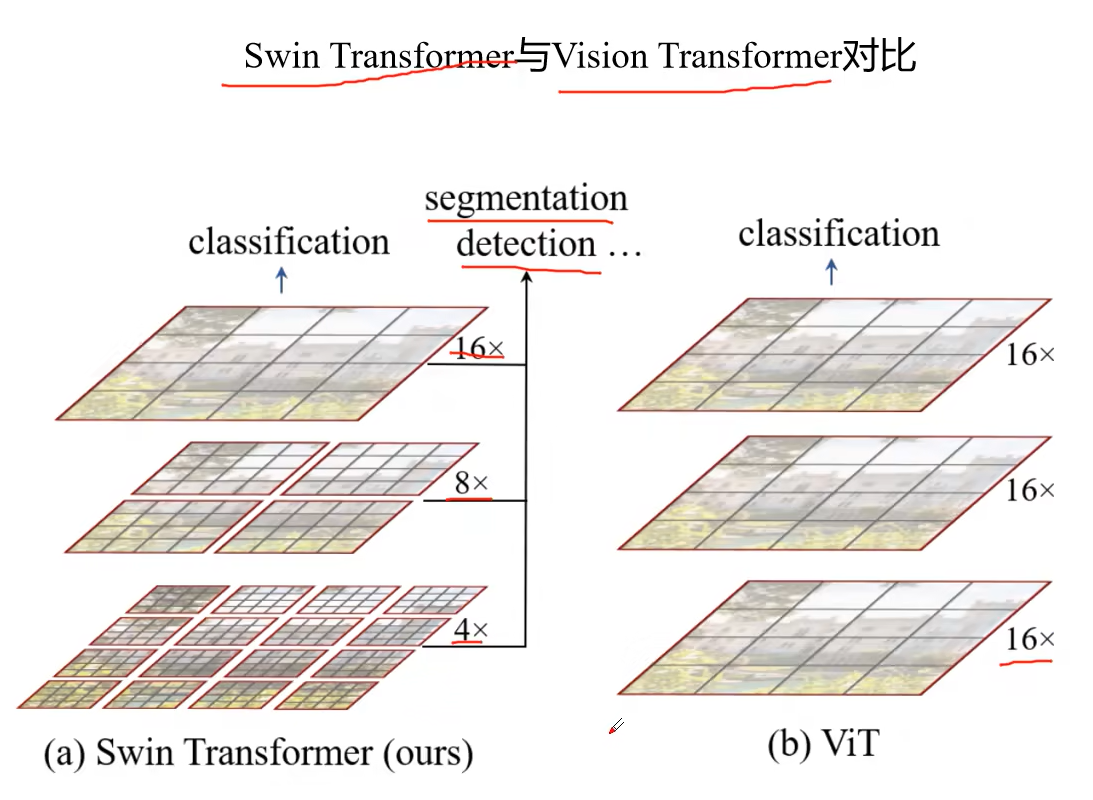
1 构建的feature map具有层次感,对于目标检测和分割任务都具有更大的优势
2 用windows将feature map分隔开,在windows窗口内部进行多头注意力的计算,大大降低了计算量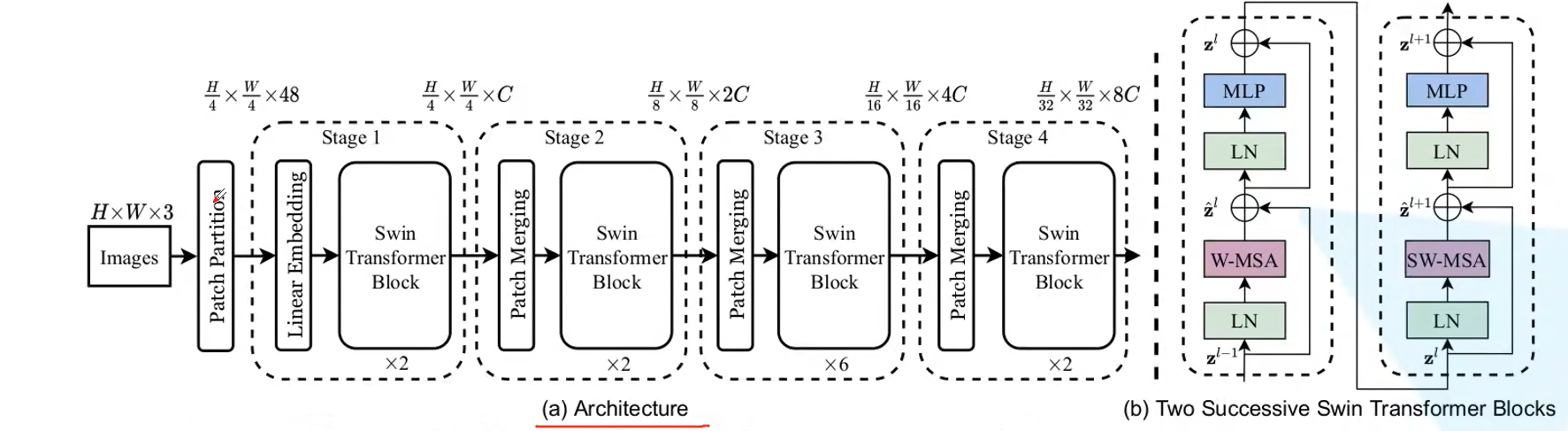
整体的流程图如上所示
其中Patch Partition的流程图如下所示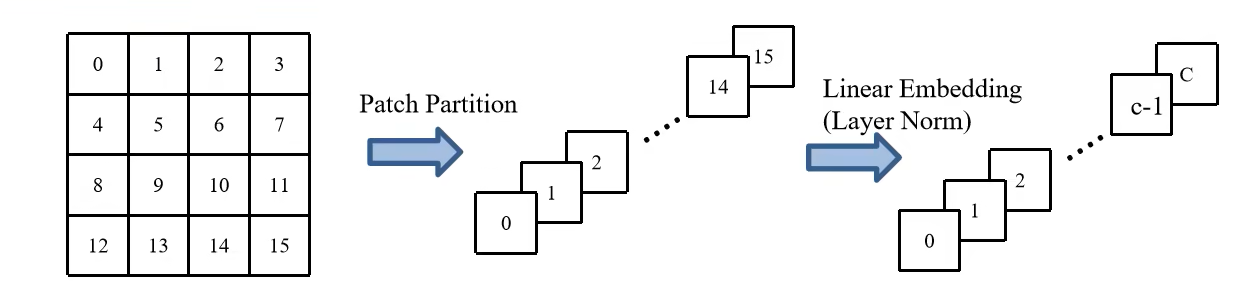
使用4x4的卷积核分割patch,然后在channel方向进行展平,这样图像的大小就变为了[h/4,w/4,48]
Linear Embedding层则是再channel维度上降维到C
而Patch Merging层就是结合了上面的两个层,高宽减半,channel乘二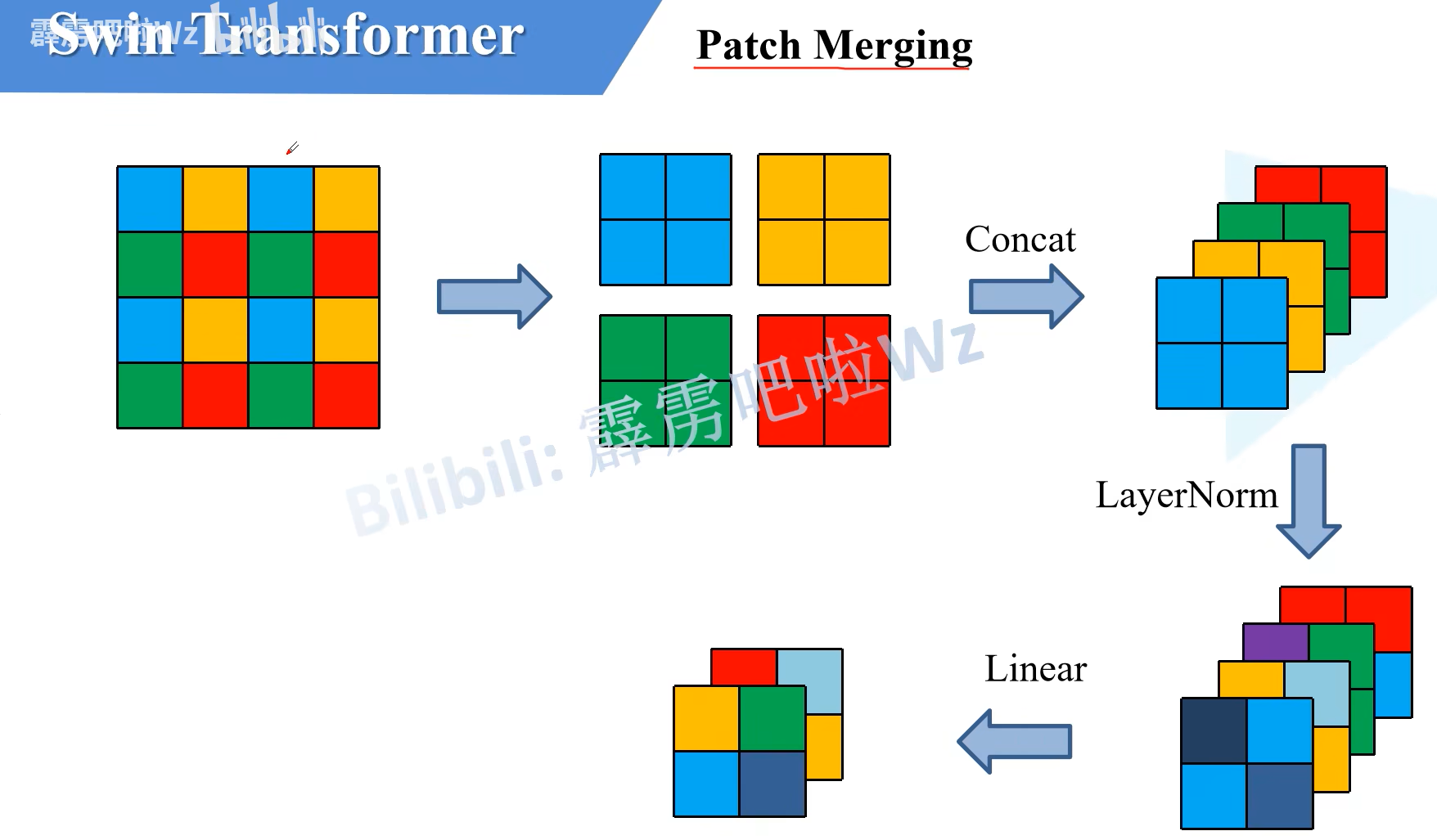
具体来说,是分割为不同的patches再在channel上拼接,经过normal层,最后经过linear层在channel维度上减半
再来看swin transformer的注意力部分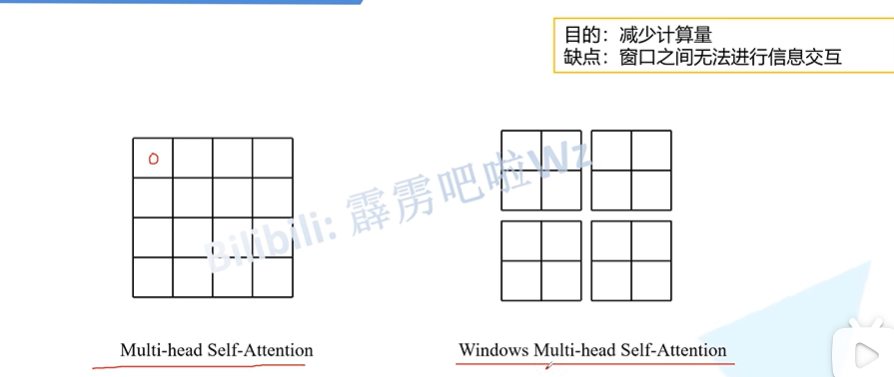
在传统的多头注意力中,在q@v时每个点都要与其他的所有点计算相似度,而在windows多头注意力中每个点只会与其所在的windows的点计算相似度,很显然这样虽然会降低计算量,但是却缺少了信息交互。
MSA和W-MSA的复杂度如下所示
MSA复杂度
