AI大模型面试真题:“衡量大模型能力的常用NLP指标有哪些?看完这一篇你就知道怎么答了!!
本文详细介绍了衡量大模型能力的五种关键NLP指标:Perplexity(困惑度)、BLEU(机器翻译评估)、ROUGE(文本摘要评估)、METEOR(加强版翻译评估)和BERTScore(基于BERT的深度语义匹配)。这些指标从简单的n-gram匹配到深度语义相似度计算,各有优缺点和适用场景,是评估大模型性能的重要工具,对AI从业者学习与面试都具有重要价值。
问题
衡量大模型能力的常用 NLP 指标有哪些?
答案
现在大模型测评的方法有很多,比如传统的 NLP metrics,Automatic Benchmark,人工评估,LLM-as-a-Judge 等等。
今天先聊聊常用的一些 NLP metrics。
BLEU
BLEU(Bilingual Evaluation Understudy)是一个很老的指标了,最早用来评估机器翻译的质量。
其核心思想是: 如果与参考答案匹配的n-gram越多,那么就认为翻译质量越高。是一个只看准确率的指标。
由于并不看 n-gram 的召回率,这样的匹配方法对于短文本是有利的。极端情况下,要评估的文本只有一个词,这个词在参考答案中,那么 BLEU 的得分就是满分。为了解决这个问题,BLEU 又加了个长度惩罚因子。所以 BLEU 的公式有两部分组成:几何平均的n-gram精度 和 长度惩罚因子,具体如下:
其中 pn 为 n-gram 匹配的精度。
BP 全称为 Brevity Penalty, 是一个长度惩罚项。
若机器翻译长度 c 短于参考翻译 r,则惩罚得分:
避免短句子因部分匹配而得分虚高。
BLEU 的优点是计算简单,可以快速的粗略估计翻译的质量。但是也有缺点:
- 由于使用 n-gram 计算,可能无法准确捕捉翻译文本的整体含义或流畅性。
- 即使加入惩罚,由于只关注准确率,BLEU 打分还是对短文本有利。
ROUGE
这是一个评估文本摘要的常用指标,全称为 Recall-Oriented Understudy for Gisting Evaluation。最早的 ROUGE 只关注召回率。但是后来 ROUGE 计算的时候把准确率和召回率都考虑到了。
最早用于评估文本摘要的效果。让模型输出一份文本摘要,然后与人写的文本摘要进行对比。ROUGE 的做法就是在这两份摘要上计算准确率和召回率。
最简单的 ROUGE 是 ROUGE-1,它只计算单个词的匹配情况。
ROUGE-1 Recall 就是模型输出匹配的人类摘要词数,除以人类摘要的总词数。ROUGE-1 Precision 则是模型输出匹配的人类摘要词数,除以模型输出摘要的总词数。知道了 Recall 和 Precision,还可以计算一个 ROUGE-F1 的结果。
然而 ROUGE-1 有一个很大的问题,那就是不考虑词的顺序。比如 “小处不可随便” 和 “不可随处小便”,“屡败屡战” 和 “屡战屡败”, 在 ROUGE-1 看来没什么区别。
所以又有了 ROUGE-n, 取 n-gram 来作为匹配的对象。ROUGE-n 只专注于连续词的顺序,对于不连续的词则并不认为是一个好的匹配。
ROUGE-L 可以缓解 ROUGE-n 的问题,它匹配的是模型摘要和人类摘要的最长公共子序列。这使得 ROUGE-L 对单词的确切顺序不那么敏感,即使文本的写法可能完全不同,但是也能捕捉到文本的主旨或要点。
总结来说,ROUGE 的指标可以用来测评有参考答案的文本生成质量。
优势是计算高效,适合大规模生成任务的快速横向对比。
缺陷是仅基于表面词汇重叠,无法捕获语义的层面的信息,比如稍微换个同义词和表达顺序就会导致指标显著下降。
METEOR
METEOR 全称为 Metric for Evaluation of Translation with Explicit ORdering。依然可以根据参考答案进行打分,可以说是前两个的进一步的加强版。
它采用准确率,召回率,碎片惩罚三部分来计算。
假设 wt 为候选文本的单词数,wr 为参考文本的单词数。
假设 m 为候选文本和参考文本中匹配词的个数。注意 METEOR 在匹配的时候考虑了词形词干(Stemmer)和同义词(Synonymy),所以一定程度上缓解了精确匹配导致的无法捕获语义的问题。
那么准确率 , 召回率
与传统 F1 不同的是,这里的计算采用了调和平均,通常公式如下:
可以看出,到目前为止 METEOR 没有考虑 n-gram,都是 unigram。那如何使用顺序信息呢?
