从Transformer到实际部署:小型语言模型(SLM)实战指南,小白也能掌握的AI部署全攻略!
文章介绍小型语言模型(SLM)在特定任务上优于大型模型的优势,详细讲解Transformer架构工作原理,提供从零开始微调7B模型的完整流程,以及使用llama.cpp和vLLM进行生产部署的方法。讨论何时选择SLM而非云API的决策框架,以及生产环境中的常见问题解决方案,帮助开发者在有限资源下高效部署专业化的AI模型。
从Transformer基础到实际部署
你的CTO刚刚终止了你的AI项目。
演示非常完美。你的医疗聊天bot以令人印象深刻的准确性回答了患者问题。医生们很喜欢它。试点运行也很顺利。然后,会计部门发来了云API账单:一个月五位数。
你的CTO算了算全面部署到所有诊所的成本,说了一句话:“我们需要更好地考虑投资回报率。”
你的合规官员早已表示反对——患者数据不能离开大楼,这是HIPAA合规的硬性要求。
你的用户拒绝了2025年仍需3秒的响应时间。
三个"不"。项目死亡。
但没人告诉你:你一直在解决错误的问题。
你需要的是一个专家,而不是通才。你需要一个可以在自己数据中心运行的模型,而不是别人云上的模型。你需要一个能装在4GB内存中、400毫秒内响应的模型,而不是需要40GB内存、3秒响应的模型。
你需要一个小型语言模型。
反直觉的真相:小型模型往往优于大型模型。
不是因为小型模型知道更多——它们不知道。但它们知道对你的问题来说什么更重要。医疗专家在医疗问题上胜过全科医生。法律专家在合同分析上胜过博学者。同样的原理,应用于AI。
可以这样理解:你不需要一辆F1赛车来通勤上班。你需要一辆可靠、高效的交通工具,能应对真实路况并安全到达目的地。
这正是小型语言模型的构建目标:为特定目的而生的智能。
TL;DR:你将学到什么
问题:云API昂贵、缓慢,且无法通过合规审查。大多数AI项目都死在这里。
解决方案:小型语言模型(1-10B参数),可本地运行、即时响应、每百万次查询成本只需几美分。
你将学到:
- • Transformer的实际工作原理(10分钟就能明白的解释)
- • 何时构建SLM与仅使用API(包含决策框架)
- • 如何在消费级硬件上微调7B模型(分步代码)
- • 不会在凌晨3点崩溃的生产部署(监控、量化等)
适合人群:你是高级工程师或架构师,需要在不烧钱或违反合规的前提下交付AI功能。你想了解基础知识并看到实际实现,而不是营销幻灯片。
时间投入:25分钟阅读 如果你厌倦了不符合约束条件的API,这是值得的。
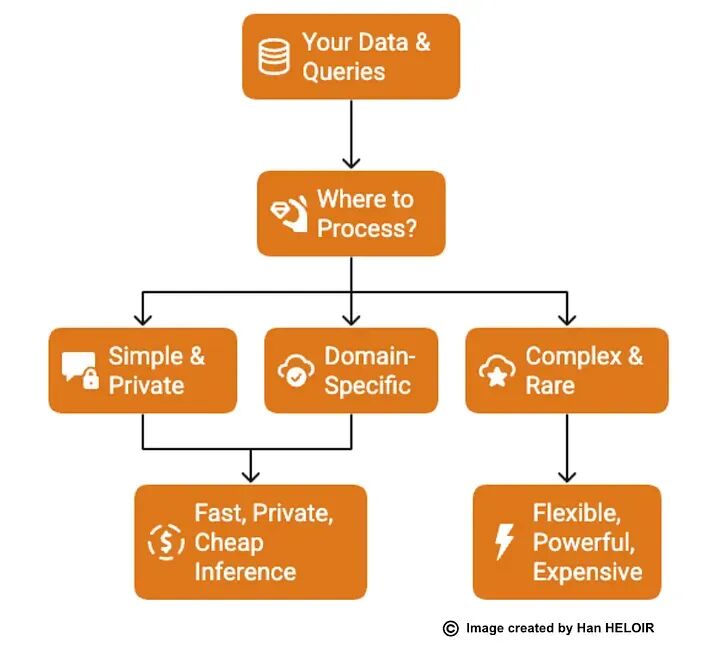
语言模型部署选项决策流程图
第1节:直觉理解 — 从未真正学过Transformer?从这里开始
让我们明确一点:语言模型只是预测接下来内容的软件。
你每天都在使用一个——你手机的自动补全功能。输入"我正前往…“,它会建议"商店”、“办公室"或"健身房”。这就是一个语言模型,基于从数百万例子中学到的模式进行预测。

没什么神奇的。只是大规模的模式匹配。
但有趣的部分来了。
演变:从愚蠢的自动补全到真正的理解
旧式自动补全(1990年代-2010年代):只看最后一个词
你输入:“bank”
它建议:“account”、“statement”、“transfer”
问题:不理解上下文
语言模型(2020年代):阅读整个对话
你输入:“I love fishing by the bank”
模型理解:你指的是河岸,而不是金融机构
建议:“watching the sunset”、“catching bass”、“on weekends”
**区别是什么?**注意力机制。
模型"关注"你句子中的所有单词,而不仅仅是最后一个。它理解"fishing"附近的"bank"与"savings"附近的"bank"含义不同。
这种机制——关注上下文——就是Transformer。这就是架构。"语言模型"部分是它的功能:预测文本。
现在让我展示注意力机制的实际工作原理。我保证不用线性代数。
一直在更新,更多的大模型学习和面试资料已经上传带到CSDN的官方了,有需要的朋友可以扫描下方二维码免费领取【保证100%免费】👇👇

Transformer架构:注意力就是你所需要的一切
2017年,谷歌研究人员发表了一篇题为"Attention Is All You Need"的论文,改变了一切。他们引入了Transformer——模型理解语言的新方式。
他们解决的问题:如何让模型理解句子中相距较远的单词可以相互关联?
考虑这个句子:The animal didn’t cross the street becauseitwas too tired.
"it"指的是什么?动物还是街道?你知道是动物——街道不会累。但模型如何弄清楚这一点?
旧方法(RNNs — 循环神经网络):
- • 从左到右逐词处理
- • 当到达"it"时,模型已经部分"忘记"了"animal"
- • 像短期记忆丧失一样阅读
- • 结果:对"it"的含义感到困惑
Transformer方法:
- • 同时查看所有单词
- • 计算哪些单词相互关联
- • “it"强烈关注"animal”,弱关注"street"
- • 像一次性把整个句子放在面前
- • 结果:立即知道"it"=动物
注意力机制实际工作原理(无需数学知识)
把注意力想象成剧院里的聚光灯。
设置:
你试图理解句子中的"it"这个词。Transformer创建了三个问题:
-
- 查询(Query):“我想理解什么?”(单词"it")
-
- 键(Key):“其他单词有什么信息?”(所有其他单词广告它们的意思)
-
- 值(Value):“我应该使用的实际含义是什么?”(要提取的内容)

过程:
步骤1:"it"问:“谁能告诉我我指的是什么?”
步骤2:每个单词回答相关性得分:
- • “animal” → 高相关性(90%)
- • “street” → 低相关性(10%)
- • “because” → 无相关性(0%)
- • “tired” → 中等相关性(40%)
步骤3:"it"取加权平均值:
- • 主要从"animal"复制含义(90%)
- • 稍微考虑"tired"(40%)
- • 忽略"street"(10%)
结果:“it”=动物
这对每个单词同时发生,查看所有其他单词。这就是为什么它被称为**“自注意力”**——每个单词关注所有其他单词。
多头注意力:同时关注多个方面
这里变得巧妙了。一个注意力机制可以专注于语法。另一个专注于意义。另一个专注于关系。
例句:The chef who runs the restaurant makes amazing pasta.