计算注意力中的Q时,会首先将输入经过一个Wq生成Q,在这个过程中需要将[hw,C]的输入经过一个[C,C]的矩阵生成大小为[hw,C]的Q,复杂度是hw*C*C=hwC²,要生成QKV复杂度就是3hwC²
随后需要计算Q@KT@V,这个过程的复杂度是(hw)²C+(hw)²C=2(hw)²C
在多头注意力中最后还需要经过一个融合矩阵,和生成QKV一样需要纬度不变,因此复杂度也是hwC²
总的复杂度是4hwC²+2(hw)²C
W-MSA复杂度
W-MSA是将输入划分为许多个M*M的小windows窗口,在窗口内部做多头注意力计算
因此共有h/M*w/M 个 M*M 的小窗口,每个窗口的复杂度是
4M*M*C²+2(M * M)²C = 4M²C²+2(M²)²C
总的复杂度就是 h/M*w/M *(4M²C²+2(M²)²C) = 4hwC²+2(M)²hwC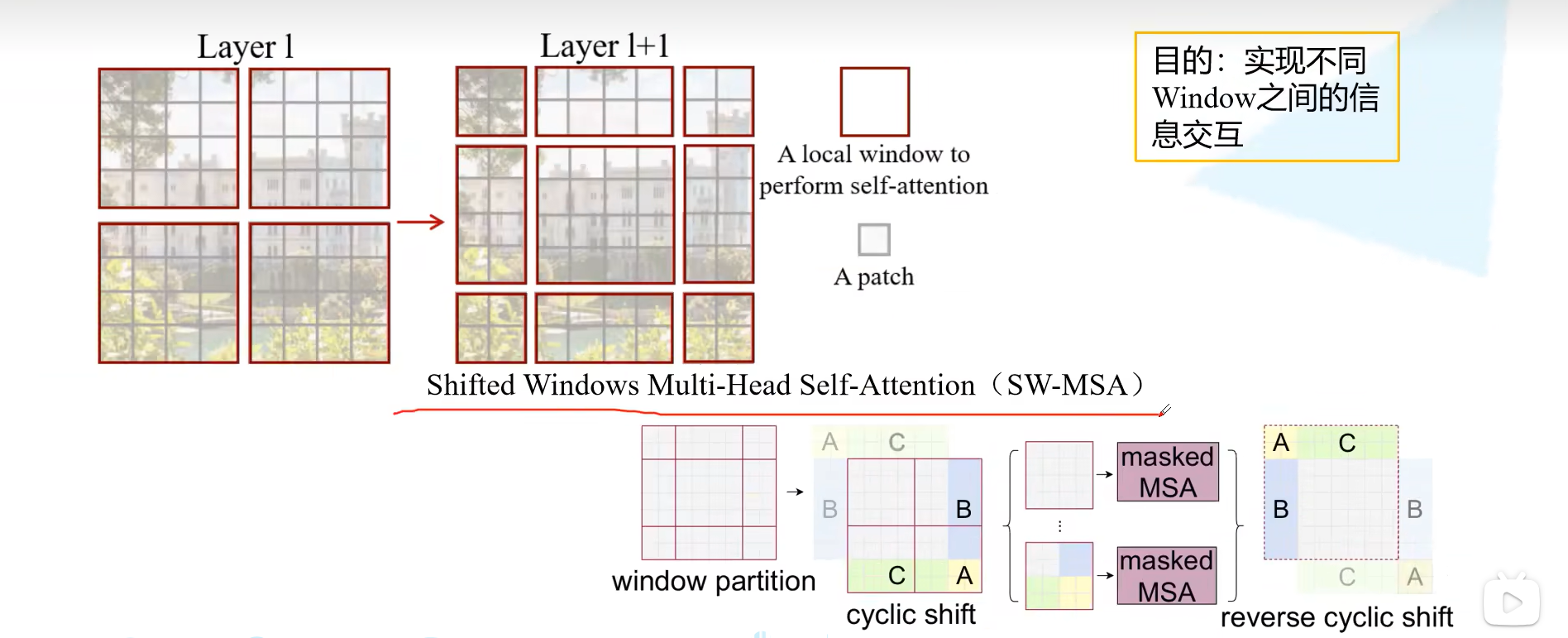
W-MSA是在每个窗口内部做注意力,因此缺少了窗口与窗口之间的信息交互
为了解决这个问题,在上面的图中显示swin transformer中还有一个SW-MSA去计算注意力,W-MSA和SW-MSA是交替出现的,这就是stage 1-4 总是成偶数出现的原因
在Layer l中是W-MSA,那么在Layer l+1中就是SW-MSA,将原先的四个窗口又划分为九个窗口,这里的九个窗口中每个窗口就携带了更多的信息,划分之后不能直接做注意力
