Meta SAM-3 重磅发布:视觉 AI 迈入“想分什么就分什么”的自由时代
Meta发布了新一代视觉基础模型Segment Anything Model 3 (SAM-3),实现了从"分割一切"到"理解一切"的跨越。SAM-3通过创新的"可提示概念分割"技术支持文本、示例图和视觉提示,能对图像和视频中的任意概念进行检测、分割和跟踪。其混合AI/人工数据引擎显著提升了训练效率,创建了包含400多万个概念的训练集。
Meta 正式发布了其新一代视觉基础模型 Segment Anything Model 3 (SAM-3),标志着计算机视觉领域在通用目标理解上迈出了关键一步。SAM-3 是一个统一的模型,能够通过文本、示例图和视觉提示对图像和视频中的任何视觉概念进行检测、分割和跟踪。本文将深入探讨 SAM-3 的核心技术突破——可提示概念分割,其创新的混合数据引擎,以及它如何赋能下一代创意工具和科学研究。
Demo: https://segment-anything.com
Code: https://github.com/facebookresearch/sam3
Website: https://ai.meta.com/sam3
核心要点:
- 推出Meta Segment Anything Model 3 (SAM 3),这是一个统一的模型,它使用文本、示例和视觉提示来检测、分割和跟踪图像和视频中的对象。
- 作为此次发布的一部分,将分享SAM3 模型检查点、评估数据集和微调代码。 还推出了Segment Anything Playground,这是一个新平台,让任何人都能轻松了解 SAM 的功能,并尝试使用尖端 AI 模型进行创意媒体修改。
- 在Instagram 的视频创作应用Edits中,SAM 3 即将推出全新特效,创作者可以将其应用于视频中的特定人物或物体。
- SAM3 带来的全新创作体验也将登陆 Meta AI 应用的 Vibes 功能以及网页版meta.ai。 此外,还分享了 SAM3D,这是一套开源模型、代码和数据,用于从单张图像重建 3D 物体和人体,为物理世界场景中的基于实物的 3D重建树立了新标准。
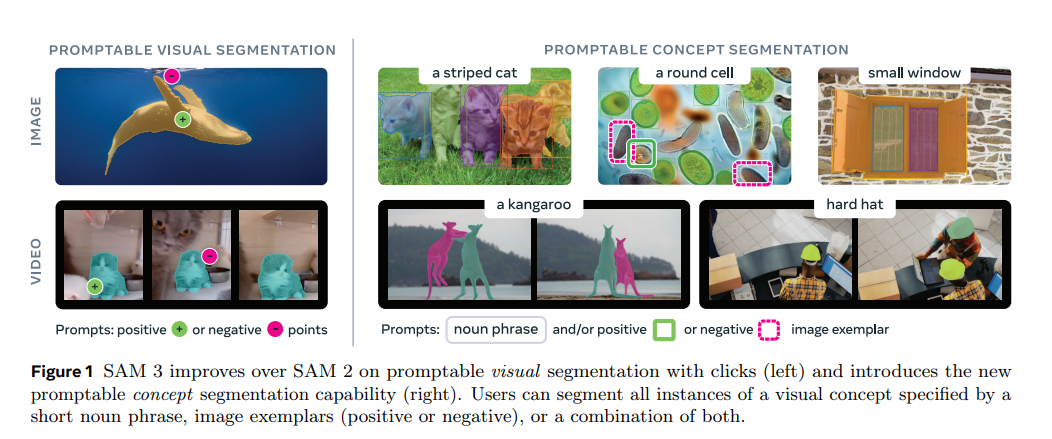
一、核心突破:从“分割一切”到“理解一切”
Segment Anything Model (SAM) 系列的初衷是实现对图像中所有物体的零样本分割。SAM-3 在此基础上,将能力从纯粹的视觉提示扩展到了语义提示,实现了可提示概念分割(Promptable Concept Segmentation)。
1. 统一的视觉任务处理能力
SAM-3 是一个统一的模型,集成了三大核心视觉任务:
