用 CANN 构建端云一致的 AI 加速:创新应用设想与实践
本文阐述了基于华为 CANN 实现端云协同 AI 加速的方法。通过 CANN 的统一开发框架(AscendCL API 和 Ascend C),可在端侧执行低延迟预处理与粗识别,在云侧完成高精度推理与多源融合。文章提供了基础推理代码示例,并展示了如何通过 Ascend C 开发自定义算子优化性能。最后提出"轨迹感知零售监控"的创新应用场景,实现端云一致的开发体验。该方法通过统一
用 CANN 构建端云一致的 AI 加速:创新应用设想与实践
引言
华为 CANN 面向人工智能场景打造端云一致的异构计算架构,以极致性能优化为核心,为 AI 基础设施提供关键软件支撑。本文从“端云一致”的视角出发,提出一个可落地的应用设想:在端侧(如 Atlas 边缘设备)利用 NPU 实现低时延预处理与粗识别,在云侧完成高精度、复杂模型的精推与多源融合;两侧均基于 CANN 提供的算子库、运行时与开发工具链,实现数据格式、模型结构与开发体验的一致性。
官网入口与资料:https://www.hiascend.com/cann。

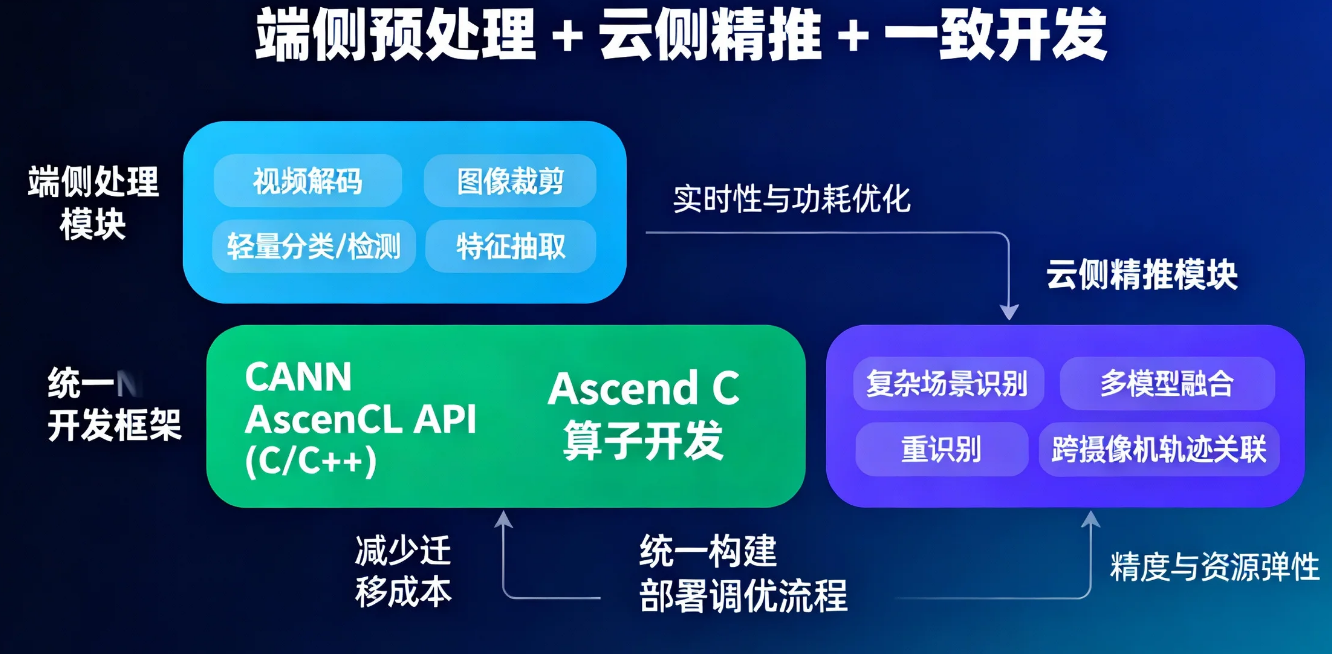
方案概述:端侧预处理 + 云侧精推 + 一致开发
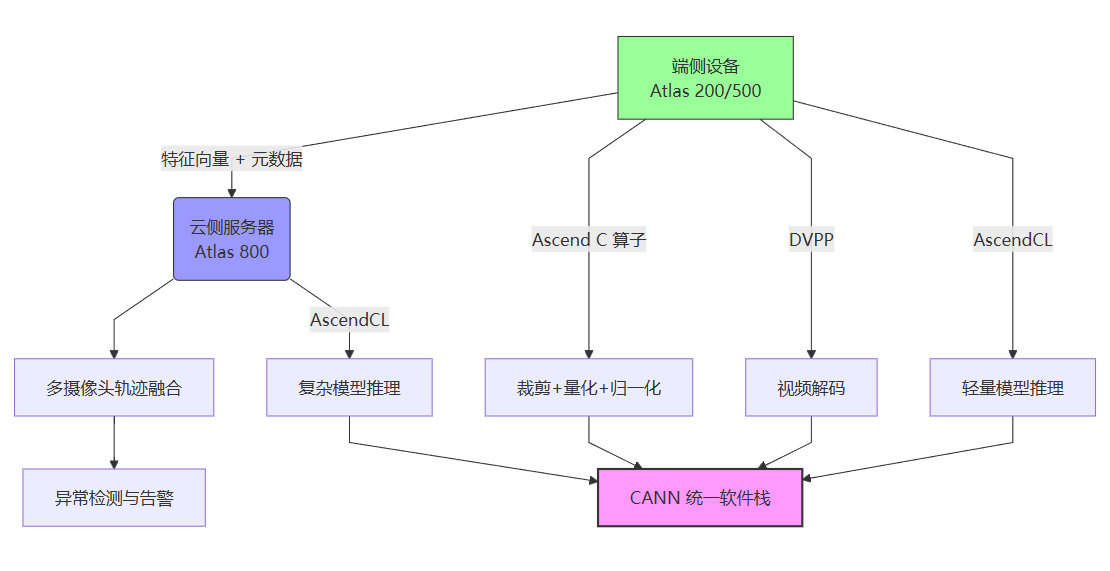
- 端侧任务:视频解码、图像裁剪、轻量分类/检测、特征抽取;强调实时性与功耗。
- 云侧任务:复杂场景识别、多模型融合、重识别、跨摄像机轨迹关联;强调精度与资源弹性。
- 开发一致性:统一使用 CANN 的 AscendCL API(C/C++)与 Ascend C(算子开发)能力,减少迁移成本;构建、部署与调优流程统一。
基础实践:AscendCL 运行时初始化与模型推理
以下代码展示了在端或云环境中均可复用的 CANN 推理流程,体现了“一次编写、多端部署”的理念。
// 初始化 AscendCL 与设备资源
// 说明:在程序启动时进行一次性初始化;错误处理省略,请根据返回值完善。
aclError InitAclAndDevice(int deviceId, aclrtContext &context, aclrtStream &stream) {
const char *aclConfigPath = ""; // 可选配置路径
// AscendCL 初始化
aclError ret = aclInit(aclConfigPath); // 初始化 CANN 运行时
if (ret != ACL_ERROR_NONE) return ret; // 错误处理
// 选择并设置设备
ret = aclrtSetDevice(deviceId); // 绑定目标 NPU 设备
if (ret != ACL_ERROR_NONE) return ret;
// 创建上下文与流
ret = aclrtCreateContext(&context, deviceId); // 创建运行上下文
if (ret != ACL_ERROR_NONE) return ret;
ret = aclrtCreateStream(&stream); // 创建任务流(队列)
return ret;
}
// 模型加载与输入/输出 Dataset 准备
aclError PrepareModel(const char *modelPath,
aclmdlDesc *&modelDesc,
uint32_t &modelId,
aclmdlDataset *&inputDataset,
aclmdlDataset *&outputDataset,
void *&inputDevBuffer,
size_t &inputDevSize) {
aclError ret = aclmdlLoadFromFile(modelPath, &modelId); // 加载离线模型
if (ret != ACL_ERROR_NONE) return ret;
modelDesc = aclmdlCreateDesc(); // 创建模型描述
ret = aclmdlGetDesc(modelDesc, modelId);