将上面的三个windows移到下面,再将左边的三个windows移到右边,就得到了新的feature map,将5和3,1和7,8 6 2 0合为一起,内部去做注意力,但是又会有一个新的问题,就是例如5和3,1和7本身就不在一起,强行去一起做注意力是不行的,因此就需要加上mask MSA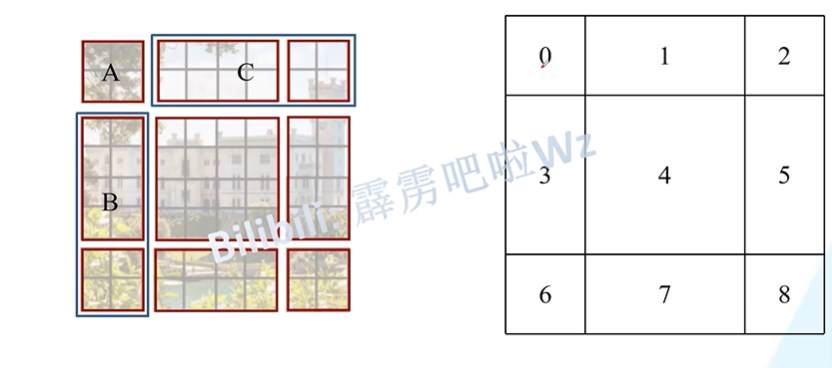
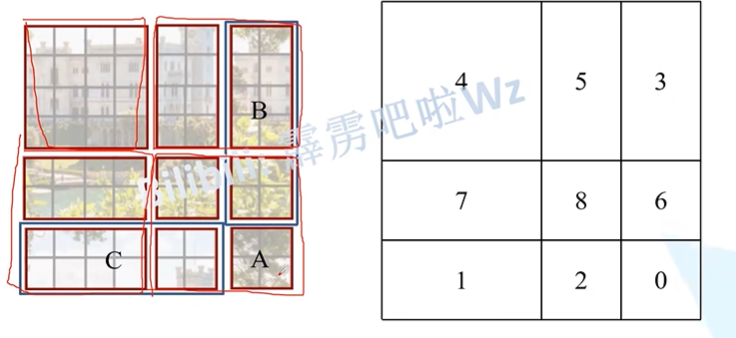
例如5和3,在对区域5中的0去做注意力时,将2 3 6 7 10 11 14 15的值减去100,这样在经过softmax后就相当于是0了。
在做完所有的操作后还会将移动过的windows再移动回去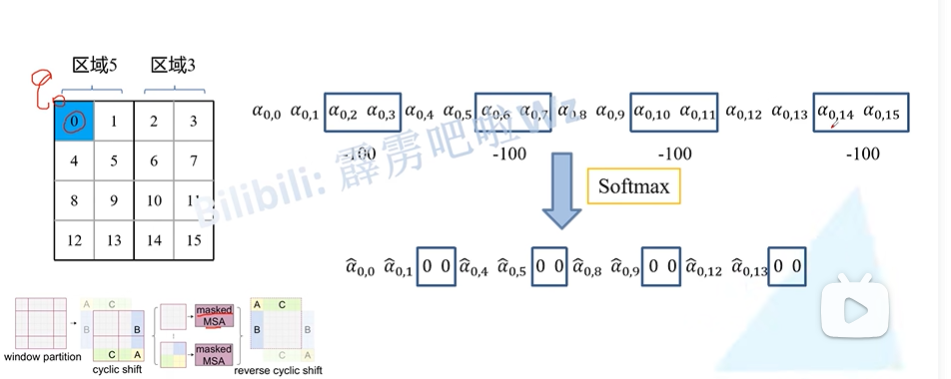
思考题
在ViT中要降低 Attention的计算量,有哪些方法?(提示:Swin的 Window attention,PVT的attention)
swin 的windows 就是在windows内做注意力,再“打乱”一下做注意力,这个做的还比较厉害一点
PVT 就是在生成QKV之后,将K和V做一个下采样,例如QKV原本是[hw,C],KV就先变为[hw/R²,C],这样Q@KT再@V后维度不变,也实现了减小计算量的目的
我觉得,有些论文能发表在顶会上的很重要一个原因是实验做的足够多,还有一个可能是通讯有名了hhhhh
Swin体现了一种什么思路?对后来工作有哪些启发?(提示:先局部再整体)
将较大的feature map分割成小的windows分别做注意力,为了防止信息交互少还添加了SW-MSA层,这样既减小了计算量效果也不会差