- 检测 (Detection)
- 分割 (Segmentation)
- 跟踪 (Tracking)
它能处理图像和视频,并支持多种提示模态,极大地提升了模型的灵活性和实用性[1]。
2. 突破性的“可提示概念分割”
传统的分割模型通常受限于固定的文本标签集,难以处理未预定义的或细微的概念(例如,可以分割“人”,但难以分割“条纹红色的雨伞”)。SAM-3 通过引入可提示概念分割,克服了这一限制:
| 提示模态 | 描述 | 优势 |
|---|---|---|
| 文本提示 (Text Prompts) | 开放词汇的短名词短语(Open-Vocabulary Short Noun Phrases)。 | 摆脱固定标签集的限制,实现对任意概念的分割。 |
| 示例图提示 (Exemplar Prompts) | 提供一张包含目标概念的图像作为示例。 | 尤其适用于难以用文本描述或罕见的概念。 |
| 视觉提示 (Visual Prompts) | 沿袭 SAM 1 和 SAM 2 的能力,支持掩码、边界框和点。 | 保持了交互式视觉分割的强大能力。 |
3. 性能飞跃
SAM-3 在新的 SA-Co (Segment Anything with Concepts) 评估基准上,在图像和视频的概念分割性能上实现了 2 倍的提升,并持续在交互式视觉分割任务上保持领先。此外,SAM-3 的推理速度极快,在 H200 GPU 上,单张图像(包含 100 多个检测对象)的推理时间仅为 30 毫秒[1]。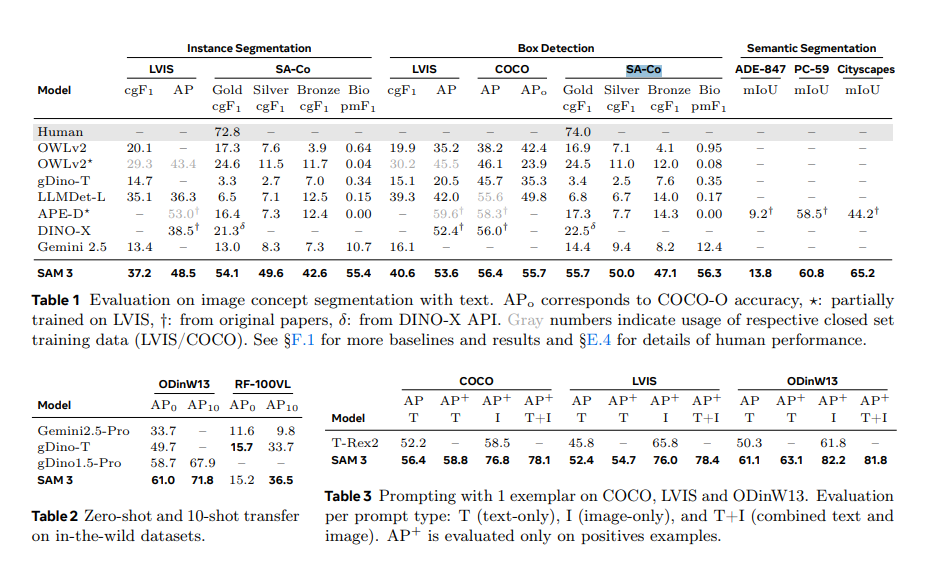
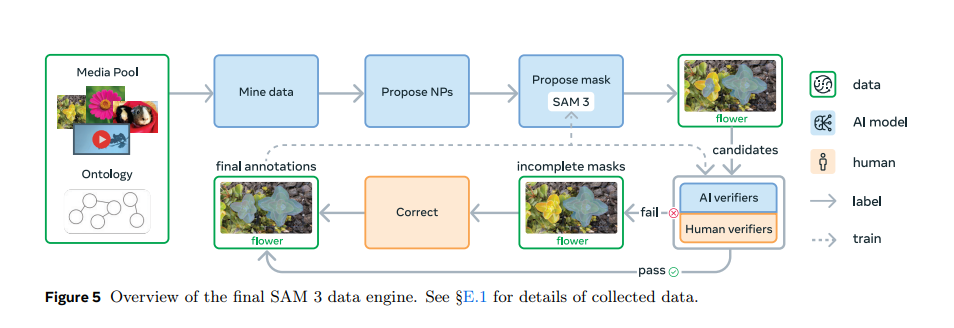
二、创新驱动:混合 AI/人工数据引擎
高质量、大规模的标注数据是训练 SAM-3 的关键挑战。Meta 创新性地构建了一个可扩展的混合数据引擎,结合了 SAM-3 自身、人工标注员和 AI 模型(如基于 Llama 3.2v 的标注系统),实现了数据标注效率的巨大飞跃[1]。
- 效率提升: 相比纯人工标注,该系统在负面提示(Negative Prompts)上的速度提高了约 5 倍,在正面提示(Positive Prompts)上提高了 36%。
- 数据规模: 最终创建了一个包含超过 400 万个独特概念的大型多样化训练集。
- AI 辅助标注: AI 标注员(基于 Llama 3.2v)负责验证和修正 SAM-3 生成的初始掩码,并过滤掉简单的示例,将人类标注员的精力集中在最具挑战性的案例上。
三、模型架构与应用生态
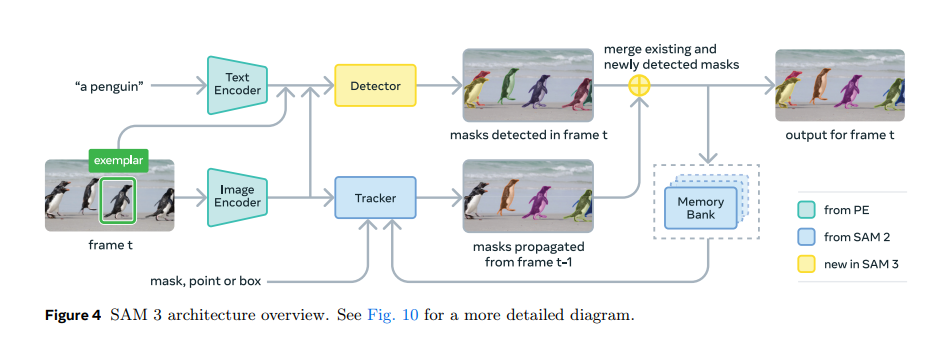