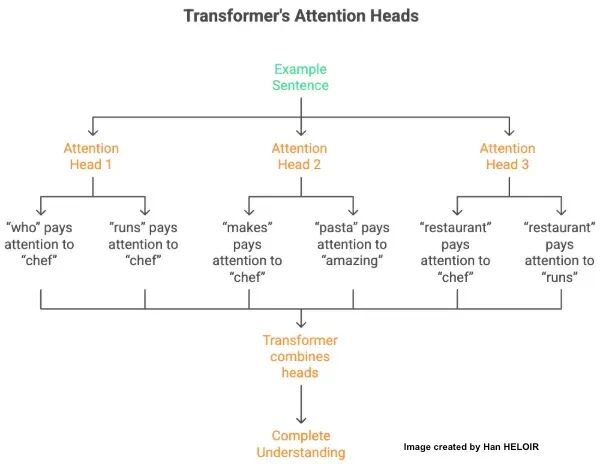
例句:The chef who runs the restaurant makes amazing pasta.
注意力头1(语法重点):
• “who"关注"chef”(主语)
• “runs"关注"chef”(动词一致性)
注意力头2(意义重点):
• “makes"关注"chef”(谁在做)
• “pasta"关注"amazing”(什么品质)
注意力头3(关系重点):
• “restaurant"关注"chef"和"runs”(chef经营restaurant)
每个"头"专攻不同模式。Transformer结合所有头构建完整理解。
这对小型模型的重要性:
• Phi-3-mini:32个注意力头
• Qwen2–1.5B:16个注意力头
• TinyLlama-1.1B:32个注意力头
更多头=可以同时跟踪更多关系。但即使是16个头也能捕捉复杂模式——关键在于高效设计,而不仅仅是数量。
完整Transformer块(简化版)
Transformer不仅仅是注意力。它有协同工作的层:
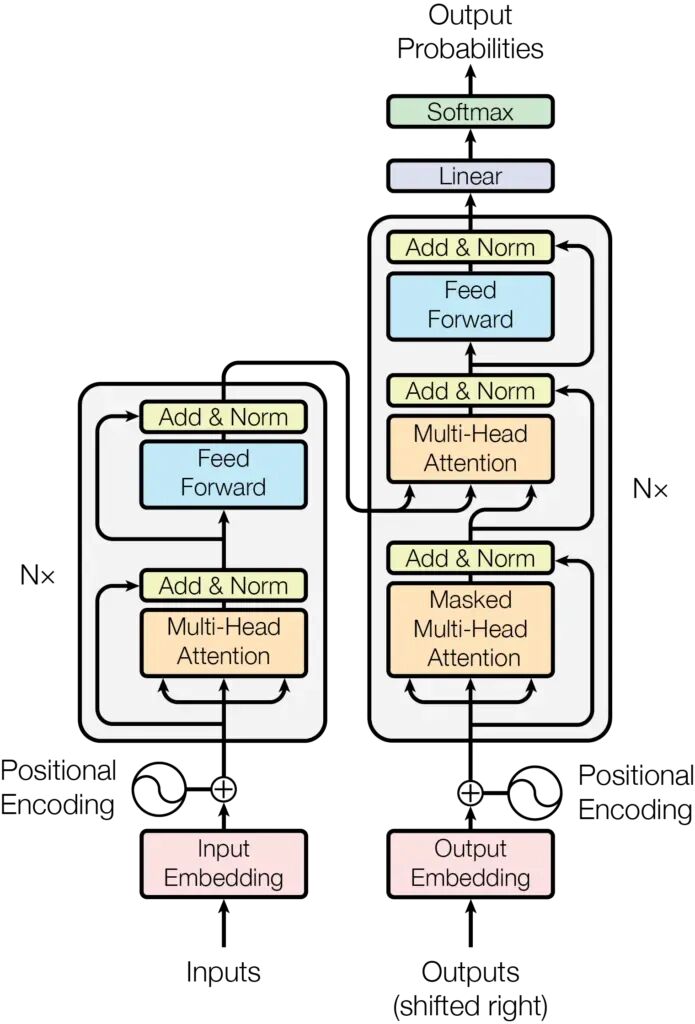
Attention is all you need(必读论文)
步骤1:分词(TOKENIZATION)
分解为片段:["The", "cat", "sat", "on"]
步骤2:嵌入(EMBEDDING)
转换为模型理解的数字(向量)
"cat" → [0.2, 0.8, 0.1, 0.9, ...]
步骤3:位置编码(POSITIONAL ENCODING)
添加单词位置信息
(位置很重要:dog bites man ≠ man bites dog)
步骤4:多头自注意力(MULTI-HEAD SELF-ATTENTION)
每个单词检查所有其他单词以创建上下文感知表示。
步骤5:前馈网络(FEED-FORWARD NETWORK)
处理注意力输出并应用学习到的转换。
步骤6:层归一化(LAYER NORMALIZATION)
保持处理过程中数值稳定
步骤7:重复12-40次
每层提取更深模式(数量取决于模型大小)
步骤8:输出预测(OUTPUT PREDICTION)
所有可能下一个单词的概率分布:
- • “mat” → 45%
- • “chair” → 30%
- • “floor” → 15% …
最终输出:mat
关键见解:每层完善理解。
早期层(1-6):学习基本模式——语法、常用短语、句子结构
中间层(7-20):学习语义关系——单词一起的含义
深层(20+):学习抽象概念——逻辑、推理、领域知识
小型模型层数较少(6-32层)vs大型模型(40-80+层)。但对于专注任务,专注于你领域的较少层通常比在所有内容上训练的许多层效果更好。
这就是SLM的全部秘密:深度不是一切。专业化更重要。
为什么Transformer取代了其他一切

为什么Transformer取代了其他一切
Transformer之前(RNNs, LSTMs):
• 顺序处理单词(慢)
• 难以处理长距离关系
• 难以并行化(无法有效利用GPU)
• "忘记"句子开头的信息
Transformer之后:
• 同时处理所有单词(快)
• 通过注意力自然处理长距离关系
• 大规模并行(GPU喜欢它们)
• 可以平等关注任何之前的单词
这就是为什么每个现代语言模型——ChatGPT、Claude、Gemini和所有SLM——都使用Transformer架构。它就是更好。
SLM的效率突破:
研究人员发现你不需要96层和1750亿参数。你可以:
• 使用24层配合智能注意力模式
• 在高质量领域数据上训练
• 针对特定硬件(手机、笔记本电脑)优化
• 应用高效注意力机制(分组查询注意力、滑动窗口)
结果:在特定任务上匹配或击败大型模型的10-100倍更小的模型。
当任务明确定义时,专业化胜过泛化。
现代SLM中的注意力模式
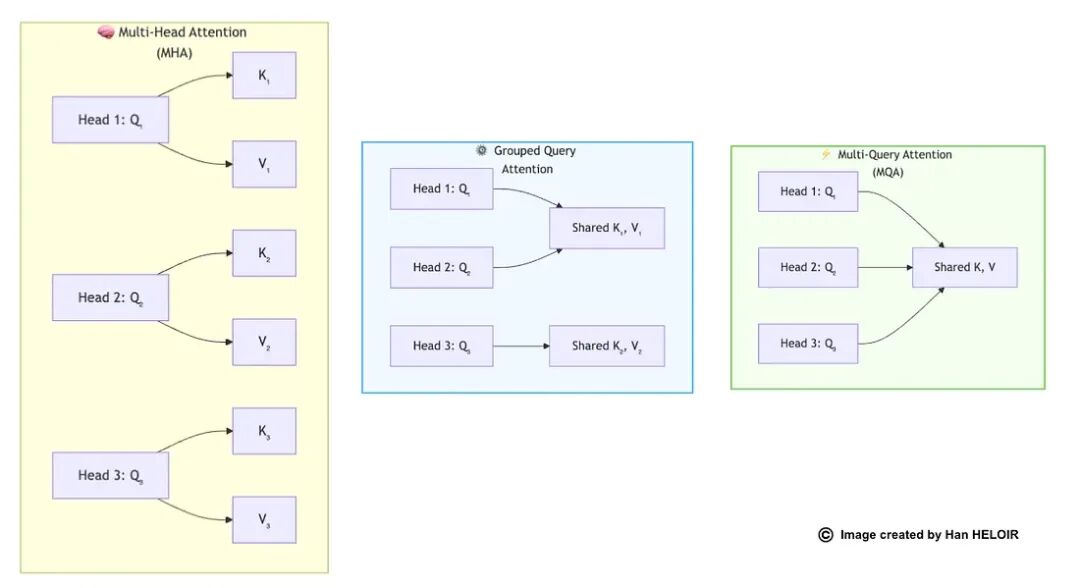
现代小型模型使用优化的注意力机制。让我展示演变过程:
1. 标准多头注意力(MHA)
每个头有自己的键、值和查询。这是2017年论文的原始方法。
内存使用:高——每个头存储单独参数
质量:优秀
用于:GPT-2、早期BERT、学术模型
2. 分组查询注意力(GQA)
头在组内共享键和值。你获得4倍内存减少,能力几乎相同。
内存使用:中等——组间共享参数
质量:几乎与MHA相同
用于:Llama-3、Mistral、大多数现代SLM
这是当前的最佳平衡点。你几乎没有任何损失,但获得了巨大的效率。
3. 多查询注意力(MQA)
所有头共享相同的键和值。最大效率,轻微质量权衡。
内存使用:低——最大共享
质量:良好(轻微下降)
用于:PaLM、一些移动模型
对于生产SLM,GQA是你的默认选择。所有成功的模型都在使用它。
你现在比刚听说Transformer的工程师更了解它。
下一个问题:你甚至应该构建一个吗?让我们弄清楚这一点。
第2节:决策 — “你甚至应该构建这个吗?”
