超越视觉极限:Mini-o3复现OpenAI o3强大推理能力,开启多轮视觉搜索新纪元
o3的核心特点是能够产生数十步的思维链条,支持多种推理模式(如深度优先搜索、试错探索和自我反思),并且推理轮次越多,准确率越高。特别是在挑战性的VisualProbe-Hard数据集上,Mini-o3达到了48.0%的准确率,显著超过其他开源模型(DeepEyes为35.1%,Pixel Reasoner为28.8%)。这项工作的意义不仅在于复现了OpenAI o3类模型的能力,更重要的是为多模态

近日,字节跳动与香港大学的研究团队推出了Mini-o3,一个旨在复现OpenAI强大但未公开的o3模型能力的开源系统。这项研究突破了现有视觉语言模型在复杂视觉推理任务中的局限,让我们来看看这一令人振奋的进展。



OpenAI o3:神秘而强大的多模态推理引擎

OpenAI在2025年初推出了o3系列模型,展示了令人惊叹的多模态推理能力。根据官方演示,o3能够进行深度多轮推理,在复杂视觉搜索任务中表现出色。
o3的核心特点是能够产生数十步的思维链条,支持多种推理模式(如深度优先搜索、试错探索和自我反思),并且推理轮次越多,准确率越高。然而,OpenAI并未公开o3的技术细节和模型权重,给学术界和产业界留下了巨大空白。


现有模型的局限性:浅层推理与有限交互

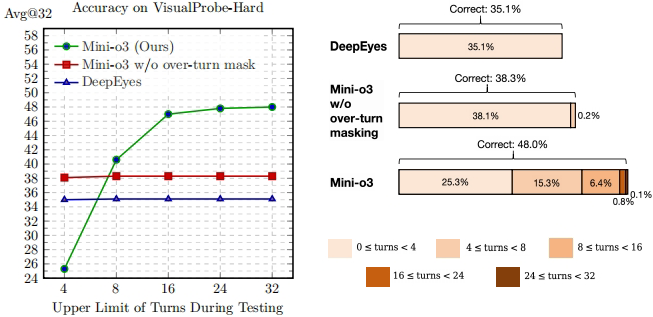
当前开源的视觉语言模型(如DeepEyes、LLaVA系列)在简单视觉搜索任务上表现尚可,但在需要试错探索的挑战性任务上表现不佳。论文图1(位于第2页)清晰展示了这一问题:DeepEyes在VisualProbe-Hard数据集上仅有35.1%的准确率。
现有模型主要存在两个问题:
-
一是推理模式单调,缺乏多样性;
-
二是交互轮次有限,例如在HR-Bench-4K数据集中,平均每个样本仅使用1轮图像工具交互。
Mini-o3解决方案:三位一体的技术路线
研究团队提出了一个完整的技术方案来复现o3类模型的能力,主要包括三个核心组件:
01
构建VisualProbe挑战性数据集
团队首先构建了VisualProbe数据集,包含4000个训练样本和500个测试样本,分为简单、中等和困难三个难度级别。
与现有基准(如V* Bench、HR-Bench)相比,VisualProbe具有三大特点:
-
目标物体尺寸小
-
干扰物体数量多
-
图像分辨率高

这些特性使VisualProbe成为真正挑战性的测试平台,需要模型进行迭代探索和试错推理。
02
冷启动数据收集流程
研究发现,如果直接使用强化学习训练,模型倾向于产生简短响应和少量推理轮次。为此,团队开发了迭代式冷启动数据收集流程
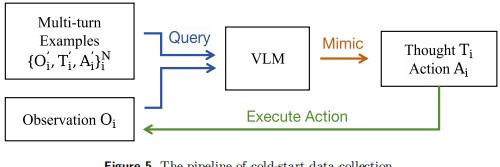
该方法使用少量人工编写的示例(仅6个),通过现有VLM模型的上下文学习能力,生成约6000条高质量多轮轨迹。这些轨迹展示了多种推理模式:深度优先搜索、试错探索和目标维持。
03
过度轮次掩码技术
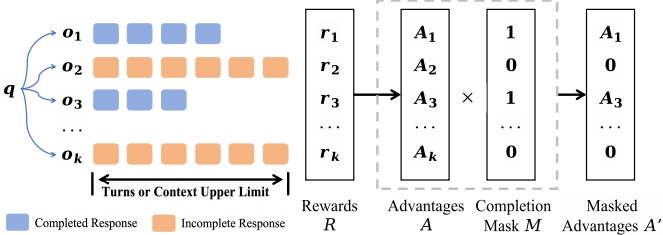
这是研究的关键创新点。在传统强化学习设置中,超过最大轮次的响应会被惩罚(奖励设为0),这会导致模型过早给出答案,抑制了深度推理。
团队提出了过度轮次掩码技术(图7位于第8页),避免惩罚那些超过训练时轮次上限的响应,从而:
-
减少训练不稳定性
-
支持测试时轮次扩展
-
使模型能够解决需要大量推理轮次的难题
04
模型架构与训练流程
Mini-o3基于Qwen2.5-VL-7B-Instruct模型构建,其多轮代理推理流程如图所示:

训练过程分为两个阶段:
-
监督微调(SFT):使用冷启动数据训练模型生成多样且稳健的推理轨迹
-
强化学习与可验证奖励(RLVR):使用GRPO算法和语义感知奖励优化模型策略
05
卓越的性能表现
如表1(位于第9页)所示,Mini-o3在多个视觉搜索基准测试中实现了最先进的性能:
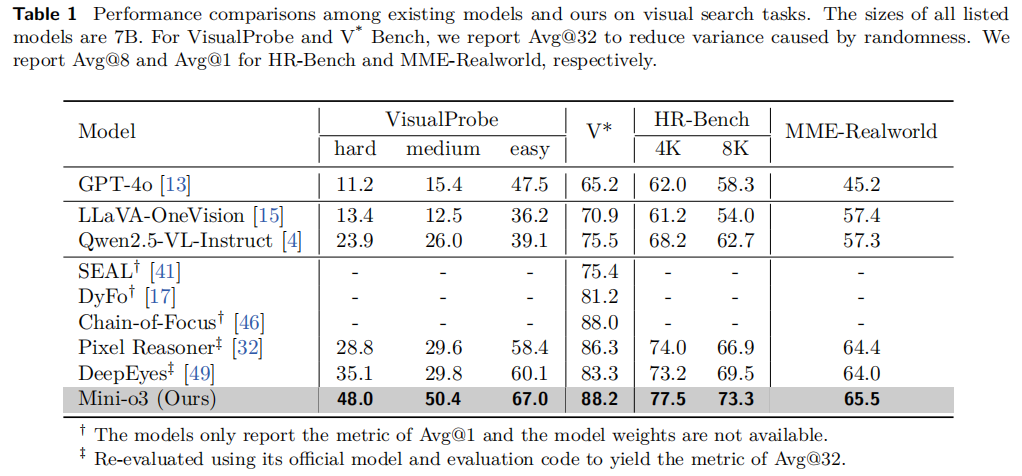
特别是在挑战性的VisualProbe-Hard数据集上,Mini-o3达到了48.0%的准确率,显著超过其他开源模型(DeepEyes为35.1%,Pixel Reasoner为28.8%)。
深度推理:Mini-o3的实际应用示例
论文附录中提供了多个Mini-o3的实际推理案例,展示了其强大的多轮推理能力:
01
城市交通场景推理
模型通过多轮推理(渐进缩放、假设修正和回溯)识别箭头方向。

02
集装箱码头文本识别
在密集文本标记中定位特定字符串并读取下方数字。
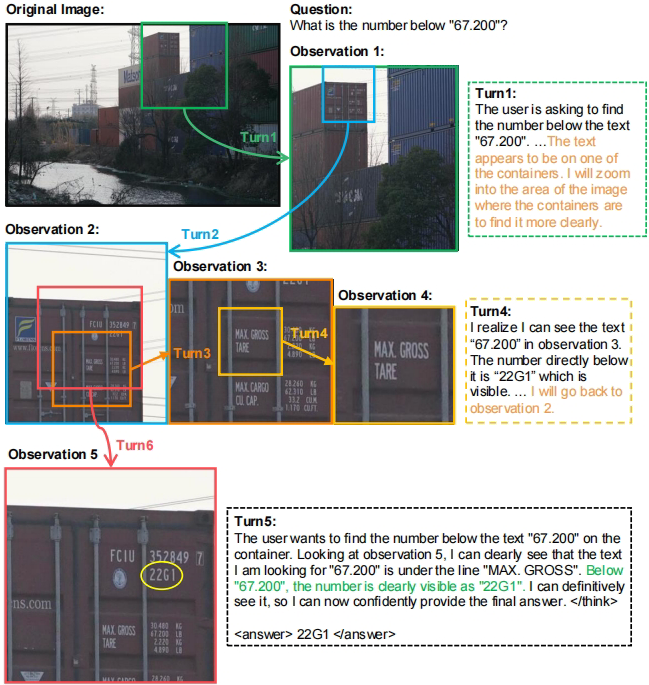
03
湖边村庄路牌识别
经过18轮推理,最终识别出标志上的数字"30"。

技术贡献与未来意义
Mini-o3的研究提供了完整可复现的技术方案,包括:
-
挑战性视觉搜索数据集的构建方法
-
利用现有VLM生成高质量冷启动数据的流程
-
创新的过度轮次掩码技术,支持测试时轮次扩展
这项工作的意义不仅在于复现了OpenAI o3类模型的能力,更重要的是为多模态模型的深度推理研究提供了实用指南。团队开源了所有代码和模型权重,促进了学术交流和进一步研究。


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 17
17 0
0- 0



 已为社区贡献26条内容
已为社区贡献26条内容

所有评论(0)