有些网络将CNN和Transformer结合,为什么一般把 CNN block放在面前,Transformer block放在后面?
我认为CNN block有时候是用来作为embedding的替代或改进的,例如在VIT中是使用卷积分割patches+展平操作来模拟embedding层,可以在卷积分割这个地方来添加CNN层来更好的模拟embedding层
阅读并了解Restormer,思考:Transformer的基本结构为 attention+ FFN,这个工作分别做了哪些改进?
这篇论文是CVPR2022上面的一篇,整体思想是:
对于图像修复来讲,CNN和transformer各有缺点
CNN由于其天生的受限的感受野,难以建模长距离像素依赖关系,也就是很难将一个区域与离它很远的区域联系起来:也许会有这样的情况,白云和湖面的倒影有很强的关系,但CNN的卷积核却很难理解
Transformer的注意力机制理论上会让每个像素与其他所有像素都有互动,但是它对于高分辨率的图像计算起来特别复杂,训练缓慢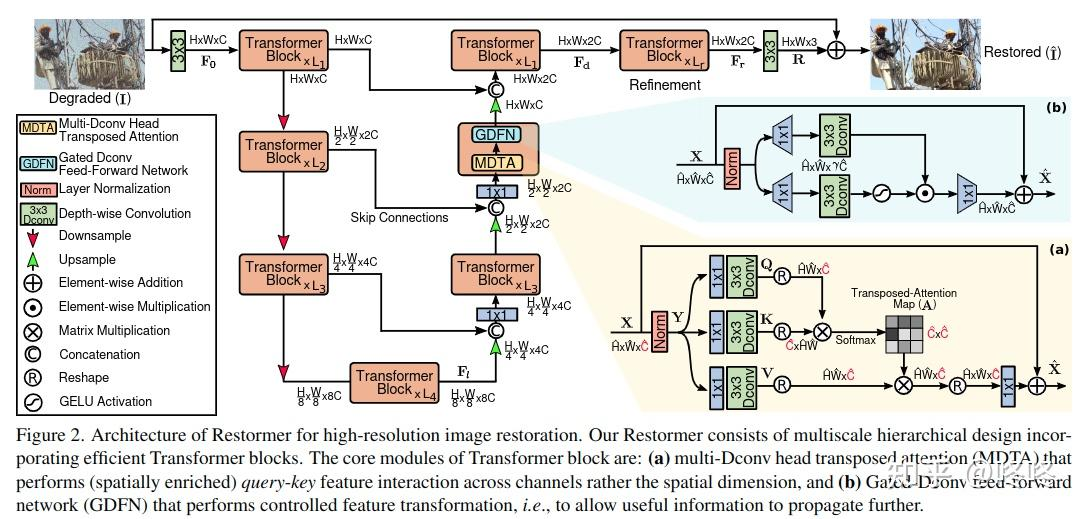
Restormer的目标是设计一个高效的Transformer模型,适用于高分辨率图像恢复,其创新点在于:
1、多Dconv头转置注意力(MDTA)
我看了几篇博客的介绍,他们说这篇论文不是计算空间上的注意力而是通道上的注意力,但是都没有细讲,论文的结构图也没有很好的解决我的疑惑,于是就去看了一下源码
源码关于MDTA部分的代码如下所示
class Attention(nn.Module):