你了解SLM如何工作。现在困难的问题是:你应该为你的用例构建一个吗?
大多数工程师直接跳到实现。这是一个错误。使用SLM与云API的决策对你的架构、成本和团队带宽有巨大影响。
让我们系统地做出这个决定。
决策树
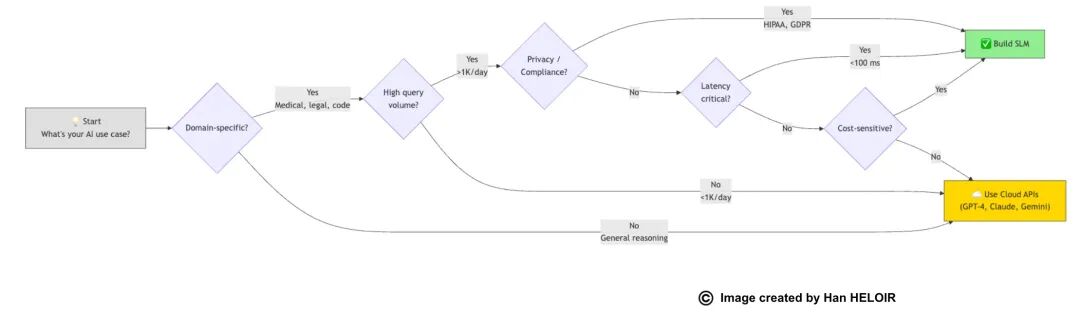 你甚至应该构建SLM吗?
你甚至应该构建SLM吗?
现实世界的信号
忘记清单。以下是了解你是否需要SLM的方法:
当你有这种对话时你需要SLM:“API演示完美,但我们实际上不能部署它,因为[合规/成本/延迟]。”
这就是信号。当API解决了技术问题但创造了业务问题时,你需要SLM。
一家金融科技初创公司使用OpenAI API构建了欺诈检测助手。效果很好。然后他们的客户安全团队问:"你把交易数据发送到OpenAI的服务器了?"项目冷了下来。他们用本地7B模型重建,该模型在欺诈模式上进行了微调。
相比之下,一个内容营销团队为博客文章生成构建了SLM。花了两个月微调。部署了。然后意识到GPT-4写得更好,而且他们每月只需要20篇文章。API每月只需50美元。他们的工程时间成本远不止这些。
混合真相
大多数生产系统不会只选择一个。它们两者都用。
从API开始。构建更快,维护更容易,在你弄清楚用户实际需要时提供灵活性。收集真实使用数据。看看哪些查询常见,哪些棘手,哪些昂贵。
然后,有选择地将部分功能迁移到SLM。
一个客户支持初创公司开始用GPT-4处理一切。三个月后,他们注意到80%的查询属于六类:订单状态、退货、产品规格、运输信息、账户问题和常见问题解答。他们专门针对这些类别微调了一个小型语言模型。现在SLM以每次查询0.0001美元而不是0.02美元处理常见情况。API处理奇怪的边缘案例和复杂升级。
他们的成本下降了85%。延迟改善了70%。而且他们没有花三个月构建可能不起作用的东西。
你的决策点
停止阅读并诚实回答:你是否有SLM或自定义语言模型能解决的实际问题?
不是"微调模型会很酷吗?“不是"我想学习SLM”。你是否有API无法处理的合规要求、成本压力、延迟需求或专业化领域?
- • 如果是,继续阅读。下一部分将向你展示如何构建一个。
- • 如果不是,使用API并交付你的产品。当你有SLM实际能解决的问题时再回来。
最好的工程师知道什么时候不构建。不要为了工程而工程。
第3节:构建 — 让我们做一个(不需要博士学位)
你决定构建一个SLM或自定义模型。现在到了大多数教程忽略的部分:在Jupyter notebook之外实际有效的实现。
我将向你展示三条路径。大多数教程只展示微调,因为它最容易解释。但根据你的约束条件,你可能需要不同的方法。让我们明确每条路径的实际含义。
三条路径(明智选择)
路径1:微调(从这里开始)
它是什么:获取现有模型并教它你的特定任务。你不是改变模型的核心知识——而是在其上添加专门能力。
把它想象成一个心脏病专家,他读了医学院(预训练)然后做了心脏病学住院医师(微调)。
何时使用:
- • 你有100-10,000个例子
- • 你的领域专业化但使用自然语言
- • 你想要几天而不是几个月的结果
这是你的默认路径。 它需要最少的数据、最少的计算和最少的专长。除非你有特定原因,否则从这里开始。
路径2:蒸馏(针对大小约束)
它是什么:将大型模型压缩成更小的模型,同时保持性能。你本质上是让GPT-4教7B模型模仿它在你的特定任务上的行为。
何时使用:
- • 你有一个完美工作但无法适应目标硬件的大型模型
- • 你在训练期间可以访问大型模型
- • 你需要任务绝对最小的模型
现实检查:这比微调更难,需要更多专业知识。只有当微调不符合你的约束条件时才走这条路。
路径3:从头训练(可能不要)
它是什么:就像听起来一样——初始化随机权重,从零开始在你的数据上训练模型。
何时使用:
- • 你的领域太独特,预训练模型对你毫无帮助
- • 高度专业化的科学符号、专有编程语言、完全非英语文字
- • 你有数十亿个训练令牌
- • 你有几个月的时间和严肃的GPU集群
诚实评估:这很少必要。即使是专业化领域,多语言模型或领域适应模型也给你巨大的领先优势。
只有当你有ML研究人员团队和严肃的计算预算时才从头训练。
在本节其余部分,我们专注于微调——95%的人应该走的路径。
一直在更新,更多的大模型学习和面试资料已经上传带到CSDN的官方了,有需要的朋友可以扫描下方二维码免费领取【保证100%免费】👇👇
微调配方
接下来会发生什么。我们将采用Mistral-7B(72亿参数,由Mistral AI在通用知识上训练)并将其适应你的领域。
这种技术称为LoRA — 低秩适应。我们不是更新所有72亿参数,而是添加小的"适配器"层,只训练总参数的1-2%。
为什么有效:基础模型已经了解语言、推理和一般事实。我们只是在教它你的特定模式和术语。
它高效、快速,并且适合消费级GPU内存。大学生可以在游戏PC上运行这个。
让我们构建它。
步骤1:环境设置
你需要Python 3.10+和至少8GB显存的GPU。如果你本地没有GPU,使用Google Colab(免费层可行)或Runpod(便宜的云GPU,每小时0.30美元)。
# 安装依赖pip install transformers==4.38.0 peft==0.8.2 bitsandbytes==0.42.0 accelerate==0.26.1 datasets==2.16.1 scipy
这些包在做实际工作:
- •
transformers:Hugging Face的加载和运行模型库 - •
peft:参数高效微调 - 处理LoRA适配器 - •
bitsandbytes:量化库 - 在更少内存中适应模型 - •
accelerate:分布式训练和内存优化 - •
datasets:数据加载和预处理 - •
scipy:某些优化器操作所需
这五个库做了所有繁重工作。感谢开源社区。
步骤2:加载基础模型
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfigimport torchmodel_name = "mistralai/Mistral-7B-Instruct-v0.2"# 配置4位量化bnb_config = BitsAndBytesConfig( load_in_4bit=True, bnb_4bit_quant_type="nf4", # NormalFloat4 - 神经网络最优 bnb_4bit_compute_dtype=torch.float16, bnb_4bit_use_double_quant=True # 嵌套量化以额外节省内存)# 加载量化模型model = AutoModelForCausalLM.from_pretrained( model_name, quantization_config=bnb_config, device_map="auto", # 自动使用GPU(如果可用) trust_remote_code=True)tokenizer = AutoTokenizer.from_pretrained(model_name)tokenizer.pad_token = tokenizer.eos_tokentokenizer.padding_side = "right" # 训练所需
刚刚发生了什么?