1. 模块化架构设计
SAM-3 的架构设计旨在解决多任务冲突,它建立在 Meta 之前多项 AI 成果之上:
- 编码器: 图像和文本编码器来自 Meta Perception Encoder,这是一个开源模型,为 SAM-3 带来了显著的性能飞跃。
- 检测器: 基于使用 Transformer 进行目标检测的 DETR 模型。
- 跟踪器: 基于 SAM 2 中的**内存库(Memory Bank)和内存编码器(Memory Encoder)**组件。
2. 赋能下一代应用
SAM-3 的强大能力正被迅速集成到 Meta 的产品生态中:
- 创意媒体工具: 在 Instagram 的视频创作应用 Edits 中,SAM-3 将支持创作者对视频中的特定人物或物体应用动态效果,将复杂的编辑工作流简化为一键操作。
- 3D 重建: 与 SAM-3 同时发布的 SAM 3D 套件,能够从单张图像重建 3D 物体和人体,为物理世界场景中的 3D 重建设定了新标准。
- 商业应用: SAM-3 和 SAM 3D 共同驱动了 Facebook Marketplace 的 “View in Room” 功能,让用户在购买前就能在自己的空间中可视化家居装饰品的效果。
- 科学研究: Meta 与 Conservation X Labs 等机构合作,利用 SAM-3 创建了首个公开的野生动物监测视频数据集 SA-FARI,用于加速保护工作。
结论
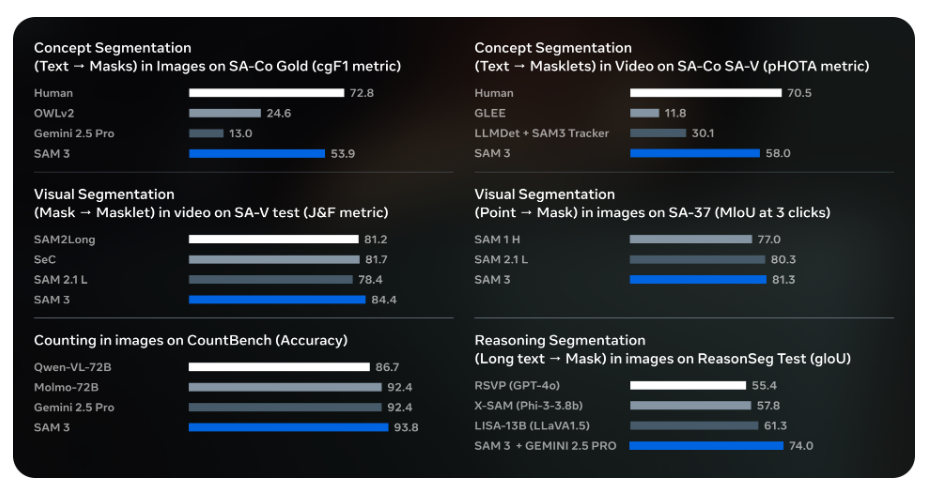
Meta Segment Anything Model 3 (SAM-3) 的发布,不仅巩固了 Meta 在计算机视觉基础模型领域的领先地位,更通过可提示概念分割和混合数据引擎等创新,极大地拓宽了通用视觉模型的应用边界。SAM-3 正在将复杂的视觉理解能力带入日常的创意工具、商业应用乃至前沿的科学研究中,为开发者和研究人员提供了一个前所未有的强大工具,以更高效、更灵活的方式处理和理解视觉世界。
参考文献
[1] Introducing Meta Segment Anything Model 3 and Segment Anything Playground. https://ai.meta.com/blog/segment-anything-model-3/. Meta AI Blog. Nov 19, 2025.

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 7
7 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)