METEOR 的做法是在候选文本和参考文本中可以匹配的两个单词中间划一条线,这样就构建了一个二部图。然后就开始寻找二分图最大匹配。当然答案可能有很多个,这个时候就选择线交叉最少的解,这样就可以尽量保证连续的 chunk 可以匹配到。
定义惩罚项为
其中 c 是分割的 chunk 数量,越小越好。um 为 匹配到的单词数。
最终 METEOR 的得分为
METEOR 的方法缓解了 BLEU 和 ROUGE 的部分问题,尤其是可以借助 Stemmer 工具和 同义词工具来解决部分语义匹配对问题。在实际使用中,METEOR 也比 BLEU 和 ROUGE 更接近人类测评的结果。
BERTScore
当 BERT 出现后,可以用深度语义匹配来捕捉同义词替换和上下文关联,仅仅通过 cosine 相似度就可以判断两个词是否相似。
所以 BERTScore 就借助了 BERT 计算了下面三个指标:
- 精确率(Precision):生成文本中的每个词与参考文本中最相似的词匹配,计算相似度均值。
- 召回率(Recall):参考文本中的每个词与生成文本中最相似的词匹配,计算相似度均值。
- F1值:精确率和召回率的调和平均。
公式如下, 也很容易理解:
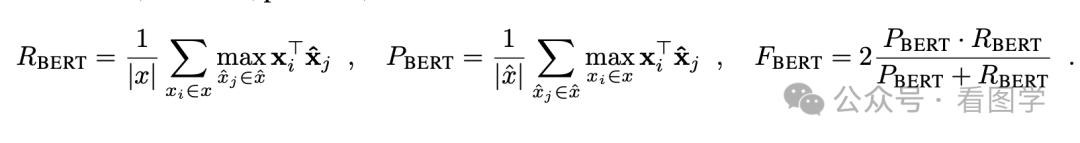
实际应用中,BERTScore 可对词向量进行IDF(逆文档频率)加权,使某些关键词(如名词)的匹配贡献更大。
最后
为了助力朋友们跳槽面试、升职加薪、职业困境,提高自己的技术,本文给大家整了一套涵盖AI大模型所有技术栈的快速学习方法和笔记。目前已经收到了七八个网友的反馈,说是面试问到了很多这里面的知识点。
由于文章篇幅有限,不能将全部的面试题+答案解析展示出来,有需要完整面试题资料的朋友,可以扫描下方二维码免费领取哦!!! 👇👇👇👇


面试题展示
1、请解释一下BERT模型的原理和应用场景。
答案:BERT(Bidirectional Encoder Representations from Transformers)是一种预训练的语言模型,通过双向Transformer编码器来学习文本的表示。它在自然语言处理任务中取得了很好的效果,如文本分类、命名实体识别等。
2、什么是序列到序列模型(Seq2Seq),并举例说明其在自然语言处理中的应用。
答案:Seq2Seq模型是一种将一个序列映射到另一个序列的模型,常用于机器翻译、对话生成等任务。例如,将英文句子翻译成法文句子。
3、请解释一下Transformer模型的原理和优势。
答案:Transformer是一种基于自注意力机制的模型,用于处理序列数据。它的优势在于能够并行计算,减少了训练时间,并且在很多自然语言处理任务中表现出色。
4、什么是注意力机制(Attention Mechanism),并举例说明其在深度学习中的应用。
答案:注意力机制是一种机制,用于给予模型对不同部分输入的不同权重。在深度学习中,注意力机制常用于提升模型在处理长序列数据时的性能,如机器翻译、文本摘要等任务。
5、请解释一下卷积神经网络(CNN)在计算机视觉中的应用,并说明其优势。
答案:CNN是一种专门用于处理图像数据的神经网络结构,通过卷积层和池化层提取图像特征。它在计算机视觉任务中广泛应用,如图像分类、目标检测等,并且具有参数共享和平移不变性等优势。
6、请解释一下生成对抗网络(GAN)的原理和应用。
答案:GAN是一种由生成器和判别器组成的对抗性网络结构,用于生成逼真的数据样本。它在图像生成、图像修复等任务中取得了很好的效果。
7、请解释一下强化学习(Reinforcement Learning)的原理和应用。
答案:强化学习是一种通过与环境交互学习最优策略的机器学习方法。它在游戏领域、机器人控制等领域有广泛的应用。