你将一个72亿参数的模型加载到约5GB内存中。没有量化,这需要28GB。魔法在于BitsAndBytesConfig设置。
nf4量化类型专为神经网络权重设计 - 它比标准4位整数更好地保持准确性。
双量化压缩量化常数本身,在质量损失可忽略的情况下额外节省约0.5GB。
步骤3:准备你的数据(这是大多数人失败的地方)
这是大多数教程失败的地方。他们向你展示如何微调但不解释什么数据格式实际有效。
你的数据需要是指令-响应对。每个例子应该显示模型将收到什么输入和你期望什么输出。
training_data = [\ {\ "instruction": "2型糖尿病的症状有哪些?",\ "output": "常见症状包括口渴增加、尿频、饥饿增加、体重意外减轻、疲劳、视力模糊、伤口愈合缓慢和频繁感染。"\ },\ {\ "instruction": "高血压如何诊断?",\ "output": "高血压通过多次血压测量诊断。两次独立场合读数130/80 mmHg或更高通常表明高血压。"\ },\ {\ "instruction": "解释1型和2型糖尿病的区别。",\ "output": "1型糖尿病是自身免疫性疾病,身体不产生胰岛素。2型糖尿病是代谢性疾病,身体对胰岛素产生抵抗或产生不足。"\ },\ # 添加100-1000+这样的例子\]
你需要多少数据?
真实答案:取决于任务复杂性。
- • 简单分类:100-500个例子通常足够。
- • 特定领域问答:500-2000个例子以获得良好覆盖。
- • 复杂推理:2000-10000个例子以获得可靠行为。
从小处着手。在200个例子上微调并测试。如果性能不足,有策略地收集更多数据——找到失败案例并添加覆盖它们的例子。
不要在知道微调是否有帮助之前浪费时间收集10,000个例子。
步骤4:格式化你的数据
模型期望特定格式。Mistral使用简洁的指令格式:
def format_instruction(example): """将你的数据转换为Mistral期望的格式""" prompt = f"""[INST] {example['instruction']} [/INST] {example['output']}</s>""" return prompt# 格式化所有训练数据formatted_data = [format_instruction(ex) for ex in training_data]
这种格式很重要。 Mistral是用[INST]和[/INST]标记训练的,以标记用户指令和助手响应。</s>标记表示响应结束。在微调期间使用这种确切格式确保模型理解对话结构。
如果你跳过这种格式化或使用错误的标记,你的模型将生成不遵循指令的混乱输出。
工程师浪费几天调试,结果意识到他们的提示格式错误,这种情况时有发生。
步骤5:配置LoRA
现在我们设置实际训练的适配器层:
from peft import LoraConfig, get_peft_model, prepare_model_for_kbit_training# 准备量化训练模型model.gradient_checkpointing_enable() # 在反向传播期间节省内存model = prepare_model_for_kbit_training(model)# 配置LoRAlora_config = LoraConfig( r=16, # 秩 - 控制适配器容量 lora_alpha=32, # 缩放因子(通常是秩的2倍) target_modules=["q_proj", "k_proj", "v_proj", "o_proj"], # 注意力层 lora_dropout=0.05, # 正则化以防止过拟合 bias="none", task_type="CAUSAL_LM")# 向模型添加LoRA适配器model = get_peft_model(model, lora_config)# 检查我们实际训练的参数数量trainable_params = sum(p.numel() for p in model.parameters() if p.requires_grad)total_params = sum(p.numel() for p in model.parameters())print(f"Trainable: {trainable_params:,} ({100 * trainable_params / total_params:.2f}%)")# 输出:Trainable: 134,217,728 (1.86%)
让我们分解这些参数:
r=16(秩):这控制适配器层的容量。更高秩意味着更多参数,这意味着学习复杂模式的能力更强,但也需要更多内存和过拟合风险。
- • 对于Mistral-7B,从16开始。
- • 如果训练后性能差,尝试32或64。
- • 如果你过拟合(训练性能好,验证性能差),尝试8。
lora_alpha=32:这缩放适配器的贡献。公式是scaling = lora_alpha / r,所以alpha=32和r=16,适配器以2×权重贡献。这是标准比率 - 除非你有特定原因改变,否则坚持使用。
target_modules:这些是我们适应的注意力层。Mistral使用标准注意力投影:查询、键、值和输出。
仅适应这四个层就能以最少的参数获得出色性能。你可以添加前馈层(gate_proj、up_proj、down_proj),但这会增加训练时间和内存使用。只有当仅注意力适应不够时才这样做。
lora_dropout=0.05:Dropout在训练期间随机将5%的适配器权重归零。这防止过拟合——模型不能过度依赖任何单一模式。对于小数据集(<500个例子),增加到0.1。
步骤6:训练配置
from transformers import Trainer, TrainingArguments, DataCollatorForLanguageModelingfrom datasets import Dataset# 转换为Hugging Face数据集格式dataset = Dataset.from_dict({"text": formatted_data})# 标记化数据def tokenize_function(examples): return tokenizer( examples["text"], truncation=True, max_length=512, padding="max_length" )tokenized_dataset = dataset.map( tokenize_function, batched=True, remove_columns=["text"])# 训练配置training_args = TrainingArguments( output_dir="./mistral-medical-lora", num_train_epochs=3, # 查看完整数据集的次数 per_device_train_batch_size=2, # 每GPU样本数(7B模型减少) gradient_accumulation_steps=8, # 有效批量大小 = 2 * 8 = 16 learning_rate=2e-4, # 适应速度 logging_steps=10, # 每10步记录一次 save_steps=100, # 每100步保存检查点 save_total_limit=3, # 只保留最近3个检查点 warmup_steps=50, # 逐渐增加学习率 fp16=True, # 使用混合精度(更快,更少内存) optim="paged_adamw_8bit", # 内存高效优化器 report_to="none", # 如果不需要禁用wandb/tensorboard)# 初始化训练器trainer = Trainer( model=model, args=training_args, train_dataset=tokenized_dataset, data_collator=DataCollatorForLanguageModeling(tokenizer, mlm=False))# 开始训练trainer.train()
训练将需要1-4小时,具体取决于你的数据集大小和GPU。你会看到这样的输出:
Step 10: Loss: 2.34Step 20: Loss: 1.76Step 30: Loss: 1.42Step 40: Loss: 1.18
损失应该随时间减少。注意几种模式:
健康训练:损失从约2.5稳步下降到约0.8-1.2。这意味着模型在学习。
不学习:损失始终在2.0-2.5左右。你的学习率可能太低(尝试3e-4),或者你的数据格式错误。
过拟合:损失下降到接近0(如0.1-0.3)。你在记忆训练数据。减少epoch,增加dropout,或添加更多样化的数据。
爆炸:损失突然跳到NaN或巨大数字。学习率太高(尝试1e-4),或者你有损坏的数据。
步骤7:保存和测试
# 保存LoRA适配器(7B模型仅约100MB)model.save_pretrained("./mistral-medical-lora")tokenizer.save_pretrained("./mistral-medical-lora")# 测试推理def generate_response(instruction): prompt = f"[INST] {instruction} [/INST]" inputs = tokenizer(prompt, return_tensors="pt").to(model.device) outputs = model.generate( **inputs, max_new_tokens=200, temperature=0.7, # 控制随机性(0=确定性,1=创造性) top_p=0.9, # 核采样阈值 do_sample=True, # 启用采样vs贪婪解码 pad_token_id=tokenizer.eos_token_id ) response = tokenizer.decode(outputs[0], skip_special_tokens=True) # 仅提取响应部分(在[/INST]之后) response = response.split("[/INST]")[-1].strip() return response# 测试print(generate_response("什么导致2型糖尿病?"))