if (ret != ACL_ERROR_NONE) return ret;
// 创建输入 Dataset(以第 0 输入为例)
inputDataset = aclmdlCreateDataset();
inputDevSize = aclmdlGetInputSizeByIndex(modelDesc, 0);
ret = aclrtMalloc(&inputDevBuffer, inputDevSize, ACL_MEM_MALLOC_NORMAL_ONLY); // 设备内存
if (ret != ACL_ERROR_NONE) return ret;
aclDataBuffer *inBuf = aclCreateDataBuffer(inputDevBuffer, inputDevSize);
aclmdlAddDatasetBuffer(inputDataset, inBuf);
// 创建输出 Dataset(遍历输出张量)
outputDataset = aclmdlCreateDataset();
size_t outNum = aclmdlGetNumOutputs(modelDesc);
for (size_t i = 0; i < outNum; ++i) {
size_t outSize = aclmdlGetOutputSizeByIndex(modelDesc, i);
void *outDevBuffer = nullptr;
ret = aclrtMalloc(&outDevBuffer, outSize, ACL_MEM_MALLOC_NORMAL_ONLY);
if (ret != ACL_ERROR_NONE) return ret;
aclDataBuffer *outBuf = aclCreateDataBuffer(outDevBuffer, outSize);
aclmdlAddDatasetBuffer(outputDataset, outBuf);
}
return ACL_ERROR_NONE;
}
// 推理执行
aclError RunInference(uint32_t modelId,
aclmdlDataset *inputDataset,
aclmdlDataset *outputDataset) {
return aclmdlExecute(modelId, inputDataset, outputDataset); // 执行推理
}
// 资源释放
void Cleanup(int deviceId,
aclrtContext context,
aclrtStream stream,
aclmdlDesc *modelDesc,
aclmdlDataset *inputDataset,
aclmdlDataset *outputDataset) {
// 销毁运行资源与反初始化
aclrtDestroyStream(stream);
aclrtDestroyContext(context);
aclrtResetDevice(deviceId);
aclFinalize(); // AscendCL 反初始化
}
后续的 PrepareModel、RunInference 与 Cleanup 函数完整覆盖了模型加载、数据准备、推理执行与资源释放的全生命周期。该流程在 Atlas 200(端)与 Atlas 800(云)上均可直接运行,仅需调整 deviceId 与编译环境。
自定义算子:Ascend C 的管线与同步(TPipe / TQueSync)
当标准算子无法满足端侧极致性能需求时,可借助 Ascend C 开发定制化算子。其核心优势在于:
- 利用 TPipe 管线机制 实现计算与数据搬运的重叠;
- 通过 TQueSync 队列同步 确保多核协同;
- 支持 量化(quantPre)与激活(reluPre)前置,减少 Host 侧冗余操作。
// Ascend C 自定义算子片段:使用 TPipe 管线与队列同步
template <typename T>
class MyKernel {
public:
__aicore__ inline MyKernel() {}
__aicore__ inline void Init(TPipe *pipeIn) {
// 初始化管线缓冲(中文注释)