def __init__(self, dim, num_heads, bias):
super(Attention, self).__init__()
self.num_heads = num_heads
self.temperature = nn.Parameter(torch.ones(num_heads, 1, 1))
self.qkv = nn.Conv2d(dim, dim*3, kernel_size=1, bias=bias)
self.qkv_dwconv = nn.Conv2d(dim*3, dim*3, kernel_size=3, stride=1, padding=1, groups=dim*3, bias=bias)
self.project_out = nn.Conv2d(dim, dim, kernel_size=1, bias=bias)
def forward(self, x):
b,c,h,w = x.shape
qkv = self.qkv_dwconv(self.qkv(x))
q,k,v = qkv.chunk(3, dim=1)
q = rearrange(q, 'b (head c) h w -> b head c (h w)', head=self.num_heads)
k = rearrange(k, 'b (head c) h w -> b head c (h w)', head=self.num_heads)
v = rearrange(v, 'b (head c) h w -> b head c (h w)', head=self.num_heads)
q = torch.nn.functional.normalize(q, dim=-1)
k = torch.nn.functional.normalize(k, dim=-1)
attn = (q @ k.transpose(-2, -1)) * self.temperature
attn = attn.softmax(dim=-1)
out = (attn @ v)
out = rearrange(out, 'b head c (h w) -> b (head c) h w', head=self.num_heads, h=h, w=w)
out = self.project_out(out)
return out
一个1x1的卷积,一个3x3的卷积……等一下,不是深度可分离卷积吗?难道groups=3就完成了DW+PW的操作吗?好像还真的是这样,我发现好多论文中的复杂的故事在实现上都很简单,就像vit中分割patches的操作也可以使用conv2d实现。到底是首先想到了轻量化设计再提出了深度可分离卷积DW+PW,最后发现竟然conv2d可以直接支持这样做;还是发现了conv2d中的groups参数,又发现这个操作可以减少参数量和计算量,再想到可以用到轻量化上从而讲了一个好故事。
言归正传,从代码中可以看出,所谓的MDTA,实际上就是在生成qkv时使用了深度可分离卷积,让计算量和参数量变少
2、门控Dconv前馈网络(GDFN)
class FeedForward(nn.Module):
def __init__(self, dim, ffn_expansion_factor, bias):
super(FeedForward, self).__init__()
hidden_features = int(dim*ffn_expansion_factor)
self.project_in = nn.Conv2d(dim, hidden_features*2, kernel_size=1, bias=bias)
self.dwconv = nn.Conv2d(hidden_features*2, hidden_features*2, kernel_size=3, stride=1, padding=1, groups=hidden_features*2, bias=bias)
self.project_out = nn.Conv2d(hidden_features, dim, kernel_size=1, bias=bias)
def forward(self, x):
x = self.project_in(x)
x1, x2 = self.dwconv(x).chunk(2, dim=1)
x = F.gelu(x1) * x2
x = self.project_out(x)
return x
可以看出,这里所谓的GDFN就是用深度可分离卷积核去代替卷积核

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 21
21 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)