如果你的模型给出合理输出:恭喜!你刚刚在消费级硬件上微调了一个7B语言模型。
如果输出是无意义的,你可能需要更多训练数据,或者你的数据格式错误。
这是一个快速调试清单:
- • 模型输出随机令牌?检查你的提示格式——确保你正确使用
[INST]和[/INST]。 - • 模型重复指令?增加
temperature到0.8-1.0或检查你是否正确提取响应部分。 - • 模型给出简短、不完整的答案?增加
max_new_tokens到300-500。 - • 模型拒绝回答?你可能微调了太多"我无法回答"响应的数据。检查你的训练数据。
实际发生了什么?
让我们揭开你刚刚做的事情的神秘面纱。基础Mistral模型已经知道如何生成连贯的文本、遵循指令和推理一般主题。
你没有教它那些技能。
你教了它什么:你的特定领域模式、术语和响应风格。模型学会了当你问医疗问题时,它应该用医疗术语和结构化解释回应。它学习了你的数据集模式和约定。
LoRA适配器是插入模型注意力机制的小型神经网络层。在训练期间,基础模型保持冻结——那72亿参数没有改变。只有你的1.34亿适配器参数训练。这就是为什么它快速且内存高效。
当你运行推理时,模型将冻结的基础知识与你的专门适配器结合起来。基础模型提供语言理解和推理。你的适配器将这些能力引向你的领域。
这样理解:Mistral是一个会说50种语言的专业翻译。你的LoRA适配器教那个翻译医疗术语和约定。
翻译仍然知道如何翻译——你只是给了他们领域专业知识。
内存现实
让我诚实说明教程没有提到的事情:训练比推理使用显著更多的内存。
推理期间(仅运行模型):
- • 4位量化Mistral-7B:约5GB显存
- • 你的LoRA适配器:约100MB
- • 激活内存:约500MB
- • 总计:约5.5GB
训练期间(反向传播和优化):
- • 模型权重:约5GB
- • 梯度:约3GB(仅可训练参数,但仍然可观)
- • 优化器状态:约4GB(Adam存储每个参数的动量和方差)
- • 激活检查点:约2GB(通过梯度检查点减少)
- • 总计:约14GB
这就是为什么8GB显存的GPU训练7B模型可能很紧张。我向你展示的设置(批量大小=2,梯度累积=8,启用梯度检查点)是优化为适合8GB,但勉强。
如果你内存不足,尝试:
- • 将批量大小减少到1
- • 将梯度累积增加到16
- • 将max_length从512减少到256
- • 使用更小的秩(r=8而不是16)
- • 考虑使用更小的模型(3B而不是7B)
第6节:部署 — 教程没有提到的生产秘密
你有一个微调模型。它在你的笔记本电脑上运行良好。现在你需要将它部署到生产环境。
这是大多数教程结束的地方。
它们向你展示快乐路径——在Jupyter notebook中训练模型,运行几个测试查询,庆祝。然后你只能自己弄清楚如何实际部署这个东西。
我将向你展示接下来会发生什么。真正的问题开始于:
- • 你的模型在某些输入上随机失败,你不知道为什么
- • 某些查询延迟飙升到5秒,其他只需300毫秒
- • 内存使用缓慢上升,直到服务器在凌晨3点崩溃
- • 用户抱怨响应不一致
让我们解决这个问题。
框架丛林(选择你的武器)
你有一个微调的Mistral模型。你如何在生产中实际运行它?
有几十种推理框架。每个都做出不同的权衡。选择错误会花费你数周的迁移时间。
让我帮你避免那种痛苦。
llama.cpp:主力军
它是什么:C++推理引擎,编译成单个二进制文件。没有Python依赖,没有版本地狱,没有神秘的conda环境破坏。
它擅长什么:
- • 在CPU上高效运行
- • 比任何其他框架更好地处理量化
- • 跨平台(Linux、Mac、Windows,甚至树莓派)
- • 无聊的技术,就是有效
当以下情况时使用llama.cpp:
- • 部署到没有GPU的服务器
- • 边缘设备(物联网、移动、嵌入式系统)
- • 你需要可靠性而不是前沿功能
- • 你想要5年后无需更新仍能工作的东西
作者(Georgi Gerganov)为每个CPU架构——Apple Silicon、x86、ARM——痴迷地优化。
vLLM:速度之王
它是什么:GPU优化的推理服务器,为大规模吞吐量构建。秘诀是连续批处理——动态批处理多个请求以最大化GPU利用率。
它擅长什么:
- • 每分钟处理数千个请求
- • 最大化GPU利用率(相同硬件上查询量增加10倍)
- • 高量级时每次查询成本低
当以下情况时使用vLLM:
- • 你有GPU
- • 高查询量(>1000请求/分钟)
- • 延迟不是你的主要约束(200-500毫秒可以接受)
- • 成本优化很重要
单个A100 GPU配合vLLM可以处理比运行朴素推理的10个GPU更多的流量。如果你每分钟服务数千个请求,vLLM通过减少基础设施成本自行支付。
ONNX Runtime:外交官
它是什么:微软的跨平台推理运行时。转换模型一次,随处运行——Windows、Mac、Linux、ARM、x86。
它擅长什么:
- • 跨平台兼容性
- • 与.NET/C++/Java集成
- • 企业生产环境
- • 稳定,文档齐全
当以下情况时使用ONNX:
- • 你需要跨平台部署
- • 你正在与现有企业基础设施集成
- • 你需要供应商支持和长期稳定性
转换过程偶尔痛苦,但一旦完成,部署就简单了。
这是决策矩阵:
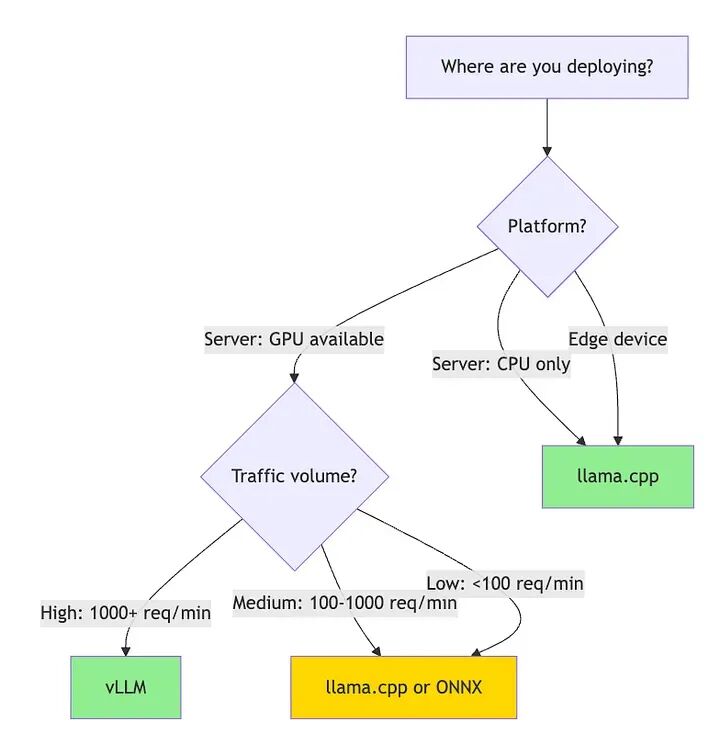
在本节中,我将专注于llama.cpp(最通用)和vLLM(最高性能)。这些涵盖了90%的生产部署。
使用llama.cpp部署
让我们让你的Mistral模型在生产中运行。首先,我们需要将其转换为llama.cpp的格式。
步骤1:转换为GGUF
GGUF是llama.cpp的模型格式。它为快速加载和高效推理而优化。
# 克隆llama.cppgit clone https://github.com/ggerganov/llama.cppcd llama.cpp# 构建make# 转换你的微调模型python convert-hf-to-gguf.py \ /path/to/your/mistral-medical-lora \ --outfile mistral-lora.gguf \ --outtype f16
这创建了一个全精度(16位浮点)GGUF文件。它很大——Mistral-7B约14GB。我们接下来将量化它。
步骤2:为生产量化
这里变得有趣了。你可以用不同比例权衡模型大小和质量。
# 4位量化(大多数用例推荐)./quantize mistral-medical.gguf mistral-medical-Q4_K_M.gguf Q4_K_M# 5位量化(更好质量,更大尺寸)./quantize mistral-medical.gguf mistral-medical-Q5_K_M.gguf Q5_K_M# 8位量化(接近原始质量)./quantize mistral-medical.gguf mistral-medical-Q8_0.gguf Q8_0
让我们谈谈这些量化级别实际意味着什么:
Q4_K_M(4位,中等质量):
- • 大小:约4.1GB(从14GB减少)
- • 质量损失:通常1-3%