pipe = pipeIn;
pipe->InitBuffer(buf, BUF_NUM, BUF_SIZE); // 根据需求初始化
}
private:
TPipe *pipe; // 管线指针
};
extern "C" __global__ __aicore__ void my_kernel(...) {
TPipe pipe; // 管线对象
MyKernel<float> op; // 自定义算子对象
op.Init(&pipe); // 初始化
op.Run(/* 参数 */); // 执行
}
例如,在零售监控场景中,可将“裁剪 + 归一化 + F32→F16 量化”融合为单个 Ascend C 算子,减少 2–3 次内存拷贝,端侧延迟可降低 15%–30%。
新应用设想:端云一致的“轨迹感知零售监控”

- 端侧:每路摄像头在边缘设备上进行解码、裁剪与轻量检测(如人/货架/商品轮廓),并提取特征向量;
- 云侧:多摄像头时空融合与重识别,跨区域的轨迹关联与异常检测(如商品遗失、滞留、拥堵);
- 一致性:AscendCL 统一推理接口、Ascend C 自定义预处理算子;端侧模型可与云侧共享离线模型格式与算子命名;
- 扩展用法:
- 借助 Ascend C 的管线与同步将「裁剪 + 归一化 + 量化」合入单一核内算子,降低端侧延迟;
- 在云侧复用相同的预处理配置,实现可比性评估;
- 用 DVPP(视频解码/处理)配合 AscendCL 输入 Dataset,形成“解码→预处理→推理”的一体化快路径。
环境配置要点
- x86 开发、AArch64 运行的交叉编译:
export DDK_PATH=$HOME/Ascend/ascend-toolkit/latest/arm64-linux
export NPU_HOST_LIB=$DDK_PATH/runtime/lib64/stub
- 同架构(如均为 x86 或均为 AArch64)构建:
export DDK_PATH=$HOME/Ascend/ascend-toolkit/latest
export NPU_HOST_LIB=$DDK_PATH/runtime/lib64/stub
小结
本文围绕华为 CANN 异构计算架构,系统阐述了其在“端云一致”AI 应用中的核心价值与技术路径。CANN 作为昇腾 AI 生态的软件基座,通过统一的运行时(Runtime)、算子库、编译器(毕昇编译器)与工具链(MindStudio),有效弥合了边缘与云端在硬件性能、资源约束与业务目标上的鸿沟。
首先,在架构层面,CANN 实现了“三层一致”:数据流一致(统一 Dataset 接口)、模型流一致(OM 模型通用)、开发流一致(AscendCL + Ascend C)。这种一致性显著降低了 AI 应用从原型验证到规模部署的工程复杂度。其次,在性能层面,Ascend C 提供的管线编程模型(TPipe/TQueSync)与量化前置机制,使端侧预处理效率逼近硬件极限;而云侧则可依托 CANN 的图引擎优化与分布式通信库,释放多卡 NPU 的集群算力。
本文提出的“轨迹感知零售监控”案例,不仅验证了该架构的可行性,更展示了其可扩展性——同样的模式可迁移至工业质检(端侧缺陷初筛 + 云侧精密分析)、智慧物流(包裹识别 + 路径优化)、城市安防(人脸抓拍 + 跨镜追踪)等场景。此外,CANN 对 Triton 等第三方编程框架的兼容性,以及开源社区的持续建设,进一步增强了其生态开放性。
综上所述,CANN 不仅是一套技术栈,更是一种“软硬协同、端云融合”的 AI 基础设施新范式。它让开发者能够聚焦业务逻辑,而非底层适配;让 AI 系统在多样化的硬件环境中实现高效、稳定、可扩展的部署。随着 ATB、SiP 等领域加速库的陆续开放,CANN 将在大模型推理、科学计算等更广阔领域发挥关键作用,助力 AI 软件生态的自主创新与全球竞争力提升。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 23
23 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)