8、请解释一下自监督学习(Self-Supervised Learning)的原理和优势。
答案:自监督学习是一种无需人工标注标签的学习方法,通过模型自动生成标签进行训练。它在数据标注困难的情况下有很大的优势。
9、解释一下迁移学习(Transfer Learning)的原理和应用。
答案:迁移学习是一种将在一个任务上学到的知识迁移到另一个任务上的学习方法。它在数据稀缺或新任务数据量较小时有很好的效果。
10、请解释一下模型蒸馏(Model Distillation)的原理和应用。
答案:模型蒸馏是一种通过训练一个小模型来近似一个大模型的方法。它可以减少模型的计算和存储开销,并在移动端部署时有很大的优势。
11、请解释一下LSTM(Long Short-Term Memory)模型的原理和应用场景。
答案:LSTM是一种特殊的循环神经网络结构,用于处理序列数据。它通过门控单元来学习长期依赖关系,常用于语言建模、时间序列预测等任务。
12、请解释一下BERT模型的原理和应用场景。
答案:BERT(Bidirectional Encoder Representations from Transformers)是一种预训练的语言模型,通过双向Transformer编码器来学习文本的表示。它在自然语言处理任务中取得了很好的效果,如文本分类、命名实体识别等。
13、什么是注意力机制(Attention Mechanism),并举例说明其在深度学习中的应用。
答案:注意力机制是一种机制,用于给予模型对不同部分输入的不同权重。在深度学习中,注意力机制常用于提升模型在处理长序列数据时的性能,如机器翻译、文本摘要等任务。
14、请解释一下生成对抗网络(GAN)的原理和应用。
答案:GAN是一种由生成器和判别器组成的对抗性网络结构,用于生成逼真的数据样本。它在图像生成、图像修复等任务中取得了很好的效果。
15、请解释一下卷积神经网络(CNN)在计算机视觉中的应用,并说明其优势。
答案:CNN是一种专门用于处理图像数据的神经网络结构,通过卷积层和池化层提取图像特征。它在计算机视觉任务中广泛应用,如图像分类、目标检测等,并且具有参数共享和平移不变性等优势。
16、请解释一下强化学习(Reinforcement Learning)的原理和应用。
答案:强化学习是一种通过与环境交互学习最优策略的机器学习方法。它在游戏领域、机器人控制等领域有广泛的应用。
17、请解释一下自监督学习(Self-Supervised Learning)的原理和优势。
答案:自监督学习是一种无需人工标注标签的学习方法,通过模型自动生成标签进行训练。它在数据标注困难的情况下有很大的优势。
18、请解释一下迁移学习(Transfer Learning)的原理和应用。
答案:迁移学习是一种将在一个任务上学到的知识迁移到另一个任务上的学习方法。它在数据稀缺或新任务数据量较小时有很好的效果。
19、请解释一下模型蒸馏(Model Distillation)的原理和应用。
答案:模型蒸馏是一种通过训练一个小模型来近似一个大模型的方法。它可以减少模型的计算和存储开销,并在移动端部署时有很大的优势。
20、请解释一下BERT中的Masked Language Model(MLM)任务及其作用。
答案:MLM是BERT预训练任务之一,通过在输入文本中随机mask掉一部分词汇,让模型预测这些被mask掉的词汇。
由于文章篇幅有限,不能将全部的面试题+答案解析展示出来,有需要完整面试题资料的朋友,可以扫描下方二维码免费领取哦!!! 👇👇👇👇



有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 3
3 0
0- 0



 已为社区贡献274条内容
已为社区贡献274条内容

所有评论(0)