- • 速度:快速推理,高效内存使用
- • 将此作为默认值
Q5_K_M(5位,中等质量):
- • 大小:约4.8GB
- • 质量损失:通常<1%
- • 速度:比Q4稍慢
- • 当质量比大小更重要时使用
Q8_0(8位):
- • 大小:约7.2GB
- • 质量损失:通常<0.5%
- • 速度:比Q4/Q5慢
- • 当你需要接近原始质量且有内存时使用
"K_M"后缀表示量化方法。 llama.cpp对不同层类型使用不同技术。"K"方法更新更好——它们在激进压缩的同时保持质量。
与原始模型的质量差异几乎不可察觉,但内存节省是巨大的。对于7B模型,你从14GB降到4GB。这就是需要昂贵的GPU服务器和运行在200美元二手工作站之间的区别。
步骤3:运行推理服务器
llama.cpp包括一个生产就绪的HTTP服务器:
./server \ -m mistral-medical-Q4_K_M.gguf \ -c 4096 \ # 上下文长度(模型能看到的最大令牌数) -t 8 \ # CPU线程数(匹配你的核心数) -ngl 35 \ # GPU层(如果你有GPU) --port 8080 \ --host 0.0.0.0 # 监听所有接口
服务器公开了OpenAI兼容的API。这很棒——无论你使用OpenAI的API还是本地模型,你的应用程序代码都不需要改变。
步骤4:进行API调用
import requestsimport jsondef query_model(instruction, temperature=0.7): """通过HTTP API查询部署的模型""" url = "http://localhost:8080/v1/chat/completions" payload = { "messages": [\ {\ "role": "user",\ "content": instruction\ }\ ], "temperature": temperature, "max_tokens": 200, "stream": False } response = requests.post(url, json=payload) result = response.json() return result['choices'][0]['message']['content']# 测试answer = query_model("2型糖尿病的症状有哪些?")print(answer)
这与OpenAI的API完全相同。 如果你用GPT-4构建了原型,你可以通过更改一个URL切换到本地模型。无需重写代码。
这就是标准接口的力量。
步骤5:流式处理以获得更好的用户体验
用户讨厌等待。流式处理在生成时显示令牌,使响应感觉更快。
def query_model_streaming(instruction): """流式传输令牌生成""" url = "http://localhost:8080/v1/chat/completions" payload = { "messages": [{"role": "user", "content": instruction}], "temperature": 0.7, "max_tokens": 200, "stream": True # 启用流式处理 } response = requests.post(url, json=payload, stream=True) for line in response.iter_lines(): if line: # 解析SSE格式 line = line.decode('utf-8') if line.startswith('data: '): data = line[6:] # 移除'data: '前缀 if data == '[DONE]': break try: chunk = json.loads(data) token = chunk['choices'][0]['delta'].get('content', '') if token: print(token, end='', flush=True) except json.JSONDecodeError: continue print() # 结尾换行# 测试流式处理query_model_streaming("解释胰岛素抵抗如何发展。")
你会看到令牌一个接一个出现,就像ChatGPT一样。完整响应需要相同时间,但感知延迟显著下降。 用户在模型仍在生成时就开始阅读。
使用vLLM部署(高吞吐量GPU服务)
如果你有GPU并且需要每分钟服务数百或数千个请求,vLLM是答案。
魔法是PagedAttention——它管理KV缓存(注意力缓存)就像操作系统管理内存一样。传统推理为最大序列长度预分配内存,浪费空间。vLLM动态分配仅需要的内容并在请求之间共享内存。
结果:相同硬件上吞吐量提高10-20倍。
设置vLLM
pip install vllm
启动服务器
from vllm import LLM, SamplingParams# 初始化模型llm = LLM( model="/path/to/your/mistral-medical-lora", tensor_parallel_size=1, # GPU数量(单GPU为1) max_model_len=4096, # 上下文长度 gpu_memory_utilization=0.9, # 使用90%的GPU内存 quantization="awq" # 可选:AWQ量化以提高速度)# 或作为HTTP服务器启动# python -m vllm.entrypoints.openai.api_server \# --model /path/to/your/mistral-medical-lora \# --port 8000
批处理
vLLM在批处理请求时表现出色:
from vllm import SamplingParams# 定义采样参数sampling_params = SamplingParams( temperature=0.7, top_p=0.9, max_tokens=200)# 同时处理多个请求prompts = [\ "什么导致2型糖尿病?",\ "解释胰岛素抵抗。",\ "糖尿病的危险因素有哪些?",\ # ...数百更多\]# vLLM自动批处理这些以最大化GPU利用率outputs = llm.generate(prompts, sampling_params)for output in outputs: print(f"Prompt: {output.prompt}") print(f"Response: {output.outputs[0].text}") print("---")
在单个A100 GPU上,vLLM可以为7B模型每秒处理50-100个请求。 那是每天400-800万个请求。尝试用朴素推理做到这一点——你需要10-20个GPU。
量化深度探索
你已经看到量化在行动。让我们理解实际发生了什么。
神经网络权重通常存储为32位或16位浮点数。量化将它们转换为8位、4位甚至2位整数。你正在丢弃精度。问题是:在模型崩溃之前你可以丢弃多少?
什么不起作用:朴素量化
只是将所有权重四舍五入为整数。这会破坏模型。0.0001的权重对某些计算很重要——将其四舍五入为0会破坏事情。
什么实际有效:智能量化
分析每层的权重分布。某些层比其他层更敏感。对不同层类型应用不同的量化策略。
llama.cpp的"K"量化方法做到了这一点。注意力层(Q、K和V投影)使用更高精度的量化。前馈层容忍更激进的压缩。
以下是不同量化级别的模型质量变化:
原始(FP16):100%基准质量
- • Q8_0:99.5%质量;几乎不可察觉的差异
- • Q5_K_M:98-99%质量——边缘案例轻微下降
- • Q4_K_M:96-98%质量——复杂推理明显下降,大多数任务可以接受
- • Q3_K_M:92-95%质量——开始挣扎,只在绝望时使用
- • Q2_K:85-90%质量——连贯但频繁错误
对于生产,Q4_K_M是最佳平衡点。 你获得75%的大小减少,质量损失2-4%。大多数用户不会注意到差异。
测量量化影响
不要凭感觉。测量它:
def evaluate_quantization(test_cases, model_original, model_quantized): """将量化模型与原始模型比较""" results = { 'exact_match': 0, 'similar': 0, 'different': 0 } for test in test_cases: response_orig = model_original.generate(test['prompt']) response_quant = model_quantized.generate(test['prompt']) # 简单比较(生产中使用适当指标) if response_orig == response_quant: results['exact_match'] += 1 elif similar_enough(response_orig, response_quant): # 定义你的阈值 results['similar'] += 1 else: results['different'] += 1 print(f"差异在:{test['prompt']}") print(f"原始:{response_orig}") print(f"量化:{response_quant}\n") print(f"完全匹配:{results['exact_match'] / len(test_cases):.1%}") print(f"相似响应:{results['similar'] / len(test_cases):.1%}") print(f"不同响应:{results['different'] / len(test_cases):.1%}")
在部署量化模型之前,在100-200个测试用例上运行这个。如果"不同"百分比高于10%,你的量化太激进了。
生产现实没有人提到
让我们谈谈你在生产中实际会遇到的问题。
问题1:长上下文内存峰值
你的模型处理大多数查询都很好,然后在长对话上崩溃。
问题:KV缓存随上下文长度增长。
KV缓存存储所有先前令牌的注意力键和值。对于4位量化的7B模型,每个令牌使用约0.5MB缓存。 2000令牌的对话仅缓存就需要1GB。
解决方案1:实现上下文修剪
def smart_context_pruning(conversation_history, model, max_tokens=2000): """在保留重要信息的同时将上下文保持在限制内""" # 标记化检查长度 full_context = "\n".join(conversation_history) token_count = len(model.tokenize(full_context)) if token_count <= max_tokens: return full_context # 策略1:保留第一条消息+最近的消息 system_prompt = conversation_history[0] recent_messages = conversation_history[-5:] # 最近5次交流 pruned_context = system_prompt + "\n" + "\n".join(recent_messages) # 策略2:如果仍然太长,截断最近的消息 if len(model.tokenize(pruned_context)) > max_tokens: tokens = model.tokenize(pruned_context) pruned_tokens = tokens[-max_tokens:] pruned_context = model.detokenize(pruned_tokens) return pruned_context
更好的解决方案:定期总结旧上下文。
def maintain_context_with_summary(conversation, model, summary_threshold=1500): """当上下文太长时总结旧上下文""" token_count = len(model.tokenize("\n".join(conversation))) if token_count > summary_threshold: # 总结除最后3条消息外的所有内容 old_messages = conversation[:-3] recent_messages = conversation[-3:] summary_prompt = f"用2-3句话总结这段对话:\n{old_messages}" summary = model.generate(summary_prompt) # 新对话:摘要+最近的消息 conversation = [f"之前对话摘要:{summary}"] + recent_messages return conversation
问题2:非确定性输出破坏测试
你为模型编写测试。它们在本地通过。它们在CI中失败。模型每次给出不同的答案。
这是采样问题。当temperature > 0时,模型从概率分布中随机采样。相同输入,每次不同输出。
测试解决方案:使用确定性生成。
def deterministic_generate(model, prompt): """生成可重现的输出""" return model.generate( prompt, temperature=0.0, # 无随机性 do_sample=False, # 贪婪解码 top_k=1, # 总是选择最可能的令牌 seed=42 # 固定随机种子(如果框架支持) )
对于生产:对需要一致性的任务(分类、提取)使用温度0,对创造性任务(写作、头脑风暴)使用温度0.7-1.0。
问题3:偶尔的垃圾输出
你的模型99%时间工作正常。然后随机输出"aaaaaaaaa"或重复同一短语50次。
当模型陷入重复循环或遇到奇怪的概率峰值时会发生这种情况。
解决方案:添加重复惩罚和停止条件。
def generate_with_safety_guards(model, prompt): """Generate with protections against common failure modes""" output = model.generate( prompt, max_tokens=200, temperature=0.7, repetition_penalty=1.2, # Penalize repeated tokens no_repeat_ngram_size=3, # Don't repeat any 3-token sequence early_stopping=True, # Stop at natural end bad_words_ids=None, # Can block specific tokens eos_token_id=model.config.eos_token_id ) # Post-generation validation if is_repetitive(output): # Regenerate with higher temperature output = model.generate(prompt, temperature=0.9) return outputdef is_repetitive(text, threshold=0.3): """Check if text has excessive repetition""" words = text.split() if len(words) < 10: return False unique_ratio = len(set(words)) / len(words) return unique_ratio < threshold
这些生产现实将你的SLM从原型转变为可靠的生产系统。量化、上下文管理和安全生成是区分玩具和真正生产就绪系统的关键。
问题4: 不一致的延迟
大多数查询在300毫秒内完成。有些需要2秒。您的用户会注意到这一点。
问题所在:变长序列。更长的输出需要更长的生成时间。每个token都是顺序生成的。
解决方案:设置一致的token限制并流式传输响应。
async def query_with_timeout(model, prompt, timeout_seconds=2.0): """确保响应在时间限制内完成""" import asyncio async def generate(): return model.generate( prompt, max_tokens=100, # 限制确保有界延迟 stream=True ) try: return await asyncio.wait_for(generate(), timeout=timeout_seconds) except asyncio.TimeoutError: # 回退:返回部分响应或错误 return "Response took too long, please try a simpler question."
对于关键的延迟要求,使用更短的max_tokens限制。一个7B模型生成约20-30 tokens/秒。要保证<500ms的响应,将token限制在10-15个以内。
生产环境监控
你无法改进你无法测量的东西。以下是需要跟踪的内容:
import timeimport loggingfrom collections import dequefrom dataclasses import dataclassfrom typing import Optional@dataclassclass InferenceMetrics: latency: float tokens_generated: int error: Optional[str] = Noneclass ProductionMonitor: def __init__(self, window_size=1000): self.metrics = deque(maxlen=window_size) self.total_requests = 0 def log_inference(self, latency, tokens=0, error=None): """记录每个推理请求""" self.total_requests += 1 self.metrics.append(InferenceMetrics(latency, tokens, error)) def get_stats(self): """计算当前性能统计""" if not self.metrics: return {} latencies = [m.latency for m in self.metrics if not m.error] errors = [m for m in self.metrics if m.error] sorted_lat = sorted(latencies) return { 'p50_latency_ms': sorted_lat[len(sorted_lat)//2] * 1000, 'p95_latency_ms': sorted_lat[int(len(sorted_lat)*0.95)] * 1000, 'p99_latency_ms': sorted_lat[int(len(sorted_lat)*0.99)] * 1000, 'error_rate': len(errors) / len(self.metrics), 'avg_tokens': sum(m.tokens_generated for m in self.metrics) / len(self.metrics), 'total_requests': self.total_requests } def check_health(self): """在性能下降时发出警报""" stats = self.get_stats() if stats.get('p95_latency_ms', 0) > 1000: logging.warning(f"High P95 latency: {stats['p95_latency_ms']:.0f}ms") if stats.get('error_rate', 0) > 0.05: logging.error(f"High error rate: {stats['error_rate']:.1%}")# 使用方法monitor = ProductionMonitor()def monitored_inference(model, prompt): """用监控包装所有推理""" start = time.time() error = None tokens = 0 try: response = model.generate(prompt) tokens = len(model.tokenize(response)) return response except Exception as e: error = str(e) raise finally: monitor.log_inference(time.time() - start, tokens, error) # 每100个请求检查一次健康状况 if monitor.total_requests % 100 == 0: print(monitor.get_stats()) monitor.check_health()
跟踪这些指标:
- • P50/P95/P99 延迟: 了解您的延迟分布
- • 错误率: 尽早捕获可靠性问题
- • 每秒token数: 监控生成速度
- • 内存使用: 检测内存泄漏
- • CPU/GPU利用率: 优化资源使用
当指标下降时设置警报。P95延迟跳升2倍表示有问题。错误率超过1%需要调查。
第7节: 真正的机遇
大多数公司仍然不理解这种转变。他们认为AI意味着"调用OpenAI API"。他们在特定任务上为通用模型烧钱。他们接受3秒的延迟,因为他们不知道存在替代方案。他们完全避免使用AI,因为合规团队对云API说不。
现在你知道得更多了。
你知道在特定任务上,针对领域数据微调的7B模型胜过通用模型。你知道Q4_K_M量化可以将内存使用量降低75%,而质量损失很小。你知道llama.cpp可以在CPU上以亚秒级延迟提供模型服务。你知道本地部署可以解决云API无法解决的合规问题。
这些知识就是优势。在大多数人还不知道SLM存在的时候使用它。
现在正在推出AI产品的公司并不是使用最大的模型。他们使用的是合适大小的模型。在他们的数据上微调。部署在他们的基础设施上。针对他们的特定用例进行优化。
这就是机遇。构建一些特定的东西,无情地优化它,将它交付给需要它的用户。
回顾与下一步
你学到的内容:
- • transformers如何工作(注意力机制、多头注意力、层架构)
- • 何时构建SLM vs. 使用API(基于合规性、成本、延迟的决策框架)
- • 如何在消费级硬件上使用LoRA微调7B模型
- • 如何使用llama.cpp(CPU)和vLLM(GPU)进行生产部署
- • 实际生产问题及其解决方法
你的下一个实验:
-
- 选择一个你非常了解的窄领域(你的工作、爱好或特定任务)
-
- 收集200对指令-响应对
-
- 使用本文中的确切代码微调Mistral-7B
-
- 使用llama.cpp部署它
-
- 在20个测试用例上将它与GPT-4进行比较
AI的未来就在这里。它运行在你已经拥有的硬件上,针对你实际面临的问题进行微调。
现在去构建一些东西吧。
延伸阅读
研究论文:
- • Attention Is All You Need — 原始transformer论文
- • LoRA: Low-Rank Adaptation — 参数高效微调技术
工具与框架:
- • llama.cpp — LLM的CPU推理
- • vLLM — 高吞吐量GPU推理
- • Hugging Face Transformers — 模型中心和训练库
模型:
- • Mistral-7B — 出色的微调基础模型
- • Phi-3 — 微软的高效小型模型
- • Qwen3 — 阿里巴巴的多语言SLM系列
如何系统的学习大模型 AI ?
由于新岗位的生产效率,要优于被取代岗位的生产效率,所以实际上整个社会的生产效率是提升的。
但是具体到个人,只能说是:
“最先掌握AI的人,将会比较晚掌握AI的人有竞争优势”。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
一直在更新,更多的大模型学习和面试资料已经上传带到CSDN的官方了,有需要的朋友可以扫描下方二维码免费领取【保证100%免费】👇👇
01.大模型风口已至:月薪30K+的AI岗正在批量诞生

2025年大模型应用呈现爆发式增长,根据工信部最新数据:
国内大模型相关岗位缺口达47万
初级工程师平均薪资28K(数据来源:BOSS直聘报告)
70%企业存在"能用模型不会调优"的痛点
真实案例:某二本机械专业学员,通过4个月系统学习,成功拿到某AI医疗公司大模型优化岗offer,薪资直接翻3倍!
02.大模型 AI 学习和面试资料
1️⃣ 提示词工程:把ChatGPT从玩具变成生产工具
2️⃣ RAG系统:让大模型精准输出行业知识
3️⃣ 智能体开发:用AutoGPT打造24小时数字员工
📦熬了三个大夜整理的《AI进化工具包》送你:
✔️ 大厂内部LLM落地手册(含58个真实案例)
✔️ 提示词设计模板库(覆盖12大应用场景)
✔️ 私藏学习路径图(0基础到项目实战仅需90天)






第一阶段(10天):初阶应用
该阶段让大家对大模型 AI有一个最前沿的认识,对大模型 AI 的理解超过 95% 的人,可以在相关讨论时发表高级、不跟风、又接地气的见解,别人只会和 AI 聊天,而你能调教 AI,并能用代码将大模型和业务衔接。
- 大模型 AI 能干什么?
- 大模型是怎样获得「智能」的?
- 用好 AI 的核心心法
- 大模型应用业务架构
- 大模型应用技术架构
- 代码示例:向 GPT-3.5 灌入新知识
- 提示工程的意义和核心思想
- Prompt 典型构成
- 指令调优方法论
- 思维链和思维树
- Prompt 攻击和防范
- …
第二阶段(30天):高阶应用
该阶段我们正式进入大模型 AI 进阶实战学习,学会构造私有知识库,扩展 AI 的能力。快速开发一个完整的基于 agent 对话机器人。掌握功能最强的大模型开发框架,抓住最新的技术进展,适合 Python 和 JavaScript 程序员。
- 为什么要做 RAG
- 搭建一个简单的 ChatPDF
- 检索的基础概念
- 什么是向量表示(Embeddings)
- 向量数据库与向量检索
- 基于向量检索的 RAG
- 搭建 RAG 系统的扩展知识
- 混合检索与 RAG-Fusion 简介
- 向量模型本地部署
- …
第三阶段(30天):模型训练
恭喜你,如果学到这里,你基本可以找到一份大模型 AI相关的工作,自己也能训练 GPT 了!通过微调,训练自己的垂直大模型,能独立训练开源多模态大模型,掌握更多技术方案。
到此为止,大概2个月的时间。你已经成为了一名“AI小子”。那么你还想往下探索吗?
- 为什么要做 RAG
- 什么是模型
- 什么是模型训练
- 求解器 & 损失函数简介
- 小实验2:手写一个简单的神经网络并训练它
- 什么是训练/预训练/微调/轻量化微调
- Transformer结构简介
- 轻量化微调
- 实验数据集的构建
- …
第四阶段(20天):商业闭环
对全球大模型从性能、吞吐量、成本等方面有一定的认知,可以在云端和本地等多种环境下部署大模型,找到适合自己的项目/创业方向,做一名被 AI 武装的产品经理。
- 硬件选型
- 带你了解全球大模型
- 使用国产大模型服务
- 搭建 OpenAI 代理
- 热身:基于阿里云 PAI 部署 Stable Diffusion
- 在本地计算机运行大模型
- 大模型的私有化部署
- 基于 vLLM 部署大模型
- 案例:如何优雅地在阿里云私有部署开源大模型
- 部署一套开源 LLM 项目
- 内容安全
- 互联网信息服务算法备案
- …
学习是一个过程,只要学习就会有挑战。天道酬勤,你越努力,就会成为越优秀的自己。
如果你能在15天内完成所有的任务,那你堪称天才。然而,如果你能完成 60-70% 的内容,你就已经开始具备成为一名大模型 AI 的正确特征了。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 20
20 0
0- 0



 已为社区贡献409条内容
已为社区贡献409条内容

所有评论(0)